
在过去的几年中,对机器学习模型的对抗攻击越来越引起人们的兴趣。通过仅对卷积神经网络的输入进行细微更改,可以输出完全不同的结果。最初的攻击是通过稍微改变输入图像的像素值来欺骗分类器以输出错误类来实现的。
在本文中提出了一种生成对抗图像块的方法,该图像块针对具有许多类内变异的目标,即人。目标是生成一个能够成功地将人隐藏在人体分类器中的图像块。攻击可能被恶意使用,以阻碍现有的监视系统,入侵者可以通过在对准监控摄像机的身体上放一块小纸板来偷偷摸摸。
从结果可以看出,系统大大降低了人体检测的精度。本文的应用程序在现实场景中也能很好地发挥作用,在该场景中,用相机拍摄图像块。本文是第一个对内部等级较高的目标(例如人)进行此类攻击的。
0x01 Absert
卷积神经网络(CNN)的兴起在计算机视觉领域取得了巨大的成功。 CNN在其中学习图像的数据驱动的端到端已证明在各种计算机视觉任务中均能获得最佳效果。由于这些体系结构的深度,神经网络能够在网络底部(数据输入的地方)学习非常基础的过滤器,而在顶部学习非常抽象的高级功能。为此,典型的CNN包含数百万个学习到的参数。尽管此方法可生成非常准确的模型,但可解释性却大大降低。确切地理解为什么网络将一个人的图像分类为一个人非常困难。
网络通过查看许多其他人的图片来了解一个人的样子。通过评估模型可以通过将模型与带有人类注释的图像进行比较,来确定该模型在人体检测方面的性能。但是,以这种方式评估模型只能告诉检测器在特定测试集上的表现如何。该测试集通常不包含旨在以错误方式操纵模型的样本,也不包含专门针对欺骗模型的样本。这对于不太可能发生攻击的应用程序(例如,针对老年人跌倒的检测)是很好的,但是在安全系统中却可能带来真正的问题。安全系统的人体检测模型中的漏洞可能用于绕过用于破坏建筑物预防措施的监视摄像机。
在本文中重点介绍了这种对人体检测系统进行攻击的风险。创建了一个小的(约40厘米×40厘米)“对抗性图像块”,用作掩盖设备以将人隐藏在检测器中。下图对此进行了演示。系统源代码可在以下网址获得:https://gitlab.com/EAVISE/adversarial-yolo

0x02 Related work
随着CNN的普及,在过去的几年中,对CNN的对抗性攻击有所增加。在本节中回顾了这类攻击的历史。首先讨论对分类器的数字攻击,然后再讨论针对人脸识别和对象检测的现实攻击。然后,简要讨论物体检测器YOLOv2,该物体检测器是攻击的目标。
分类任务早在2014年显示了对抗性攻击的存在。之后成功地产生了对分类模型的对抗攻击。使用一种能够欺骗网络的方法来对图像进行误分类,同时仅稍微更改图像的像素值,以使人眼看不到该更改。之后提出一种更快的渐变符号方法,使其更实用(更快)对图像进行对抗攻击,在更大的图像集中找到了可以对网络进行攻击的单个图像。
一种算法可以通过减少图像更改来产生攻击,并且比以前更快。他们使用超平面为输入图像的不同输出类别之间的边界建模。 另一种对抗攻击再次使用优化方法,与已经提到的攻击相比,它们在图像的准确性和差异(使用不同的规范)方面得到了证明,不是更改像素值,而是生成可以以数字方式放置在图像上以欺骗分类器的色块。没有使用一个图像,而是使用各种图像来构建类内鲁棒性。
针对停车牌分类的任务,由于停车牌可能出现的形态不同,它们会生成一个贴纸,然后将其粘贴到停车标志上,以使其无法识别。 还有一种优化3D模型纹理的方法。将不同形态的图像显示给优化器,以增强对不同姿势和光照变化的鲁棒性。然后使用3D打印机打印得到的对象。
用于人脸识别的真实世界对抗攻击中提供了真实世界对抗攻击的示例,使用可蒙骗面部识别系统的印刷眼镜。为了保证健壮性,眼镜需要在各种各样的不同姿势下工作。为此优化了眼镜上的印刷,以使它们可以处理大量图像而不是单个图像。它们还包括非可打印性分数(NPS),该分数可确保图像中使用的颜色可以由打印机表示。
用于物体检测的真实对抗攻击的目标是在Faster R-CNN检测器中检测停车标志。使用“变换期望”(EOT)(对图像进行各种变换)的概念来增强针对不同姿势的鲁棒性。
与所有针对物体检测器的攻击都将重点放在具有固定视觉模式(如交通标志)的对象上,而不考虑类别内部的变化。以前没有工作提出过一种检测方法,该方法可用于诸如人体之类的多种类别。
本文以流行的YOLOv2物体检测器为目标。 YOLO适用于更大种类的单物体检测器(以及诸如SSD之类的探测器),其中边界框,物体分数和类别分数可通过在网络上单次通过直接预测。 YOLOv2是完全卷积的,将输入的图像传递到网络,在网络中,各个层将其还原为输出网格,其分辨率比原始输入分辨率小32倍。此输出网格中的每个单元格包含五个预测(称为“锚点”),边界框包含不同的宽高比。每个锚点都包含一个向量[xoffset,yoffset,w,h,pobj,pcls1,pcls2,…,pclsn]。 xoffset和yoffset是与当前锚点相比边界框中心的位置,w和h是边界框的宽度和高度,pobj是此锚点包含对象的概率,pcls1至pclsn是使用交叉熵损失学习的对象的类评分。下图显示了此体系结构的概述。
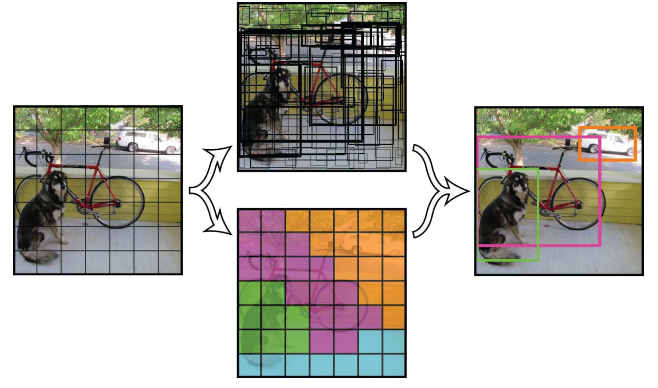
0x03 Generating adversarial patches against person detectors
这项工作的目标是创建一个能够生成可打印的对抗图像块的系统,该对抗图像块可用于欺骗人体检测器。如前所述已经表明在现实世界中对目标检测器进行对抗是可能的。本文着重于那些与停车标志的统一外观不同的人体。通过使用优化过程(在图像像素上),尝试找到一个大数据集上的图像块,该图像块有效地降低了人体检测的准确性。在本节中,深入解释了生成这些对抗图像块的过程。
优化目标包括三个部分:
•Lnps非可打印性得分(The non-printability score),代表了普通打印机可以很好地表现出图像块中颜色的好坏。如下:
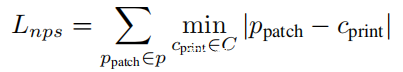
其中ppatch是图像块P中的一个像素,而cprint是一组可打印颜色C中的一种颜色。这种损失有利于图像中的颜色与该组可打印颜色中的颜色非常接近。
•Ltv(total variation)这种损失确保了优化器偏爱具有平滑颜色过渡的图像,并防止了噪点图像。可以根据图像块P计算Ltv,如下所示:
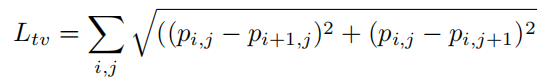
如果相邻像素相似,则得分较低;如果相邻像素不同,则得分较高。
•Lobj图像中的最大物体分数(The maximum objectness score in the image.)。数据块的目的是在图像中隐藏人物。为此,训练目标是使检测器输出的物体或类别分数最小化。此分数将在本节稍后部分中详细讨论。
这三部分中的总损失函数如下:
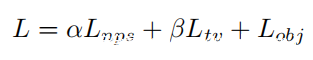
将由经验确定的因子α和β缩放的三个损失的总和,并使用Adam算法进行优化。优化器的目标是使总损耗L最小。在优化过程中,冻结网络中的所有权重,仅更改数据块中的值。在过程开始时,数据块会根据随机值进行初始化。
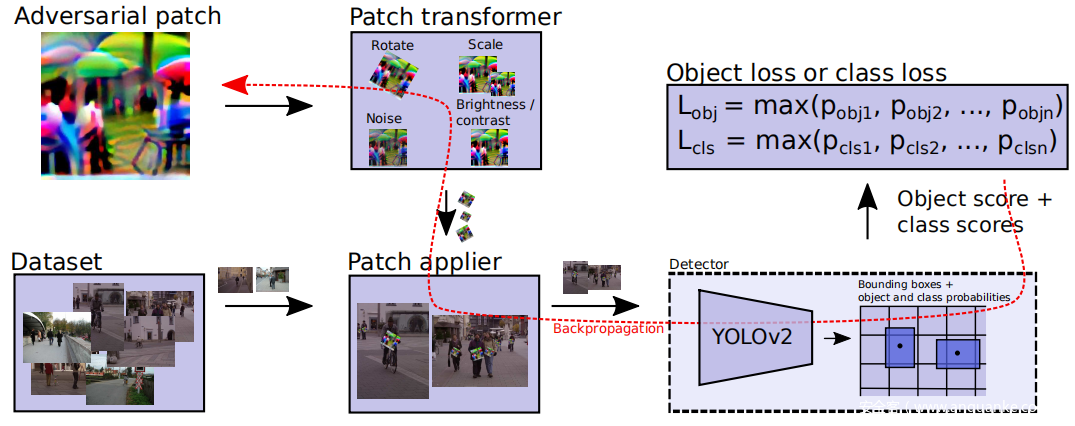
上图概述了如何计算物体损失。遵循相同的过程来计算类别概率。
A.最小化检测器输出的概率
YOLOv2物体检测器输出一个单元格网格,每个单元格包含一系列锚点(默认为5个)。每个锚点都包含边界框的位置,目标概率和类别得分。为了使检测器能够忽略人体,使用三种不同的方法进行实验:可以最小化分类人体的分类概率(下图d中的样本数据块,最小化客观评分(下图c)),或者(图b和a)的组合,尝试了所有方法。最小化类得分有将人体类切换到其他类的趋势。在实验中,使用了在MS COCO数据集上训练的YOLO检测器,发现生成的数据块在COCO数据集中被检测为另一个类别,图a和b是获取类别和目标概率的示例,在图a的情况下,学习到的数据块最终类似于“泰迪熊”类别似乎压倒了“人”类别,但是由于数据块开始类似于另一类,因此 数据块不太能转移到在不包含该类的数据集上训练的其他模型。

B.准备训练数据
与先前在停车标志上所做的工作相比,为人体类别创建对抗性数据块更具挑战性:
•人的外观变化更大:衣服,肤色,大小,姿势……与总是具有相同八角形且通常是红色的停车标志相比。
•人们可以出现在许多不同的环境中,停车标志大多出现在同一条路的街道旁。
•人的外观会因人朝向相机还是朝向相机而有所不同。
•在可以放置数据块的人体身上没有一致的地方。在停车标志上,可以轻松计算出数据块的确切位置。
在本节中将说明如何应对这些挑战。使用不同人的真实图像,工作流程如下:首先在图像数据集上运行人体目标检测器。这将产生边界框,根据检测器显示人在图像中的位置。然后,在相对于这些边界框的固定位置上,将数据块的当前版本以不同的变换应用于图像。
然后将生成的图像(与其他图像一起)送入检测器。测量仍被检测为人体的分数,将其用于计算损失函数。通过在整个网络上进行反向传播,优化器可以进一步更改色块中的像素,从而使检测器更加笨拙。
这种方法的一个有趣的副作用是不仅限于带注释的数据集。可以将任何视频或图像收集输入目标检测器以生成绑定框。这使系统也可以进行更有针对性的攻击。当从目标环境中获得可用数据时,可以简单地使用素材来生成特定于该场景的数据块。大概比常规数据集更好。
在测试中使用Inria数据集的图像。这些图像更针对全身的行人,更适合于本文的监控摄像头应用。
C.使数据块更加强大
在本文中,针对必须在现实世界中使用的数据块。这意味着它们首先被打印出来,然后由摄像机拍摄。执行此操作时,有很多因素会影响数据块的外观:灯光可能会改变,数据块可能会略微旋转,数据块相对于人的大小可能会改变,相机可能会增加噪点或使数据块稍微模糊,视角可能会有所不同。 。 。为了尽可能多地考虑这一点,先对数据块进行了一些转换,然后再将其应用于图像。执行以下随机转换:
•数据块每次旋转最多20度
•数据块随机缩放
•随机噪声放在贴片的顶部
•数据块的亮度和对比度随机更改
0x04 Results
在本节中评估数据块的有效性。通过使用训练过程中使用的相同过程(包括随机转换)将其应用于Inria测试集来评估数据块。在实验中,试图最小化一些可能隐藏人的不同参数。作为对照,还将结果与包含随机噪声的数据块进行比较,该随机噪声的评估方式与本文随机数据块完全相同。下图显示了不同数据块的结果。
OBJ-CLS的目标是最大程度地减少物体分数和类别分数的乘积,在OBJ中仅物体分数,而在CLS中仅类别分数。 NOISE是随机噪声控制数据块,而CLEAN是没有应用数据块的基线。 (因为通过在数据集上运行相同的检测器生成的边界框,得到了理想的结果。)从此PR曲线中,可以清楚地看到与随机生成的数据块(OBJ-CLS,OBJ和CLS)相比,其影响用作控件的数据块。
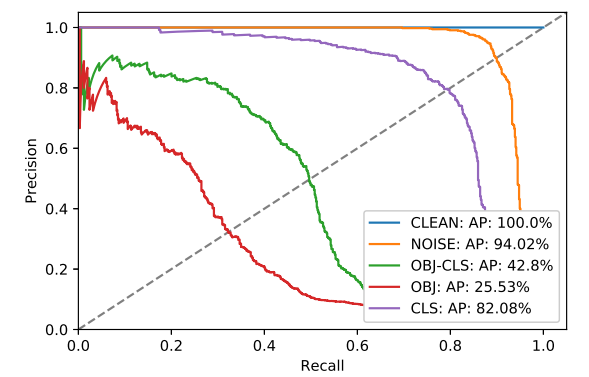
还可以看到,与使用类评分相比,最小化对象评分(OBJ)具有最大的影响(最低平均精度(AP))。
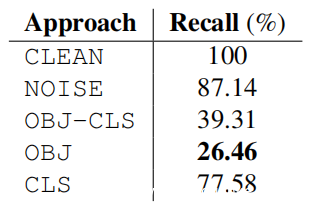
确定PR曲线上用于检测的良好工作点的一种典型方法是在PR曲线上绘制一条对角线(上图中的虚线),并查看其与PR曲线相交的位置。如果对CLEAN PR曲线执行此操作,则可以使用该工作点处的结果阈值作为参考,以查看方法将降低检测器的查全率。换句话说,问一个问题:使用本文的数据块程序可以避免监视系统生成的警报有多少?下表使用上图的缩写显示了该分析的结果。从中可以清楚地看到,使用数据块程序(OBJ-CLS,OBJ和CLS)显着降低了生成警报的数量。
下图显示了应用于Inria测试集中某些图像的数据块样本。首先将YOLOv2检测器应用于没有数据块(行1),具有随机数据块(行2)和生成最佳数据块(OBJ)(行3)的图像。在大多数情况下,数据块程序能够成功地将人体隐藏在检测器中。如果不是这种情况,则贴片未对准人的中心。这可以通过以下事实来解释:在优化过程中,贴片也仅位于边界框确定的人的中心。

在下图中测试了印刷版数据块在现实世界中的运作情况。总的来说,该数据块似乎运行良好。由于贴片在相对于将贴片保持在正确位置的包围盒的固定位置上训练的事实似乎非常重要。可以找到演示视频:https://youtu.be/MIbFvK2S9g8

0x05 Conclusion
在本文中提出了一种为人体检测器生成对抗数据块的系统,该系统可以打印出来并在现实世界中使用。通过优化图像来最大程度地减少检测器输出中与人的外貌有关的不同概率来做到这一点。在实验中比较了不同的方法,发现最大程度地减少了物体丢失会产生最有效的数据块。
从对打印出的数据块程序进行的实际测试中,还可以看到数据块程序可以很好地将人员隐藏在对物体检测器中,这表明使用类似检测器的安全系统可能会受到这种攻击。
如果将这项技术与复杂的服装模拟相结合,可以设计出T恤印花,从而使人几乎看不见自动监视摄像机(使用YOLO探测器)。
将来希望扩展这项工作。一种方法是对输入数据进行更多(仿射)变换或使用模拟数据(即将贴片作为纹理应用于人的3D模型上)。可以做更多工作的另一个领域是可转移性。当前的数据块不能很好地转移到Faster R-CNN 之类的完全不同的体系结构上,同时针对不同的体系结构进行优化可能会对此有所改善。







发表评论
您还未登录,请先登录。
登录