
介绍
“ Karta”是IDA的python插件,其功能是在已经编译过的二进制文件中搜索是否使用了开源的代码。该插件是为了匹配大体积二进制文件中的开放源代码库的开源代码(通常是查找固件)。对于每天处理固件的人来说,反复的执行net-snmp显然是在浪费时间。所以需要一个工具来识别二进制文件所使用的开源,并在IDA中自动匹配。
这个插件的初衷是加快匹配的过程。用几个小时去匹配一个包含300个函数的库是很低效的一件事,更何况实际工作过程中逆向的工程会远大于此,比如超过100,000个函数的体积。当然,结合逆向工程行业的一些经验教训,我们解决了这个问题,并取得了比预期更好的结果。
事实证明,出于性能原因而部署的启发式方法对匹配结果也有很大的影响。该插件产生的误报率非常低,而准确性很高。这对于匹配中小型二进制文件也很有用。
因此,我们认为Karta可以成为研究人员的重要工具。
Karta的功能如下:
- 侦查阶段–鉴别二进制文件中使用的开源代码,包括其版本。
- 清除混淆状况-为使用的开源代码匹配符号,从而节省逆向工程看起来是已知功能的时间。
- 查找1 day–使用已使用的开源代码列表,其符号已在二进制文件中匹配,可以轻松地在可执行文件\固件文件中查找1 day。
Karta
如前所述,Karta是IDA的源代码辅助二进制匹配插件。该插件实现了2个功能:
- 1.标识–标识静态编译的开源代码的确切版本。
- 2.匹配–匹配已识别开源的符号。
该插件的源代码现在可以在Github中找到。
有时在不同体系架构上编译开源库是一件非常困难的事,因此我们通过使插件体系架构独立来消除了此步骤。例如,如果我们要匹配libpng开源版本1.2.29 (在HP OfficeJet固件中使用的版本),我们要做的就是从Github克隆它并在我们的(x86)机器上编译它。编译之后,Karta可以生成一个描述该库的规范的.json配置文件。使用此配置,即使固件已编译为Big-Endian ARM Thumb模式,我们的插件现在也可以成功地在固件中找到该库。
Karta由模块组成,IDA反汇编器模块可以用任何其他反汇编模块代替。
寻找 1 day
虽然我们描述了插件的几个使用案例,但在流行软件中寻找1day可能是最有趣的。这是我们研究的两个现实的例子。
HP OfficeJet固件
在我们的FAX研究过程中,我们需要1天的时间才能用作调试漏洞。最终,我们使用了Devil’s Ivy。在完成Karta的开发之后,就该回到固件并检查Karta如何帮助我们进行研究了。
Karta的返回结果显示固件中使用的开源库是:
- libpng: 1.2.29
- zlib: 1.2.3
- OpenSSL: 1.0.1.j
- mDNSResponder: unknown
- gSOAP: 2.7
在这里我们可以看到确实使用了gSOAP,并且快速的CVE搜索表明它包含一个关键漏洞:CVE-2017-9765(Devil’s Ivy)。
在为该版本的gSOAP快速编译配置后,我们运行了匹配器并导入了匹配的符号。在这里我们可以看到Karta匹配了易受攻击的代码函数soap_get_pi:
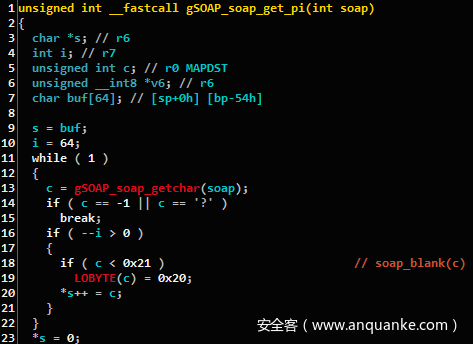
图1:反编译的soap_get_pi函数,与插件匹配。
对于我们的插件来说,这是个好消息:它可以在实际情况下按预期工作。
普通的闭源软件– TeamViewer
在固件中轻松找到1day很方便,但是我们在Windows PC上使用的日常程序又如何呢?在阅读Project Zero在WebRTC上的博客文章时,我们看到他们在一个名为libvpx的库中发现了一个漏洞:
CVE-2018-6155 在称为VP8的视频编解码器中可以免费使用。有趣的是,由于它会影响VP8库libvpx而不是WebRTC中的代码,因此它有可能影响使用WebRTC之外的使用该库的软件。由于此错误,发布了针对libvpx的通用修复程序。
这看起来很有趣,因为Project Zero特别指出此漏洞“具有影响使用WebRTC以外的其他功能使用该库的软件的潜力。” 我们已经在计算机上安装了TeamViewer,听起来应该使用相同的开源库,让我们检查一下。
我们在IDA中打开了TeamViewer.exe,并在进行分析的同时开始工作。我们下载了最新版本的libvpx(1.7.0),为其编写了一个简单的标识符,并将其添加到Karta。由于我们等不及IDA完成分析,因此我们停止了分析并运行Karta的标识符插件。确定的开源是:
- zlib: 1.2.5
- mDNSResponder: unknown
- libjpeg: 8b
- libvpx: 1.6.1
TeamViewer不仅使用libvpx,而且使用的是2017年1月以来的旧版本。
查看Google发行的补丁,我们知道我们感兴趣的函数是vp8_deblock,如下所示:
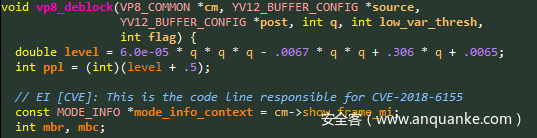
图2: vp8_deblock函数的代码片段,容易受到CVE-2018-6155的攻击
我们让IDA恢复分析,并着手为libvpx版本1.6.1编译Karta配置。准备好配置后,在IDA完成对二进制文件的分析之后,我们运行了Karta的Matcher插件。如您所见,匹配器发现了我们易受攻击的函数:

图3: Karta的匹配结果显示,它与易受攻击的功能相匹配-用蓝色突出显示。
将结果导入IDA之后,我们可以使用数字常量清楚地看到这是正确的匹配。
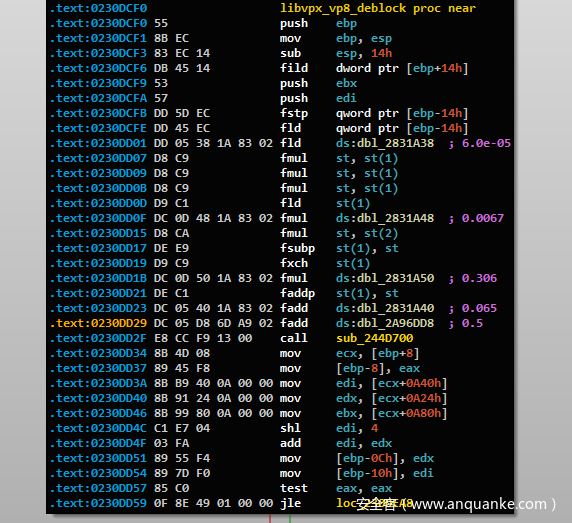
图4:易受攻击的功能,与我们的插件相匹配,如IDA Pro中所示。
有了它,我们在TeamViewer程序中发现了一个漏洞,甚至我们确切地知道了调试断点的位置。整个过程大约花费了2个小时。唯一的瓶颈是IDA的分析,因为TeamViewer是一个相当大的程序,其中包含143,000多个函数。
Karta –如何运作?
二进制匹配
二进制匹配的核心可以归结为最基本的问题:我们要检查两个函数(一个来自已编译的开源程序,另一个来自我们的二进制程序)是否代表同一个函数。为了能够比较这两个函数,我们需要将它们转换为统一的基本表示形式,通常称为“规范表示形式”。这种表示形式通常包括我们从函数中提取的一组功能:数字常量列表,字符串列表,汇编指令数量等。
当尝试匹配一组相关函数(例如,已编译的开源项目)时,我们会在规范表示中存储其他信息,以便对函数之间的关系进行编码:被调用函数(被调用方)列表,调用我们(调用者)等的函数。使用此信息,我们可以尝试根据两个函数在控制流图(CFG)中的规则/位置来进行匹配。
在这里,我们使用一些传统的二进制匹配工具,例如BinDiff或Diaphora。尽管每个匹配工具都有自己独特的匹配启发法,但它们都基于相同的归约法:比较两个规范表示并对结果进行评分。这意味着二进制匹配工具首先将所有函数转换为它们的规范表示形式,然后再继续。
避免内存爆炸
当分析具有大约65,000个函数的二进制文件(例如我们的OfficeJet打印机的固件)时,为所有函数构建规范表示的过程根本无法扩展。这会花费很长时间(通常超过一个小时),并且会消耗3GB以上的磁盘空间。不用说,稍后将此数据集加载到内存中通常会使匹配的程序崩溃。
如果我们想匹配巨大体积的二进制文件时,则需要改变策略。由于开源库相对较小,因此我们的问题可描述为:
M –我们开源中的功能数量
N –二进制中的函数数
我们希望在大小为N的二进制文件中匹配M函数,其中M << N,理想情况下是通过消耗依赖于M而不依赖于N的内存。
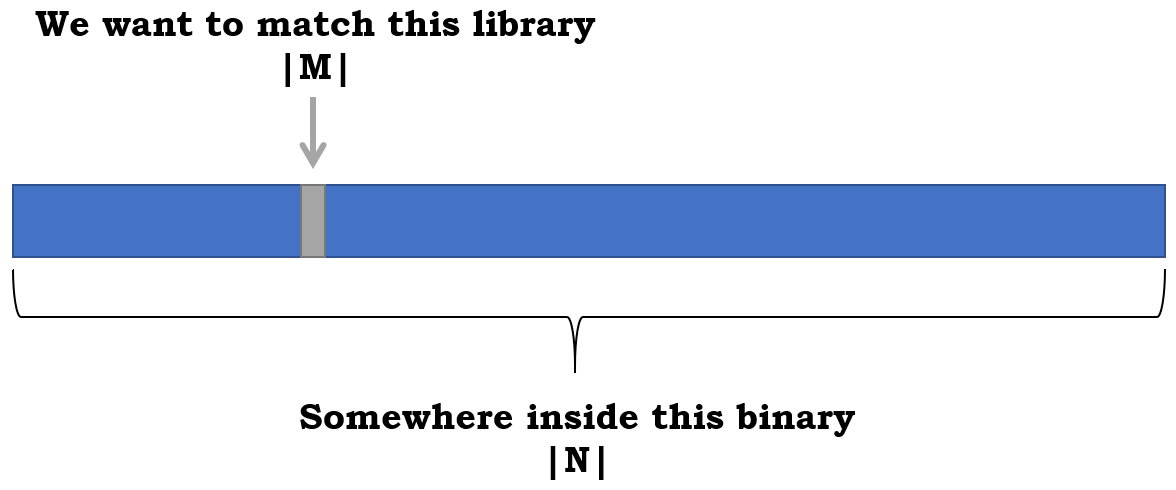
图5:我们尝试在其中匹配库的二进制地址空间的图示。
关键思想–链接器位置
如果我们搁置一个稍后将要讨论的特殊情况,则可以简化编译过程并链接到以下步骤:
- 1.编译器独立地编译每个源文件,并创建一个匹配的二进制文件(对于gcc为.o,对于Visual Studio为.obj)。
- 2.链接器将所有二进制文件组合到单个二进制Blob中。
- 3.在链接阶段,此Blob将按原样插入最终程序/固件。
这导致两个重要的结论:
- 1.编译后的源代码包含在固件/可执行文件内的单个连续Blob中。
- 2.一旦找到该Blob的单个代表(将其称为anchor),我们就可以根据我们知道应该在该Blob中的函数数量来推测二进制中该Blob的上下边界。
从本质上讲,这是Karta所基于的关键点。
Karta — 创建map
Karta是源代码辅助工具。通过利用源代码中的信息,我们可以构建一个映射:哪个函数包含在哪个文件中,以及库包含哪些文件。
这是匹配二进制库的过程:
- 1.从一个基本的标识符脚本开始,该脚本检查二进制文件是否使用了该库,以及使用的是哪个版本– O(N)时间和O(1)内存消耗。
- 2.确定后,扫描二进制文件以查找锚函数-O(N)时间和O(1)内存消耗。
- 3.使用定位的锚点函数放大可能在我们的库中包含的二进制函数的推测范围– O(1)时间和O(1)内存消耗。
- 4.从这一点出发,所有逻辑都将集中在大小为O(M)的范围内。
这是一个例子:
- 我们的库具有322个函数,并且找到5个锚定函数。
- 最低锚点位于二进制文件中的函数#2622处。
- 最高锚点位于二进制文件中的函数#2842处。
- 锚点之间包含的范围包括2842 – 2622 +1 = 221个函数。
- 我们仍然需要找到322 – 221 = 101个函数。
- 为了安全起见,在我们的地图中,我们在第一个锚点之前包含101个函数,在最后一个锚点之后包含101个函数。
- 总体而言,所关注函数的数量:101 + 221 + 101 = 423个函数<< 65,000(全二进制)。
我们现在要做的就是仅针对所关注的函数构建规范的表示形式,从而从那时起极大地提高我们的性能。
注意:该映射可能会进一步提供帮助,因为文件ac中的函数foo()仅应与ac中的函数匹配。这样就无需将其与我们已经确定为驻留在不同文件中的函数进行比较。
锚点的选择
就其性质而言,锚函数在我们得到规范表示之前便已匹配。这限制了我们在搜索函数时可以使用的函数。另外,我们要确保我们的锚点唯一地标识我们的库,并且不包括对我们正在处理的二进制文件中的其他库的任何误报。
在不事先了解所有开放源代码是什么样的情况下,决定复杂的独特函数的标准有点雄心勃勃。但是,我们编写了一些启发式方法,这些方法在实践中效果很好。我们扫描开源中的所有函数,并搜索唯一的数字常量和唯一的字符串。如果常量足够复杂(具有较高熵的数字或足够长的字符串),或者可以组合在一起以具有足够的唯一性(例如:同一函数中的3个唯一的中等长度字符串),则我们将该函数标记为锚。
这是在OpenSSL中找到的锚点函数的示例:
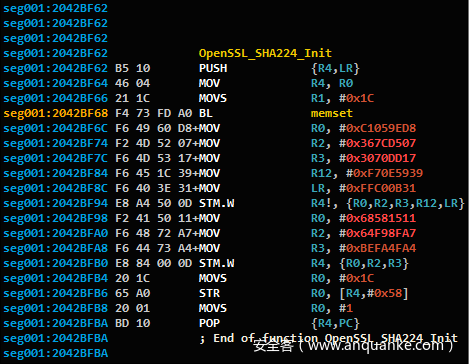
图6:在IDA Pro中可以看到来自OpenSSL的SHA224_Init函数
我们选择此函数是因为其独特的数字常量。
确切的规则是可配置的,可以在以下文件中找到:src / config / anchor_config.py
匹配步骤
每个受支持的库都有一个标识符,试图将其定位在二进制文件中。由于大多数开放源代码都包含唯一的字符串(通常带有完整的版本详细信息),因此大多数标识符都是基于字符串的,并为它们尝试识别的库进行了配置。找到该库后,标识符将尝试提取版本信息,并对可执行文件/固件使用的确切版本进行指纹识别。
说开源项目试图隐藏它们在已编译二进制文件中的存在就离事实不远了。这些库不仅经常包含唯一的字符串(短时间的Google搜索可以将其识别为原始库的线索),而且它们通常包含不必要的信息。这是来自libpng的版权声明的示例,该字符串是用二进制文件编译的:

图7:来自libpng的版权字符串,包含在已编译的二进制文件中
在大多数情况下,确定可执行文件中是否存在开放源代码库相对容易。
尽管在标识阶段还有其他解决方案,例如Google最近在Project Zero博客中描述的解决方案,但似乎很难与这种基本但有效的简单字符串搜索竞争。依靠标识符的出色结果,我们决定将大部分精力集中在匹配逻辑上,以使标识符保持整洁而简单。
由于标识符的简化性质,我们希望其他研究人员可以轻松扩展我们的插件并添加对新的开源库的支持。由于它是开源的,因此对我们插件的任何贡献也将帮助社区中的其他研究人员完成他们的项目。
使用标识符中的信息,将加载特定库版本的配置(基于.json *)。第一步是在二进制文件中扫描与我们库的锚定函数匹配的唯一数字常量和唯一字符串。没有锚,我们将无法放大库并继续进行匹配过程。
比赛开始后,整个配置将被加载到内存中。这消除了使用更流行的sqlite数据库的需求,因为我们没有关于配置的查询。从sqlite到json的过渡导致配置文件(KB代替MB)的大小大大减少。
使用由匹配的锚点定义的聚焦函数范围,我们绘制了文件映射的初始草图。我们可以查明每个包含匹配锚函数的文件的位置,并估计其下限和上限(使用与前面所述相同的逻辑)。其余文件被标记为“浮动”,并被称为“无处不在”;它们可以位于整个重点区域内的任何位置。
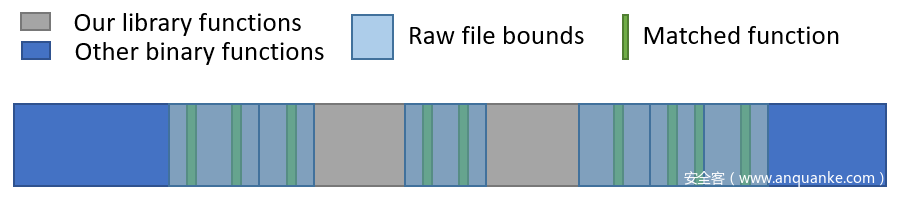
图8:到目前为止我们匹配结果的示例图
许多开源项目倾向于包含包含源文件名称的调试/跟踪字符串。通常,这些字符串位于提到的源文件中的函数中,这意味着我们可以将它们用作文件提示。绘制初始map后,我们可以使用这些提示来精确定位其他文件的位置。依靠搜索空间很小的事实,以及这些字符串的性质,这些匹配项将具有相对较高的准确率。
一个代理是本地唯一的函数。它也可以称为本地锚。在其文件中,它是一个锚点,但是它包含的常数比全局锚点所要求的常数弱。每个找到的文件都尝试匹配其自身的代理,再次以相对较高的准确率。
从这一点来看,我们的逻辑是相当传统的。基于两个规范表示的相似性,每次匹配尝试都会得到一个分数。当没有更多函数要匹配时,或者当匹配回合未能找到新的匹配项时,或者当内部文件识别出内部假设无法成立时,匹配结束。当IDA存在分析问题或存在链接程序优化时,通常会发生后一种情况。
如前所述,Karta尝试使用尽可能多的匹配知识,包括:
- 函数必须仅与同一文件中的函数匹配。
- 静态函数不能被其他文件中的函数引用。
- 编译器倾向于保持局部性,这意味着相邻的源函数也倾向于以二进制形式保持相邻。
在实际案例中,这些基于位置的启发式方法均已显着改善了匹配结果。可以在Karta的文档阅读文档中找到匹配的启发式技巧的完整列表,可从我们的Github存储库访问该文档。
在此之前,我们选择忽略了一个很重要的问题:Karta的主要假设是,开源将被编译为一个连续的Blob,并且内部文件不会相互混合。不幸的是,使用链接器优化进行编译时并非如此,使用Visual Studio编译Windows程序时就已经如此。
确实,当我们最初尝试在Adobe PDF的一个二进制文件(2d.x3d)中匹配libtiff时,我们得到的结果并不理想:只有176/500个函数被匹配。经过调查,链接器将具有相同二进制结构的函数组合在一起。例如,使用不同名称或不同名称范围两次实施的函数(来自不同文件的静态函数)。
图9a:来自libtiff的两个相同函数中的第一个,驻留在不同文件中
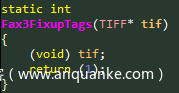
图9b:来自libtiff的两个相同函数的第二个函数,位于不同文件中。
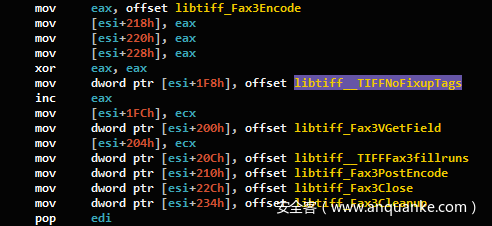
图10:来自IDA Pro的分析,显示使用的是上部函数,而不是下部的函数
尽管此优化减小了可执行文件的大小,但它不仅与我们的位置假设不符,而且还大大改变了控制流程图。两个不相关的函数(每个函数都有自己的边缘)将被合并到调用图中的单个顶点中。稍后进行了几次快速检查,我们发现此优化还会破坏其他二进制匹配工具的匹配结果。
我们决定像链接器一样解决此问题。在为开源库编译规范表示时,我们对每个函数的链接器视图进行哈希处理,并将其存储为唯一的函数ID。最初我们对字节本身进行了哈希处理,但是当两个函数引用相同的全局变量并且该变量位于每个文件中的不同偏移量时,引入了一个错误。请参见图11和12。我们通过对大多数操作码的字节进行哈希处理,并在引用导出的全局变量时对指令的文本进行哈希处理来解决此问题。
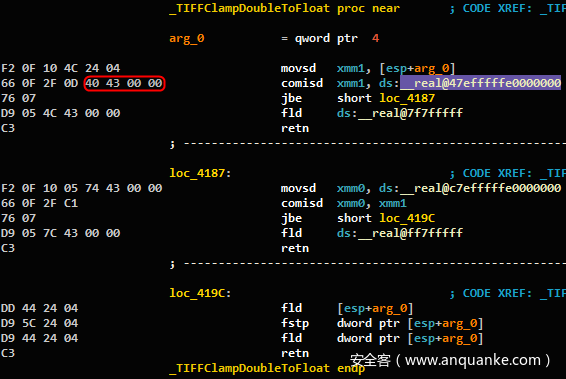
图11:文件tif_dirwrite.c中的函数TIFFClampDoubleToFloat()
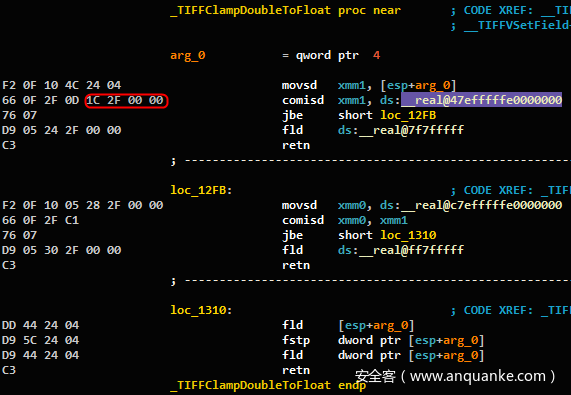
图12:文件tif_dir.c中的函数TIFFClampDoubleToFloat()
我们的匹配器使用这些“冲突ID”来定义链接程序可能决定合并在一起的潜在合并候选者组。在匹配过程中,匹配器会寻找任何可能合并的线索。当匹配器在控制流程图中发现两个合并候选函数是同一二进制函数的可能候选者时,它可以确定发生了合并。做出此决定后,二进制函数现在知道它代表了几个源函数,并将保存与其匹配的合并源函数的列表。
使用此优化,我们现在可以修复控制流图中的异常,因为每个检测到的合并有效地将控制流图扩展到链接器优化之前的一步,使其恢复到其原始状态。在同一二进制文件(2d.x3d)上再次进行测试时,我们获得了明显更好的结果:匹配了248/500个函数,提高了41%。
如图所示,Karta为函数_TIFFNoFixupTags确定了链接器的优化:

图13:来自Karta的匹配结果,可成功识别链接器合并的函数
现在该测试Karta如何处理我们原始的OfficeJet固件了。我们在计算机上的虚拟机(VM)(不是最佳基准测试环境)中测试了插件,结果如下:
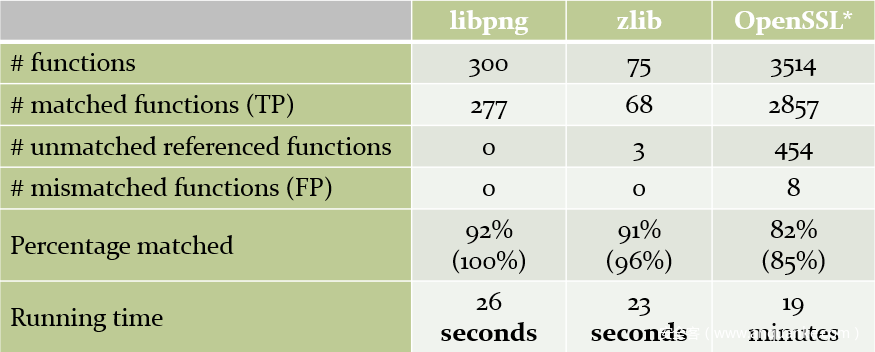
图14:经过测试的OfficeJet固件的匹配结果
我们可以很容易地看到,即使有大约65,000个函数,将开源与300个函数(如libpng)进行匹配也用了不到30秒的时间。另外,我们能够匹配所有引用的库函数,即在控制流程图中具有至少一条边的函数。
验证结果的唯一方法是对IDA中的函数进行手动分析。由于OpenSSL包含大量的函数(对于开放源代码),因此误报率可能更高,因为我们没有手动分析其所有函数。
事实证明,Karta比我们的手动分析更为准确,因为在大多数冲突中,事实证明我们是错的,Karta对该函数的标记做得更好。
注意事项1:请务必注意,由于Karta致力于函数的规范表示,因此与体系架构无关。我们用于上述比较的配置是在x86 32位设置上使用gcc进行编译的,后来与Big-Endian ARM Thumb模式二进制文件匹配。
注意事项2:因为我们的匹配是从匹配的开源库的角度进行的,所以我们还可以推断出“外部”函数的信息,这些函数不是我们库的一部分,而是从我们的库中调用的。例如,libpng使用zlib,因此我们的匹配器甚至在开始匹配zlib之前就能够识别inflateEnd和deflateEnd函数。

图15:在libpng匹配期间匹配的外部zlib函数
此外,在大多数情况下,我们能够匹配标准库中的函数,例如:memcpy,memcmp,malloc等。任何致力于反编译固件文件的研究人员都知道,缺少FLIRT签名使得必须通过以下方式启动每个项目:反转并匹配流行的libc函数。通过使用Karta,大多数流行的函数将“免费”匹配,从而使我们无需弄清楚哪个函数是memcpy,哪个函数是memmove。
与已知的Bin-Diffing工具比较
我们知道,有时很难区分所有可用的二进制比较/匹配工具。既然我们已经完成了Karta的介绍,那么现在是将我们的插件与其他流行工具进行比较的好时机,重点关注每种工具的不同目标和特征。请记住,我们没有对工具的结果进行基准测试,主要是因为这些工具并非针对同一目标而设计。
由于我们无法比较所有现有工具,因此我们选择关注以下流行工具:
BinDiff: “ BinDiff是二进制文件的比较工具,是协助漏洞的研究人员和工程师们迅速地找到反汇编代码的异同。
使用BinDiff,可以识别和隔离针对供应商提供的补丁程序中的漏洞的修复程序。还可以在多个版本的同一二进制文件的反汇编之间移植符号和注释,或使用BinDiff收集代码盗窃或专利侵权的证据。”
Diaphora: “ Diaphora(Diaphora(διαφορά,希腊语,表示“差异”),是IDA的程序差异插件,类似于Zynamics Bindiff或其他FOSS同行,例如YaDiff,DarunGrim,TurboDiff等,它在SyScan 2015期间发布。”
Pigaios: “ Pigaios(’πηγαίος’,在’source code’中为希腊语,意为’source’)是一种直接针对二进制文件比较/匹配源代码的工具。这个想法是将一个工具指向一个代码库,而不管它是否可以编译(例如,部分源代码或平台上没有可用的源代码),从该代码库中提取信息,然后导入一个代码库中。 IDA数据库函数名称(符号),结构和枚举。”
FunctionSimSearch:FunctionSimSearch是一组工具,可有效地对相对较大的可能函数(二进制)进行模糊搜索。这些工具的目的是匹配已知的(可能是易受攻击的)函数,以识别静态链接的软件库*。
Karta: “ Karta(俄语为“ map”)是一个IDA Python插件,用于识别和匹配给定二进制文件中的开源库。该插件使用独特的技术,使其能够支持庞大的二进制文件(> 200,000个函数),而对整体性能几乎没有影响。”
比较参数为:
- 开源–该工具是开源的吗?(是)还是封闭源?(不)
- 不可知的体系结构–可以将两个样本进行比较,而不必考虑它们最初被编译为何种体系结构?
- 支持大型二进制文件-是否支持大型二进制文件?
- 辅助源代码–它是否利用源代码中的信息来提高匹配率?
- 标识版本–是否标识比较样本的版本?它是在匹配之前还是之后执行此操作?
这是我们的结果表:
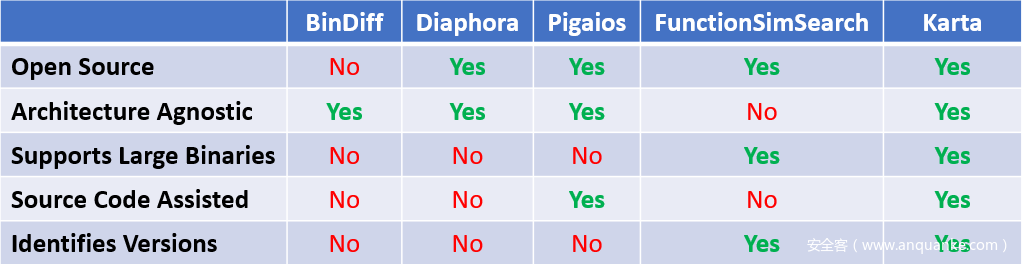
图16:我们的匹配工具与流行的差异/匹配工具之间的比较
注意:虽然BinDiff和Diaphora可用于比较两个二进制文件(bin-diff),例如,用于色块差分,但Karta的开发目标是匹配已知开放源代码的二进制符号。虽然这限制了可使用Karta的用例,但其目标明确的目标使其能够使用更简单的比较启发式方法来提高匹配率。
由于没有(已知的)解决所有二进制匹配/差异问题的解决办法,因此我们认为,根据最初设计的目标判断每种工具非常重要。
附录:当前支持的库列表
- 1.libpng
- 2.zlib
- 3.OpenSSL
- 4.OpenSSH
- 5.net-snmp
- 6.gSOAP
- 7.libxml2
- 8.libtiff
- 9.mDNSResponder
- 10.MAC-Telnet
- 11.libjpeg-turbo
- 12.libjpeg
- 13.icu
- 14.libvpx
- 15.treck – 闭源项目






发表评论
您还未登录,请先登录。
登录