

近年来,钓鱼检测和识别方法不断发展,可以防御网络钓鱼攻击。网络钓鱼检测解决方案通常会报告二进制结果,即是否进行网络钓鱼,而没有任何解释。相比之下,网络钓鱼识别方法是通过将网页与预定义的合法参考进行可视比较来识别网络钓鱼网页,并报告网络钓鱼及其目标品牌(brand),从而得出可解释的结果。
在这项工作中设计了一种混合式深度学习工具Phishpedia(https://sites.google.com/view/phishpedia-site/home ),以解决网络钓鱼识别方面的两个主要技术挑战,即(i)准确识别网页屏幕截图上的可识别logo,以及(ii)匹配同一品牌的logo变体。 Phishpedia可以实现高精度和低运行时开销。重要的是与一般方法不同,Phishpedia不需要接受任何网络钓鱼样本的训练。使用真实的网络钓鱼数据进行了广泛的实验;结果表明,在准确有效地识别网络钓鱼页面方面,网络钓鱼明显优于基准识别方法(EMD,PhishZoo和LogoSENSE)。还通过CertStream服务部署了Phishpedia,并在30天内发现了1,704个新的真实钓鱼网站,这比其他解决方案要多得多。而且,其中1133个未被VirusTotal中的任何引擎报告。
0x01 Introduction
网络钓鱼是攻击链中的重要一步,在过去几年中发展到一定程度,以至现在可以作为服务使用并提供(Phishing as a Service)。根据报道,网络钓鱼工具的价格从2018年到2019年翻了一番,因此在网络钓鱼攻击期间,网络钓鱼攻击量飙升了4-5倍也就不足为奇了。 同时,研究人员一直在开发新的和不同的解决方案来检测网络钓鱼页面。将其大致分为网络钓鱼检测和网络钓鱼识别方法。
虚假网页检测解决方案通常基于动态黑名单或受监督的机器学习模型,这些模型在具有基本事实的数据集上进行训练。尽管某些网络钓鱼检测模型仅使用URL(用于训练和预测),而其他网络钓鱼模型另外使用HTML内容进行特征提取。它们受到三个基本局限性的影响:(i)用于训练的有偏倚的网络钓鱼数据集导致偏向模型;(ii)需要持续提供大标签的网络钓鱼数据集保持模型最新;(iii)没有对预测结果的解释。此外,请注意,可以通过非常不同的HTML脚本来呈现相似的网页,这在推断网页的视觉语义上会带来技术挑战,从而影响检测精度。此外,攻击者可以轻易采用逃避技术来欺骗此类解决方案。
相比之下,网络钓鱼识别解决方案维护着网络钓鱼攻击针对的品牌参考集(或其网页)。基于这样的合法参考数据库,建立了模型。随后,在操作中,如果模型预测给定的网页与参考数据库中特定品牌的网页相似,但是域名与所标识的品牌不同,则该网页将被归类为网络钓鱼页面。网络钓鱼识别模型的目标不仅是检测网络钓鱼页面,而且还可以识别网络钓鱼目标。
一些早期的网络钓鱼识别提议将给定网页的屏幕快照与参考数据库中所有网页的屏幕快照进行比较。例如使用地动距离(EMD,Earth Mover’s Distance)技术来计算两个网页的屏幕截图的相似度。但是,这种方法受到以下的限制:网页及其内容是动态的,并且也经常更新。这会导致精度降低;此外,计算开销随着引用的屏幕截图数量的增加而增加。因此,最近的工作转移到使用品牌的真实身份(logo)来进行网络钓鱼识别。在参考数据库中将可疑网站的logo与目标品牌的logo进行比较网页及其设计的变化。此外,随着尺度不变特征变换(SIFT, Scale-Invariant Feature Transform)等技术的出现,有可能比较尺度和方向不同的图像。但是,基于SIFT的方法不仅在计算上昂贵(本研究实验表明处理每个屏幕截图大约需要19秒)也不准确。如系统所示,SIFToften不会提取与参logo匹配的相关特征点。这也反映在本文的实验评估中。
针对网络钓鱼识别当前最新研究的局限性,在这项工作中提出了一种实用且可解释的网络钓鱼识别系统Phishpedia。将Phishpedia设计为一种混合式深度学习系统,该系统由两个用于识别网络钓鱼页面的流水线式深度学习模型组成。更具体地说将网络钓鱼识别问题分解为:(i)identity logo识别问题和(ii)品牌识别问题。使用定制化的对象检测模型来解决前者问题,使用基于转移学习的Siamese模型来解决后者。混合深度学习系统使Phishpedia在识别网络钓鱼尝试及其目标方面可以达到很高的准确性。非常重要的是,Phishpedia无需任何网络钓鱼数据集即可对模型进行训练从而实现了这一目标,避免了网络钓鱼样本中的潜在偏差。此外,网络钓鱼还可以在钓鱼页面的屏幕截图上提供可解释的视觉注释(有关系统输出的示例,请参见下图)。此外,由于基于深度学习的图像识别解决方案容易遭受规避攻击,因此也将梯度掩蔽技术结合到了Phishpedia上以反对抗攻击。最后,给定屏幕快照及其URL,Phishpedia会在0.2秒内进行预测,这也使其比现有解决方案更加实用。
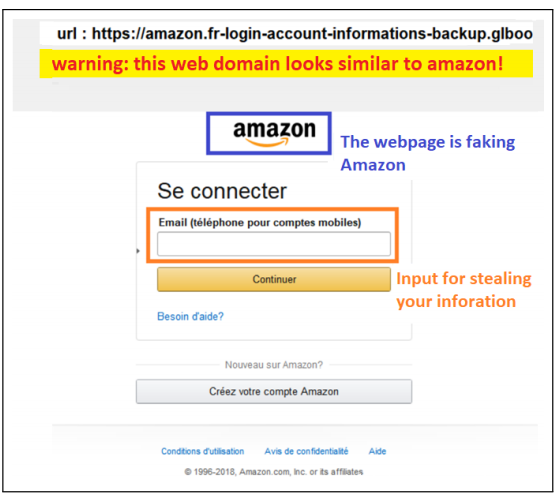
本文进行全面的实验以评估Phishpedia。首先,使用从OpenPhish高级订阅获得的六个月的网络钓鱼URL,将Phishpedia与最新的网络钓鱼识别方法(即EMD,PhishZoo和LogoSENSE)进行比较。实验表明,Phishpedia在识别准确度和运行时间开销方面明显优于基线方法。其次,证明了混合深度学习系统能够防御一些众所周知的基于梯度的对抗攻击,例如DeepFool,JSMA,StepLL和FGSM。第三,本研究进行了一个网络钓鱼发现实验,在该实验中,使用五个网络钓鱼检测器/识别器来运行网络钓鱼,以在野寻找新的网络钓鱼网页。结果表明,在互联网上发现网络钓鱼新页面方面,Phishpedia具有比基准方法更高的性能优势。与其他解决方案相比,Phishpedia报告了更多的网络钓鱼网页,而且误报率也要低得多– Phishpedia在30天内发现了1,704个网络钓鱼网页,其中VirusTotal 中的任何引擎都未检测到其中的1,133个网络钓鱼网页。此外,即使一周后VirusTotal仍未报告其中74.6%的病毒。
0x02 Overview of Phishpedia
A.威胁模型
本工作中考虑的威胁模型如下:攻击者构建了一个伪造的网页W’,该网页伪装成特定品牌(例如Paypal)的合法网站W的用户界面,更具体地说,是具有输入框的表单,该表单允许用户输入凭据信息(例如,用户名,密码,银行帐户详细信息等)。然后,攻击者通过电子邮件,社交网络等将网页W的URL发送给许多用户。获得该链接的用户在单击该网络钓鱼页面W’的URL时会成为受害者,并提供与合法网站W相对应的敏感帐户信息。目标是检测此类网络钓鱼网页,识别目标品牌,并生成直观的注释,以解释将网页归类为网络钓鱼页面的原因。
B.概述
下图概述了提出的系统Phishpedia。网络钓鱼将输入URL和描述合法品牌logo及其网络域的目标品牌列表作为输入;然后生成网络钓鱼目标(如果将该URL视为网络钓鱼)作为输出。将标识合法品牌的logo称为该品牌的identity logo。此外,输入框可使用户输入凭据信息(例如用户名和密码)。
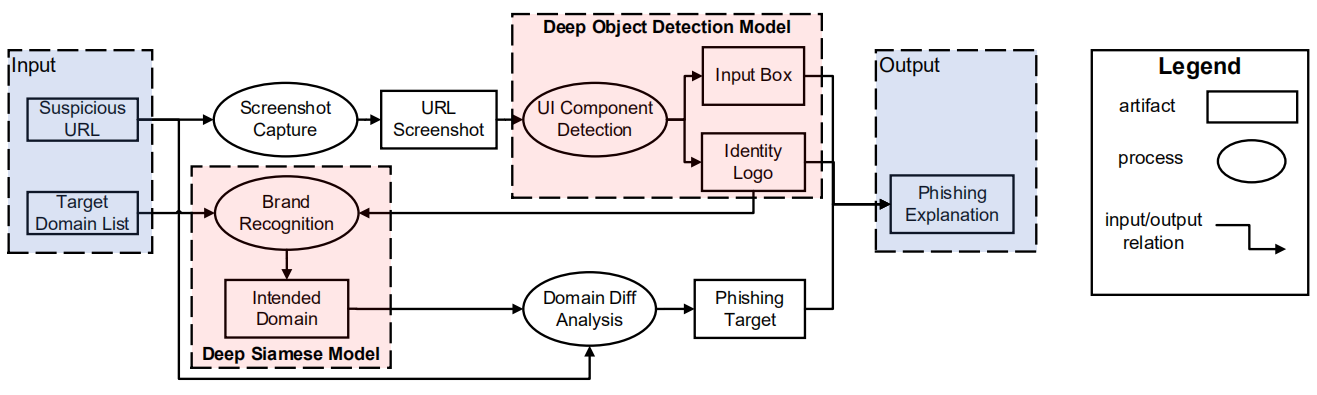
给定一个URL,首先在沙盒中捕获其屏幕截图,然后将网络钓鱼识别任务分解为两个:对象检测任务和图像识别任务。首先,在屏幕快照中使用对象检测算法来检测重要的UI组件,特别是identity logo和输入框。下一步通过Siamese模型,将检测到的identity logo与目标品牌列表中的logo进行比较,从而确定网络钓鱼的目标。一旦目标品牌列表中的logo(例如Paypal的logo)匹配,将其对应的域(例如paypal.com)视为捕获的屏幕截图的预期域。随后分析目标域名和给定URL域名之间的差异,以报告网络钓鱼结果。最后结合了报告的identity logo,输入框和网络钓鱼目标,以合成可视化的网络钓鱼说明。
0x03 Design and Development of Phishpedia
A.检测UI组件
首先解释一些重要的概念。对象检测模型将图像作为输入,并生成一组边界框以注释图像上对象的位置和大小。在问题设置中,图像是网页截图,而感兴趣的对象是logo或输入框。该模型将为每个对象(即logo或输入框)生成具有置信度得分的边界框。
本文分析检测logo和输入框的位置和形状的多种解决方案,并选择Faster-RCNN模型来解决此问题,因为它最能完全满足报告logo的要求。在后文将Faster-RCNN模型与其他候选模型进行比较,简要描述了其网络结构以解释如何将其应用于检测logo和输入框。
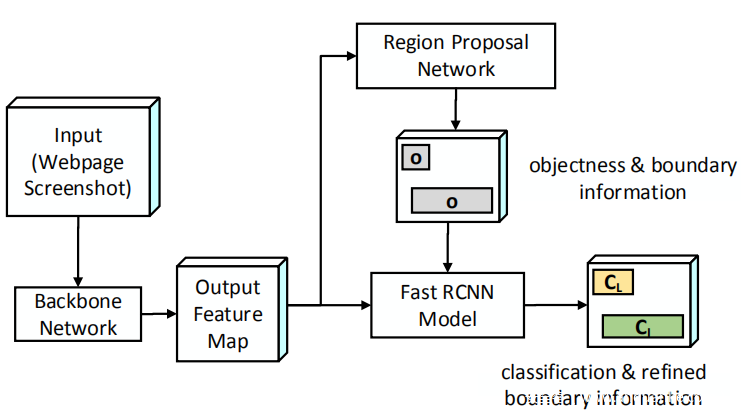
上图展示了Faster-RCNN的网络结构。这是一个两阶段的对象检测模型,包括区域候选网络(RPN)和Fast RCNN模型。鉴于输入的屏幕截图,使用骨干网(例如,Resnet50)来转换目标将屏幕快照输入到形状为M×M×c的特征图中,其中M表示特征图的大小,c表示通道大小。以功能图为输入,Faster-RCNN使用RPN预测输入屏幕截图上的一组边界框,为屏幕截图显示一组“对象”。如图所示,对于每个边界框(灰色矩形),RPN将报告一个对象得分,以表明其包含一个对象(即设置中的UI组件)的可能性及其形状。然后,Fast-RCNN模型将输出特征图和边界框的输入用于(i)预测对象类别(即logo或输入框),以及(ii)细化每个对象的形状和大小。
给定屏幕截图,Faster-RCNN模型报告一组候选徽标L = {l1,l2,…,ln};每个li(i∈[1,n])都附有一个置信度分数。根据logo的得分对logo进行排名,并将排名第一的logo作为identity logo。
B.品牌识别
目标品牌列表包括考虑用于网络钓鱼识别的多个品牌。对于每个品牌,都会保留两种logo的logo变体列表和合法域名列表。首先,维护多个品牌logo变体可以使本研究以更精确,更灵活的方式匹配logo图像。其次,一个品牌可以对应多个合法域名。例如,亚马逊品牌可以具有“ amazon.com”和“ amazon.jp.co”之类的域。捕获此类信息可以减少误报。
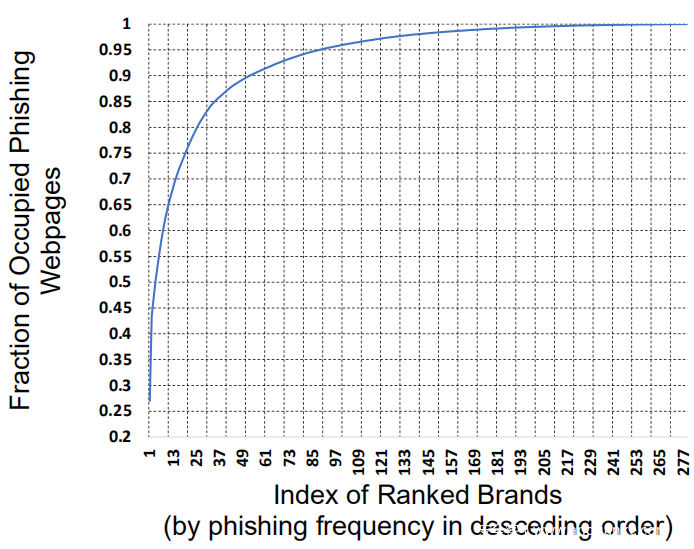
给定已报告的身份logo l,如果其与目标品牌列表中logo lt的相似度高于预定阈值θ,则将相应的品牌报告为网络钓鱼目标品牌。通常能否准确识别检测到的品牌logo,部分取决于受保护品牌的数量。由于世界上有很多品牌,因此一般的品牌识别可能需要非常长的目标品牌列表。但是目标品牌列表的长度不一定那么长。首先,根据OpenPhish feed对大约3万个网络钓鱼网页进行的经验研究表明,排名前100位的品牌覆盖了95.8%的网络钓鱼网页;参见上图。该经验结果与直觉一致,即要使网络钓鱼活动有利可图,攻击者必须将目标对准著名的大型企业或金融实体。此外,用户可以添加新品牌及其logo和域名(例如,本地银行)以自定义受保护的目标列表。
logo比较:这里的关键技术挑战是估计两个logo的相似性。一种简单的解决方案是将logo识别视为图像分类任务,其中输入是logo图像,输出是其品牌。然而,图像分类模型具有两个固有的缺点。首先,分类模型在运行期间无法支持在目标品牌列表中添加新品牌。一旦添加了新品牌,就需要重新培训整个网络。第二,分类模型需要预先定义类别(即设置中的品牌)。因此,给定logo在训练数据集中带有未知品牌,该模型将始终将其归类为现有品牌之一,这可能在实际应用中引起较大的误报。
在这项工作中,选择Siamese神经网络模型来解决上述挑战。通常,Siamese神经网络模型将图像转换为代表性的矢量。因此,可以通过两个图像的代表向量的相似度(例如,余弦相似度)来估算两个图像的相似度。通常,通过为模型提供一对图像来训练Siamese模型。正样本是一对相同类别的图像,负样本是一对不同类别的图像。然后,使用预测正样本的高分和负样本的低分的损失函数(例如,Triplet loss)。

但是实验表明,通过上述常规方法训练Siamese模型来比较logo是无效的。Siamese模型的常规训练过程选择三个图像<Ic1,I’c1,Ic2>作为样本来计算三重态损失,其中Ic1和I‘c1属于c1类,Ic2属于c2类。训练的目的是确保同一类别(sim(Ic1,I’c1))中图像的相似度应大于不同类别(sim(Ic1,Ic2))中图像的相似度。同一品牌下的logo可能会有很大差异(例如上图)。很难强迫模型学习相同品牌的不同logo变体的相似代表向量(例如,图a和图b)。从进行的实验中,观察到如果迫使模型达到这一具有挑战性的目标,则会产生将不同类别的品牌预测为相似的副作用。

在这项工作中,利用迁移学习来解决上述挑战。如上图所示,首先设计logo分类任务,以便骨干网(例如Resnetv2网络)捕获logo图像的特征。通过分类任务,允许模型从同一品牌的不同logo变体中提取不同特征。将骨干网与具有一层隐藏层的完全连接的网络相连。使用Logo2K +数据集来训练该任务,以对2341个品牌进行分类。然后,以骨干网为基础,并与全局平均池(GAP)层进行连接,以构造2048个维的代表性向量。 GAP层汇总了从骨干网络输出的特征图,并表示logo图像的语义特征。因此,对于非常不同的logo变体(例如,前图中的那些),学习了不同的代表矢量。在不强制模型为不同图像学习统一的代表向量的情况下,本文避免了引入错误logo匹配结果的风险。然后将两个logo图像的代表向量的余弦相似度计算为相似度。
最后要执行logo品牌分类任务,注意到可以选择对模型训练进行微调,以使Siamese模型更适应目标品牌列表中受保护的logo。假设目标列表的大小为n;在Logo2K +数据集上训练模型之后,可以用n个输出神经元的另一个连接层替换完全连接的层,这对应于目标品牌的数量。因此,可以针对目标列表中的品牌专门训练模型。实验表明,这种可选的训练过程可以提高logo识别能力,同时仍保留在目标品牌列表中添加看不见的新logo的灵活性。
C.反对抗攻击
众所周知,深度学习模型容易受到对抗性攻击。为对象检测模型(例如DAG)和分类模型(例如DeepFool和FGSM)设计了最新的对抗攻击。让神经网络成为函数f(x),x是样本。通常,大多数基于梯度的方法都基于偏导数∂f/∂x进行攻击,以求出x上的最小扰动δ,以获得x’=x +δ,从而可以将目标模型设为f(x’)= f(x)。
传统的反对抗攻击的防御技术通常采用多种对抗训练方法。但是,对抗训练方法也会降低原始模型的性能,并且对于某些看不见的对抗样本可能无法很好地发挥作用。相反,设计了一种新的简单的对抗防御技术,将Faster-RCNN和Siamese模型转换为可对抗某些基于梯度的众所周知的对抗攻击,同时(i)仍保持模型性能,并且(ii)不需要其他(对抗性)训练,增加了系统的复杂性。
具体来说,将两个模型的某些层中的ReLU函数替换为逐步ReLU函数。在这种方法中,将step-ReLU函数设计为下式,其中传统ReLU的线性函数被替换为step函数;下图对此进行了说明。参数α确定步长函数中的间隙大小。
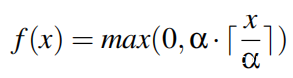
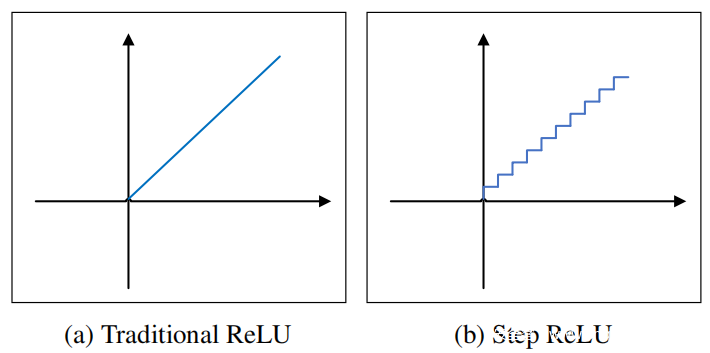
阶跃导数的偏导数∂f/∂x为0或无穷大,从而减小了基于梯度的攻击(例如DeepFool,JSMA,StepLL和FGSM的影响 )。此外,转换后的ReLU激活函数层可以在很大程度上保留激活函数输出值的精度,从而有助于保留原始网络模型的性能。
0x04 Implementation
在上一节中介绍的组件之上构建了Phishpedia。根据经验研究在目标列表中选择了181个品牌,因为它们是最受欢迎的网络钓鱼目标,占网络钓鱼攻击的99.1%。值得回顾的是,网络钓鱼不需要训练的网络钓鱼数据集。
对象检测模型:基于Detectron2框架训练了Faster-RCNN模型。与最初的Faster-RCNN模型可以互换地训练区域建议网络和Fast-RCNN模型不同,采用的Detectron2框架使用四个特征层,并共同训练这两个模型,以提高训练效率。
Siamese模型:通过PyTorch框架训练了Siamese模型。选择Resnetv2作为骨干网。使用Logo2k +数据集来训练品牌分类任务,作为转移学习的基础模型。这两个神经网络都在配备Xeon Silver 4108(1.8GHz),128G DDR4 RAM和NVIDIA Tesla V100 GPU的Ubuntu16.04服务器上进行训练。所有评估实验(均在同一服务器上进行。
0x05 Performance Evaluation
接下来,进行综合实验以回答以下研究问题:
•RQ1:与最新的基准相比,网络钓鱼在识别网络钓鱼页面方面的准确性如何?
•RQ2:Phishpedia的核心组件(即对象检测模型和Siamese模型)的准确性是多少?
•RQ3:如果在运行期间在目标品牌列表中添加了新logo,则Phishpedia的性能如何(换句话说,Phishpedia呈现经过培训的Siamese模型未看到的新logo)?
•RQ4:针对Phishpedia的替代技术选择是什么?它们的性能如何?
•RQ5:Phishpedia如何抵抗最新的对抗攻击?
•RQ6:Phishpedia是否有助于在野中发现网络钓鱼网页?
为了回答RQ1进行了实验,比较了大约30K网页虚假网页(通过订阅Openphish Premium Service获得)和其他30,000良性网页(来自Alexa排名第一的网站)中Phishpedia与其他基准方法的性能。为了回答RQ2,分别评估了目标检测模型和Siamese模型的性能。对于RQ3和RQ4,当将看不见的logo添加到目标品牌列表中时,以及在采用替代的技术选项时,都会进行对照实验,以评估Phishpedia的性能。为了回答RQ5,在模型上应用梯度掩蔽技术之前和之后评估模型的准确性和对抗攻击的成功率。对于RQ6,进行了网络钓鱼发现实验,以比较Phishpedia和其他五个解决方案在报告真实世界中虚假网页的性能。
A.数据集
为了回答上述研究问题收集了相关的数据集。详情如下:
网络钓鱼网页数据集:为了收集实时网络钓鱼网页及其目标品牌作为真实情况,订阅了OpenPhish Premium Service,为期六个月;这提供了35万个网络钓鱼URL。运行了一个每日爬虫程序,该爬虫基于OpenPhish每日供稿,不仅收集了Web内容(HTML代码),而且还截取了与网络钓鱼URL对应的网页的屏幕截图。这能够在URL被淘汰之前获得所有相关信息。此外,手动清理了无法打开网页(即,当访问它们时不可用的网页)和非网络钓鱼网页(例如,该网页不再用于网络钓鱼并已被清理,或者当访问该网页时是纯空白页面) 。另外使用VPN在多次访问网络钓鱼页面时更改IP地址,以最大程度地降低隐藏技术的效果。还手动验证(有时更正)了样品的目标品牌。结果,最终收集了29,496个网络钓鱼网页用于实验评估。请注意,从PhishTank爬虫的常规数据集和OpenPhish的免费版本没有网络钓鱼目标品牌信息。尽管现有的工作使用较大的网络钓鱼数据集进行网络钓鱼检测实验(即,没有识别目标品牌),但本研究还是收集了最大的网络钓鱼识别实验数据集。
良性网页数据集:在本实验中,从排名最高的Alexa列表中收集了29,951个良性网页。类似于网络钓鱼网页数据集,还保留了每个URL的屏幕截图。
标记的网页截图数据集:为了独立地评估对象检测模型,使用收集到的(良性数据集)约30K Alexa benign网页及其屏幕截图。将在屏幕截图上标记身份logo和用户输入的任务外包。
B.将Phishpedia与最新的基准进行比较(RQ1)
(1)网络钓鱼网页中的logo频率
从网络钓鱼网页数据集中随机抽取了5,000个网页,并手动验证其中有70个没有logo。也就是说,带有logo的网络钓鱼网页的比例约为98.6%。下图显示了OpenPhish报告为Adobe的仿冒网站的网页的屏幕截图,但是,如果没有logo,认为假冒攻击是不可能成功的,因为用户甚至可能不知道在该页面提供哪种凭据。换句话说,要有效,logo是网络钓鱼网页的重要特征。
(2)评估基准
选择EMD,PhishZoo和LogoSENSE]作为基准网络钓鱼识别方法。下表显示了基准方法的详细信息。它们代表了不同的基于视觉相似性的识别方法,即屏幕快照相似性(EMD),基于SIFT的相似性(PhishZoo)和基于HOG矢量的相似性(LogoSENSE)。目标品牌列表与包含181个品牌的PhishZoo和Phishpedia相同。
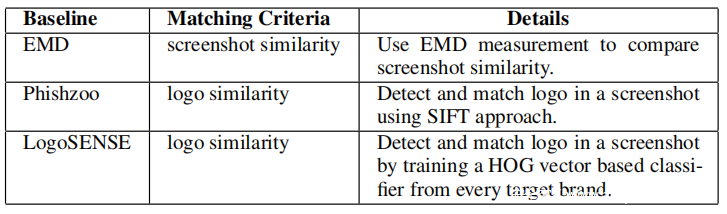
由于EMD本质上是一种用于估算两个屏幕截图的相似性的测量技术,因此它可以根据引用的屏幕截图的数量来不同地执行(在标识和运行时开销方面)。引用的屏幕截图数量越多,可以实现的调用率就越高,但是运行时成本也就越高。因此,为评估定义了两个EMD版本:
•EMDnormal:在此版本中,为EMD配备了181张代表性屏幕截图(在线收集)作为参考,并针对整个网络钓鱼和良性网页数据集评估其性能。
•EMDmore_ref:对网络钓鱼网页数据集进行摘要匹配,发现前半部分的屏幕截图可以匹配后半部分的屏幕截图的48%。这表明具有更多参考文献的EMD可能会实现更高的召回率。因此,在此版本中,暂时将六个月的网络钓鱼网页数据集划分为两个相等的部分。为了提高EMDmore_ref的运行时效率,将摘要匹配应用于前半个时间段中的约15k屏幕截图;这样可以将参考屏幕截图的数量减少到3k左右。
对于LogoSENSE,让它检测针对五个特定品牌的钓鱼网站网页-Paypal,Microsoft,Chase Personal Banking,DHL Airway和Bank of America。选择这些品牌是因为它们在本文实证研究中很受欢迎。该列表仅限于五个品牌,因为LogoSENSE要求本研究为每个品牌训练分类器,这意味着需要为这181个品牌中的每个标记足够的网络钓鱼屏幕截图,并为此实验训练181个分类器。由于实验成本高昂,改为手动标记前五名品牌的网络钓鱼和良性屏幕截图,以训练LogoSENSE。但是,为了公平起见,运行LogoSENSE来检测和识别仅针对这五个品牌的网络钓鱼网页。请注意,相应的网络钓鱼页面数量高达15,658;同时仍保留29,951个良性网页来评估其误报率。由于这三种方法的代码不是开源的,因此将它们用于评估。
在此实验中,让EMDnormal的相似性阈值为0.92,EMD more_ref的相似性阈值为0.96,PhishZoo的相似性阈值为0.4,Phishpedia的相似性阈值为0.83。在为每个模型尝试了多个阈值之后,这些值是最佳阈值。
(3)结果(RQ1):网络钓鱼识别的准确性
在下表中,将网络钓鱼和基线方法的网络钓鱼识别率(IdentificationRate),网络钓鱼检测的支持率(检测率)和运行时开销进行了比较。按以下方式计算每列:假设钓鱼网站总数为Nump,报告的钓鱼网站数量为Repp,报告的真实钓鱼网站数量为ReppTP,报告的带有品牌正确报告的真实钓鱼网站数量为Idp。 “识别率”列的计算方式为IDp/ReppTP。精度以RepTP/Repp的形式计算,而召回率以RepTP/Nump的形式计算。
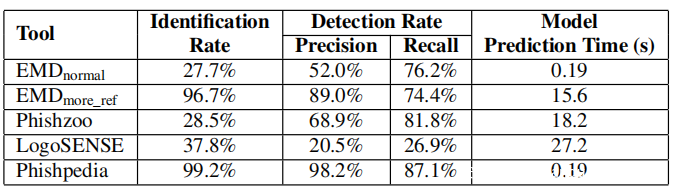
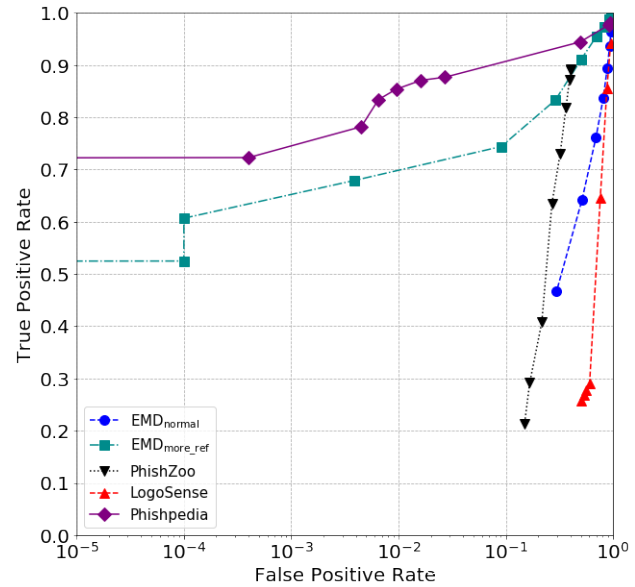
上表列出了这些方法的最佳结果(识别率,准确性和召回率之间的平衡)。请注意,所有方法都将URL作为输入,因此它们都具有将URL转换为其屏幕截图的相同过程和成本,这平均需要大约1.88s。同样,优化网络通信和捕获屏幕截图的技术不在这项工作的范围之内。请注意,在识别率,检测率和运行时开销方面,Phishpedia优于基准方法。 EMDnormal具有与Phishpedia相似的运行时效率,但识别和检测精度较差。相比之下,EMDmore_ref在精确度和召回率方面却获得了更好的性能,但是在更高且不切实际的运行时上–平均而言,处理给定的网页需要15.6秒。PhishZoo还需要大量的计算时间来确定网页,而LogoSENSE却很低检测和识别率。此外,在下图中绘制了所有识别方法的ROC曲线。随着FPR的降低,除了EMDmore_ref外,观察到了Phishpedia与基准方法之间的差距正在扩大。除了Phishpedia之外,EMDmore_ref是在较低的FPR上实现有意义的召回(TPR)的另一种方法(尽管这会带来较高的计算成本),但是,如果考虑较低的FPR值10^(-2)、10^(-3)和10^(-4) ,这是操作部署所必需的,注意到与EMDmore_ref相比,Phishpedia的召回率仍然更高。
基准定性分析:EMD受困于从网页屏幕截图中提取粗略特征(例如,像素颜色)。下图显示了一个网络钓鱼页面EMD misseded报告(假阴性)和一个错误报告的页面(假阳性)。

由于SIFT的技术局限性,PhishZoo处于不利地位。 SIFT通过从logo中提取k个特征点和从屏幕截图中提取k0个特征点来匹配logo。只要匹配k个特征点的k’个,从而k‘≤k且k’/k大于阈值,SIFT就会报告logo出现在屏幕截图上。观察到它的局限性主要在于提取不完整的特征点以及所提取的特征点不匹配,如下图所示。

LogoSENSE会同时导致高误报率和漏报率:LogoSENSE在屏幕快照中使用logo大小的滑动窗口。滑动窗口的内容将被转换为HOG向量,并被馈送到一组训练有素的SVM模型,每个模型都代表一个品牌logo。输出是与此HOG向量具有最高相似性的品牌logo。在实验中使用屏幕快照中的滑动窗口,观察到固定的滑动窗口通常会覆盖部分logo(请参见下图c),这对相应的SVM模型提出了很好的预测。此外,LogoSENSE很难推广到更复杂(或看不见)的屏幕截图,因此经常将按钮报告为logo(如下图d所示)。还观察到,屏幕截图上的大量滑动窗口会导致大量的运行时开销。

对Phishpedia的定性分析:借助精确的身份logo识别和logo图像比较,网络钓鱼可以克服网络钓鱼识别所面临的挑战。但是将调查网络钓鱼进行错误预测的特定重要案例。
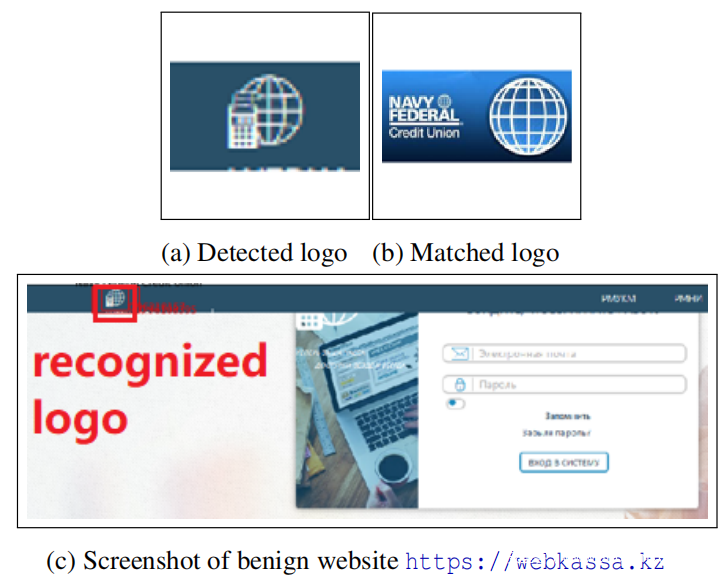
假阳性:当良性网页上的logo看起来像是众所周知的合法品牌logo时,Phishpedia会做出错误的积极预测。如下图所示,良性网站的logo看起来与品牌Navy Federal的logo变体类似(请参见下图b)。这样的一对相似logo混淆了Phishpedia中的Siamese模型。一种补救措施是通过长宽比和更详细的布局对图像相似性施加更严格的限制。
假阴性:毫不奇怪,Phishpedia错过了针对受保护目标品牌列表之外的品牌的网络钓鱼网页。对于所有网络钓鱼识别方法来说,这都是一个普遍的问题。在实践中,可以通过增强目标列表来缓解此问题。
C.单个组件分析(RQ2)
(1)评估logo检测
在带有标签的屏幕截图数据集中使用约29K个样本来训练模型,并使用约1600个样本进行测试。计算每个类(即logo和输入框)的IoU阈值的平均精度(AP),范围从0.5到0.95,间隔为0.05。下表给出了结果。与Faster RCNN相比,PASCAL VOC数据集上的mAP为67.9 ,在本实验中,预测logo和输入框所达到的mAP(即训练为63.1,测试为59.7)表明性能可接受。

(2)评估logo识别
为了独立评估Siamese模型,手动标记了181个品牌的1,000个虚假网站网页截图的身份logo,并采样了带有标签的身份logo的1000个良性网页截图。然后,提供2,000个身份logo(每个屏幕快照)作为训练后的Siamese模型的输入,以评估Siamese模型可以比较logo的程度。请注意,这些屏幕截图中的logo是样本,不在训练数据集中。
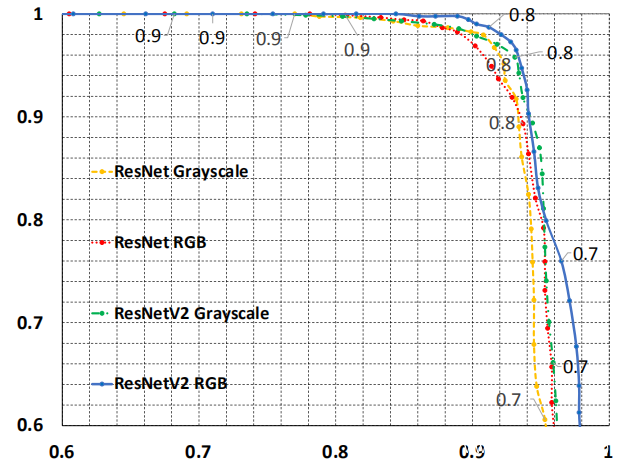
还尝试了一种替代性骨干网和一种替代性输入(就logo颜色而言)。将Resnet50和RestnetV2-50作为骨干网进行实验,并考虑两种形式的logo输入-一种是RGB,另一种是灰度。通过将Siamese模型的相似性阈值从0.5更改为0.9,以0.05为间隔,可以在下图中绘制每种配置的精确调用曲线。通常,四种配置的性能是可比较的并且可以接受。此外,带有RGB logo的Resnetv2(蓝色曲线)可实现最佳性能。根据以上结果得出结论,Faster-RCNN和Siamese模型在识别和比较logo方面均具有良好的性能。
D.Phishpedia概要(RQ3)
在本实验中评估了在将新logo(训练中未使用)添加到目标品牌列表时,Siamese模型是否可推广。为此在迁移学习的第二阶段对模型进行了训练,该模型仅在目标品牌列表中使用了130个品牌logo,并检查它是否可以有效匹配其余51个品牌logo(未对其进行训练,但形成新的目标列表)。随机抽取了51个品牌的logo样本,这些logo涵盖了标记数据集中的7,411个虚假网站。
在51个“新”品牌覆盖的7,411个网页中,Phishpedia识别了87.46%的网络钓鱼网页,其高识别率为99.91%。这表明Siamese模型很好地捕获了从logo样本中提取的可概括特征。因此本文方法是通用的,可以在运行时在目标品牌列表中添加新logo。
E.替代选项(RQ4)
接下来评估实施Phishpedia的其他技术选择,研究以下技术选择:
•Op1:其他知名的对象检测算法(一级模型,例如Yolov3)如何执行logo识别?
•Op2:经过一阶段转移学习和两阶段转移学习训练的Siamese模型如何进行logo比较?
•Op3:采用传统程序(例如,三重态损失)训练的Siamese模型如何进行logo比较?
•Op4:可以用诸如感知哈希(PH)的更简单方法来代替Siamese模型吗?
(1)设置
对于Op1,选择一种流行的一级目标检测模型Yolov3。采用通过Tensorflow 1.4框架实现的Yolov3模型。在训练Faster-RCNN模型的同一集群上训练模型。对于Op2,将经过一阶段训练的Siamese模型与经过两阶段训练的模型进行比较。对于Op3,使用Triplet损失以传统方式训练Siamese模型。在本实验中,使用三重态损失函数训练模型。对于Op4,用实现的标准感知哈希算法替换了Siamese模型。
(2)结果
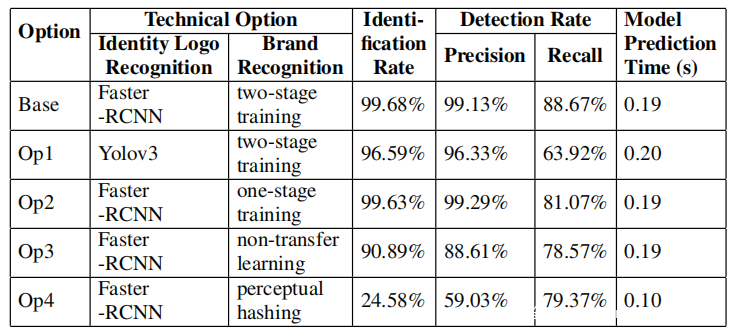
下表显示了在不同技术选项上的实验结果。总体而言,观察到Yolov3具有很好的识别准确性,尽管它丢失了许多网络钓鱼网页。此外看到,与一阶段训练相比,针对Siamese模型的两阶段训练可提高召回率,而以传统方式训练Siamese模型会对整体表现产生不利影响。最后,观察到感知哈希算法不如Siamese模型那么胜任,因为它对logo的细微变化不太灵活。因此得出的结论是,Phishpedia在logo识别和logo比较方面采用了合理的解决方案。
F.对抗防御(RQ5)
(1)基于梯度的技术实验
在这组实验中,在对象检测模型和Siamese模型上都应用了最新的对抗性攻击,其目标是两个:(i)分析Phishpedia在防御对抗性攻击方面的功效,以及(ii)评估对抗防御技术对Phishpedia的性能(在准确性方面)的影响。
使用DAG对抗攻击来评估目标检测模型的鲁棒性。将DAG用于约1,600个屏幕截图的测试集。选择四种对抗性攻击来评估Siamese模型的鲁棒性:DeepFool,i-FGSM,i-StepLL和JSMA。将这些对抗性攻击应用于1,000张屏幕截图中标记的logo,以查看Siamese模型是否仍可以与目标品牌列表中的logo准确匹配。对于每个对抗攻击,将攻击迭代限制设置为100。此外,对于DAG攻击,攻击学习率ε为0.5;对于i-FGSM和i-StepLL攻击,攻击学习率ε为0.05(请注意,DeepFool和JSMA使用无学习率)。

上表报告了对抗攻击对目标检测模型的影响;显示了原始模型和转换模型的预测准确性。同样,下表报告了Siamese模型的对抗攻击结果。至于下表中的logo匹配准确性,将N(= 1,000)个logo输入到Siamese模型中。如果将k个logo与其目标列表中其正确品牌的logo变体匹配,则logo匹配精度计算为k / N。观察到(i)本研究防御技术有效地防御了现有的最新对抗攻击;(ii)Phishpedia的准确性得到了很好的保护,并且不受防御技术的影响。

(2)使用梯度掩蔽技术进行实验
虽然基于梯度掩蔽的方法对于基于流行的基于梯度的攻击是有效的,但设计了一些对抗性攻击来掩蔽梯度以促进攻击。在这项实验中,采用了最先进的梯度掩蔽技术后向传递可微近似(BPDA,Backward Pass Differentiable Approximation)来攻击Phishpedia。 BDPA假设神经网络中的梯度掩蔽层是已知的;然后通过其梯度估算技术恢复梯度。
假设模型中的梯度掩蔽层被攻击者知道,将在BPDA的默认设置下使用不同数量的掩蔽层对Phishpedia的Siamese模型进行攻击。结果显示在下表中,在表中比较了攻击前后的模型准确性。 BPDA被认为对少量的掩蔽层有效,但是对于大量的掩蔽层则不太有效。随着估计层数的增加,BPDA在其掩蔽的梯度中引入了更多的偏差。结果,当掩蔽层的数量增加时,在偏置方向上进行对抗攻击。

0x06 Phishing Discovery in the Wild (RQ6)
本文还设计了一种网络钓鱼发现实验,以将网络钓鱼与文献中的五种网络钓鱼检测/识别解决方案进行比较,以了解它们在野(即互联网)中检测网络钓鱼新页面的有效性。
A.CertStream服务
本研究使用CertStream服务,其中包含从证书透明日志网络注册的新域。证书透明性通常用于公开审核和监视向新域颁发TLS / SSL证书的事件。在本实验研究中,使用此服务来检索新兴的域。
B.网络钓鱼发现实验
通过整合报告的新兴域和网络钓鱼检测器或识别器,构建了网络钓鱼定位器。利用Phishpedia每天从报告的新兴域中扫描和识别网络钓鱼网页。在本实验中,选择了文献中的五个已知方法,以评估它们可以报告多少个真实的网络钓鱼页面以及所报告的网络钓鱼页面的精确度。将所有解决方案运行了30天(从2020年9月10日到2020年10月9日)。在实验过程中,记录登录网址和每个网址的屏幕截图,以进行事后分析。对于每种解决方案,都使用最佳结果相对应的配置。这导致每个解决方案报告的网络钓鱼页面数量不同。在报告的网络钓鱼URL中,选择了报告最多的网络钓鱼网页(即,预测概率最高的网页),以手动调查基础事实。每个报告的网络钓鱼网页均由两名审查员独立评估。对于他们不同意的网络钓鱼网页,让他们进行讨论并达成共识。然后,使用VirusTotal检查它是否报告相同的结果。 VirusTotal配备了70多个引擎,可用于恶意网页检测(例如Google Safebrowsing)。如果某个特定的解决方案(即五个基准之一或Phishpedia)报告了一个真实的网络钓鱼网页,但VirusTotal引擎均未在同一天报告其可疑,则认为该解决方案发现了一个为期零天的网络钓鱼网页。
C.基准
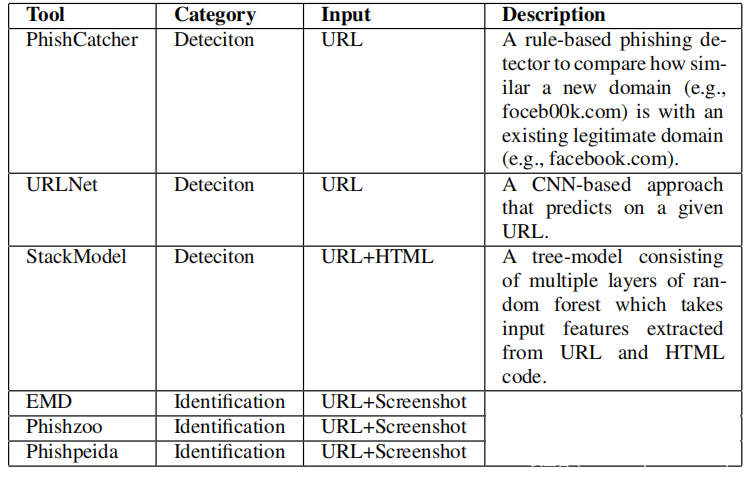
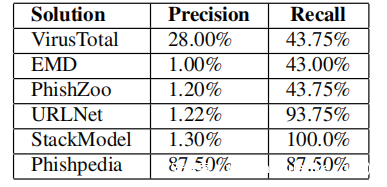
选择涵盖网络钓鱼检测器和识别器的基准,如上表所示。URLNet和StackModel是报告的两种最先进和最新技术。此外,它们使用不同的输入:URLNet仅使用URL字符串作为输入,而StackModel预测给定页面的URL和HTML内容。基于与各种行业参与者的讨论,还知道安全供应商正在考虑与上述类似的解决方案。对于此处的实验,使用网络钓鱼(来自OpenPhish)和良性(来自Alexa)网页的数据集训练这两个模型。此外,选择PhishCatcher作为另一个基准,因为它是商业产品PhishFinder的开源版本,可使用CertStream搜索网络钓鱼网页。与其他网络钓鱼检测器(例如URLNet和StackModel)类似,它也根据其预定义规则分配可疑分数。最后还在本实验中考虑了EMD和PhishZoo,因为它们是最先进的网络钓鱼识别方法。注意,未选择LogoSENSE,因为它仅支持有限数量的品牌,从而导致不公平的比较。
D.结果
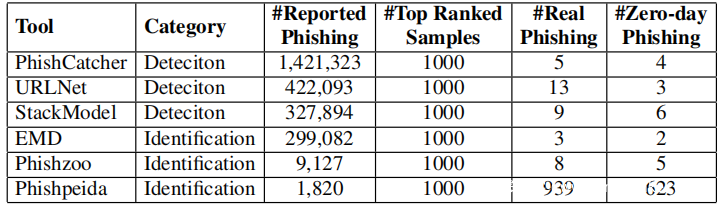
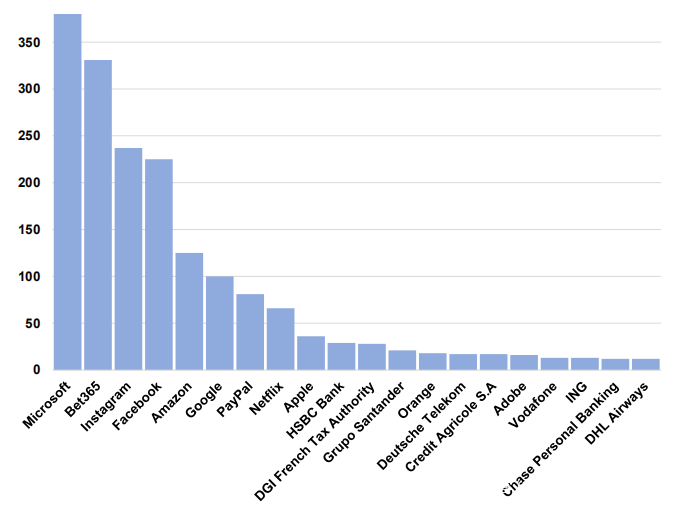
下表总结了发现的网络钓鱼网页的结果。观察到,与其他基准方法相比,Phishpedia报告的网络钓鱼结果要准确得多。实际上,在Phishpedia报告的所有1,820个网络钓鱼网页中,实际的网络钓鱼网页总数为1,704。在Phishpedia识别的这些网页中,有1,133个是被VirusTotal视为良性的新的仿冒网页。这些发现的网页仿冒网页范围超过88个品牌。下图显示了前20个品牌的网络钓鱼网页。按照建议的使用VirusTotal的做法,对所有发现的真实网络钓鱼网页进行了事后分析,发现VirusTotal仍未报告其中的74.6%。
(1)为什么Phishpedia优于基准?
根据实验结果,还可以从两个方面观察到Phishpedia相对于基准方法的优势:
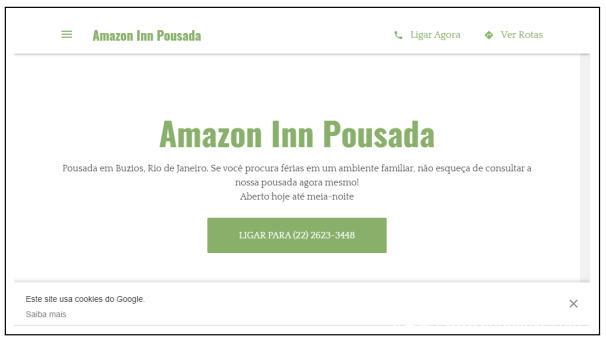
观察1:合理的URL /域不是网络钓鱼的有力指标。 PhishCatcher报告的网页最多为网页仿冒,但准确性很低。注意到,PhishCatcher对于包含可信商标名的域名(例如“ https://www.amazon-voucher.com/ ”和“ http://amazoninnpousada.com/ ”)报告了较高的可疑度。下图显示了后者的示例。很多工作都假设看起来与合法网站的域名相似的域名更容易被网络钓鱼。但是,本研究的网络钓鱼发现实验不支持这种假设,并且发现名称真实性与网络钓鱼可疑性之间的相关性较小。虽然这样的结论是违反直觉的,但从统计上讲,鉴于PhishCatcher报告的真实钓鱼网页很少。
观察2:过度拟合或学习到的偏见是机器学习方法的致命缺陷。基于机器学习的方法即使在实验数据集上显示出非常准确的结果,也无法在这样的实际发现研究中很好地发挥作用。 StackModel是一个基于树的模型,它能够生成特征重要性,以解释该模型为何将网页视为网络钓鱼。给定一个良性网页,例如“ https://www.httpspro-afld-amazon2020.cu.ma ”,发现StackModel将其报告为网络钓鱼,因为它的HTML长度小且域名出现率低,即域名出现的频率HTML文本。观察到在OpenPhish数据集中,这两个特征(即HTML代码长度和域出现)是网络钓鱼的重要指标。但是,这两个特征与网络钓鱼意图之间没有因果关系。但是,在网络钓鱼发现实验中,模型学习到的偏差会导致大量误报。总体而言,机器学习模型通常从数据集中了解关联性而非因果关系,这对于将其应用在现实世界场景中是有风险的。
(2)调查误报
接下来,调查了Phishpedia在此发现实验期间报告的误报;这是由于两个原因:(i)基于模板的网站和(ii)带有一些最大和非常受欢迎的公司(例如Google,Facebook或LinkedIn)的logo的良性网站。
基于模板的网站:发现大多数误报归因于某些网站是由网络托管服务(例如https://www.cpanel.net/ )提供的模板构建的。设置后,该网站通常具有一个辅助网站域,例如“ webmail.eventgiftshop.com”。但是,Web管理员保留默认logo,如下图所示。在此实验中,Phishpedia将其报告为网络钓鱼。可以说,鉴于这种网页设计,即使是人类用户也难以确定它是否是网络钓鱼页面。作为一种快速补救措施,可以设置白名单以禁止Phishpedia报告基于Webmail的网页的警告。但是,从安全性的角度来看,此类网站可能被认为具有不良的UI设计,从而为网络钓鱼者提供了构建无法区分的网络钓鱼网页的机会。
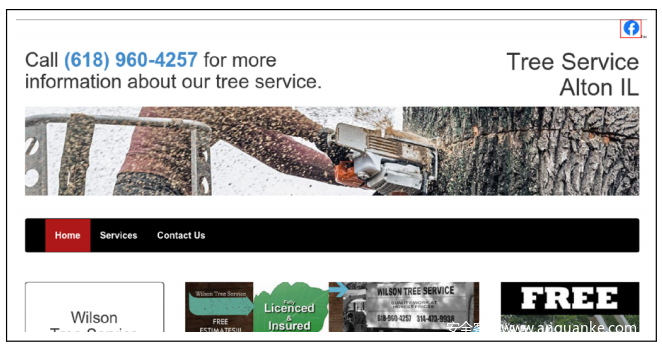
带有大公司logo的良性网站:还观察到,Phishpedia有时会错误地篡改一个带有大型知名公司logo(如Google,Facebook,LinkedIn等)logo的良性网站。称其为Phishpedia的可信网站。出现这些logo是出于广告目的,或者是为了方便注册而使用的单点登录(SSO)。下图提供了两个示例,鉴于一个合理的网站在其屏幕截图上显示了一个大公司logo,Phishpedia可能会将屏幕截图解释为该大公司的页面并将其报告为网络钓鱼页面。
为了进一步评估Phishpedia在这些可能的网页上的表现,还从CertStream收集了131,975个URL,并在具有Google,Facebook和LinkedIn徽标的网页上对Phishpedia进行了实验,结果发现了47(0.036%)这样的网页,并且手动验证确认其中四个是真实的网上虚假网页。在这47个网页中,Phishpedia报告其中有7个是网络钓鱼。精度为47,召回率为4/4。
直观上,Phishpedia对此类网站具有鲁棒性,因为它可以识别identity logo,而不是任意logo。当Faster-RCNN模型报告多个logo时,Phishpedia将使用具有最高置信度的logo。但是,此类网页仍可能导致误报。
(3)调查漏报
本研究还在钓鱼发现实验中调查了Phishpedia的漏报。请注意,很难获得度量召回率,因为只能通过手动验证基本事实,这对于大规模评估而言是费力的。在此实验中,对1,500个CertStream URL进行了采样。评估发现没有网络钓鱼网址。因此进一步使用PhishCatcher选择了1,500个CertStream URL,并在其中确认了16个真实的网络钓鱼网页。以PhishCatcher报告的上述1,500个CertStreamURL的网络钓鱼标签为标准,比较VirusTotal,EMD,PhishZoo,URLNet,StackModel和Phishpedia的准确性和召回率。结果在下表中给出。与其他基准相比,Phishpedia在精度和召回率之间达到了良好的平衡。
0x07 Discussions
A.网页语义
对Phishpedia的愿景是识别网页屏幕快照的语义,以便可以将其呈现的意图与其真实领域进行比较。通过Faster-RCNN和Siamese模型识别身份logo和品牌来实现这一目标。尽管实验显示出令人鼓舞的结果,但语义扫描有时会超出logo域不一致的范围。例如,一个良性网页可能包含Google图标作为其内容,这可能会使Phishpedia感到困惑。
B.应用和部署场景
方案1 URL访问拦截:传递网络钓鱼网页URL的最常见渠道之一是电子邮件。供应商可以使用多种选项来部署电子邮件安全网关。 i)电子邮件中的所有URL被发送到Phishpedia;然后将结果用于对邮件的网上诱骗进行分类或传递给用户。 ii)电子邮件中的每个URL都会进行转换,并以云服务链接作为前缀,因此,每当用户单击链接时,云中的Phishpedia服务都会对该URL进行分析。在这种情况下,Phishpedia可以忽略不计的额外延迟。
方案2 补充网络钓鱼检测器:网络钓鱼也可用于为现有的网络钓鱼检测器提供解释。一个典型的示例是SOC(安全运营中心)的分析人员浏览被多个网络钓鱼检测程序归类为网络钓鱼的URL列表。然后,可以使用网络钓鱼来识别网络钓鱼目标,并在网页屏幕截图上提供直观的说明。
方案3 威胁情报收集:凭借其高精度,Phishpedia可以作为独立服务运行,以在互联网上发现新的网络钓鱼页面。这种实时威胁情报可用于维护动态黑名单,以便用户阻止对网络钓鱼页面的访问。
0x08 Threats to Validity
在实验中,内部威胁是本文重新实现所有基准方法,因为它们的实现未公开。尽管这可能导致无法获得这些模型的最佳性能,但本研究在多个阈值上进行了基准实验。例如,对于LogoSENSE,评估了多个版本并报告了最佳性能的结果。外部威胁是,由于钓鱼网站的伪装,VirusTotal引擎可能会受到不利影响。因此,无法确定改进的检测是来自Phishpedia,还是来自Phishpedia运行的爬虫基础结构。
0x09 Conclusion
在这项工作中提出了Phishpedia,以通过视觉解释来识别网络钓鱼网页。 Phishpedia很好地解决了logo检测和品牌识别方面的挑战性问题。评估表明,Phishpedia在使用真实数据集的实验中表现出比最新技术更好的性能,并且能够发现新的在线网络钓鱼页面。在今后的工作中,将在带有大公司logo的良性网页上解决Phishpedia的误报问题。此外将把Phishpedia扩展到一个在线网络钓鱼监视系统,以收集活动的网络钓鱼工具包,在此系统上应用最先进的程序分析技术来获得对网络钓鱼活动的更多见解。







发表评论
您还未登录,请先登录。
登录