

作者:魂淡p
预估稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
前言
一直以来,我认为我们所使用的密码由各个不同的信息间断组合而成,而选用哪些信息、如何组合,这些是需要被认真研究的,目前我还未看到对此有相关的较为严谨的文章,本着尽量严谨的学习态度,我对大众密码进行了一次分析,并在此讲述我的分析过程和结论。
另外,由于该数据并非近期数据,以及当时该网站几乎没有密码策略的原因,分析的结果可能并不适用现下情况。
0x01 理论准备
在这里,我将使用“密码片段”“弱密码片段”“弱密码行为片段”的概念帮助本文的编写,所谓的密码片段,指的是在一串密码中,我们所使用的不同的信息片段,如hll19980606,该密码可以分为两个密码片段,一是姓名的缩写hll,二是其出生日期,二者代表了不同的含义。
所谓弱密码片段,指的是大多数人在进行密码生成的过程中经常使用到的一个字符串片段,比如由a12345 a6633 a6666 这三个密码,我们可以得知,在密码组合的过程中,我们经常使用到a这个片段,则a就是我们所指的弱密码片段。
弱密码行为片段,指的是大众常在密码中使用的信息,例如前面提到的具有特殊意义的日期时间、个人的姓名、身份证、手机号码等不同含义的信息,这些信息所展现出来的密码片段就是我们所说的密码行为片段,而弱密码行为片段即人们在密码中常用的信息。
一般而言,密码片段可以从字母、数字、字符三个类型的字符串来考虑,因为单一的信息往往采用单一的字符串类型来保存,比如姓名使用字母,生日使用数字,因此当不同类型的字符串交替出现时,其极有可能出现了不同的密码片段,我们可以据此来提取密码片段以进行分析。
另一方面,物以类聚,不同的社区和团体的用户可能在密码的使用方面会有不同的倾向,对不同类型的用户的密码进行分析,也是我们应该考虑的事。
对弱密码片段、弱密码行为片段进行统计分析,有助于我们更方便的猜测不同用户可能使用的密码。
0x02 数据提取
出于数据量和数据纯净度的考虑,本次所分析的密码库采用的是网上公开流传的某数据库,数据量经过统计达70w条,由于数据本身为sql文件,其中含有转义字符,自写程序处理起来较为麻烦,因此决定将其导入mysql后再格式化导出所需字段。
导出命令类似:
mysql -uroot -ppass -e "select password from xxx.xxx" >>pass.txt需要提醒一点的是,使用上述方法导出,第一行是字段名password,另外其中的换行符为CRLF,即”rn”,其实与0x03内的代码不符,因此如需套用下述代码,应先将”rn”处理为”n”。
亦可采用select into outfile的方式,不再赘述。
0x03 数据处理
数据量略大,使用图形化编辑器处理容易造成程序假死,这里使用php的cli模式,简单写了几行代码,方便数据的提取。
主要实现的是字符串正则提取和替换,在使用的时候按需求修改正则表达式或选择性注释,代码类似下述,PHP 5.6.27测试通过,可能有少量冗余代码,出现内存用尽的警告时将$leng改小一点即可,或者可以尝试使用类似ini_set('memory_limit',128M); 的代码,将分配给php的内存调大一点。
用法
php.exe xxx.php pass.txt代码内容
<?php
$filename = $argv[1];
$r='_'.rand().'.txt';
$leng=1024*1024*30;
$offset=0;
for (;;){
$length=$leng;
//正确提取行内数据,防止一行字符只提取了部分
for (;;){
if (file_get_contents($filename,false,null,$offset+$length,1)==="n" ||filesize($filename)<=$offset+$length) {
break 1;
} else{
$length=$length>=(filesize($filename)-$offset)?filesize($filename)-$offset:$length;
$length--;
if($length===0)
exit("length maybe too short");
}
}
$c=file_get_contents($filename,false,null,$offset,$length);
// // 正则提取,自动分行
// preg_match_all('/([^da-zA-Z]+)/mi', $c, $test);
// foreach ($test[1] as $key => $value) {
// file_put_contents($filename.$r, $value."n",FILE_APPEND);
// }
// $offset+=$length;
// if($offset>filesize($filename))
// break 1;
// //正则替换
$test=preg_replace("/n /mi"," ",$c);
file_put_contents($filename.$r, $test,FILE_APPEND);
$offset+=$length;
if($offset>=filesize($filename))
break 1;
//去除重复空白行
// $test=preg_replace("/(n){2,}/mi","n",$c);
// file_put_contents($filename.$r, $test,FILE_APPEND);
// $offset+=$length;
// if($offset>=filesize($filename))
// break 1;
}
echo $filename.$r;
?>下述代码是我用于计算词频的,
php.exe count.php pass.txt代码内容
<?php
$filename = $argv[1];
$r_file=$filename.'_'.rand().'.txt';
$f=file($filename);
$f_c=array_count_values($f);
arsort($f_c);
foreach ($f_c as $key => $value) {
file_put_contents($r_file, $value.' '.$key,FILE_APPEND);
}
echo $r_file;
?>其他代码大同小异,就不提供了,密码片段的提取过程只是一个正则的修改,不再细述。
0x04弱密码片段统计分析
经过处理,我们从字符串类型、片段完整度两方面提取了9个文件,如下:
multi.txt_字母提取.txt_C_O.txt_20115.txt
multi.txt_字符提取.txt_C_O.txt_5327.txt
multi.txt_数字提取.txt_C_O.txt_19182.txt
字母提取.txt_C_O.txt_373.txt
字母行.txt_C_O.txt_16123.txt
字符提取.txt_C_O.txt_26830.txt
字符行.txt_C_O.txt_3954.txt
数字提取.txt_C_O.txt_15998.txt
数字行.txt_C_O.txt_5071.txtxx行指只用作完整密码的片段,multi.txt指不用作完整密码的片段,xx提取指包含以上二者的片段。
下面直接使用excel生成了可视化统计图。
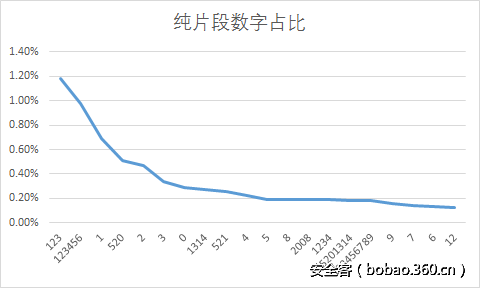
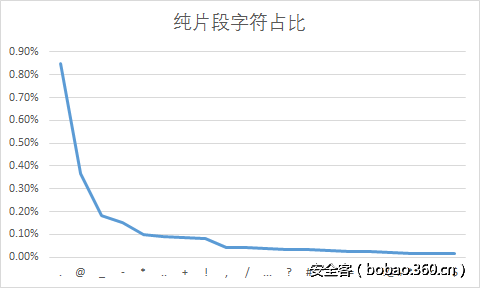
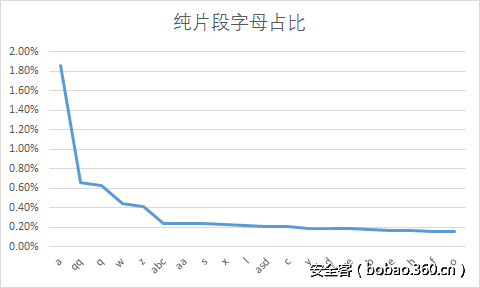
到这里可以看出,该网站的用户在进行组合密码的时候,最常用的片段是123,123456,1,520,.,a,qq等,他们往往以这些片段与其他信息组合。
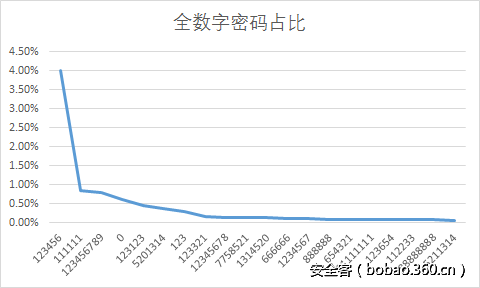
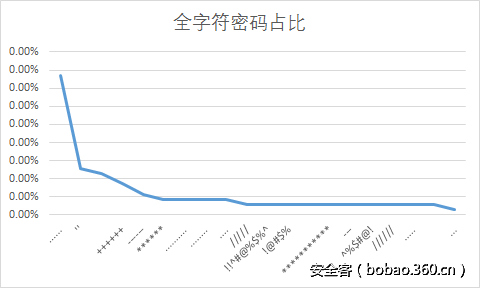
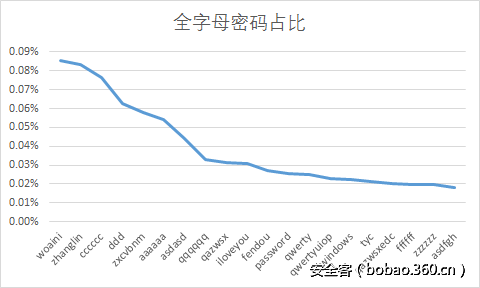
在不进行组合时,他们更多使用的是例如123456,……,woaini这些片段,和上述片段稍有不同
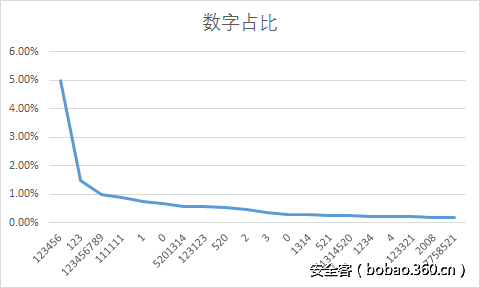
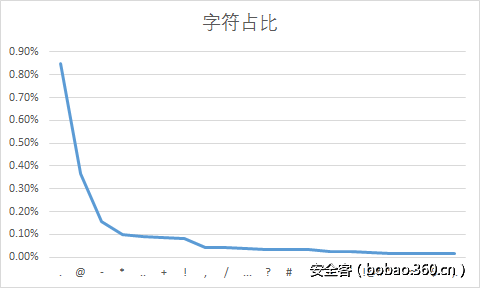
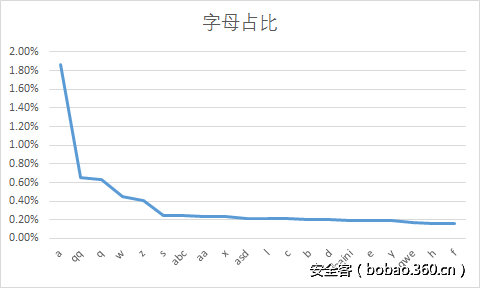
统一观察的结果基本是前面二者相加,做一个宽泛的概述。
0x05 字符串类型组合情况
这里我使用了数据库,方便数据的筛选。
另外,用a代表大小写字母,0代表数字,~代表特殊字符。
提取top20的组合制成统计图,情况如下。
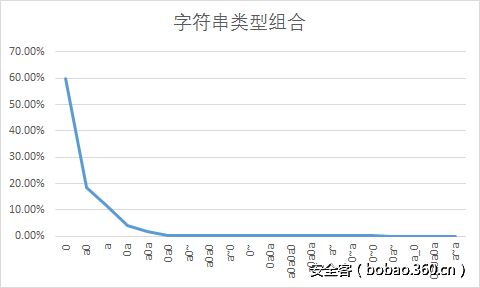
数据结果显示,该批密码数据中,纯数字类型的密码高达60%(可以说是很可怕了)。
参考代码如下
<?php
$con = mysqli_connect($mysqlhost, $username, $password, $dbname)
or die('SQL server down');
$arr=file('xxx.txt',FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
foreach ($arr as $key => $value) {
$t=preg_replace('/[a-zA-Z]+/','a',$value);
$t=preg_replace('/d+/','0',$t);
$t=preg_replace('/[^w]+/','~',$t);
if(!$record[$t]){
$record[$t]=1;
}else{
$record[$t]++;
}
echo $key." 1n";
}
unset($arr);
$n=0;
foreach ($record as $key => $value) {
$n++;
$key=addslashes($key);
mysqli_query(
$con,
"INSERT passtest(string,times) VALUES('{$key}', '{$value}')"
);
echo $n." 2n";
}
mysqli_close($con);
?>
0x06 弱密码行为片段统计分析
这里我们是定义了一些行为标准,然后按照标准来匹配的。
但是又不得不说的是,一个片段是否属于行为片段,是比较难通过简单的规则来判断的,因此这里的分析所展现的结果十分有限。比如一个数字是否是和用户相关的QQ账号,是不能简单的看数字的,还需要通过有效的关系库,进行更复杂的分析。
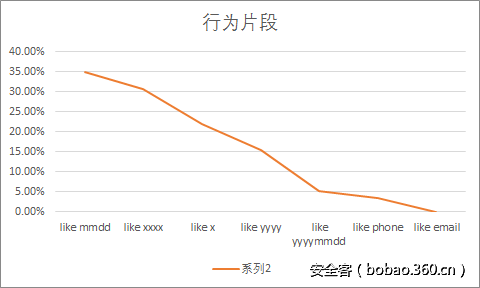
测试代码
<?php
$arr['yyyy']='/(19|20)[0-9]{2}/i';
$arr['yyyymmdd']='/(19|20)[0-9]{2}(0[1-9]{1}|1[0-2]{1})[0-3][0-9]/i';
$arr['mmdd']='/(0[1-9]{1}|1[0-2]{1})[0-3][0-9]/i';
$arr['xxxx']='/((AO|AI|OU)|([ZSC][H])|([qwertypsdfghjklzxcbnm])){2,4}/i';
$arr['x']='/((AO|AI|OU)|([ZSC][H])|([qwertypsdfghjklzxcbnm]))[aoeiuv]{1,2}[ng]{0,2}/i';
$arr['phone']='/1(3|5|7|8)d{9}/i';
$arr['email']='/w+@w+.w+/i';
// $arr['qq']='/[1-9]d{4,9}/i';
$f=file('xxx.txt',FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
foreach ($f as $key => $value) {
echo $key."n";
foreach ($arr as $key1 => $value1) {
if(preg_match($value1,$value))
if(!$n[$key1])
$n[$key1]=1;
else
$n[$key1]++;
}
}
echo "Now writing...n";
foreach ($n as $key => $value) {
file_put_contents('xxx.new.txt',$key.' '.$value."n",FILE_APPEND);
}
?>0x07 修正工作
其实细心的朋友应该考虑到了,在0x03中采用的是按照字符串类型来分割片段,这是有问题的,比如在处理如q1w2e3,hllsb,20082333,passw0rd这样的字符串,就容易显得心有余而力不足。
因此我在这里也使用了另一种方法来进行词频,无视字符串类型,不过依然不完美,主要的原理就是从所有密码中提取所有连续的m个字符,计算词频,然后提取所有的m-1个字符,计算词频……直到提取所有连续的3个字符,提取词频。
每次提取的连续字符数其实也就是我们说的粒度或者精度了,由于粒度本身很难正确控制,而一般而言粒度越小,带来的信息量往往越低,像abcd,不能把四个字母都单独作为片段,字符单独作为片段往往是用于不同类型字符的隔断,例如a123456,xxx@xxx.xxx,而这时候的单个字符,我们使用0x03的方法是可以提取出来的。因此我们应当适度控制最小粒度。
因此,当粒度太小,排行第一的字符容易是一些无意义字符,粒度太大容易过滤掉一些片段,另一方面,由于原理的限制,这种方法提取非常耗计算资源。
在这里,我提取了前1w个密码作为分析。结果如下。
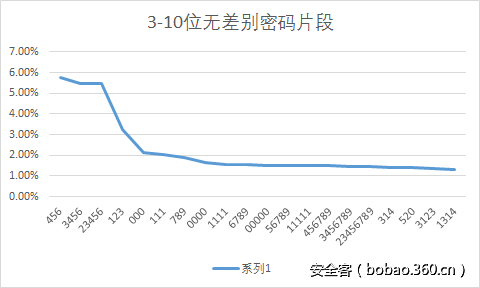
倒不是我刻意处理了字母和字符,而是提取出来的前1w密码的样本分析结果的确如此,其实这也符合0x04 0x05的统计结果。
不过这样的问题也很明显,字符串23456的使用频率和3456、456频率很接近,也就是说,实际上23456是出现最频繁片段,而3456 456脱离23456存在的情况并不多。因此还需要进一步再进行分析。
下面是我使用的代码,在处理大量数据的时候,下列代码就显得力不从心了,甚至容易出现内存不够的现象。
<?php
ini_set('memory_limit', '128M');
$file=$argv[1];
$a=file($file,FILE_IGNORE_NEW_LINES | FILE_SKIP_EMPTY_LINES);
$max=0;
foreach ($a as $key => $value) {
$max=$max>=strlen($value)?$max:strlen($value);
}
// $m=$max;
$m=10;
$n=0;
for (; $m>3 ; ) { //控制最小粒度
foreach ($a as $key1 => $value1) {
if($value1>=$m){
$i=0;
for(;$i+$m<=strlen($value1);){
$c=substr($value1, $i,$m);
if($b[$c]){
$n=0;
$i++;
continue ;
}
foreach ($a as $key2 => $value2) {
if(stripos($value2, $c)){
$n++;
}
}
$b[$c]=$n;
$n=0;
$i++;
}
}
echo $m.' '.$key1."n";
}
$m--;
//echo $m."n";
}
arsort($b);
// print_r($b);
foreach ($b as $key => $value) {
file_put_contents($file.'_new.txt', $value.' '.$key."rn",FILE_APPEND);
}
?>0x08 可能更好的解决方案
廉价劳动力:可以使用一个较低的价格,雇人来将这些片段给分割出来,比如hllsb,让他在hll和sb之间加个回车,不过这显然需要一定的财力支撑。
免费劳动力:像是拥有大量用户的互联网公司,就可以玩这种游戏,“验证码1:中国是那一年建国的,验证码2:请将hllshabi分割成几个有意义的片段(如xxwoaini=xx|woaini),通过验证码1来判断2分割正确的概率”。不过如果真的应用的话,并不像我描述的这么简单。
可能略显简单的方法:直接定义一个预设表,预设一些常用的片段。
可能更智能的方案:
思考一下,我们为什么看到q1w2e3,passw0rd的时候会知道这不应该拆分,而看到hllsb,20082333这类却觉得应该拆分?
我认为是熟悉度的原因,qwe和123本身是一个比较眼熟的片段,在q1w2e3中,qwe和123本身间隔的不远,我们很容易从中提取出我们熟悉的这两个片段。
而对于passw0rd,对我们来说password是一个眼熟的片段,二者其实差别不大,可以看到其实只有一个字节被替换成了相近的0,其实就算被替换成了passw@rd,或者替换成其他类似的字符串,我们稍微思考一下也是可以理解它是由password演变而来的。
至于hllsb,20082333,这二者应该算是典型了,前者是因为我们知道sb这个片段,而hll又正好属于声母,h属于百家姓里的姓氏的声母,可以推测出hll为人名,这都是熟悉度的典型代表。同样的,2008匹配了公元纪年法且符合近、现代年份,2333匹配了网络用语。也就是说,熟悉度不仅仅是具体某个字符串,还可能是匹配某种格式。
因此如果要模拟大脑的思路,我们可以建立一个预设表,其中字段可以是:弱密码片段、常用类型、网络用语、英文常见单词、韵母表、百家姓……等等,然后将字符串进行一定的处理,然后与预设表进行匹配,如果可以高度匹配某个值或类型,那么就表示该字符串很可能是一个独立的片段,应该独立看待,如果匹配了多个值和类型,说明该字符串应该进行切割。
对字符串进行的处理主要体现在比如以下几个方面,以上述四个字符串为例:
以上四个都是直接匹配时无法高度匹配的,在这种情况下,应当处理后再次进行匹配。
q1w2e3:对于这种两种类型的字符串交替过于频繁的,单类型字符串的单元太小,太小的单元往往意味着信息量低,因此对于类型交叉频繁的字符串,可以考虑提取单一类型,重新分割为qwe和123两个片段,然后分别查询预设表,如果二者中有一个高度匹配,那么整体就应当作为单一片段看待;
passw0rd:对于这种,其实本身就与password高度匹配,可以直接查询。不过我们知道password本身是有意义的,这种方式可以通过尝试先建立一张替换表,尝试进行字符串替换,将替换的结果带入预设表查询。
hllsb、20082333:可以进行逆向匹配,分析表中是否有某数据匹配了该字符串的一部分,是否又有数据匹配了字符串的剩余一部分,如果未匹配的部分较少,就可以将未匹配的部分丢弃了。
当然这个只是一个设想,实现起来还是有困难的。
写在最后
任何一个小的点,都可以继续深入下去,使之成为一门学问。
至少我认为,大众密码不仅是有单纯的弱口令问题,虽然目前也有所谓的社会工程学字典,但是字典的生成不该是单纯的信息重组,里面的信息还需要我们认真分析。除了本次的对于大众密码的简单分析,我们往往还需要针对不同群体和不同的个体进行针对性的密码分析,以分析出最接近可能的用户密码。






发表评论
您还未登录,请先登录。
登录