
尽管基于深度学习的语音系统非常受欢迎,但它们容易受到对抗性攻击,其中恶意制作的音频会触发目标系统的异常行为。在本文中介绍了SirenAttack,这是一种新的攻击类型,可以产生对抗性音频。与现有攻击相比,SirenAttack具有以下重要特征:(i)多用途:在白盒和黑盒设置下,它都能欺骗一系列端到端的语音系统; (ii)有效性:它能够产生对抗性音频,这些音频可以被目标语音系统识别为特定短语; (iii)隐蔽性:它能够产生与人类感知的良性对立音频难以区分的对抗性音频。本研究对一套基于深度学习的先进语音系统(包括语音命令识别,说话者识别和语音事件分类)进行经验评估,结果显示了SirenAttack的多功能性,有效性和隐蔽性。例如,针对ResNet18模型,它在IEMOCAP数据集上实现了99.45%的攻击成功率,而生成的对抗性音频也被多种流行的ASR平台误解,包括Google Cloud Speech,Microsoft Bing Voice和IBM Speech-to-Text。本研究进一步评估了三种缓解这种攻击的潜在防御方法。
0x01 Introduction
如今,以机器学习为基础的语音系统在日常生活中无处不在,从手机上的智能锁到智能家居设备上的语音助手,再到云上的机器翻译服务。通常根据应用场景,语音系统可以分为两种类型:面向分类的系统和面向识别的系统。面向分类的语音系统通常首先将音频从时域转换到频域,然后对相应的声谱图进行分类。例如,通常集成到声音监控系统中的语音事件分类系统可以识别诸如玻璃破碎之类的物理事件。与面向分类的语音系统相比,面向识别的语音系统通常更为复杂,因为它需要首先将音频分割成帧,对每个帧进行预测,然后基于Connectionist-Temporal-Classication(CTC)损失或注意力导出识别结果。最典型的示例是自动语音识别(ASR)系统,该系统已广泛集成到各种流行的语音助手(例如Siri,Google Now)中。
由于其卓越的性能,当今的大多数语音系统都是基于深度神经网络模型构建的。但是,此类模型天生就容易受到对抗性输入的攻击,这些输入是恶意制作的样本(通常通过向合法样本中添加人类无法察觉的噪声)来触发目标模型的行为异常。语音系统需要处理时间维度上的信息变化,这比图像分类系统要复杂得多。其次,音频采样率通常很高(例如16kHz,这意味着每秒采样16,000个点),但是图像总共只有数百/数千个像素(例如,最流行的数据集中图像的大小,即,MNIST和CIFAR-10,分别为28×28和32×32)。因此,与图像相比,制作对抗性音频更加困难,因为向音频添加少量噪声不太可能影响局部特征。
最近业界提出了几种机制来产生对抗性音,它们都是基于梯度信息的,因此共享彼此之间有很小的差异。尽管这些针对语音系统的工作是开创性的,但由于至少以下原因之一,它们在实践中受到限制:(i)它们仅针对白盒设置下的特定语音模型进行设计; (ii)他们只能进行非针对性的攻击,目的只是简单地使目标系统行为不当; (iii)他们只能产生针对语音上相似的词组的对抗性音频。此外,它们都没有在端到端设置中得到全面评估。
0x02 Background
A.面向识别的语音系统
语音识别是最流行的语音系统之一。传统的语音识别系统由语音模型,字典和语言模型组成。语音模型和语言模型分别进行训练。该方法的缺点在于,它不一定会提高整体识别性能。近来,端到端语音识别变得越来越流行,因为当给定足够的标记训练数据时,端到端语音识别具有出色的性能。因此,本文专注于攻击端到端的语音识别系统,而不是传统的系统。
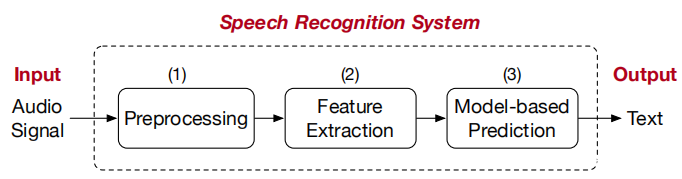
端到端语音识别模型可以将原始音频直接映射到输出单词,如上图所示。它包括以下三个步骤:(1)预处理,该步骤消除了信号能量低于特定阈值的时间段。此步骤中使用的最流行的技术之一是语音活动检测(VAD),通常包括降噪阶段,块特征计算阶段和分类阶段。 (2)特征提取,此步骤将预处理的音频拆分为短帧,并从每个帧中提取特征。语音识别系统中最常用的特征提取方法是MFCC 。从高层次上讲,提取MFCC特征需要通过离散傅立叶变换将音频转换到频域,应用梅尔滤波器组,然后执行傅立叶逆变换将信号转换回时域。 (3)基于模型的预测,此步骤将提取的特征作为输入,并将其与现有模型进行匹配以生成预测结果。现代系统通常使用具有CTC损失函数的递归神经网络(RNN),该函数仅需要一个输入序列和一个输出序列。
B.面向分类的音箱系统
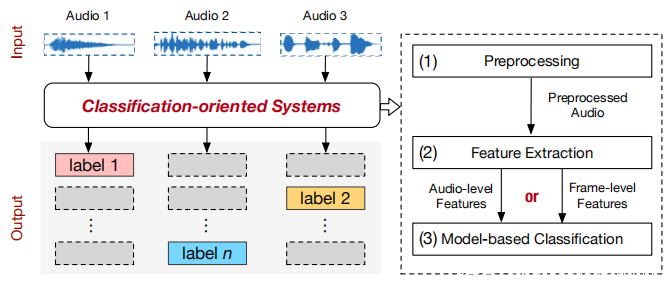
通常,面向分类的语音系统的目的是将音频片段中的采样点分类为给定类之一。如下图所示,面向分类的语音系统包括以下三个步骤:(1)预处理。此步骤与面向识别的系统中的步骤相同。 (2)特征提取。此步骤可以提取两种特征。一个是音频级别的特征,另一个是帧级别的特征。从整个音频波形中提取音频级特征,而从分段的波形帧中提取帧级特征。这两种方法都使用卷积神经网络(CNN)来提取特征。 (3)基于模型的分类。此步骤将提取的特征作为输入,并将其与在线构建的现有模型进行匹配以生成分类结果。此步骤中使用的技术可以有很大的不同。然而,由于其在计算机视觉领域的出色表现,现代系统通常会使用CNN。
0x03 Attack Design
A.问题表述
给定一个从特征空间X到一组预测结果Y的预先训练的分类/识别模型f:X-> Y,一个攻击者的目标是从合法的音频x∈X产生一个具有其地面真实性标签y的对抗性音频xadv ∈Y,因此xadv≈x,即人类很难区分xadv和x,而分类器预测f(xadv)= t,其中t是目标短语或类,t≠y。
B.威胁模型
在白盒设置下,假定攻击者完全了解所有详细信息,包括有关受害模型的模型体系结构和模型参数,并且可以在进行攻击时与其进行交互。这是大多数先前工作中采用的常见威胁模型,该模型假设攻击者拥有最大的权力。
在黑盒设置下,假定攻击者对受害者模型的体系结构,参数或训练数据一无所知。因此,受害者模型的查询功能可以被描述为一个Oracle O(x),它返回候选类的置信度值。这种假设是可行的,因为许多机器学习即服务(MLaaS)平台通常不发布其详细的算法或训练数据,而是提供每个候选类的置信度值。
C.准备
粒子群优化(PSO):PSO是一种启发式和随机算法,通过模仿一群鸟类的行为来寻找优化问题的解决方案。它可以在不需要梯度信息的情况下搜索非常大的候选解空间。在较高的层次上,它通过迭代使一组候选解(称为粒子)根据其适合度值在搜索空间中移动来解决问题。粒子的适应度值是目标函数对该粒子在解空间中位置的评估结果。在每次迭代中,每个粒子的运动都会受到其局部最佳位置Pbest的影响,同时会被引导向搜索空间中的全局最佳位置Gbest。预计此迭代过程将使集群向最佳解决方案发展。满足终止标准后,Gbest应该将解决方案保留在全球最低水平。
Fooling梯度法:Fooling梯度法是对抗性图像生成研究中引用的一种简单方法。在这种方法中,相对于输入数据而不是模型参数计算梯度。然后,将相同的梯度下降技术应用于迭代修改输入数据。简而言之,用于训练NN的标准设置与Fooling梯度方法之间的关键区别在于(1)仅将梯度应用于输入数据,并且(2)在网络的预测与模型之间计算损失目标标签,而不是地面真相标签。
D.攻击设计
逻辑上,面向分类的任务可以视为面向识别任务的一帧实例。因此,从白盒和黑盒设置的角度介绍SirenAttack,而不是从应用程序场景入手。
(1)白盒攻击
在较高级别上,白盒攻击包含两个阶段。第一阶段的目标是找到接近精确的对抗噪声δ的粗粒度噪声δ’,而第二阶段的目标是通过稍微修改δ’来找到精确的对抗噪声δ。设计这种程序时要考虑有效性和效率。算法1中显示了详细的白盒攻击。第一阶段包含第2-13行中的步骤,第二阶段包含第15-19行中的步骤。

首先,将epoch初始化为零,并根据均匀分布(第1行)生成n_particle个随机序列。随机序列统称为已评估。然后,使用目标输出t和种子运行PSO子例程(第3行)。如果有任何粒子pi在添加到原始音频x时产生目标输出t,则攻击成功(第4-5行),粒子pi是预期的噪声δ。否则,将保留当前PSO运行中适应性值最小的最佳粒子,作为下一次PSO运行(第7-8行)的种子之一。从n_step epoch开始,从最近的n_step PSO运行(第10-12行)计算出全局最佳适应性值的标准偏差std。一旦std低于阈值ϵ,连续运行PSO子例程来找到确切的噪声δ就没有效率,因为全局最佳适应性值现在变化缓慢。因此,仅在第一阶段之后获得粗粒度噪声δ’。
将一步强调算法的两个关键方面:(1)修改了PSO算法,以在所有PSO迭代中全局跟踪当前保存的最佳粒子,而不是使用标准PSO算法。(2)在每次迭代期间,PSO的目标是使定义为g(x + pi)的目标函数最小化。请注意,类似RNN的模型的输出是一个矩阵,其中包含每帧字符的概率。因此,在这种攻击中,选择CTC损失函数作为g(·),即g(x + pi)= CTC-loss(x + pi)。然后,将每个粒子处的g(x + pi)值沿新方向移动。
在第二阶段中计算损失函数,并使用欺骗梯度方法调整δ0,直到O(x +δ’)= t或epoch达到epochmax为止。损失函数定义如下:
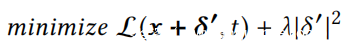
其中L是CTC损失而λ|δ’|^2是正则项。可以将该损失函数修改为L(x +δ’)以进行非目标攻击。
(2)黑盒攻击
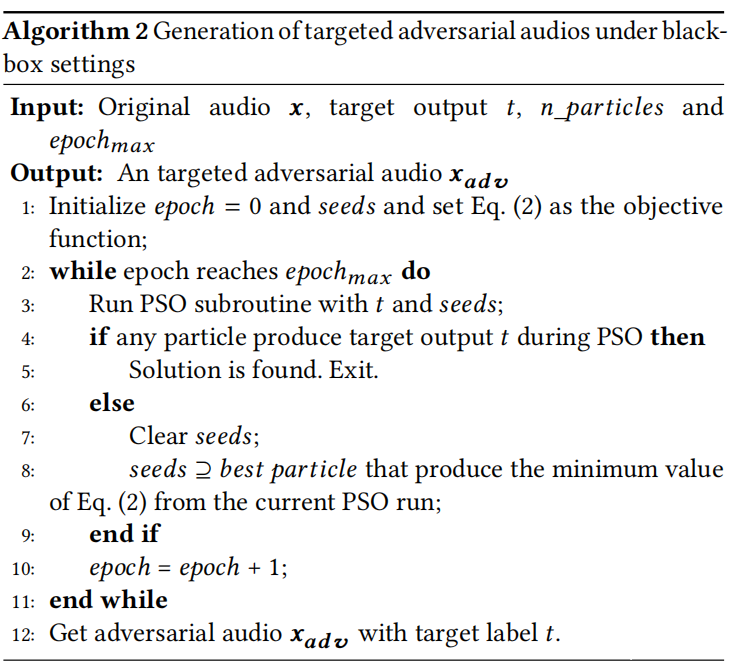
详细的黑盒攻击如算法2所示。为了欺骗机器学习模型,向其提供了合法的音频x和目标输出t。还将粒子数预定义为n_particles,最大epoch数定义为epochmax。黑盒攻击的基本过程(第2-11行)与白盒攻击的第一阶段相似,除了以下两点:(i)由于缺少丢失信息,目标函数有所不同;并且(ii)终止条件不同,因为在此过程中应获得确切的噪声δ。对g(·)的几种定义进行了实验,发现以下是最有效的:
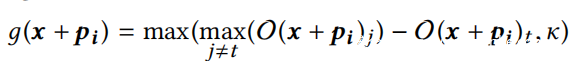
其中O(x + pi)j是输入x + pi的标签j的置信度值。函数可以将粒子移动到最大化目标标签t概率的位置。此外,可以使用数κ来控制错误预测的置信度,并且κ较小意味着所发现的对抗性音频将以较高的置信度被预测为t。为SirenAttack设置κ= 0,但是注意到,这种公式的一个附带好处是,它允许人们控制所需的置信度。算法在此过程(第2-11行)上迭代,直到攻击成功或达到epochmax为止。如果成功,将获得一个可以被受害者模型预测为t的对抗性音频xadv。此外,可以使用此函数进行微不足道的修改来进行非目标攻击。
与白盒攻击相比,黑盒攻击效率较低,并且在生成的对抗性音频中引入了更多噪声。这是因为黑盒攻击缺乏损失信息和梯度信息。因此,黑盒攻击的一些性能下降是合理的。
0x04 White-box Attack Evalution
A.数据集
在本实验中,将来自Common Voice数据集和VCTK Corpus的音频作为原始样本。Common Voice数据集是用户根据大量公共领域来源(例如,用户提交的博客文章,电影和其他公共语音语料库)中的文本读取的语音数据的语料库。它具有500个小时的采样,其中包括20,000人录制的40万记录。 VCTK语料库包含来自109位以英语为母语的说话者的语音数据,并带有不同的口音。
B.目标模型
在这组评估中,研究了DeepSpeech的安全性,这是百度提出的基于RNN的最新ASR模型,该模型在包含100,000小时的嘈杂语音数据的数据集上进行了训练,并且可以实现在嘈杂的环境(例如餐厅)中,准确度约为81%。由于以下原因,选择DeepSpeech作为目标模型:(i)由于缺乏足够的实现细节,因此难以在这些论文中重现结果,并且( ii)一些可用的语音转文本引擎(例如WaveNet)的输入数据格式是MFC特征,而不是原始音频波形,因此需要从MFCC逆过程中重建对抗性音频,这将大大降低音频的质量。音频。另一方面,由Mozilla组织实施的DeepSpeech模型是评估SirenAttack的正确选择,该模型在Github存储库中拥有6000颗以上的star。它的输入数据格式是原始音频波形。尽管这是一个研究项目,但DeepSpeech的开发人员声称,百度将在未来将DeepSpeech集成到自动汽车,CoolBox和可穿戴设备中。因此,与其他模型相比,它更加实用。
C.评估指标
有两种客观的音频质量评估技术,即信噪比(SNR)和客观差异等级(ODG)。由于以前的工作通常使用SNR来评估所产生的对抗性音频的质量,因此也使用SNR来评估音频质量以与先前的作品保持一致并进行比较。SNR是一种广泛用于量化信号功率水平的指标噪声功率,其计算方法如下:
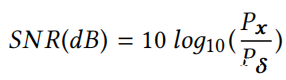
其中x是原始音频波形,δ是相加的噪声,Px和Pδ分别是原始信号和噪声信号的功率。较大的SNR值表示较小的噪声等级。为了本研究目的,使用它来测量对抗性音频相对于原始音频的失真。
根据IFPI的规定,不可察觉的噪声要求噪声信号与原始信号之间的SNR值至少为20dB。但是,这对于SirenAttack是不必要的。只要不影响人类感知,SirenAttack就可以忍受一定程度的噪音。因此,生成的对抗性音频的SNR是可接受的,即使它们未达到阈值20dB。
在具有两个运行频率为2.40GHz的Intel Xeon E5- 2640 v4 CPU,64 GB内存,4TB HDD和GeForce GTX 1080 Ti GPU卡的服务器上进行了实验。在所有实验中,将epochmax = 300,n_step = 5,ϵ = 2以及PSO的迭代极限设置为30。对于PSO子例程,设置n_particles = 25,c1 = c2 = 1.4961。特别地,r1和r2是从[0,1]均匀采样的随机值,以避免一致性。另外,对惯性权重w采用了自适应方法,即最初设定w = 0.9,这使得PSO具有很强的全局优化能力。随着迭代次数的增加,w减小,使得PSO具有很强的局部优化能力。当迭代结束时,w = 0.1。对于基于梯度的阶段,对超参数(例如学习率)进行了一些搜索,以找到有效性和效率之间的权衡。特别是将学习率设置为1。
D.结果与分析

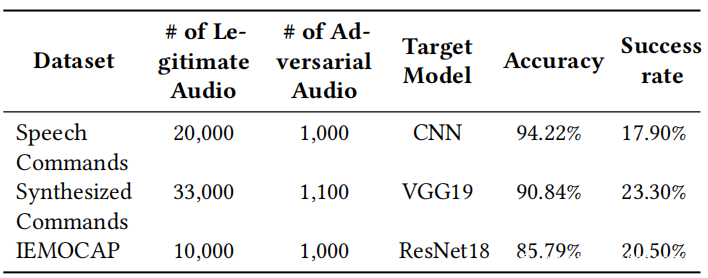
有效性和效率:主要实验结果显示在上表中,该表总结了SirenAttack在两个数据集上的性能。从Common Voice数据集和VCTK语料库中随机选择了200个实例作为原始音频。从所有Google即时语音命令列表中随机选择目标命令。评估生成对抗性音频的平均时间,因为对于攻击者而言,在实际环境中发动攻击非常重要。从上表中,可以看到SirenAttack非常有效。在Common Voice数据集和VCTK语料库上分别生成成功的对抗性音频(成功率100%)所需的平均时间不到1600秒和1900秒。因此,攻击者可能会在短时间内创建大量对抗性音频。此外,对抗性音频的失真很小,如上表所示。例如,Common Voice数据集上生成的对抗性音频的平均SNR为18.72 dB,这意味着与原始音频相比,失真度不到2%。
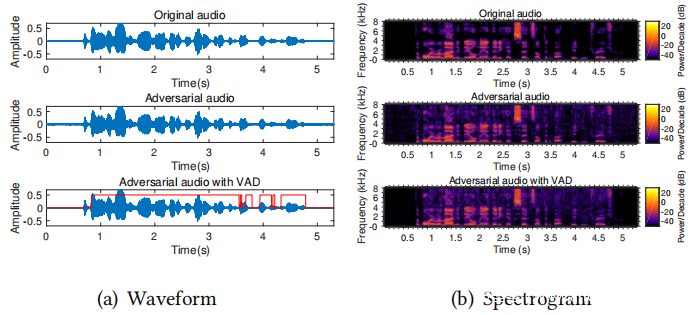
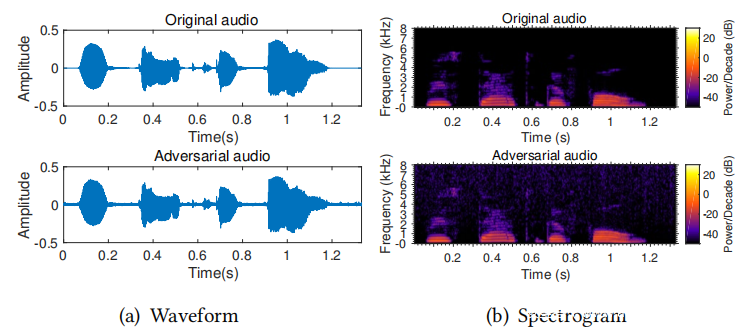
为了失真可视化,在上图中绘制了示例原始音频和相应的对抗性音频的波形和频谱图。图(b)中的原始音频和相应的对抗性音频的频谱图是获得的波形短时傅立叶变换(STFT),其中水平轴表示时间,垂直轴表示频率,颜色表示能量强度。实际上,在声音进入人耳后,耳蜗也会处理类似于STFT的声音。因此,人们可以分辨的声音通常会在声谱图上显示特定的模式。从图(b)中可以看到,尽管噪声涵盖了很广的频谱,但其能量却远低于人声部分。因此,对抗性音频中的噪声对于人类来说是可忽略的,并且这种攻击是非常隐蔽的。
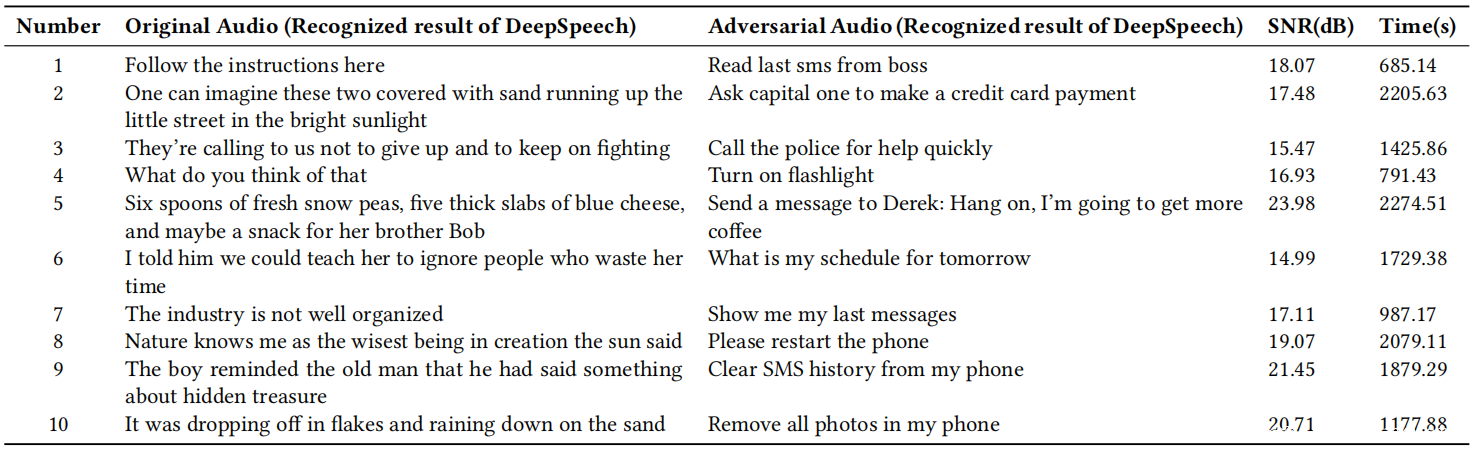
示例:上表显示了五个示例,其中对抗性音频的预测结果已完全更改。例如,将“follow the instructions here”转换为“read last sms from boss”的情况可用于通过用户的语音助手窃取用户的隐私信息。因此,攻击者可以利用这种攻击对语音识别系统进行恶意攻击。此外,观察到话语的长度与生成对抗性音频所需的时间之间呈正相关,这意味着生成较长的对抗性音频可能会在一定程度上导致缩放问题。
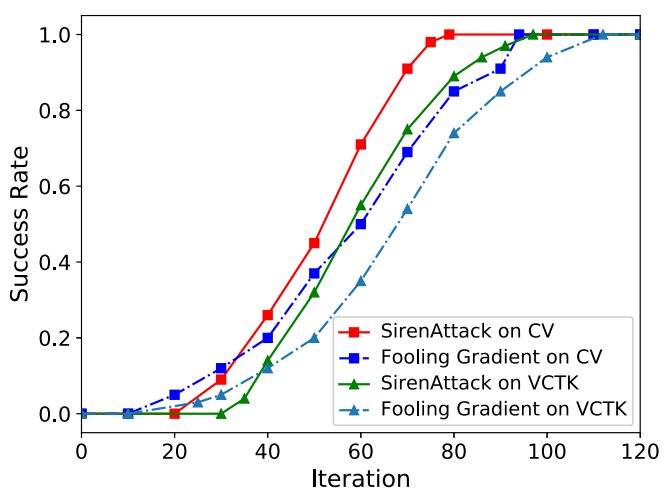
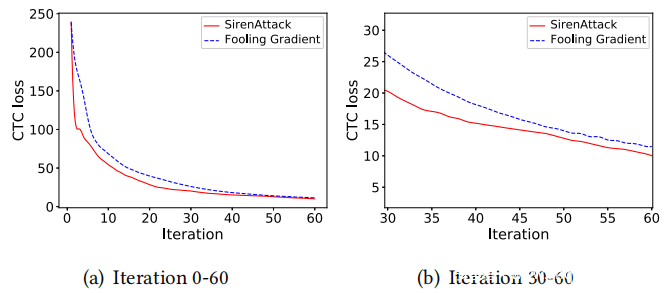
性能比较:通过在上图中显示迭代与成功率之间的相关性,将SirenAttack与fooling梯度法进行了比较。观察到公共语音数据集上的SirenAttack在迭代79时达到了100%的成功率,而fooling梯度方法达到了100迭代94的%成功率。这表明SirenAttack更有效率。尽管fooling梯度法比SirenAttack更快地找到第一个对抗性音频,但其成功率增加得较慢。具体来说,以“the boy reminded the old man that he had said something about hidden treasure”转换为“clear SMS history from my phone”为例,显示了fooling梯度法(蓝色虚线)和SirenAttack的CTC损失(红色实线)。在下图中可以看到,SirenAttack中的CTC损失下降速度比fooling梯度法中的下降快。这意味着SirenAttack选择的方向可以比fooling方法更快地找到对抗性音频。
改善攻击:为了进一步提高SirenAttack的性能,使用了语音活动检测(VAD)工具包来查找音频的活动部分,并且仅向活动区域添加噪声,从中可以看到VAD确实增加了所生成的对抗性音频的SNR,并提高了生成过程的效率。例如,使用VAD时,Common Voice数据集上的对抗性音频的平均SNR为20.01 dB(不带VAD时为18.72 dB),平均生成时间为1201.66秒(不带VAD时为1560.14秒)。此外,比较了带有和不带有VAD的示例对抗音频的波形和频谱图,从中可以看到无效语音部分几乎占据了原始音频的三分之一。因此,将噪声添加到音频的活动部分确实会增加对抗性音频的SNR,即生成更好的对抗性音频。
0x05 Black-box Attack Evalution
A.目标应用
在三个不同的场景下进行了黑盒攻击,包括语音命令识别,说话者识别和语音事件分类。
(1)语音命令识别

在这种情况下,生成了可以被识别为语音命令识别系统目标短语的对抗命令。例如,可以从一个声音说“yes”开始,系统可以正确识别该声音。发起攻击后,系统将输入识别为“no”,而人类仍然清楚地听到“yes”。
首先,简要介绍在这套评估中使用的数据集和受害者模型。所使用的数据集简要描述如下:(i)语音命令数据集。该数据集包含65,000个包含30个简短单词的音频文件。每个文件都是一个单词的一秒钟音频,例如:“yes”,“no”,数字和方向。 (ii)综合命令。如上表所示,通过几个著名的Text-to-Speech引擎(包括百度,Google,Bing和IBM)合成了11个长语音命令的33,000个音频文件,每个标签以不同的速度和音调合成了3,000个剪辑。这11个命令是日常生活中常用的命令,例如“okay Google”和“turn on the airplane mode”。选择它们代表对个人语音助手的各种潜在攻击。
目标受害者模型如下:(i)CNN模型由TensorFlow团队进行了预训练,在语音命令数据集上实现了96.10%的分类精度。 (ii)六个最先进的语音命令识别模型。使用VGG19,DenseNet,ResNet18,ResNeXt,WideResNet18和DPN-92作为目标受害者模型。这些模型以对图像数据的良好分类性能而闻名。此外,它们在TensorFlow语音识别挑战赛中表现出色。因此,修改它们以适应频谱图输入。
(2)说话者识别
说话者识别是根据声音特征对人的识别,可将其用于验证说话者的身份,这是安全过程的一部分。通过将说话者识别任务限制在十类分类问题中来简化说话者识别任务,这是合理且普遍的。它使模型性能更好。另外,从评估的角度来看,攻击具有良好性能的模型更有意义。然后,针对语音命令识别任务中使用的相同类型的模型。此外,使用IEMOCAP数据集进行对抗性攻击,该数据集由十个说话者(五名女性,五名男性)组成,并且是语音副语言研究中常用的数据集。
(3)语音事件分类
语音事件分类的目的是为音频信号中的语音事件(例如“dogbark”,“siren”)提供预定的标签。它具有许多应用,包括音频监控系统,助听器,智能房间监控和内容检测。在这种情况下,目标是欺骗语音事件分类系统以产生错误的目标预测。例如,可能从正确识别为“gunshot”的音频开始,这是一种危险事件,可能引起监控器的注意。但是,系统会将相应的对抗性音频分类为正常事件(例如“dogbark”),而人类仍然可以听到“gunshot”。
使用三个大型语音事件数据集来评估SirenAttack:(i)AudioSet具有632个语音事件类,涵盖了广泛的日常环境声音。(ii)ESC-50包含2,000个5秒长的环境音频录音,分为50个类,每个类有40个音频。 (iii)UrbanSound8K包含来自十个类别的8,732个带标签的声音片段(每个片段不超过四秒钟)。对于受害模型,根据AudioSet的说明,使用YouTube-8M入门代码来训练三种受害模型,包括逻辑模型(LM),专家混合(MoE)模型和帧级逻辑模型(FLLM)。
B.实施
黑盒攻击的实现细节与白盒攻击的实现细节几乎相同。区别之一是由于缺乏预先训练的模型,需要训练一些目标模型。因此,除了CNN模型外,所有模型都采用保持测试策略进行训练,即分别将80%,10%,10%的数据用于训练,验证和测试。超参数仅在验证集上进行了调整。
C.评估结果
从语音命令数据集中选择了2,000个音频片段,每个标签200个片段,并为每个音频文件生成了9个目标对抗性音频。例如,对于音频“no”,生成了旨在被标识为“yes”,“left”等的对抗性音频。如果SirenAttack在epochmax迭代中未能找到对抗性音频,则将其声明为失败,反之亦然。同样,评估了所需的时间和SNR。请注意,CNN模型已在语音命令数据集上进行了预训练。因此,没有在Synthesized Commands数据集上对其进行评估。
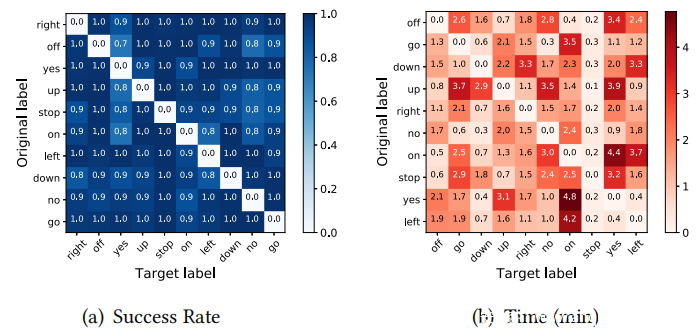
攻击结果中δ= 800和epochmax = 300,包括模型在原始数据集上的准确性,SirenAttack的成功率,生成的对抗性音频的SNR和生成对抗性音频的平均时间。上图(a)和(b)显示了对对成功率和在语音命令数据集上生成SirenAttack对抗性音频的平均时间。下图示出了示例原始音频和对应的对抗音频的波形和频谱图。可以从上图观察到以下内容。
•从前图(a)中,可以看出,SirenAttack在针对所有目标模型的情况下均有效,即使模型在合法数据集上具有较高的性能。例如,SirenAttack相对于CNN模型,在语音命令数据集上具有95.25%的成功率,而相对于VGG19模型,在Synthesized Commands数据集上具有93.75%的成功率。此外,注意到某些转换似乎比其他转换容易。例如,从“yes”到“stop”的转换可以完成10次迭代,而从“stop”到“yes”的转换则需要160次迭代。推测这可能是由于受害者模型在不同类别之间的不同预测稳健性造成的。另一个有趣的观察结果是,在攻击过程中出现了一些中间对抗性音频。例如,当将“restart the phone”转换为“flashlight on”时,转录结果首先变为“clear notification”,然后变为“flashlight on”。

•从上表中可以看出,对抗性音频的平均生成时间非常短。例如,与CNN模型相对时,语音命令数据集的对抗性音频的平均生成时间为100.69秒。另外,从图(b)中可以看到,所有对抗性音频都可以在不到5分钟的时间内生成,并且某些{source,target}对(例如{go,stop})可以在一分钟之内完成。因此,SirenAttack在实践中非常有效。
•从前表中还可以看到噪声很小,例如,与目标模型相对时,两个数据集中的对抗性音频的SNR范围从14 dB到22 dB。这意味着对抗性音频中的噪声小于3%。此外,在上图中显示了示例音频及其对应的对抗音频的波形和频谱图,从中还可以看到噪声几乎可以忽略。这表明了SirenAttack的隐蔽性。
攻击说话者识别系统:在此评估中,使用了IEMOCAP数据集中的1,000个音频剪辑,每个扬声器100个剪辑,并为每个音频文件生成了9个目标对抗性音频。攻击结果显示在上表中,其中δ= 800和epochmax = 300。进一步显示了SirenAttack的配对成功率以及生成对抗性音频的平均时间。与对语音命令识别系统的攻击类似,SirenAttack对所有目标模型也非常有效,如表所示。例如,相对于ResNet18模型,SirenAttack的成功率为99.45%。另外,SirenAttack在此任务中也很有效,例如,IEMOCAP数据集相对于VGG19模型的对抗性音频的平均生成时间为376.40秒。
攻击语音事件分类系统: 在此评估中,训练了LM模型和MoE模型的音频级别特征,另外在帧级特征上训练了FLLM模型,这些特征是由VGGish模型提取的。对于ESC-50和UrbanSound8K数据集,受害者模型分别在自己的数据集上训练;对于AudioSet,将UrbanSound8K上的预训练模型作为受害者模型。为了证明SirenAttack可以将威胁事件转换为正常事件,从三个数据集中随机选择了150个与{威胁事件,正常事件}模式匹配的{source,target}对,以评估SirenAttack。

结果显示在上表中,从中可以看到SirenAttack对目标模型也有效。例如,相对于LM模型,SirenAttack在AudioSet数据集上的成功率为92.67%,平均生成时间为283.57秒。下表展示了SirenAttack将威胁事件转换为正常事件的一些示例,例如,SirenAttack可以将威胁事件“gunshot”转换为正常事件“dogbark”,可用作对声音监控系统的攻击。

0x06 Further Analysis
A.扰动分析
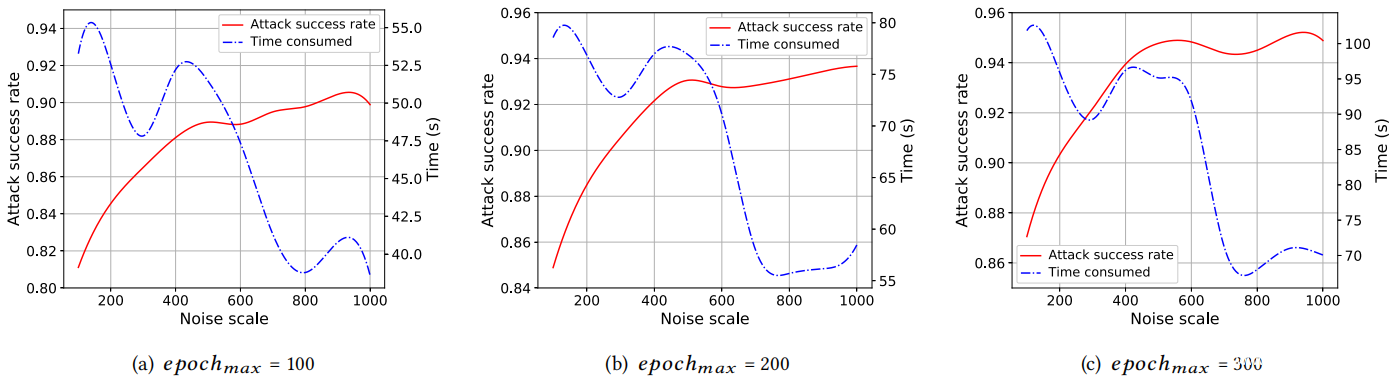
现在,评估噪声标度δ和epochmax对生成对抗性音频的有效性和效率的影响。具体来说,在语音命令数据集上生成了具有不同噪声限制值以及epochmax = 100、200、300的对抗性音频。目标模型是CNN。成功率和所需时间如上图所示,从中可以看到成功率的趋势通常与噪声等级一致。例如,当epochmax =100时,SirenAttack在δ=100时具有82%的成功率,而在δ=1000时具有90%的成功率。这意味着攻击者可以使用更大的噪声等级来提高其攻击的成功率。另一方面,较大的δ也意味着较低的效用,即,人可能注意到音频的变化。从上图中,还可以看到,当δ= 800时,所有三个时间曲线均达到最小值。此外,当epochmax = 300时,总体成功率高于epochmax = 100、200。这些发现有助于推导出更好的参数设置。因此,在评估中使用δ= 800,最大epoch= 300。
B.可传递性评估
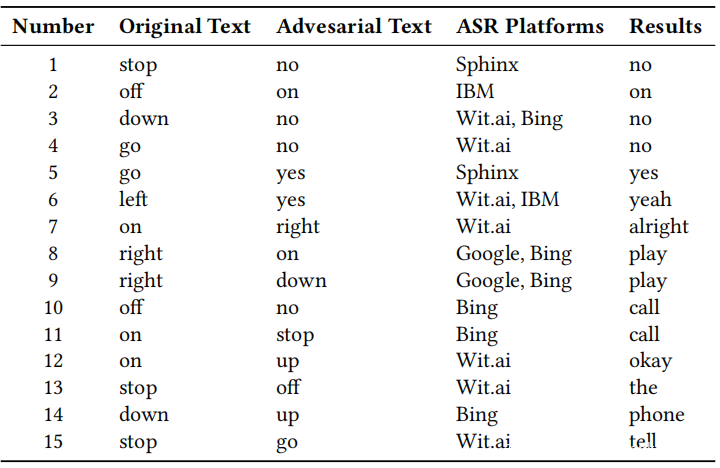
先前的研究表明,即使一个模型生成的对抗图像具有不同的体系结构,也可能被其他模型错误分类,即对抗图像具有可传递性,可用于进行黑盒攻击。因此,感兴趣的是(i)对抗性音频中是否还存在可传递性,以及(ii)此属性是否可用于进行黑盒攻击。具体来说,使用目标模型为VGG19的语音命令数据集生成的500种对抗性音频,对几种著名的ASR平台进行了概念验证攻击,其中包括Sphinx,Google Cloud语音识别,Microsoft Bing语音识别,Houndify,Wit.ai和IBM语音转文字。请注意,不会直接在这些ASR平台上进行黑盒攻击,因为它们都是面向识别的模型,除了最终转录外,它们不会提供任何信息。在这种情况下,如果可能的话,很难对这些模型直接进行黑盒攻击,同时还要保证增加的噪声是人类无法察觉的。

评估结果如上表所示,从中可以看到,SirenAttack生成的对抗性音频在某种程度上也可能被目标ASR平台误解为目标文本。例如,SirenAttack在Sphinx平台上获得了39.60%的成功率。这意味着,SirenAttack生成的对抗性音频可用于将针对性的黑盒攻击安装到其他ASR平台上。表中的1-7行显示了一些已成功转移到其他ASR平台的示例。此外,下表中的第8-15行还显示了一些其他误分类结果,这意味着SirenAttack生成的对抗性音频与“ call 911”,“ okay Google”, “restart the phone”,然后“tell me the phone number of Jack”。
C.感知研究
为了量化SirenAttack生成的对抗性音频在感知上的真实感,还在Amazon Mechanical Turk(MTurk)上与人类参与者进行了一项用户研究。在研究之前咨询了IRB办公室,该研究已获批准,除必要的结果数据外,未收集任何其他参与者信息。
在这项研究中,招募了200位年龄在18至40岁之间的英语为母语的人参加调查。要求每个参与者在安静的环境中聆听从语音命令数据集生成的20个合法音频和20个对抗性音频,并以CNN作为目标模型。在每次试用期间,都将为参与者提供无限制的时间来重放音频并做出决定。对于每种音频,都需要回答一系列问题,即(1)他们从该音频中听到了什么(从给定的十个选项中选择一个选项,即stop, go, yes, no, left, right, off, on, up和down); (2)他们是否听到了比正常命令更异常的声音(这四个选项是no, not sure, a little noisy和noisy); (3)如果在(2)中选择一个有点嘈杂或嘈杂的选项,则他们认为噪声来自哪里(三个选项是 device(speaker, radio等),sample itself, other)。
在检查结果之后,发现可以正确识别93.50%的合法音频,而可以将92.00%的对抗性音频识别为原始标签。 没有任何对抗性音频被分类为其对抗性标签。 这表明生成的对抗性音频对人类的感知影响很小。 此外,有38.5%的参与者认为对抗性音频有些吵杂,只有4.5%的参与者认为噪音来自样本本身。 此外,有10.5%的参与者认为对抗性音频很吵,只有2.5%的参与者认为噪音来自样本本身。 这意味着SirenAttack是隐蔽的。
0x07 Potential Defenses
对抗训练:对抗性训练意味着用合法和对抗性例子来训练新模型。在上表中显示了该方案的性能以及详细的设置,其中的准确度表示新模型在合法音频上的预测准确度。从表中可以看出,对抗性音频的成功率降低了,而模型在合法样本上的表现并没有太大变化。但是,对抗训练的局限性在于它需要知道攻击策略的细节,并需要足够的对抗音频来进行训练。但是,实际上,攻击者通常不会公开其方法或对抗性音频。此外,他们可以频繁更改攻击的参数(例如,扰动因子)以逃避防御。因此,对抗训练仅限于防御未知的对抗攻击。
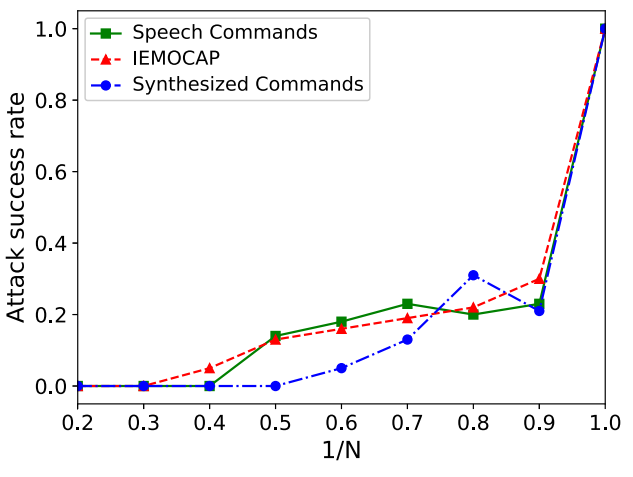
降低音频采样频率:第二种潜在的防御方法是降低输入音频x的采样率。将降采样的音频表示为D(x),并将其识别结果称为yD。当给语音系统提供带有标签yadv的对抗性音频xadv时,如果yD≠yadv,则xadv将被确定为成功防御。这种防御的结果如上图所示,其中x轴表示原始采样率是下采样率的N倍。从图可以看出,这种防御会降低SirenAttack的成功率。例如,当1/N = 0.8时,SirenAttack的成功率为20%。但是,根据奈奎斯特采样定理,当采样率低于原始音频最高频率的两倍时,此方法将导致失真。
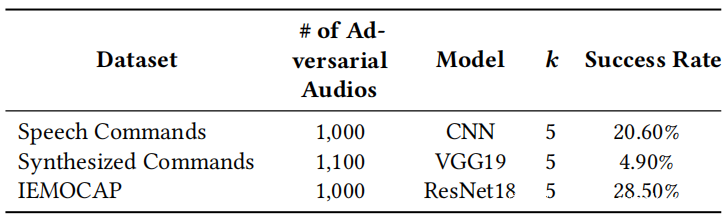
滑动平均滤波(MAF):现在,将固定长度的滑动窗口用于MAF,以减少对抗性噪声的影响。具体而言,对于一个采样点xi,将其前后的k−1个点视为局部参考点,并用xi参考点的平均值代替xi。结果显示在上表中,从中可以看到MAF可以降低SirenAttack的成功率。例如,当k = 5时,在语音命令数据集上,SirenAttack的成功率降低到20.60%。但是,MAF可能会降低音频质量,从而对模型的性能产生负面影响。
0x08 Discussion
普遍的对抗性扰动:在SirenAttack中,需要为每种音频找到特殊的对抗性噪声。在图像域中,可以构造单个扰动δ,当将其应用于各种图像时会导致分类错误。如果可能的话,这种攻击对音频也将具有难以置信的强大功能。
更多威胁性攻击:在评估中,假设攻击者可以将音频文件直接馈送到受害者模型。这是现实的,因为许多语音内容监控器可以直接检查原始音频。因此,SirenAttack确实会对网络环境造成威胁。但是,更强大的攻击场景是“over-the-air”,攻击者会根据合法音频x(t)实时计算并播放对抗性噪声信号δ(t),从而使叠加的音频x(t)+δ(t)将被解释为恶意命令。另外,SirenAttack可以与其他攻击结合起来形成更危险的攻击,例如,将SirenAttack与GVS-Attacks结合使用,以便恶意软件可以在发现机会时重放对抗性音频。
0x09 Conclusion
在本文中,研究了在白盒和黑盒环境中针对音箱系统的针对性对抗攻击。 这是首次针对各种语音系统生成对抗性音频的研究,包括语音识别,说话者识别和语音事件分类。 大量的实验结果表明,SirenAttack是有效且高效的,并且在许多实际应用中都具有潜在的威胁。







发表评论
您还未登录,请先登录。
登录