
就像是程序员,运维一样深夜”作案(jiaban)”总会遇到一些奇里古怪的事情,好歹我是经历过“大世面”的人,吓住,不可能的,让我们来数数那些在建设SOC遇到的奇怪事。
目录结构
0x00.关于SOC
0x01.SOC的产生
0x02.SOC开始建设
0x03.SOC稳定运行
0x04.那些奇怪事
0x05.SOC建设全过程
0x06.附录(CheckList)
致谢

0x00.关于SOC
首先,我在这里提到的SOC指的是Security Operation Center,也就是安全运营中心,和网络上说到的SOC安全管理平台不一样,前者是针对一个组织和团队,是一个Team,后者更偏向于一个工具,这是最本质的区别,而安全运营中心里面有一个非常重要的部分就是日志安全,需要对海量日志进行监控,分析,处理,展现等等,而实现这部分操作的架构或者产品,常常被称之为安全管理平台(SOC,我一般把这个叫做/Sao:K/),安全运营中心我一般直接称之为SOC/S:O:C/;本文提到的SOC就是安全运营中心。
所以说安全运营中心究竟是什么?每个公司对于职能都有不同的看法,我这里就简单说说我遇到的SOC:
我的安全运营中心(SOC)是一个团队,一个信息安全团队,建立在一个基本准则之上,负责监督和分析企业的安全状况,处置企业的异常情况,让企业的安全走上正轨,随着技术,业务增长完成安全的更新迭代。SOC团队的目标就是通过技术解决方案和强健的一套流程 检测、分析并且响应网络安全事件。安全运营中心通常充当了安全分析师以及管理者的角色,监督全部安全操作。SOC工作人员同组织结构的事件响应团队紧密合作,确保发现的安全问题迅速得到解决。实际上我们也是事件响应团队的一部分。
安全运营中心监控和分析网络、服务器、终端、数据库、应用、网站和其他的系统,寻找可能代表一个安全事件或者攻击的异常活动。负责确保潜在的安全事件能够被正确识别、分析、防护、调查取证和报告。
0x01.SOC的产生
SOC团队负责的是正在进行的企业信息安全运营组件,是否参与制定安全策略、设计安全架构或者实施保护措施。安全运营中心人员主要包含安全分析人员,安全领导,安全专家等,SOC共同探测、分析和反馈报告,防止网络安全事件发生。如果能够高级取证分析、密码分析以及恶意软件逆向工程,那就最好了。
而SOC的产生大概有这么几个特点:
1.公司以前没有SOC,是运维,加开发,监控几个部门协同一起做一些日常的维护和处理,后来遇到无法处理的安全事件时,开始请求SOC帮助,由于没有SOC,那么就开始组建呗;
2.公司是子公司,或者公司本身就把安全职能部门算入到了创建初期的团队之中,这里就是一开始就建设SOC团队,其实也是在建设企业安全,包括SIEM事件管理体系和ISMS信息安全管理体系。
我的Team应该是属于第2种,我是在一个炎热的夏天去面试,唠嗑,最后有幸加入到了SOC团队,接下来就开展了一系列大刀阔斧的建设。
0x02.SOC开始建设
建立一个组织的SOC的第一步就是清楚地定义包含具体业务的战略目标,且获得全体相关人员的支持。一旦战略开发,基础设施支持这一战略的实现。典型的SOC的基础设施包括防火墙、IPS/ IDS、漏洞检测解决方案、嗅探、安全信息和事件管理(SIEM)系统。技术应该通过数据流、遥测、数据包捕获、syslog和其他方法来收集数据,这样SOC工作人员可以关联和分析数据和活动。安全运营中心也监控网络和端点漏洞以保护敏感数据和符合行业或政府法规。
SOC的关键优势在于通过持续不断的检测分析数据活动,改善了安全事件的检测。通过夜以继日的分析跨组织网络、终端、服务器和数据库的活动,SOC团队确保及时检测和相应安全事件。SOC提供的24/7监控为组织提供了对抗安全事件和入侵的先机,而且无关资源、时间或者攻击类型。
许多安全领导人将更加关注人为因素,而非技术因素,不再依赖一个脚本,而是直接评估和减轻威胁。SOC连续工作管理已知威胁,同时识别新的风险,在风险承受能力范围内满足公司和客户的需求,而防火墙、IPS等技术系统可以防止基本攻击,重大事件上则需要进行人为分析。
为达到最佳效果,SOC必须跟上最新威胁情报,并利用这些信息来改善内部检测和防御机制。SOC消耗的数据来自组织内部和相关信息的外部资源,从而提供洞察威胁和漏洞。这个外部网络情报包括新闻提要、签名更新、事件报告、威胁简报和脆弱性警报,这些都有助于SOC跟上不断发展的网络威胁现状。SOC员工必须为SOC监视工具不断注入威胁情报,保持最新的威胁情报信息,而SOC则必须区分真正的威胁和非威胁。
真正成功的SOC利用安全自动化变得更加有效和高效。通过结合高度娴熟的安全分析师与安全自动化,提高组织分析能力,加强安全措施,更好的防止数据泄露和网络攻击。
1.第一阶段:梳理已有的安全防御,整理相关的安全设备管理权限,整理相关的资产;
这里主要是梳理资产,资产应该包括3大部分:组织架构和人员,基础设施资产,应用系统资产
很好理解,组织架构,人员一般前期主要针对经常关联的那些人员,账户信息,变更审核等等,然后人事变更和人事那边做好联系;基础设施资产主要是硬件服务器,网络设备,安全设备等等;应用系统资产就是业务系统,环境划分与安全域,业务流向。这里没有大多的技术含量,处理的越仔细越详细,越有条理越好。
2.第二阶段:进行全网安全状态分析;
这里主要是针对之前的安全措施进行补充,将不足的安全项进行提交,然后开始在监控,运维,系统管理的协助下,对全网的环境开始进行基线扫描,漏洞扫描,数据分级保护,ISMS体系建设等等。
3.第三阶段:持续监控和应急处置
在全网基线合规,漏洞基本修复和处理的情况下,开始对全网的状态进行严苛监控,一般来说,会涉及账户信息管理:特权账户的使用和通告,非工作时间的登陆审查,;变更管理:审计变更合规与否;IPS,IDS,WAF等安全设备状态监控和日志分析,服务器日志分析,这里就是着重使用SIEM安全信息事件管理平台的地方了,这里一般会用上我之前说的SOC/Sao:k/工具,一般有钱就直接买大型互联网安全厂商的产品和服务,没钱就自建日志分析平台,一般采用的是OSSIM或者ELK日志架构。
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
基本上到这一步,都是对特定的安全需求做精细化处置,开始做安全自动化,不断的调优,然后根据实际情况,反个黑产,反个链接,做点舆情监控,来个威胁模型分析,业务量足够大可以建设一下APT防御,千万别忘记建设安全知识库,不过有些工作还是要从建设初期就开始,就比如自动化和知识库,需要一定的积累才行。
0x03.SOC稳定运行
在SOC建设完之后,基本上整个SOC稳定运行,日志想怎么看就怎么看,这样不够精细咋们就调,账户管理,权限变更,变更审计有条不紊,就该对整套SOC团队建设完成的SIEM安全事件管理系统进行定期的巡检和维护,因为所有的安全监控都是基于这一套安全检测和监控系统,如果系统自身出现了问题,如何区保障监测的可靠性,一般的操作有:
1.巡检,定期的巡检检查SIEM系统的运行情况,比如物理状态,服务情况等等。
2.季度重启,保障SIEM服务器能够满足故障恢复的基本要求。
3.日志存储:定期检查日志保存情况。
此外需要注意的是,如果前期收集日志是一通收,也就是说日志没有做分类,需要后期区进行分类,也就是需要了解你能收到什么类型的日志,然后再SIEM展现的平台做好相关的关联和汇总,越清晰越好,一般来说,按照产品来区分,产品之下再分应用,安全,信息类日志等。
0x04.那些奇怪事
4.1.”时间”幽灵

是日,周五也;Duke看到18点左右,就准备收拾东西回去,下班回家,临走之前将之前其他部门申请的权限及时分配下去,以便周末变更之用。就这样Duke按时的回去了。
时间过的很快,周末眨眼间就没了,周一回来之后,Duke对几个监控频道迅速的review,主要是针对特权账户登陆,非工作时间登陆,主频道(高危事件),活动频道(一般事件),查看的时间是从上周五9点-这周一9点,Duke快速review中,忽然,他发现,在特权账户登陆和非工作时间登陆中出现几条鲜红的事件:
20171215 03:34 路人甲 login 192.168.1.1 root 192.168.7.1 ….
20171215 04:10 路人甲 login 192.168.1.1 root 192.168.7.1 ….
20171215 04:22 路人甲 login 192.168.1.1 root 192.168.7.1 ….
Duke瞬间觉得不对劲了,立马咨询了一下周五变更的小伙伴,然后他们都说周五9点左右就离开了,变更早就做完了(一点都不按套路出牌,说好的周末变更);然后Duke就觉得是不是机器被黑了,我的天,然后他开始去查历史登陆记录,last发现在192.168.7.1上发现了上面三个登陆事件,而且都是一个地址,终端,登陆账号的确是root,然后他去查近期的root所有的操作,查看了root的.bash_history发现了一些操作,然后从堡垒机进行进一步的操作分析,发现当时的操作并没有什么不对,都是一些重启服务,打包文件的操作,重启服务?
Duke查看了crontab和checklist
crontab -u <-l, -r, -e>
然后Duke又查看了几个可疑进程:
for pid in $(pgrep进程名称); do echo -n "${pid} " ; ps -p ${pid} -o lstart | grep -v "START" ; done
再查看了几个进程的启动时间:
for pid in $(pgrep async); do echo -n "${pid} " ; ps -p ${pid} -o lstart | grep -v "START" ; done
最后查看了进程的关联IP:
netstat -anp | grep进程ID
没毛病啊,老铁,Duke有点拿这3条事件没办法,但是它的颜色是那么的鲜红,然后他又去堡垒机查看了一下操作录屏,然后,他发现,堡垒机录屏的事件分别是19:34;20:10;20:22;
唉,这个时间好像对的上,然后那这个时间去咨询了一下运维和监控的小伙伴,确定变更时间,的确是这三个时间,那问题是?
服务器的时钟可能没有同步,所以产生的日志源有问题,Duke立马去查看了192.168.7.1的时间,果然,现在的时间比真实时间慢了14h,我的天,然后直接和系统管理员联系,通过NTP对所有的服务器的时间进行同步了。
总结:不论是平时的业务还是办公,或者是SIEM建设,日志和攻防的基础都是时间差,也就是说,时间越同步越精确,你的事件处理越准确越高效。
4.2.死灰复燃的亡魂
Scott大哥来到监控室,悄摸摸的对我们说:
“等会下班有事么?”
“没啊?哥,请吃饭?”
“吃啥啊?服务器中勒索病毒了,快来看!”
“这么新奇?我都没见过中病毒的服务器欸,我要看”
“。。。。。。”

就这样我们下班留了下来,留下来的Duke和Felix看着Feng大佬和其他大佬们,然后我们小脑袋不断的思考,这特么啥玩意,我得看看。
然后,Duke对邮箱地址做了检索,然后去查找最近勒索病毒的一些公告,最后发现,这尼玛好像可以挖矿
“哥,这玩意好像可以挖矿诶?”
“就你话多”
“。。。”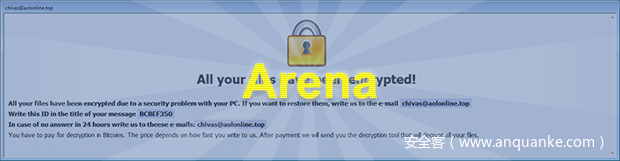
Duke查了一下,发现这病毒叫Arena,中文名叫艾瑞娜,好名字,不得不说,然后我们发现了一些东西:Trojan.Gen.2和PUBA.Bitcoinmine病毒,其实一开始我就看成了PUBG挖矿病毒了,嘿嘿嘿,然后进一步查看安全日志和预警信息,发现在C盘还有这玩意:Heur.AdvML.B病毒,路径在user账户appdataroamingmicrosoftwindowsstart,啥都别说了,先干掉这些玩意,然后我建议看下任务管理器,我也觉得这是个好主意:
“占用率不错啊,70%了”
( ̄▽ ̄)”
发现这病毒还通过OneDrive传输文件出去,然后我们发现了一个国外的IP,再查查,看看这个撒比(dalao)还干了啥。然后发现账户区域多了一个奇怪的账户,这里我们可以创建一个类似的账户以便去以假乱真,然后还等着干嘛,干掉那个新账户,接着我们发现最早是一个普通账户,我们把他叫做Disco吧(普通的Disco);出现了异常登陆,登陆地址是美国,
“我们有美国的子公司么?”
“瞎说,不存在的”
“那这个?”
“干掉”
然后我们把病毒处理了,中毒机器的账户密码改了,系统还原了,处理完就回去了。
若干天后(一个礼拜左右吧)
微信传来了一个消息:
“192.168.1.1服务器状态满了”
“这么厉害的吗?我看看”,“卧槽,真满了”,”机器应该是闲着没事做,挖矿了“
”就你话多“
然后我还能怎样?我还怎么样?排查呗,然后经过大佬Feng和我们的排查发现,又是那个普通的Disco在普通的挖矿,哎哟,( ̄y▽, ̄)╭ ,你还死灰复燃了,不对,这次好像换了个机器=。=
我去,这不是机器漏洞,这是弱口令啊。
”对“
”对的“
然后我们又给机器来了一套全面按摩(检查),检查完,发现,账户没有新建,然后就是在挖矿,也没有勒索我(这次低调了),然后OneDrive泥煤还是开着的,然后我们就干掉了它,还原镜像,然后我说:
”要不我们把所有账户全部统计一下,然后把Disco都重置了?“
”工作量有点大“
”=。=“
”搞呗“
就这样,我们把整个区域的Disco全部干掉了,你说你是Disco我会爱你么?干掉。不存在的
总结:账户管理要到位,所有的账户必须通过堡垒机进行管控,特权账户必须申请,审批后授予,然后需要及时收回,同时对操作要按时做审计,最后弱口令一点要干掉。偷偷告诉你们我见过的一些弱口令啊:
1qaz@WSX,qwer1234,1qaz@WSX#EDC,什么嘛,当我没有字典嘛,分分钟给你爆了
4.3.你的能量超乎你的想象
”Duke,去吧SIEM重装一下,然后写一份手册“
”OjbK“
然后我就找包,拷贝,上传,一气呵成,准备开始我的丰功伟业:重装SIEM,并记录过程。
唉,开始呗,在这之间我遇到好多事情的,我跟你们说,最奇葩的在后面
我兴奋的拿着我root账户,噼里啪啦一梭子下去,配置?不存在的,直接回车,然后提示我:
ulimit too small,然后建议我改成4096
然后继续操作,回车到最后设置一个登陆账户,我设置完了后,准备去检查一下我可爱的服务,然后我进入到了/etc/init.d 啥,你告诉我没有这个服务,然后我只能打开我那些user config book啊,然后我找了好久都没有找到相关的故障报错的信息。
我想,我可能需要再来一次,然后我删除了组件,重新开始了安装,然后我发现最上面有一对小字:please install tools through Disco,啊哈?啥,用普通用户啊
我只好用Disco再来一遍,果然,服务起来了
后来我去检查了一下,我们可爱的SIEM(外国血统哦)需要使用普通用户创建服务,这样服务才能创建成功,那是不是root就不行了,不是,只是root不是默认的,我在最后面又看到了一排小字:
if you use root install as service,please run this command:
玛耶,你这不是刁难我胖虎近视么。
总结:有的时候你发现你的权限过大,这其实并不是一件好事,需要的时候再去获取或许是个更好的选择,因为权限过大也可能会出事,另外就是,别忽略小字
4.4百鬼夜行

夜半时分,为何蜜罐Honey会出现在其他区域,深夜十分,Honey为何不洗洗睡呢,要想知道为何Honey夜晚熬夜修仙,请慢慢看下去。欢迎准时收听:百鬼夜行—蜜罐
正文:
夜晚凌晨3点整,Felix正在梦乡,SZ夜晚的星空是那么的明媚,天空有几朵云朵飘荡着,夜猫子般的没有散去,可能正是应了一句话:月黑风高杀人夜,当然,这里没有命案;
一个浑身漆黑的影子在服务器A区域(安全域A)起来了,这么晚了,Honeypot小姐姐还没有睡,她神情麻木的游荡着,用简单一些的话来说,她梦游了,要叫醒他么?
A.叫醒
B.不叫醒
C.你就是一叙事人,叫啥叫
我当然是选择C啦,这么晚不睡,等着猝死吧。HoneyPot,简称Honey,我们Honey依然没有察觉自己在梦游,她仿佛很开心,一会儿在通往服务器B区域(安全域B,简称B区)瞧瞧,一会儿在C区瞧瞧,飘过来,飘过去的。然后Honey不知道从哪哪来的钥匙,开始去打开B,C甚至D,E等其他区域的门,门牌上写着445,有的可能写着443,有的可能写着135,138啥的,总之,Honey去开门了,开门?我又不在,开门干啥,肯定不是迎接我。
然后Honey打开了B区的门,打开了C区的门,D区的,E区的,能打开的都打开了,然后我明白了,她嫌弃我A区的空间太小了,然后从A跑到B,然后跑到C,就这样跑了一个晚上,不知道Honey累不累,反正我累的睡着了。
第二天早上,Felix来到办公室后,发现Honey有去过B,C,D,E等区域的痕迹(日志),立马对Honey进行了检查,彻彻底底的检查(算了,不开车);最后发现,Honey吃了毒苹果(中毒),然后神志不清的实现了内网漫游,中毒的Honey来了一次说走就走,还是熬夜的旅行,后来Honey飞升了
总结:中毒区域及时隔离,能恢复就回复,不能回复的想办法恢复,低权限可以暴力重装,蜜罐规则和机制要把控好,一些高危端口别开放,访问控制和规则要严谨,最后做好日志监控和相应的备份,顺便提一下,蜜罐玩不好还是要节制,不然责任基本上都是在你。
0x05.SOC建设全过程
这里我就SOC建设整体思维,以三个阶段的形式展现一下,也类似于“规划,建设,运维”的三个阶段。但这是笔者的SOC经历,每个人经历的可能不一样,也就是说,说不定你就是过去做最后一个阶段,或者在每个阶段的比重都有所不同,毕竟一切都应以实际情况出发。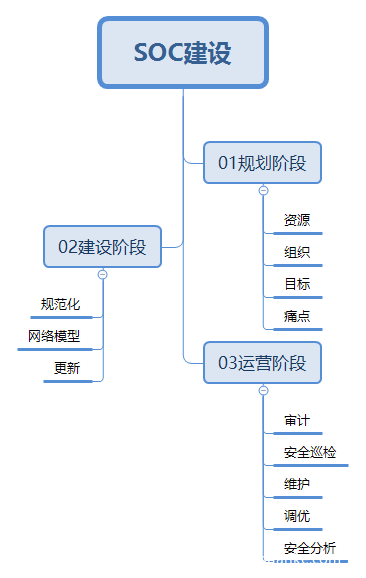
第一个阶段:规划
我一直都很坚信一句话:凡事预则立,不预则废;凡是预而立,尽在于心;
一个好的系统应该都有一份详细的规划和架构方案,一个好的SOC运营方案也应该是有详细的筹划和准备的,那么再规划阶段应该考虑一些什么东西呢?
1.资源
首先你要知道你的SOC运营中心有哪些支持的资源,这里提到的是工具或者辅助类的系统,一般来说支撑SOC运营中心的工具主要就是日志监控平台SOC/sao:k/,和其他的IPS,IDS,WAF,FW,终端管理,堡垒机,防病毒的安全设备等
其次,你可能需要一些进行测试和分析的服务器,一般用来按环境部署扫描器和用来镜像一些环境,还原测试
最后,你需要大量的日志,尽可能按照一级:环境分类,二级:设备,三级:日志类型,做到能够满足编写日志监控规则的要求即可,不用太详细,会带来不必要的工作量
备注:你可能还需要一些服务器的临时权限,一般用于对服务器进行检查和溯源分析等等
2.组织
我所在的公司SOC是一级部门,所以会比较注重安全,但并不是所有的企业都是特别注重安全,所以你需要去调整一个自身的位置,其实公司重视安全并不意味着你就可以强势,很多时候,决策是需要互相理解的,所以你需要知道你进行安全运营的时候,你所基础的那些部门会有哪些,一般来说会涉及到:监控,运维,业务,应用,基础设施以及OA部门,你们之间处理相关事件会不断的交流,另外还有一层组织就是领导部门,一般来说到部门的负责人是SOC工程师的顶端,至于再往上通过你的上级Leader再往上协调即可
3.目标
咋门既然要建设SOC运营中心,去监控整个企业的安全状态,那就得知道我们的目标,一般来说会有一些很简单的目标
a.运维权限的监控,目标不是针对运维组,而是排除他们的嫌疑,去分析异常登陆
b.账户权限的监控,和a有点像,一般来说是针对账户资源的
c.日志监控,监控所有的安全设备,系统,网络的日志即可,至于数据库业务那种,自己看着办,反正安全设备,系统,网络就基本上够吃一套了
e.变更审计,不是说你申请了变更就可以瞎搞,所以你需要对变更做一些详细的分析和判断
那么以上分别对应的资源就是:运维监控堡垒机权限,账户管理权限,日志服务器权限,变更审计权限
4.痛点
并不是所有的SOC都是从头开始建设,有的可能已经存在一段时间了,而恰好在某个时间段需要你就救火,这里的痛点指的就是企业当前迫于眉睫,亟待解决的安全问题
比如说你的员工上网行为不规范,经常不小心打通了内网,再比如你的员工把文件传输出去了,在或者离职的员工没有做好管理,出现了风险,甚至你的企业被勒索病毒烦恼,APT攻击缠绕,等等,都需要你去不断的收集上级领导,员工的安全需求,以及你自己发现的一些安全漏洞
第二个阶段:建设
建设实际上是在你知道自己想要把安全做到什么程度之后准备开始实施的阶段,这个阶段是凸显一个安全工程师底蕴的时刻,你得有足够丰富的系统经验去部署你的SOC,足够支持解决企业安全风险的安全知识,以及基本的网络通信等等,这些都是一个在对企业建设安全需要使用的一些部分,建设其实有点像架构好你的SOC监控平台的结构,然后安装,配置,调试,这类工作我就不做赘述,提一下我在建设过程的一些技巧吧。
1.资产规范很重要
你必须把你的资产严格按照你们内部定义或者集团定义的一套标准进行命名,在这里我把这个过程叫做资产建模,80%的企业的资产命名会出现一些差异,而建模的目标就是让所有的资产处于一种绝对标准化的命名,这样的优势是什么?有助于排查和分析,溯源,至于资产统一后的结果是如何的,一般按照具体的需求进行命名即可,但是要注意这里的资产,可以分享给基础设施,但并不建议强行推给他们,这会造成对方的工作负担,只有适合自己的才是最好的资产规范,我这里采用的是环境_应用名_IP的方式进行命名
例如:UAT_Test_192.168.1.1
最后注意的是,资产以IP为粒度,一个IP一个资产
2.网络结构
或许你们有网络架构师在对你们的网络做架构,这部分不需要太担心,网络架构基本上会负责基本的隔离要求,你可以考虑一些部署安全产品的位置以及补充一些安全防护手段,但这不是我要说的重点,这里的网络结构是网络区域的严格区分,主要是针对每个区域进行相应的命名,一般是使用英文进行规范,命名不要太长,也不用太洋气,内部看得懂就行
3.更新
更新主要是针对账户,资产,以及日志接入的更新,因为账户,资产在后续可能会增加,所以这里可以采用资产管理系统,或者定时的手动去咨询资产和账户情况,日志接入的更新一般都是在掌控中的,因为需要SOC团队和基础部门做日志的调试,参与其中
第三阶段:运营
当你的SOC日志监控平台搭建完毕,稳定运行的时候,就要考虑一些基础的运营内容
1.审计
审计账户的使用情况,审计资源的分配情况,审计变更的执行情况
2.巡检
定期对服务器,网络做巡检,主要是安全类型的巡检,就是基线和漏洞部分,这里可以加入漏洞管理,定期扫描和追踪漏洞修复情况
3.维护
对SOC监控平台做定期的巡检,这里是安全和系统的巡检,季度的重启
4调优
SOC监控平台建设完毕之后不可能是直接完美无缺的,所以需要不断地调整,这里你可以优化规则,可以优化日志,总之监控预警怎么直观怎么做
5.安全分析
这里一般来说是针对安全事件,比如企业遭到了攻击,或者出现了异常的事件预警,这里需要及时去处理和溯源,然后这里补充一个我在尝试去做到一个东西:威胁建模,可能是资产建模,网络建模产生的奇葩想法,。
威胁建模,用于对外部威胁的汇总,这里前期考虑的是通用安全威胁,其实有点像风险建模,然后以图形的方式去汇总整个威胁图,这个拓扑图实际上就是按类威胁汇总,图形化显示,然后中间可以加上防护措施,和备注一下缺陷和可能存在的优化点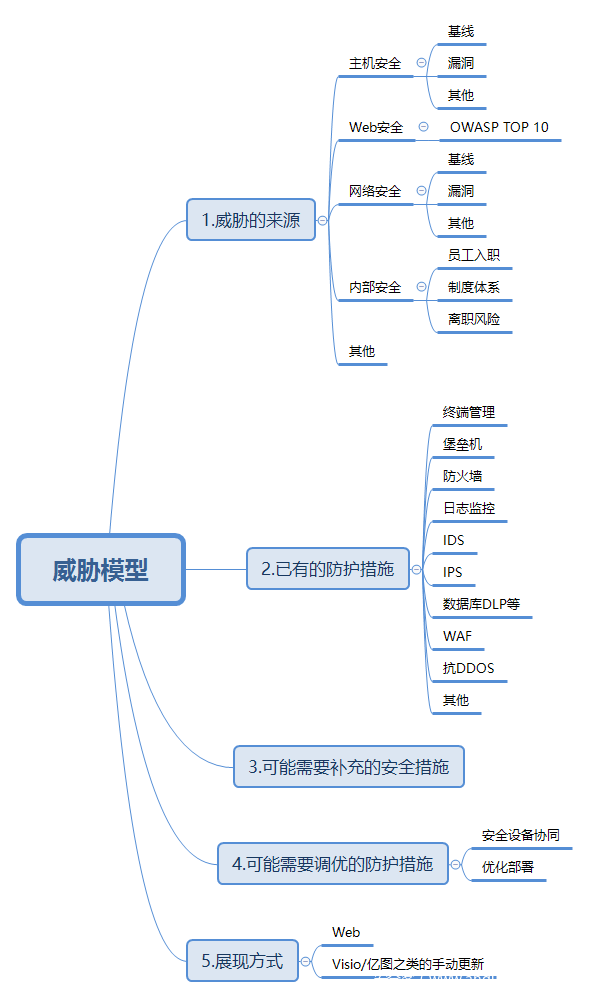
0x06.附录(CheckList)
一个互联网企业在建设SOC过程中应该考虑的一些点,可能会缺一些东西,欢迎补充
1.网络安全
安全措施:
防火墙
IPS
IDS
网络设备ACL
可能出现的安全威胁:
访问控制规则过于松散:主要是any-any,另外大网段的网络控制策略
流量监控
2.系统安全
安全措施:
基线扫描
Nessus扫描以及补丁修复
漏洞管理
可能出现的安全威胁:
漏洞得不到及时修复和跟进
3.资产安全
安全措施:
资产管理
堡垒机
Symantec Endpoint Protection Manager
针对Web的AWVS
针对操作系统的Nessus
针对数据库的Nessus基线扫描
针对Port的Nmap,后续可能需要Masscan(IPV6)
可能出现的安全威胁:
漏洞管理:漏洞及时追踪和更新,以及补丁修复情况追踪
资产安全度:资产安全程度监控,以及实时汇总和修复(类似云镜,目前PRD,DR,UAT暂无)
专门针对数据库的DBscan漏洞扫描
针对APP安全的MobSF扫描
建议:
对接CNNVD漏洞库
风险监控:巡风
漏洞自查:定期自查,汇总
漏洞管理流程(包括漏洞发现,漏洞修复)
接入DBscan(需要详细评估)
接入MobSF
4.终端
安全措施:
终端管理
可能出现的安全威胁:
终端漏洞造成办公区域甚至其他区域门户大开
5.人员安全
安全措施:
离职人员账号管控
安全意识培训
安全技术培训
可能出现的安全威胁:
安全审计培训:相关流程
开发,运维安全培训
6.邮件安全
安全措施:
邮件安全网关
防病毒
可能出现的安全威胁:
社工,APT攻击
7.APT防护
安全措施:
APT攻击防护:SIEM/SOC
应急响应
蜜罐
8.Web安全
安全措施
AWVS扫描
渗透测试
代码审计
DNS服务器防护
域名防护
可能出现的安全威胁
风险,威胁修复
API接口
中间件容器安全
9.运维安全
安全措施
权限管理
账户管理
变更审计
上传下载文档审计,记录
自动化运维:Puppet,Salt Stack
DevSecOps
10.告警安全
安全措施
邮件通知
短信通知
可能存在的安全措施
未涉及所有的基础设施
告警有效性
通知内容
通知人员清单更新
通知实时性
总结一下:
SOC是我这些年来比较钟爱的一个Team,从无到有,从一开始的规划,到后来的稳定运行,就像是看到了自己的孩子成长一样,收获了许多,最后我希望她能够茁壮成长。
致谢
感谢我的SOC Leader,Teamates
感谢辉哥,锋哥,刘哥
感谢Felix的Honey蜜罐







发表评论
您还未登录,请先登录。
登录