

零、 前言
- 先前做CTF时对于算法识别插件一直颇有微词,一方面是Linux下没有合适的,第二个是算法识别插件大部分只针对一个特定的常量数组进行识别。由于在CTF的逆向中我们需要的是找到加密的主函数,所以我尝试结合了yara的识别原理,通过对常量数组的引用的查找,一步步递归构建调用树。调用树根部就是可能的密码算法主函数。
- 由于这种办法需要常量分布于算法的各个步骤中,所以我尝试选取了DES算法
一、DES算法识别的主要流程
1.1 背景介绍
- 密码学算法识别在很早之前就已经有成熟的实现。我遇到过的实现有如下几种:
- 对于内嵌的代码,典型的有PEiD的KryptoAnalyzer插件。原理很简单,一般的密码学算法都有特定的常量数组,例如MD5的state(0123456789ABCDEFFE…10),DES的P_Box等等。找到该算法的一个常量数组就可以判定存在该密码学算法。
- 对于使用第三方库,典型的有使用IDA的FILRT签名的快速识别,将常见的密码学库做成签名。那么调用的这个第三方库的所有加密函数都会被识别。
- 这篇文章主要讨论了第一种算法的实现与优化(因为KryptoAnalyzer只针对Windows平台,所以该算法实现对于辅助elf文件分析是有意义的)。
1.2 实现原理
- 对于第一种算法,以KryptoAnalyzer为例,它只会给出一个p_box识别的位置以及调用该常量的位置
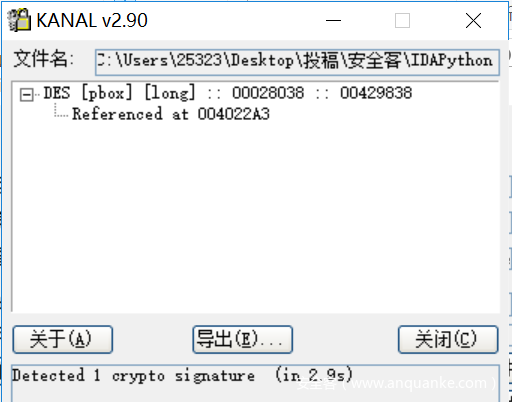
- 而事实上例如DES之类的算法存在非常多的常量,我们完全可以尝试根据这些常量的位置,调用关系构建调用树,最终找到可能的主函数。例如常量const1,const2,const3被addr1,addr2,addr3处的代码引用,这三处代码分别属于func1,func2,func3,而三个函数调用关系为func3调用func2,func1,我们可以根据常量、调用常量的位置(所属函数)以及调用这些调用常量的函数的函数构建关系图,最终找到可能的主函数func3。
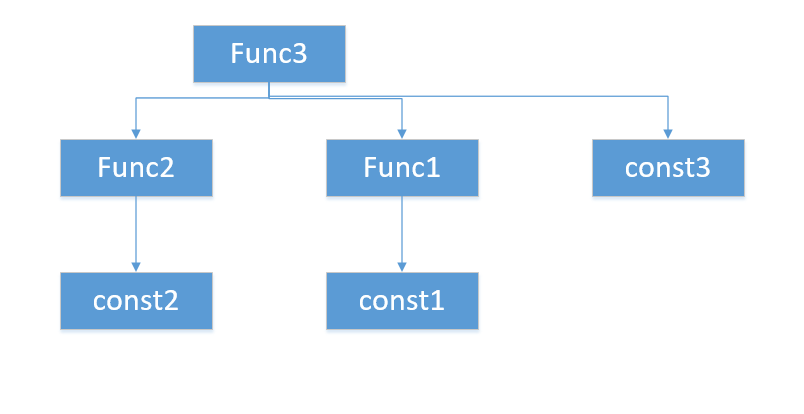
1.3 实现流程
- 那么我们的实现流程如下:
- 选择需要的常量
- 查找各个常量所在位置
- 查找引用各个常量的代码地址,查找这些地址所属函数,以及调用这些函数的地址以及其所属函数,构建调用树
1.4 思路局限性
- 当前思路由于需要大量常量,所以目前只适用于常量较多且分布于算法实现各个步骤的算法,因此本次实现选择了DES。
- 另外,即使构建了调用树,也无法百分百确定这个调用树的根就是算法的主函数,例如根为func,则主函数有可能是调用func的func1,需要使用者自行动态调试判断。且存在算法被篡改的可能性,此时就需要具体分析以寻找被篡改部分了。
- 需要注意的是,验证过程中注意输入类型,输入类型可能是一个String格式,有可能是自定义类型,一切需要具体情况具体分析。
二、DES算法
2.1 DES算法简介
- DES算法为密码体制中的对称密码体制,又被称为美国数据加密标准。
- DES是一个分组加密算法,典型的DES以64位为分组对数据加密,加密和解密用的是同一个算法。
- 密钥长64位,密钥事实上是56位参与DES运算(第8、16、24、32、40、48、56、64位是校验位,使得每个密钥都有奇数个1),分组后的明文组和56位的密钥按位替代或交换的方法形成密文组。
- 对于DES算法,我将其简单分为两大部分:秘钥处理部分和密文加密部分
1.2 秘钥处理流程
- 第一步是秘钥初始变换,输入的秘钥按照下文的常量表来完成一个变换
initial_key_permutaion= [57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4];
- 之后变换完输出的秘钥拆分成左右两部分C0与D0,C0与D0按照下表分别进行移位
key_shift_sizes=[-1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1];
- 移位完成后得到16个左右变换后的子秘钥C0-C15,D0-D15,将C0与D0,C1与D1…Ci与Di合并,按照下表压缩
sub_key_permutation= [14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32];
- 这样我们得到的16个结果就是最终需要的16个子秘钥。
- 最终用伪代码阐释一遍流程
# 秘钥初始变换,输出结果拆分为C0,D0
C[0],D[0]=initial_key_permutaion(key)
# 移位
for i in range(2,16):
C[i+1]=key_shift_mov(C[i])
D[i+1]=key_shift_mov(D[i])
# 压缩取得子秘钥
for i in range(16):
subkey[i]=sub_key_permutation(C[i],D[i])
2.3 密文处理流程
- 首先我们扩充密文到64位
sub_key_permutation= [14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32]
- 之后我们将输出结果拆分为左右两部分L0与R0,进行16轮运算
- 第一步是使用下表扩展Ri
message_expansion = [32, 1, 2, 3, 4, 5,
4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13,
12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21,
20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29,
28, 29, 30, 31, 32, 1];
- 之后引入子秘钥$subkey[i]$,与扩展后的Ri进行异或运算
- 之后将异或结果拆分为$8*6$bit分组,每个分组用下面S盒变换后组合
S1 = [14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13];
S2 = [15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9];
S3 = [10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12];
S4 = [ 7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14];
S5 = [ 2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3];
S6 = [12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13];
S7 = [ 4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12];
S8 = [13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11];
- 最终将8个s盒输出重新组合,输入下表处理
right_sub_message_permutation = [16, 7, 20, 21,
29, 12, 28, 17,
1, 15, 23, 26,
5, 18, 31, 10,
2, 8, 24, 14,
32, 27, 3, 9,
19, 13, 30, 6,
22, 11, 4, 25];
- 最终输出的就是Li+1,也就是说将Ri进行三个变换后作为下一轮Li+1输入
- 经过16轮运算后,将最终的L15与R15组合,进行一次置换
final_message_permutation = [40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25];
- 用伪代码阐释一下
# 初始置换
L[0],R[0]=sub_key_permutation(plaintext)
# 16轮循环处理
for i in range(16):
# message_expansion扩展
exp_r=message_expansion(Ri)
# 与子秘钥异或
xor_r=exp_r^subkey[i]
# S盒变换
s_r=S[xor_r]
# 处理S盒输出
L[i+1]=right_sub_message_permutation(s_r)
R[i+1]=L[i]
# 最终逆变换
final_message_permutation(L[15],R[15])
三、常量查找
- 在第一部分的DES算法简介中,我们已经了解了DES算法中涉及到的所有常量。那么我们接下来就是在IDA中查找对应的数据了。
3.1 为什么是IDA Python
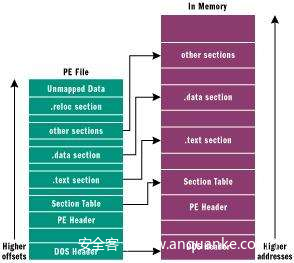
- 在这边我们首先要搞明白一个虚拟内存和磁盘的概念。一般我们的可执行文件在操作系统中是以文件形式存在的,也就是存储在磁盘中。而运行时操作系统会将其装载到虚拟内存中(真正执行还需要装载到物理内存中,但与本文无关,此处也不做讨论)。在虚拟内存和磁盘中文件内容是不变的,但是占用大小发生了改变。如下图:
![PE内存映射]()
- 最主要的改变就是对齐大小发生改变。原先在磁盘中每个区会被补全为$FileAligmnetn$大小,而在内存中则补全为$SectionAlignmentn$的大小(n为正整数)。因此我们可以在磁盘中以文件形式读取可执行文件查找,但是查找到的常量位置是文件偏移。需要转换为虚拟内存地址后才能使用。
- 而在IDA中,可执行文件直接按照内存中的排列显示。因此省去了转换虚拟内存地址的过程。
- 此外,我们需要查找引用这些常量的代码地址,因此我们需要使用到IDA的查找交叉引用过程,这个是IDA的一个非常强大的功能,能够定位所有显式调用的代码地址。(例如 call 0x401000就是显示调用,而call eax,eax=0x401000则无法在静态分析中得到)
- IDA Python并非IDA的原生脚本语言,但是IDA Python支持所有IDA原生语言idc的特性,并且可以使用所有Python 2的库(建议添加系统路径):
# 此处是系统中的Python2 的sys.path
syspaths=[]
import sys
for pa in syspaths:
if pa not in sys.path:
sys.path.append(pa)
- 关于IDA python的基础知识,此处就不再赘述了,有兴趣的可以找一下IDA Python-Book的文档查看一下
3.2 确定查找范围
- 对于查找范围,简单粗暴的办法就是用MinEA()到MaxEA(),也就是最小的虚拟地址到最大的虚拟地址。不过这种方法效率不是很高,而且存在误报风险。
- 一般常量存放在.rdata段,也有少量在.data段,因此搜索两个段足以。注意,此处可能存在文件将段名修改的情况,例如.data段换为DATA段,所以建议先查看下段名之后指定
def getSegAddr():
textStart=0;textEnd=0;dataStart=0;dataEnd=0;rdataStart=0;rdataEnd=0;
for seg in idautils.Segments():
if (idc.SegName(seg)).lower()=='.text' or (idc.SegName(seg)).lower()=='text':
textStart=idc.SegStart(seg);
textEnd=idc.SegEnd(seg);
if (idc.SegName(seg)).lower()=='.data' or (idc.SegName(seg)).lower()=='data':
dataStart=idc.SegStart(seg);
dataEnd=idc.SegEnd(seg);
if (idc.SegName(seg)).lower()=='.rdata' or (idc.SegName(seg)).lower()=='rdata':
rdataStart=idc.SegStart(seg);
rdataEnd=idc.SegEnd(seg);
return dataStart,dataEnd,rdataStart,rdataEnd;
3.3 编写查找常量
- 查找函数非常简单,但是有一些点需要注意:
- 常量存储不一定都是BYTE格式,有很大可能是WORD、DWORD乃至QWORD,因此需要能够支持指定数据格式类型的匹配。
- 在密码学中我们的索引下标(压缩或扩展变换中使用的数组)都是从1开始的,而在C语言中是从0开始的,所以匹配时需要注意可能存在一个单位的偏移。
def findCrypt(pattens,size=1):
# 目前已支持搜索data,rdata段,支持由于C语言数组下标造成的偏移的矫正,支持Crypto的单个数据单位大小指定
dataStart,dataEnd,rdataStart,rdataEnd=getSegAddr();
crypt={};
for key in pattens:
tmp=pattens[key];
patten=[0]*size*len(tmp);
for i in range(len(tmp)):
patten[i*size]=tmp[i];
addr_d1=match(patten,dataStart,dataEnd);
addr_r1=match(patten,rdataStart,rdataEnd);
# 考虑到C数组从0开始,所以index可能-1
for i in range(len(patten)):
if i%size==0:
patten[i]-=1;
addr_d2=match(patten,dataStart,dataEnd);
addr_r2=match(patten,rdataStart,rdataEnd);
if (addr_d1&addr_r1&addr_d2&addr_r2)==idc.BADADDR:
print 'const not found';
else:
crypt[key]=addr_d1&addr_r1&addr_d2&addr_r2;
print 'Find %s in addr %08x'%(key,addr_d1&addr_r1&addr_d2&addr_r2)
return crypt;
def match(patten,startEa,endEa):
if startEa==endEa:
return idc.BADADDR;
cur=startEa;
while cur<endEa-len(patten):
found_flag=1;
i=0;
while i<len(patten):
if Byte(cur+i)!=patten[i]&0xFF:
found_flag=0;
break;
i+=1;
if found_flag==1:
return cur;
cur+=1;
return idc.BADADDR
四、构建调用树
- 那么在先前我们找到了所有的常量数组的地址。之后就是查找交叉引用了。
- IDAPython 对此提供了DataRefsTo的API,表示查找调用此处的代码地址,并将代码地址所属的函数地址保存,下面代码中func_dict的key是函数地址,而键值是该函数调用的常量数组
func_dict={};
for k in const_data:
func_list=[];
for addr in idautils.DataRefsTo(const_data[k]):
func=idaapi.get_func(addr);
if func_dict.has_key(func.startEA):
func_dict[func.startEA].append(k);
else:
func_dict[func.startEA]=[k];
- 之后我们可以进一步使用CodeRefsTo来查找调用这些函数的代码地址以及这些代码地址所属的函数来构建调用树,其中CodeRefsTo的第二个参数0表示正常流顺序。调用树结构用list的嵌套来表示从属关系。
def del_the_same(father):
keys=father.keys();
record=[];
for k in keys:
for k1 in keys:
if k in father[k1]:
record.append(k);
for r in record:
father.pop(r);
return father
while len(func_dict)!=1:
father={};
del_list=[];
for k in func_dict:
codes=idautils.CodeRefsTo(k,0);
for code in codes:
func=idaapi.get_func(code);
if father.has_key(func.startEA) and (k not in father[func.startEA]):
if func_dict.has_key(k):
father[func.startEA].append(k);
father[func.startEA].append(func_dict[k]);
else:
father[func.startEA].append(k);
else:
if func_dict.has_key(k):
father[func.startEA]=[k,func_dict[k]];
#father[func.startEA]=[k];
else:
father[func.startEA]=[k];
for k in father:
for k1 in father[k]:
if k1 in father.keys():
father[k][father[k].index(k1)]=[k1,father[k1]];
del_list.append(k1);
for l in del_list:
father.pop(l);
father=del_the_same(father);
func_dict=father;
root_func=func_dict.keys()[0];
final_tree=[root_func,func_dict[root_func]];
while len(final_tree)==2
and (type(final_tree[0])!=type([]) and final_tree[0] not in record_func.keys()):
final_tree=final_tree[1];
- 最终我们得到调用树结构,并将其打印出来
# 绘制树状图格式
'''
href http://paste.ubuntu.org.cn/104713
'''
blank=[chr(183)]##此处为空格格式;Windows控制台下可改为chr(12288) ;linux系统中可改为chr(32)【chr(32)==' ' ;chr(183)=='·' ;chr(12288)==' '】
tabs=['']
def tree(lst):
l=len(lst)
if l==0:print('─'*3)
else:
for i,j in enumerate(lst):
if i!=0:
print tabs[0],
if l==1:
s='─'*3
elif i==0:
s='┬'+'─'*2
elif i+1==l:
s='└'+'─'*2
else:
s='├'+'─'*2
print s,
if type(j)==type([]) or isinstance(j,tuple):
if i+1==l:
tabs[0]+=blank[0]*3
else:
tabs[0]+='│'+blank[0]*2
tree(j)
else:
try:
j='sub_%08x'%j;
except:
1+1;
print(j);
tabs[0]=tabs[0][:-3]
tree(final_tree)
- 最终成功得到图的结构,此处以实验吧的”加密算法”一题为例,得到调用图如下:
┬── ┬── sub_004026a0
│ └── ┬── sub_00402590
│ └── ┬── sub_00402140
│ ├── ─── initial_message_permutation
│ ├── ┬── sub_004023b0
││ └── ┬── sub_00402280
││ └── ─── right_sub_message_permutation
│ ├── ┬── S
││ └── message_expansion
│ ├── sub_004021e0
│ └── ─── final_message_permutation
│ └── ┬── sub_00402310
│ └── ┬── sub_key_permutation
│ ├── initial_key_permutaion
│ └── initial_key_permutaion
│ └── ┬── sub_00402590
│ └── ┬── sub_00402140
│ ├── ─── initial_message_permutation
│ ├── ┬── sub_004023b0
││ └── ┬── sub_00402280
││ └── ─── right_sub_message_permutation
│ ├── ┬── S
││ └── message_expansion
│ ├── sub_004021e0
│ └── ─── final_message_permutation
│ └── ┬── sub_00402310
│ └── ┬── sub_key_permutation
│ ├── initial_key_permutaion
│ └── initial_key_permutaion
- 最终判断出各个函数的调用关系。
五、总结
- 我们成功通过了IDA Python实现了调用图生成,完成了对DES的识别与分析,但是树的代码方面有待优化(本人不是非常擅长这部分,欢迎各位大佬指正与优化),其中难免存在错漏,也欢迎各位大佬们指出。
六、参考文献
- FLIRT 常见库地址
- IDA Python-book 翻译版地址 https://bbs.pediy.com/thread-225920.htm
- DES 算法参考 https://github.com/dhuertas/DES
- 调用图绘制 http://paste.ubuntu.org.cn/104713







发表评论
您还未登录,请先登录。
登录