

一、简介
- v8 是一种 JS 引擎的实现,它由Google开发,使用C++编写。v8 被设计用于提高网页浏览器内部 JavaScript 代码执行的性能。为了提高性能,v8 将会把 JS 代码转换为更高效的机器码,而非传统的使用解释器执行。因此 v8 引入了 JIT (Just-In-Time) 机制,该机制将会在运行时动态编译 JS 代码为机器码,以提高运行速度。
- TurboFan是 v8 的优化编译器之一,它使用了 sea of nodes 这个编译器概念。
sea of nodes 不是单纯的指某个图的结点,它是一种特殊中间表示的图。
它的表示形式与一般的CFG/DFG不同,其具体内容请查阅上面的连接。
TurboFan的相关源码位于
v8/compiler文件夹下。 - 这是笔者初次学习v8 turboFan所写下的笔记,内容包括但不限于turboFan运行参数的使用、部分
OptimizationPhases的工作机理,以及拿来练手的GoogleCTF 2018(Final) Just-In-Time题题解。该笔记基于 Introduction to TurboFan 并适当拓宽了一部分内容。如果在阅读文章时发现错误或者存在不足之处,欢迎各位师傅斧正!
二、环境搭建
- 这里的环境搭建较为简单,首先搭配一个 v8 环境(必须,没有 v8 环境要怎么研究 v8, 2333)。这里使用的版本号是7.0.276.3。
如何搭配v8环境?请移步 下拉&编译 chromium&v8 代码
这里需要补充一下,v8 的 gn args中必须加一个
v8_untrusted_code_mitigations = false的标志,即最后使用的gn args如下:# Set build arguments here. See `gn help buildargs`. is_debug = true target_cpu = "x64" v8_enable_backtrace = true v8_enable_slow_dchecks = true v8_optimized_debug = false # 加上这个 v8_untrusted_code_mitigations = false具体原因将在下面讲解
CheckBounds结点优化时提到。 - 然后安装一下 v8 的turbolizer,turbolizer将用于调试 v8 TurboFan中
sea of nodes图的工具。cd v8/tools/turbolizer # 获取依赖项 npm i # 构建 npm run-script build # 直接在turbolizer文件夹下启动静态http服务 python -m SimpleHTTPServer构建turbolizer时可能会报一些TypeScript的语法错误ERROR,这些ERROR无伤大雅,不影响turbolizer的功能使用。
- turbolizer 的使用方式如下:
- 首先编写一段测试函数
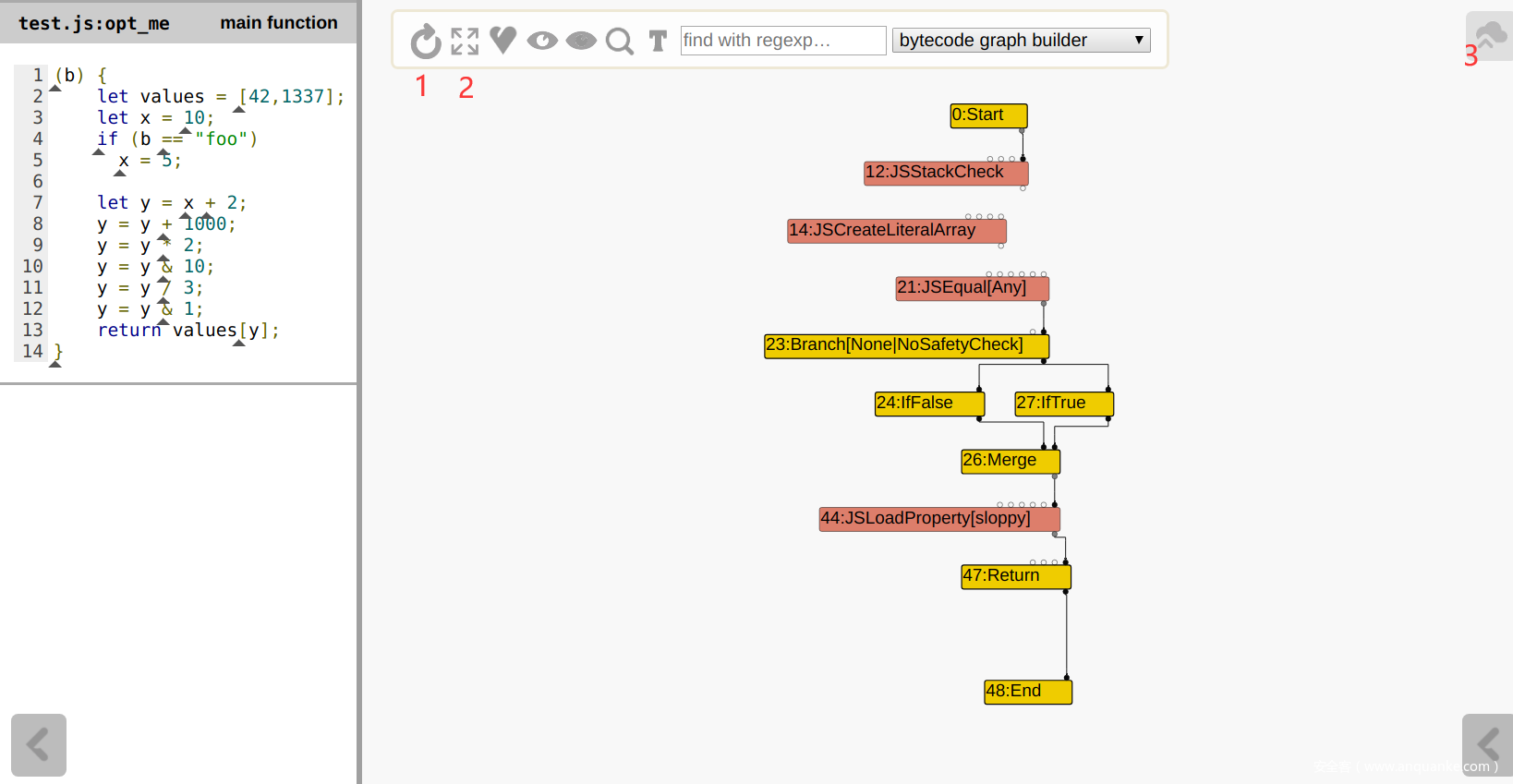
// 目标优化函数 function opt_me(b) { let values = [42,1337]; let x = 10; if (b == "foo") x = 5; let y = x + 2; y = y + 1000; y = y * 2; y = y & 10; y = y / 3; y = y & 1; return values[y]; } // 必须!在优化该函数前必须先进行一次编译,以便于为该函数提供type feedback opt_me(); // 必须! 使用v8 natives-syntax来强制优化该函数 %OptimizeFunctionOnNextCall(opt_me); // 必须! 不调用目标函数则无法执行优化 opt_me();一定要在执行
%OptimizeFunctionOnNextCall(opt_me)之前调用一次目标函数,否则生成的graph将会因为没有type feedback而导致完全不一样的结果。需要注意的是type feedback有点玄学,在执行
OptimizeFunctionOnNextCall前,如果目标函数内部存在一些边界操作(例如多次使用超过Number.MAX_SAFE_INTEGER大小的整数等),那么调用目标函数的方式可能会影响turboFan的功能,包括但不限于传入参数的不同、调用目标函数次数的不同等等等等。因此在执行
%OptimizeFunctionOnNextCall前,目标函数的调用方式,必须自己把握,手动确认调用几次,传入什么参数会优化出特定的效果。若想优化一个函数,除了可以使用
%OptimizeFunctionOnNextCall以外,还可以多次执行该函数(次数要大,建议上for循环)来触发优化。 - 然后使用 d8 执行,不过需要加上
--trace-turbo参数。$ ../../v8/v8/out.gn/x64.debug/d8 test.js --allow-natives-syntax --trace-turbo Concurrent recompilation has been disabled for tracing. --------------------------------------------------- Begin compiling method opt_me using Turbofan --------------------------------------------------- Finished compiling method opt_me using Turbofan之后本地就会生成
turbo.cfg和turbo-xxx-xx.json文件。 - 使用浏览器打开
127.0.0.1:8000(注意之前在turbolizer文件夹下启动了http服务)然后点击右上角的3号按钮,在文件选择窗口中选择刚刚生成的turbo-xxx-xx.json文件,之后就会显示以下信息:![]() 不过这里的结点只显示了控制结点,如果需要显示全部结点,则先点击一下上方的2号按钮,将结点全部展开,之后再点击1号按钮,重新排列:
不过这里的结点只显示了控制结点,如果需要显示全部结点,则先点击一下上方的2号按钮,将结点全部展开,之后再点击1号按钮,重新排列:![]()
- 首先编写一段测试函数
 不过这里的结点只显示了控制结点,如果需要显示全部结点,则先点击一下上方的2号按钮,将结点全部展开,之后再点击1号按钮,重新排列:
不过这里的结点只显示了控制结点,如果需要显示全部结点,则先点击一下上方的2号按钮,将结点全部展开,之后再点击1号按钮,重新排列:
三、turboFan的代码优化
- 我们可以使用
--trace-opt参数来追踪函数的优化信息。以下是函数opt_me被turboFan优化时所生成的信息。$ ../../v8/v8/out.gn/x64.debug/d8 test.js --allow-natives-syntax --trace-opt [manually marking 0x0a7a24823759 <JSFunction opt_me (sfi = 0xa7a24823591)> for non-concurrent optimization] [compiling method 0x0a7a24823759 <JSFunction opt_me (sfi = 0xa7a24823591)> using TurboFan] [optimizing 0x0a7a24823759 <JSFunction opt_me (sfi = 0xa7a24823591)> - took 53.965, 19.410, 0.667 ms]上面输出中的
manually marking即我们在代码中手动设置的%OptimizeFunctionOnNextCall。我们可以使用 v8 本地语法来查看优化前和优化后的机器码(使用
%DisassembleFunction本地语法)输出信息过长,这里只截取一部分输出。
$ ../../v8/v8/out.gn/x64.debug/d8 test.js --allow-natives-syntax 0x2b59fe964c1: [Code] - map: 0x05116bd02ae9 <Map> kind = BUILTIN name = InterpreterEntryTrampoline compiler = unknown address = 0x2b59fe964c1 Instructions (size = 995) 0x2b59fe96500 0 488b5f27 REX.W movq rbx,[rdi+0x27] 0x2b59fe96504 4 488b5b07 REX.W movq rbx,[rbx+0x7] 0x2b59fe96508 8 488b4b0f REX.W movq rcx,[rbx+0xf] .... 0x2b59ff49541: [Code] - map: 0x05116bd02ae9 <Map> kind = OPTIMIZED_FUNCTION stack_slots = 5 compiler = turbofan address = 0x2b59ff49541 Instructions (size = 212) 0x2b59ff49580 0 488d1df9ffffff REX.W leaq rbx,[rip+0xfffffff9] 0x2b59ff49587 7 483bd9 REX.W cmpq rbx,rcx 0x2b59ff4958a a 7418 jz 0x2b59ff495a4 <+0x24> 0x2b59ff4958c c 48ba000000003e000000 REX.W movq rdx,0x3e00000000 ...可以看到,所生成的代码长度从原先的995,优化为212,大幅度优化了代码。
需要注意的是,即便不使用
%OptimizeFunctionOnNextCall,将opt_me函数重复执行一定次数,一样可以触发TurboFan的优化。 - 细心的小伙伴应该可以在上面环境搭建的图中看到
deoptimize反优化。为什么需要反优化?这就涉及到turboFan的优化机制。以下面这个js代码为例(注意:没有使用%OptimizeFunctionOnNextCall)class Player{} class Wall{} function move(obj) { var tmp = obj.x + 42; var x = Math.random(); x += 1; return tmp + x; } for (var i = 0; i < 0x10000; ++i) { move(new Player()); } move(new Wall()); for (var i = 0; i < 0x10000; ++i) { move(new Wall()); }跟踪一下该代码的opt以及deopt:
$ ../../v8/v8/out.gn/x64.debug/d8 test.js --allow-natives-syntax --trace-opt --trace-deopt [marking 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> for optimized recompilation, reason: small function, ICs with typeinfo: 7/7 (100%), generic ICs: 0/7 (0%)] [compiling method 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> using TurboFan] [optimizing 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> - took 6.583, 2.385, 0.129 ms] [completed optimizing 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)>] # 分割线--------------------------------------------------------------------- [marking 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> for optimized recompilation, reason: hot and stable, ICs with typeinfo: 7/13 (53%), generic ICs: 0/13 (0%)] [compiling method 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> using TurboFan OSR] [optimizing 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> - took 3.684, 7.337, 0.409 ms] # 分割线--------------------------------------------------------------------- [deoptimizing (DEOPT soft): begin 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> (opt #1) @6, FP to SP delta: 104, caller sp: 0x7ffed15d2a08] ;;; deoptimize at <test.js:15:6>, Insufficient type feedback for construct ... [deoptimizing (soft): end 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> @6 => node=154, pc=0x7f0d956522e0, caller sp=0x7ffed15d2a08, took 0.496 ms] [deoptimizing (DEOPT eager): begin 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> (opt #0) @1, FP to SP delta: 24, caller sp: 0x7ffed15d2990] ;;; deoptimize at <test.js:5:17>, wrong map ... [deoptimizing (eager): end 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> @1 => node=0, pc=0x7f0d956522e0, caller sp=0x7ffed15d2990, took 0.355 ms] # 分割线--------------------------------------------------------------------- [marking 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> for optimized recompilation, reason: small function, ICs with typeinfo: 7/7 (100%), generic ICs: 0/7 (0%)] [compiling method 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> using TurboFan] [optimizing 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)> - took 1.435, 2.427, 0.159 ms] [completed optimizing 0x3c72eab23a99 <JSFunction move (sfi = 0x3c72eab235f9)>] [compiling method 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> using TurboFan OSR] [optimizing 0x3c72eab238e9 <JSFunction (sfi = 0x3c72eab234e9)> - took 3.399, 6.299, 0.239 ms]- 首先,
move函数被标记为可优化的(optimized recompilation),原因是该函数为small function。然后便开始重新编译以及优化。 - 之后,
move函数再一次被标记为可优化的,原因是hot and stable。这是因为 v8 首先生成的是 ignition bytecode。 如果某个函数被重复执行多次,那么TurboFan就会重新生成一些优化后的代码。
以下是获取优化理由的的v8代码。如果该JS函数可被优化,则将在外部的v8函数中,mark该JS函数为待优化的。
OptimizationReason RuntimeProfiler::ShouldOptimize(JSFunction* function, JavaScriptFrame* frame) { SharedFunctionInfo* shared = function->shared(); int ticks = function->feedback_vector()->profiler_ticks(); if (shared->GetBytecodeArray()->length() > kMaxBytecodeSizeForOpt) { return OptimizationReason::kDoNotOptimize; } int ticks_for_optimization = kProfilerTicksBeforeOptimization + (shared->GetBytecodeArray()->length() / kBytecodeSizeAllowancePerTick); // 如果执行次数较多,则标记为HotAndStable if (ticks >= ticks_for_optimization) { return OptimizationReason::kHotAndStable; // 如果函数较小,则为 small function } else if (!any_ic_changed_ && shared->GetBytecodeArray()->length() < kMaxBytecodeSizeForEarlyOpt) { // If no IC was patched since the last tick and this function is very // small, optimistically optimize it now. return OptimizationReason::kSmallFunction; } else if (FLAG_trace_opt_verbose) { PrintF("[not yet optimizing "); function->PrintName(); PrintF(", not enough ticks: %d/%d and ", ticks, kProfilerTicksBeforeOptimization); if (any_ic_changed_) { PrintF("ICs changed]\n"); } else { PrintF(" too large for small function optimization: %d/%d]\n", shared->GetBytecodeArray()->length(), kMaxBytecodeSizeForEarlyOpt); } } return OptimizationReason::kDoNotOptimize; }- 但接下来就开始deopt move函数了,原因是
Insufficient type feedback for construct,目标代码是move(new Wall())中的new Wall()。这是因为turboFan的代码优化基于推测,即speculative optimizations。当我们多次执行move(new Player())时,turboFan会猜测move函数的参数总是Player对象,因此将move函数优化为更适合Player对象执行的代码,这样使得Player对象使用move函数时速度将会很快。这种猜想机制需要一种反馈来动态修改猜想,那么这种反馈就是 type feedback,Ignition instructions将利用 type feedback来帮助TurboFan的speculative optimizations。v8源码中,
JSFunction类中存在一个类型为FeedbackVector的成员变量,该FeedbackVector将在JS函数被编译后启用。因此一旦传入的参数不再是
Player类型,即刚刚所说的Wall类型,那么将会使得猜想不成立,因此立即反优化,即销毁一部分的ignition bytecode并重新生成。需要注意的是,反优化机制(deoptimization)有着巨大的性能成本,应尽量避免反优化的产生。
- 下一个
deopt的原因为wrong map。这里的map可以暂时理解为类型。与上一条deopt的原因类似,所生成的move优化函数只是针对于Player对象,因此一旦传入一个Wall对象,那么传入的类型就与函数中的类型不匹配,所以只能开始反优化。 - 如果我们在代码中来回使用
Player对象和Wall对象,那么TurboFan也会综合考虑,并相应的再次优化代码。
- 首先,
四、turboFan的执行流程
- turboFan的代码优化有多条执行流,其中最常见到的是下面这条:
![]()
- 从
Runtime_CompileOptimized_Concurrent函数开始,设置并行编译&优化 特定的JS函数// v8\src\runtime\runtime-compiler.cc 46 RUNTIME_FUNCTION(Runtime_CompileOptimized_Concurrent) { HandleScope scope(isolate); DCHECK_EQ(1, args.length()); CONVERT_ARG_HANDLE_CHECKED(JSFunction, function, 0); StackLimitCheck check(isolate); if (check.JsHasOverflowed(kStackSpaceRequiredForCompilation * KB)) { return isolate->StackOverflow(); } // 设置并行模式,之后开始编译与优化 if (!Compiler::CompileOptimized(function, ConcurrencyMode::kConcurrent)) { return ReadOnlyRoots(isolate).exception(); } DCHECK(function->is_compiled()); return function->code(); } - 在
Compiler::CompileOptimized函数中,继续执行GetOptimizedCode函数,并将可能生成的优化代码传递给JSFunction对象。// v8\src\compiler.cc bool Compiler::CompileOptimized(Handle<JSFunction> function, ConcurrencyMode mode) { if (function->IsOptimized()) return true; Isolate* isolate = function->GetIsolate(); DCHECK(AllowCompilation::IsAllowed(isolate)); // Start a compilation. Handle<Code> code; if (!GetOptimizedCode(function, mode).ToHandle(&code)) { // Optimization failed, get unoptimized code. Unoptimized code must exist // already if we are optimizing. DCHECK(!isolate->has_pending_exception()); DCHECK(function->shared()->is_compiled()); DCHECK(function->shared()->IsInterpreted()); code = BUILTIN_CODE(isolate, InterpreterEntryTrampoline); } // Install code on closure. function->set_code(*code); // Check postconditions on success. DCHECK(!isolate->has_pending_exception()); DCHECK(function->shared()->is_compiled()); DCHECK(function->is_compiled()); DCHECK_IMPLIES(function->HasOptimizationMarker(), function->IsInOptimizationQueue()); DCHECK_IMPLIES(function->HasOptimizationMarker(), function->ChecksOptimizationMarker()); DCHECK_IMPLIES(function->IsInOptimizationQueue(), mode == ConcurrencyMode::kConcurrent); return true; } -
GetOptimizedCode的函数代码如下:// v8\src\compiler.cc MaybeHandle<Code> GetOptimizedCode(Handle<JSFunction> function, ConcurrencyMode mode, BailoutId osr_offset = BailoutId::None(), JavaScriptFrame* osr_frame = nullptr) { Isolate* isolate = function->GetIsolate(); Handle<SharedFunctionInfo> shared(function->shared(), isolate); // Make sure we clear the optimization marker on the function so that we // don't try to re-optimize. if (function->HasOptimizationMarker()) { function->ClearOptimizationMarker(); } if (isolate->debug()->needs_check_on_function_call()) { // Do not optimize when debugger needs to hook into every call. return MaybeHandle<Code>(); } Handle<Code> cached_code; if (GetCodeFromOptimizedCodeCache(function, osr_offset) .ToHandle(&cached_code)) { if (FLAG_trace_opt) { PrintF("[found optimized code for "); function->ShortPrint(); if (!osr_offset.IsNone()) { PrintF(" at OSR AST id %d", osr_offset.ToInt()); } PrintF("]\n"); } return cached_code; } // Reset profiler ticks, function is no longer considered hot. DCHECK(shared->is_compiled()); function->feedback_vector()->set_profiler_ticks(0); VMState<COMPILER> state(isolate); DCHECK(!isolate->has_pending_exception()); PostponeInterruptsScope postpone(isolate); bool has_script = shared->script()->IsScript(); // BUG(5946): This DCHECK is necessary to make certain that we won't // tolerate the lack of a script without bytecode. DCHECK_IMPLIES(!has_script, shared->HasBytecodeArray()); std::unique_ptr<OptimizedCompilationJob> job( compiler::Pipeline::NewCompilationJob(isolate, function, has_script)); OptimizedCompilationInfo* compilation_info = job->compilation_info(); compilation_info->SetOptimizingForOsr(osr_offset, osr_frame); // Do not use TurboFan if we need to be able to set break points. if (compilation_info->shared_info()->HasBreakInfo()) { compilation_info->AbortOptimization(BailoutReason::kFunctionBeingDebugged); return MaybeHandle<Code>(); } // Do not use TurboFan when %NeverOptimizeFunction was applied. if (shared->optimization_disabled() && shared->disable_optimization_reason() == BailoutReason::kOptimizationDisabledForTest) { compilation_info->AbortOptimization( BailoutReason::kOptimizationDisabledForTest); return MaybeHandle<Code>(); } // Do not use TurboFan if optimization is disabled or function doesn't pass // turbo_filter. if (!FLAG_opt || !shared->PassesFilter(FLAG_turbo_filter)) { compilation_info->AbortOptimization(BailoutReason::kOptimizationDisabled); return MaybeHandle<Code>(); } TimerEventScope<TimerEventOptimizeCode> optimize_code_timer(isolate); RuntimeCallTimerScope runtimeTimer(isolate, RuntimeCallCounterId::kOptimizeCode); TRACE_EVENT0(TRACE_DISABLED_BY_DEFAULT("v8.compile"), "V8.OptimizeCode"); // In case of concurrent recompilation, all handles below this point will be // allocated in a deferred handle scope that is detached and handed off to // the background thread when we return. base::Optional<CompilationHandleScope> compilation; if (mode == ConcurrencyMode::kConcurrent) { compilation.emplace(isolate, compilation_info); } // All handles below will be canonicalized. CanonicalHandleScope canonical(isolate); // Reopen handles in the new CompilationHandleScope. compilation_info->ReopenHandlesInNewHandleScope(isolate); if (mode == ConcurrencyMode::kConcurrent) { if (GetOptimizedCodeLater(job.get(), isolate)) { job.release(); // The background recompile job owns this now. // Set the optimization marker and return a code object which checks it. function->SetOptimizationMarker(OptimizationMarker::kInOptimizationQueue); DCHECK(function->IsInterpreted() || (!function->is_compiled() && function->shared()->IsInterpreted())); DCHECK(function->shared()->HasBytecodeArray()); return BUILTIN_CODE(isolate, InterpreterEntryTrampoline); } } else { if (GetOptimizedCodeNow(job.get(), isolate)) return compilation_info->code(); } if (isolate->has_pending_exception()) isolate->clear_pending_exception(); return MaybeHandle<Code>(); }函数代码有点长,这里总结一下所做的操作:
- 如果之前该函数被mark为待优化的,则取消该mark(回想一下
--trace-opt的输出) - 如果debugger需要hook该函数,或者在该函数上下了断点,则不优化该函数,直接返回。
- 如果之前已经优化过该函数(存在OptimizedCodeCache),则直接返回之前优化后的代码。
- 重置当前函数的
profiler ticks,使得该函数不再hot,这样做的目的是使当前函数不被重复优化。 - 如果设置了一些禁止优化的参数(例如
%NeverOptimizeFunction,或者设置了turbo_filter),则取消当前函数的优化。 - 以上步骤完成后则开始优化代码,优化代码也有两种不同的方式,分别是并行优化和非并行优化。在大多数情况下执行的都是并行优化,因为速度更快。并行优化会先执行
GetOptimizedCodeLater函数,在该函数中判断一些异常条件,例如任务队列已满或者内存占用过高。如果没有异常条件,则执行OptimizedCompilationJob::PrepareJob函数,并继续在更深层次的调用PipelineImpl::CreateGraph来建图。如果GetOptimizedCodeLater函数工作正常,则将会把优化任务Job放入任务队列中。任务队列将安排另一个线程执行优化操作。另一个线程的栈帧如下,该线程将执行Job->ExecuteJob并在更深层次调用PipelineImpl::OptimizeGraph来优化之前建立的图结构:![]()
当另一个线程在优化代码时,主线程可以继续执行其他任务:
![]()
- 如果之前该函数被mark为待优化的,则取消该mark(回想一下
- 综上我们可以得知,JIT最终的优化位于
PipelineImpl类中,包括建图以及优化图等// v8\src\compiler\pipeline.cc class PipelineImpl final { public: explicit PipelineImpl(PipelineData* data) : data_(data) {} // Helpers for executing pipeline phases. template <typename Phase> void Run(); template <typename Phase, typename Arg0> void Run(Arg0 arg_0); template <typename Phase, typename Arg0, typename Arg1> void Run(Arg0 arg_0, Arg1 arg_1); // Step A. Run the graph creation and initial optimization passes. bool CreateGraph(); // B. Run the concurrent optimization passes. bool OptimizeGraph(Linkage* linkage); // Substep B.1. Produce a scheduled graph. void ComputeScheduledGraph(); // Substep B.2. Select instructions from a scheduled graph. bool SelectInstructions(Linkage* linkage); // Step C. Run the code assembly pass. void AssembleCode(Linkage* linkage); // Step D. Run the code finalization pass. MaybeHandle<Code> FinalizeCode(); // Step E. Install any code dependencies. bool CommitDependencies(Handle<Code> code); void VerifyGeneratedCodeIsIdempotent(); void RunPrintAndVerify(const char* phase, bool untyped = false); MaybeHandle<Code> GenerateCode(CallDescriptor* call_descriptor); void AllocateRegisters(const RegisterConfiguration* config, CallDescriptor* call_descriptor, bool run_verifier); OptimizedCompilationInfo* info() const; Isolate* isolate() const; CodeGenerator* code_generator() const; private: PipelineData* const data_; };


五、初探optimization phases
1. 简介
与LLVM IR的各种Pass类似,turboFan中使用各类phases进行建图、搜集信息以及简化图。
以下是PipelineImpl::CreateGraph函数源码,其中使用了大量的Phase。这些Phase有些用于建图,有些用于优化(在建图时也会执行一部分简单的优化),还有些为接下来的优化做准备:
bool PipelineImpl::CreateGraph() {
PipelineData* data = this->data_;
data->BeginPhaseKind("graph creation");
if (info()->trace_turbo_json_enabled() ||
info()->trace_turbo_graph_enabled()) {
CodeTracer::Scope tracing_scope(data->GetCodeTracer());
OFStream os(tracing_scope.file());
os << "---------------------------------------------------\n"
<< "Begin compiling method " << info()->GetDebugName().get()
<< " using Turbofan" << std::endl;
}
if (info()->trace_turbo_json_enabled()) {
TurboCfgFile tcf(isolate());
tcf << AsC1VCompilation(info());
}
data->source_positions()->AddDecorator();
if (data->info()->trace_turbo_json_enabled()) {
data->node_origins()->AddDecorator();
}
Run<GraphBuilderPhase>();
RunPrintAndVerify(GraphBuilderPhase::phase_name(), true);
// Perform function context specialization and inlining (if enabled).
Run<InliningPhase>();
RunPrintAndVerify(InliningPhase::phase_name(), true);
// Remove dead->live edges from the graph.
Run<EarlyGraphTrimmingPhase>();
RunPrintAndVerify(EarlyGraphTrimmingPhase::phase_name(), true);
// Run the type-sensitive lowerings and optimizations on the graph.
{
// Determine the Typer operation flags.
Typer::Flags flags = Typer::kNoFlags;
if (is_sloppy(info()->shared_info()->language_mode()) &&
info()->shared_info()->IsUserJavaScript()) {
// Sloppy mode functions always have an Object for this.
flags |= Typer::kThisIsReceiver;
}
if (IsClassConstructor(info()->shared_info()->kind())) {
// Class constructors cannot be [[Call]]ed.
flags |= Typer::kNewTargetIsReceiver;
}
// Type the graph and keep the Typer running on newly created nodes within
// this scope; the Typer is automatically unlinked from the Graph once we
// leave this scope below.
Typer typer(isolate(), data->js_heap_broker(), flags, data->graph());
Run<TyperPhase>(&typer);
RunPrintAndVerify(TyperPhase::phase_name());
// Do some hacky things to prepare for the optimization phase.
// (caching handles, etc.).
Run<ConcurrentOptimizationPrepPhase>();
if (FLAG_concurrent_compiler_frontend) {
data->js_heap_broker()->SerializeStandardObjects();
Run<CopyMetadataForConcurrentCompilePhase>();
}
// Lower JSOperators where we can determine types.
Run<TypedLoweringPhase>();
RunPrintAndVerify(TypedLoweringPhase::phase_name());
}
data->EndPhaseKind();
return true;
}
PipelineImpl::OptimizeGraph函数代码如下,该函数将会对所建立的图进行优化:
bool PipelineImpl::OptimizeGraph(Linkage* linkage) {
PipelineData* data = this->data_;
data->BeginPhaseKind("lowering");
if (data->info()->is_loop_peeling_enabled()) {
Run<LoopPeelingPhase>();
RunPrintAndVerify(LoopPeelingPhase::phase_name(), true);
} else {
Run<LoopExitEliminationPhase>();
RunPrintAndVerify(LoopExitEliminationPhase::phase_name(), true);
}
if (FLAG_turbo_load_elimination) {
Run<LoadEliminationPhase>();
RunPrintAndVerify(LoadEliminationPhase::phase_name());
}
if (FLAG_turbo_escape) {
Run<EscapeAnalysisPhase>();
if (data->compilation_failed()) {
info()->AbortOptimization(
BailoutReason::kCyclicObjectStateDetectedInEscapeAnalysis);
data->EndPhaseKind();
return false;
}
RunPrintAndVerify(EscapeAnalysisPhase::phase_name());
}
// Perform simplified lowering. This has to run w/o the Typer decorator,
// because we cannot compute meaningful types anyways, and the computed types
// might even conflict with the representation/truncation logic.
Run<SimplifiedLoweringPhase>();
RunPrintAndVerify(SimplifiedLoweringPhase::phase_name(), true);
// From now on it is invalid to look at types on the nodes, because the types
// on the nodes might not make sense after representation selection due to the
// way we handle truncations; if we'd want to look at types afterwards we'd
// essentially need to re-type (large portions of) the graph.
// In order to catch bugs related to type access after this point, we now
// remove the types from the nodes (currently only in Debug builds).
#ifdef DEBUG
Run<UntyperPhase>();
RunPrintAndVerify(UntyperPhase::phase_name(), true);
#endif
// Run generic lowering pass.
Run<GenericLoweringPhase>();
RunPrintAndVerify(GenericLoweringPhase::phase_name(), true);
data->BeginPhaseKind("block building");
// Run early optimization pass.
Run<EarlyOptimizationPhase>();
RunPrintAndVerify(EarlyOptimizationPhase::phase_name(), true);
Run<EffectControlLinearizationPhase>();
RunPrintAndVerify(EffectControlLinearizationPhase::phase_name(), true);
if (FLAG_turbo_store_elimination) {
Run<StoreStoreEliminationPhase>();
RunPrintAndVerify(StoreStoreEliminationPhase::phase_name(), true);
}
// Optimize control flow.
if (FLAG_turbo_cf_optimization) {
Run<ControlFlowOptimizationPhase>();
RunPrintAndVerify(ControlFlowOptimizationPhase::phase_name(), true);
}
// Optimize memory access and allocation operations.
Run<MemoryOptimizationPhase>();
// TODO(jarin, rossberg): Remove UNTYPED once machine typing works.
RunPrintAndVerify(MemoryOptimizationPhase::phase_name(), true);
// Lower changes that have been inserted before.
Run<LateOptimizationPhase>();
// TODO(jarin, rossberg): Remove UNTYPED once machine typing works.
RunPrintAndVerify(LateOptimizationPhase::phase_name(), true);
data->source_positions()->RemoveDecorator();
if (data->info()->trace_turbo_json_enabled()) {
data->node_origins()->RemoveDecorator();
}
ComputeScheduledGraph();
return SelectInstructions(linkage);
}
由于上面两个函数涉及到的Phase众多,这里请各位自行阅读源码来了解各个Phase的具体功能。
接下来我们只介绍几个比较重要的Phases:GraphBuilderPhase、TyperPhase和SimplifiedLoweringPhase。
2. GraphBuilderPhase
-
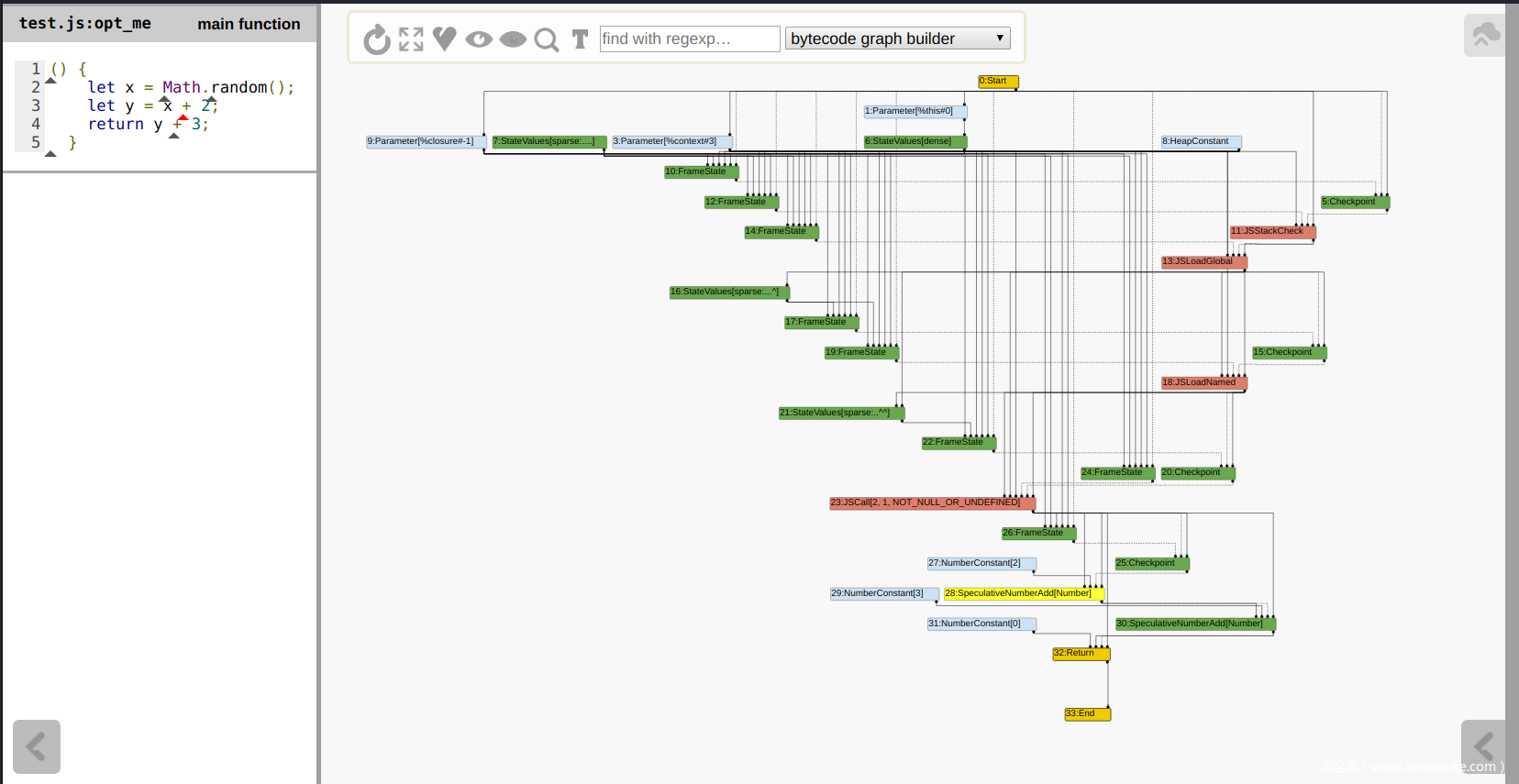
GraphBuilderPhase将遍历字节码,并建一个初始的图,这个图将用于接下来Phase的处理,包括但不限于各种代码优化。 - 一个简单的例子
![]()
3. TyperPhase
-
TyperPhase将会遍历整个图的所有结点,并给每个结点设置一个Type属性,该操作将在建图完成后被执行给每个结点设置Type的操作是不是极其类似于编译原理中的语义分析呢? XD
bool PipelineImpl::CreateGraph() { // ... Run<GraphBuilderPhase>(); RunPrintAndVerify(GraphBuilderPhase::phase_name(), true); // ... // Run the type-sensitive lowerings and optimizations on the graph. { // ... // Type the graph and keep the Typer running on newly created nodes within // this scope; the Typer is automatically unlinked from the Graph once we // leave this scope below. Typer typer(isolate(), data->js_heap_broker(), flags, data->graph()); Run<TyperPhase>(&typer); RunPrintAndVerify(TyperPhase::phase_name()); // ... } // ... }其中,具体执行的是
TyperPhase::Run函数:struct TyperPhase { static const char* phase_name() { return "typer"; } void Run(PipelineData* data, Zone* temp_zone, Typer* typer) { // ... typer->Run(roots, &induction_vars); } };在该函数中继续调用
Typer::Run函数,并在GraphReducer::ReduceGraph函数中最终调用到Typer::Visitor::Reduce函数:void Typer::Run(const NodeVector& roots, LoopVariableOptimizer* induction_vars) { // ... Visitor visitor(this, induction_vars); GraphReducer graph_reducer(zone(), graph()); graph_reducer.AddReducer(&visitor); for (Node* const root : roots) graph_reducer.ReduceNode(root); graph_reducer.ReduceGraph(); // ... }在
Typer::Visitor::Reduce函数中存在一个较大的switch结构,通过该switch结构,当Visitor遍历每个node时,即可最终调用到对应的XXXTyper函数。例如,对于一个JSCall结点,将在TyperPhase中最终调用到
Typer::Visitor::JSCallTyper - 这里我们简单看一下
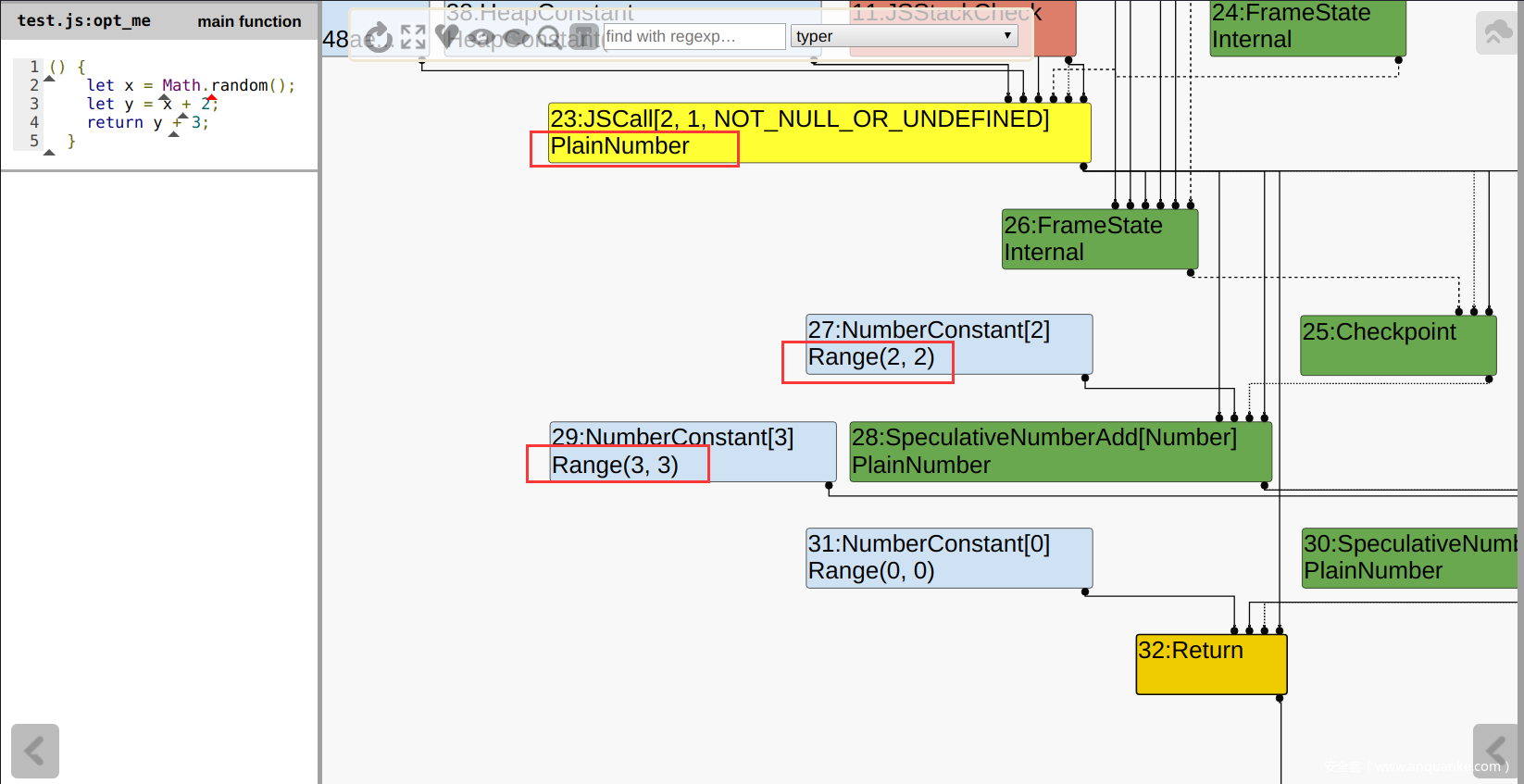
JSCallTyper函数源码,该函数中存在一个很大的switch结构,该结构将设置每个Builtin函数结点的Type属性,即函数的返回值类型。Type Typer::Visitor::JSCallTyper(Type fun, Typer* t) { if (!fun.IsHeapConstant() || !fun.AsHeapConstant()->Ref().IsJSFunction()) { return Type::NonInternal(); } JSFunctionRef function = fun.AsHeapConstant()->Ref().AsJSFunction(); if (!function.shared().HasBuiltinFunctionId()) { return Type::NonInternal(); } switch (function.shared().builtin_function_id()) { case BuiltinFunctionId::kMathRandom: return Type::PlainNumber(); // ... - 而对于一个常数
NumberConstant类型,TyperPhase也会打上一个对应的类型Type Typer::Visitor::TypeNumberConstant(Node* node) // 注意这里使用的是double,这也就说明了为什么Number.MAX_SAFE_INTEGER = 9007199254740991 double number = OpParameter<double>(node->op()); return Type::NewConstant(number, zone()); }而在
Type::NewConstant函数中,我们会发现一个神奇的设计:Type Type::NewConstant(double value, Zone* zone) { // 对于一个正常的整数 if (RangeType::IsInteger(value)) { // 实际上所设置的Type是一个range! return Range(value, value, zone); // 否则如果是一个异常的-0,则返回对应的MinusZero } else if (IsMinusZero(value)) { return Type::MinusZero(); // 如果是NAN,则返回NaN } else if (std::isnan(value)) { return Type::NaN(); } DCHECK(OtherNumberConstantType::IsOtherNumberConstant(value)); return OtherNumberConstant(value, zone); }对于JS代码中的一个NumberConstant,实际上设置的Type是一个Range,只不过这个Range的首尾范围均是该数,例如
NumberConstant(3) => Range(3, 3, zone) - 以下这张图可以证明
TyperPhase正如预期那样执行:![]()
- 与之相应的,v8采用了SSA。因此对于一个Phi结点,它将设置该节点的Type为几个可能值的Range的并集。
Type Typer::Visitor::TypePhi(Node* node) { int arity = node->op()->ValueInputCount(); Type type = Operand(node, 0); for (int i = 1; i < arity; ++i) { type = Type::Union(type, Operand(node, i), zone()); } return type; }请看以下示例:
![]()
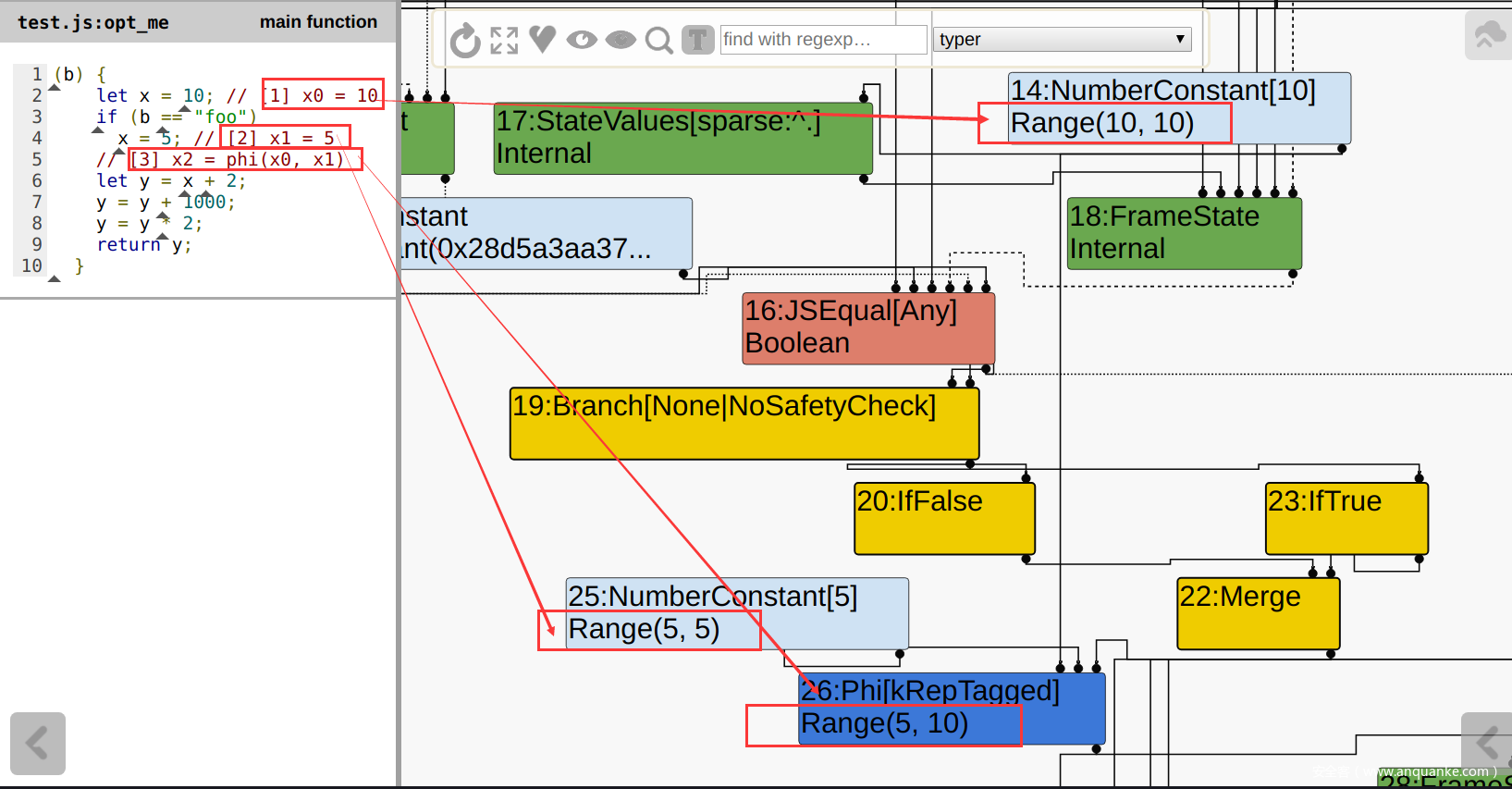
4. SimplifiedLoweringPhase
-
SimplifiedLoweringPhase会遍历结点做一些处理,同时也会对图做一些优化操作。这里我们只关注该Phase优化CheckBound的细节,因为CheckBound通常是用于判断 JS数组(例如ArrayBuffer) 是否越界使用 所设置的结点。 - 首先我们可以通过以下路径来找到优化
CheckBound的目标代码:SimplifiedLoweringPhase::Run SimplifiedLowering::LowerAllNodes RepresentationSelector::Run RepresentationSelector::VisitNode目标代码如下:
// Dispatching routine for visiting the node {node} with the usage {use}. // Depending on the operator, propagate new usage info to the inputs. void VisitNode(Node* node, Truncation truncation, SimplifiedLowering* lowering) { // Unconditionally eliminate unused pure nodes (only relevant if there's // a pure operation in between two effectful ones, where the last one // is unused). // Note: We must not do this for constants, as they are cached and we // would thus kill the cached {node} during lowering (i.e. replace all // uses with Dead), but at that point some node lowering might have // already taken the constant {node} from the cache (while it was in // a sane state still) and we would afterwards replace that use with // Dead as well. if (node->op()->ValueInputCount() > 0 && node->op()->HasProperty(Operator::kPure)) { if (truncation.IsUnused()) return VisitUnused(node); } switch (node->opcode()) { // ... case IrOpcode::kCheckBounds: { const CheckParameters& p = CheckParametersOf(node->op()); Type index_type = TypeOf(node->InputAt(0)); Type length_type = TypeOf(node->InputAt(1)); if (index_type.Is(Type::Integral32OrMinusZero())) { // Map -0 to 0, and the values in the [-2^31,-1] range to the // [2^31,2^32-1] range, which will be considered out-of-bounds // as well, because the {length_type} is limited to Unsigned31. VisitBinop(node, UseInfo::TruncatingWord32(), MachineRepresentation::kWord32); if (lower() && lowering->poisoning_level_ == PoisoningMitigationLevel::kDontPoison) { // 可以看到,如果当前索引的最大值小于length的最小值,则表示当前索引的使用没有越界 if (index_type.IsNone() || length_type.IsNone() || (index_type.Min() >= 0.0 && index_type.Max() < length_type.Min())) { // The bounds check is redundant if we already know that // the index is within the bounds of [0.0, length[. // CheckBound将会被优化 DeferReplacement(node, node->InputAt(0)); } } } else { VisitBinop( node, UseInfo::CheckedSigned32AsWord32(kIdentifyZeros, p.feedback()), UseInfo::TruncatingWord32(), MachineRepresentation::kWord32); } return; } // .... } // ... }可以看到,在
CheckBound的优化判断逻辑中,如果当前索引的最大值小于length的最小值,则表示当前索引的使用没有越界,此时将会移除CheckBound结点以简化IR图。需要注意NumberConstant结点的Type是一个Range类型,因此才会有最大值Max和最小值Min的概念。
- 这里需要解释一下环境搭配中所说的,为什么要添加一个编译参数
v8_optimized_debug = false,注意看上面判断条件中的这行条件if (lower() && lowering->poisoning_level_ == PoisoningMitigationLevel::kDontPoison)visitNode时有三个状态,分别是Phase::PROPAGATE(信息收集)、Phase::RETYPE(从类型反馈中获取类型)以及Phase::LOWER(开始优化)。当真正开始优化时,lower()条件自然成立,因此我们无需处理这个。但对于下一个条件,通过动态调试可以得知,
poisoning_level始终不为PoisoningMitigationLevel::kDontPoison。通过追溯lowering->poisoning_level_,我们可以发现它实际上在PipelineCompilationJob::PrepareJobImpl中被设置PipelineCompilationJob::Status PipelineCompilationJob::PrepareJobImpl( Isolate* isolate) { // ... // Compute and set poisoning level. PoisoningMitigationLevel load_poisoning = PoisoningMitigationLevel::kDontPoison; if (FLAG_branch_load_poisoning) { load_poisoning = PoisoningMitigationLevel::kPoisonAll; } else if (FLAG_untrusted_code_mitigations) { load_poisoning = PoisoningMitigationLevel::kPoisonCriticalOnly; } // ... }而
FLAG_branch_load_poisoning始终为false,FLAG_untrusted_code_mitigations始终为true编译参数v8_untrusted_code_mitigations 默认 true,使得宏DISABLE_UNTRUSTED_CODE_MITIGATIONS没有被定义,因此默认设置
FLAG_untrusted_code_mitigations = true// v8/src/flag-definitions.h // 设置`FLAG_untrusted_code_mitigations` #ifdef DISABLE_UNTRUSTED_CODE_MITIGATIONS #define V8_DEFAULT_UNTRUSTED_CODE_MITIGATIONS false #else #define V8_DEFAULT_UNTRUSTED_CODE_MITIGATIONS true #endif DEFINE_BOOL(untrusted_code_mitigations, V8_DEFAULT_UNTRUSTED_CODE_MITIGATIONS, "Enable mitigations for executing untrusted code") #undef V8_DEFAULT_UNTRUSTED_CODE_MITIGATIONS // 设置`FLAG_branch_load_poisoning` DEFINE_BOOL(branch_load_poisoning, false, "Mask loads with branch conditions.")# BUILD.gn declare_args() { # ... # Enable mitigations for executing untrusted code. # 默认为true v8_untrusted_code_mitigations = true # ... } # ... if (!v8_untrusted_code_mitigations) { defines += [ "DISABLE_UNTRUSTED_CODE_MITIGATIONS" ] } # ...这样就会使得
load_poisoning始终为PoisoningMitigationLevel::kPoisonCriticalOnly,因此始终无法执行checkBounds的优化操作。所以我们需要手动设置编译参数v8_untrusted_code_mitigations = false,以启动checkbounds的优化。 - 以下是一个简单checkbounds优化的例子
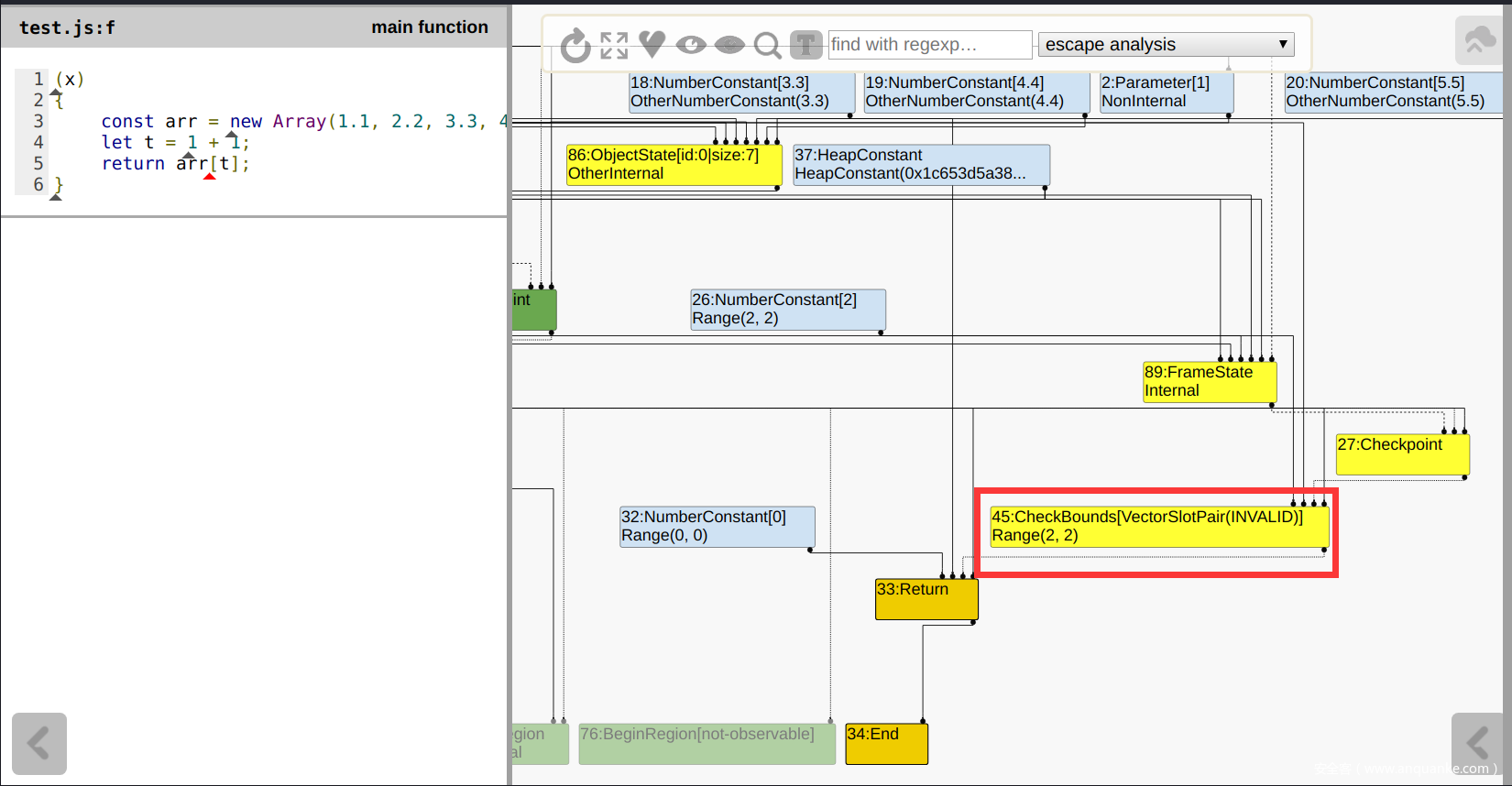
function f(x) { const arr = new Array(1.1, 2.2, 3.3, 4.4, 5.5); let t = 1 + 1; return arr[t]; } console.log(f(1)); %OptimizeFunctionOnNextCall(f); console.log(f(1));优化前发现存在一个checkBounds:
![]()
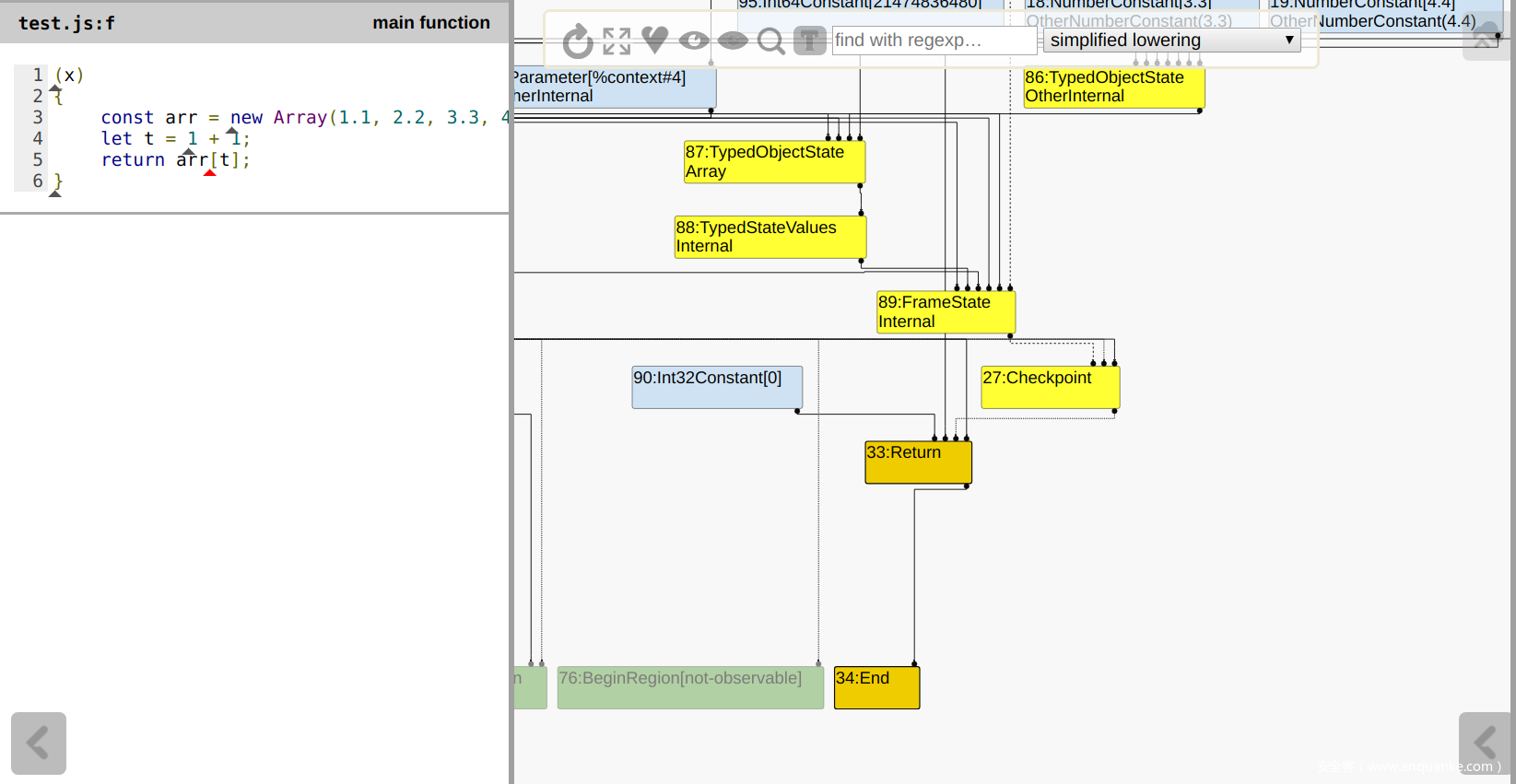
执行完
SimplifiedLoweringPhase后,CheckBounds被优化了:![]()






发表评论
您还未登录,请先登录。
登录