![]()
引言
- 最近参与的一个项目涉及到了二进制重写相关的问题,也因此看了几篇相关工具的论文。与之前曾经一直想做的动态装载有不少重合,因此在此做一个整理。
- 本文主要整理了动态库装载地址不确定对于其他模块的调用造成的影响,以及编译器的解决方案。例如程序中有一个
call printf的指令,然而汇编器生成汇编代码的时候libc装载地址不确定。那么这一类问题如何归类,编译器如何解决这一类问题,这是本文的主要部分。同时本文也重点在延迟绑定方面借助动态调试进行了较为详细的解说。
- 本文涉及到的知识:
- 操作系统中的内存装载相关知识
- 程序的静态链接与动态链接
- 部分涉及到汇编(本文使用的是x86体系)
- 由于本人水平有限,若大佬们发现存在错漏,还望不吝指出。
一、程序的加载与链接
- 本节介绍一些问题相关的前置知识,以及该问题是如何产生的。有操作系统相关知识的读者可以跳过不看。
1.1 内存与磁盘空间
- 众所周知,计算机的内存相对于磁盘读取速度快得多,也因此内存1个G的价格相较于磁盘也是贵得多。这也是一切讨论的前提。
- 程序执行时需要将程序加载到内存中。而由于现代计算机需要并发运行多个程序,若直接加载,往往会存在内存空间不足的情况。直接扩充内存,出于成本考虑是一个昂贵且不现实的方案。由于硬盘的成本较低,操作系统会用硬盘替代内存的部分功能。具体原理如下:
- 由于每个程序存在一个独立的地址空间,所以为每个程序分配一块4G(32位下)的虚拟内存空间,虚拟内存并不实际占用真正的物理内存,而是用硬盘来替代。
- 将虚拟内存分为一个个页,每个页有固定大小(例如4KB)。当执行到程序的某个地址时,判断该地址所在页是否在内存。若不在,触发缺页中断,操作系统会按照一个置换算法将该地址所在的页调入内存。
- 这样由于程序的时间空间局部性原理,加上合理的调页算法,可以用较小的内存实现较高的访存效率。
1.2 程序的静态链接与动态链接
- 程序的代码基本上不可能全部在一个源文件中实现。例如以最经典的helloworld为例,调用的
printf函数就没有被我们在源文件中实现,而实际上是通过调用C语言标准库实现。以Linux中为例,库文件是libc。
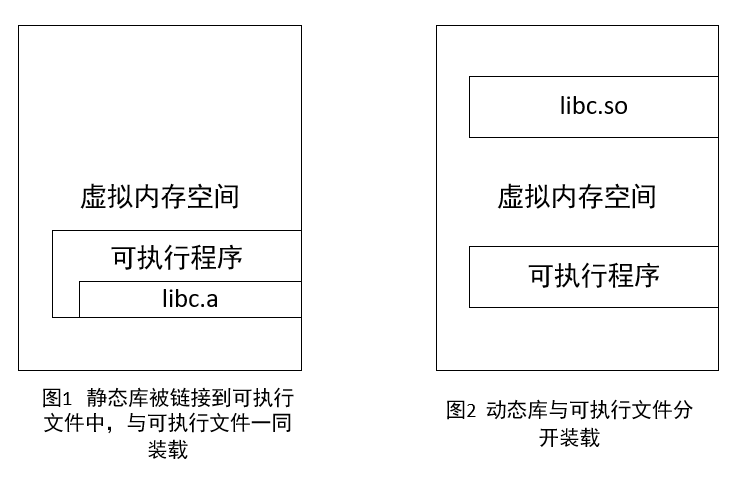
- 我们对于这种文件的调用有两种方式,一种是链接过程中加入静态库,例如libc-a-b-c.a。另一种是执行时动态调用动态库,例如libc-a-b-c.so:
- 其中使用静态库,相当于将静态库文件与我们编写的程序链接在一起,生成成一个可执行文件,在这种情况下我们的可执行文件无需任何依赖即可执行。此时文件大小较使用动态库明显大。
- 使用动态库则不同,生成的可执行文件并不包含库文件,也就是说可执行文件没有库的情况下是无法执行的。在执行期间,可执行文件被加载进虚拟内存时,可执行文件涉及到的动态库也被加载进内存。此时可执行文件大小较使用静态库明显小很多。
![]()
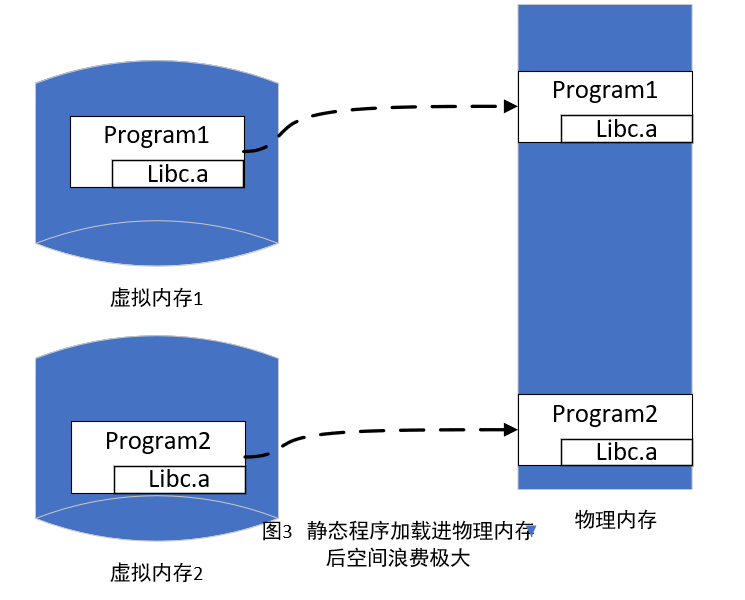
- 事实上,系统中大部分程序都是需要几个特定的库。倘若我们都使用静态库的方案,当系统运行100个进程时,若这些进程同时执行到库部分的代码,物理内存被占据了100个库的大小。考虑到内存是非常宝贵的,这种方案显然是不合理的。
![]()
- 使用动态链接库也可能会导致一些版本接口改变造成的依赖性问题。但考虑到其相对于静态库节约的内存,该方案在目前被广泛的使用。
1.3 从编译到链接
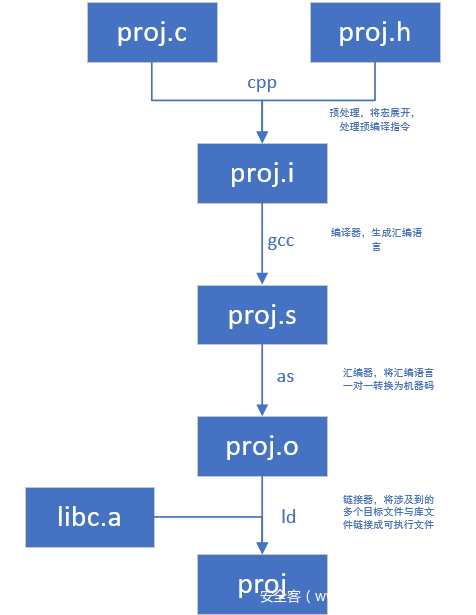
- 在日常的开发工作中,我们往往使用的是集成开发环境。一个按键就能够帮我们完成从源码到可执行文件的转换。即使是在Linux的shell下,往往也是gcc一条指令就可以完成。事实上,程序从源码到可执行文件需要有一个复杂的过程。
![]()
- 然而当我们不再将静态库编译进程序,而是动态加载库文件时,问题就出现了。众所周知,汇编语言中控制流转换是需要地址的。例如一条调用
printf的API的语句
printf("IOLI Crackme Level 0x00n");
...
.text:0804842E 29 C4 sub esp, eax
.text:08048430 C7 04 24 68 85 04 08 mov dword ptr [esp], offset format ; "IOLI Crackme Level 0x00n"
.text:08048437 E8 04 FF FF FF call _printf
...
- 在这段汇编中,我们可以看到call指令很明显涉及到地址。这段汇编代码中的地址是在链接的阶段完成的,而动态库中的API地址是在装载之后才确定的。(实际上部分重要的动态库,例如ntdll等有着几乎是固定的装载地址,但对于大部分dll而言这仍然是个问题,尤其是当ASLR机制被引入之后)这为我们的程序编译造成了非常大的麻烦。
二、地址无关代码
2.1 静态共享库
- 对于这一问题,一开始人们的想法是在编译阶段前,也就是汇编代码生成之前确定API的地址。那么这么一来每个库的装载地址都需要预先确定。
- 在早期,我们使用动态库的时候曾经有过一种名为静态共享库的解决方案。这与当前使用的动态库不太一样。其主要特点是将模块统一交给操作系统管理,使用的库会被固定加载到某个地址。这样我们就可以在编译的时候确定函数的地址。因为每个函数由于其库是确定的,所以其库在内存中的装载地址也是确定的,由此就可以得到其地址。
- 然而该方案有几个很严重的问题:
- 库在升级的过程中不能改变原有函数的位置,不能有API的删减,否则将导致已经生成的可执行文件无法执行。
- 自己编写的库文件无法以共享库的形式被使用
- 为了解决这一问题,我们不再强制要求模块在固定地址装载,而是试图在模块装载地址确定之后再修复函数引用的地址。
- 顺带一提,目前可执行文件的模块装载地址在没有开启ASLR的前提下是固定的。例如Windows下地址为0x00400000,Linux下为0x0804000。
2.2 装载时重定位
- 我们首先想到的就是重定位。简而言之就是对其他模块的函数的引用在链接时只填写函数相对于其模块的起始地址,到装载时模块基地址确定后再修改为相对地址+基地址。例如foo相对于模块a的代码段起始地址是0x100,先在链接阶段填入,之后模块a装载后确定基地址为0x600000,则修改所有调用foo处地址为0x600100。
- 这种方案到目前为止都在被广为使用,但是也存在一个问题,那就是指令共享时无法正常使用。
- 为什么会有指令共享?当前操作系统中,一个进程可以理解为对一个程序的一次执行,当系统多次运行一个程序(数据不同)时,为了节约内存,就会产生多个进程在物理地址中共用一个代码段的情况(在虚拟内存中仍然是各有一份代码,因为进程有独立的地址空间)。
- 那么在这种情况下,显然重定位修改只能针对一个进程,对于另一个进程,就无法正常使用了。当然,对于动态链接库,此方案仍然可以正常使用。
2.3 地址无关代码
- 那么有没有一套通用的方案?答案是有的。由于指令部分可能是共享的,所以我们很自然的想到将需要重定位的部分从指令中分离出来,放到数据中。由于每个进程数据是独一无二的,所以这样就可以实现重定位的同时不影响代码的共享。
- 首先我们先将模块的地址引用分为四种:模块内部的函数调用,模块内部的数据访问,模块外部的函数调用,模块外部的数据访问。
2.3.1 模块内部函数调用或跳转
- 这种情况可以说是最简单的,由于被调用的函数与调用者处于同一模块,两者之间相对位置固定,所以这种指令不需要定位,一条相对跳转/调用就可以完成。而返回时由于
call指令会自动完成push $PC的操作,所以ret不需要任何处理就可以定位到原先call的下一条指令(PC在取完call之后指向下一条指令的地址而不是call的地址)。
0x8048349 <foo>:
...
.init:080482FE E8 81 00 00 00 call sub_8048384
...
- 例如上面代码中,e8是
call指令的操作码,81 00 00 00实际上是小端序的0x00000081,补码表示,实际上是0x81的偏移。该指令实际上是一条相对调用指令。我们将call下一条指令的地址(0x080482FE+0x5)加上偏移量就得到了指令地址,即0x8048384。
2.3.2 模块内部数据调用
- 首先,由于模块装载地址是不确定的,所以对于模块内部数据调用我们无法使用直接地址。其次,由于模块内部数据与代码处于同一个模块中,尽管处于不同的段(一般代码处于
.text而数据处于.data段),两者之间的相对偏移量可以说是确定的。唯一的问题在于,没有一条相对当前PC地址的访存指令,所以我们需要获得当前地址才能够完成模块内部数据调用。
- 幸运的是,elf为我们提供了一个很好的解决方案,
__i686.get_pc_thunk.xx函数,该函数只有两条语句:
.text:08048515 __i686_get_pc_thunk_bx proc near ; CODE XREF: __libc_csu_init+8↑p
.text:08048515 mov ebx, [esp+0]
.text:08048518 retn
.text:08048518 __i686_get_pc_thunk_bx endp
- 由于
call指令等效于push $PC,所以mov ebx, [esp+0]相当于取call <__i686.get_pc_thunk.bx>指令的下一条地址指令到ecx,此时就可以通过ecx加上偏移,完成对模块内部数据的寻址。
.text:080484A8 call __i686_get_pc_thunk_bx
.text:080484AD add ebx, 1B47h
.text:080484B3 sub esp, 1Ch
.text:080484B6 call _init_proc
.text:080484BB lea eax, (__CTOR_LIST__ - 8049FF4h)[ebx]
.text:080484C1 lea edx, (__CTOR_LIST__ - 8049FF4h)[ebx]
- 此处我们看到,程序调用
call __i686_get_pc_thunk_bx后对ebx(即0x080484AD的地址)进行了加0x1B47的操作,也就是加上了偏移量。之后两条lea指令则是通过一些常量结合先前的地址完成偏移量计算,最终完成访存操作。
2.3.3 模块间数据访问
- 跨模块间调用显然要麻烦的多,因为我们只有在被调用的代码所在模块装载完成后才能够获得其基地址。
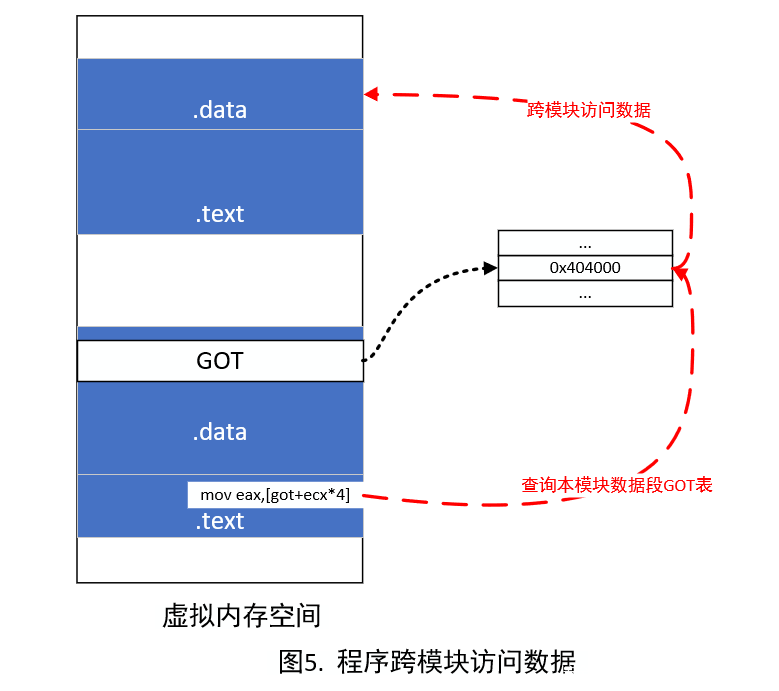
- 先前我们提到,为了避免影响代码共享的效果,我们必须将与跨模块相关的调用与代码段分离,放在数据段中。那么具体的实现办法就是对于跨模块的调用,我们使用一张表来存储其地址。该表最初是未初始化,模块装载后该表完成初始化。访问变量时,先取出表中的地址,之后通过该地址来完成访问。这也就是GOT表。
- 由于每个进程有着不同的数据段,因此我们对同一程序的不同进程也可以保持不同的地址访问。
![]()
2.3.4 模块间跳转与调用
- 对于模块之间的跳转与调用,我们可以采用2.3.3的方法来修改,唯一有区别的就是相对于2.3.3访问从got表取得的地址,这里采用的是
call这个从got表中获得的地址。
call 494 <__i686.get_pc_thunk.cx>
add $0x118c,%ecx
mov 0xfffffffc(%ecx),eax
call *(%eax)
- 这种方法非常简单,但存在部分对性能的浪费,实际上ELF采用另一种近似原理的方案。
三、延迟绑定
- 先前我们在2.3.4中提到模块间相对跳转需要通过GOT表间接完成。由于GOT表是在模块装载后才能确定的,所以说我们需要逐一初始化GOT表表项。对于数据访问相关的项倒还好,毕竟所有项是必定会被访问的。然而对于函数访问,相当多的函数可能从程序执行到结束都不会被访问,这也造成了极大的浪费。
- 对此,编译器使用了一种延迟绑定的技术,使用PLT(Procedure Linkage Table)方法来实现。即当第一次访问函数时才将GOT表填入。在这种情况下我们就无法通过直接访问GOT表来完成函数调用了。因为如果直接访问GOT表,则在第一次访问时GOT表尚未初始化,就会出现访存错误。编译器对此使用的是不直接访问GOT表,而是通过一个plt来完成跳转。根据情况选择装填GOT表或直接访问GOT表地址。
- 也因此,为了与原先的GOT表区分,所有的函数填入的表被称之为
.plt.got表而不是原先的GOT表。
- 我们尝试用gdb实际跟踪程序,首先查看main的反汇编
gdb-peda$ disassemble main
Dump of assembler code for function main:
0x08048414 <+0>: push ebp
...
0x08048430 <+28>: mov DWORD PTR [esp],0x8048568
0x08048437 <+35>: call 0x8048340 <printf@plt>
0x0804843c <+40>: mov DWORD PTR [esp],0x8048581
0x08048443 <+47>: call 0x8048340 <printf@plt>
...
0x08048491 <+125>: leave
0x08048492 <+126>: ret
End of assembler dump.
- 其中我们可以很明显的看到调用的0x8048340实际上是plt而不是实际函数。
gdb-peda$ disassemble 0x8048340
Dump of assembler code for function printf@plt:
0x08048340 <+0>: jmp DWORD PTR ds:0x804a008
0x08048346 <+6>: push 0x10
0x0804834b <+11>: jmp 0x8048310
End of as
gdb-peda$ x/4x 0x804a008
0x804a008 <printf@got.plt>: 0x08048346 0x08048356 0x00000000 0x00000000
- 我们查看
printf@plt处发现实际上第一处是一个跳转,在当前情况下(程序未运行,只是装载到虚存中)跳转的地址是0x08048346。也就是printf@plt的第二条语句。尝试实际运行,发现情况的确如我们所料。
=> 0x8048340 <printf@plt>: jmp DWORD PTR ds:0x804a008
| 0x8048346 <printf@plt+6>: push 0x10
| 0x804834b <printf@plt+11>: jmp 0x8048310
| 0x8048350 <strcmp@plt>: jmp DWORD PTR ds:0x804a00c
| 0x8048356 <strcmp@plt+6>: push 0x18
|-> 0x8048346 <printf@plt+6>: push 0x10
0x804834b <printf@plt+11>: jmp 0x8048310
0x8048350 <strcmp@plt>: jmp DWORD PTR ds:0x804a00c
0x8048356 <strcmp@plt+6>: push 0x18
- 之后是
push 0x10与jmp 0x8048310。实际上查询后可得,此处0x10为printf在.plt.got表中的偏移,继续看0x8048310。
=> 0x804834b <printf@plt+11>: jmp 0x8048310
| 0x8048350 <strcmp@plt>: jmp DWORD PTR ds:0x804a00c
| 0x8048356 <strcmp@plt+6>: push 0x18
| 0x804835b <strcmp@plt+11>: jmp 0x8048310
| 0x8048360 <_start>: xor ebp,ebp
|-> 0x8048310: push DWORD PTR ds:0x8049ff8
0x8048316: jmp DWORD PTR ds:0x8049ffc
0x804831c: add BYTE PTR [eax],al
0x804831e: add BYTE PTR [eax],al
- 非常有趣的是我们看到对于其他函数的plt部分(例如下面的
strcmp@plt),最终也会跳到0x8048316,因此可以猜测实际上这个是plt的分发处。
gdb-peda$ x/2x 0x8049ff8
0x8049ff8: 0xf7ffd940 0xf7feae10
gdb-peda$ vmmap
Start End Perm Name
0x08048000 0x08049000 r-xp /home/kdsj/Desktop/Workshop2015/IOLI-crackme/bin-linux/crackme0x00
0x08049000 0x0804a000 r--p /home/kdsj/Desktop/Workshop2015/IOLI-crackme/bin-linux/crackme0x00
0x0804a000 0x0804b000 rw-p /home/kdsj/Desktop/Workshop2015/IOLI-crackme/bin-linux/crackme0x00
0xf7dde000 0xf7fb3000 r-xp /lib/i386-linux-gnu/libc-2.27.so
0xf7fb3000 0xf7fb4000 ---p /lib/i386-linux-gnu/libc-2.27.so
0xf7fb4000 0xf7fb6000 r--p /lib/i386-linux-gnu/libc-2.27.so
0xf7fb6000 0xf7fb7000 rw-p /lib/i386-linux-gnu/libc-2.27.so
0xf7fb7000 0xf7fba000 rw-p mapped
0xf7fd0000 0xf7fd2000 rw-p mapped
0xf7fd2000 0xf7fd5000 r--p [vvar]
0xf7fd5000 0xf7fd6000 r-xp [vdso]
0xf7fd6000 0xf7ffc000 r-xp /lib/i386-linux-gnu/ld-2.27.so
0xf7ffc000 0xf7ffd000 r--p /lib/i386-linux-gnu/ld-2.27.so
0xf7ffd000 0xf7ffe000 rw-p /lib/i386-linux-gnu/ld-2.27.so
0xfffdd000 0xffffe000 rw-p [stack]
- 继续执行下去,有一个对0x8049ff8地址的内容的
push操作,以及一个对0x8049ffc地址内容的jmp操作。所以我们查看了一下0x8049ff8与0x8049ffc地址。顺带查询了一下该ELF加载模块所在内存,即将访问的0xf7feae10在ld-2.27.so库之中。根据其r-xp的属性(由于有可执行属性)可以大致猜测是.text段,也就是我们先前提到的2.3.4的跨模块调用。则0x8049ff8与0x8049ffc应当处于.plt.got表中。
- 尝试执行发现gdb没有识别出0xf7feae10的函数名,所以我们计算一下偏移(访问的函数地址-模块装载基址)
>>> hex(0xf7feae10-0xf7fd6000)
'0x14e10'
- 一般情况下我们可以用IDA装载
ld-2.27.so之后,在Export中通过偏移查找该函数名。然而由于IDA没有该函数符号信息,所以此处我偷懒了,直接查询文档确定该处为_dl_runtime_resolve()函数。该函数的功能很简单,就是解析出函数的真实地址,得到地址后将这一真实地址填入GOT表。顺带一提,我们用IDA可以看到实际上.plt.got开始的地址是0x08048ff4,也就是0xf7feae10保存的0x08048ffc为.plt.got的第3项。
.got.plt:08049FF4 ; Segment type: Pure data
.got.plt:08049FF4 ; Segment permissions: Read/Write
.got.plt:08049FF4 _got_plt segment dword public 'DATA' use32
.got.plt:08049FF4 assume cs:_got_plt
.got.plt:08049FF4 ;org 8049FF4h
.got.plt:08049FF4 _GLOBAL_OFFSET_TABLE_ dd offset _DYNAMIC
.got.plt:08049FF8 dword_8049FF8 dd 0 ; DATA XREF: sub_8048310↑r
.got.plt:08049FFC dword_8049FFC dd 0 ; DATA XREF: sub_8048310+6↑r
- 那么我们整理一下,首先程序第一次访问
printf函数,用户代码中的call会将程序带到.plt部分,其中有三条指令:
gdb-peda$ disassemble 0x8048340
Dump of assembler code for function printf@plt:
0x08048340 <+0>: jmp DWORD PTR ds:0x804a008
0x08048346 <+6>: push 0x10
0x0804834b <+11>: jmp 0x8048310
End of as
- 第一条指令表示访问
.plt.got表中printf对应表项,由于此处该表项未初始化,所以该表项填入的地址指向jmp下一条地址。下一条push压入prinf在GOT表中的偏移,之后我们进入plt的分发部分。
|-> 0x8048310: push DWORD PTR ds:0x8049ff8
0x8048316: jmp DWORD PTR ds:0x8049ffc
- 这两条指令中,
push指令压入.plt.got中的第二项,也就是本模块的ID,jmp指令等效于调用_dl_runtime_resolve()函数解析printf的真实地址并填入.got.plt表。最后完成调用后返回到printf@plt,
Dump of assembler code for function printf@plt:
0x08048340 <+0>: jmp DWORD PTR ds:0x804a008
0x08048346 <+6>: push 0x10
- 此时由于
.plt.got表已经完成装填,所以正常调用printf函数而不执行下面的装填操作(完成printf的执行后直接ret回用户代码)。这一点可以通过在push处下断点验证,直接r完程序,查看push处断点被触发几次即可。
四、总结
- 在当前,由于集成开发环境的广泛使用,我们往往忽略了程序的链接过程。程序的编译看似不起眼实则非常重要。看了下网上也没有比较完整的文档,因此整理了一下相关的资料。
- 本文第二部分主要参考了《程序员的自我修养—链接、装载与库》一书,书上较本文内容更加详尽,有空的建议看看。本文第二部分借助书中第7章的架构结合自己理解进行了表述,同时第一部分写了一点自认为有益的前置知识,第三部分通过调试过程进行了较为完整的解说,希望对各位有所帮助。同时也为之后预计完成的二进制重写工具原理难点介绍做一定的前置准备。
- 同时由于本人水平所限,文中难免存在错漏,希望各位大佬能够不吝指正文中的错漏。









发表评论
您还未登录,请先登录。
登录