
// 文丨支叶盛
美团安全研究员,主要从事 Linux 内核安全及二进制程序安全等方向的研究,当前负责美团内部操作系统安全、云原生安全等方向的安全建设。
随着云计算的蓬勃发展,云原生的概念于2013年被提出,Pivotal 公司的 Matt Stine 在概念中提出了云原生的4个要点:DevOps、持续交付、微服务、容器。而在 2015 年 Google 主导成立了云原生计算基金会(CNCF),CNCF 也给出了对云原生(Cloud Native)的定义,其中包含三个方面:1)应用容器化;2)面向微服务架构;3)应用支持容器的编排调度。
随着近几年来云原生生态的不断壮大,所有主流云计算供应商都加入了该基金会, CNCF 基金会中的会员以及容纳的项目越来越多,原先的定义已经限制了云原生生态的发展,到了 2018 年 CNCF 为云原生进行了重新定位,同时指出云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。围绕这些概念、定义和代表技术,最为基础的就是容器和微服务。在容器应用之前,相关的云计算的应用多数运行于虚拟机上,但虚拟机会有额外的资源浪费和维护成本,并且其启动速度较慢。正是容器技术所具有的占用资源少、部署速度快和便于迁移等特点,助力了云原生生态的蓬勃发展,其中 Docker 和 Kubernetes 是企业容器运行时和容器编排的首要选择。
而于此同时,如何保证云原生环境的安全性也在不断受到挑战。在云原生技术应用的过程中,大多数企业都遇到过不同程度的安全问题,无论是前两年爆出的某著名车企的容器集群入侵事件,还是容器官方镜像仓库 Docker Hub 存在恶意镜像,用户在享受云原生相关技术便利的同时,也产生了极大的安全担忧。而作为云原生的基石——容器的安全性更是重中之重,为了满足云原生业务上对安全防护工具的全面性、便捷性以及性能上的要求,围绕着容器运行时安全的多个内核安全特性也在不断发展,本文将对近年来针对容器运行过程中的安全加固技术进行逐一介绍。(在本文中,若无特殊说明,容器指代 Docker 容器)
01容器安全概述
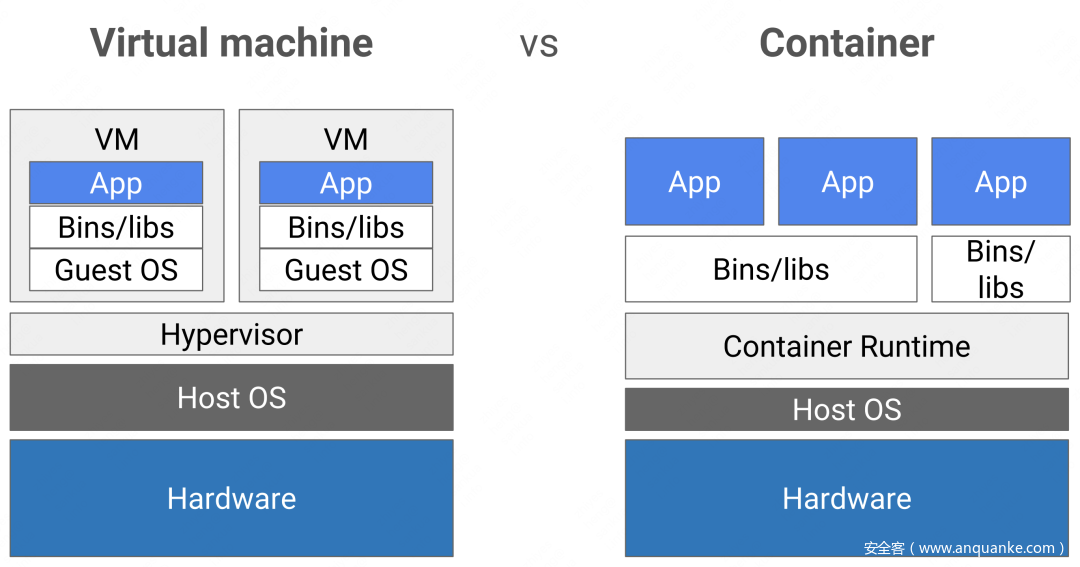
在实现云原生的主要技术中,容器作为支撑应用运行的重要载体,为应用的运行提供了隔离和封装,成为云原生应用的基础设施底座。与虚拟机不同的是,虚拟机模拟了硬件系统,每个虚拟机都运行在独立的 Guest OS 上,而容器之间却共享操作系统内核,并未实现完全的隔离。若虚拟化软件存在缺陷,或宿主机内核被攻击,将会造诸多的安全问题,包括隔离资源失效、容器逃逸等,影响宿主机上的其他容器甚至整个内网环境的安全(下图展示了 VM 和容器在系统架构上的差异)。
据《Sysdig 2022 云原生安全和使用报告》显示,超过75%的运行容器存在高危或严重漏洞、62%的容器被检测出包含 shell 命令、76%的容器使用 root 权限运行。鉴于云原生的攻击手段的独特性, 安全组织 MITRE 的对抗战术和技术知识库(ATT&CK 框架)在2021年推出了专门针对容器的攻击模型。云原生安全在近年来获得了大量的关注。
Google 在其 GCP 上讨论容器安全风险时,依据容器风险的来源,将其分为了三个方面:
- 基础架构安全:主要是指容器管理平台能够提供的基本功能的安全。
- 软件供应链安全:主要是指容器镜像安全。
- 运行时安全:确保安全响应团队能够检测到环境中运行的容器所面临的安全威胁。
而 Google 的这个分类方法,其实也可以归结抽象为对容器生命周期中三个过程的安全:
- 构建时安全:在容器镜像构建过程中,分析构建镜像时所使用的命令和配置参数,还原镜像文件构建过程,掌握命令使用的敏感操作,以及分析镜像文件是否包含密码、令牌、密钥和用户机密信息等敏感信息。同时,分析镜像的软件组成,发现镜像文件中包含的恶意文件、病毒和木马,以及所使用的依赖库和组件存在的安全漏洞,避免镜像本身存在的安全风险。
- 部署时安全:分析镜像无风险后,镜像被提交至镜像仓库。在该阶段,将检查容器环境的镜像仓库配置,确保使用加密方式连接镜像仓库。当镜像仓库中新增镜像或使用镜像创建容器时,自动化校验镜像签名或MD5值,确保镜像来源可信且未被篡改,一旦发现镜像来源不可信或被篡改,禁止使用该镜像创建容器。
- 运行时安全:当确认镜像安全后,进入到容器运行阶段。该阶段主要是是保证容器运行环境的安全,防止容器出现异常行为,这其中就包括主机环境配置安全、容器守护进程配置安全、容器应用的运行安全。
在容器生命周期的三个过程中,攻击者往往是在前两个阶段部署相关的恶意代码,在容器运行时对环境真正执行相关的攻击指令。因此,容器运行时相比于其他两个阶段更直接、也更容易分析出环境中的恶意行为。与其他虚拟化技术类似,逃逸也是针对容器运行时存在的漏洞最为严重的攻击利用行为。攻击者可通过利用漏洞“逃逸”出自身拥有的权限范围,实现对宿主机或者宿主机上其他容器的访问,其中最为简单的就是造成宿主机的资源耗尽,往往会直接危害底层宿主机和整个云原生系统的安全。根据风险所在层次的不同,可以进一步展开为:危险配置导致的容器安全风险、危险挂载导致的容器安全风险、相关程序漏洞导致的容器安全风险、内核漏洞导致的容器安全风险:
- 危险配置导致的容器安全风险:用户可以通过修改容器环境配置或在启动容器时指定参数来改变容器的相关约束,但如果用户为一些不完全受控的容器配置了某些危险的配置参数,就为攻击者提供了一定程度的可以攻击利用的安全漏洞,例如未授权访问带来的容器安全风险,特权模式运行带来的容器安全风险。
- 危险挂载导致的容器安全风险:将宿主机上的敏感文件或目录挂载到容器内部,尤其是那些不完全受控的容器内部,往往也会带来安全风险。这种挂载行为可以通过环境配置来设定,也可以在运行时进行动态挂载,因此这里单独地归为一类。随着应用的逐渐深化,挂载操作变得愈加广泛,甚至为了实现特定功能或方便操作,使用者会选择将外部敏感资源或文件系统直接挂载入容器,由此而来的安全问题也呈现上升趋势。例如:挂载 Docker Socket 引入的容器安全风险、挂载宿主机 procfs、sysfs 引入的容器安全问题等。
- 相关程序漏洞导致的容器安全风险:所谓相关程序漏洞,指的是那些参与到容器运行、管理的服务端以及客户端程序自身存在的漏洞。例如,CVE-2019-5736、CVE-2021-30465、CVE-2020-15257等存在于 Container Daemon、runC 上的容器安全漏洞。
- 内核漏洞导致的容器安全风险:Linux 内核漏洞的危害之大、影响范围之广,使得它在各种攻防话题下都占有一席之地,特别是在容器环境中由于容器与宿主机共享了内核,攻击者可以直接在容器中对内核漏洞进行利用攻击。近年来,Linux 系统曝出过无数内核漏洞,例如最有名气的漏洞之一——脏牛(CVE-2016-5195)漏洞也能用来进行容器逃逸。
安全容器的漏洞
安全容器是为了解决内核共享问题导致的安全风险所研发的一种运行时技术,它为容器应用提供一个完整的操作系统执行环境(常常是 Linux ABI),将应用的执行环境与宿主机操作系统隔离开,避免应用直接访问主机资源,从而可以在容器主机之间或容器之间提供额外的保护。例如,Kata Containers 就是为每一个容器运行一个独立虚拟机,从而避免其与宿主机共享内核。无论是理论上,还是实践中,安全容器都具有非常高的安全性。然而在 2020 年 Black Hat 北美会议上,Yuval Avrahami 分享了利用多个漏洞成功从 Kata containers 逃逸的议题,安全容器首次被发现存在逃逸可能性,他使用发现的三个漏洞(CVE-2020-2023、CVE-2020-2025 和 CVE-2020-2026)组成漏洞利用链先后进行容器逃逸和虚拟机逃逸,成功从容器内部逃逸到宿主机上。
为缓解甚至消除这些容器运行时的安全隐患,社区提供了一系列强化配置并且多年来也研发了相关的加固工具。CIS 发布的 Docker 基线已成为 Linux 主机配置和 Docker 主机加固的最佳实践。同样,CIS也发布了 Kubernetes 基线,传统的漏洞扫描工具、独立的容器安全产品(如 Aqua Security 和 NeuVector)和私有维护人员已经在 GitHub 上发布了脚本,可实现自动化的 Kubernetes 安全检查。接下来,我们将着重介绍一些行而有效的容器运行时的安全加固技术以及近年来的一些发展。
02容器运行时安全加固
运行时安全是在容器运行时通过检测和防止恶意行为来提供主动保护,可以说是整个容器生命周期中的最后一道安全屏障。其核心思想就是监控并限制容器中高危的行为,缩小容器进程的能力和权限。容器本身是利用了 Namespace 和 Cgroup 技术,将容器和宿主机之间的资源进行了隔离并加以限制。
Namespace
Namespace 即命名空间,也被称为名称空间,这是 Linux 提供的一种内核级别的环境隔离功能,它的主要用途是对容器提供资源的访问隔离,这些资源包括文件系统挂载 、主机名和域名、进程间通信 、进程访问、网络隔离、用户和组隔离等。容器充分利用了 Namespace 的技术,使其达到尽可能地隔离容器之间以及对宿主机的影响。
Cgroup
Cgroup全称为 Control Group,它也是容器的重要特性。如果说 Namespace 是用于隔离,那么 Cgroup 则是限制容器对于资源的占用,如CPU、内存、磁盘 I/O 等。这个特性可以有效地避免某个容器因为被 DDOS 攻击或者自身程序的问题导致对资源的不断占用,并最终影响到宿主机及上面运行的其他容器,出现“雪崩”的灾难 。
虽然这种隔离限制从资源层面实现了对容器和宿主机之间的环境独立,宿主机的资源对容器不再可见,但是这种方式并没有达到真正意义上的安全隔离。由于容器的内核与宿主内核共享,一旦容器中通过恶意行为进行一些高危的操作权限,或者是利用内核漏洞,往往就可以突破这种资源上的隔离,造成容器逃逸,重新危害到宿主机及上面运行的其他容器。
目前 Linux 内核提供了一系列的安全能力可以对这些攻击行为进行有效防护。结合内核安全技术的能力,这些技术的作用范围可以简单地分为两种:一种是限制是限制行为本身,另一种则是限制行为作用的对象范围。首先我们介绍如果有效切断这些造成逃逸的恶意行为,如何去限制发起行为的能力。
2.1 Capabilities 和 Seccomp
在 Linux 系统中 Root 用户作为超级用户拥有全部的操作权限,以 Root 身份运行容器,相当于将打开容器资源限制大门的钥匙交给了容器自身,这是十分危险的。但如果以非 Root 身份在后台运行容器的话,由于缺少权限容器中的应用进程容易处处受限。为了适应这种复杂的权限需求,Linux 细化了 Root 权限的管控能力,从 2.2 版本起 Linux 内核能够进一步将超级用户的权限分解为细颗粒度的单元,这些单元称为 Capabilities。例如,CAP_CHOWN 允许用户对文件的 UID 和 GID 进行任意修改,即执行 chown 命令。
*Capabilities 详细信息可通过 Linux Programmer’s Manual 进行查看:https://man7.org/linux/man-pages/man7/capabilities.7.html
几乎所有与超级用户相关的特权都被分解成了单独的 Capability,可以分别启用或禁用。这种系统权限机制提供了细粒度的操作权限的访问控制,控制容器运行所需的 Capabilities 范围,可以有效切断容器中攻击者的行为操作。即使容器攻击者取得了 Root 权限,由于不能获得主机的完全的操作权限,也进一步限制了攻击对宿主机的破坏。Docker 在容器管理中默认限制了容器的 Capabilities, 其中仅开启如下部分:
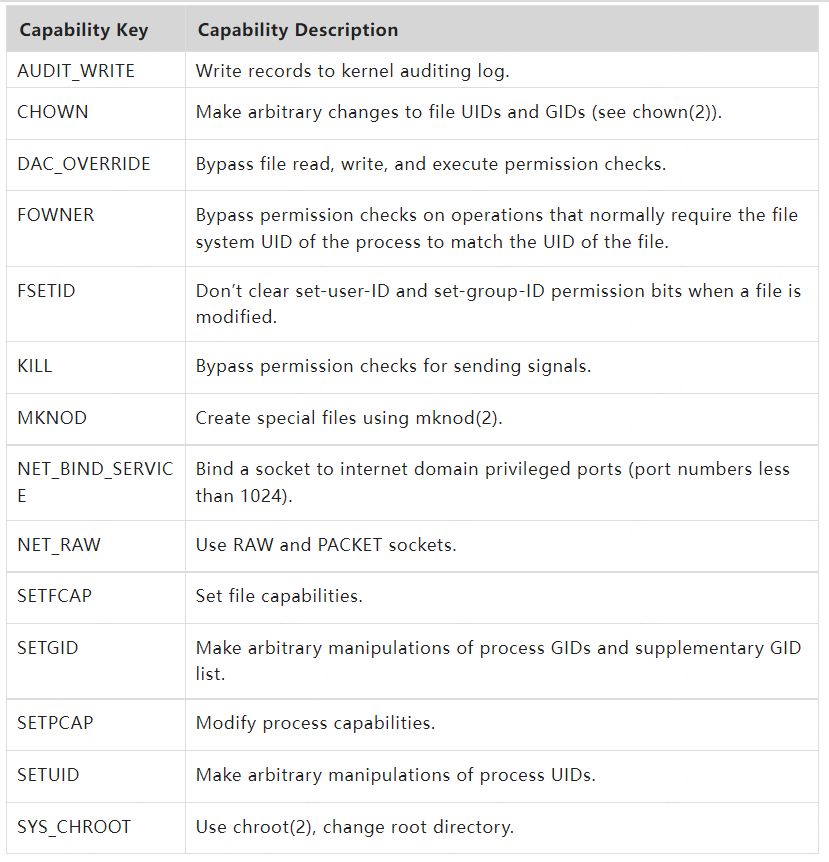
但是基于 Capabilities 的权限访问管理,有时候并不能很好地限制住容器的操作权限。例如,SYS_ADMIN 管理了 mount,umount,pivot_root,swapon,swapoff,sethostname,setdomainname 等等系统调用的访问权限,一旦应用进程因为需要进行 sethostname 这样的操作而在容器中开启了 SYS_ADMIN 组的 Capabilities,那么也就让容器具有了 mount 这类可以挂载系统资源的操作权限,导致容器存在逃逸的风险。Seccomp(Secure Computing Mode)同样也是一种 Linux 内核提供的安全特性,它可以以白名单或黑名单的方式限制进程进行系统调用。相对于 Capabilities 将系统调用以组的形式进行分类管理,Seccomp 是对系统调用更细粒度的单点控制。
Seccomp 首次于内核 2.6.12 版合入 Linux 主线。早期的 Seccomp 只支持过滤使用四个系统调用:read,write,_exit,sigreturn。在这种安全模式下,除了已打开的文件描述符和允许的四种系统调用,一旦进程尝试访问其他系统调用,内核就会使用 SIGKILL 或 SIGSYS 信号来终止该进程。由于这种限制太过于严格,在实际应用中作用并不大。
为了解决此问题,2012 年的内核 3.5 版本引入了一种新的 Seccomp 模式,叫做 SECCOMP_MODE_FILTER。这个功能允许用户使用可配置的策略过滤系统调用,该策略使用 Berkeley Packet Filter(BPF)规则实现,从而使 Seccomp 可以对任意的系统调用及其参数(仅常数,无法指针解引用)进行过滤。因此使用这种模式的的 Seccomp 也被称之为 Seccomp-BPF。而程序在 fork/clone 或 execve 时,BPF 过滤规则是可以从父进程继承到子进程,因此 Seccomp 机制可以很好地用于限制容器的权限。
seccomp 设定的系统调用过滤规则能传递给子程序的关键在于 prctl 系统调用:
prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0);
prctl 的 No New Privileges Flag 可以避免类似 execve 的系统调用授予父进程没有的权限。详见:https://man7.org/linux/man-pages/man2/prctl.2.html
目前 docker 在运行容器时会使用默认配置,其中禁止了约 44 个系统调用,当然也可以使用 –security-opt 选项将默认的配置文件替换为自定义的配置文件。
*docker默认配置详见:https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
在 5.0 版本内核中又加入了新的 seccomp-unotify 模式。Seccomp-BPF 模式对系统调用的判断过程是由加载到内核的 BPF 程序来完成的,而 Seccomp-unotify 机制可以将这一判断过程移交给另一个用户态的进程来完成。同时,利用该模式 Filter 进程不仅可以检测系统调用的参数,还可以对指针参数进行解引用,查看指针所指向的内存。这就方便了判断程序对调用行为的分析判断,大大扩充了 Seccomp 机制的过滤能力。作为一种新增特性,Seccomp-unotify 模式更为强大的过滤能力相信后续会在容器安全加固中拥有比较大的使用空间。
需要注意的是,这种位于 syscall 入口处的检查判断是存在 TOCTTOU(Time Of Check To Time Of Use)风险的——风险就在于此时的一些内存数据依旧保存在用户空间,从入口检测到实际使用还需要一定的时间,攻击者完全可以在这段时间内通过其他并发线程对用户空间上的数据进行修改。因此 Seccomp 以及 Capabilities 的优势不在于限制容器中的进程能否通过 syscall 去访问一些特定的资源,而在于直接去排除容器中进程发起这类 syscall 行为的能力。接下来我们也将讨论如何更有效地限制这些行为的作用对象,以及阻断逃逸后的攻击者对宿主机中其他资源的访问。
2.2 MAC 和 LSM
Namespace 机制让容器和宿主机之间实现了资源上的隔离,让宿主机上的其他资源对容器不再可见。但是这种虚拟隔离并没有限制容器中进程的访问权限,资源访问权限的管理却是由 Linux DAC(Discretionary Access Control,自主访问控制,以下简称 DAC)机制来完成的,它主要依赖的进程的 uid 和 gid 来进行管理。因此一旦容器中的攻击者突破了 Namespace 的界限,往往就可以对容器外的资源进行访问。而解决这一安全风险的关键就是——强制访问控制(Mandatory Access Control——MAC,以下简称MAC)。其中最为熟知的 MAC 访问控制安全模块,就是 SELinux、AppArmor等。
SELinux
早期的操作系统几乎没有考虑安全问题,系统中只有一个用户并且可以访问系统任何资源。而随着多用户系统的发展,为了有效限制用户的访问权限,确保用户只能访问他们需要的资源,出现了访问控制机制来增强安全性。其中主要的访问控制就是 DAC 机制。DAC 通常允许授权用户自主改变客体的访问控制属性,这样就可指定其他用户是否有权访问该客体。然而,DAC 机制只约束了用户、同用户组内的用户、其他用户对文件的可读、可写、可执行权限,这对系统的保护作用非常有限。
Linux 系统中所有内容都是以文件的形式保存和管理的,即一切皆文件。
为了克服这种脆弱性,出现了 MAC 机制,其基本原理是利用配置的安全策略来控制对客体的访问,且这种访问不被单个程序和用户所影响。SELinux(Security-Enhanced Linux)是由美国国家安全局(NSA)联合其他安全机构(比如 SCC 公司)共同开发的一套 MAC 安全认证机制,并在 Linux 2.6 版本后集成在内核中。SELinux 规定了每个对象(程序、文件和进程等)都有一个安全上下文(Security Context),它依附于每个对象身上,包含了许多重要的信息,包括 SELinux 用户(不同于Linux系统的用户)、角色(Role)、类型(Type)和级别(Security Level)等。
管理员可以通过定制安全策略(Security Policy)来定义这些安全上下文,从而定义哪种对象具有什么权限。当一个对象需要执行某个操作时,系统会按照该对象以及该对象要操作的对象的安全上下文所定制的安全策略来检查相对应的权限。如果全部权限都符合,系统就会允许该操作,否则将阻断这个操作。
SELinux 与 DAC
在启用了 SELinux 的 Linux 操作系统中,SELinux 并不是取代传统的 DAC 机制。当某个对象需要执行某个操作时,需要先通过 DAC 机制的检测,再由 SELinux 定制的安全策略来检测。如果 DAC 规则拒绝访问,则根本无需使用 SELinux 策略。只有通过 DAC 和 SELinux 的双重权限检查确认之后,才能执行操作。
SELinux 其中一个重要概念就是 TE(Type Enforcement,类型强制),其原理是将权限与程序的上下文结合在一起,而不是与执行程序的用户,这是目前使用最为广泛的 MAC 检测机制。
SELinux 支持两种 MAC 检测机制
Type Enforcement (TE)
顾名思义,Type Enforcement 是根据安全上下文中的 type 进行权限审查,审查主体的 type 对客体的 type 的某种操作是否具有访问权限,主要集中于程序访问控制决策。
Multi-Level Security (MLS)
多层安全机制,是基于Bell-La Padula (BLP) 模型,将主体和客体定义成多层次的安全等级,不同安全等级之间有相关的访问约束,常见的访问约束是 “no write down” 和 “no read up”。它是根据安全上下文中的最后一个字段 label 进行确认的。
它允许管理者可以基于程序的功能和安全属性,加上用户要完成任务所需的访问权作出访问决策,将程序限制到功能合适、权限最小化的程度。并且这个安全策略采用的是白名单方法,这意味着程序在运行过程中只能被授予策略中明确允许的访问权限。因此,即使某个程序出现了故障或被攻击,但整个系统的安全并不会受到威胁。
容器与 SELinux
容器在默认配置下是没有开启 SELinux 功能的,需要管理者修改 Docker 守护进程中的参数配置进行开启。
如何为容器启用 SELinux:
1.在 dockerd 启动时加上 –selinux-enabled 参数,在 CentOS上 可以修改 systemd 配置文件 docker.service
2.在/etc/docker/daemon.json配置文件中加上:{ “selinux-enabled”: true } 然后重启 docker 服务
开启 SELinux 后,依据自带的默认策略,启动容器中的进程一般会打上 container_t 的标签,容器具备操作权限的资源则一般会打上 container_file_t 的标签。(docker 每创建一个容器,容器中对象的安全上下文还会分配一个额外的信息—— Category,以此来确保容器之间的访问隔离。简单点说是说一个容器A中的进程是无法访问容器B的资源)
这样容器中的进程就无法对容器中的一些特殊资源进行修改,甚至是逃逸后这些进程依旧无法对宿主机的其他资源进行访问。
需要注意的是,docker 在启动过程中可以通过 -v 参数额外挂载一些宿主机上的目录/文件。如果直接挂载在容器中进行访问时,操作是会被 SELinux 阻止:
需要通过加上后缀 :z 或者 :Z 来改变挂载资源的上下文的标签。两者存在区别,具体可以查看 Docker ,详见:Docshttps://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container—volumes-from
近年来比较突出的利用 procfs/sysfs 中的特殊文件进行容器逃逸的方法,在利用 SELinux 对容器环境进行加固后,是可以进行有效阻止。以利用 /proc/sys/kernel/modprobe 进行容器逃逸为例,作为宿主机相关的文件 modprobe 被配置了 usermodehelper_t 的标签,对于容器中的进程 modprobe 文件是没有写权限的,也就阻止了攻击者进行逃逸的操作。
利用 /proc/sys/kernel/modprobe 进行容器逃逸的原理
/proc/sys/kernel/modprobe 用于设置自动加载内核模块相关 usermode helper 的完成路径,默认是 /sbin/modprobe,Linux内核安装或卸载模块的时候就会触发这个被指定的 usermode helper。
在 Documentation for /proc/sys/kernel/ – The Linux Kernel documentation中也提到:“if userspace passes an unknown filesystem type to mount(), then the kernel will automatically request the corresponding filesystem module by executing this usermode helper.”。
也就是说执行一个未知的文件类型,内核也会去调用这个指定的程序。
攻击者就可以替换原有的 modprobe_path 为恶意代码的地址,之后执行一个未知文件类型,内核就会去调用恶意文件,执行恶意代码。
但是这个攻击的利用需要一定的权限,在 docker 中默认 /proc/sys/kernel/modprobe 是不可写入的,需要对 /proc/sys 以 rw 方式 remount 才可以修改文件内容,这就需要被攻击的容器环境具有 SYS_ADMIN 的权限。
*Documentation for /proc/sys/kernel/ – The Linux Kernel documentation 原文详见:https://www.kernel.org/doc/html/latest/admin-guide/sysctl/kernel.html#modprobe
AppArmor
另一个用于此目的的类似的 Linux 内核安全模块是 AppArmor。AppArmor 得到了开发 Linux Ubuntu 发行版的母公司 Canonical 的支持,其目的是希望开发一个比 SELinux 更简单易用的访问控制模块。
RedHat 旗下的所有 Linux 发行版都预装或提供 SELinux 设置,包括 RHEL、CentOS 和 Fedora,而 AppArmor 安装在 Debian、Ubuntu、它们的衍生发行版以及 SUSE Enterprise Server 和 OpenSUSE 发行版上。
与 SELinux 不同,AppArmor 是作为 DAC 机制的补充,用于限制指定目标程序的资源访问权限,例如是否允许读/写某个特定的目录/文件、打开/读/写网络端口以及是否具备某类 Linux Capabilities 等。为了简单易用,Apparmor使用文件名(路径名)作为安全标签,而SELinux使用文件的 inode 作为安全标签。在文件系统中,只有inode才具有唯一性,因此相比于 SELinux,通过改名等方式,AppArmor 存在被绕过的风险。
Docker 本身也提供了对于容器环境的默认 AppArmor 配置,启动容器时系统会自动应用 docker-default 安全配置文件,配置文件通过 template 模板生成,(Docker 也设计了针对 docker 守护进程的配置文件 contrib/apparmor,但是当前并没有包含在 docker 相关发行包中),也可以通过 –security-opt apparmor=<profile-name> 命令行选项指定自定义的配置文件。
*template 模板详见:https://github.com/moby/moby/blob/master/profiles/apparmor/template.go,Docker 守护进程的配置文件 contrib/apparmor详见:https://github.com/moby/moby/tree/master/contrib/apparmor
管理者可以通过检查进程的 /proc/<pid>/attr/current 文件来查看对应进程是否配置了相应的 AppArmor 配置文件:
通过配置 AppArmor 同样可以阻断之前提到的逃逸攻击,例如 docker-default 配置中不仅限制了容器进程对 procfs/sysfs 等敏感文件/目录的写权限,并且限制容器中进程进行 mount 操作。(利用 AppArmor 的配置文件同样可以限制容器 Capabilities 权限,并配置 Seccomp 功能)
LSM 的现状
不管是 SELinux 还是 AppArmor 其实都是 Linux 安全模块(Linux Security Module,以下简称 LSM),都是基于 LSM 框架—— Linux 操作系统内核提供的一种安全机制,来完成对进程对 Linux 资源访问权限的判断(Capabilities 其实也是一个 LSM 模块)。LSM 虽然被称作“模块”,但不同于 LKM(Loadable Kernel Module),这些扩展并不是可加载的内核模块,而是和内核代码一起编译在内核文件(vmlinuz)中,并且只能在系统启动时就进行初始化。
LSM 与 SELinux
在2001年的 Linux Kernel 峰会上,NSA 代表建议在 Linux Kernel 2.5 中加入 SELinux。然而,这一提议遭到了 Linus Torvalds 的拒绝。一方面,SELinux 并不是惟一用于增强 Linux 安全性的安全子系统;另一方面,并不是所有的开发人员都认为 SELinux 是最佳解决方案。最终 SELinux 没能加入到 Linux Kernel 2.5,取而代之的是 Linux Security Module 的开发被提上日程。
LSM 子系统自提出后开发了近3年,并终于在 Linux Kernel 2.6正式加入到内核中,随之应运而生了大量LSM,比如 SELinux、SMACK、AppArmor、TOMOYO、Yama、loadPin、SetSafeID、Lockdown 等。

从上图可以看出 LSM 框架在Linux安全体系中所处的位置,LSM hook 点一般会被插入到被访问的内核对象与 DAC 检查之间。系统在完成 DAC 检查通过之后,然后根据 LSM 框架调用系统中启用的 LSM 模块,检查是否允许访问,这也是为什么 SELinux 的检查是在 DAC 之后的原因。同时我们也可以看到与之前 Seccomp 在系统调用入口点的检测判断不同,LSM Hook 点所在的位置基本上位于实际资源的访问之前,在这个时候相关的数据信息已经从用户空间复制到内核空间中,也就不会再有攻击者在用户空间进行篡改的可能性。
如果系统中有多个 LSM 模块,就会根据 LSM 在初始化时的优先顺序依次执行,所有检查都被允许才可以继续访问内核对象。通过使用 LSM 框架,就可以进行内核安全审计和元数据捕获。安全开发人员只需要按照既定的调用规范编写 LSM 模块,并加载进 Linux 内核,不再需要对系统内核代码进行修改。这就方便了安全人员不在受限于已有的 AppArmor、SELinux 等模块可以基于自身公司容器环境的实际需求,定制化的开发更为轻便的访问控制模块,有针对性地保障容器环境。而 Linux 5.4中加入的 lockdown 模块直接禁止了运行时对内核的动态修改,使得 LSM 框架成为 Linux 安全加固工具开发的最佳途径之一。
LSM Stacking
当前的 Linux 系统虽然支持多个 LSM 模块的运行,但是这种运行依然存在着很大的限制,例如 SELinux 和 AppArmor 不能运行在同一系统中。其实基于这种限制,LSM 模块被划分为两种:Major LSM 和 Minor LSM。目前 Linux 系统中提供的 Major LSM 包括 SELinux、SMACK、AppArmor 和 TOMOYO,这四个模块都是 MAC 的实现。LSM 框架在最初设计时只允许启用一个 LSM 模块,Major LSM 模块在设计开发时都假设自己拥有对受保护内核对象的安全上下文指针和安全标识符的独占访问权限。例如进程相关的“/proc/[pid]/attr”目录下的相关文件,就是用来标记进程的安全属性,像“/proc/[pid]/attr/current”文件,被 SELinux 用来标识进程的安全上下文,而 AppArmor 模块则用于标识进程对应的配置文件。由于 Major LSM 所具有的排他性,即使四个安全模块都编译进了内核,内核在启动时只能打开一个 Major LSM 模块。而 Minor LSM 模块则没有这种排他性,可以同时运行在系统中。相比于 Major LSM,他们的作用范围更小,较少地访问或者使用内核对象的安全上下文指针,例如 YAMA 模块主要是对 Ptrace 函数调用进行访问控制。其他 Minor LSM 模块还有 LoadPin、SetSafeID、Lockdown 等。并且他们一般直接硬编码了大部分安全策略,相对地 Major LSM 模块则可以加载用户可配置的安全策略。在 Linux 5.1 版本之前,通过启动参数 “security=”,内核在启动时确认打开哪个 Major LSM 模块,若未指定则按照 Kconfig 编译配置中 CONFIG_DEFAULT_SECURITY 的值启动。
为了更便于多个 LSM 模块的加载使用,LSM 框架在近年来也在逐步逐步消除 Major LSM 模块之间独占性的问题。从 5.1 版本开始,改进了模块的启动方式,启动参数由 “lsm=” 替换了原有的 “security=”(参数被保留,但是存在 “lsm=” 参数时,不起作用), Kconfig 编译配置中 CONFIG_DEFAULT_SECURITY 也被替换为 CONFIG_LSM。内核在启动过程中会按照 “lsm=” 参数中的顺序启动相应的的 LSM 模块。
为了区分Major LSM 和 Minor LSM,引入了 LSM_FLAG_LEGACY_MAJOR 和 LSM_FLAG_EXCLUSIVE 标志来标注对应的 LSM 模块的排他性。如果启动顺序中配置多个 Major LSM 模块,那么在启动过程中,内核会按照顺序只打开第一个具有 LSM_FLAG_EXCLUSIVE 标志的模块。当然这部分只是对模块启动的优化,改进的另一个重要的目标就是可以让一个系统中开启多个 Major LSM 模块。从 5.1 版本开始 TOMOYO 已经被消除了排他性标记,而 AppArmor 也很快将可以消除这一标记,与其他 MAC 模块同时运行在同一系统中(参考 LSM: Module stacking for AppArmor)。这种特性的发展为不同业务容器配置不同的 MAC 模块带来了可能性。
*LSM: Module stacking for AppArmor,详见:https://lwn.net/ml/linux-kernel/20220415211801.12667-1-casey@schaufler-ca.com/
2.3 eBPF 观测与防护
eBPF,全称为扩展的伯克利数据包过滤器(Extended Berkeley Packet Filter),是传统 BPF(以下称为 cBPF)的后继者。之前我们介绍过 SECCOMP_MODE_FILTER 模式下的 Seccomp 也是通过 cBPF 来构建自定义的系统调用筛查规则。cBPF 最初的设计目标是用于过滤网络数据包的,受限在内核空间使用,只有少数用户空间程序(例如:tcpdump和 seccomp)可以编写这类过滤器。
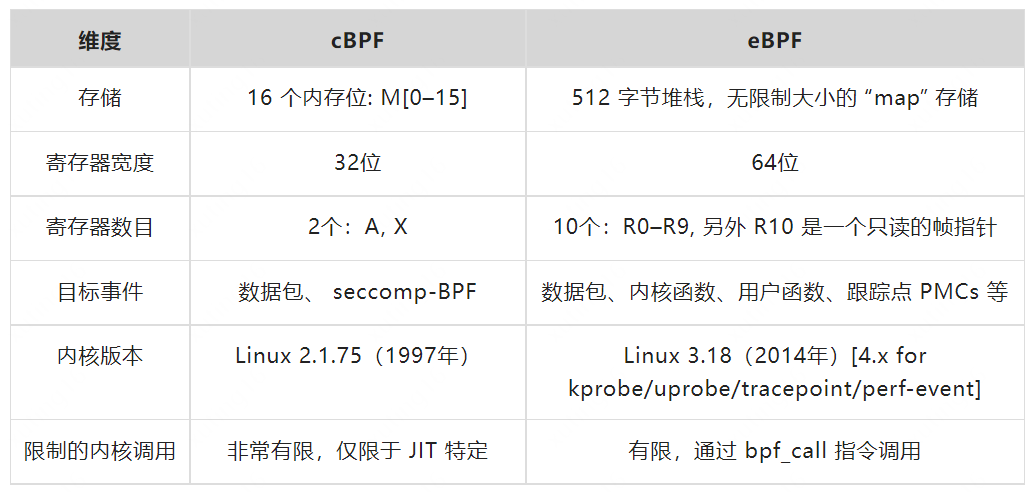
2014 年,Alexei Starovoitov 对 cBPF 进行彻底地改造,实现了更为高效的 eBPF。时至今日 cBPF 现在已经基本废弃,Linux 内核只运行 eBPF,内核会将加载的 cBPF 转换成 eBPF 再执行。下面是 CBPF 和 eBPF 的对比:(参考【19】)
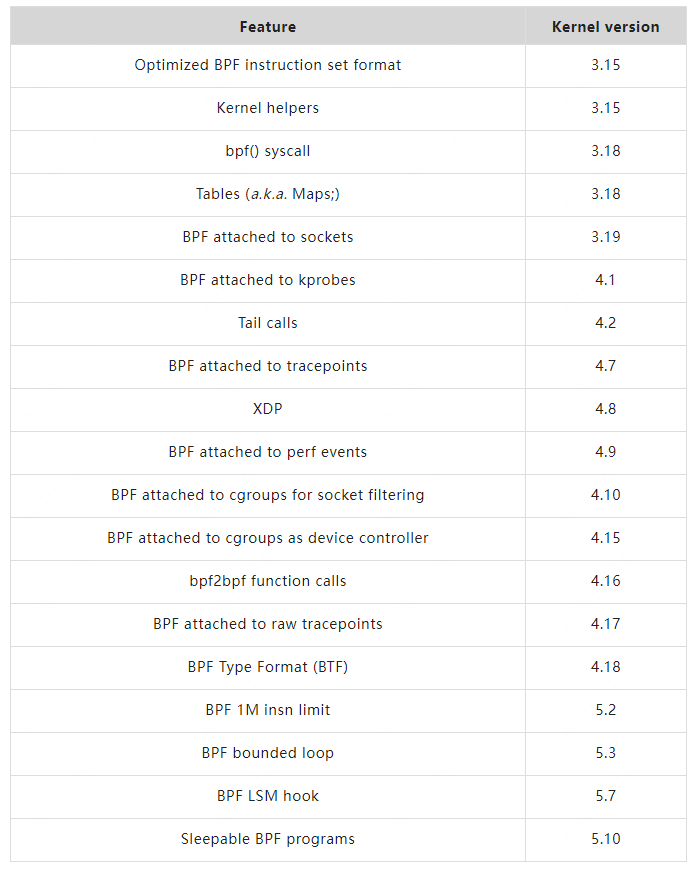
eBPF 的设计的最初目标是针对现代硬件进行的优化,生成指令集更接近硬件的 ISA(Instruction Set Architecture),所以 eBPF 相比于原有的 BPF 解释器生成的机器码执行得更快。在这之后更重要的一步改进优化就是将 eBPF 扩展到用户空间,提供了用户空间和内核空间数据交互的能力,这也使得 eBPF 可以适用于更为复杂的数据观察和分析场景中。随着越来越多的新特性被合入到 Linux 内核社区,eBPF 支持的功能已经越来越丰富,扩展了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及 LSM 等事件类型。下表列出了目前 eBPF 一些重要的特性(详细可参见 BPF Features by Linux Kernel Version:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md):
随着这些改进的加入,eBPF 的使用场景也不再仅仅是网络分析,可以基于 eBPF 开发性能分析、系统追踪、网络优化、安全防护等多种类型的工具和平台,许多最新的检测、监控软件和性能跟踪工具都是基于 BPF 技术,并且在云原生社区中,eBPF 被大量项目采用(例如 Cilium、Falco、Tracee)。
*Cilium详见:https://docs.cilium.io/en/v1.8/intro/、Falco详见:https://falco.org/、Tracee详见:https://github.com/aquasecurity/tracee
eBPF 程序本身是一个标准的 ELF(可执行和可链接格式,Executable and Linkable Format)文件,一般由 C 语言开发并使用 LLVM 编译而成。作为标准的对象文件,同样可以用像 readelf 这样的工具来检查,其中包含程序字节码和所有映射的定义。之后用户空间程序就可以通过 bpf() 系统调用将 eBPF 字节码加载到内核,在加载的过程中,内核会使用验证器组件对字节码的安全性进行验证,避免 eBPF 程序不会对内核造成崩溃影响。在 eBPF 程序运行过程中,如果有需要就可以通过 Maps 或者 perf-event 事件将执行结果或者检测到的数据信息回传至用户空间程序,并且用户空间程序也可以通过 Maps 给 eBPF 程序传递数据。下图是 eBPF 整个流程的图示:

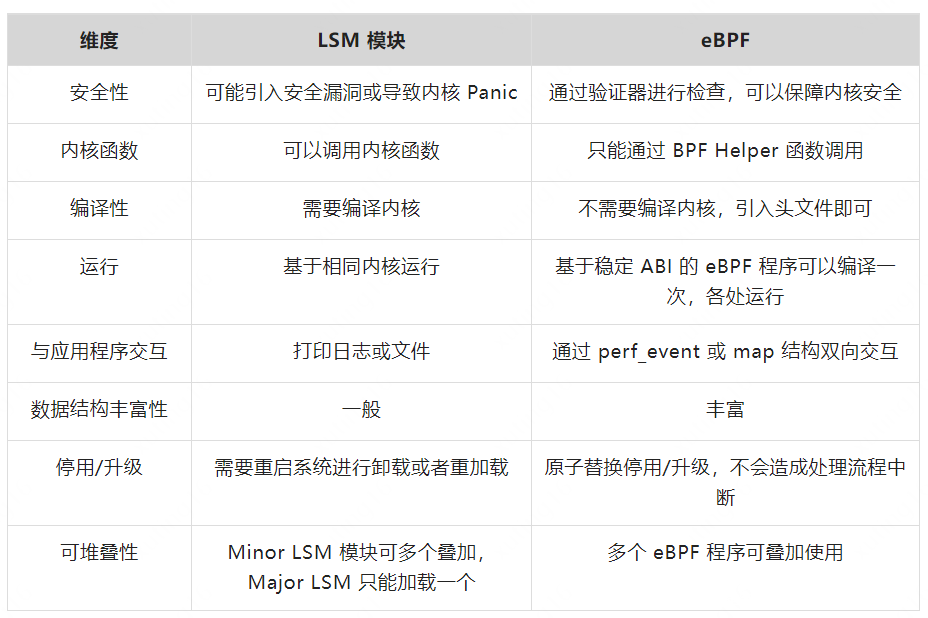
2.4 eBPF 与 LSM 模块
相较于 LSM 框架,eBPF 提供了一种更加简便安全的方式在 Linux 内核中运行自定义的代码。通过编写内核模块来改变或扩展内核行为,往往需要足够的内核编程知识,并且在编写使用过程中需要十分谨慎,以免因为一些疏忽带来内核代码崩溃的问题,甚至留下攻击者可以利用的漏洞。因此为了保障内核安全性,往往内核模块的开发以及内核新版本的发布,都需要长时间的分析测试。
而 eBPF 程序的开发则不需要通过复杂的内核编译,只需要引入相关结构体的头文件申明,这就给 eBPF 程序的开发降低了难度。同时 eBPF 在安全性保证上提供了一道有效的屏障—— eBPF 验证器:在整个 eBPF 的使用过程中,内核会在加载 eBPF 程序时对 eBPF 程序进行分析验证,保证 eBPF 程序不会造成内核崩溃等问题,当然这不意味着 eBPF 程序在开发后不需要经过测试验证,但是在一定程度上保障了 eBPF 的安全性。验证器首先会确保程序中没有不可达的指令,并且没有无界循环,确保程序在一定数量的指令数量后安全地终止,其次通过模拟执行,确保所有路径都是可以运行完成的,验证程序没有越界访问内存。在验证通过后,eBPF 程序才能被解释执行。更具有优势的一点是,eBPF 程序是可以动态地从内核中加载或删除,而不像 LSM 模块需要重启系统才能进行模块加载,完全可以做到不打断任何已经存在的进程。
下表列举了一些 LSM 模块和 eBPF 的差异点:(参考【19】)
2.5 eBPF 与容器安全
正如前面提到,作为一个功能丰富的新特性,eBPF 提供了一种便利的可基于系统或程序事件高效安全执行特定代码的通用能力,并且它可检测的事件覆盖了系统的各个方面(如下图所示),提供了丰富的可观察信息,甚至在 Linux 5.7 版本后 eBPF 程序可以插入 LSM hook 点。
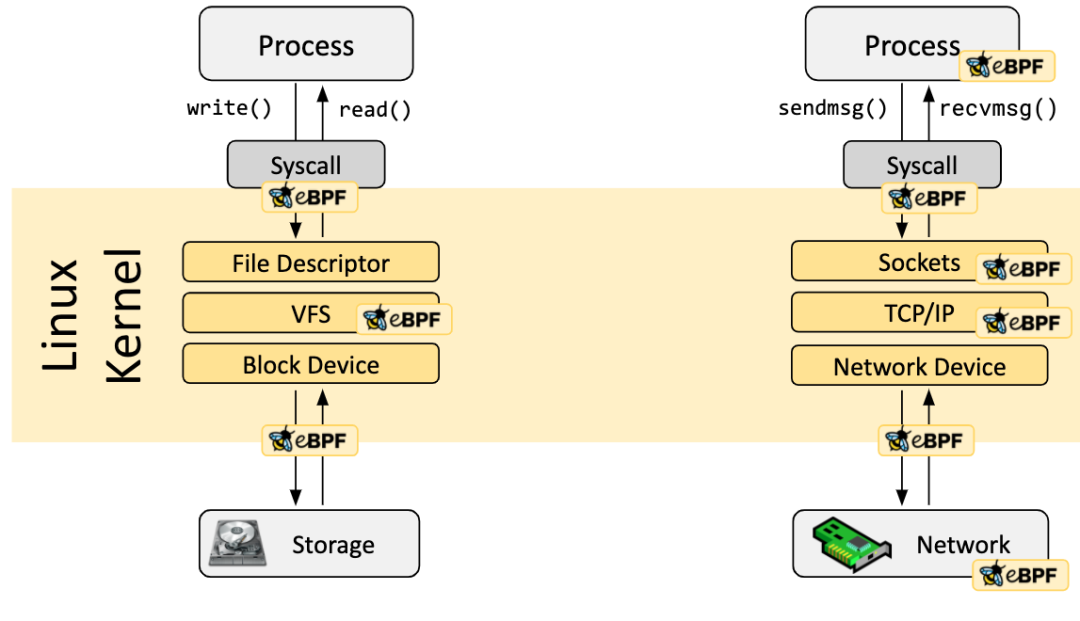
对于容器环境来说,所有运行在一台机器上的容器都和主机共享内核,内核了解主机上运行的所有应用代码。eBPF 的 Hook 点可以说是遍布内核的各个角落,这对于容器安全的检测和防护是很大的助力,方便了对容器中正在进行的操作的分析和判断,近些年来有许多利用这项新技术来解决一些容器安全问题的工具。当前这类安全上的工具主要可以分为两类:一类是确保网络活动的安全,eBPF 最初就是用于网络数据包过滤的技术,可以在网络驱动中尽可能早的位置提供最优的数据包处理能力,过滤并丢弃恶意或非预期的流量以及防范 DDOS 攻击等。而另一类则是检测恶意行为,确保应用程序在运行时的行为安全。例如利用 eBPF 同样可以在系统调用的入口处插入检测过滤程序,但是相比于 Seccomp 更强大的地方在于,eBPF 程序可以对其中的指针参数进行解引用,这也就方便了更进一步的行为分析。
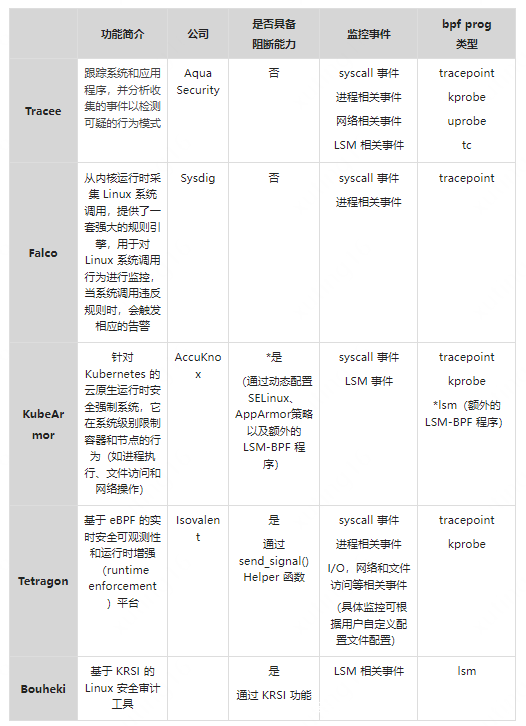
早期的 eBPF 程序并没有直接的阻断功能,而是作为观测分析工具将收集到的的信息交给用户空间程序,这样用户空间程序根据这些信息判断目标进程操作的威胁性来杀死目标进程。目前大部分的成熟的基于 eBPF 开发的安全工具都将其作为系统观察和信息收集的手段加以利用,例如 Aqua Security 云原生安全公司开发的 Tracee 和 Sysdig 开发的 Falco 都是基于 eBPF 系统观测能力的异常行为检测工具。之后在 Linux 5.3 版本中引入了 send_signal() Helper 函数,BPF 程序本身具备了可以直接决断是否终止目标进程的能力。
2022年5月,Cilium 的母公司 Isovalent 在欧洲举行的 KubeCon 技术峰会期间发布了云原生运行时防护系统——Tetragon,正是利用这一新特性来做到安全防护的能力。无论是通过用户空间高权限进程杀死恶意进程,或者是 eBPF 程序直接通过 send_signal() 终止进程,这两种加固阻断的方式或多或少都是存在 TOCTTOU 风险的。直到 Linux 5.7 版本,eBPF 程序可以直接插入 LSM hook 点,并影响 LSM Hook 点的判定结果。需要区分的是,5.7 版本之前的 eBPF 程序虽然可以利用 kprobe 进行动态插入来观测 LSM 相关方法的情况,但是只能用于数据采集,并不能影响 LSM 方法的返回值。正是这一新特性 Kernel Runtime Security Instrumentation(简称 KRSI)的出现,使得基于 eBPF 开发的安全工具才具备真正意义上的加固阻断能力,也为云原生安全加固相关的工作带来了更多可能。
下表列举了当前比较有名的基于 eBPF 开发的安全工具(当前基于KRSI的项目较少,笔者选取了github上比较有特点的一个开源项目作为对比):
03容器运行时安全的未来
当前云原生的技术大多数被服务于 Web 应用的相关业务,此类业务往往把性能要求放在较为靠前的位置,对于设备上选用的安全加固技术都会有性能方面的考量。而 eBPF 的出现为容器安全带来了一种能够动态、轻量、无感知的提升防御能力的方式。其全面的观测能力,可以轻松地监控到容器安全可观测性的四个黄金信号【18】:进程执行、网络套接字、文件访问和七层网络身份,保证了安全检测的全面性。同时 KRSI 特性的出现使得 eBPF 程序还具备了等同于 LSM 模块进行访问控制的决断能力,而不再只是单纯地作为观测工具。因此在未来的发展过程中,eBPF 的相关应用将是容器运行时安全最重要的助力。同时,不可忽视的是对低版本内核系统上的安全防护,目前并在未来很长的一段时间内,大多数的主机服务器上仍然将运行着 Linux 3.* 以及 4.* 的系统。对于这些系统来说,Seccomp、LSM 模块等内核安全机制依旧是保障容器安全不可或缺的部分。
【参考资料】
1.“Docker Overview”:https://docs.docker.com/get-started/overview/
2.“云原生之容器安全实践”:https://tech.meituan.com/2020/03/12/cloud-native-security.html
3.“Exploring container security: An overview”:https://cloud.google.com/blog/products/gcp/exploring-container-security-an-overview
4.“MITRE ATT&CK® Containers Matrix”:https://attack.mitre.org/matrices/enterprise/containers/
5.“Sysdig 2022 Cloud‑Native Security and Usage Report”:https://sysdig.com/wp-content/uploads/2022-cloud-native-security-and-usage-report.pdf
6.CIS Docker Benchmark:https://www.cisecurity.org/benchmark/docker
7.CIS Azure Kubernetes Service (AKS) Benchmark:https://www.cisecurity.org/benchmark/kubernetes
8.“New Container Kernel Features” – Christian Brauner, Canonical Ltd.*:https://static.sched.com/hosted_files/ossna19/22/OSS%20NA%202019_%20New%20Container%20Kernel%20Features.pdf
9.“capabilities(7) – Linux man page”:http://man7.org/linux/man-pages/man7/capabilities.7.html
10.“Seccomp BPF (SECure COMPuting with filters)“:https://www.kernel.org/doc/html/latest/userspace-api/seccomp_filter.html
11.“seccomp_unotify(2) — Linux manual page”:https://man7.org/linux/man-pages/man2/seccomp_unotify.2.html
12.“Inside the Linux Security Modules (LSM)” – Vandana Salve, Prasme Systems:https://static.sched.com/hosted_files/ossna2020/3a/ELC_Inside_LSM.pdf
13.“LSM Stacking – What You Can Do Now and What’s Next” – Casey Schaufler, Intel:https://static.sched.com/hosted_files/lsseu2019/84/201910-LSS-EU-xxx-Stacking.pdf
14.《What Is eBPF? An Introduction to a New Generation of Networking, Security, and Observability Tools》—— Liz Rice
15.“eBPF Documentation”:https://ebpf.io/what-is-ebpf
16.“eBPF 技术简介”:https://cloudnative.to/blog/bpf-intro/
17.《Linux Observability with BPF: Advanced Programming for Performance, Analysis and Networking》(译名《Linux内核观测技术BPF》)—— David Calavera and Lorenzo Fontana
18.《Security Observability with eBPF: Measuring Cloud Native Security Through eBPF Observability》—— Jed Salazar and Natalia Reka Ivanko
19.“基于 eBPF 实现容器运行时安全”:https://www.ebpf.top/post/ebpf_container_security/
20.“Tetragon进程阻断原理”:https://www.cnxct.com/how-tetragon-preventing-attacks/
21.“KRSI — the other BPF security module”:https://lwn.net/Articles/808048/







发表评论
您还未登录,请先登录。
登录