

前言
对于人工智能系统而言,对抗样本的存在是其面临最大的威胁之一,因为对抗样本仅需要针对模型生成特定扰动即可,而相比之下,数据投毒等攻击手段还需要攻击者可以控制训练集等,对攻击者的假设更强,在实际中对抗攻击是更容易出现的。本文试图对CV领域的对抗攻击技术做一个全面的介绍,首先会介绍重要的背景知识,包括距离度量、攻击者假设(攻击者知识、能力等)、对抗样本存在的本质原因以及对抗样本迁移性相关背景,之后会介绍一些典型的对抗攻击技术并给出实际攻击效果。

相关知识
距离度量
对抗样本x’与原样本x在特定的距离度量方式下需要很接近,常用的就是Lp范数度量,两者之间的距离表示为: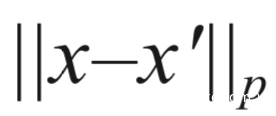
||||p定义为:
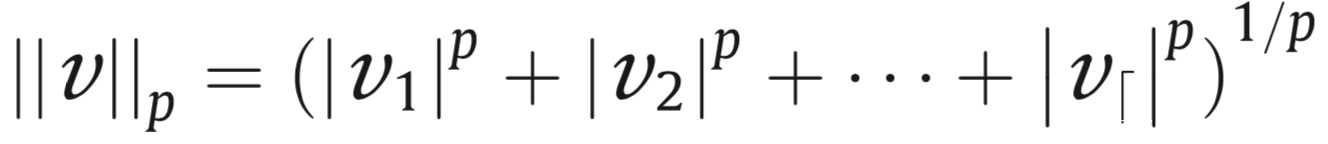
Lp范数不是一个范数,而是一组范数,根据p的不同,范数也不同,下图是一个讲点关于p范数的变化图
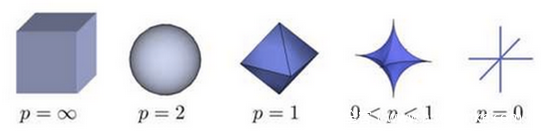
上图所示是p从无穷变化为0时,三维空间中到圆点的距离为1的点构成的图形的变化情况。
对于连续数据的测量,L0距离表示修改的原样本中的元素的数量,L2则是x‘和x之间的欧式距离,而L_infty是用的最多的,其测量的是x’和x之间的对应元素值最大的差异。而对于离散数据,可以用其他距离度量,比如删除点数、语义相似度等。
攻击者知识
为了发动对抗攻击,攻击者可能需要有以下知识:
全部或部分训练集
样本的特征表示
模型具体结构
模型输出
……
攻击者能力
这里注意区分攻击者能力和攻击者知识,攻击者知识是攻击者掌握的情况,攻击者能力则是攻击者在一定约束情况下可以采取的方案,包括但不限于如下:
修改输入样本
修改特征向量
……
本质
对抗样本之所以会存在目前主要有以下代表性的解释
这类解释认为对抗样本是从总体样本所在概率空间的某一子空间中抽样得到的,而模型在训练阶段因为训练样本有限,只学习了一些局部的子空间,对抗样本超出了模型能学习的概率分布所在支集。如下所示,对抗样本可能存在于某些低概率区域中。

这类解释认为高维空间的线性模型是生成对抗样本的原因。假设给定输入以及对抗样本,我们来考虑权重向量和对抗样本的內积:
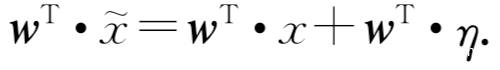
设激活函数为线性函数,对抗扰动导致激活函数增加了一部分,只要其中的扰动满足最大范数约束,就可以最大限度地增加对抗干扰,若权重向量的维数是n,则激活函数会相比于扰动之前增加emn,又由于扰动不会随着维数的增加而增加,但是却能引起激活函数值线性增加,换句话说,对于高维情况,输入的极小扰动会引起输入很大的改变。
此外,[20]认为数据流形的高维几何结构产生了对抗样本,[21]则发现记忆能力强的模型更容易受到对抗样本攻击,这些解释并不完全合理,限于篇幅,不再介绍,感兴趣的话可以自行查阅相关资料。
可迁移性
我们知道对抗样本具有可迁移性,事实上,可迁移性可以进一步细分为以下三类:
在同一数据集的不同子集下训练的不同模型之间存在可迁移性,如VGG和ResNet之间
对抗样本在执行不同任务的模型之间也存在可迁移性,如语义分割、图像分割、目标检测等任务之间
对抗样本在不同机器学习技术之间,比如SVM和DNN之间存在迁移性
对抗样本可迁移性的程度与以下因素有关:
[18]指出误分类率高的对抗样本其可迁移性反而较差
[19]指出神经网络、k近邻这类机器学习技术,其对抗样本在跨技术的模型中迁移性更强;而线性回归、支持向量机、决策树等方法,其生成的对抗样本在相同技术模型内的可迁移性更强
[17]指出执行非定向攻击得到的对抗样本其可迁移性比进行定向攻击得到的对抗样本更强
[16]指出在同一数据集上训练的不同模型间的可迁移性较强,因为这些模型学习的是相同的统计信息,所以会被同一对抗样本欺骗
评估
生成对抗样本的方案这么多,那么怎么对其进行评估呢?一般我们主要考虑以下方面
对抗样本的产生就是为了让模型对其误分类,所以评估误分类是首要的,这方面主要考虑两个指标,一个是误分类率,即能够成功欺骗模型的样本数占总样本数的比例,另一个是误分类置信度,其表示成本使模型误分类的对抗样本输入模型时,模型给出的置信度水平。
对抗样本在让模型误分类的同时还需要确保人类不会发觉,所以需要衡量其隐蔽性,一般使用Lp范数进行度量。
对抗样本在实际应用过程中可能会受到各种因素干扰,所以需要评估此时对抗样本的鲁棒性,一种常见的做法就是对其进行处理,如加噪声、压缩等,测试处理后的对抗样本是否仍能被模型误分类。
不同方案对攻击能力、知识等要求不同,在生成对抗样本的时间、资源要求上也不一样,这也是需要考虑的一方面。
攻击
根据攻击的目标可以分为定向攻击和非定向攻击,根据攻击频率可以分为单步攻击和迭代攻击,根据攻击攻击者的知识,将攻击分为白盒、灰盒、黑盒。
在黑盒模型中,攻击者仅能与模型进行交互,得到样本的预测结果,然后使用成对的数据集(样本,预测结果)等训练替代分类器,在替代分类器上进行对抗攻击,由于对抗样本的可迁移性,由此生成的对抗样本可以对目标模型实现攻击。对抗样本在不同模型间的迁移能力或者说泛化能力是对抗扰动与模型的
在灰盒模型中,攻击者除了可以与模型交互外,还知道模型的结构或者攻击者知识的部分,此时攻击者可以利用已知的结构信息构造更精确的替代分类器,然后进行攻击,显而易见,其攻击性能优于黑盒模型。
在白盒模型中,攻击者知道模型的全部信息,所以其攻击效果是最强的。
典型对抗攻击算法
L-BFGS
[1]首先发现某些人类难以察觉的扰动会引起模型对图片的错误分类,并提出一种称为L-BFGS的方法,通过最小化Lp范数找到这种扰动,公式为:
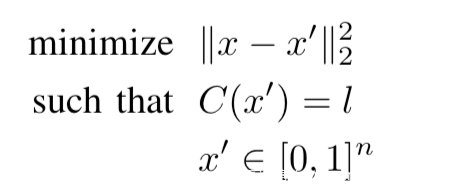
但是该问题不易求解,所以使用最小化混合损失,即用下式来替代求解
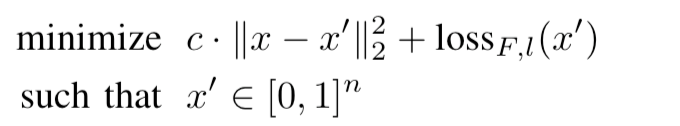
并通过线性搜索找到最优解
作者实验中给出的的生成的对抗样本如下

FGSM
[2]通过在原样本的L_infty范数限制下生产对抗样本,这是一种典型的一步攻击算法,通过沿着对抗损失函数的梯度方向(符号方向)执行一步更新,以增加最陡峭方向上的损失,其公式如下

这本身是一种非定向攻击,通过降低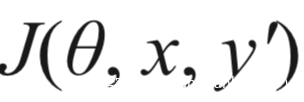
的梯度就可以实现定向攻击,此时的梯度更新可以表示为:
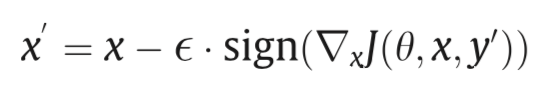
作者在论文中给出的就是最为人熟知的对抗样本了

后面介绍的*-FGSM都属于对FGSM的改进。
I-FGSM
[3]通过一个迭代优化器优化多次提高FGSM的性能,它以较小的步长执行FGSM,并将更新后的对抗样本裁减到有效范围内,通过这种方式迭代T次即可
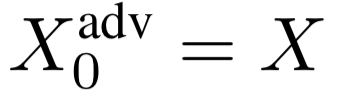
在第n次迭代得到的对抗样本如下:
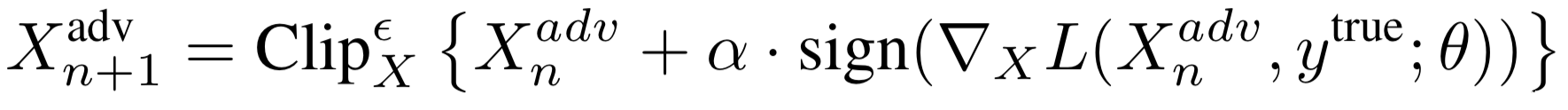
MI-FGSM
[4]将动量项添加到攻击的迭代过程中,这有利于加快收敛速度、使更新方向更加平稳,并在迭代期间能够从较差的局部最大值中逃脱,从而达到更好的攻击效果.以如下方式迭代更新对抗样本:
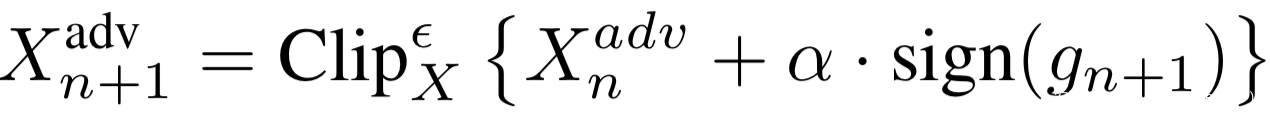
其中的梯度通过下式进行更新

DI-FGSM
[23]采用了多种输入模式来提高对抗样本的可传递性,名字中的D代表了随机的变换。其迭代方式类似于I-FGSM,其第n次迭代得到的对抗样本为:

上式中的T为随机转换函数,定义如下

此外,我们知道,动量和多样化的输入是缓解过拟合现象的两种完全不同的方式,所以可以将其结合起来,在这里可以用下式替换MI-FGSM中的梯度更新公式,就可以实现攻击

JSMA
[6]提出了基于雅克比的显著性图方法,利用雅克比矩阵,计算从输入到输出的显著图,因此只修改一小部分的输入特征就能达到改变输出结构的目的.
它利用较小的L0扰动生成对抗样本,首先在softmax层之前计算logit层输出的l(x)的雅克比矩阵:
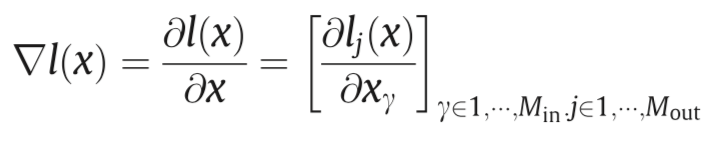
这可以表示输入x的各个分量如何影响不同类别的logit层输出。根据上式计算对抗性显著图S()以选择需要扰动的像素,从而在logit层的输出得到所需的变化
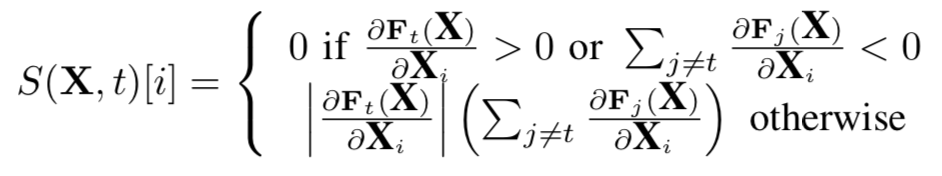
选择扰动具有最大S()的像素,从而增加目标类别的logit层输出或者减少其他类别的logit层输出,实现对抗攻击的目的。如下所示,是LeNet的784维输入的显著映射,784=28*28,仅需选择那些较大的绝对值进行扰动就可以实现对抗效果,因为较大的绝对值对应于对输入有较大影响的特征。
针对全黑的图,该算法生成的目标类别为0到9的对抗样本如下所示

C&W
[5]是一种基于优化的攻击方式,同时兼顾高攻击准确率和低对抗扰动的两个方面,达到真正意义上对抗样本的效果,即在模型分类出错的情况下,人眼不可查觉(相比之前FGSM等方法攻击生成的图片非常模糊,人眼可以察觉到)。它可以生成L0,L2,L_infty范数限制下的对抗样本CW0,CW2,CW_infty,其不使用如下所示,也就是之前流行的优化目标函数:
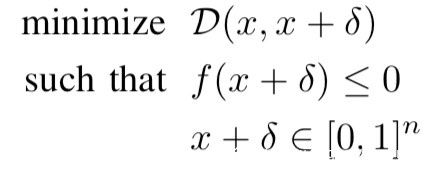
而是使用该优化目标函数作为替代:

式子中的D是距离度量,f是自定义的对抗损失,只有当模型的预测为攻击目标时才满足f<=0,另外上式中的扰动表示如下
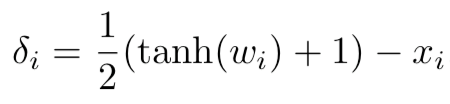
这是为了确保生成的对抗样本是有效的图像
对MNIST数据集应用L_infty范数,进行定向攻击,结果如下

PGD
[11]从鲁棒性优化的角度研究了神经网络的对抗鲁棒性,使用了一种natural saddle point (min-max) 公式来定义对对抗攻击的安全性。这个公式将攻击和防御放到了同一个理论框架中,使得我们对攻击和防御的性能有了良好的量化.作者对此鞍点公式相对应的优化场景进行了仔细的实验研究,提出了PGD这个一阶方法(利用局部一阶信息)来解决这个问题。鞍点问题如下所示
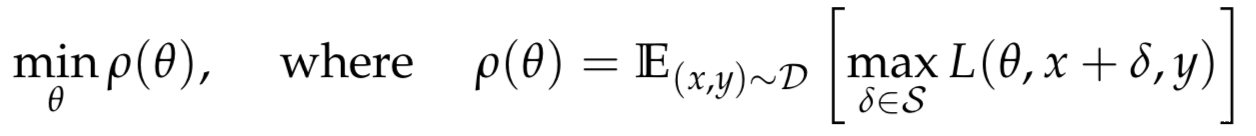
这个鞍点问题并不是那么容易解决。该问题涉及到出处理一个非凸的外部最小化问题和一个非凹的内部最大化问题。作者正是使用PGD解决最大化问题,其用下式生成对抗样本
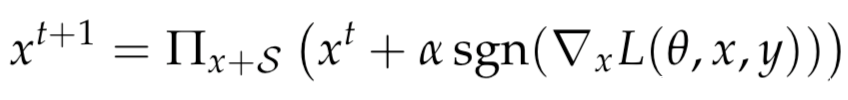
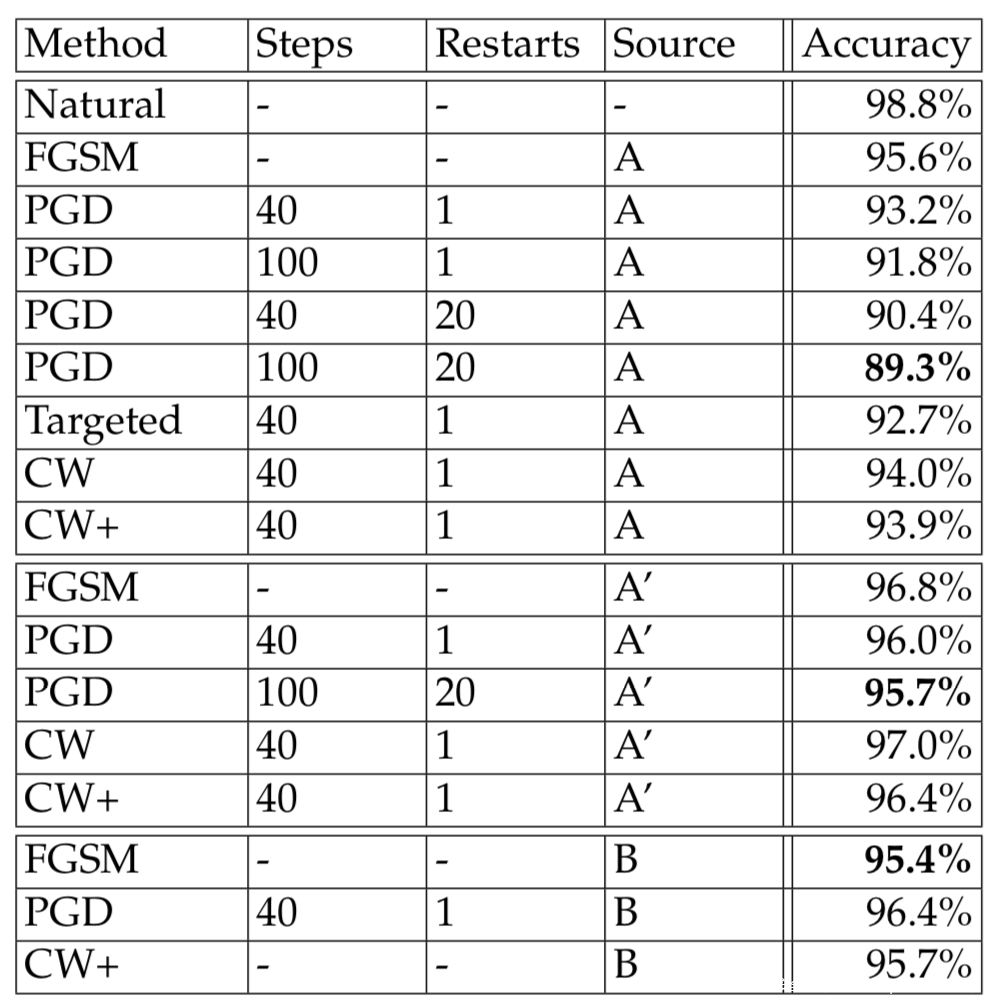
PGD是非常强的first-order攻击,能防御PGD的网络,就可以防御其他任何first-order攻击,所以在防御时很多工作都会用PGD进行对抗训练。针对MNIST训练集做的实验表明,PGD明显优于在PGD之前提出的对抗攻击方案:
Deepfool
[7]通过寻求当前的点在高维空间中离所有非真实类的决策边界中最近的一个,来作为攻击后的类,不过需要注意的是,这是一种贪心算法,并不能保证收敛到最优扰动,其通过下式迭代计算扰动

该方法只需将问题变为计算从x到所有类之间的决策边界所形成的凸多面体P表面的距离,就可以用于攻击多分类器。
下表是在不同分类器上做的比较,表中的引用文献4,18分别是本文中的[2],[1]
从表中可以看到,Deepfool的扰动是最小的

ATN
[24]以自监督的方式训练前馈神经网络以生成对抗样本,其优化目标为:
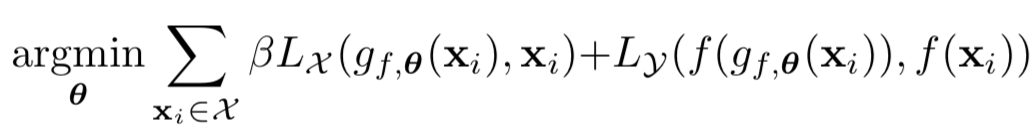
上式中的g就是我们需要的网络,输入原图像,输出对抗样本,即
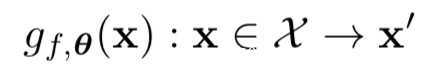
在该研究汇中,将Ly,t定义为
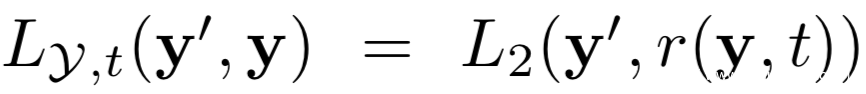
上式中的r(y,t)表示为

下图是对MNIST数据集0~9类分别对另外9个目标类的定向攻击,生成的对抗样本

实战
这部分给出几种流行的对抗攻击算法针对同一原样本实现的对抗攻击,为了便于比较,同时打印出lp范数、原样本、对抗样本以及加入的对抗扰动
L-BFGS


FGSM


I-FGSM


MI-FGSM


C&W
![]()

ILCM[17]


PGD


防御
防御技术可以分为启发式和可证明式,启发式防御是指对某些特定攻击具有良好性能,但是没有给出防御性能的理论性保障,对抗训练就是其中的典型代表,已有的研究表明,对抗训练可以在多个数据集上抵御各种L_infiy攻击,其防御是最好的。而可证明式防御在明确知道对抗攻击类别的情况下,可证明式防御能够计算模型输出的最低精度。比如最近流行的可证明式防御是制定对抗性多面体,并通过凸松弛来限制它的上界。宽松弛过后的上界可以作为已训练模型的一个保障,它可以证明在限定的限制条件下,没有任何攻击可以超过该上界对应的攻击成功率。但是这些可证明式防御措施的实际性能仍然比对抗训练的性能差很多。相关细节不再赘述,安全客也有相关文章(“如何防御对抗攻击”)可以参考。
参考
1.Intriguing properties of neural networks
2.Explaining and harnessing adversarial examples
3.Adversarial examples in the physical world
4.Boosting adversarial attacks with momentum
5.Towards evaluating the robustness of neural networks
6.The limitations of deep learning in adversarial settings
7.DeepFool: a simple and accurate method to fool deep neural networks
8.EAD: elastic-net attacks to deep neural networks via adversarial examples
9.Adversarial examples in the physical world
10.Ensemble Adversarial Training: Attacks and Defenses
11.Towards Deep Learning Models Resistant to Adversarial Attacks
12.Universal Adversarial Perturbations
13.Decision Boundary Analysis of Adversarial Exam- plesa
17.Adversarial Machine Learning at Scale
18.Spatially Transformed Adversarial Examples
19.Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
20.Adversarial Spheres
21.A Closer Look at Memorization in Deep Networks
22.Practical Black-Box Attacks against Machine Learning
23.Improving Transferability of Adversarial Examples with Input Diversity
24.Adversarial transformation networks: Learning to generate adversarial examples
25.Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models







发表评论
您还未登录,请先登录。
登录