

在本文中,我们将为读者详细介绍覆盖率导向的UEFI固件模糊测试技术。
在本文上一部分中,我们为读者讲解了如何检测未初始化的内存泄露,接下来,我们将为读者详细介绍Efi-Fuzz与NotMyUefiFault方面的知识。
Efi-Fuzz
到目前为止,我们对UEFI的处理还远远没有完成。UEFI规范的篇幅多达2700多页,是如今蓬勃发展的数字巨兽的又一例证。就像许多其他庞杂的规范和技术一样,一个人无论多么有天赋,都很难在一生中全部掌握。不过,公平的说,我们了解的UEFI背景知识已经足以进行一些实际的模糊测试工作了。
在本节中,我们将介绍efi-fuzz:一个简单的、覆盖率导向的fuzzer,可用于对NVRAM变量的内容进行模糊测试。首先,我们将详细介绍如何正确设置模糊测试环境,然后展示如何对专门为此创建的测试应用程序进行模糊测试。总的来说,要使用efi-fuzz,必须遵循以下步骤:
如果在Windows上运行,需要安装WSL。不过,我们推荐安装WSL2,而不是原来的WSL,后者有时会比较慢。Windows 10的完整安装说明可以在这里找到:https://docs.microsoft.com/en-us/windows/wsl/install-win10。
在WSL发行版中,还需安装一些必要的包,以便可以编译C语言源代码:sudo apt install build-essential automake。
安装支持Unicorn模式的AFL++。完整的构建说明可以在这里找到,但为了完整起见,我们还是要在这里列出它们。
克隆存储库:
git clone https://github.com/AFLplusplus/AFLplusplus构建核心的AFL++二进制文件:
make构建Unicorn支持功能:
cd unicorn_mode
./build_unicorn_support.sh完成安装工作:
make install获取并解压要进行模糊测试的UEFI固件。关于实践中如何完成该任务的详细介绍,请参考该系列的第一篇文章或其他文献,如《Rootkits and Bootkits》。
克隆fuzzer并安装所需的依赖项:
git clone https://github.com/Sentinel-One/efi_fuzz
pip install -r efi_fuzz/requirements.txt准备一个仿真的NVRAM环境,它将被Qiling用来服务于对GetVariable()的调用。出于灵活性的考虑,fuzzer不会直接从SPI转储中使用其NVRAM存储,而是从事先准备好的序列化Python字典中使用NVRAM存储。要通过SPI转储创建该字典,可以使用以下命令:
python scripts/prepare_nvram.py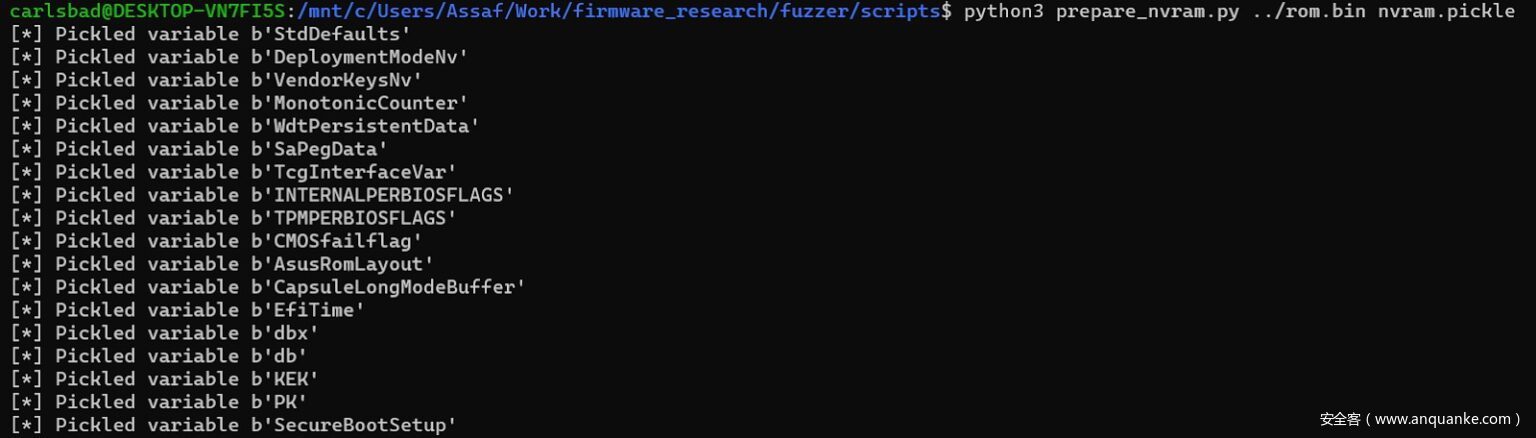
图16 序列化NVRAM环境
为NVRAM变量准备初始corpus。像vanilla AFL一样,AFL++希望能以二进制文件的形式为突变进程通过seed。为了满足这一要求,可以使用prepare_afl_corpus.py脚本:
python scripts/prepare_afl_corpus.py afl_inputs运行该脚本后,所有seed文件将整齐地保存在afl_inputs目录下。根据设计,每个变量都有自己的专用子目录。另外,请注意,当在SPI转储中发现了同一个变量的多个实例(可能在不同的FV上)时,每个种子文件都将以其顺号作为后缀(例如VarName_0,VarName_1等)。
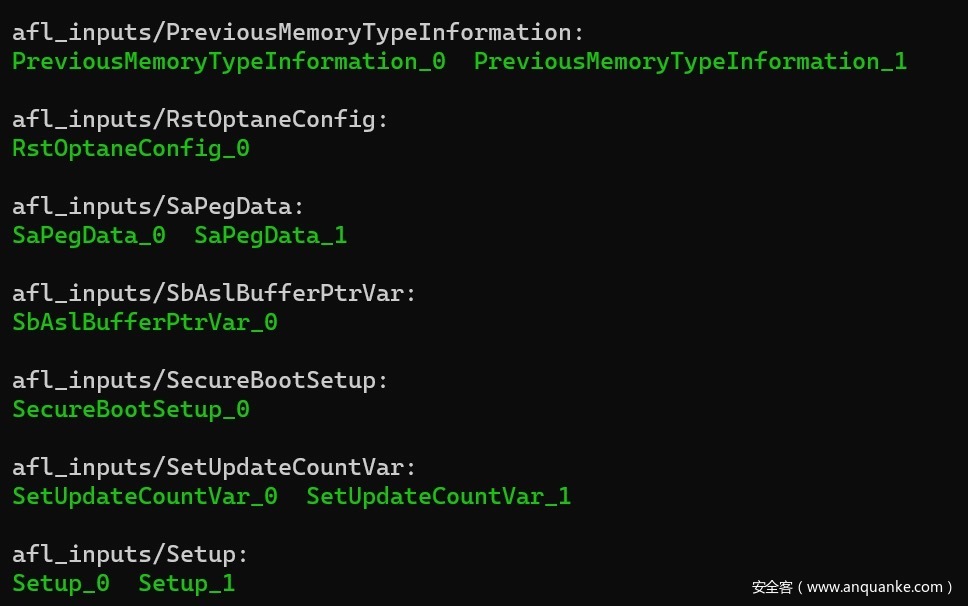
图17 fuzzer的初始seed。这里的内容截取自ls -R afl_inputs命令的输出结果。
选择要模糊测试的目标模块。显然,目标模块应在执行过程中获取某些NVRAM变量的内容。根据经验,仅依赖“薄”变量(例如布尔标志)的模块不容易出现解析漏洞,因此,应优先选择使用“厚”变量(例如Setup变量)的模块。
让fuzzer试运行(dry run)一次。在试运行期间,目标模块是在没有AFL参与的情况下进行仿真的。我们进行试运行,是为了确保:
目标模块确实能获取某些NVRAM变量的内容。
目标模块成功运行完成。
要进行试运行,请使用以下命令:
python efi_fuzz.py <target> <nvram> <varname> <seed>以下屏幕截图可以更好地说明该过程:
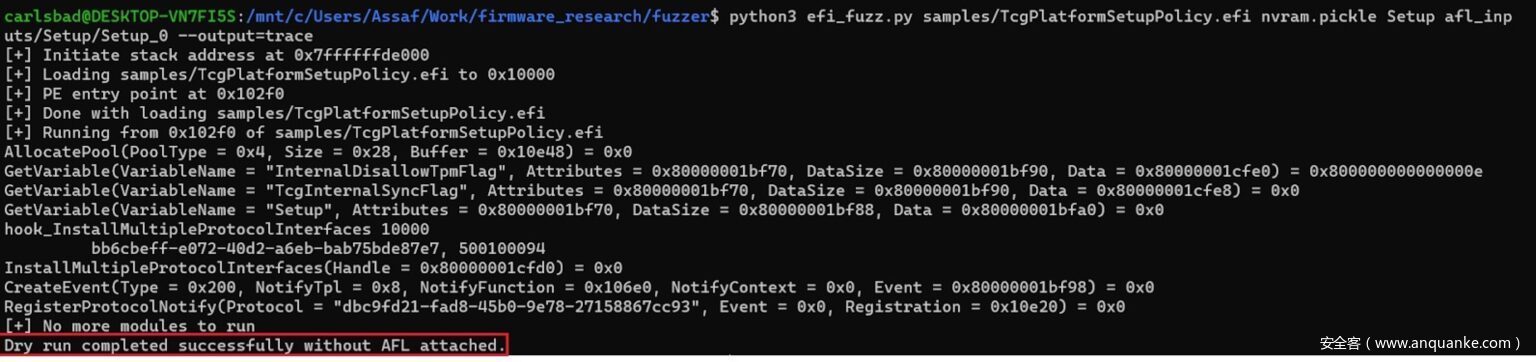
图18 Fuzzer的试运行情况
如果试运行没有成功完成,可以通过以下技巧来帮助排除问题:
使用-output开关来生成更详细的输出。这个标志的有效选项包括“trace”、“disasm”和“debug”。一般来说,“disasm”能提供最详细的信息,因为它会显示已经执行指令的实际汇编代码。
延长仿真超时时间。这可以通过传递-timeout标志和指定的毫秒值来实现。
有时,试运行可能会在NVRAM变量解析运行很长一段时间后才崩溃。在这种情况下,我们可能会采用部分仿真的方式。要启用这一功能,只需将-end参数与最后一条要模拟的指令的十六进制地址一起传递给fuzzer即可。

图19 使用-output、-timeout和-end标志可以帮助排除试运行过程中出现的各种问题。
当我们对试运行的结果感到满意后,我们终于可以进入“实干”阶段了。在进行“湿”模糊测试的过程中,AFL++将不断为所选的NVRAM变量产生新的突变。同时,efi-fuzz会用新的突变模拟目标二进制代码,然后向AFL++报告覆盖率信息,并通过这些覆盖率信息帮助突变过程向更有前途的方向发展。进行“湿”模糊测试的命令如下所示:
afl-fuzz -i afl_inputs/<varname> -o afl_outputs/ -U -- python efi_fuzz.py <target> <nvram> @@下面,我们将通过一个具体的例子来进行演示。为此,我们专门编写了一含有相关问题的UEFI驱动程序,叫做NotMyUefiFault。
NotMyUefiFault
前段时间,作为SysInternals工具套件的一部分,Mark Russinovich开发并发布了一个名为NotMyFault的小工具。NotMyFault背后的基本想法是创建一个工具,可以用来故意在Windows系统上崩溃、挂起并导致内核内存泄漏。它的主要目标受众是寻求有用的方法来学习如何识别和诊断设备驱动程序和硬件问题的内核开发人员。
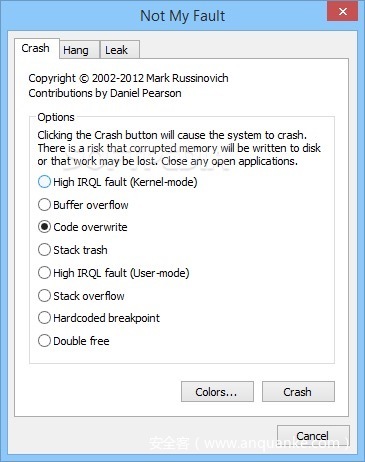
图20 有了NotMyFault,用户就可以通过GUI选择要生成的漏洞类型
秉承这一基本理念,我们打算开发一个具有类似功能的,以UEFI为中心的工具,以便在UEFI仿真环境中生成不同的崩溃和反模式。由于这两个工具有很大的相似性,并且为了向Mark Russinovich和他在SysInternals上的工作致敬,我们决定将我们的工具命名为NotMyUefiFault。然而,与NotMyFault不同的是,NotMyFault的目的是作为一个教育工具,我们更多的是将NotMyUefiFault作为fuzzer的可用性测试工具。
NotMyUefiFault的工作原理是简单地读取一个名为FaultType的NVRAM变量。然后,根据它的值以及下面的符号来决定生成哪类漏洞:
POOL_OVERFLOW_MEM:通过BS->CopyMem()触发内存池上溢。
POOL_UNDERFLOW_MEM:通过BS->CopyMem()触发内存池下溢。
POOL_OVERFLOW_SET_MEM:通过BS->SetMem()触发内存池上溢。
POOL_UNDERFLOW_SET_MEM:通过BS->SetMem()触发内存池下溢。
POOL_OVERFLOW_USER_CODE:触发用户代码的内存池上溢。
POOL_UNDERFLOW_USER_CODE:触发用户代码的内存池下溢。
POOL_OOB_READ_AHEAD:在内存池缓冲区之前触发越界读取。
POOL_OOB_READ_BEHIND:在内存池缓冲区之后触发越界读取。
POOL_DOUBLE_FREE:连续两次释放同一个内存池块。
POOL_INVALID_FREE:释放一个未被BS->AllocatePool()分配的指针。
POOL_UAF_READ:在内存池缓冲区被释放后,从内存池缓冲区读取数据。
POOL_UAF_WRITE:在内存池缓冲区被释放后,向内存池缓冲区写入数据。
NULL_DEREFERENCE_DETERMINISTIC:对NULL页面执行写入操作。
NULL_DEREFERENCE_NON_DETERMINISTIC:用BS->AllocatePool()分配一个缓冲区,然后使用它,而不先检查是否为NULL页面。
STACK_BUFFER_OVERFLOW:生成一个基于堆栈的缓冲区溢出。
STACK_UNINITIALIZED_MEMORY_LEAK:通过NVRAM泄露未初始化的栈内存。
要练习NotMyUefiFault的用法,我们需要:
通过fuzzing seeds创建一个目录。这里我们选择0xFFFFFFFF作为单基测试用例,因为它不对应于任何有效的漏洞类型值。
mkdir -p afl_inputs/FaultType
echo -ne "\xFF\xFF\xFF\xFF" > afl_inputs/FaultType/FaultType_0运行Fuzzer:
afl-fuzz -T NotMyUefiFault -i afl_inputs/FaultType/ -o afl_outputs/ -U -- python efi_fuzz.py NotMyUefiFault/bin/NotMyUefiFault.efi nvram.pickle FaultType @@等到检测到崩溃时,可以看到类似下面的输出内容:

图21 通过对NotMyUefiFault.efi进行模糊测试,Fuzzer很快就识别出16个存在漏洞的路径中的14个
之后,可以通过浏览afl_output/crashes目录来检查导致崩溃的各个变量blob。

图22 查看导致崩溃的二进制blob
请注意,如果您想检测情况#16 (STACK_UNINITIALIZED_MEMORY_LEAK),则必须明确地将-u, –track-uninitialized标志传递给Fuzzer。
小结
在实验UEFI模糊测试技术的过程中,我们很快就意识到,孤立地模拟UEFI模块不会让我们走得很远。主要原因是UEFI模块之间并不是孤立的,相反,它们通常会通过协同工作来实现某些目标。在某种程度上,仿真一个UEFI模块就相当于加载一个二进制文件,而不是映射它正常工作所依赖的所有共享库。因此,孤立的仿真显然不是正确的方式。
正如第二篇文章中简单提到的,在UEFI中,模块间调用的主要单位叫做协议。一个模块可以通过调用InstallProtocolInterface()或InstallMultipleProtocolInterfaces()等服务来公开自己对某个协议的实现,从而起到协议提供者的作用。此外,UEFI模块还可以通过使用LocateProtocol()、OpenProtocol()等服务使用其他模块安装的协议。如果所请求的协议由于某种原因不存在,调用模块可以通过三种方式进行响应,这三种方式包括:
退出,并提供适当的错误代码(如EFI_NOT_FOUND)。
隐含地假设请求的协议已经被安装。在这种情况下,调用模块可能甚至都不会检查返回的接口指针的有效性,一旦试图去引用它就会崩溃。尽管这看起来像是一个bug,但事实上,有时UEFI模块有非常令人信服的理由来相信其他模块在启动过程中已经提前执行了。因此,它们可以从逻辑上推断出某些协议应该已经可用。关于这个话题的更多细节将在本系列的第四篇文章中加以介绍。

图23 像TxtDxe这样的模块隐含地假设某些协议已经可以使用了
最后,调用模块可以使用RegisterProtocolNotify()服务来注册一个通知事件,一旦为协议安装了接口,就会发出相应的通知。该通知事件通常与一个回调函数关联在一起,正因为如此,当回调函数最终被调用时,调用模块就能保证所请求的协议已经就绪了。UEFI开发者通常的做法是使用这个回调函数再次调用OpenProtocol()或LocateProtocol(),这次就能成功了。
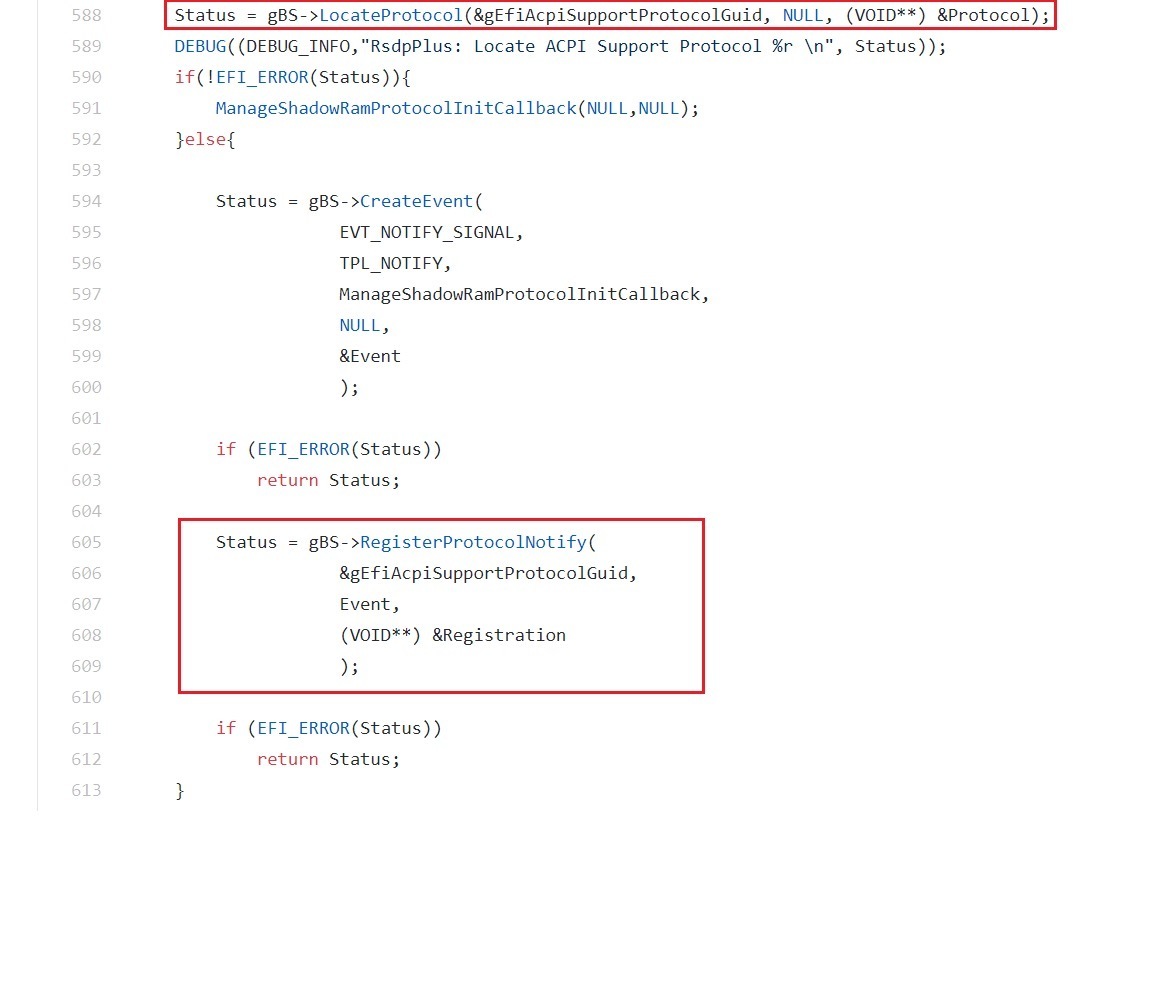
图24 RegisterProtocolNotify()可以用来处理传递给LocateProtocol()的协议尚未安装的情况
从模糊测试的角度来看,所有这些不同的响应的共同点是,它们极大地限制了我们的代码覆盖率。为了提高代码覆盖率,我们应该找到一种方法来满足这些协议请求。作为一个例子,让我们考察一下测试机的固件映像中的TcgDxe。
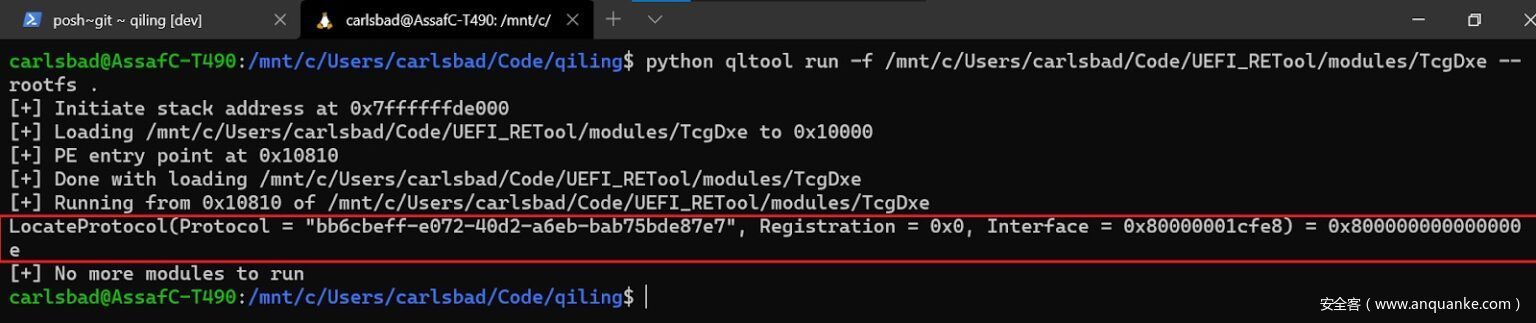
图25 TcgDxe未能找到所需的协议。0x800000000000000e是EFI_NOT_FOUND的状态码。
从上面的截图中可以看出,TcgDxe选择了策略(1)来处理缺失的协议,即退出。现在的问题就变成了,如何找到实现由bb6cbeff-e072-40d2-a6eb-bab75bde87e7标识的协议的模块,从而满足TcgDxe的依赖关系?
不幸的是,这个GUID并没有出现在UEFITool的GUID数据库中,也没有出现在任何谷歌搜索结果中。这时,我们有两个选择:
在源自固件映像的所有模块中搜索代表GUID的二进制字节序列。这种方法有一个明显的缺点,那就是它无法分辨提供者模块和消费者模块之间的区别,因此需要一些手工工作来处理这些问题。
使用UEFI_RETool等工具来构建模块之间的关系图,然后搜索TcgDxe所依赖的所有模块。实际上,UEFI_RETool试图通过分析汇编代码和寻找一些特定的模式来确定对提供者和消费者服务的调用。虽然理论上这听起来很有希望,但实际上汇编代码可能看起来与UEFI_RETool期望的有些不同,因此这种方法通常会有大量的错漏。
图26 相互关联的UEFI模块的依赖关系图
最后,我们可以通过常识性逻辑和启发式方法,将搜索范围缩小为少数几个潜在的候选模块。例如,就TcgDxe而言,我们可能会加载其他以Tcg*为前缀的模块,希望其中一个模块能够注册我们“渴望”的协议。
经过研究,我们发现我们感兴趣的协议确实会被另一个名为TcgPlatformSetupPolicy的模块注册。知道了这一点,就可以将这两个模块加载到仿真环境中,从而满足TcgDxe的依赖关系。
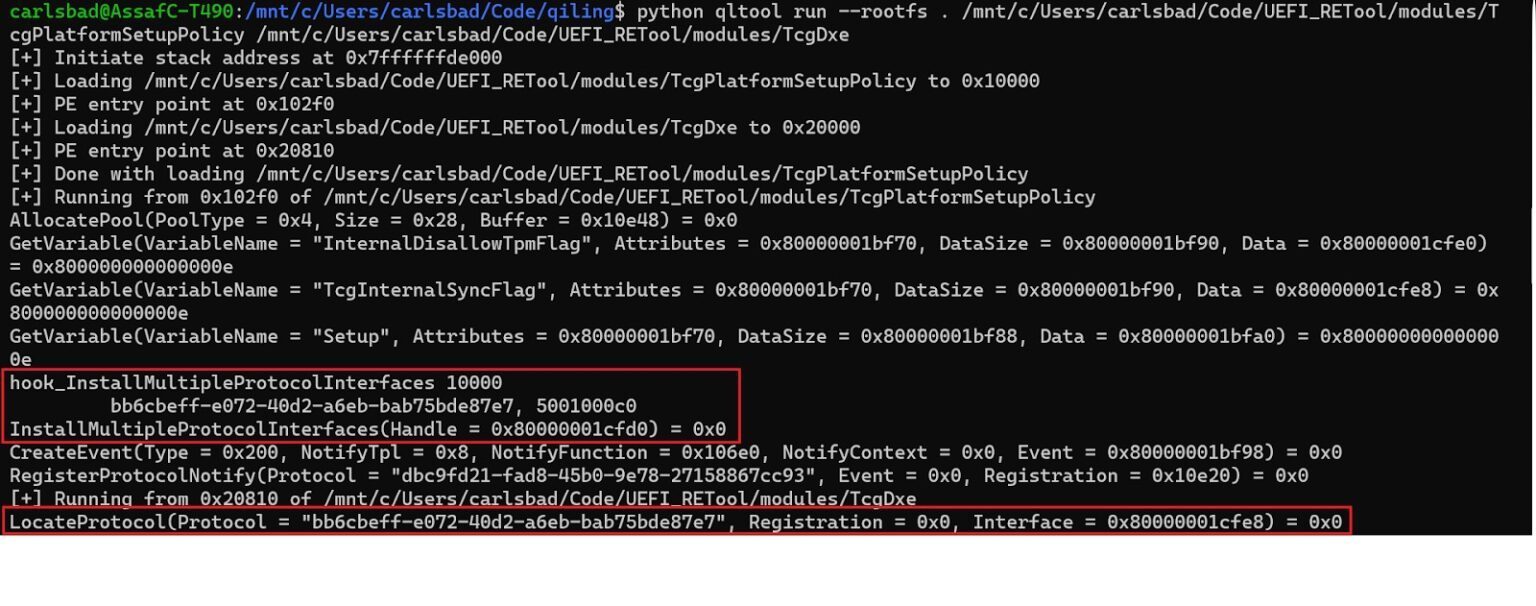
图27 TcgDxe的仿真已经成功在望了
虽然这次我们成功了,但我们目前的解决方案显然缺乏良好的扩展性。例如,如果TcgPlatformSetupPolicy还有另一组需要手动解决的依赖关系,那该咋办?
为了解决这些问题,我们应该在fuzzer中添加某种协调层(orchestration layer)。理想情况下,这个层会自动解析模块之间的依赖关系,并保证一个模块只有在其所有的依赖关系被解析后才会被加载。显然,使用这样的协调层将使我们能够从单个模块的模糊测试逐渐过渡到整个FV的模糊测试,例如托管DXE阶段的卷。这个话题,以及一些其他方向,如利用符号执行引擎进行模糊测试,将在本系列的后续部分进行讨论。
我们想借此机会感谢Caleb Fenton、Matan Mates、Phil Stokes和Migo Kedem的支持、编辑工作和宝贵建议。







发表评论
您还未登录,请先登录。
登录