
0. 概述
近一两年,供应链攻击已不只是白帽子的实验试水,转变成黑客和黑产的真实攻击手段,“软件供应链安全”概念,重新成为了炙手可热的话题。
当前对供应链安全的探讨多是关于机制的,例如企业上下游公司的攻击面,或者各种开发语言软件包管理引用的投毒欺骗。但是对于一线的开发实践中的风险,目前鲜有分析。
试想,在一个多人协作开发的项目中,如果:
- 有一个偷懒的开发者复制很多网上贴的示例代码或错误代码;
- 或者一个新加入的开发者,复制了该项目的某些旧代码,其中有一些带有已修复的bug;
- 甚至如果有一个恶意开发者,故意写了一个形似手误的bug、但实际是可以被远程利用的隐蔽后门。
那么项目的拥有者要如何分辨这些有风险的代码?只要把这些潜在的“坏的”开发角色换为上游开源代码供应方,一个完全可能的“开源供应链漏洞”场景就很好理解了。
从这一个简单的假想出发,本文将带领读者看到,设计开源代码使用的开发实践中的真实威胁,以及我们构建好的一个解决方案。
1. “代码复用”引入的深层次供应链问题
目前为止,受到广泛关注的供应链风险,集中于两类:以名称易于混淆的恶意软件包仓库投毒,如PyPi、NPM仓库的投毒攻击;以及渗透软件厂商的上下游供应商,以窃取其掌握的敏感信息。但源代码的流动和依赖,远非库依赖那么简单。
这里,我们抽象出一个开发实践中普遍存在,但内中安全风险并未引起广泛注意和分析的供应链威胁向量——代码复用。
1.1. 代码复用与漏洞:Google P0分析视角
今年6月,Google Project Zero下属的漏洞根因分析小组发出半年度在野利用漏洞报告。报告分析2022年上半年内,发现被在野利用的系统或关键基础软件0day漏洞中,50%(9/18)并非全新孤立的漏洞,而是某个历史漏洞的关联“变种”,主要分为三类:
- 历史被修复的漏洞,补丁代码被回滚造成漏洞重现,如CVE-2022-22620,是WebKit引擎在2013年已经修复的漏洞,于2016年代码重构中被原样改了回去;
- 某个此前被修复的漏洞,在有关联和相似关系的其它功能模块中发现类似漏洞,如CVE-2021-39793,是Linux etnaviv驱动程序修补的bug,在Google Pixel Mali GPU私有驱动代码中的同源漏洞;
- 对于漏洞根因,此前的修复方案不完整,造成可在新的漏洞触发路径利用,如Windows系统win32k驱动中,CVE-2022-21882是CVE-2021-1732的相同用户模式回调bug。
这样的观察侧面表明,自体或继承的同源代码,带有复杂的风险,特别是对黑客黑产而言,挖掘利用这些“炒冷饭”的漏洞,实际是很经济的实践。
1.2. 各种形式的“代码复用”及对应的风险案例
结合开源生态以及企业级产品开发实践,我们归结除了简单的软件包引用形式外,至少有三个颗粒度的代码复用形式,特别是在C/C++这类没有统一的包依赖管理机制的主流开发语言中存在。
1.2.1. 开源项目子目录或文件形式包含
某些项目依赖于特定开源组件功能,但出于维持明确的依赖关系、清晰的制品形式的目的,并不会动态链接(依赖)独立的软件包或动态库,而是将固定版本的开源代码,完整目录或者裁剪的部分文件形式,直接包含在代码目录下,同步编译静态链接在制品二进制中。
这种情况下,开发者的诉求一般是追求“稳定可用即可”,并规避依赖子模块接口更新带来的维护成本,更不会主动关注子模块是否有安全更新并跟进,因此很容易存在有历史漏洞的成分。
例如,Java开发的移动端通信SDK和软件Telegram,以jni调用形式包含了boringssl,而后者是Google自OpenSSL 1.1.0历史分支fork并维护的二次开发项目。虽然boringssl以一定机制跟进了上游的漏洞修复,但Telegram对这些依赖的更新没有确定策略,最后一次更新boringssl停留在2020.8.15,因此近两年多的漏洞都可能影响着Telegram(如果构造出合理的调用路径),并进一步影响封装Telegram的更下游应用,如Nekogram。
1.2.2. 函数和片段级别代码复用(复制)
开源代码往往也成为开发实践中取之不竭的代码模板和材料。对于某些典型原子功能的实现,开发者“借用”开源代码片段并依据自己项目的上下文做适当修改变形,是较为普遍,但又无法评估存在占比的实践。根据Synopsys今年在17个商业体超过2400个商用软件代码仓库中分析后,形成的开源安全与风险分析报告认为,商业软件中78%比例的代码实际是开源代码。
在我们对开源代码的分析中,也有一定量的代码复用,并随着复用的旧版本开源代码引入潜在脆弱代码的案例。例如,某款韩国 自研 的IoT专用安全库中的密码算法实现中,即发现了疑似复制自OpenSSL密码算法库中中国SM2算法的功能实现,且复制版本为被爆出高危漏洞CVE-2021-3711的修补前函数。
1.2.3. 数据结构和接口调用的语法复用
另一种典型的问题是数据结构和接口的误用。对某些未充分文档化的数据结构和功能接口,项目内部协作的开发者可能存在共通的错误理解和误用情况;作为SDK导出的接口被下游开发者误用的情况更是屡见不鲜。此时就会看到针对一个漏洞根因的多处位置、语法各异但语用同源的漏洞,这样的案例屡见不鲜。
一个很容易理解的案例是,OpenSSL漏洞CVE-2021-3712,根因在于定义的结构体ASN1_IA5STRING,其中带有一个非’\0’结尾的缓冲区指针,和缓冲区有效数据长度字段;但大量开源协作开发者未意识到缓冲区并非标准C样式字符串,而使用了不安全的字符串操作函数,例如sprintf, strdup, strcat, strchr等以及其在OpenSSL中的封装版本,从而造成了多处缓冲区越界访问或写溢出等。进一步地,这个数据结构也被导出,从而被一些依赖的下游项目同样误用,造成漏洞的修复无法收敛。
2. 从问题到解决方案之间的鸿沟
考虑到代码开发中人的因素的复杂性,可以预见以上代码复用引入漏洞威胁在未来可能的增长,特别是在商业对抗领域。但现有的程序分析技术,还不足以解决这类看似简单的问题。
2.1. 软件成分分析(SCA)的掣肘
看起来源代码复用的问题,刚好是软件成分分析(SCA)的目标领域,因为可以抽象为扫描发现带有脆弱性的开源或自体代码成分——但是当前的SCA或许还并不是我们期待的模样。
现有实际投产的主流SCA技术,主要面向有统一包管理机制的开发语言生态,借助解析依赖关系配置,获得直接和间接的软件包依赖图谱,亦即“成分”,典型如对Maven、PyPi、NPM等语言包仓库的依赖。某些头部软件分析工具提供商也在将高校和科研院所的研究成果转化为可用的产品,通过对开源代码设计计算一种类似模糊哈希的指纹,或者对关键代码做token化后形成模糊查找模板,从而具备对开源代码引用的一定程度的匹配检测能力。
但是,SCA的技术路线本身就制约了可分析问题的方向和颗粒度。显然,以上讨论的代码复用引入的风险,均归类为无显式依赖关系的代码复用,这决定难以通过当下成熟的SCA技术覆盖到。而对于通过代码指纹方式扫描代码存在性,考虑到代码搜索空间,采集计算指纹的代码颗粒度越细,总和指纹库越会严重膨胀,且指纹匹配搜索的运算量也可能提升到算力瓶颈以上,从而反向约束指纹设计的精度上限;根据了解,当前具备可用性前景的技术,也仅能做文件粒度的签名和匹配查找,距离函数粒度有难以逾越的鸿沟。
此外,如上所述,一些代码复用,并不保证文本层面相似特征的保留。这种情况下,需要更偏向语法甚至语义层面的抽象和分析,这也是SCA所不具备的。
2.2. 静态源码分析测试(SAST)的缺失
考虑到成分分析方法最难覆盖到偏向语法模式相似的领域,很自然的,我们需要寻求静态源代码安全分析测试(SAST)的帮助。针对开源代码的测试,我们已经有了一个得力的工具,GitHub面向开源开放使用的CodeQL。对CodeQL的用法介绍我们在此不再赘述,它以类似SQL的规则样式对语法数据库做查询的形式、对多语言的支持、丰富的API接口都保证了作为SAST的灵活可用性。它对已知漏洞的覆盖和可扫描性又如何?
2.2.1. 实例引入
为简单地说明问题,我们不妨“臆造”一个与历史漏洞同源的代码bug。OpenSSL的一个高危历史漏洞CVE-2020-1967,是典型的空指针解引用问题。我们选择在一个由OpenSSL二次开发的开源项目BabaSSL中,将该漏洞移植到另一个上下文,移植的代码变更为:
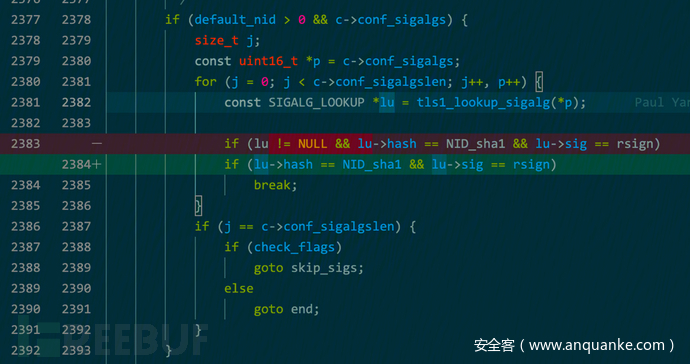
这里,tls1_lookup_sigalg()函数返回值为一个可能取值为NULL的指针,这里去掉了一个NULL的检查。实际上,如果将这处改动反过来看,那么就可以当做一个预先存在的漏洞修复的patch。针对这个“漏洞”,根据patch写ql规则覆盖漏洞成因,关键点如下:
- 需要定位的目标是一个SIGALG_LOOKUP *类型变量和一个if块;
- 变量在if同一层代码块中定义或赋值;
- 之后在if的条件语句中直接解引用其成员变量做判断;
- 当前代码块以及if的判断条件中,没有对指针与NULL的比较判断。
据此可以简单编写规则,覆盖这个漏洞的上下文:

2.2.2. 问题和需求分析
CodeQL可有效用于特定编程语言中,典型漏洞(bug)成因模式的检测。但真实的漏洞,只有一部分能够被已有的规则覆盖检出;主要原因之一,是已有规则是通用问题导向的,而其实现,又仅覆盖特定问题场景。
例如,对于C/C++语言中,空指针解引用这个经典问题(CWE-476),CodeQL用几条通用规则覆盖若干个典型问题场景,如特定指针类型变量先解引用后检查NULL,或判断某个返回值为指针类型的函数,是否在多数调用时检查了返回值是否为NULL而在某些地方未做检查。而如果某指针变量先作为参数传递到了一个用户函数,之后再做了解引用,那么受限于过程间分析的能力,无法判断传递到的函数是否是一个sanitizer,由此可能引入漏误报。
对历史漏洞编写具有一定针对性的ql规则,在现实场景有特殊价值:
- 一方面,带有漏洞的开源代码,可能被以源码形式包含在下游工程中,甚至是以代码片段形式引用,但代码结构、符号命名可能存在重写;而这种情况,一般没有统一的代码成分管理措施,这种陈旧代码引入了历史漏洞风险,却无法有效被意识到、检测出来;
- 一方面,某些漏洞的成因,可能在该项目的其它类似功能模块中同样存在,也可能在提供相似功能的其它开源项目里存在。此时,对于这些漏洞,我们需要有具备一定泛化能力的规则来做扫描,避免先被其它黑客在获取0day信息之后,率先举一反三地挖掘到。
但既然是高针对性规则,必然与漏洞具有基本一比一的数量规模,所以自动化生成,有必要性。
3. patch2ql:分析技术前瞻
patch2ql是云鼎实验室针对上述需要自动化生成扫描历史漏洞规则的问题,以CodeQL作为示例性质的SAST基底,给出的从代码补丁(patch)自动生成规则(ql)的技术方案。该技术当前正在逐步完善和转化中(由在途的专利申请保护),此处仅对其关键技术框架和节点做简要说明。
3.1. 关键实现路径
首先明确,尝试用自动化的方法,“理解”漏洞的成因,特别是语义、逻辑层面的原因,现阶段跨度过大;合理的方式是,由patch的代码增删改,刻画出语法层面的代码上下文,寻找相似代码上下文;这种相似性的大原则是:
- 具备patch中未改变的必备上下文语法要素,在上文例子中,主要包括特定类型的变量,对应的初始化语句,if语句,对变量的解引用,次要包括具体解引用访问的成员变量名,当前代码块上一层的代码块类型(如是for循环的body),当前语句下一层的语句类型(如是break);
- 包含patch所去掉的代码要素,包括删除的以及修改的原始代码,这在上文没有体现;
- 不包含patch新增的代码要素,对应上文中修复该处漏洞额外引入的NULL比较。
为实现以上目标,考虑包含三个关键步骤:
- 代码要素的圈定,包括上述的三类要素。考虑到要有对代码文本层面变动的抗性,这里考虑从AST层面实现比对;
- 根据所有主要和次要的AST节点要素,按照一定模式,生成对应的查询限定条件语句集合,主要有exist()语句限定需要包含的AST节点,以及not exist()从句限定不应存在的节点;
- 从上述条件语句集合中组合条件形成ql,在目标项目上做类似回归测试,保证对目标漏洞代码上下文可检出、尽量保证低误报数量,反复测试从而整理得到最优的集合。
3.2. AST层面的patch前后差异比对刻画
选择在AST层面圈定代码差异,主要有两方面考虑:一是AST是语法要素节点构成的树状结构,可以有效做语法差异的比对;二是由AST节点之间的“边”,亦即语法调用关系,可直接串连为生成规则语句的对象。
针对AST这样的树形图,常规文本序列形式的diff难以符合需求,而需要考虑到层次结构,做结构化比对。我们改进了编辑脚本生成算法,针对代码特征,设计针对代码颗粒度、自然的语法迁移关系的节点匹配条件,针对补丁前后目标函数的代码AST,分别扫描得到其中的插入、删除、更新、移动的语法树节点和子树。
举例说明,对于如下漏洞修复的代码补丁:
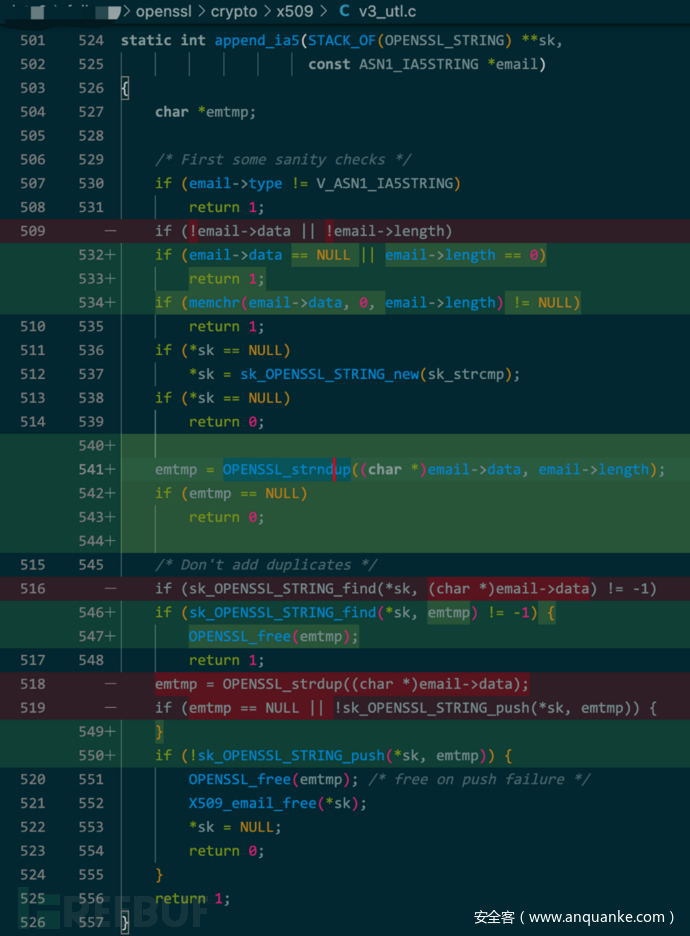
可观察到其中的关键修复逻辑,是针对非安全的缓冲区对象,增加额外NULL判断,并使用安全的字符串操作函数。在AST层面使用算法,可得到差异的语法节点:

3.3. 关键语法节点的查询条件表述
之后的任务是,将打补丁前后,差异的语法节点,以及未变动的、对函数逻辑而言起关键标识作用的语法节点,“翻译”为ql查询规则中的查询条件,从而获得多维度、尽可能全面的查询条件集合。
这样的翻译工作需要考虑到目标语言的语法,特定节点关系,典型的补丁修补形式,以及必要的代码上下文描述。例如,如果修补的代码,是对一个if语句中的条件增加或改写了条件谓词,那么也需要对对应的then语句块做必要的查询说明,从而描述出来变更的条件判断语句所“控制影响”的是对哪些关键变量的操作;又比如一个赋值语句的右值表达式中,将部分操作数做了更新,那么有必要进一步描述整个右值操作数、被赋值的变量以及变量之后的使用场景(数据流)。
上一节的差异AST,经此一步,转化为如下的繁复的查询语句集合(所显示的为局部):
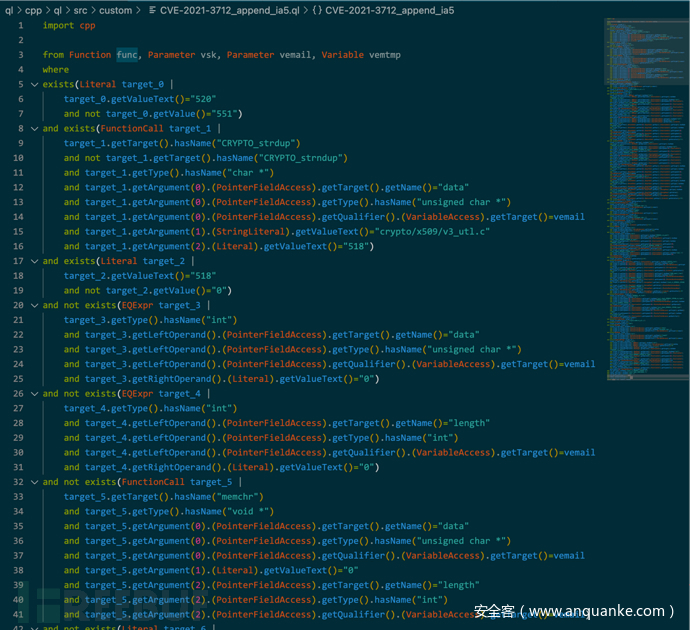
3.4. 查询条件筛选与规则优化
最终在以上的规则集合上做加工,选取必要的查询对象和条件,合并冗余语句,去除有冲突和错误的条件,并将某些对象根据语法关联整合得到抽象的语法对象描述,从而可以得到两类查询规则:
- 一类精准匹配目标唯一漏洞,描述所有必要上下文和代码语法,以检测存在适度的代码变形的原始历史漏洞为目标,即准确规则;
- 一类尝试通过忽略部分查询条件,并对某些查询条件做泛化(如从准确判断目标变量类型,调整为描述目标类类型的父类型,或忽略类型、直接描述其访问的成员),从而得到可能允许有一定程度的“误报”,但具备能够检测同源、同语法漏洞类型的衍生、相似漏洞的能力,即泛化规则。
这样得到的一份最精简优化规则如下:
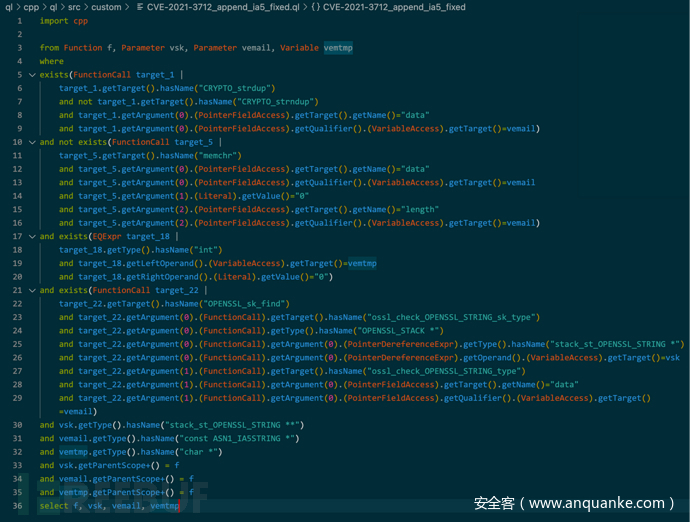
4. 典型案例
借助CodeQL本地测试环境,可以利用patch2ql工具生成的特定项目的规则,方便地扫描检测某些与该项目存在潜在关联性的开源工程是否有引入性质的同源漏洞。
值得注意的是:由CodeQL的许可限制,工具仅可以用于对开源代码的扫描,请勿用于商业私有代码的扫描和CI/CD流程的集成;此外,此前曾有的LGTM.com网站提供了一套在线编写规则扫描已预置编译后代码数据库的平台,可以不必本地重新构建数据库,但该网站即将下线停止服务,因此规则的试用复现也请遵循指引,搭建CodeQL的本地环境。
4.1. 案例说明:子项目级静态包含扫描
分析中首先选取C/C++项目中,将其它开源代码某个快照版本静态包含,并在生成时编译为静态库或直接.o形式链接引用的开源项目。一个很好的例子是CMake,其中在Utilities子目录下附带二方开源代码,基本进行代码剪裁后添加“cm”前缀存在,并由开发者做版本的同步和维护。
其中存在有“cmcurl”目录为静态包含的curl,剪裁仅保留了libcurl共享库部分代码和编译逻辑;由提交历史分析,CMake开发者有一定的适配定制,采取不定期人工从上游(upstream)项目合并变动的同步策略,最后一次同步为2022.05.16。根据curlver.h头文件指示,同步的libcurl版本为7.83.1。
使用一款具有函数/片段颗粒度相似度和版本判断的软件成分分析商业软件FossID,对最新的CMake进行扫描,扫描共耗时约2小时。可以识别到curl的代码成分,选取其中一个cmcurl目录下文件,扫描成分判定结果如下:
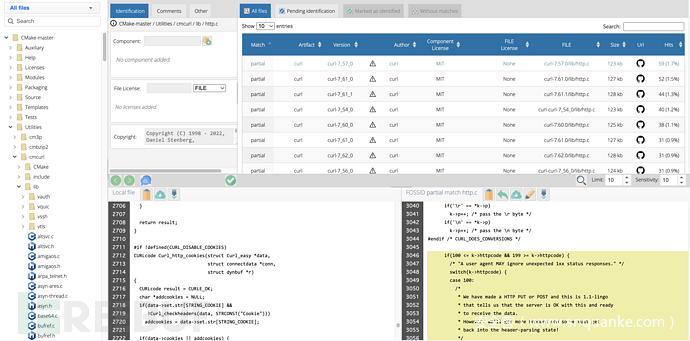
由此可见,该商业方案确实是采用按片段相似度确定与某些历史版本的最大似然成分的。但可能由于知识库(KB)难以持续、细粒度更新,参与到相似度判定的代码片段也并不完整、缺少一定的模糊性,导致判定出的最大似然度的版本也只有1.7%的相似成分比例。而漏洞的提示完全是根据判定的历史版本号,给出对应知识库内容,与实际命中代码无关。
而使用patch2ql,针对某个历史漏洞patch,训练生成ql的局部对应关系如下:
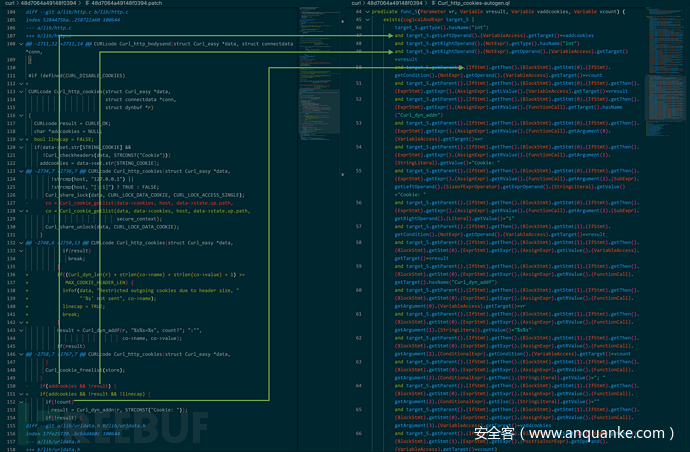
该份ql规则存在一定量冗余,但可观察到其中描述了差异的if语句条件元素,以及对应的then分支语句。使用该规则,可以扫描分析得出,CMake当中包含的cmcurl代码,存在该漏洞的同源(遗留)漏洞:

5. 如何获取
当前patch2ql工具本身仍然在持续开发演进中,功能本身计划将在进一步成熟后考虑开源。
相比工具本身,该工具生成的规则本身,能更好地服务开发者以及关注安全的白帽子。因此,patch2ql当前的中远期目标,是针对开源生态中的基础开源软件和组件,生成尽可能覆盖所有历史CVE漏洞和bug的分析规则。
当前已开放针对curl和OpenSSL部分历史漏洞生成的原始CodeQL规则集,感兴趣的白帽子可移步腾讯云鼎实验室该项目(https://github.com/YunDingLab/QlRules.git)查看分析。







发表评论
您还未登录,请先登录。
登录