

L3HCTF的题目质量相当高了,这次来复现一下比赛的时候差一点就解出的Lamda, 也是把自己当时比赛时候的思路和最后看了WP之后的正确思路都捋一捋,这种使用现成的项目对流量进行加密的流量题确实蛮有意思。
题目背景
出题人是拿一个C++的项目(ReHLDS)搭了一个CS1.6的服务器,并用客户端连接服务器,而在这同时进行了抓包,题目附件就是抓到的流量包,和虎符CTF的流量取证题目有着异曲同工之妙,都蛮好玩。
解题过程
flag的前几部分在地图的资源包中,可以在流量包的tcp部分看到
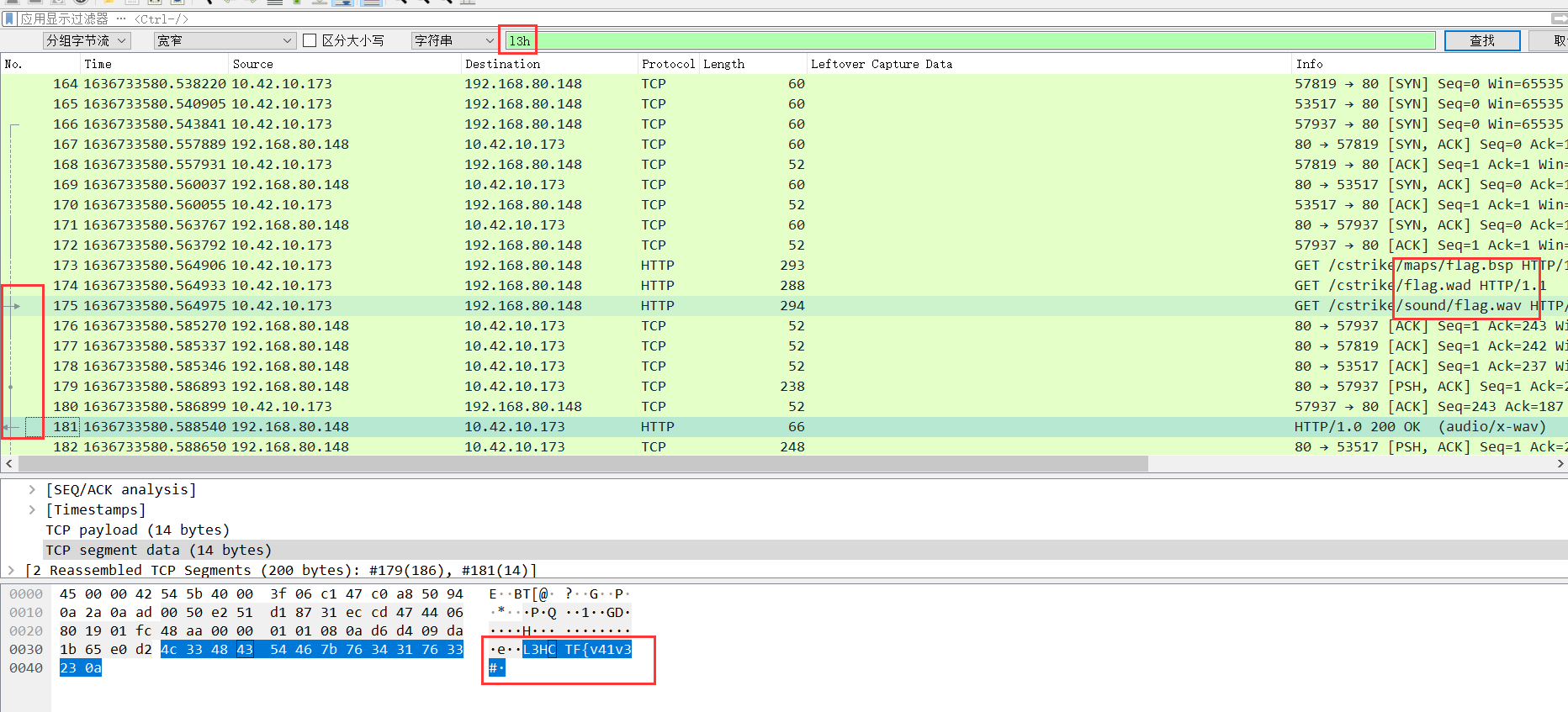
比如直接搜索l3h,就能看到在wav文件中存在flag,同时还发现了flag.bsp和flag.wad文件,同时这里文件路径里的cstrike也明示是cs的流量了
而对于wad文件,谷歌之
同样的,对于bsp文件
取个交集,遂与搜GCFScape
https://nemstools.github.io/pages/GCFScape-Download.html
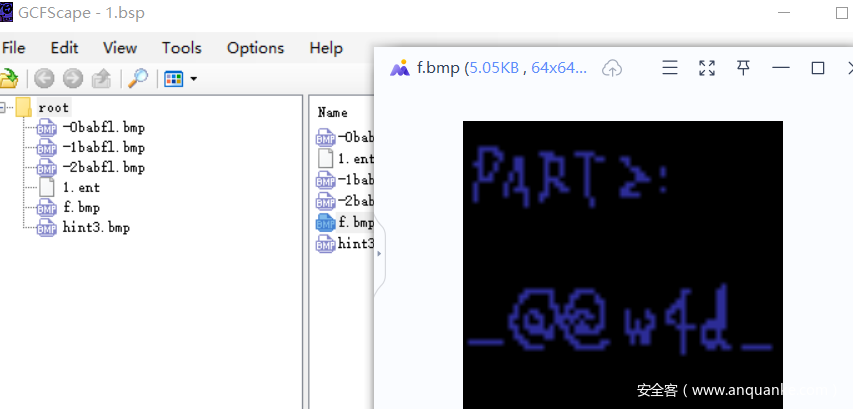
在bsp中可以看到第二部分的flag
同时还有hint
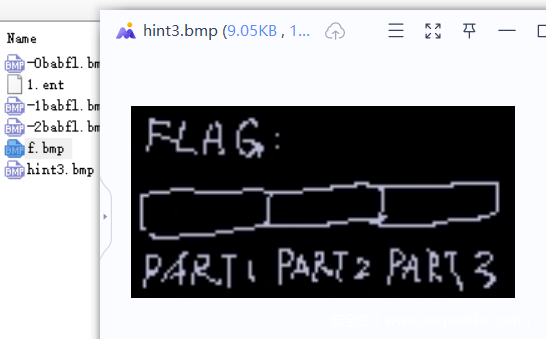
说flag分为3部分
根据比赛时的hint, part3应该在后面的udp数据中,还提示说
ReHLDS might be helpful for part 3
github搜了一下ReHLDS, 找到一个仓库,先尝试性搜了一下端口号来验证一下我们找的项目对不对
流量包中端口号如下
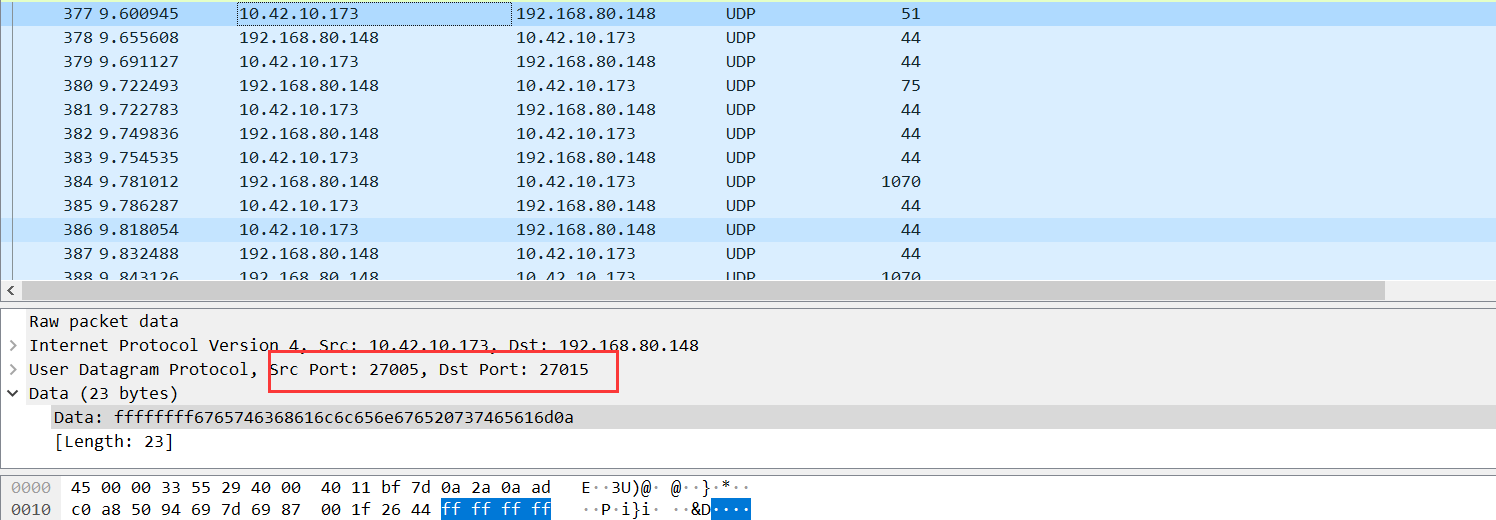
而项目中的端口号为
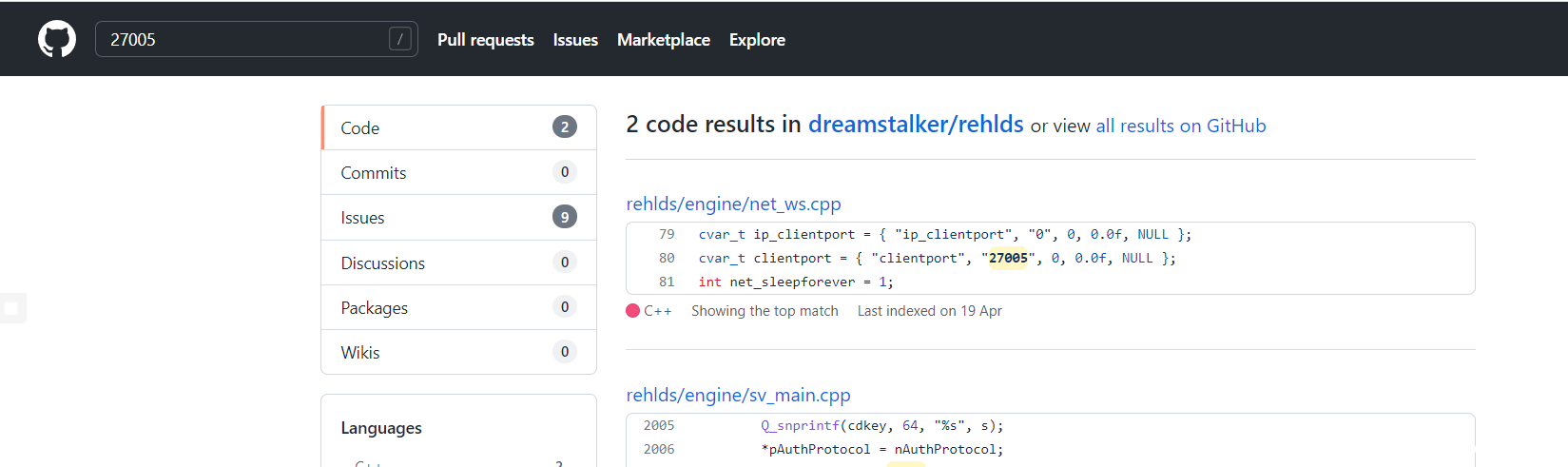
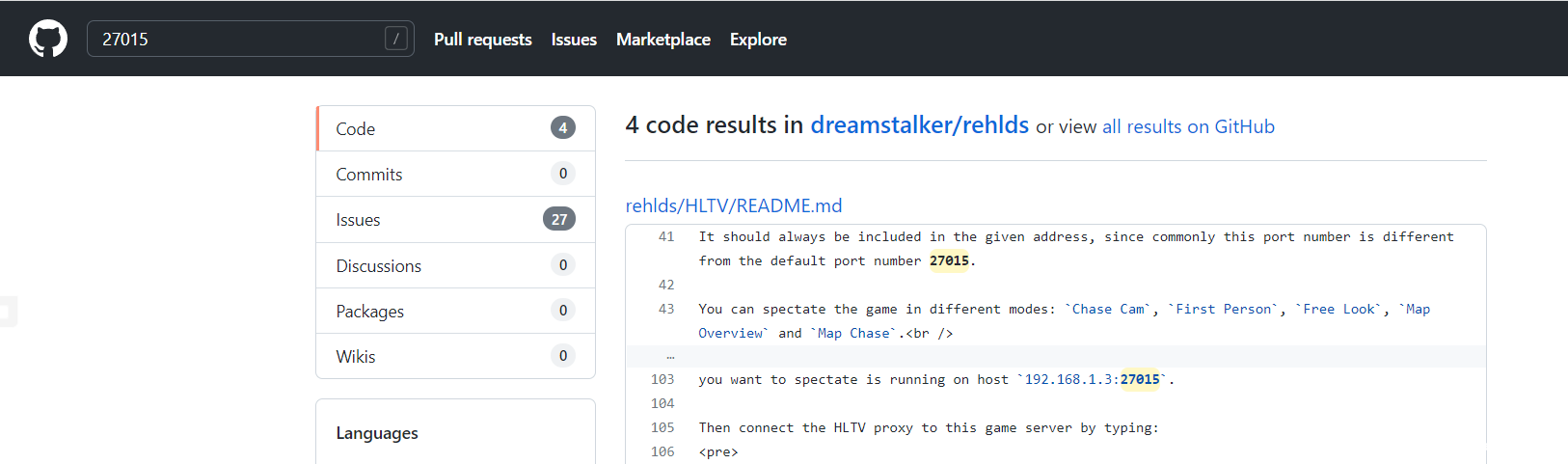
可以看到27005是客户端,27015是服务器,显然我们八成是找对项目了
故对应流量包中,10开头的是客户端 192开头的是服务器
进一步,流量包中后续是大部分的UDP流量,则搜索SOCK_DGRAM找找UDP包是用哪个函数发送的
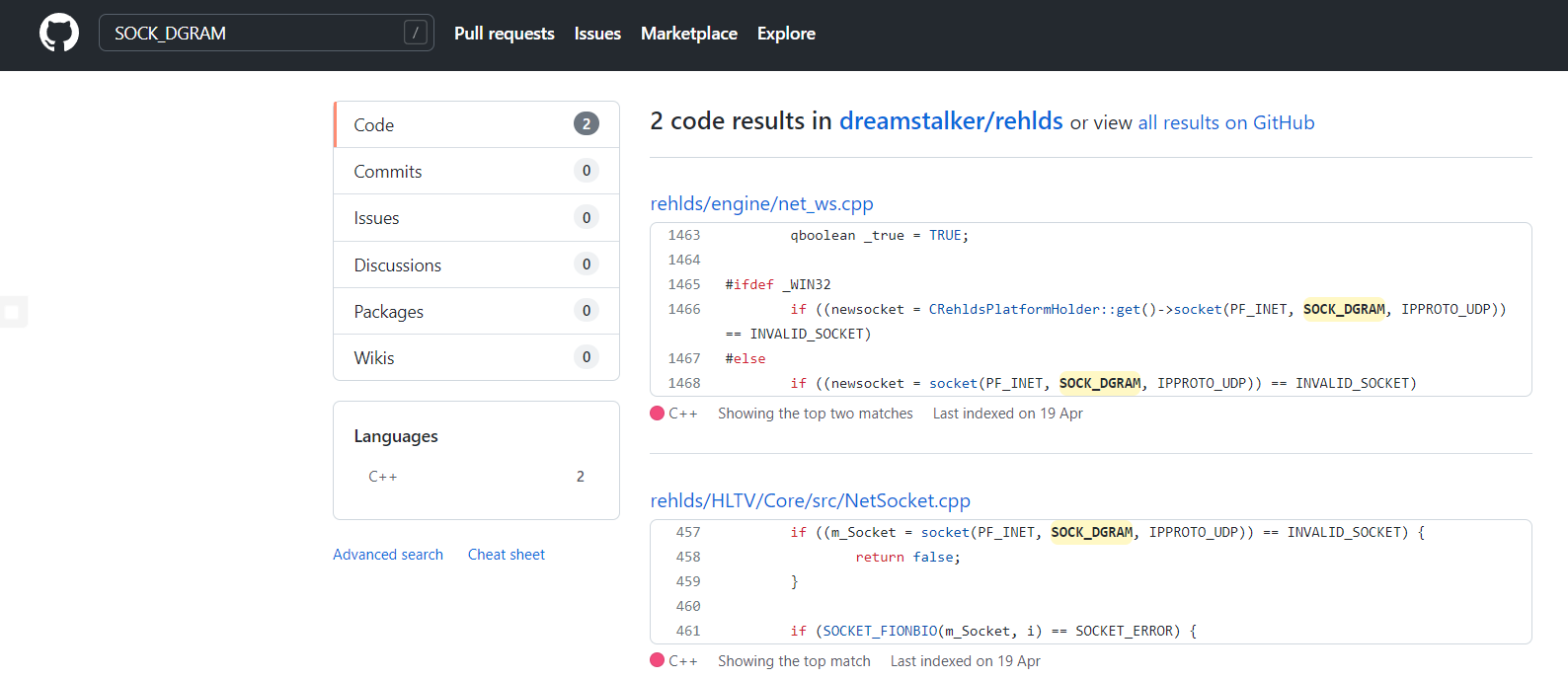
找到了对应函数,进一步去找发包sendto
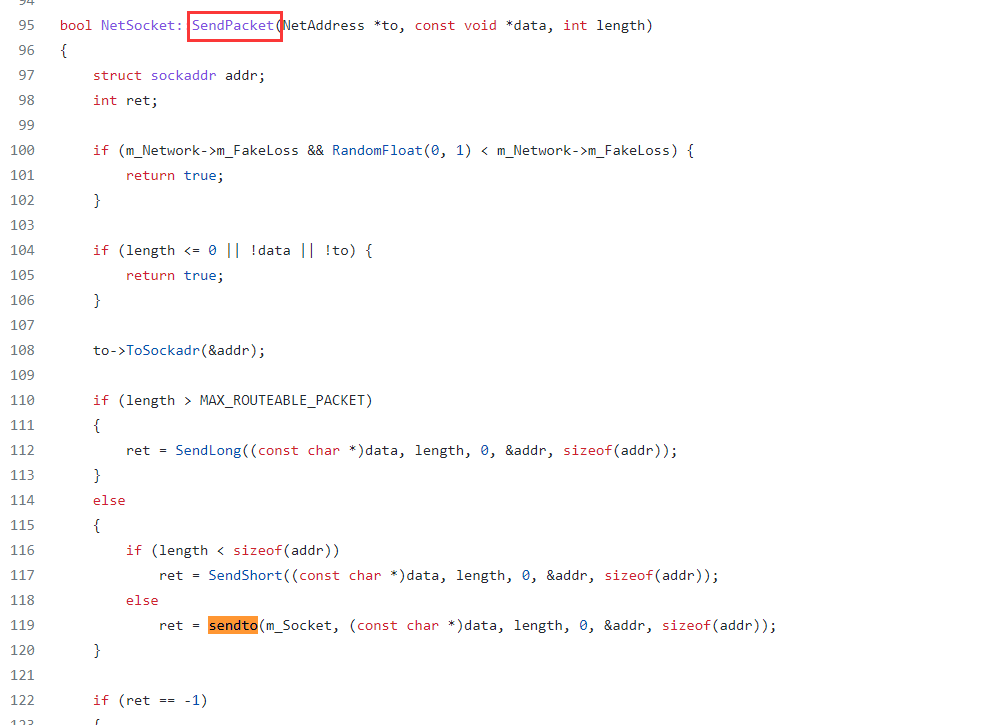
定位到了是在SendPacket调用的sentto,进一步就去看又有哪些调用这个函数就行了…搁着套娃,这样一路找下去找到加密部分的函数,解密部分的函数要么就看加密的过程来逆,要么就是找项目中现成的解密函数
或者换个思路,看看issue中有没有相关的问题
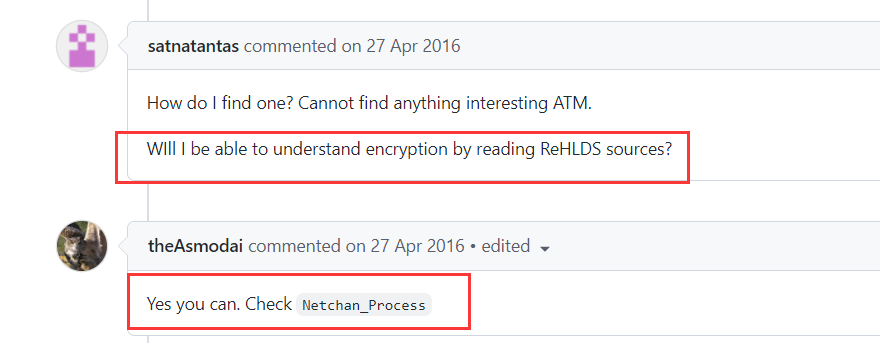
这里刚好有人在issue中提问了解密部分,那我们就check一下Netchan_Process函数
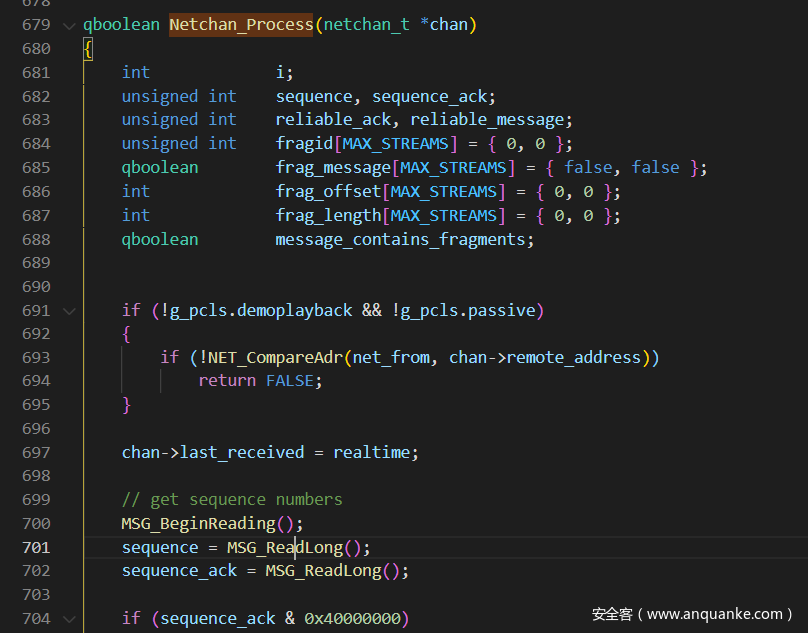
这个函数中调用了一个解密函数
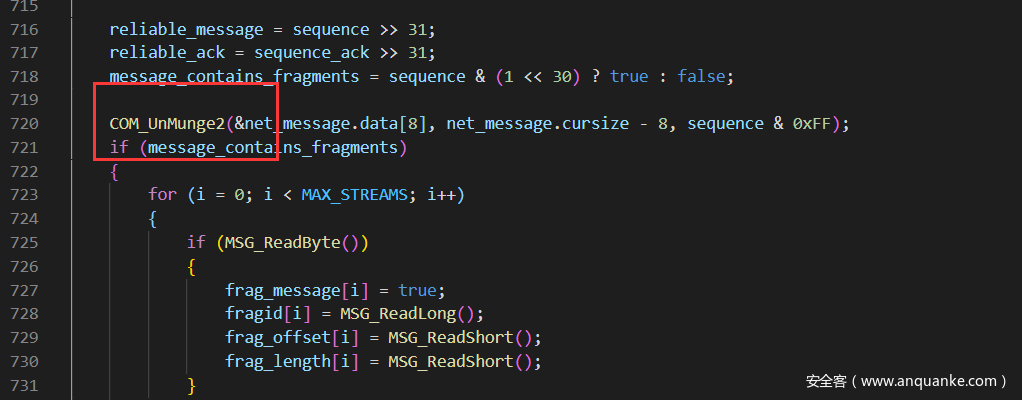
定义在这
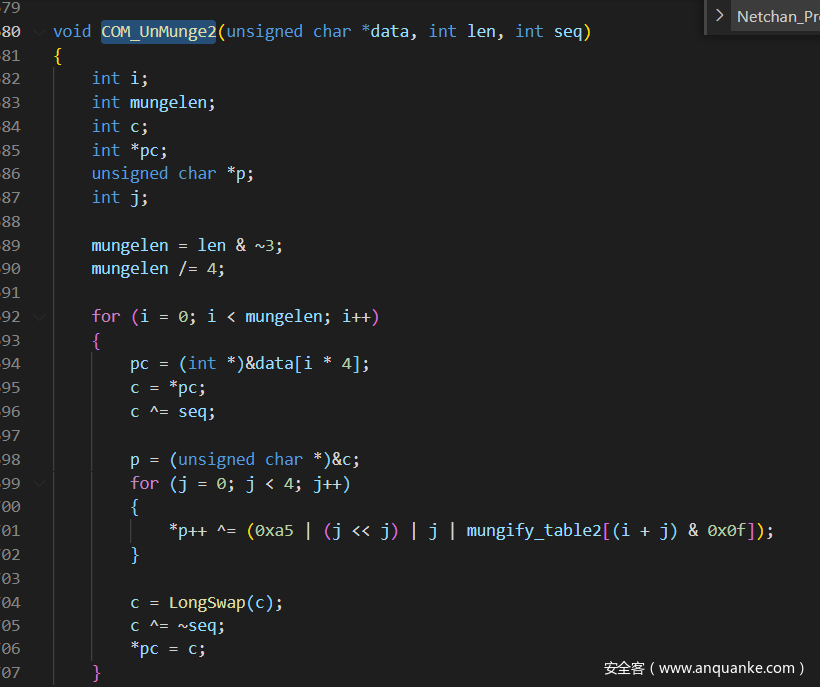
然后就是要看看参数
COM_UnMunge2(&net_message.data[8], net_message.cursize - 8, sequence & 0xFF);
其中sequence在MSG_ReadLong中
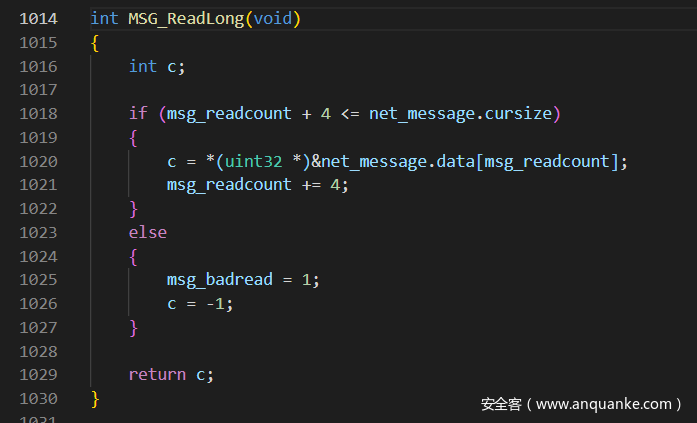
可以看到data的前4个字节就是sequence
对照udp流量

可以看到除了第一个ffffffff是建立连接时的特征字节外,其它包的前4个字节正是每次发包对应的字节
然后sequence & 0xFF,即每个包的第一个字节是seq
前两个参数就是data和len,只不过要去掉udp的前8个字节
这里写一个so文件用python来调用从而进行解密
extern "C"
{
int _LongSwap(int l)
{
unsigned int res = __builtin_bswap32(*(unsigned int *)&l);
return *(int *)&(res);
}
const unsigned char mungify_table[] =
{
0x7A, 0x64, 0x05, 0xF1,
0x1B, 0x9B, 0xA0, 0xB5,
0xCA, 0xED, 0x61, 0x0D,
0x4A, 0xDF, 0x8E, 0xC7};
const unsigned char mungify_table2[] =
{
0x05, 0x61, 0x7A, 0xED,
0x1B, 0xCA, 0x0D, 0x9B,
0x4A, 0xF1, 0x64, 0xC7,
0xB5, 0x8E, 0xDF, 0xA0};
unsigned char mungify_table3[] =
{
0x20, 0x07, 0x13, 0x61,
0x03, 0x45, 0x17, 0x72,
0x0A, 0x2D, 0x48, 0x0C,
0x4A, 0x12, 0xA9, 0xB5};
void COM_UnMunge2(unsigned char *data, int len, int seq)
{
int i;
int mungelen;
int c;
int *pc;
unsigned char *p;
int j;
mungelen = len & ~3;
mungelen /= 4;
for (i = 0; i < mungelen; i++)
{
pc = (int *)&data[i * 4];
c = *pc;
c ^= seq;
p = (unsigned char *)&c;
for (j = 0; j < 4; j++)
{
*p++ ^= (0xa5 | (j << j) | j | mungify_table2[(i + j) & 0x0f]);
}
c = _LongSwap(c);
c ^= ~seq;
*pc = c;
}
}
}
# -*- coding: UTF-8 -*-
from scapy.all import *
from ctypes import *
lib=CDLL('./dll.so')
COM_UnMunge=lib.COM_UnMunge2
pcaps = rdpcap("udp.pcap")
f=open('res','wb')
for mpacket in pcaps:
udp=mpacket[UDP]
data=bytes(udp.payload)[8:]
seq=bytes(udp.payload)[0]
c=create_string_buffer(data)
COM_UnMunge(c,len(data),seq)
print(mpacket.time,mpacket[IP].src,'->',mpacket[IP].dst)
decode_bytes=bytes(c)
print(' '.join(['%02X'%i for i in bytes(udp.payload)]))
f.write(decode_bytes)
print(decode_bytes)
f.close

简单尝试一下,第一个包输出了fakeflag.虽然是fake,但是也说明了我们的解密函数调用没问题
而在比赛期间呢,我看到解密函数之后就没怎么看源码了,就直接看数据,然后颅内简单fuzz一下,感觉是解密后的每个包的前10个字节没用,最后一个\x00没用,去掉之后直接全部dump到一个文件中再binwalk梭哈,大概的代码长这样
# -*- coding: UTF-8 -*-
from scapy.all import *
from ctypes import *
lib=CDLL('./dll.so')
COM_UnMunge=lib.COM_UnMunge2
pcaps = rdpcap("udp.pcap")
f=open('res','wb')
for mpacket in pcaps:
udp=mpacket[UDP]
data=bytes(udp.payload)[8:]
seq=bytes(udp.payload)[0]
if bytes(udp.payload)[3]==192:
c=create_string_buffer(data)
COM_UnMunge(c,len(data),seq)
print(mpacket.time,mpacket[IP].src,'->',mpacket[IP].dst)
decode_bytes=bytes(c)[10:-1]
print(decode_bytes)
if b'BZ2\x00' in decode_bytes:
print('BZ2 get!')
f.write(decode_bytes)
f.close
倒是也成功梭哈出来了5个bzip包
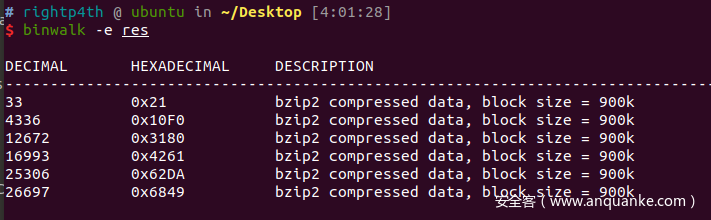
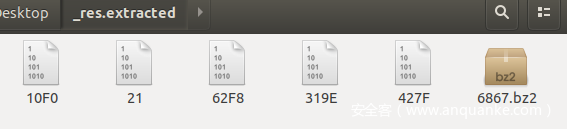
大致看了一下这样梭出来的数据也都是正确的
只有最后一个bz2没梭出来,当时觉得很奇怪
再去看看包,发现最后一个bz2处有两块数据十分相似,只错了几个字节,当时猜测是错误了
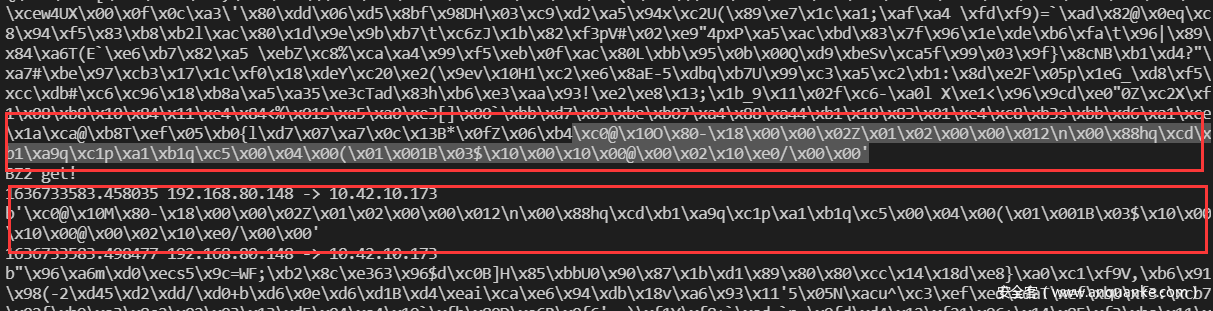
但是修正之后也是不行,就没弄了
赛后复现的时候呢,看了看wp,才知道是冗余数据,直接删除能出了,可惜了。
而且当时读源码没仔细看,fuzz的结果是对了,但是为了了解全过程,还是再读一遍源码
在解密完成后,继续看process部分的后续代码
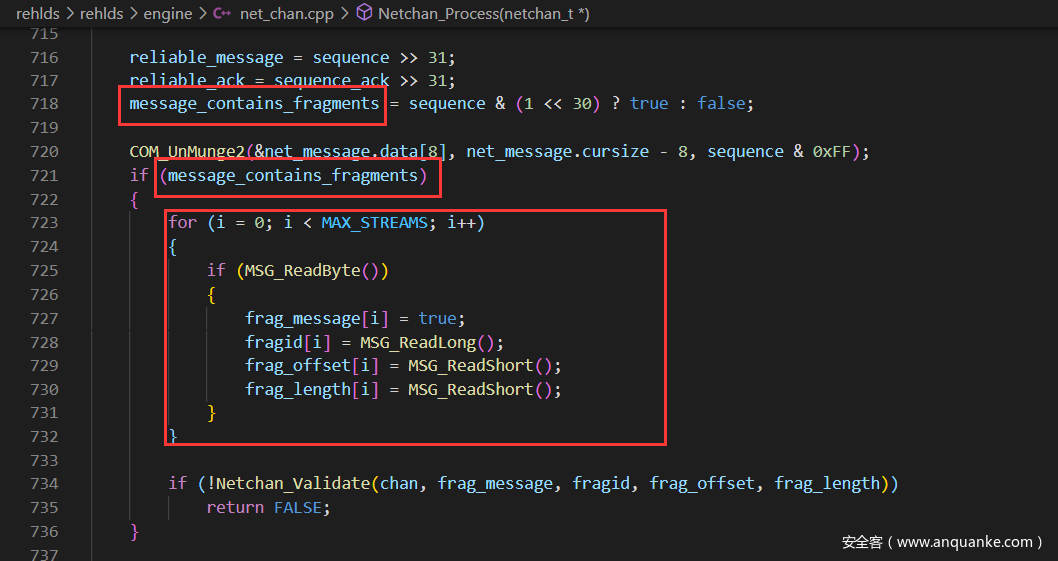
注意到这里其实对sequence & (1 << 30)做了一个简单的判定,若为真则会对解密得到的数据进行一个分块处理
这个分块流程大致如下:
- 取1字节,非0则代表又frag_msg
- 取4字节,作为frag_id
- 取2字节,作为frag的偏移
- 取2字节,作为frag的长度
然后取数据的部分在下面
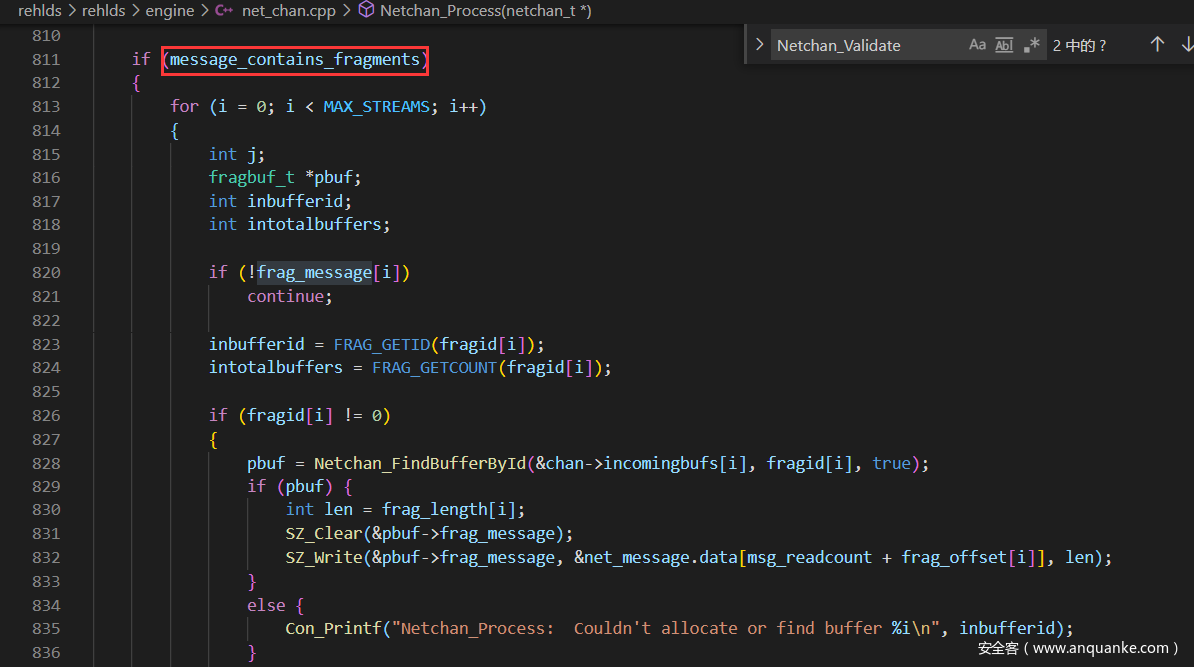
inbufferid和intotalbufers两行的操作定义在net.h中

id我们前面已经知道是4字节了,则inbufferid就是id[0:2], intotalbuffers就是id[2:4]
接着根据偏移来定位位置,从而获得对应长度的数据
这里引用一下官方wp的图,更好理解
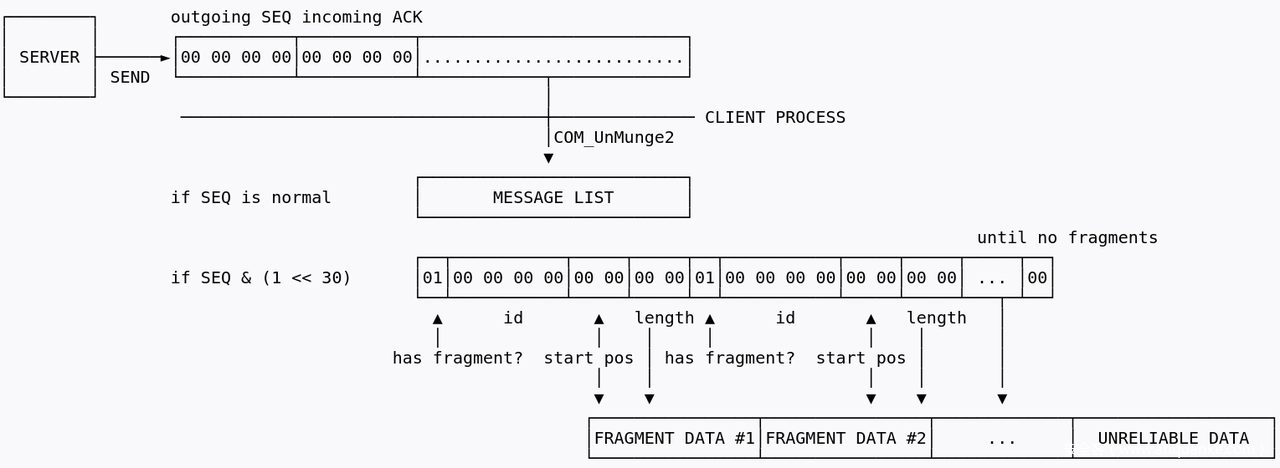
这也就刚好解释了为什么我当时fuzz出前10个字节没用,10个字节刚好是:
- 1字节的存在fragment
- 4字节的id
- 2字节的偏移
- 2字节的长度
- 1字节的frag结束
一切都刚刚好,但是这样纯fuzz而不知道原因的话是不知道frag的长度的,这就导致了我当时没看出来有冗余数据…
然后写个脚本简单验证一下
# -*- coding: UTF-8 -*-
from scapy.all import *
from ctypes import *
from Crypto.Util.number import bytes_to_long
lib=CDLL('/home/rightp4th/Desktop/dll.so')
COM_UnMunge=lib.COM_UnMunge2
pcaps = rdpcap("/home/rightp4th/Desktop/lambda_final.pcap")
f=open('res','wb')
for mpacket in pcaps.filter(lambda x:UDP in x and x[UDP].sport==27015):
# mpacket.show()
udp=mpacket[UDP]
data=bytes(udp.payload)[8:]
seq=bytes(udp.payload)[:4]
ack=bytes(udp.payload)[4:8]
if bytes_to_long(seq) & (1<<30):
c=create_string_buffer(data)
COM_UnMunge(c,len(data),seq[0])
print(mpacket.time,mpacket[IP].src,'->',mpacket[IP].dst)
decode_bytes=bytes(c)
print(decode_bytes)
if b'BZ2\x00' in decode_bytes:
print('BZ2 get!')
f.write(decode_bytes)
f.close
让他输出含有frag包的部分,得到了
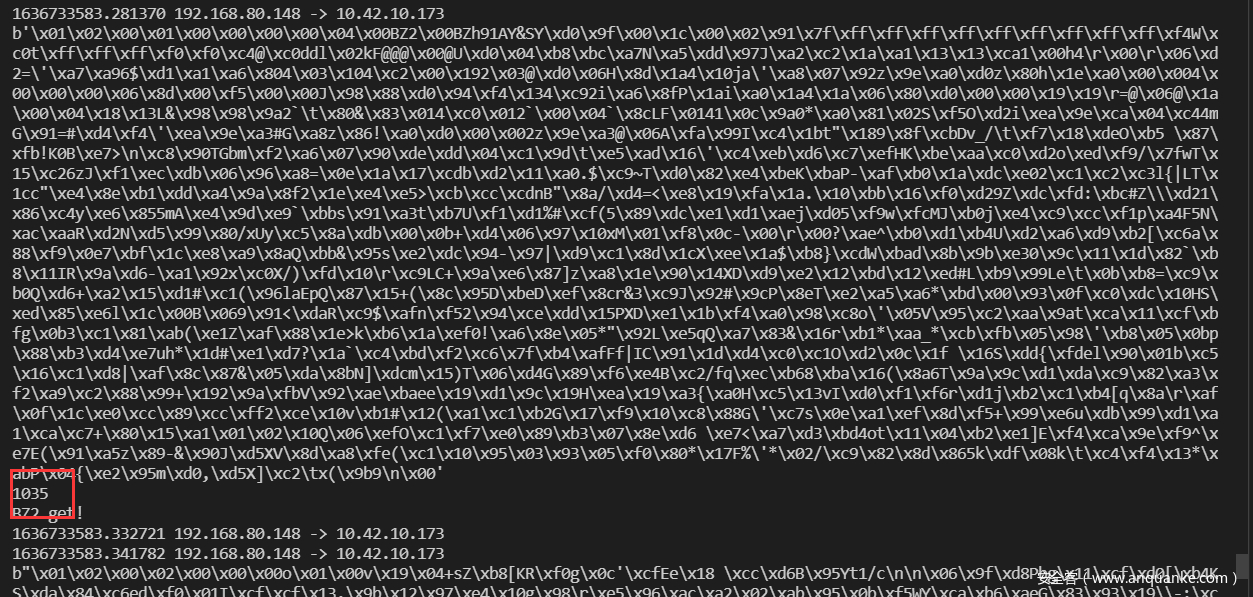
这个是正常的包的长度 1035=10(frag开头)+1024(包大小)+1(\x00结尾)
而存在冗余的包的长度是
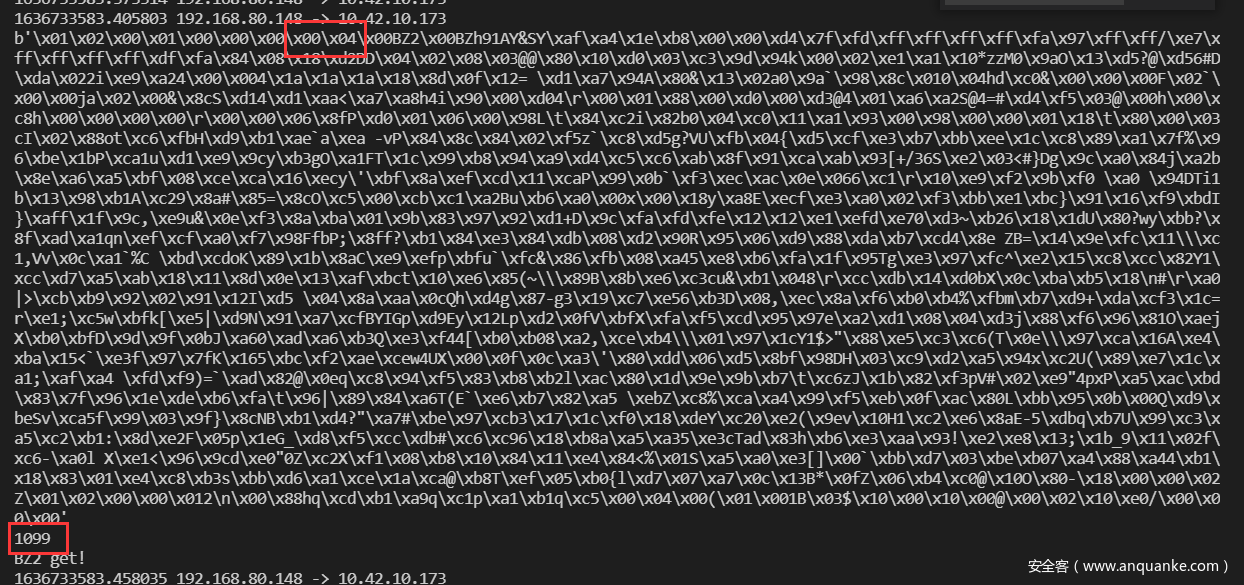
1099,很明显要长不少,进一步,按照frag的结构,图中所示frag的长度应为0x400,即1024,这和我们刚才看到的之前的包长度是一样的,故图中所示的包其实是有冗余的,应该直接舍弃后面的冗余部分
而去wireshark看看也可以发现
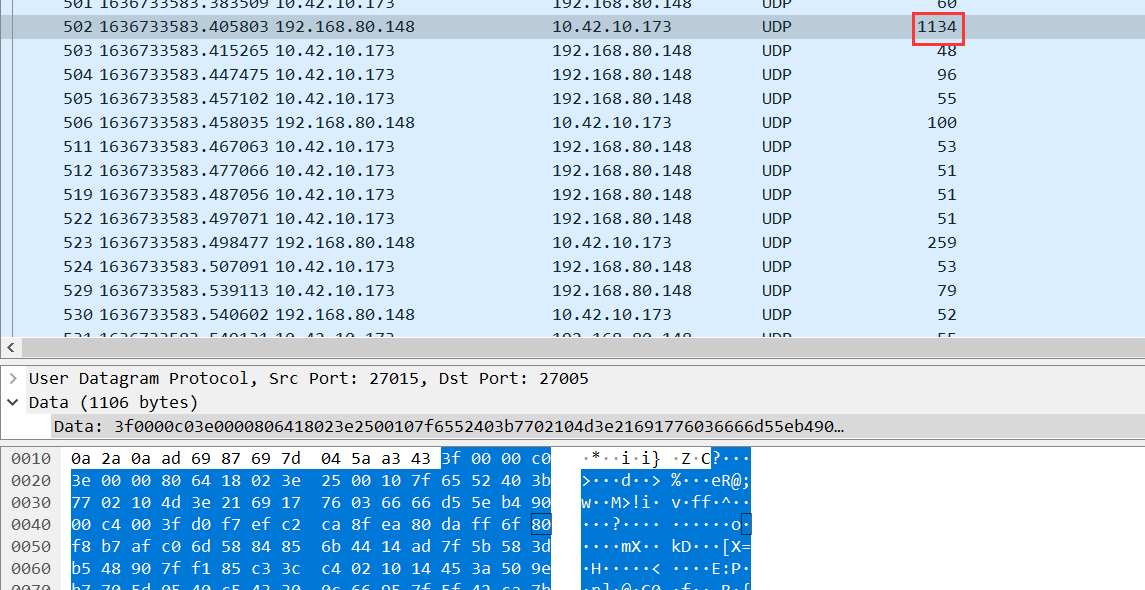
这个是在最后一个bzip包中的数据,我们通过长度也可以很明显的看出和前面的1070相比存在冗余,故若不考虑这个冗余的地方,直接梭哈,则会多出数据,导致bzip的crc校验失败,进而无法解压,这也就是为什么比赛期间我梭出来了前五个包,唯独这个包没梭出来,可惜
那咱再继续加一层判定即可
因为不难注意到所有的fragment包都只有一段,故就把代码简化了,如下
# -*- coding: UTF-8 -*-
from scapy.all import *
from ctypes import *
import struct
lib=CDLL('/home/rightp4th/Desktop/dll.so')
COM_UnMunge=lib.COM_UnMunge2
pcaps = rdpcap("/home/rightp4th/Desktop/lambda_final.pcap")
f=open('res','wb')
for mpacket in pcaps.filter(lambda x:UDP in x and x[UDP].sport==27015):
# mpacket.show()
udp=mpacket[UDP]
data=bytes(udp.payload)[8:]
seq=bytes(udp.payload)[:4]
ack=bytes(udp.payload)[4:8]
c=create_string_buffer(data)
COM_UnMunge(c,len(data),seq[0])
print(mpacket.time,mpacket[IP].src,'->',mpacket[IP].dst)
decode_bytes=bytes(c)
if len(decode_bytes)>10:
if struct.unpack('<L', seq)[0] & (1<<30):
if len(decode_bytes)>10+struct.unpack('<h', decode_bytes[7:9])[0]+1:
print('find extra data block:')
print(decode_bytes[10+struct.unpack('<h', decode_bytes[7:9])[0]:])
decode_bytes=decode_bytes[10:10+struct.unpack('<h', decode_bytes[7:9])[0]]
f.write(decode_bytes)
print(f'finally decode data:{decode_bytes}\nlength:{len(decode_bytes)}')
f.close
但是还要注意有一个非fragment包也发送了一遍类似的冗余
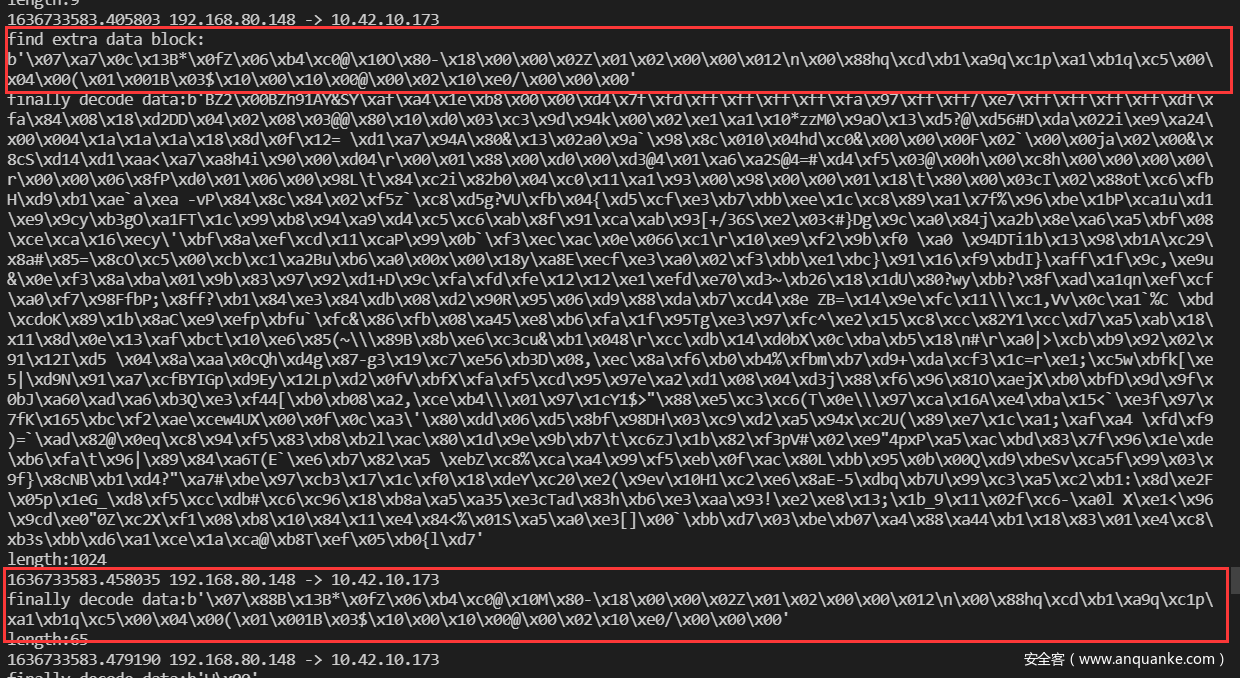
基本就差了几个字节,我们也把他过滤掉, 加一个长度过滤即可
if len(decode_bytes)==65:
continue
当然也可以先全部导出然后手动过滤,过滤后直接binwalk梭
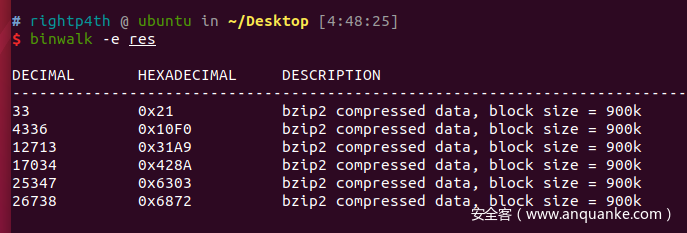
查看6872
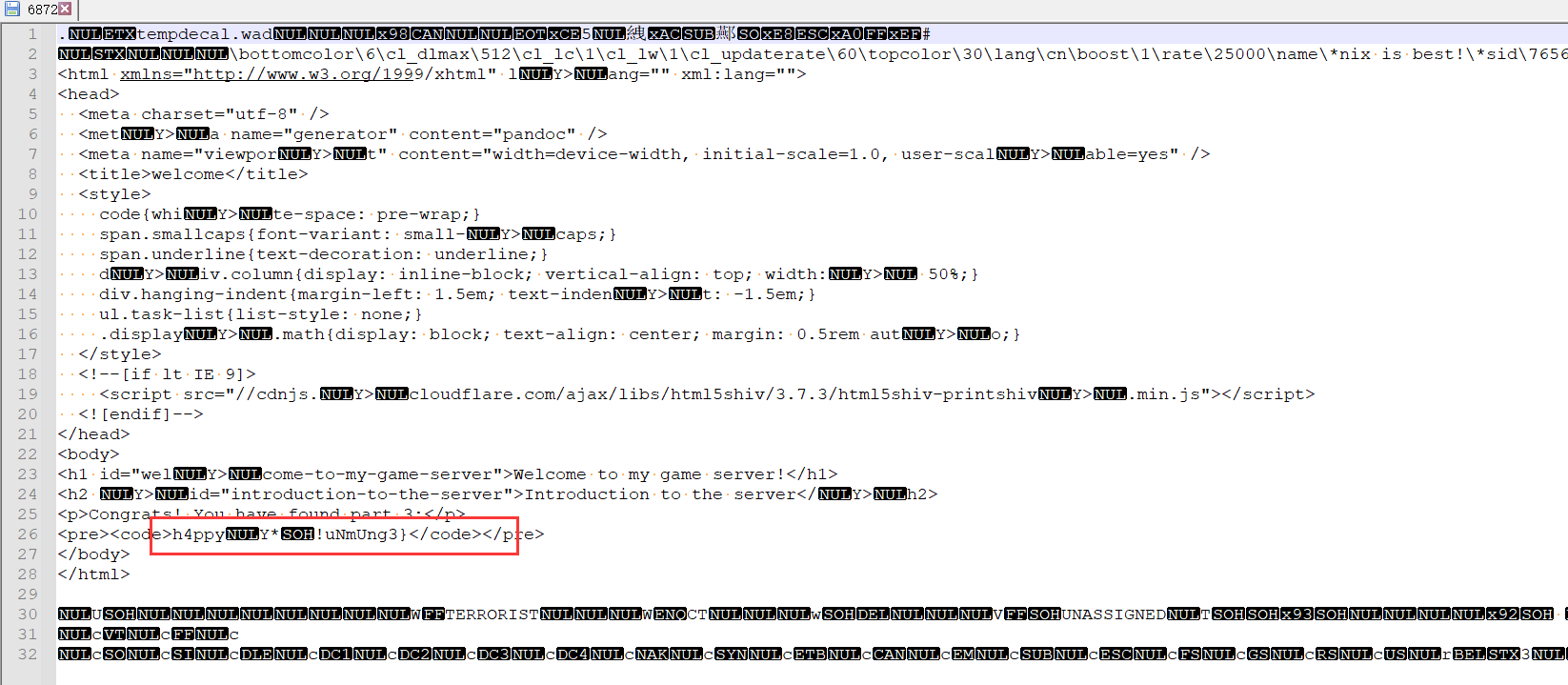
得到第三部分flag






发表评论
您还未登录,请先登录。
登录