

前言
为了提升Windows exploitation水平,最近几个月我一直在阅读与模糊测试有关的资料,而且我越来越觉得模糊测试一件很有意思的事情。在这篇文章中,我会介绍如何建造一个简单的基于变异的模糊测试器(mutation fuzzer),并使用它寻找一些开源项目中的漏洞。
这个模糊测试器是根据 @gynvael’s在Youtube上的fuzzing教程编写的,我之前不知道Gynvael有一个视频教程,所以现在待看列表上又要添加一个新的项目了。
除此之外,Brandon Faulk’s的fuzzing教程也很棒,其实Brandon说的99%的内容我都不太明白,但是他的视频确实很吸引人。我最喜欢的是他对calc.exe和c-tags的模糊测试,他还有一个很棒的视频,是对模糊测试这个概念的介绍,在这里。
选择目标
我想找一个用C或者C++编写的二进制文件,它可以从文件中解析数据,我第一个想到的就是可以从图像中解析Exif数据的二进制文件。同时,我希望目标文件不涉及任何安全问题,因为我会直接将模糊测试的结果发布出来。
基本上来说,Exif文件格式与JPEG文件格式类似。根据JPEG规范,Exif会向JPEG中插入一些图像/数字信息以及缩略图信息,所以你可以像查看JPEG文件一样,使用兼容JPEG的浏览器、图像查看器或者图像修改软件来查看Exif格式的图像文件。
——来自
https://www.media.mit.edu/pia/Research/deepview/exif.html
因为Exif是根据JPEG规范向图像中插入元数据信息,因此存在不少用来解析这类数据的程序。
开始开发
我使用Python3编写这个基于变异的模糊测试器,对进行了Exif填充的JPEG文件进行巧妙的(或者也不是那么巧妙)修改,然后传给解析器,看是否发生崩溃。除此之外,我还会编写一个适用于Kali x86版本的代码。
首先,我们需要一个正常的进行了Exif填充的JPEG文件。我在谷歌上搜索了“Sample JPEG with Exif”,然后找到了这个项目,接下来的测试使用的是Canon_400.jpg这张图片。
JPEG以及EXIF规范
在开始编写Python代码之前,为了避免对图像造成过大的破坏,我们先来看一下JPEG和EXIF规范,否则可能出现解析器无法解析的情况。
在上面引用的规范概述中,提到所有的JPEG图像均以0xFFD8开头,以0xFFD9结尾,开头的这几个字节叫做magic bytes,在*Nix系统上可以直接通过这几个字节判断文件类型。
root@kali:~# file Canon_40D.jpg
Canon_40D.jpg: JPEG image data, JFIF standard 1.01, resolution (DPI), density 72x72, segment length 16, Exif Standard: [TIFF image data, little-endian, direntries=11, manufacturer=Canon, model=Canon EOS 40D, orientation=upper-left, xresolution=166, yresolution=174, resolutionunit=2, software=GIMP 2.4.5, datetime=2008:07:31 10:38:11, GPS-Data], baseline, precision 8, 100x68, components 3
如果去掉文件名中的.jpg,会得到同样的输出:
root@kali:~# file Canon
Canon: JPEG image data, JFIF standard 1.01, resolution (DPI), density 72x72, segment length 16, Exif Standard: [TIFF image data, little-endian, direntries=11, manufacturer=Canon, model=Canon EOS 40D, orientation=upper-left, xresolution=166, yresolution=174, resolutionunit=2, software=GIMP 2.4.5, datetime=2008:07:31 10:38:11, GPS-Data], baseline, precision 8, 100x68, components 3
如果对该文件使用hexdump,我们可以发现开头和结尾的字节确实是0xFFD8和0xFFD9。
root@kali:~# hexdump Canon
0000000 d8ff e0ff 1000 464a 4649 0100 0101 4800
------SNIP------
0001f10 5aed 5158 d9ff
该规范中还提到一个有趣的信息,所有的“标记(marker)”都是以0xFF开头的,下面是几个已知的静态标记:
- 图像开始(SOI)标记:
0xFFD8 - APP1标记:
0xFFE1 - 通用标记:
0xFFXX - 图像结束(EOI)标记:
0xFFD9
因为我们并不想改变图像的长度或者文件类型,所以我们希望保持SOI和EOI标记完整不变。比如说,我们不会在图像的中间插入0xFFD9,因为这样会直接截断图像,使解析器工作异常。或者说我这样的理解并不正确,我们也可以随机的插入EOI标记?
开始编写模糊测试器
我们要做的第一件事是从JPEG文件中提取出所有字节信息,该JPEG文件就是我们接下来要进行修改的有效输入样本。
代码开头部分如下:
#!/usr/bin/env python3
import sys
# read bytes from our valid JPEG and return them in a mutable bytearray
def get_bytes(filename):
f = open(filename, "rb").read()
return bytearray(f)
if len(sys.argv) < 2:
print("Usage: JPEGfuzz.py <valid_jpg>")
else:
filename = sys.argv[1]
data = get_bytes(filename)
我们还可以看一下这个字节数组的内容是什么,读入文件后,打印数组的前10个字节。加上下面的临时代码用于查看字节值:
else:
filename = sys.argv[1]
data = get_bytes(filename)
counter = 0
for x in data:
if counter < 10:
print(x)
counter += 1
运行以上代码可以发现,实际上我们处理的是一些整齐的转换为十进制的整数,这样看起来要比“处理一张图片”简单多了。
root@kali:~# python3 fuzzer.py Canon_40D.jpg
255
216
255
224
0
16
74
70
73
70
现在看一下我们能不能用这个字节数组重新创建一个新的JPEG文件,如以下代码所示:
def create_new(data):
f = open("mutated.jpg", "wb+")
f.write(data)
f.close()
现在文件夹里应该已经有了一个mutated.jpg文件,我们对这两个文件求哈希值,看看是否相同。
root@kali:~# shasum Canon_40D.jpg mutated.jpg
c3d98686223ad69ea29c811aaab35d343ff1ae9e Canon_40D.jpg
c3d98686223ad69ea29c811aaab35d343ff1ae9e mutated.jpg
太棒了,两个文件是一样的。现在我们要在创建mutated.jpg之前,先对其中的数据进行修改,即图像文件变异。
图像文件变异
因为要保持模糊测试器的简洁,我们只实现两种变异方法,分别为:
- 位翻转
- 使用Gynvael的“Magic Numbers”覆盖字节序列
先介绍位翻转方法,255(或者说0xFF)的二进制格式是11111111,如果我们翻转其中的任意一位,例如索引2处的位,会得到11011111,这个新的数字是223即0xDF。
也可以在0-255之间随机选择一个数,覆盖任意一个字节,我不知道这两种方法有多大的区别。我的直觉告诉我这两个方法其实差不多。
现在,假设我们只想翻转1%字节中的位,该个数可以由如下代码计算得出:
num_of_flips = int((len(data) - 4) * .01)
因为文件的开头和结尾分别存在两个字节的SOI和EOI标记,我们希望保持这四个字节不动,所以不考虑这四个字节,因此要在字节数组的长度上减去4。
下一步我们要在所有索引值中随机选出要进行位翻转的索引值。首先创建一个所有可改变的索引值的范围,然后在里面随机选出num_of_flips个进行位翻转。
indexes = range(4, (len(data) - 4))
chosen_indexes = []
# iterate selecting indexes until we've hit our num_of_flips number
counter = 0
while counter < num_of_flips:
chosen_indexes.append(random.choice(indexes))
counter += 1
在脚本中添加import random,同时添加下面的调试输出语句,以确保程序正常工作。
print("Number of indexes chosen: " + str(len(chosen_indexes)))
print("Indexes chosen: " + str(chosen_indexes))
现在整个函数应该是这样的:
def bit_flip(data):
num_of_flips = int((len(data) - 4) * .01)
indexes = range(4, (len(data) - 4))
chosen_indexes = []
# iterate selecting indexes until we've hit our num_of_flips number
counter = 0
while counter < num_of_flips:
chosen_indexes.append(random.choice(indexes))
counter += 1
print("Number of indexes chosen: " + str(len(chosen_indexes)))
print("Indexes chosen: " + str(chosen_indexes))
执行上述代码会得到如下结果:
root@kali:~# python3 fuzzer.py Canon_40D.jpg
Number of indexes chosen: 79
Indexes chosen: [6580, 930, 6849, 6007, 5020, 33, 474, 4051, 7722, 5393, 3540, 54, 5290, 2106, 2544, 1786, 5969, 5211, 2256, 510, 7147, 3370, 625, 5845, 2082, 2451, 7500, 3672, 2736, 2462, 5395, 7942, 2392, 1201, 3274, 7629, 5119, 1977, 2986, 7590, 1633, 4598, 1834, 445, 481, 7823, 7708, 6840, 1596, 5212, 4277, 3894, 2860, 2912, 6755, 3557, 3535, 3745, 1780, 252, 6128, 7187, 500, 1051, 4372, 5138, 3305, 872, 6258, 2136, 3486, 5600, 651, 1624, 4368, 7076, 1802, 2335, 3553]
接下来我们需要对上述索引位置的字节进行修改,即位翻转。我用了一种比较笨的方式实现了该功能,你也可以用其他的方法。首先我们将这些索引位置的字节转化为了二进制字符串,在前面补零形成8位的长度。可以使用如下代码,将字节值(十进制数字)转换为二进制字符串,如果长度小于8位,就在前面补零,最后一行代码用于输出调试(译者注:下段代码中最后应该有一行输出语句的,类似print(current),作者没有加)。
for x in chosen_indexes:
current = data[x]
current = (bin(current).replace("0b",""))
current = "0" * (8 - len(current)) + current
执行上述代码,输出为
root@kali:~# python3 fuzzer.py Canon_40D.jpg
10100110
10111110
10010010
00110000
01110001
00110101
00110010
-----SNIP-----
对上面的每个值,我们需要随意选择一位并进行翻转,例如第一个值10100110,如果我们选择了索引值0,该处的位数原本是1,那就应该修改为0。
还有一点需要考虑,这些数值实际上并不是整型数,而是字符串,所以最后我们还需要把它们转换为整型数。
首先创建一个空的列表,把每位上的数字加到列表中,翻转选择的位,再构建新的字符串(之所以要使用列表,是因为字符串是不可变的)。最后,将字符串转为整型数,将值返回给create_new()函数,用以创建新的JPEG文件。
整个脚本如下:
#!/usr/bin/env python3
import sys
import random
# read bytes from our valid JPEG and return them in a mutable bytearray
def get_bytes(filename):
f = open(filename, "rb").read()
return bytearray(f)
def bit_flip(data):
num_of_flips = int((len(data) - 4) * .01)
indexes = range(4, (len(data) - 4))
chosen_indexes = []
# iterate selecting indexes until we've hit our num_of_flips number
counter = 0
while counter < num_of_flips:
chosen_indexes.append(random.choice(indexes))
counter += 1
for x in chosen_indexes:
current = data[x]
current = (bin(current).replace("0b",""))
current = "0" * (8 - len(current)) + current
indexes = range(0,8)
picked_index = random.choice(indexes)
new_number = []
# our new_number list now has all the digits, example: ['1', '0', '1', '0', '1', '0', '1', '0']
for i in current:
new_number.append(i)
# if the number at our randomly selected index is a 1, make it a 0, and vice versa
if new_number[picked_index] == "1":
new_number[picked_index] = "0"
else:
new_number[picked_index] = "1"
# create our new binary string of our bit-flipped number
current = ''
for i in new_number:
current += i
# convert that string to an integer
current = int(current,2)
# change the number in our byte array to our new number we just constructed
data[x] = current
return data
# create new jpg with mutated data
def create_new(data):
f = open("mutated.jpg", "wb+")
f.write(data)
f.close()
if len(sys.argv) < 2:
print("Usage: JPEGfuzz.py <valid_jpg>")
else:
filename = sys.argv[1]
data = get_bytes(filename)
mutated_data = bit_flip(data)
create_new(mutated_data)
分析变异结果
执行完脚本后,对新生成的图像执行shasum并与原始图像对比:
root@kali:~# shasum Canon_40D.jpg mutated.jpg
c3d98686223ad69ea29c811aaab35d343ff1ae9e Canon_40D.jpg
a7b619028af3d8e5ac106a697b06efcde0649249 mutated.jpg
哈希值不同,看起来文件确实发生了变化。接下来我们使用一个叫做Beyond Compare,即bcompare的程序对两者进行比较,结果会对两个文件中不同的十六进制值进行标注。
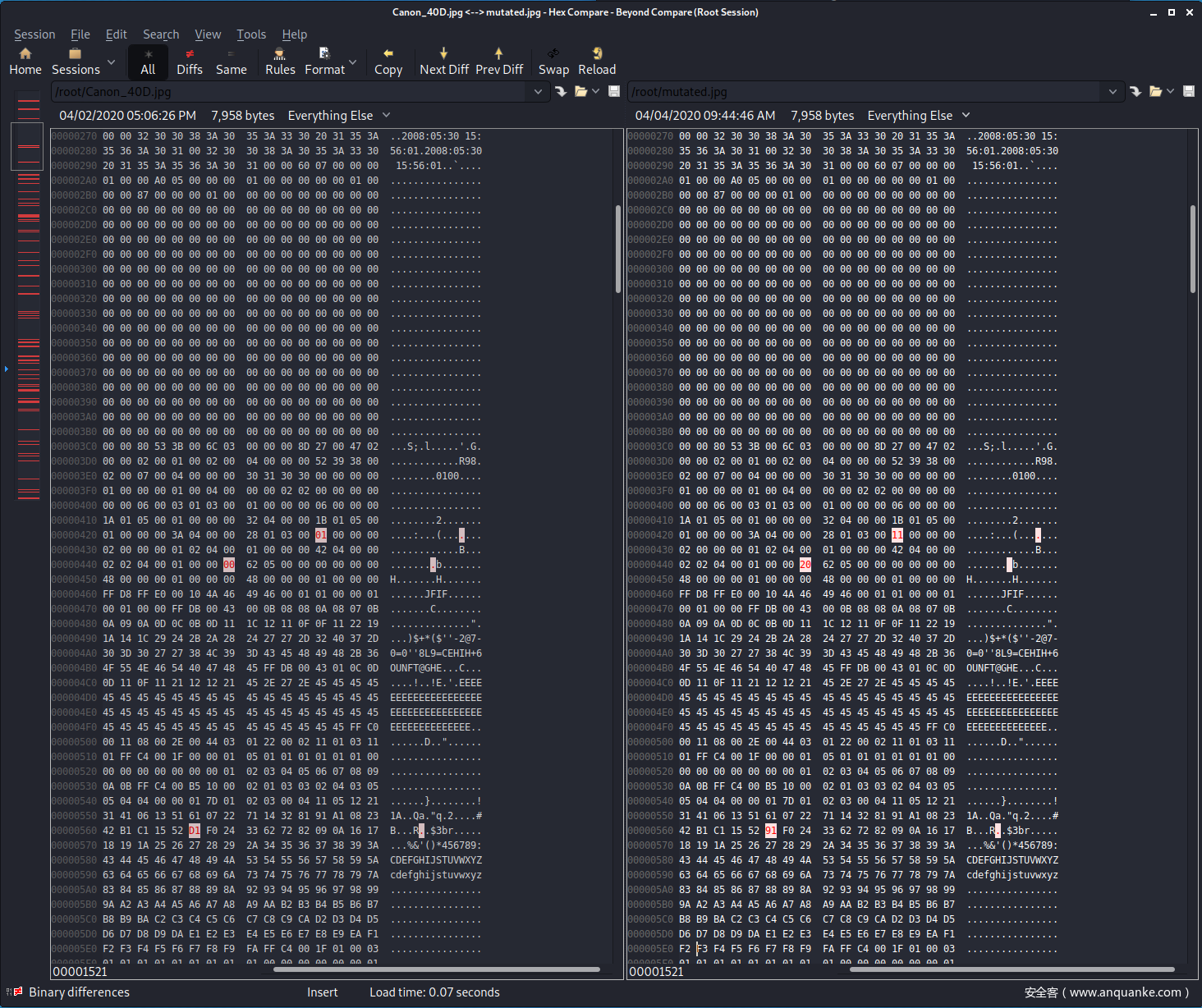
原始图像在左边,修改后的图像在右边。可以看到,仅仅一个屏幕这么大的地方就已经有3个不同位置的字节发生了位翻转。
可以证明该变异方法确实起作用了。下面我们实现第二种变异方法。
Gynvael的Magic Numbers
我们上文提到过Gynvael的fuzzing基础视频,在这个视频中,他提到了几个会对程序产生破坏性影响的“magic number”,这些数字通常与数据类型大小以及算数引起的错误有关,涉及到的数字有:
0xFF0x7F0x000xFFFF0x00000xFFFFFFFF0x00000000-
0x80000000——最小的32位整型数 -
0x40000000——数值的一半 -
0x7FFFFFFF——最大的32位整型数
如果在malloc()或者其他类型的操作中存在任何这些类型数值的算术运算,则很容易发生溢出。比如说,如果你在一个一字节的寄存器上将0x1加到0xFF上,数值会回滚到0x00,HEVD有一个类似的整数溢出漏洞。
如果我们的模糊测试器选择0x7FFFFFFF作为magic number,这个值有四字节长,所以在我们找到数组中的一个字节索引后,我们需要覆盖该字节以及接下来连续的三个字节。下面我们开始实现这个变异方法了。
实现第二种变异方法
首先我们要像Gynvael一样创建一个元组列表,元组中的第一个数字是magic number的字节大小,第二个数字是magic number中第一个字节的十进制值。
def magic(data):
magic_vals = [
(1, 255),
(1, 255),
(1, 127),
(1, 0),
(2, 255),
(2, 0),
(4, 255),
(4, 0),
(4, 128),
(4, 64),
(4, 127)
]
picked_magic = random.choice(magic_vals)
print(picked_magic)
执行上述代码,可以看到函数随机选择了一个元组:
root@kali:~# python3 fuzzer.py Canon_40D.jpg
(4, 64)
root@kali:~# python3 fuzzer.py Canon_40D.jpg
(4, 128)
root@kali:~# python3 fuzzer.py Canon_40D.jpg
(4, 0)
root@kali:~# python3 fuzzer.py Canon_40D.jpg
(2, 255)
root@kali:~# python3 fuzzer.py Canon_40D.jpg
(4, 0)
现在我们需要用这个选择的magic number随机覆盖JPEG文件中的1-4个字节,像前一个方法一样,我们设置可能的索引值范围,选择一个索引值,然后使用picked_magic覆盖该索引值处的字节。
举例来说,如果我们选择的元组是(4, 128),我们知道这是一个四字节数,magic number是0x80000000,所以接下来的操作是:
byte[x] = 128
byte[x+1] = 0
byte[x+2] = 0
byte[x+3] = 0
总结下来,方程如下:
def magic(data):
magic_vals = [
(1, 255),
(1, 255),
(1, 127),
(1, 0),
(2, 255),
(2, 0),
(4, 255),
(4, 0),
(4, 128),
(4, 64),
(4, 127)
]
picked_magic = random.choice(magic_vals)
length = len(data) - 8
index = range(0, length)
picked_index = random.choice(index)
# here we are hardcoding all the byte overwrites for all of the tuples that begin (1, )
if picked_magic[0] == 1:
if picked_magic[1] == 255: # 0xFF
data[picked_index] = 255
elif picked_magic[1] == 127: # 0x7F
data[picked_index] = 127
elif picked_magic[1] == 0: # 0x00
data[picked_index] = 0
# here we are hardcoding all the byte overwrites for all of the tuples that begin (2, )
elif picked_magic[0] == 2:
if picked_magic[1] == 255: # 0xFFFF
data[picked_index] = 255
data[picked_index + 1] = 255
elif picked_magic[1] == 0: # 0x0000
data[picked_index] = 0
data[picked_index + 1] = 0
# here we are hardcoding all of the byte overwrites for all of the tuples that being (4, )
elif picked_magic[0] == 4:
if picked_magic[1] == 255: # 0xFFFFFFFF
data[picked_index] = 255
data[picked_index + 1] = 255
data[picked_index + 2] = 255
data[picked_index + 3] = 255
elif picked_magic[1] == 0: # 0x00000000
data[picked_index] = 0
data[picked_index + 1] = 0
data[picked_index + 2] = 0
data[picked_index + 3] = 0
elif picked_magic[1] == 128: # 0x80000000
data[picked_index] = 128
data[picked_index + 1] = 0
data[picked_index + 2] = 0
data[picked_index + 3] = 0
elif picked_magic[1] == 64: # 0x40000000
data[picked_index] = 64
data[picked_index + 1] = 0
data[picked_index + 2] = 0
data[picked_index + 3] = 0
elif picked_magic[1] == 127: # 0x7FFFFFFF
data[picked_index] = 127
data[picked_index + 1] = 255
data[picked_index + 2] = 255
data[picked_index + 3] = 255
return data
分析第二种方法的变异结果
执行脚本,并使用Beyond Compare进行分析,可以看到有一个二进制值0xA6 0X76被值0xFF 0XFF覆盖了。

这正是我们想要的结果
开始模糊测试
现在我们已经有了两种进行可靠变异的方法,接下来需要做的是:
- 使用变异方法对数据进行修改;
- 用变异后数据创建新的图像;
- 将变异后图像传给二进制文件进行解析;
- 捕捉任何
Segmentation faults,并记录引发错误的图像。
目标程序
为了找到合适的目标二进制程序,我在谷歌搜索site:github.com "exif" language:c,该语句在github上查找用C编写且包含’exif’索引的项目工程。
我很快找到了一个项目:https://github.com/mkttanabe/exif
使用git clone以及building with gcc对该项目进行编译。(为了方便使用,我将编译后的二进制文件放到了/usr/bin中。)
先看一下这个程序怎么处理原始的有效JPEG文件:
root@kali:~# exif Canon_40D.jpg -verbose
system: little-endian
data: little-endian
[Canon_40D.jpg] createIfdTableArray: result=5
{0TH IFD} tags=11
tag[00] 0x010F Make
type=2 count=6 val=[Canon]
tag[01] 0x0110 Model
type=2 count=14 val=[Canon EOS 40D]
tag[02] 0x0112 Orientation
type=3 count=1 val=1
tag[03] 0x011A XResolution
type=5 count=1 val=72/1
tag[04] 0x011B YResolution
type=5 count=1 val=72/1
tag[05] 0x0128 ResolutionUnit
type=3 count=1 val=2
tag[06] 0x0131 Software
type=2 count=11 val=[GIMP 2.4.5]
tag[07] 0x0132 DateTime
type=2 count=20 val=[2008:07:31 10:38:11]
tag[08] 0x0213 YCbCrPositioning
type=3 count=1 val=2
tag[09] 0x8769 ExifIFDPointer
type=4 count=1 val=214
tag[10] 0x8825 GPSInfoIFDPointer
type=4 count=1 val=978
{EXIF IFD} tags=30
tag[00] 0x829A ExposureTime
type=5 count=1 val=1/160
tag[01] 0x829D FNumber
type=5 count=1 val=71/10
tag[02] 0x8822 ExposureProgram
type=3 count=1 val=1
tag[03] 0x8827 PhotographicSensitivity
type=3 count=1 val=100
tag[04] 0x9000 ExifVersion
type=7 count=4 val=0 2 2 1
tag[05] 0x9003 DateTimeOriginal
type=2 count=20 val=[2008:05:30 15:56:01]
tag[06] 0x9004 DateTimeDigitized
type=2 count=20 val=[2008:05:30 15:56:01]
tag[07] 0x9101 ComponentsConfiguration
type=7 count=4 val=0x01 0x02 0x03 0x00
tag[08] 0x9201 ShutterSpeedValue
type=10 count=1 val=483328/65536
tag[09] 0x9202 ApertureValue
type=5 count=1 val=368640/65536
tag[10] 0x9204 ExposureBiasValue
type=10 count=1 val=0/1
tag[11] 0x9207 MeteringMode
type=3 count=1 val=5
tag[12] 0x9209 Flash
type=3 count=1 val=9
tag[13] 0x920A FocalLength
type=5 count=1 val=135/1
tag[14] 0x9286 UserComment
type=7 count=264 val=0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 (omitted)
tag[15] 0x9290 SubSecTime
type=2 count=3 val=[00]
tag[16] 0x9291 SubSecTimeOriginal
type=2 count=3 val=[00]
tag[17] 0x9292 SubSecTimeDigitized
type=2 count=3 val=[00]
tag[18] 0xA000 FlashPixVersion
type=7 count=4 val=0 1 0 0
tag[19] 0xA001 ColorSpace
type=3 count=1 val=1
tag[20] 0xA002 PixelXDimension
type=4 count=1 val=100
tag[21] 0xA003 PixelYDimension
type=4 count=1 val=68
tag[22] 0xA005 InteroperabilityIFDPointer
type=4 count=1 val=948
tag[23] 0xA20E FocalPlaneXResolution
type=5 count=1 val=3888000/876
tag[24] 0xA20F FocalPlaneYResolution
type=5 count=1 val=2592000/583
tag[25] 0xA210 FocalPlaneResolutionUnit
type=3 count=1 val=2
tag[26] 0xA401 CustomRendered
type=3 count=1 val=0
tag[27] 0xA402 ExposureMode
type=3 count=1 val=1
tag[28] 0xA403 WhiteBalance
type=3 count=1 val=0
tag[29] 0xA406 SceneCaptureType
type=3 count=1 val=0
{Interoperability IFD} tags=2
tag[00] 0x0001 InteroperabilityIndex
type=2 count=4 val=[R98]
tag[01] 0x0002 InteroperabilityVersion
type=7 count=4 val=0 1 0 0
{GPS IFD} tags=1
tag[00] 0x0000 GPSVersionID
type=1 count=4 val=2 2 0 0
{1ST IFD} tags=6
tag[00] 0x0103 Compression
type=3 count=1 val=6
tag[01] 0x011A XResolution
type=5 count=1 val=72/1
tag[02] 0x011B YResolution
type=5 count=1 val=72/1
tag[03] 0x0128 ResolutionUnit
type=3 count=1 val=2
tag[04] 0x0201 JPEGInterchangeFormat
type=4 count=1 val=1090
tag[05] 0x0202 JPEGInterchangeFormatLength
type=4 count=1 val=1378
0th IFD : Model = [Canon EOS 40D]
Exif IFD : DateTimeOriginal = [2008:05:30 15:56:01]
可以看到程序解析出了所有的tag,并输出了与每个tag有关的字节值,这正是我们需要的功能。
寻找段错误
理想情况下,我们希望的是给该二进制文件传入变异数据,引发该程序的段错误,这意味着程序中存在漏洞。问题在于,在我监控stdout以及stderr时,一个Segmentation fault都没有出现,之所以会出现这个问题,是因为Segmentation fault信息来源于命令行而不是我们的二进制文件,即命令行收到一个SIGSEGV的信号,作为响应输出了段错误信息。
我想到的一种监控段错误的方法是使用python模块pexpect中的run()方法以及pipes模块中的quote()方法。
我们要添加一个新函数,该函数包含一个counter参数,用来记录模糊测试的迭代次数,另一个参数表示变异后data。如果run()的输出中出现Segentation,就把变异后数据写入到文件中,该文件就是能引起二进制文件崩溃的JPEG图像。
接下来创建一个叫做crashes的文件夹,所有引发崩溃的图像都保存在里面,命名格式为crash.<fuzzing iteration (counter)>.jpg,所以如果模糊测试的迭代次数是100的话,应该有一个文件/crashes/crash.100.jpg。
终端的输出每100次迭代另起一行,函数如下:
def exif(counter,data):
command = "exif mutated.jpg -verbose"
out, returncode = run("sh -c " + quote(command), withexitstatus=1)
if b"Segmentation" in out:
f = open("crashes/crash.{}.jpg".format(str(counter)), "ab+")
f.write(data)
if counter % 100 == 0:
print(counter, end="r")
需要修改脚本中最下面的代码执行流程,实现多次的模糊测试,当时执行到第1000次迭代时,停止模糊测试。同时,模糊测试器要随机选择变异方法,或者是位翻转,或者使用magic number。现在执行脚本并查看crashes文件夹中的内容。
执行完毕后,我们引发了30个崩溃!
root@kali:~/crashes# ls
crash.102.jpg crash.317.jpg crash.52.jpg crash.620.jpg crash.856.jpg
crash.129.jpg crash.324.jpg crash.551.jpg crash.694.jpg crash.861.jpg
crash.152.jpg crash.327.jpg crash.559.jpg crash.718.jpg crash.86.jpg
crash.196.jpg crash.362.jpg crash.581.jpg crash.775.jpg crash.984.jpg
crash.252.jpg crash.395.jpg crash.590.jpg crash.785.jpg crash.985.jpg
crash.285.jpg crash.44.jpg crash.610.jpg crash.84.jpg crash.987.jpg
我们可以用一句命令测试该结果:root@kali:~/crashes# for i in *.jpg; do exif "$i" -verbose > /dev/null 2>&1; done,注意,我们可以把STDOUT和STDERR重定向到/drv/null上,因为段错误来源于命令行,而不是二进制文件。
一句话命令输出结果:
root@kali:~/crashes# for i in *.jpg; do exif "$i" -verbose > /dev/null 2>&1; done
Segmentation fault
Segmentation fault
Segmentation fault
Segmentation fault
Segmentation fault
Segmentation fault
Segmentation fault
-----SNIP-----
我省略了一部分,但是确实是30个段错误,所以一切都在按计划进行。
不同崩溃的分类
现在我们有30个崩溃,以及引起崩溃的JPEG文件,下一步要分析这些崩溃的不同类型,这里我们要使用我从Brandon Faulk的视频中学到的知识。通过Brandon Faulk的崩溃示例,我发现大多数崩溃都是因为bit_flip()变异方法而不是magic()变异方法。这点很有意思,作为测试,我们可以在过程中取消选择变异方法的随机性,直接使用magic()方法执行100,000次迭代,看看会发生多少次崩溃。
使用ASan分析崩溃类型
ASan就是“地址消毒(Address Sanitizer)”,是一个装有最新版gcc的内存检测工具,用户可以使用-fsanitize=address标签对二进制文件进行编译,这样如果发生了内存访问错误,用户可以获得一份十分详尽的事件信息。
为了使用ASan,我按照这个教程 ,使用cc -fsanitize=address -ggdb -o exifsan sample_main.c exif.c重新编译了exif。
之后我把exifsan移动到/usr/bin,如果使用这个新编译的二进制文件处理引发崩溃的图像,会获得如下输出结果:
root@kali:~/crashes# exifsan crash.252.jpg -verbose
system: little-endian
data: little-endian
=================================================================
==18831==ERROR: AddressSanitizer: heap-buffer-overflow on address 0xb4d00758 at pc 0x00415b9e bp 0xbf8c91f8 sp 0xbf8c91ec
READ of size 4 at 0xb4d00758 thread T0
#0 0x415b9d in parseIFD /root/exif/exif.c:2356
#1 0x408f10 in createIfdTableArray /root/exif/exif.c:271
#2 0x4076ba in main /root/exif/sample_main.c:63
#3 0xb77d0ef0 in __libc_start_main ../csu/libc-start.c:308
#4 0x407310 in _start (/usr/bin/exifsan+0x2310)
0xb4d00758 is located 0 bytes to the right of 8-byte region [0xb4d00750,0xb4d00758)
allocated by thread T0 here:
#0 0xb7aa2097 in __interceptor_malloc (/lib/i386-linux-gnu/libasan.so.5+0x10c097)
#1 0x415a9f in parseIFD /root/exif/exif.c:2348
#2 0x408f10 in createIfdTableArray /root/exif/exif.c:271
#3 0x4076ba in main /root/exif/sample_main.c:63
#4 0xb77d0ef0 in __libc_start_main ../csu/libc-start.c:308
SUMMARY: AddressSanitizer: heap-buffer-overflow /root/exif/exif.c:2356 in parseIFD
Shadow bytes around the buggy address:
0x369a0090: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a00a0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a00b0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a00c0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a00d0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
=>0x369a00e0: fa fa fa fa fa fa fa fa fa fa 00[fa]fa fa 04 fa
0x369a00f0: fa fa 00 06 fa fa 06 fa fa fa fa fa fa fa fa fa
0x369a0100: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a0110: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a0120: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x369a0130: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==18831==ABORTING
在这个输出结果中,我们不但获得了详尽的信息,ASan还对漏洞类别进行了分类,给出了崩溃发生的地址以及堆栈跟踪。可以看到,漏洞发生时,exif.c中的parselFD函数正在进行4字节读取操作。
READ of size 4 at 0xb4d00758 thread T0
#0 0x415b9d in parseIFD /root/exif/exif.c:2356
#1 0x408f10 in createIfdTableArray /root/exif/exif.c:271
#2 0x4076ba in main /root/exif/sample_main.c:63
#3 0xb77d0ef0 in __libc_start_main ../csu/libc-start.c:308
#4 0x407310 in _start (/usr/bin/exifsan+0x2310)
因为现在已经得到了标准的二进制输出,我们可以对崩溃进行分类了。首先去除重复的崩溃,很有可能所有的30个崩溃都是同一个漏洞引起的,也有可能30个崩溃都不同(这一点不大可能,哈哈)。所以我们现在要解决这个问题。
还是用python脚本解决,我们需要遍历整个文件夹,使用新编译的exifsan对每个引发崩溃的图像进行解析,记录崩溃地址,同时查看崩溃发生时是否存在读或写操作。例如,对于crash.252.jpg文件,我们把日志文件命名为crash.252.HBO.b4f00758.READ,并将ASan的输出结果写入该日志文件,这样即使不打开日志文件,我们也知道是哪张图片引发了崩溃,漏洞类型,崩溃地址,以及执行的操作。(我会把这个代码脚本放到最后,这段代码太长了。)
执行完该分类脚本后,可以发现我们已经对所有崩溃进行了分类,而且还有一个有意思的现象。
crash.102.HBO.b4f006d4.READ
crash.102.jpg
crash.129.HBO.b4f005dc.READ
crash.129.jpg
crash.152.HBO.b4f005dc.READ
crash.152.jpg
crash.317.HBO.b4f005b4.WRITE
crash.317.jpg
crash.285.SEGV.00000000.READ
crash.285.jpg
------SNIP-----
虽然我省略了一部分,但是所有的30个崩溃中,只有一个执行的是WRITE操作,而且有很多SEGV引用的地址是NULL(0x00000000)。
接下来对使用magic()变异方法的模糊测试器进行100,000次迭代,看看是否会出现漏洞。
root@kali:~/crashes2# ls
crash.10354.jpg crash.2104.jpg crash.3368.jpg crash.45581.jpg crash.64750.jpg crash.77850.jpg crash.86367.jpg crash.94036.jpg
crash.12771.jpg crash.21126.jpg crash.35852.jpg crash.46757.jpg crash.64987.jpg crash.78452.jpg crash.86560.jpg crash.9435.jpg
crash.13341.jpg crash.23547.jpg crash.39494.jpg crash.46809.jpg crash.66340.jpg crash.78860.jpg crash.88799.jpg crash.94770.jpg
crash.14060.jpg crash.24492.jpg crash.40953.jpg crash.49520.jpg crash.6637.jpg crash.79019.jpg crash.89072.jpg crash.95438.jpg
crash.14905.jpg crash.25070.jpg crash.41505.jpg crash.50723.jpg crash.66389.jpg crash.79824.jpg crash.89738.jpg crash.95525.jpg
crash.18188.jpg crash.27783.jpg crash.41700.jpg crash.52051.jpg crash.6718.jpg crash.81206.jpg crash.90506.jpg crash.96746.jpg
crash.18350.jpg crash.2990.jpg crash.43509.jpg crash.54074.jpg crash.68527.jpg crash.8126.jpg crash.90648.jpg crash.98727.jpg
crash.19441.jpg crash.30599.jpg crash.43765.jpg crash.55183.jpg crash.6987.jpg crash.82472.jpg crash.90745.jpg crash.9969.jpg
crash.19581.jpg crash.31243.jpg crash.43813.jpg crash.5857.jpg crash.70713.jpg crash.83282.jpg crash.92426.jpg
crash.19907.jpg crash.31563.jpg crash.44974.jpg crash.59625.jpg crash.77590.jpg crash.83284.jpg crash.92775.jpg
crash.2010.jpg crash.32642.jpg crash.4554.jpg crash.64255.jpg crash.77787.jpg crash.84766.jpg crash.92906.jpg
出现了好多漏洞!
更多的疑问 & 结论
目前的模糊测试器只用于演示基本的基于变异的模糊测试,还很粗糙,可以进行大量优化。漏洞分类的过程也很混乱,使用的方法很烂,看来我还需要观看更多@gamozolabs的视频。或许下一次进行模糊测试的时候,我们可以选择一个更难的目标,用更酷的语言,例如Rust或者Go,编写模糊测试器,并且优化整个漏洞分类的过程,尝试对其中一个漏洞进行利用。
感谢文章中引用的每一个人,十分感谢。
下次见!
代码
JPEGfuzz.py
#!/usr/bin/env python3
import sys
import random
from pexpect import run
from pipes import quote
# read bytes from our valid JPEG and return them in a mutable bytearray
def get_bytes(filename):
f = open(filename, "rb").read()
return bytearray(f)
def bit_flip(data):
num_of_flips = int((len(data) - 4) * .01)
indexes = range(4, (len(data) - 4))
chosen_indexes = []
# iterate selecting indexes until we've hit our num_of_flips number
counter = 0
while counter < num_of_flips:
chosen_indexes.append(random.choice(indexes))
counter += 1
for x in chosen_indexes:
current = data[x]
current = (bin(current).replace("0b",""))
current = "0" * (8 - len(current)) + current
indexes = range(0,8)
picked_index = random.choice(indexes)
new_number = []
# our new_number list now has all the digits, example: ['1', '0', '1', '0', '1', '0', '1', '0']
for i in current:
new_number.append(i)
# if the number at our randomly selected index is a 1, make it a 0, and vice versa
if new_number[picked_index] == "1":
new_number[picked_index] = "0"
else:
new_number[picked_index] = "1"
# create our new binary string of our bit-flipped number
current = ''
for i in new_number:
current += i
# convert that string to an integer
current = int(current,2)
# change the number in our byte array to our new number we just constructed
data[x] = current
return data
def magic(data):
magic_vals = [
(1, 255),
(1, 255),
(1, 127),
(1, 0),
(2, 255),
(2, 0),
(4, 255),
(4, 0),
(4, 128),
(4, 64),
(4, 127)
]
picked_magic = random.choice(magic_vals)
length = len(data) - 8
index = range(0, length)
picked_index = random.choice(index)
# here we are hardcoding all the byte overwrites for all of the tuples that begin (1, )
if picked_magic[0] == 1:
if picked_magic[1] == 255: # 0xFF
data[picked_index] = 255
elif picked_magic[1] == 127: # 0x7F
data[picked_index] = 127
elif picked_magic[1] == 0: # 0x00
data[picked_index] = 0
# here we are hardcoding all the byte overwrites for all of the tuples that begin (2, )
elif picked_magic[0] == 2:
if picked_magic[1] == 255: # 0xFFFF
data[picked_index] = 255
data[picked_index + 1] = 255
elif picked_magic[1] == 0: # 0x0000
data[picked_index] = 0
data[picked_index + 1] = 0
# here we are hardcoding all of the byte overwrites for all of the tuples that being (4, )
elif picked_magic[0] == 4:
if picked_magic[1] == 255: # 0xFFFFFFFF
data[picked_index] = 255
data[picked_index + 1] = 255
data[picked_index + 2] = 255
data[picked_index + 3] = 255
elif picked_magic[1] == 0: # 0x00000000
data[picked_index] = 0
data[picked_index + 1] = 0
data[picked_index + 2] = 0
data[picked_index + 3] = 0
elif picked_magic[1] == 128: # 0x80000000
data[picked_index] = 128
data[picked_index + 1] = 0
data[picked_index + 2] = 0
data[picked_index + 3] = 0
elif picked_magic[1] == 64: # 0x40000000
data[picked_index] = 64
data[picked_index + 1] = 0
data[picked_index + 2] = 0
data[picked_index + 3] = 0
elif picked_magic[1] == 127: # 0x7FFFFFFF
data[picked_index] = 127
data[picked_index + 1] = 255
data[picked_index + 2] = 255
data[picked_index + 3] = 255
return data
# create new jpg with mutated data
def create_new(data):
f = open("mutated.jpg", "wb+")
f.write(data)
f.close()
def exif(counter,data):
command = "exif mutated.jpg -verbose"
out, returncode = run("sh -c " + quote(command), withexitstatus=1)
if b"Segmentation" in out:
f = open("crashes2/crash.{}.jpg".format(str(counter)), "ab+")
f.write(data)
if counter % 100 == 0:
print(counter, end="r")
if len(sys.argv) < 2:
print("Usage: JPEGfuzz.py <valid_jpg>")
else:
filename = sys.argv[1]
counter = 0
while counter < 100000:
data = get_bytes(filename)
functions = [0, 1]
picked_function = random.choice(functions)
if picked_function == 0:
mutated = magic(data)
create_new(mutated)
exif(counter,mutated)
else:
mutated = bit_flip(data)
create_new(mutated)
exif(counter,mutated)
counter += 1
triage.py
#!/usr/bin/env python3
import os
from os import listdir
def get_files():
files = os.listdir("/root/crashes/")
return files
def triage_files(files):
for x in files:
original_output = os.popen("exifsan " + x + " -verbose 2>&1").read()
output = original_output
# Getting crash reason
crash = ''
if "SEGV" in output:
crash = "SEGV"
elif "heap-buffer-overflow" in output:
crash = "HBO"
else:
crash = "UNKNOWN"
if crash == "HBO":
output = output.split("n")
counter = 0
while counter < len(output):
if output[counter] == "=================================================================":
target_line = output[counter + 1]
target_line2 = output[counter + 2]
counter += 1
else:
counter += 1
target_line = target_line.split(" ")
address = target_line[5].replace("0x","")
target_line2 = target_line2.split(" ")
operation = target_line2[0]
elif crash == "SEGV":
output = output.split("n")
counter = 0
while counter < len(output):
if output[counter] == "=================================================================":
target_line = output[counter + 1]
target_line2 = output[counter + 2]
counter += 1
else:
counter += 1
if "unknown address" in target_line:
address = "00000000"
else:
address = None
if "READ" in target_line2:
operation = "READ"
elif "WRITE" in target_line2:
operation = "WRITE"
else:
operation = None
log_name = (x.replace(".jpg","") + "." + crash + "." + address + "." + operation)
f = open(log_name,"w+")
f.write(original_output)
f.close()
files = get_files()
triage_files(files)







发表评论
您还未登录,请先登录。
登录