

Abstract+Introduction
本文作者提出了IRQDebloat,通过自动硬件重写来禁用不需要的硬件功能。本文基于以下观点:系统的外部输入大多是通过interrupt requests(IRQs)来进行传递的,IRQDebloat系统地探索了目标固件中的中断处理代码,识别出针对每个外设的处理函数,最终重写固件来禁用对应着不需要的硬件功能的函数。
Key insight: 来自驱动代码的攻击面在大多数情况下只能被经由硬件中断的外部输入触发。因此通过找到系统中的interrupt handlers,将他们与硬件功能相匹配,然后通过固件重写禁用掉不需要的功能,可以有效的关闭外部世界中的攻击面。
主要流程: IRPDebloat根据真是的嵌入式设备拍摄CPU于内存的快照,然后将快照迁移到模拟器PANDA中,然后通过一个顶层的终端处理器(a top-level interrupt handler)来系统的探索不同路径。收集到trace之后,使用differential slicing技术来准确地定位系统中针对每个外设的处理程序。最终对真是设备中的处理程序进行插桩,并将其替换为一些简单的返回函数。
应用: 两种CPU架构ARM、MIPS,四种操作系统Linux、FreeBSD、VxWorks、RiscOS,七种嵌入式SoC平台
BACKGROUND
Interrupts
interrupt来自硬件外设,并造成异步的控制流转移,转移给interrupt handler,这是用来为中断服务的函数。Interrupt handler 然后与发出中断的外设进行通信,处理外设挂起的I/O请求,最终acknowledge中断,然后结束。
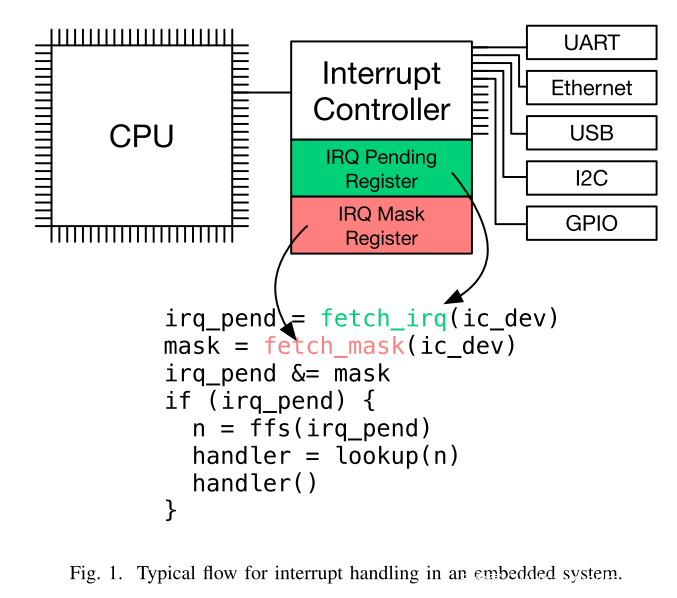
上图所示为嵌入式系统中的IRQ handling的例子,过程如下:
- 外设发起中断,中断控制器将中断号存储在MM寄存器中的bitset中的一个比特,然后再由其向CPU发送中断信号。
- CPU响应中断,跳转到架构定义的顶层的中断处理器中。
- 中断处理器而后从中断控制器中检索中断号,并使用它为特定的外设调度处理程序。
- 这个与外设对应的处理程序使用MMIO处理外设的I/O请求,最终acknowledge这个中断。
Execution Indexing
本文中找到中断处理函数的trace analysis依赖于execution indexing,一种用于对齐程序路径对的技术,标记出他们的分叉点以及重新聚合点(diverge and reconverge)。相比于一些路径中的小的分叉,更应当关注路径中大的分叉点。
工作原理:Execution index(EI)再执行中独一无二的识别出一个点,使其能够跨不同的执行路径进行比较。它使用一种栈数据结构,能够定义代码中基本块的执行上下文,比如在这个基本块到达之前触发了多少条件分支。当遇到新的的代码上下文时,比如遇到了函数调用或者条件分支,EI将其地址以及immediate post-dominator的位置压进stack内。因为根据定义,immediate post-dominator是从当前基本块出去必须经过的路径中最早的节点,它定义了执行上下文的终点。当trace中的栈顶的immediate post-dominator被触发,就将stack顶pop。
为了比较两个trace,EI假设他们最初是对齐的,两个trace都对应着空的EI stack。然后串联的沿着两条trace进行探索,同时更新EI stack,当EI stack出现不同时,算法将其标记为控制流分叉,打印分叉点,然后进入未对齐状态(disalignment state)。在此之后将设偏离的trace已经进入了嵌套的上下文中,造成了EI stack增长,算法通过探索EI stack更大的trace来尝试重新对齐路径,直到两个EI stack再次一致,在此点认为trace被重新对齐。
Assumptions and Usage Scenarios
- 分析者能够得到物理设备用于分析。
- 分析者能够为设备更新新的、修改过的固件。
- 分析者能够获取设备在运行态时的CPU和内存快照。
有了上述条件本文工作即可使用设备中的CPU和内存状态在软件模拟器中恢复执行,并通过fuzzing模拟中断控制器的MM寄存器来探索经过中断处理代码的路径。
DESIGN
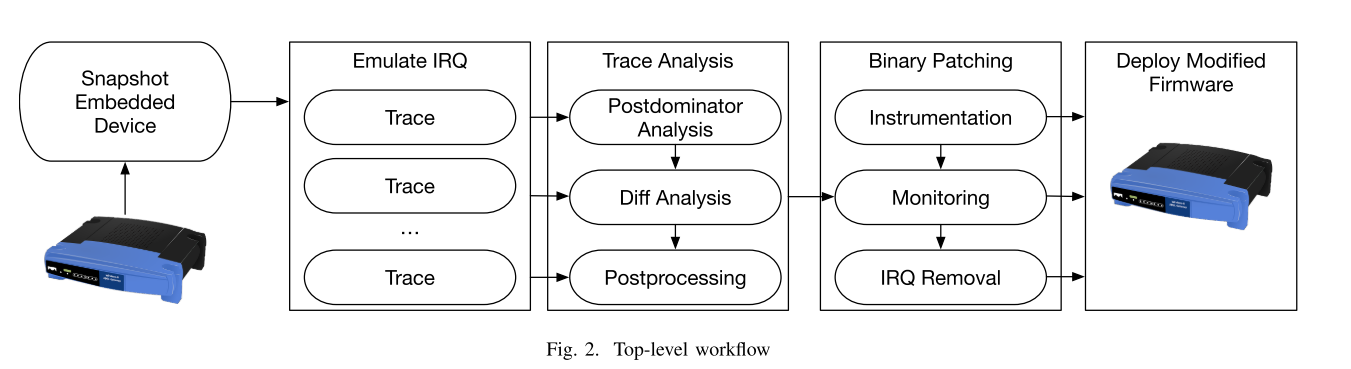
下图所示未系统流程图,首先获取设备运行态的快照,然后将其迁移到全系统模拟器PANDA中,紧接着在PANDA中触发中断、并通过fuzz MMIO寄存器来收集trace;进而为了发现中断处理程序,使用differential slicing分析收集到的trace;然后可以将固件中有关handler的功能替换为无功能函数,使其忽略外设的输入,以此来禁用相关功能。
一旦候选处理函数被识别以后,可以通过以下消除过程来识别不需要的功能:首先一个一个的禁用相关功能,然后启动设备,查看对应不需要的功能是否被禁用;当对应外设的处理函数被识别和禁用之后,来自外设驱动代码的攻击面将会被关闭。
Challenges
Hardware Diversity
每个中断控制器都能够实现其自身的协议,所以工作必须对特定的终端控制硬件没有先验知识的,所以作者开发了启发式规则来确定何时能够判断中断处理过程中结果,来允许fuzzing进一步进行探索。
Binary Analysis
中断处理程序中往往涉及了函数指针、嵌套循环以及链表函数,对于自动化二进制静态分析造成了困难,因此作者使用动态分析过程中的信息作为辅助,来加强静态分析的效果。
Fuzzing Challenges
根据固件中断处理的特点,开发出对应的fuzzing框架。
Snapshot Collection
本文原型使用JTAG、QEMU(如果没有对于目标架构的支持)、或者是运行在设备上的代码来收集快照。
Trace Collection
在快照加载到PANDA中,收集中断触发的trace,中断会使得模拟的CPU切换到IRQ mode,并跳转到架构定义的、中断处理的入口点。在此开始,开始打印经过的每个基本快的首地址。当固件读取来自RAM之外的内存地址时,会喂给一个fuzzd MMIO value。在收集完成trace之后,将会重置模拟器状态,并且尝试其他的fuzzing MMIO序列的值。
此过程需要面临的苦难就是如何中断一个执行过程的tracing,显然,需要使得trace足够长能够用来获取针对某个特殊IRQ的处理过程,并且需要尽可能地短用来提高fuzzing性能。作者采用的解决方案是,在模拟器中执行完毕10个基本快序列之后,即可acknowledge中断。
IRQ Fuzzing
Trace Preprocessing
在收集到的trace中包含较多的错误处理代码以及调试信息,所以有必要去除噪音,主要通过两种方式:
- 尝试识别来自fuzzing的与中断处理有关的I/O序列的子集。
- 通过计算trace中经过的基本块地址序列的哈希值,来消除重复trace。
Postdominator Computation: 利用immediate postdominator来加强trace的信息,所以trae中每个基本块的地址就为一个信息对(addr,ipdom)。为了解决二进制分析不精确的情况,使用trace中的地址来指导反汇编。在很多情况下,反汇编器会遗失函数中的部分基本块,因此本工作将CFG转换为sub-CFG,同时计算sub-CFG的immediate postdominators。
QEMU中的translation blocks和静态分析中的BB不一致,qemu中的translation block是以分支或者call指令结束的线性代码,而CFG中的BB将会进一步切割,因为连接基本块内部的边是不被允许的。
为了解决这个问题,在trace的重分析过程中检查丢失的BB:对于trace中的每个地址,交叉检查当前地址结束的下个地址,当前基本块的出边(outgoing ledge),以及trace中的下一个地址;来确定是否需要将translation block进一步分割为正确的BB,如果需要的话,就为对应的BB起点创建一个trace entry。
Trace Analysis
采用了differential slicing中的trace alignment算法(基于execution indexing)来分析收集到的trace,最终推断出不同的IRQ处理过程。由于所有的IRQ interrupt拥有相同的入口点,他们共享相同的trace前序,并在某特殊点进入不同的状态。所以通过比较来自fuzzing过程中的trace对,最终能够找到所有IRQ的分叉点。
Instrumentation
通过重写固件中的中断处理代码未无用函数来禁用相关中断处理过程,首先将处理函数的虚拟地址转换为物理地址,然后,对于每个patch点,提取出其物理地址附近的数据来形成签名。然后使用这个签名,在内核中搜寻以找到匹配的偏移,最终可以静态的对齐插桩。
如何对固件修改以绕过硬件签名等问题不是本文所需要解决的内容。
Manual Efforts
- 需要人工来获取设备快照,并且重新对设备刷新快照。对于每一个快照花费几小时到几天时间不等。
- 需要人工判断是否已经成功patch掉不需要的硬件功能。
- 需要人工逆向来决定patch 中断函数为无用函数的返回值为多少。







发表评论
您还未登录,请先登录。
登录