
每当大家讨论模糊测试技术的时候,对它的第一印象往往定格在:漏洞挖掘常用技术、闭源软件漏洞挖掘、二进制文件检测分析、黑盒漏洞检测技术等等。或者,你的心里也是这么想的?但是,我想说:经历了不同时代范式的迭代成长,模糊测试已然不是你心中认为的样子了。
模糊测试技术的兴起
每每提及模糊测试,大家都知道它的背景出身,模糊测试最早由威斯康星大学的Barton Miller于1988年提出。最开始,Barton Miller的实验内容是开发一个基本的命令列模糊器以测试Unix程式。这个模糊器可以用随机数据来「轰炸」这些测试程式直至其崩溃,从而对应用程序进行安全检测。在当时,这一简单的测试方法便已发现运行于 UNIX 系统上的 25%以上的程序崩溃,展现出了无与伦比的测试优越性。也就是从此时起,“它”慢慢进入大家的视野。
包括现在,世界上一些大规模的组织机构也把“它”当作质量控制和网络安全操作的一部分:
●Google用它来检查和保护Chrome中的数百万行代码。例如,2019年发现了Chrome中的 20,000 多个漏洞。
微软
●微软将它作为其软件开发生命周期的阶段之一,以发现漏洞并提高其产品的稳定性。
美国国防部 (DoD)
●美国国防部 (DoD)发布了DevSecOps参考设计和应用程序安全指南,两者都要求将它作为软件开发过程的标准部分。
华为
●华为要求所有对外提供或使用外源进行服务的C/C++代码都需要经过Fuzzing测试,且每年发现1000多个Top N问题。涉及海思、数通、云核、无线、终端、华为云(存储、计算)、公共开发部、车BU等重点单位。
或许,你对它的认知还停留在相对传统的第一印象。但不难发现,现在模糊测试技术逐渐得到了公众的关注和使用,以解决安全漏洞问题。随着技术理念的不断迭代发展,现阶段的模糊测试不仅包括传统的黑盒模糊测试,还衍生了灰/白盒的模糊测试技术。这一点,你是否已经意识到了呢?
模糊测试的不断演变模糊测试的不断演变
模糊测试技术的演变,主要因为AFL改变了传统黑盒模糊测试的产品形态。下面我们先介绍一下黑盒模糊测试。
黑盒模糊测试
如果我们要检测一个封闭屋子内是否存在安全隐患,但不了解屋内构造、也接触不到屋内的东西,那么我们就需要找到一个有效的方法判断屋内的构造。类比于应用程序的检测,很多应用程序的源代码和二进制代码等也无法获得,在此场景下,黑盒模糊测试便是探测程序“内部构造”的有效方法,它通过在自动化任务中使用格式错误/半格式错误的数据注入来查找程序实现的错误。
协议模糊测试是该技术最常见的应用场景之一,也是智能车企、军队、信创、工控等众多场景亟需的解决方案。云起无垠的模糊测试系统在智能车企的协议检测场景中可以帮助智能车企做如下检测:
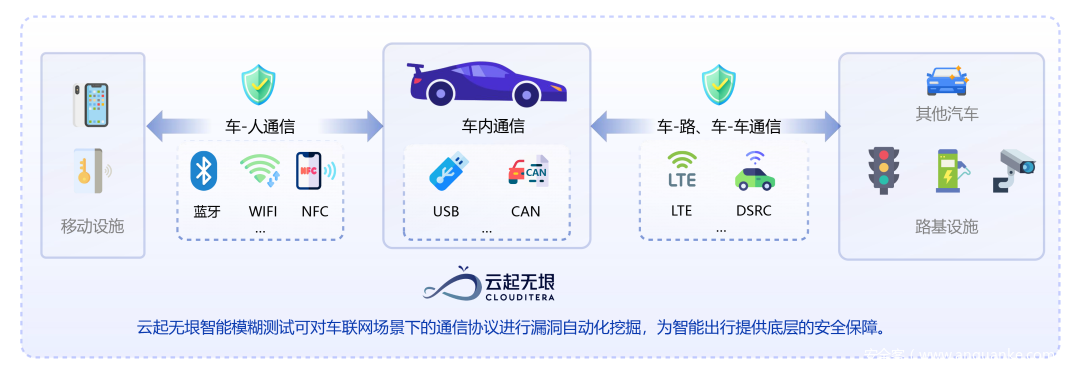
操作系统安全检测:对车联网设备的操作系统进行文件、进程、网络等方面的安全检测。
车内通信协议检测:对车内设备的通信环境进行安全检测,如CAN协议逆向、CAN协议模糊测试、CAN 数据重发测试、UDS协议测试等。
车外通信协议检测:对车载设备与外部设备或云服务的通信协议进行安全检测,如蓝牙、WIFI等安全检测。
应用软件安全检测:对车联网应用软件进行动态安全检测。
数据安全检测:对车联网设备和应用运行交互过程的数据安全进行检测。
AFL简单介绍
AFL(American Fuzzy lop)是一款基于覆盖引导的模糊测试工具,最早由安全研究员Michał Zalewski(@lcamtuf)开发。它采用遗传算法来有效地提高测试用例的代码覆盖率。它在诞生之初便在知名软件项目中检测到数十个重大软件错误,包括X.Org Server, PHP,OpenSSL,pngcrush,bash,Firefox,BIND,Qt,and SQLite。目前,作为最广泛使用的Fuzzing工具,AFL已经发现超过15000个漏洞,且基于AFL做二次开发的开发安全研究工作在这3年已经有超过100篇高水准学术论文发表。
不过,与大多数模糊器不同,AFL-fuzz观察被测试程序的内部行为,并调整它生成的测试用例以触发未探索的执行路径。因此,AFL-fuzz比其它fuzzer覆盖更多被测程序,生成的测试用例也更多。
只是,近几年AFL已经没有再更新了,社区的其它成员提供了一个具有各种改进和附加功能的更复杂的分支,称为AFL++。不管如何,都改变了模糊测试的格局。
灰盒模糊测试
灰盒模糊测试也是越来越流行的检测方式之一,它利用“检测”而不是“程序分析”来收集有关程序的信息。例如在程序中进行插桩,可以获得一条fuzzing用例在执行时对应的代码覆盖率。如果接触到了更多的程序内容,它就把这一条用例记录下来,用于改进fuzzing的效果。

现有的基于American Fuzzy Lop (AFL) 的灰盒fuzzing依赖于使用一小组变异函数将一组有效程序输入转换为新的“子”输入。这些变异函数相当简单,执行诸如翻转输入中的随机字节、插入特殊字符或删除部分输入等操作。因此,这个产生的子输入与其父输入相似但又不同。如果子输入通过影响以前未探索的代码路径来增加代码覆盖率,则将其添加到有效输入队列中,并重复该过程。
对于每个输入,模糊器都知道覆盖了哪些程序以及它们被执行的大致频率。检测通常在编译时完成,即将程序源代码编译为可执行二进制文件时。此时,可以使用虚拟机(例如QEMU)或动态检测工具(例如Intel PinTool)等在未检测的二进制文件上运行AFL。
云起无垠在AFL基础之上,融合遗传变异等算法,研发设计了无垠代码模糊测试系统。该测试系统基于反馈学习机制生成海量测试用例,对程序代码接口进行自动化动态检测,使缺陷误报率无限趋近于零,确保缺陷可定位、可复现,大幅提升安全左移的可落地性。
而且,该产品可以在代码安全检测场景中对系统源代码及二进制文件进行动态检测,检测目标工程代码的安全性及健壮性,帮助开发、测试、安全人员快速发现、定位、验证目标工程的代码缺陷,并以报告的形式呈现出来,从而可以针对性地制定解决方案。
模糊测试的工作流程模糊测试的工作流程
知道了模糊测试的常见类型之后,我们也需要知道其工作原理,只有这样才能更好的在实际应用中实施。
模糊测试是一种针对软件安全的自动化测试方法,它主要的理念是追寻测试样例的变异,并通过海量的测试数据来覆盖更多的程序执行流,从而找到更多的安全问题。Fuzzing不仅可以找到逻辑类漏洞,还能找到内存破坏的漏洞,比如缓冲区溢出、内存泄漏、条件竞争等等。这本质的原因在于Fuzzing在做软件安全测试的时候,整体的粒度会更细,测试点会更多,判断位置也会更精准。
近30年来,模糊测试技术呈飞跃式发展,它目前除了可以覆盖AST技术以外,还可以利用到符号执行、语法树变异、代码覆盖引导、遗传算法变异、污点跟踪等技术。通常情况下,完整的模糊测试流程会经历如下6个步骤:
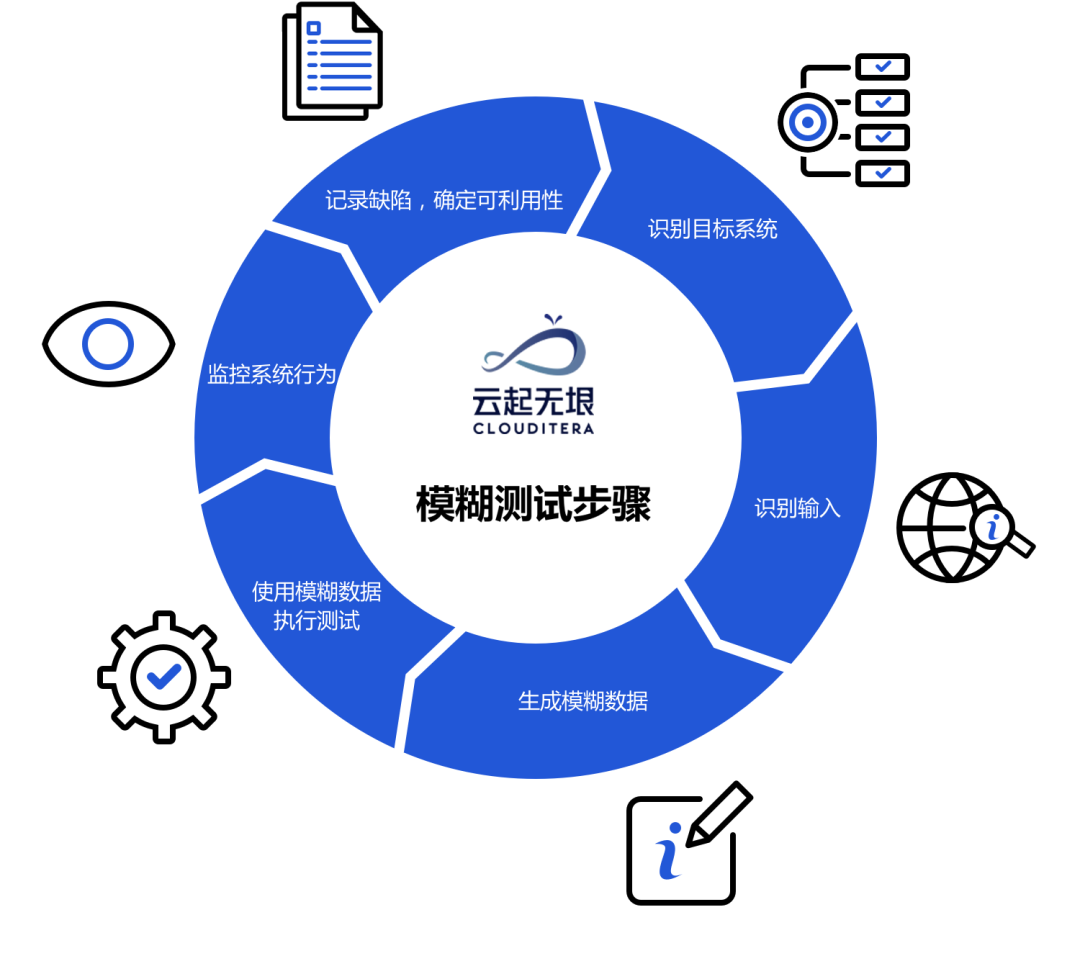
步骤一:识别目标系统
步骤二:识别输入
步骤三:生成模糊数据
步骤四:使用模糊数据执行测试
步骤五:监控系统行为
步骤六:记录缺陷,确定可利用性
模糊测试的优势
放眼当下,模糊测试之所以备受关注,主要是它为安全和高质量的程序提供了广泛的好处:
在模糊测试期间,程序会使用无效的、意外的或随机的输入执行,目的是使被测系统崩溃。现代模糊测试解决方案可以分析它们要测试的代码的结构。它们可以每秒生成数千个自动化测试用例,并标记输入通过程序的每条路径。通过这种方式,模糊器可以获得关于代码覆盖率的详细反馈。
在安全程序中使用Fuzzing可以帮助企业发现系统中未知的漏洞和0day攻击。
Fuzzing是一种自动化技术,一旦fuzzer启动并运行,它就可以开始自己寻找bug,而不需要手动/人工干预,并且可以根据需要持续这样做。
模糊测试的技术特点使其漏洞检测的准确率接近100%,并且可为每个漏洞提供详细的回溯调试信息,降低运维成本,消除误报带来的噪音。
模糊测试的未来
模糊测试的未来是智能模糊测试,具体如下:
持续集成模糊测试:DevSecOps场景下,CI/CD持续集成Fuzzing技术为每次代码变更进行增量式智能测试,实现真正的“安全左移”;
云原生模糊测试:利用云原生技术构建大规模分布式集群化Fuzzing平台,并行加速测试进度,实现效率更高、测试更精准的模糊测试;
模糊测试即服务:FaaS( Fuzzing as a Service)——简单即用型Fuzzing产品成为现实。用户无须进行额外知识学习和复杂配置,即可“开箱即用”地使用智能化Fuzzing产品,使用门槛逐渐平民化。
全栈漏洞检测能力:模糊测试技术不仅可以检测内存型漏洞,还可检测逻辑型漏洞,比如SQL注入、命令执行和条件竞争等等。
智能攻防模糊测试:在美国CGC(Cyber Grand Challenge,“网络空间超级挑战赛”)中,AI赋能下的智能模糊测试技术已使机器人自动化攻防成为可能。
除此之外,模糊测试相对传统的人工审计、AST等安全检测方式,也有其得天独厚的优势,后续将会逐一展开介绍。







发表评论
您还未登录,请先登录。
登录