

题目一 DNS恶意流量检测
0x00 题目解读
题目介绍是在赛前就给出的,从介绍中我们可以了解到
- 目标
找出五种攻击流量,并将其进行分类
意味着首先需要了解DNS攻击的种类及其特点
- 数据
描述中并没有讲太多,仅仅提到
给定的DNS流量,对这个流量的形式没有说明,猜测应该是pcap文件或者是处理过的数据文件。如果是pcap文件则需要由数据包分析的知识,可能需要利用程序对数据包进行处理,如果是后者,便简单许多,不用再进行数据处理。
因为数据包再赛前也提供下载,设置了密码,无法提前获得数据。但是虽然不能获取数据但是解压后可以看到文件夹或文件的的名字,这样基本验证了提供的数据文件pcap文件。
- 提交
提交提供了精简版的提交格式,详细要求会提供一个文档,在上一步已经看到这个文件名。着重强调提交的文件类型,应该是和之后的得分计算有关。类型或格式不当,计算得分的程序会无法计算。
- 评分
评分开始并没有讲的很明白,只是说明在4号会有一次评分。但是可以知道在赛程中间会有评分,可以通过评分调整自己的答案结构。
比赛开始,获得压缩包密码,解压文件后,得到
-
example_dns1.zip:zip压缩文件,打开后发现应该是提交的样本实例。 -
q1_final.pcap:pcap文件,看下大小,是这次的数据文件无疑了。 -
Readme-第一题.pdf:赛题详细介绍。确定最终题目:准确判断出五种DNS攻击,并说明PCAP文件中哪些数据包是攻击流量。
提交:2个csv文件(攻击分类和数据包序号),writeup,解题代码,zip格式打包。不要添加密码,不要打包文件夹。writeup影响最终得分,未详细说明,应该是想了解选手对DNS攻击的了解程度。
最终得分取最后提交的得分,不是取最高分。猜测可能是因为赛程过程中有多次提交,如果保存中间文件比较复杂,而最终评测还需要提交文件做判定。
重点:
- 数据包仅包含为五类攻击,确定数据包的攻击时可以使用。
- 评分与选手攻击编号无关,不需要关心攻击类型的排序。
- 提交攻击的请求包,那么是否可以理解,如果某种DNS攻击并不能在请求中体现出来或者不需要攻击者进行请求,应该不存在于这个数据包中,缩减攻击类型判定的范围。
- 评分规则:得分由每一类得分累加而得,每类攻击占比20%。
通过计算规则我们可以知道,每类攻击有固定的占比,所以不会因为某种攻击数量多而占去大部分分数,解题过程中就可以单独提交某种类型,进行测试;计算不是简单按照提交中正确数据包个数,如果出现误判会进行扣分,所以在提交后扣分的原因会有两个,一是提交数据包太少,攻击数据包没有找全,二是提交数据包太多,其中包含了太多错误分类,当然也会同时存在数据包不全并且包括错误分类的情况。
0x01 解题思路
在初步查看数据包后,我们队决定从两个方面入手,一利用聚类算法对数据包进行聚类,再对聚类的后的每个分类进行校验;二是对数据包进行手工查验。当然这两个方法是同步进行的。无论使用哪个方法,首先要做的第一步就是确定DNS攻击的类别。
我们的思路是想把所有的攻击分类先列出来,在根据攻击特征进行查找,但后来发现,题目中出现的攻击并不在我们最初列出的攻击中,说明我们对攻击理解的还不够全面。接下来对攻击类型进行简单介绍。
- 拒绝服务攻击拒绝服务攻击分为两种,一是面向DNS服务器的,可以称为洪泛攻击,目的是使得DNS服务器无法提供服务;二是面向客户机的,称为DNS反射放大攻击,通过伪造数据包,伪装客户机发送解析请求,使得DNS回应包阻塞指定客户机的网络通路,目的是使得客户机无法正常工作。分析攻击的特征:对第一种情况,可能会存在某一或某些主机短时间内向同一DNS服务器发送大量解析请求,造成目标DNS服务器的拒绝服务
【攻击可能存在,使用某时间段内是否存在大量向同一服务器的解析请求,且造成了服务器不正常工作】
第二种情况,是存在一个主机向DNS服务器发送大量解析请求,且请求字段为
ANY,而服务器返回的数据包远远大于平常的返回包【攻击可能存在,查看是否存在单一主机非常集中的请求
ANY解析,其transaction ID可能会出现重复,且服务器返回的数据包远远大于正常数据包】 - DNS欺骗攻击欺骗攻击同样包含很多类别,这里将DNS劫持和中间人攻击放在这里,同时还有DNS缓存注入。DNS劫持一般的操作是在服务器的层次进行攻击。
【攻击存在可能性不大,判定难度较大】
中间人攻击同样也多发生在服务器层次。
【攻击存在可能性不大,判定难度较大】
缓存注入攻击有两种方式,一种是传统的对客户机的解析请求直接进行伪造响应包,将目标IP直接注入。另一种是Kaminsky缓存投毒,这种攻击方式是攻击者首先伪装客户机解析一个服务器一定不存在的域名,然后在服务器进行递归解析时,攻击者向服务器发送伪造的响应包,同时将域名的权威服务器加入额外字段,一旦服务器将其缓存,则被投毒。
【结合题目要求,kaminsky攻击可能存在,判定条件为某一主机向服务器解析大量不存在域名,且存在大量返回
不存在域名的响应,其额外字段为相同的值】 - DNS隐通道利用DNS数据包越过防火墙规则,进行传输数据。
【攻击存在可能性不大,若攻击存在可能存在明显的构造的特殊的解析请求】
- DNS区域传送区域传送是将某台服务器的区域文件传送至另一台服务器,主要目的是实现快速的服务器更换。但若设置不当,可能造成区域文件泄露。
【攻击可能存在,关注区域文件传送的数据包】
- NSEC枚举这是针对DNSSEC的一种攻击,在未使用NSEC3的DNSSEC中,若查询区文件中不存在的域名,会以NSEC记录的形式提供靠近其的最近的下一条域名,这就造成了可能构造特殊请求,来遍历区文件,造成区文件的泄露。
【攻击可能存在,关注NSEC记录】
以上就是最初的攻击分类,类别不够完整,在之后的分析过程中在再补充。
通过 wireshark 查看 q1_final.pcap 数据,查看数据中的可用字段,分析后选择如下 28 个字段:
| 字段 | 描述 | 字段 | 描述 |
|---|---|---|---|
| frame.len | 数据长度 | dns.flags.authenticated | 服务器是否为域权威服务器 |
| ip.src | 源 ip | dns.flags.checkdisable | 非认证数据是否可接收 |
| ip.dst | 目的 ip | dns.flags.rcode | DNS reply code |
| udp.srcport | 源 udp 端口号 | dns.count.queries | s数据包中 DNS 请求数 |
| udp.dstport | 目的 udp 端口号 | dns.count.answers | 数据包中的应答数 |
| eth.src | 源 MAC 地址 | dns.count.auth_rr | 数据包中权威记录数 |
| eth.dst | 目的 MAC 地址 | dns.count.add_rr | 数据包中额外记录数 |
| dns.id | DNS Transaction ID | dns.qry.name | DNS 请求名 |
| dns.flags.response | DNS请求/响应标志 | dns.qry.class | DNS 请求类型 |
| dns.flags.opcode | DNS opcode | dns.resp.name | DNS 响应名 |
| dns.flags.authoritative | 应答是否被服务器认证 | dns.resp.type | DNS 回复类型 |
| dns.flags.truncated | 消息是否剪裁 | dns.resp.ttl | DNS 响应生存时间 |
| dns.flags.recdesired | 是否递归查询 | dns.resp.z.do | DNS 是否支持 DNSSEC |
| dns.flags.reavail | 服务器是否能递归查询 | frame.time_relative | frame 的相对时间 |
使用 tshark 命令从 pcap 数据抽取上述字段,保存到 csv 文件中:
tshark.exe -r q1_final.pcap -T fields -e frame.number -e frame.time_relative -e ip.src -e ip.dst -e frame.len -e eth.src -e eth.dst -e udp.srcport -e udp.dstport -e dns.id -e dns.flags.response -e dns.flags.opcode -e dns.flags.authoritative -e dns.flags.truncated -e dns.flags.recdesired -e dns.flags.recavail -e dns.flags.authenticated -e dns.flags.checkdisable -e dns.flags.rcode -e dns.count.queries -e dns.count.answers -e dns.count.auth_rr -e dns.count.add_rr -e dns.qry.name -e dns.qry.type -e dns.qry.class -e dns.resp.name -e dns.resp.type -e dns.resp.ttl -e dns.resp.z.do -E separator="," -E aggregator=" " -E header=y -E occurrence=f -E quote=d > q1_final.csv
使用 jupyter notebook 分析数据:
- 导入必要的库
import pandas as pd import numpy as np import matplotlib.pyplot as plt # show plot in jupyter notebook %matplotlib inline - 读取数据
# read data file_name = 'q1_final.csv' data = pd.read_csv(file_name,index_col=0) - 分析数据基本特征的分布,选择值分布较为分散的特征,如果只有一个值的特征则直接删除:
- eth.src 和 eth.dst 只有两个值,不能很好的作为可区分特征,故删除;
- dns.qry.class 只有一个值,根本没有区分度,故删除;
- dns.srcport 和 dns.dstport 的值相当分散,这是由于客户端可以随机生成端口号所致,故作用不大,删除
- ip.src 和 ip.dst 以及 dns.id 分布随机,可以用于标识一个 frame,但不能反映 frame 的行为,故不使用;同时发现主要的 ip 地址为
45.80.170.1,该地址相关的 frames 占总 frames 数的 98% 左右,故猜测为正常数据诸多,构建模型时可以先不使用该部分数据,观察聚类的效果;
根据已经得出的每种攻击类型的特征进行特征设计,初步设想以一个 frame 作为基本处理单元,但是一个 frame只能为 DNS 请求或者 DNS 响应,并不能完整的反映 DNS 会话的整个流程,因此使用集合 {ip.src, ip.dst, udp.srcport, udp.dstprot, dns.id} 标识一个 DNS 流, 故一个 DNS 流中至少包含一个请求的 frame ,但实际中绝大部分 DNS 流都包含 DNS 请求和响应两个 frame。那么 DNS 流 的特征如何构造才能区分正常的和异常的的 DNS 流呢?考虑到可能的攻击方式,异常的情况分析如下:
- 对于放大攻击, DNS 流中的响应的长度应该会很大, 同时响应长度和请求长度之比会很大;
- 对于 DNS 缓存投毒攻击, DNS 流中 DNS 请求 frame 的源地址可能和很多不同的服务器进行DNS会话;
- 对于区域传送攻击, DNS 流中 请求类型
dns.qry.type字段为255; - 其它异常情况还可能有 DNS 流中只有请求没有响应, DNS 持续时间异常, DNS 流中的权威记录和额外记录过少等;
根据分析,得到如下特征:
| 特征名 | 含义 |
|---|---|
| #frames | DNS 流 中的 frame 数 |
| qry.len | 请求长度 |
| resp.len | 请求相对应的响应长度 |
| len.ratio | 响应长度和请求长度的比值 |
| duration | 会话持续时间 |
| servers | 某一主机连接的不同服务器数量 |
| flags.resp | 标记区分请求和响应 |
| flags.opcode | 请求执行的操作 |
| flags.rcode | DNS 流中是否有响应标 |
| qry.type | 解析请求类型 |
| resp.type | 响应类型 |
| #auth_rr | 数据包中权威记录数 |
| #add_rr | 数据包中额外记录数 |
使用 Python scikit-learn 库中 sklearn.cluster 模块中的聚类算法进行聚类,首先考虑使用小的数据集上进行特征抽取和聚类,验证特征的有效性, 因为根据对数据基本特征分析时发现的主要 ip地址为 45.80.170.1 , 与该地址相关的数据占 98% 左右, 所以可以先过滤调这部分数据构造一个小数据集上进行实验性验证。
- 在 jupyter notebook 中完成数据中缺失值的处理
- 编写 python 脚本完成数据特征的抽取, 保存成 hdf 文件
- 在 jupyter notebook 中完成聚类模型的构建
最终分类结果如下:
类别 0: DNS cache pullution
| ip | frame 数 |
|---|---|
| 144.202.64.226 | 33903 |
| 18.100.48.86 | 8 |
| 6.116.183.244 | 2 |
类别 1: DNS zone transfer
| ip | frame 数 |
|---|---|
| 18.100.48.86 | 3655 |
类别 2: DNS dynamic update
| ip | frame 数 |
|---|---|
| 18.100.48.86 | 3655 |
类别 3: DNS Amplification Attack
| ip | frame 数 |
|---|---|
| 105.191.150.205 | 4150 |
| 127.130.104.152 | 11868 |
| 175.222.102.169 | 17182 |
| 6.116.183.244 | 72 (实际为NSEC) |
类别 4: Misclassificaiton
| ip | frame 数 |
|---|---|
| 144.202.64.226 | 291 |
| 18.100.48.86 | 428 |
在小数据上,使用 KMeans 算法聚类, 聚类效果很好,分类结果和手工分析结果基本相同, 除了 NSEC 枚举攻击被分类成放大, 其它4个类型基本正确, 进一步可以说明攻击类型基本确定。
NSEC 分类错误的主要原因是, 没有添加和 NSEC 攻击相关的特征, 从手动分析数据中可以看出, NSEC 枚举攻击的 frame 存在相应的标志位. 此外还有可能的原因是 NSEC这个类的数量很少 KMeans 算法适用于各类数量均匀的情况,进一步尝试使用 DBSCAN 算法进行聚类,调整 eps 和 min_samples 参数,直到分类结果为 5 类或 6 类. 分类结果和使用 KMeans 差不多,NSEC 枚举依旧误分类,因此可能的原因就是所用特征不能很好区分 NSEC 枚举攻击类型。
使用wireshark进行数据包q1_final.pcap分析。
数据包较大,共有10736020个数据包,打开比较费时,考虑将数据包进行切割,但是切割后存在一个问题,就是数据包的序号会改变对之后提取数据包的序号造成了困难,所以并没有首先对数据包进行盲目的切割,决定分析后再进行切割。
粗略浏览数据包,发现数据包结尾部分出现一部分异常流量,在并没有发现特别明显的异常。
在数据包最后一部分,出现的流量全部都是解析请求,且请求的类型为ANY,怀疑为DNS反射放大攻击。
那么就用这类攻击的特征首先进行筛选,解析请求为ANY、返回数据包很大。
设置过滤器,利用解析请求ANY 做为条件。
dns.qry.type == 255
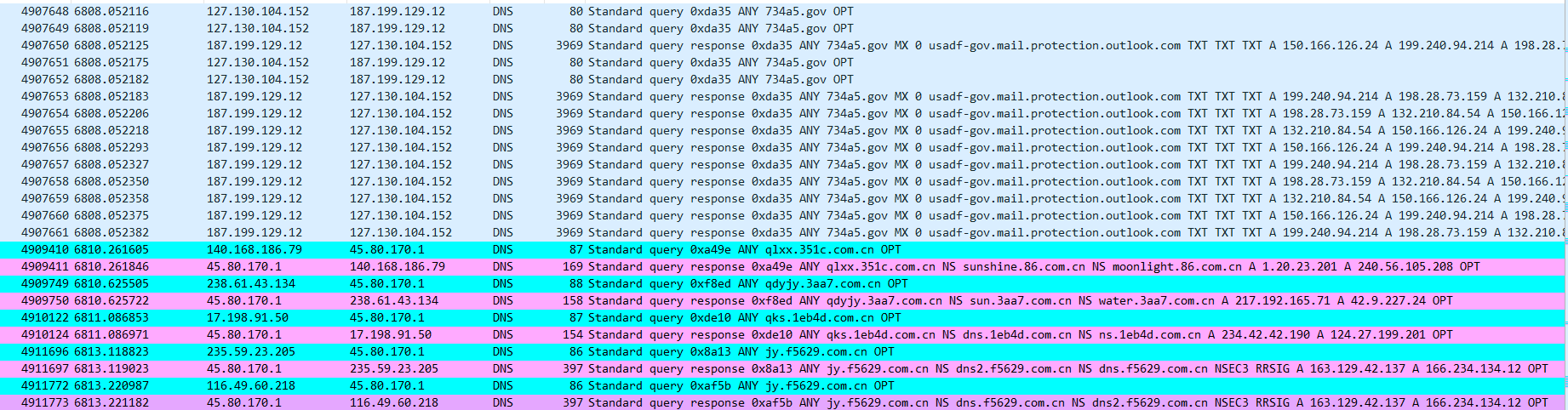
果然存在异常的数据包,但是还有很多正常的流量,还需要添加条件。
dns.qry.type == 255 && frame.len > 2000

确定为放大攻击。但这是响应包,需要找到其请求包。
首先确定服务器IP和客户机IP
| dns servers | victim ip |
|---|---|
| 187.199.129.12 | 127.130.104.152 |
| 188.141.167.218 | 175.222.102.169 |
| 70.85.232.160 | 105.191.150.205 |
这里其实还有一台服务器45.80.170.1,在第一步检查时出现但这一步并没有出现,之后检查发现,其实是有两台机器22.203.191.72和223.168.98.1向45.80.170.1发送了解析且类型为ANY,但是服务器回应为拒绝,并没有返回数据包,这部分攻击未确定。
将确定的攻击筛选出来,取出请求包。
(ip.addr == 127.130.104.152 || ip.addr == 175.222.102.169 || ip.addr == 105.191.150.205) && dns.flags.response == 0
得到DNS反射放大攻击请求数据包,取出其序号,获得第一类攻击流量。
在上面的筛选过程中就发现,其实服务器45.80.170.1是主要的DNS服务器,大部分流量是这台服务器的,那么就有一个问题,除了主要服务器45.80.170.1,还剩下多少服务器,多少数据包?
ip.src !=45.80.170.1 && ip.dst != 45.80.170.1
我用的wireshark版本有点问题,不支持ip.addr 的不等查询,只好分开写
发现剩下的数据包仅仅剩下141213个,结合上面的放大攻击,猜测是否攻击流量大部分在这里面。
对这些流量进行分析,发现异常流量。
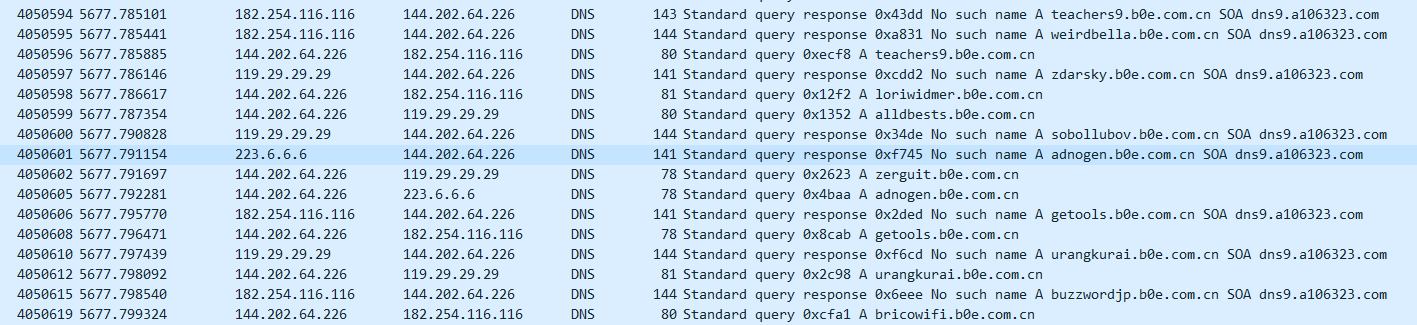
出现大量返回no such name的响应包,且响应包中包含相同的SOA记录,推测为kaminsky投毒攻击。
请求主机为144.202.64.226,获得第二类攻击流量。
排查是否存在区域传送。
dns.qry.type == 252
发现区域传送数据包

请求主机ip仅有一个,为96.199.230.176,确定为区域传送攻击。获得第三类攻击流量。
上面三种类型形成第一次提交的答案。
攻击分类为
| attackid | description |
|---|---|
| 1 | DNS zone transfer |
| 2 | DNS Amplification Attack |
| 3 | DNS cache pollution |
其中DNS zone transfer攻击请求包5297条,DNS Amplification Attack攻击请求包40990条,DNS cache pollution攻击请求包34194条。
得分:55.279
从得分上看,三种分类正确且基本上每一分类的大部分攻击流量被找到,扣分原因可能是因为有一部分错误流量,之后再做筛选。
刚开始就列出的攻击类型,在分析过程中又找到了一种攻击向量,PTR反查,利用PTR记录的特性可以遍历保留地址来获取内网的域名信息,造成内网信息泄露。
在数据包中查找是否存在这种记录。
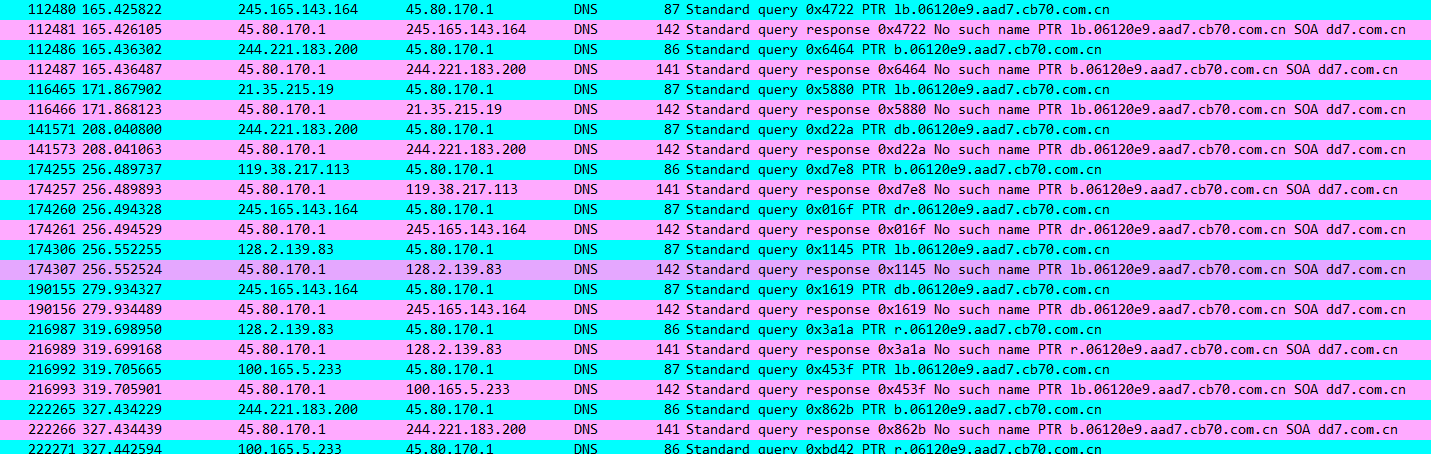
从查询结果看,数据包中确实存在PTR查询,但是查询并不具备攻击特征,其查询的是域名而不是大量的查询保留IP地址,可能不是攻击,保留,之后再做判断。
沿着之前找出的三种攻击的思路,继续在非45.80.170.1的流量上进行分析。
针对NSEC记录进行分析,发现大部分流量是存在NSEC3记录的,说明已经做了防护,那么是否存在NSEC记录呢?
dns.resp.type == 47

仅仅利用类型筛选发现被反射攻击利用的服务器也存在这个问题,需要进一步筛选。
dns.resp.type == 47 && frame.len <2000

发现异常流量,确定为攻击,攻击类型为NSEC枚举。对应的服务器和客户机为
| server | client |
|---|---|
| 185.25.160.3 | 6.116.183.244 |
对其流量进行分析发现存在一种奇怪的流量,DNS动态更新记录,感觉可能存在问题。
这部分流量在主要服务器45.80.170.1和其他服务器上都存在,对其解析请求和回应进行分析,没有确定具体的攻击类型。综合考虑,目前已经找出四种攻击,疑似攻击的PTR记录并具备攻击特征,那么这个有很大可能是攻击。主要的查询主机为18.100.48.86。
通过对RFC的解读,发现在DNS更新时是有先决条件的,但这部分流量大部分是不具备的,那么可能是攻击者利用DNS的更新机制,将目标IP进行更换,形成攻击。
现在再次确认的攻击有NSEC枚举,PTR反查不具有攻击特征,那么选择DNS dynamic update进行提交,提交非主要服务器的流量。
则目前确认的攻击为
| attackid | description |
|---|---|
| 1 | DNS zone transfer |
| 2 | DNS Amplification Attack |
| 3 | DNS cache pollution |
| 4 | DNS dynamic update |
| 5 | NSEC enumeration |
前3种攻击流量不变,增加后两种,其中DNS dynamic update具有4091条,NSEC enumeration具有74条。
得分:90.909
结合第一次提交,说明攻击类型确定为这五种,且两次提交每次的扣分在5分左右,说明攻击流量已经大部分被找出,接下来进行进一步的筛选。
对3种攻击进行筛选,DNS zone transfer和DNS cache pollution数量较少,且特征较明显,应该不会错选或遗漏。对于DNS Amplification Attack,存在一个问题,就是在主要服务器45.80.170.1也有一部分疑似攻击流量,第一次提交仅仅是将其种一部分加入答案,现在将主要服务的全部疑似流量加入。
则现在的DNS Amplification Attack攻击流量有41551条,其余攻击流量不变。
得分:90.57
分数下降,说明加入的流量是错误的,并且由两次的分差和本次增加的流量条数,结合得分计算公式,可以估算DNS Amplification Attack流量的总条数在32000条左右,数字并不确切,但也有一定的参考依据。
第三次提交确定主要服务器的放大流量是误判流量,则将放大流量中主要服务器相关流量删除,提交3种攻击分类。
第四次提交得分为:59.97。确定前三种攻击的主要攻击流量。
对后两种攻击,NSEC枚举的数量较少,且特征明显,不容易误判。但DNS dynamic update情况比较复杂,第一,仅对主机18.100.48.86的响应的种类就有很多;第二,也存在主要服务器的响应。首先考虑不同类型的响应的区分度。
在分析时发现请求数大于响应数,可能存在某些请求没有接收到响应。响应的类型一共有五种,数量最多的为拒绝,根据得分情况,保留占比大的拒绝响应,将其他的响应的请求包删除,进行提交。此时DNS dynamic update攻击流量数量为3381条。
第五次提交得分为:93.35。分析得分后发现得分降低,说明删除的流量中正确流量占大部分,且扣分达到了7分,说明这种攻击存在较大部分流量没有找到。
考虑主要服务器上的更新流量,经过分析,发现其对应的主机有两台237.205.156.233和19.220.251.87,并且请求流量数量不同,前者具有535条,后者414条,决定将其共同提交,可以根据分数变化,确定最终的攻击流量。此时DNS dynamic update攻击流量数量为4345条。
在第五次提交的基础上,第六次提交得分为:97.1,得分提高4分,确定新增加的全部为攻击流量。
修改最终结果,将第五次提交中删除的部分添加至第六次提交答案中,最终攻击流量确定。
攻击类型为
| attackid | description |
|---|---|
| 1 | DNS zone transfer |
| 2 | DNS Amplification Attack |
| 3 | DNS cache pollution |
| 4 | DNS dynamic update |
| 5 | NSEC enumeration |
其中,DNS zone transfer包括5298条,DNS Amplification Attack包括33200条,DNS cache pollution包括34194条,DNS dynamic update包括5055条,NSEC enumeration包括72条。
题目二 DGA域名家族聚类
0x00 题目解读
从官网给出的信息是对DNS流量中的DGA域名进行识别并且进行家族聚类,给出的数据包依然是pcap文件,粗略观察可以看出,数据包中存在明显的NXDomain的响应,确定目标。
实验方法在实验过程中逐步完善,但局限于比赛提交次数,一部分实验方法的结果并没有经过验证,这里尽可能介绍实验中使用的方法,希望赛后可能得到进一步的确定。
实验使用环境参数:
- python3
- sklearn
- keras2.2.4
- pands 0.22
- numpy 1.15
0x01 DGA域名识别
首先将提供的pcap数据包进行处理,使其比较方便进行下一步的操作,这里进行的操作是选取数据包中有用的数据,将其保存为csv文件。采用和题目一类似的方式将数据提取出来。
在进行DGA域名识别时,从两个方面进行考虑:特征分类和先验经验。
确定区分DGA域名与正常域名的原则:
DGA域名的特点是是大部分是随机生成的字符串,所以其可读性非常差,为了确定其可读性,我们这采用元音或辅音字母比例,在正常的单词中,为了更好的发音,元音和辅音存在配合关系,不会出现非常多的连续辅音或元音的情况;隐马尔科夫模型(HMM)计算字符串的转移概率;香农熵计算字符串的混乱程度。
考虑到域名避免与现有域名产生较多的碰撞,DGA域名选取的长度较长。
从DGA解析的角度出发,当感染主机运行DGA算法,并且尝试连接DAG域名时,其解析流量中会出现大量的NXDomain的解析响应,因为大部分的DGA域名都不会被解析到,之后攻击者在展开攻击后注册了某个域名,才会出现解析成功的响应。所以这里从解析主机和域名解析关联两方面入手分析,对于解析主机的解析行为特征,从主机解析的域名分布及解析类型考虑。对于域名解析关联,出发点是考虑该域名的解析情况,关注域名解析总数,解析该域名的ip总数,对应每个IP解析的数量,在解析过程中的响应类型,还包括流量中的transaction id的数量,用于判断是否是重传。这里计算域名解析失败率,记录该域名在解析中失败的比例。
从上面的原则中最终确定的特征包括
| 特征名 | 含义 |
|---|---|
| domain_len | 域名长度 |
| domain_entropy | 域名香农熵 |
| domain_consonants_ratio | 域名辅音比例 |
| domain_number_ratio | 域名数字比例 |
| hmm | 域名中字符的转移概率 |
| r_code | 响应类型 |
| domain_tld | 域名顶级域 |
| domain_ip_dal | 解析该域名的IP地址解析域名的平均长度 |
| number_qry | 解析该域名的IP解析域名总数 |
| number_res_a | 该IP解析请求中记录A的数量比例 |
| domain_ip_more | 该IP地址解析域名中大于平均长度的数量比例 |
| failed_ratio | 域名解析失败率 |
| max_consonants_ratio | 最长连续辅音比例 |
| vowel_ratio | 域名中元音比例 |
| hyphen_ratio | 域名中连字符比例 |
| unique_char | 域名唯一字符数 |
| ngrams_statics | 域名 n-gram 频率分布的统计特征,包括 均值,标准差,中位数,25% percentile,75% percentile,最小值,最大值,n 取 1,2,3,故该特征最终为长度为21的向量 |
在获取特征后,使用机器学习算法进行识别,这里采用kmeans聚类算法。
对实验数据进行人工分析,利用已有知识进行数据筛选。
在对未响应域名的分析过程中,发现在未响应中存在一部分非DGA域名。如果存在一台主机反复请求一个域名,但该域名解析不成功,但从行为上看,其并不是DGA域名。另外还存在一些域名,在形式上与DGA域名非常相似,但其解析模式令人费解。如 xmbdgkqvlbnrx.co.uk,怀疑其并非是DGA域名,而是某IOT设备的域名。
对分类结果进行查看,发现其中存在一部分仅仅是字符串而不存在顶级域的解析域名,这明显并非是DGA域名。
根据观察发现和已有经验对识别结果做进一步的筛选。
0x02 DGA域名家族聚类
在通过第一步的识别获得DGA域名后,对其进行家族分类。
对于家族聚类,思路是利用主机关联性和域名特征相似性两方面综合考虑。
如果利用主机相似性进行聚类,不得不考虑的问题是:在获得数据中,一台主机仅仅产生一种DGA还是会产生多中DGA,这会影响到后面的聚类效果。
仅利用域名本身存在的字符串特征进行聚类。
基本思路:
- 同一家族的DGA域名在字符串特征上存在一定的相似性
- 直接聚类可能导致类内方差太大
考虑到如果直接聚合成大类效果可能不好,方法考虑先聚合成小类,再根据一些指标进行小类间的聚合,指标在下面介绍。
聚类算法采用的是kmeans算法,采用了47个特征。这里还利用Xmeans进行实验,以获得较好的初步聚类。
在合并指标的选择上首先考虑经常作为聚类评判标准的silhouette_score和calinski_harabaz_score,但是其是从数据的角度上进行考虑,可能对特定的问题的表现并不好。
考虑自定义的指标,首先对单个类别的评价,计算每类的方差,类内的IP重合度[对类内的每个ip计算其解析的域名,计算n个IP的解析重合度],IP聚合程度[主要IP所占比例]。
考虑类合并的指标,两类的重合IP重要度[两类中重合IP部分在各自类比中所占的比重],IP重合度[两种中重合IP的比重],合并方差波动率[先考虑将两类进行合并,查看合并前和合并后的方差波动水平]。
缺乏实验依据,在类别合并方面没有找到可以有效表示其效果的显著性指标。
计算两类IP重合度,示例代码
# 计算两类之间的相关程度
def correlation_ip_cluster(c1,c2):
#两类的ip重合度:
# 重合ip域名重合度:从重合ip中其解析的域名数量,计算比例
# 输入c1,c2为两个类别的数据
# 输出为c1,c2中重合ip与ip并集的比例
c1_ip_list = ip_list[c1.index]
c1_list = [i for inner in c1_ip_list.values for i in inner if type(i) != list]
c1_list_sup = [j for inner in c1_ip_list.values for i in inner if type(i) == list for j in i]
c1_list.extend(c1_list_sup)
c2_ip_list = ip_list[c2.index]
c2_list = [i for inner in c2_ip_list.values for i in inner if type(i) != list]
c2_list_sup = [j for inner in c2_ip_list.values for i in inner if type(i) == list for j in i]
c2_list.extend(c2_list_sup)
corr_ip = len(set(c1_list).intersection(set(c2_list)))/len((set(c1_list).union(set(c2_list))))
return corr_ip
基本思路:
- 不同主机请求相同的可疑域名,说明主机产生同类型的 DGA
- 一个域名集 被 一个主机集所共同查询,说明域名集属于同一类的可能性大
步骤:
- 生成无响应域名 NXDomains 和产生无响应域名主机 NXHosts 的关联矩阵 M,矩阵行表示主机,列表示域名,矩阵的值 Mi,j计算如下:
![m.png]()
- 计算相似矩阵 S
![sSnipaste_2019-05-31_21-13-53.png]()
- 使用 PCA 对相似矩阵,进行降维
- 基于相似性矩阵,使用 KMeans,XMeans 算法进行聚类


结果分析:
使用 XMeans 算法,分成了40个类,很多类别数目过少,和仅使用域名字符特征进行 XMeans 算法进行聚类的结果一样,结果并不理想。因此进一步,考虑结合两种方法。
本方法考虑的首要因素是主机之间的关联性,假设一台主机只产生一种DGA,那么可以将某一台主机产生的域名分为同一个家族,同时在出现一个域名被多个主机解析的情况下,那么将另一台主机解析的域名同样归入此家族。
首先计算获得所有有关联的主机及其解析的域名,发现存在大部分主机之间是没有关联的,即没有与其他主机的域名产生重合。这种情况需要利用其他手段对单个主机的类别进行合并。
利用kmeans聚类计算类别相似性
在仅仅利用主机关联进行家族分类后,得到37个类别,其中大部分是单个主机的类别,需要将其合并至其他类别中。本方法利用kmeans产生的域名相似性进行二次聚类。
利用kmeans算法,使用域名字符串特征,对DGA域名进行不同类别数的多次聚类,这里选取的类别数是[3,20]。这样可以获得18个聚类结果,然后将之前进行主机关联获得的37个类别与18个分类结果中的每一个类别进行对比,计算每个类别的域名重合度,选取最大的域名重合定义为相关类别,然后将相关类别中的IP取出,得出相关IP。
例如:当n 取5时,kmeans得到5类,将主机关联获得的37个类别中的域名分别与5类中的域名进行比较,如果前者的第一类与后者的第三类的域名重合度最高,则将后者第三类的ip与前者第一类的ip记作为相关ip。
在获得了37类的每类的相关ip集合后,利用相关ip集合与原有类别的ip集合的重合度,将重合度高的类别聚合在一起。
例如,A类的相关ip集合为{1,2,3,4},B类的ip集合为{3,4,5,6},C类的ip集合为{2,3,4,8},则A类和C类的重合度更高,则将A类和C类进行合并。
# 计算主机ip关联类别和聚类类别的关联性,输出中具有主机关联类别之间的关联关系
def ip_cluster_kmeans_k():
connected_df = pd.read_hdf('./input/connected_df_2.h5')
connected_df.drop(330,axis = 1,inplace = True)
ip_set_list,ip_cluster = ip_cluster_func(connected_df)
corr_ip_2_ip_pd = pd.DataFrame(np.array(ip_set_list).reshape([37,1]),columns=["iplist"])
for i in tqdm(range(3,22)):
feat_cluster = feat_cluster_func(i,connected_df)
corr_ip_2_ip = ip_corr(ip_cluster,feat_cluster)
corr_ip_2_ip_pd["cluster_{num}".format(num =i)] = corr_ip_2_ip
com_c_list = []
max_corr_list = []
for i in corr_ip_2_ip_pd.values[:,1:]:
max_corr = 0
com_c = 0
ip_c = pd.Series([k for j in i for k in j])
ip_ser = ip_c.value_counts()
ip_c_corr = set(ip_ser.index[ip_ser == ip_ser.max()])
for j,ip_c_list in enumerate(ip_set_list):
re_corr = len(ip_c_corr.intersection(ip_c_list)) / len(ip_c_list)
if re_corr > max_corr:
max_corr = re_corr
com_c = j
com_c_list.append(com_c)
max_corr_list.append(max_corr)
corr_ip_2_ip_pd["combination"] = com_c_list
corr_ip_2_ip_pd.to_csv("combination_ip_feat_more_cluster.csv")
return corr_ip_2_ip_pd
方向二最终得分:75
赛后反思
整体开来,能力建设团队专业性非常强,真正的做到应用数据说话,从数据中确定异常,而THUteam1和DeepDeer及我们本身都是利用足够的知识,针对性的对局部数据进行分析。
赛后看了前三名的writeup后,发现在大赛中的不足之处:
- 某些点的分析不够透彻
比赛中为脱敏数据可能对字符分布、语义、信息熵等造成影响
题目一和二中的攻击流量为人为构造,是纯净的攻击流量,在第二题的解题过程中忽视了这一点,导致开始方向出错
- 对数据流量的整体认识不足
在获得数据后,总是有主观的考虑,在这一点上,阿里云团队展现了非常强的专业性,从数据本身出发的方法更具泛化性
- 对机器学习的认识太浅薄
机器学习是一个工具,但并不是某个算法就可以解决全部问题,还需要增加对算法本质和广度的认识
- 利用现有资源能力不足
在题目二中,由于前期方向错误,浪费时间。但最大的问题其实是没有利用找到的公开数据。







发表评论
您还未登录,请先登录。
登录