

电子邮件威胁形势在不断发展,即使是运营商级的垃圾邮件过滤器也难以抵御。因此,危险的垃圾邮件可能会到达用户,然后导致破坏性攻击在公司网络中传播。本文描述了一种在大型企业(意大利电信集团,TIM)环境中应用的早期恶意垃圾邮件检测协作方法。在过去两年中员工和安全分析师的共同努力下,收集了大量潜在恶意垃圾邮件的数据集,每封电子邮件都被标记为严重或不相关的垃圾邮件。
通过分析危险电子邮件的主要区别特征,识别出一组包括传统和新颖的特征,然后通过应用通用监督机器学习分类器进行测试和优化。大量实验结果表明,支持向量机和随机森林分类器实现了最佳性能,优化后的特征集只有 36 个特征,实现了 91.6% 的召回率和 95.2% 的精度。对 40,000 多名公司员工进行的实验也证实了这些结果,最后重新设计了电子邮件威胁管理流程,以确保公司网络安全,并提高所有公司员工的安全意识。
0x01 Introduction
电子邮件仍然是最常用的进行网络攻击的渠道之一,使公司经常面临安全漏洞的威胁。这与电子邮件在日常工作生活中的重要性和广泛使用相冲突。赛门铁克的互联网安全威胁报告指出,垃圾邮件的数量正在上升,自 2015 年以来每年都是如此,2018 年收到的电子邮件中有 55% 被归类为垃圾邮件。属于垃圾邮件类别的要么是恶意推销和销售产品的尝试,要么是包含重大威胁的消息,例如网络钓鱼企图窃取凭据或恶意软件传送以进行间谍活动和盗窃敏感数据。
随着此类攻击数量和恶性程度的增加,据估计2019 年美国的经济损失约为 18 亿美元。欧洲网络犯罪中心 (EUROPOL) 声称,在 78% 的网络间谍事件中,电子邮件攻击被用作主要感染媒介。因此,公司 SOC(安全运营中心)和 CERT(计算机应急响应小组)需要大型安全分析师团队,通常称为反网络钓鱼小组,监控这种特定类型的威胁。不幸的是,电子邮件安全威胁的问题越来越具有挑战性,因为每天网络上确实有大量的垃圾邮件,其中夹杂着恶意的电子邮件。 这使得分析师的工作成为真正的“大海捞针”搜索。
构建有效垃圾邮件的技术各不相同,从使用高级策略来逃避垃圾邮件过滤器到复杂的社会工程技术来欺骗人们。虽然垃圾邮件过滤器可以很好地应对由垃圾邮件引起的一些问题,例如网络过载、时间和生产力的损失、恼怒和不适,但它们仍然无法解决电子邮件作为攻击媒介的问题。电子邮件攻击的范围多种多样,从涉及纯技术方面的遗留攻击,由于 SMTP 协议和配置漏洞仍然可行,到更复杂的社会技术现代机器学习和社会工程技术使方法成为可能。
在这些场景中,攻击者的目标通常是传播恶意软件、窃取身份验证凭据或实施金融欺诈。根据目标,攻击可分为:恶意软件传播、(鱼叉式)网络钓鱼、欺诈和诈骗。最危险的是针对特定组织或人群“量身定制”的,并且与通才的策略有很大不同。大公司的员工通常接受过不会被电子邮件攻击企图愚弄的培训,但他们实际上出于各种原因而碰巧,包括大公司拥有各个年龄段的员工,具有不同的教育程度和不同的技术专长和人们缺乏集中注意力来识别网络钓鱼攻击可能至关重要。每个员工都可以成为垃圾邮件发送者和攻击者的切入点。在拥有数万名员工的公司中,每天会收到数百万封电子邮件,其中 55% 是未经请求的。虽然这些未经请求的邮件中有 95% 被垃圾邮件过滤器阻止,但剩下的 5%(每天大约 2.5 万封)仍然是潜在危险的电子邮件数量,数量太大而无法监控。
在这项工作中,垃圾邮件只是一封不需要的电子邮件,研究者对其中的大多数不感兴趣,而是更想了解它们中的任何一个是否造成或有可能造成安全事件:“与安全相关的系统事件,其中系统的安全策略被违反或以其他方式被破坏”。当员工浏览恶意网站或下载恶意电子邮件附件(例如勒索软件、木马等)时,可能会发生安全事件。安全事件会产生不同的影响,具体取决于所涉及员工的数量和角色、威胁的性质以及安全系统(即企业防病毒软件)对它们的抵御效果。将导致或可能导致安全事件的电子邮件称为严重垃圾邮件。由于大公司收到的不请自来的电子邮件数量确实庞大且不断增加,人工分析是不可行的。因此,需要一种自动机制来检测绕过常见反垃圾邮件过滤器的关键垃圾邮件。
本文报告了过去 2 年里意大利电信集团(意大利最大的电信公司)反网络钓鱼小组开展的活动,包括: 构建真实垃圾邮件收集系统;标记数据标签;研究严重垃圾邮件的特征;基于机器学习技术的关键垃圾邮件检测自动化系统的设计、开发和部署;根据获得的见解开展宣传活动。平均每月有 3000 万封电子邮件到达公司员工和外部合作者的 100,000 个邮箱,其中大部分都被垃圾邮件过滤器过滤掉。最初的想法是收集多年来通过垃圾邮件过滤器并被用户报告为不需要的垃圾邮件,同时存储 SOC 分析师生成的有关可能发生的安全事件的信息。为此,设计了一个用于报告和监控此类垃圾邮件的协作框架,其设计目标是收集数据。该框架支持安全分析师的工作,允许他们直接在数据上注释分析结果,从而获得可靠的基本事实。通过这种方法,收集了过去 2 年报告的 22,000 多封独特电子邮件的标记数据集。从数据集的样本中提取了几个传统和新颖的特征。各种机器学习算法已被用于执行二进制分类:严重或不相关的垃圾邮件。已经对基于机器学习的主要分类算法进行了测试和比较,以找到最佳分类算法,包括高斯朴素贝叶斯、决策树、支持向量机、神经网络和随机森林。
结果表明,随机森林实现了最佳性能,精度为 95.2%,召回率为 91.6%,F-Score为 93.3%。已经分析了不同特征集对此类性能的影响。结果表明,从 79 个特征中选择最好的 36 个特征可以获得最佳性能。由于特征的提取成本在相同类型的特征之间分担,因此它们被分组到称为特征字段的集合中.在改变特征字段的数量时还对性能进行了评估:通过使用 8 个特征字段中的 4 个,这导致显着的成本降低,性能(仅)下降5%。特征排名工作还提供了关于如何构建和检测关键电子邮件的重要解释。这些知识导致设计了为期一周的宣传活动,该活动涉及公司所有 40,000 多名员工,包括高级经理和高管。实验证实,系统正确地模拟了网络钓鱼现象,并与训练有素的人员一起代表了一个对大多数电子邮件攻击强大的防御生态系统。
0x02 Collaborative Framework
本节介绍公司垃圾邮件的生命周期。在这项工作的场景中,针对垃圾邮件欺诈的防御采用协作方法:除了商业电子邮件过滤系统之外,还有一个报告收集系统,允许计算机紧急响应小组以保护受影响的用户,这要归功于更有意识/更专业的用户对威胁的识别。这种分布式方法对于检测否则会被忽视的安全事件非常重要。与预防策略一样重要的是,定期开展宣传活动以培训用户识别基于电子邮件的网络攻击,以提高他们的风险意识并教育他们报告此类企图破坏公司的安全。事实上,用户培训在减少他们对网络钓鱼的脆弱性方面发挥着重要作用。通常,当发生安全事件时,会按照相关性递增的顺序执行以下一项或多项恢复操作:
• 向所有涉及恶意电子邮件检测的用户发送通知;
• 在导航代理中添加过滤器以阻止导航或从恶意或其他未知来源下载;
• 修复被任何恶意软件破坏的节点和网络。重置可能已被违反的帐户和凭据;
• 从技术上分析深入的附件和链接,以彻底了解其风险并充分保护受影响的用户;
• 调查攻击者并采取可能的法律行动。
协作框架的目的是识别和解决已经发生的安全事件,并在它们发生之前拦截它们。预测哪些垃圾邮件实际上会产生安全事件可以利用机器学习技术。为每封报告的电子邮件估计和分配准确的风险级别非常重要。传入的报告数量巨大。优先分析他们的分析可以让安全专家只对最相关的调查进行深入调查。下图所示的生态系统允许随着时间的推移收集到达用户的垃圾邮件,并记住其中哪些导致收件人下载附件或浏览链接。该信息直接记录在公司导航代理的跟踪日志中,只有在安全事件的明确可能性的情况下,分析人员才能请求。对这些邮件的分析可以深入了解了最重要的垃圾邮件的主要特征。原则上,即使在用户报告之前,也可以使用未经监督的方法对所有电子邮件的风险评分进行上游估计。然而,鉴于要分析的电子邮件数量庞大,该过程不应耗时。为此,还研究了特征减少对分类性能的影响。
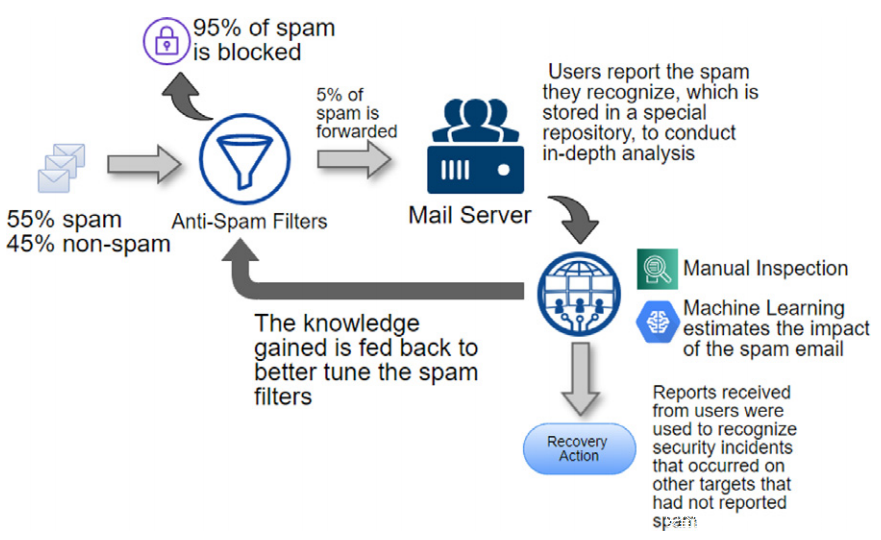
A.数据采集
数据收集系统于 2018 年初启动。从那时起,每当员工收到不需要的电子邮件并决定向安全部门报告时,它就会存储在档案中。根据定义,数据集中的所有电子邮件都是垃圾邮件。有关电子邮件每个元素的大量附加安全相关信息会自动计算并与其一起存储。这是向所有公司的 SOC 提供的典型信息,以便正确管理此类攻击。出于这个原因,数据集高度专业化,信息直接来自现场并迅速提供给分析师。此类信息通常只能通过购买第三方服务(例如信誉服务、沙箱、威胁情报源、黑名单服务等)才能获得。根据这些信息,组成反网络钓鱼小组的特定安全分析师小组,每天检查这些传入的垃圾邮件是否产生安全事件。由于每天都会收到大量报告,因此无法对每个报告进行彻底的安全检查,主要是因为它们中的大多数代表简单的噪音。第一次分类非常重要,因为它允许进行初始过滤,优先考虑需要立即检查的垃圾邮件;然而,这项区分任务不能委派给电子邮件的简单收件人,因为它需要强大的安全专业知识才能执行。
上面提到的安全检查是一系列广泛的检查,例如评估此电子邮件在所有其他用户的邮箱中的传播范围,是否有人点击了恶意链接,是否下载了恶意软件附件,如果某些工作站已被感染,凭据是否已被侵犯等。此外,这些检查还可以包括导航代理的日志分析、工作站上安装的用户代理,有时还包括对电子邮件收件人的采访。最后,分析师发现的所有证据也与垃圾邮件报告一起存储:分析师是否检测到安全事件,以及分析师采取的(可能的)补救措施。这允许分析人员在日常工作中使用数据收集系统对数据进行手动分类和标记。数据集中的电子邮件报告分为两种可能的类别:
• 严重垃圾邮件 – 标签 1,阳性:造成安全事件或至少需要采取防御措施以防止未来感染的垃圾邮件;
• 不相关的垃圾邮件 – 标签 0,阴性:垃圾邮件具有低危险或没有危险,并且不需要任何恢复操作。
通常,数据集 {(x1, y1), . . ., (xn, yn)} 建立后,其中每个样本 xi 由 m 个特征值 < f0, …, fm−1 > 组成并且有一个关联的类 yi ∈ {0, 1}。每天都会收到来自100,000 名用户的数百份报告。其中许多是重复的,因为这些类型的攻击通常在大型活动中执行,这些活动针对同一封电子邮件的许多收件人。排除重复项并且不考虑由于数量庞大而未处理的许多报告,在本工作发布时,数据集包含总共 21,932 个不同的样本:3931 个被标记为严重/阳性,18,001 个被标记为非相关/阴性。该数据集已被用于执行监督机器学习并获得一个分类器,该分类器允许立即识别邮件中包含的威胁。
标记数据集的稀缺性是网络安全环境中的一个已知问题,即使是人类在手动标记数据集时也可能遇到困难,从而加剧了这一问题。在其他情况下,例如识别照片中的狗或猫,与需要强大先验知识的安全分析师标记工作相比,标记任务要简单得多。尽管只有严格的关键和医疗保健环境需要几乎完美的可靠性水平,但认为始终需要对手动标签可靠性进行彻底分析,以确保它不会破坏实验的正确性。由于分类问题集的性质,实际上,人类对样本阳性与否的判断可能是模棱两可的,或者在参与手动标记的各个专家分析师之间可能有所不同。这就是为什么在开始研究之前,本研究决定评估手动标记的注释一致性和评估者间可靠性。
用于衡量标签一致性和评分者间可靠性的主要指标是:一致性百分比和 Kappa 统计量。第一个更传统的方法是通过一致性观察数除以观察总数来计算。它的主要限制是它没有考虑评分者在标签上猜测的可能性;实际上,根据评估者的经验,在案例中,这种可能性很小,但众所周知,所有人都会犯错。 Kappa 统计量旨在考虑猜测的可能性,但它还有其他种类的限制。它是通过以下方式计算的:
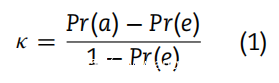
其中 Pr(a) 是一致概率,Pr(e) 是一致可能性概率):
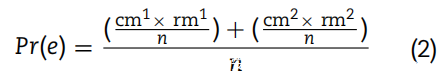
一致性百分比和 Kappa 统计量都有优点和局限性,但简而言之,可以假设前者是注释一致性的上限,后者是注释一致性的下限。为了计算这两个指标,两位分析师(经验最丰富的分析师和经验最差的分析师)被要求在完全独立的会话中处理相同的垃圾邮件报告子集(由 n = 263 个元素组成),以查看他们是否同意标签。评估的要点是对报告的第一眼,当助理决定电子邮件是否有可能造成安全事件时。确定安全事件是否发生的以下步骤由更多标准化程序指导,如 ISO/IEC 27001 标准所定义,基于没有任何自由裁量方法的证据。
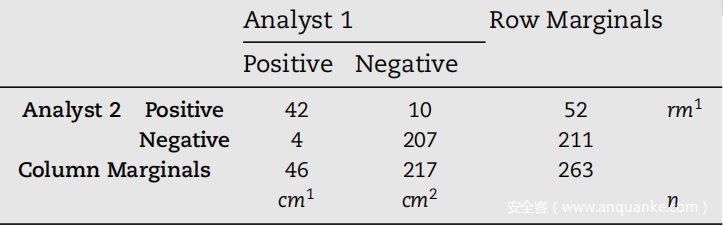
该实验的结果如上表所示。与经验丰富的分析师相比,经验较少的第二位分析师认为更多的垃圾邮件是危险的;他可能会感到不那么自信,更愿意收到误报,而不是忽视潜在的事件。然而,两位分析师对 263 项观察的回应达成了 94.67% 的一致。使用 (1) 计算的 Kappa 统计量应用 (2),为 83.3%。因此,数据集的标记可以被认为是非常可靠的,可以用来训练机器学习模型部署在这个操作环境中。
从报告垃圾邮件时自动收集的原始信息开始,设计了要提取并用作学习模型输入的一组特征。从样本中提取的全套特征列于下表中,包括 79 个特征。这些特征按提取它们的信息的性质或它们被认为擅长区分这两个类的原因进行分组。每组特征称为特征域,将在下面进行深入描述。
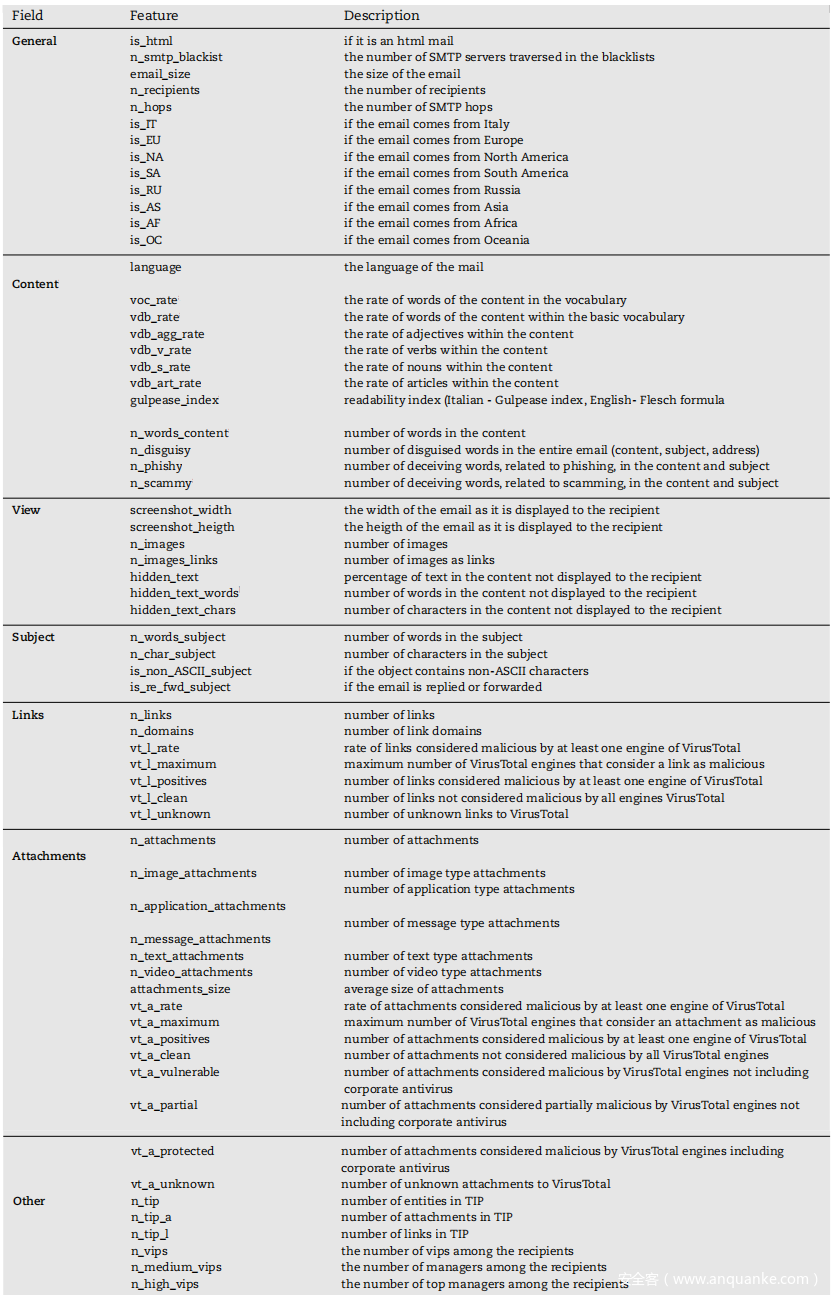
1)General:一般信息,主要是从 SMTP 标头中提取的:如果有任何 SMTP 服务器被列入黑名单、邮件的大小、收件人的数量等,以及所有为提供有关电子邮件来源和目的地信息的特征。
理由:预计这些特征本身不会有很大的区别,但它们可能与其他特征相关。此外,基于来源和 SMTP 路径的电子邮件危险性评估是反垃圾邮件过滤器进行的典型分析,它也可能对分类任务有用。
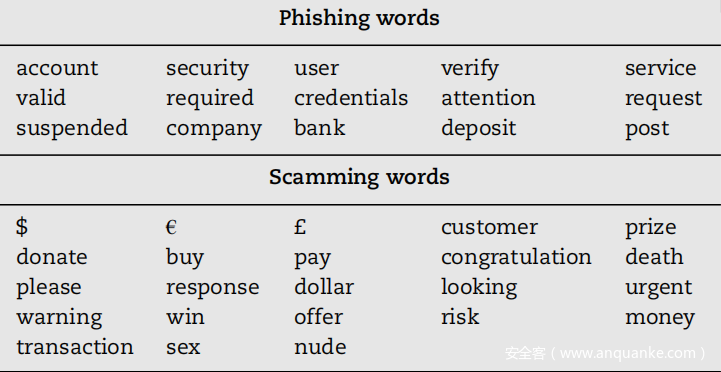
2)Content:从邮件内容中的文本中提取的特征:语言、字数、欺骗性词数、伪装性词数、可读性指标、文本的简洁性和正确性等。 至于“欺骗性词”,以前的研究表明,上表中列出的词是最常用于吸引受骗目标注意力的词。已经手动验证,这在数据集中也是如此。此外,“伪装性词”是指与公司名称、子公司名称、主要合伙人名称等编辑距离为1的词语。所有内容特征也已在使用光学字符识别工具提取的文本上计算,生成 Content_View 特征(如下一个特征字段所述)。
理由:电子邮件携带的实际消息是内容,这也是分析的主要元素之一,以检测攻击的存在并估计其有效性。这是攻击者用来满足研究者认为攻击成功所必需的第一个条件的主要手段:必须说服接收者。这些特征可能允许分类器将收件人立即丢弃的电子邮件与那些诱发错误的电子邮件区分开来,从而对攻击者有利。例如,搜索伪装词很有用,因为与公司通常使用的地址或域类似的地址或域经常被精心设计以欺骗员工。
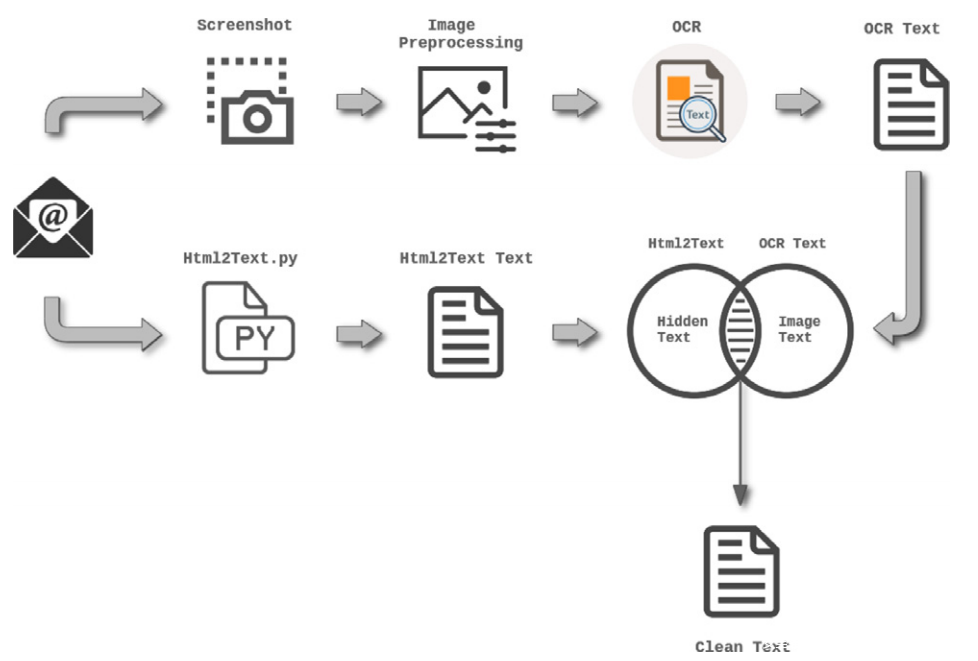
3)View:从显示给收件人的电子邮件屏幕截图中提取的特征:屏幕截图的高度和宽度、图像数量、内容中的文本数量,但收件人未读取的文本数量等。
理由:这些特征已被选择包含在分析中,还包括收件人在打开电子邮件时的认知视觉感知。此外,垃圾邮件发送者经常使用基于 html/css 的技巧将文本注入电子邮件的内容中,弄脏了自动系统对文本执行的所有分析指标,但要避免收件人阅读(例如相同背景颜色的文本、带有“display: none”选项的文本等)。使用光学字符识别 (OCR) 工具提取了几个特征,具有双重目标:检测电子邮件中包含的文本与实际显示的文本之间的差异,作为恶意行为的指标,同时计算电子邮件上的内容特征。收件人实际阅读的文本(生成 Content_View 特征)。特征的提取过程如下:
4)Subject:从电子邮件主题中提取的特征:字数、字符数、是否有非 ASCII 字符、电子邮件是否被转发或回复。
理由:主题行是收件人阅读电子邮件的第一件事,众所周知,它对于所传递信息的交流有效性具有重要意义。 出于这个原因,主题行也有望根据主题的特征在多大程度上可以欺骗收件人相信消息。
5)Links:邮件中的链接特征:数量、链接域数、URL分析服务信息等。
理由:链接可能是邮件中恶意内容的载体,必须仔细分析以量化邮件的数量满足研究者认为攻击成功所必需的第二个条件:攻击的有效载荷不能微不足道。从这个角度来看,依赖来自在线链接和域信誉系统的信息非常有用,这些系统通常可供公司的 SOC 使用。 VirusTotal 已用于此分析(https://www.virustotal.com/gui/home/upload )。
6)Attachments:有关电子邮件附件的特征:数量、类型、大小、来自沙箱和防病毒软件的信息等。
理由:与链接一样,附件可能是电子邮件恶意内容的载体,出于同样的原因,必须仔细对其进行全面分析。来自沙箱和防病毒系统的信息可以提供帮助,尤其是考虑到公司使用的特定系统。
7)Others:其他类型的信息不在前面的字段中:由于威胁情报活动而已知的恶意实体的数量、在收件人公司中的角色等。
理由:与公司密切相关的其他信息也有助于识别比其他信息更相关的电子邮件:收件人或报告人在公司中的角色的战略重要性对于评估可能出现的风险非常有用的妥协。例如:如果被欺骗的员工发送一封包含个人议程或会议信息的电子邮件,则可能不会被视为安全事件。就经理而言,由于他/她所处理的信息非常敏感,因此肯定是这样。此外,来自公司安全部门管理的内部平台威胁情报平台(TIP)的信息也被纳入该领域。
设计的特征集包括传统和新特征,包括以前工作中考虑的信息,但现在已正确转换为 ML 特征,以及公司 SOC 可用但从未用于这些目的的信息。 相信这组特征代表了对该领域的重要贡献。
0x03 Experimental Analysis and Results
可用数据集分为两部分:训练集(85%)和测试集(15%)。训练集用于与模型的选择和优化、其超参数、权重、阈值和特征相关的分析。这些结果已通过 10 倍交叉验证得到验证。测试集用于评估在前一阶段适当调整和优化的模型的实际性能。
A.选择监督机器学习模型
已经训练了几个机器学习模型来执行上面解释的二元分类,目的是选择最好的模型并对其进行更深入的实验。已使用 Scikit-learn 和以下基于 ML 的算法:最近邻、线性支持向量机(Linear SVM)、径向基函数支持向量机(RBF SVM)、决策树、随机森林、自适应Boosting (AdaBoost)、朴素贝叶斯、二次判别分析 (QDA)、多层感知器神经网络 (MLP Neural Net)。这些 ML 模型是根据其他有关垃圾邮件检测的工作所展示的实验选择的。
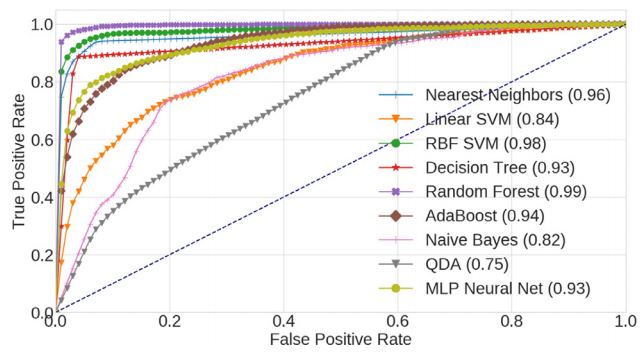
这九种监督方法的分类能力已经通过计算真假阳性率 (TPR/FPR) 进行了测试,使用全套特征作为输入。上图描绘了每个模型获得的接收者操作特征(ROC) 曲线。这些结果是在训练集上通过 10 倍交叉验证获得的。用于评估这些方法性能的指标之一是曲线下面积 (AUC),这表明两种最佳方法是随机森林 (99%) 和 RBF SVM (98%)。随机森林在森林中配置了 140 棵树,在每个节点的随机子集中配置了 8 个变量。RBF SVM 的伽马系数为 0.7,惩罚参数 C 为 5。由于数据集不平衡,单独使用 AUC 无法正确评估性能。出于这个原因,它仅用于最佳模型的初步选择,而以下所有结果均以精度和召回率的形式显示。下一节将详细评估两种最佳性能方法的精度和召回率指标,作为类权重、分类阈值和特征集的函数。
B.调整超参数、类权重和阈值
本节解释了正确调整先前选择的两个模型所采用的方法:随机森林和 RBF SVM。使用 Scikit-Learn 提供的 Ran domizedSearchCV 和 GridSearchCV 函数已自动对此类模型的超参数训练集进行优化。这些函数指定要为每个超参数测试的一组值。在网格搜索的情况下,系统在所有超参数值的所有组合上进行评估,而随机搜索从指定的分布中随机抽取超参数的值,执行预定次数的迭代。超参数的最佳值是通过首先使用 Randomized SearchCV 来确定数量级并缩小要测试的值的范围,然后使用 GridSearchCV 来微调最佳值的搜索来找到的。根据执行的测试,随机森林使用以下超参数实现了 98.5% 的精度和 89.1% 的召回率的最高性能:

RBF SVM 使用以下超参数实现了 92.4% 的精度和 88.9% 的最高性能召回率:

然后使用两个模型的这些超参数值进行后续分析。
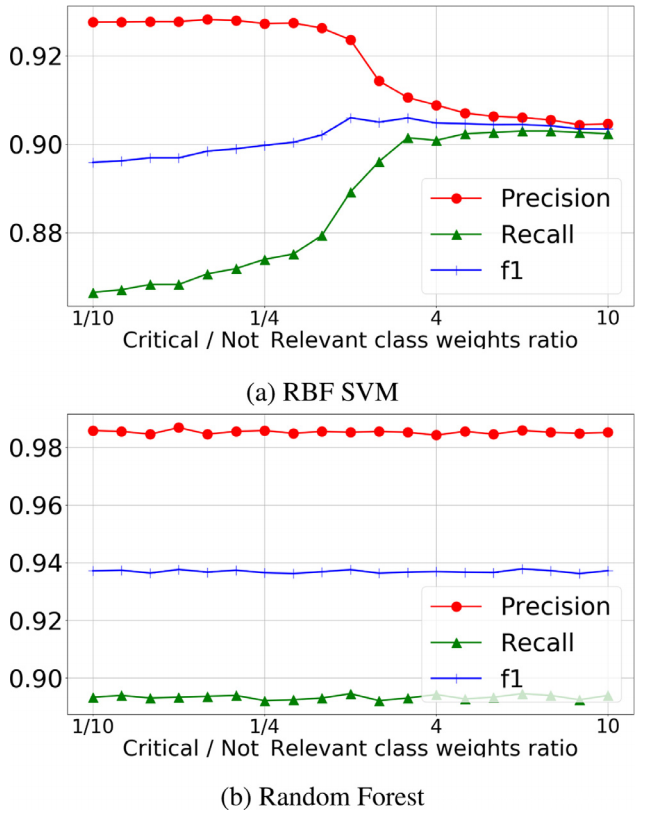
上图显示了 RBF SVM 和随机森林的精度、召回率和 F-measure,改变了分配给两个类别的权重。随机森林在一般情况下具有更好的性能(F-measure 为 93.8%)。另一方面,RBF SVM 以牺牲精度 (90.6%) 为代价获得了更高的召回率 (90.3%)。在某些情况下,RBF SVM 可能更适合最大化召回率(高达 90.3%)并最小化风险。在其他情况下,可能更普遍的是,与精度(下降到 90.6%)的权衡意味着过多的误报。随机森林的 Re call 值略小(高达 89.1%),但精度值要高得多(高达 98.5%)。因此选择的类权重是:
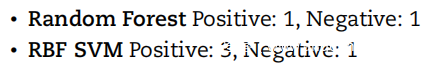
分类阈值已使用上面报告的类权重进行了调整。下图显示了作为分类阈值函数的 RBF SVM 和随机森林的精度、召回率和 F-measure。根据上图,即使在召回率更重要的情况下,随机森林也显示出比 RBF SVM 更好的性能。分析 F-Measure 曲线峰值处的图形,随机森林召回率 (93%) 获得比 RBF SVM 召回率 (88.8%) 更高的值,但保持更高的 精度值(96.5% vs. 93%)。此外,即使是可实现的最佳 RBF SVM 召回率(93.5%)也几乎无法击败之前的随机森林召回率。因此对于本研究,随机森林是最好的监督机器学习模型。 RBF SVM 的最佳分类阈值为 0.525,随机森林的最佳分类阈值为 0.375。
C.特征排名
本节分析每个特征的重要性。已经执行了两种类型的分析:第一种分析考虑每个特征的个体贡献,第二种分析考虑每个特征作为完整特征集的一部分的贡献,因此考虑彼此之间的相关性。第一次分析允许在网络钓鱼攻击的基础上加深认知现象,突出显示与其他垃圾邮件相比对某些垃圾邮件具有重大影响的特征。这些结果是为邮件收件人开展宣传活动的基本指南,培训他们处理他们所表现出的特定认知漏洞。第二个分析更关注技术方面:在所有其他特征的背景下评估每个特征的真实形成贡献可能会导致识别具有最佳分类性能的特征子集。然而,使用较少的特征会降低要执行的处理的复杂性、执行时间和成本。此外,由于冗余信息、数据中的噪声和过度拟合,大量特征并不总是对应于性能的提高。
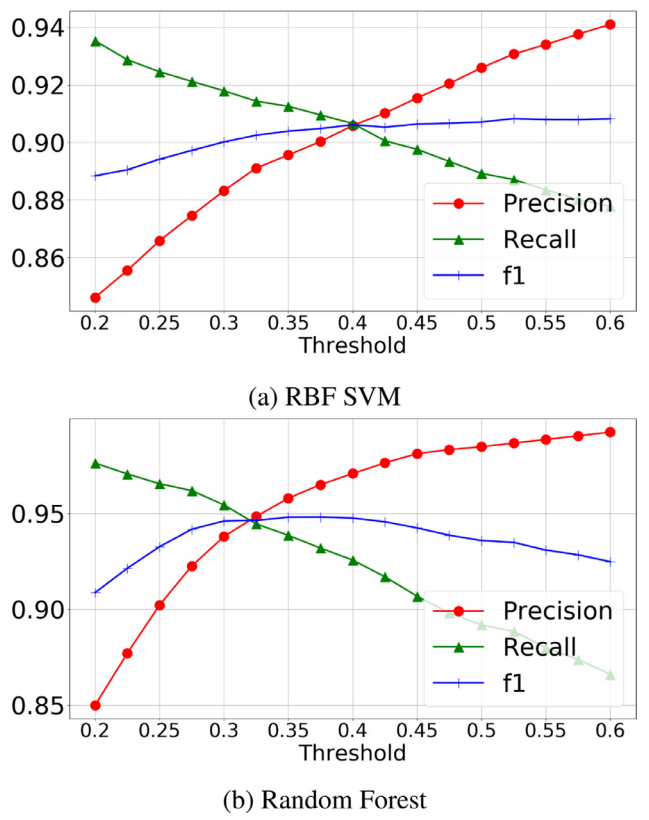
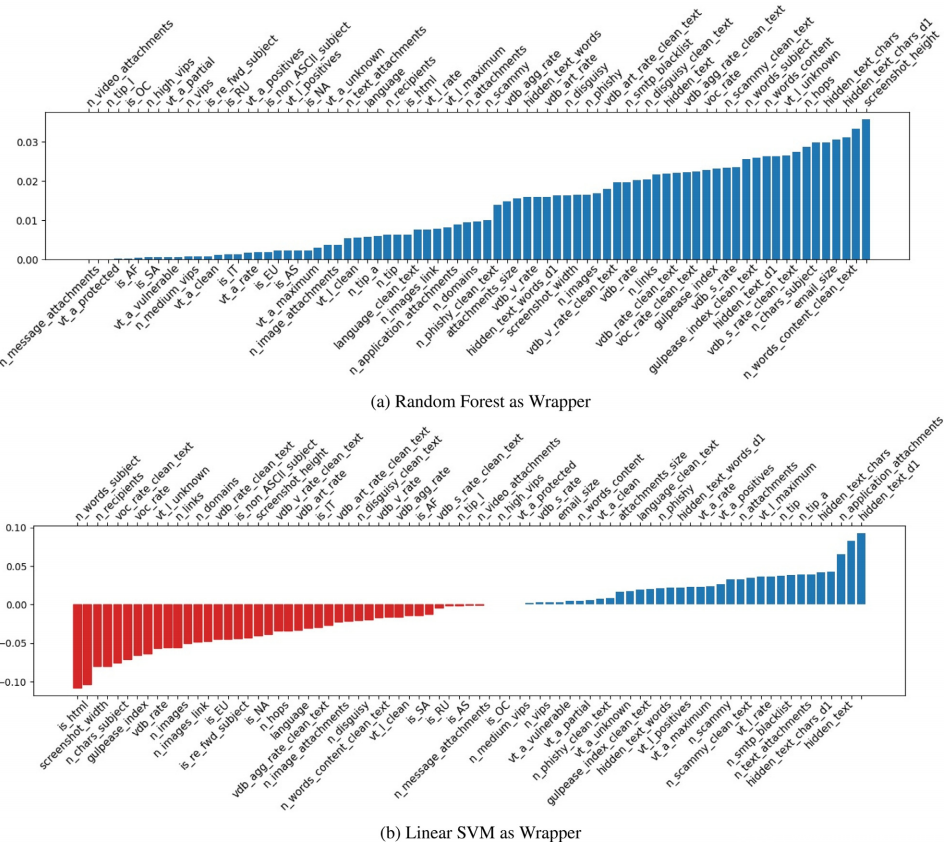
为了估计每个特征 fi 的个体预测能力,已经计算了它与离散(二进制)目标变量 y 之间的互信息。结果如上图所示,表明成功的电子邮件攻击的区别特征主要涉及内容的编写方式。评价标点符号的文本可读性的指标、信息在高度上的分散程度、句法的正确性和简洁程度以及所使用的术语都是非常相关的特征。上图还显示,“clean text”版本中的“Content”特征几乎都比“normal”版本重要。这证实了需要一种方法来识别和隔离注入电子邮件中的隐藏文本。有趣的是,垃圾邮件的来源国并不是识别关键垃圾邮件的判别因素,而与信誉系统相关的特征(如 VirusTotal 和 SMTP 黑名单)以及 SMTP 跃点数提供了相当重要的贡献。
Wrapper 方法已被用于选择特征的最佳子集:它包括使用给定 ML 模型(称为 Wrapper)的预测性能来评估特征子集的相对有用性。在随机森林的情况下,特征的重要性表示该特征对减少基尼不纯度的贡献有多大,这很容易计算。至于 RBF SVM,相反,计算特征的实际重要性是一个复杂的过程,出于这个原因,具有线性内核的 SVM 已被用于计算特征重要性。这些研究的结果如下图所示。由于互信息分析,它们证实了已经发现的内容,还有一些有趣的补充:接收者的数量和主题的单词也与分类相关。此外,如果与其他特征相关,来自威胁情报过程的信息也会变得很重要。
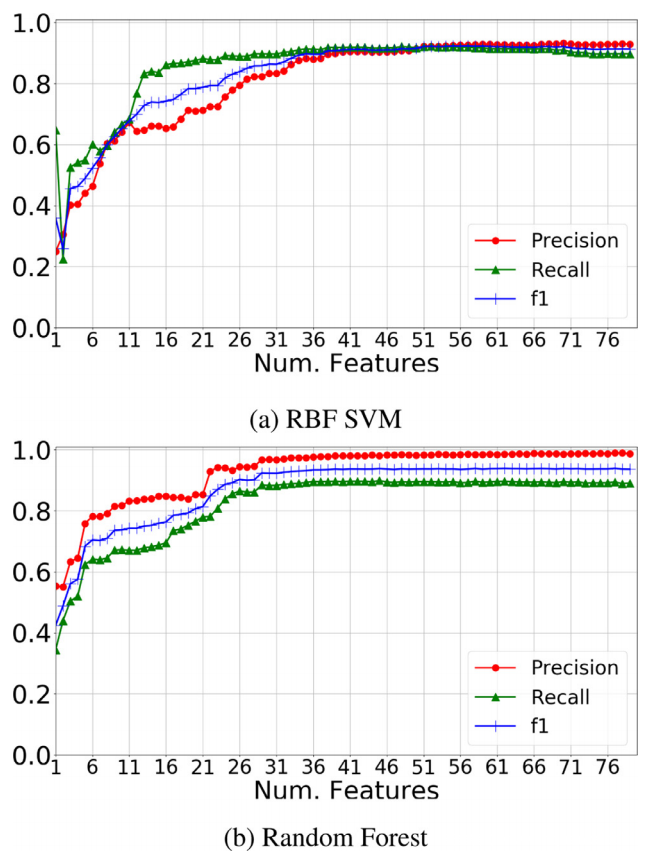
已经评估了特征数量对分类性能的影响。递归特征消除程序已用于此目的。结果如下图所示。在这两种情况下,使用整个特征集都会适得其反:分类器的性能略有下降,而训练和分类时间增加。随机森林和 SVM 的最佳性能分别通过 36 个和 51 个特征实现,而次优性能可以通过 29 个(RF)和 38 个(SVM)特征实现。
之前执行的特征排序过程没有考虑一个重要因素:计算/提取特征的成本。此成本既可以是计算性的(计算特征价值所需的时间),也可以是货币性的(购买资源、购买第三方服务的许可证)。每个特征字段都要考虑特征的提取成本:如果您可以获得某个特征的值,那么您就可以获得该字段的所有特征。因此,上述分析也使用特征域分辨率进行。为此,使用随机森林的 Wrapper 方法一次只使用一个特征字段执行。然后,根据预先计算的排名,评估分类性能,增加特征字段的数量,在每一步添加最好的剩余字段的所有特征。结果如下图所示,表明:
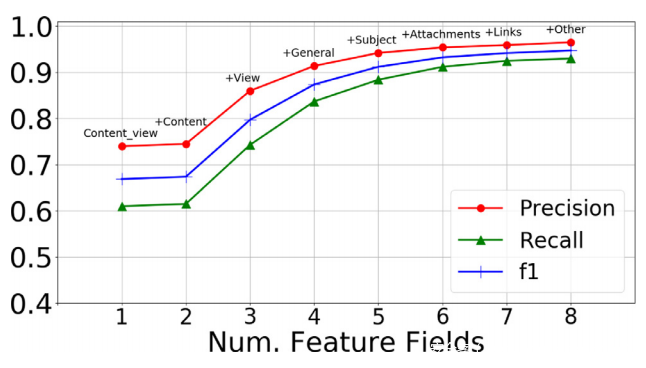
• 正如预期的那样,最好的领域是关于电子邮件的内容和观点的领域,因为它们对受害者有直接的影响。也显示选择“Content_view”时“Content”是多余的;
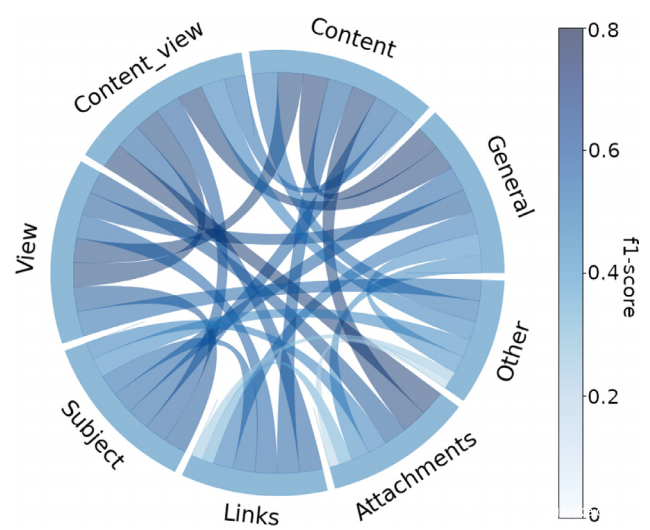
• 因此不考虑Content,四个特征字段就足以获得良好的性能,避免提取所有特征的成本。然而,即使只有两个特征字段也可以满足要求,因此已经对哪个是最好的字段进行了详尽的研究。下图显示了所有可能对的 F1-score 性能:将Content特征与View、General和Attchment中的任何一个结合起来,可以获得具有两个特征字段的最佳性能。对于Attchment尤其如此,这是一个意想不到的结果,因为仅此字段的性能就很差。
D.分类性能
学习算法的性能评估过程需要使用一组在训练和优化阶段从未见过的样本进行最终测试。最终在测试集(之前保留的数据集的 15%)上测试了适当调整的两个模型的分类性能,获得的结果如下表所示。与相比,性能仅低 1-2 个百分点验证阶段。这些最终结果证实了随机森林是实现研究目的的最佳选择,最高 95.2% 的精度、91.6% 的召回率和 93.3% 的 F-Score 达到 36 个特征。
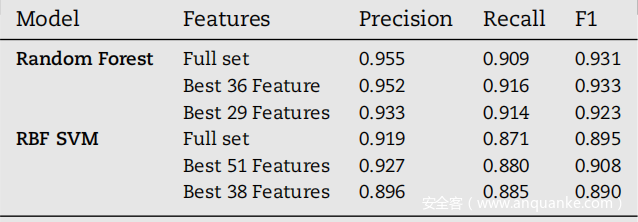
如此令人印象深刻的性能值允许在公司的基础设施中部署自动分类器,将其集成到公司 SOC 的实际电子邮件威胁管理流程中。特别是,分类器会分析 SOC 收到的所有报告,对它们进行优先排序,并向分析人员证明最危险的报告,然后分析人员可以进行进一步调查,以防止可能发生的事件并减轻当前的事件。该集成系统现在可以每天检测一些原本不会被检测到的安全事件。
0x04 Evading the Detector with Adversarial Samples
基于机器学习的分类器的漏洞在以往工作中众所周知。在特定场景中,投毒攻击很难执行,因为训练集中样本的标记是由人类分析师手动执行的。未手动标记的样本不会成为训练集的一部分。另一方面,规避攻击更容易执行,例如,通过网络钓鱼电子邮件对分类器认为重要的特定特征具有扰动值。这些技术对图像分类器非常有效,因为它们过分强调一小部分特征(像素),因此非常容易受到攻击。例如,带有一些篡改像素的熊猫图像在人眼中仍然是熊猫,但对于基于机器学习的分类器而言则不是。
因此,重要的是要了解类似的问题是否也会影响这项工作中提出的分类器。特别是,验证高效的网络钓鱼电子邮件(即很有可能误导人类并损害系统)在其特征受到干扰以使其不再与分类器相关时是否仍然有效非常重要。为此,开展了一项大型实证实验:对公司几乎所有员工(包括高层管理人员和高管)进行宣传活动。越来越远离分类器的积极决策区域的对抗样本已生成为合成垃圾邮件,并在一周的时间跨度内发送给员工。正如下面详细报道的那样,获得的结果表明,一旦样本进入阴性决策区域(因此未被分类器检测到),它们在成功攻击方面变得稍微有效。为此目的而设计的方法如下:
1.从数据集中对正样本进行聚类,以获得成功攻击的代表性样本。从这个过程中已经获得了大约 5 个质心(centroid),并且选择了最适合运行该活动并测量成功率的质心。这样的质心代表使用链接执行的网络钓鱼攻击。使用该样本获得了生成对抗样本的特征向量:
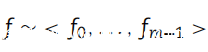
2.为了生成对抗样本,这个特征向量已经被操纵,用扰动δ改变一些特征:
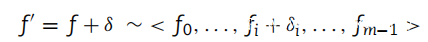

根据其应用的特征在每个操纵中适当地选择扰动的强度,以便无论如何保持攻击的完整性。它始终是特征值的 20% 左右。它们总结在上表中。为了获得一组与分类器相关性越来越低的对抗样本,它们中的每一个都是通过对前一个样本添加新的操作来获得的。无法测试所有可能的操作组合,以避免向公司人员发送过多未经请求的电子邮件。设 C 为聚类得到的起始质心,Si 为对抗样本:
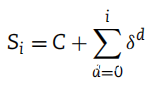
3.获得了代表实验中使用的网络钓鱼模板的七个对抗样本。此类合成电子邮件发送给总共 41,154 人,其专业知识、教育程度和年龄各不相同。每个钓鱼模板随机发给5879人,目的是衡量每个模板的成功程度。
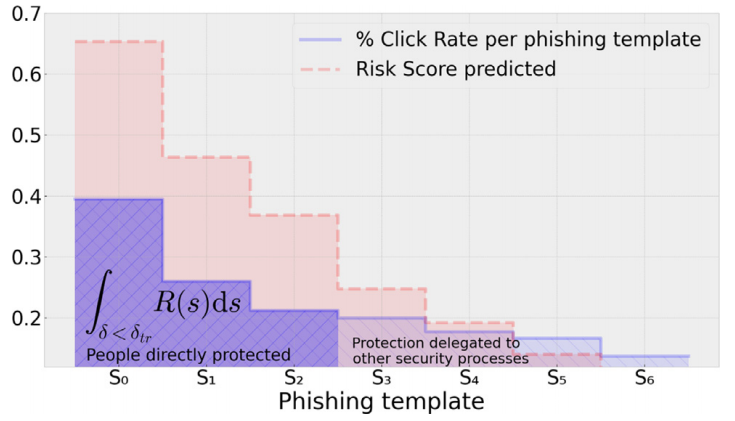
以这种方式设计的实验产生了如上图所示的结果,它突出并证实了:
• 随着扰动的增加,属于阳性(风险评分)的概率会降低。
• 随着风险评分的降低,网络钓鱼模板的成功程度也随之降低。这意味着分类器正确地对现象建模。
• 特征的更改会导致点击率与其重要性成正比的下降。对最重要特征进行的第一次更改比后续更改更能降低风险评分。
这种分析可以确定最佳风险评分阈值(或 δtr 扰动阈值),以便对垃圾邮件报告的分析进行优先级排序。 对于该阈值的每个值,代表 SOC 可以在此任务上提供的工作量,检测到的可能安全事件的数量最大化,最小化那些未被注意到的安全事件。 这是非常重要的,因为不可能检查所有此类报告,并且为了不为那些不危险的报告浪费太多精力。
0x05 Discussion and Limitations
通过本文方法可以自动区分收到的未经请求的电子邮件是否代表攻击,并准确估计其成功的可能性。通过这种方式,可以帮助反网络钓鱼分析人员将其有限的资源用于最危险的网络钓鱼攻击。下面讨论了本文方法和攻击者可能采用的规避策略的局限性。
A.分析不可行性
由于模型基于复杂的特征,通过长时间的计算和使用许可的第三方服务提取,由于货币和计算限制,不可能将这种深入的安全分析扩展到所有收到的电子邮件,每天数百万封. 特征排序部分显示了特征减少仍然可以节省大部分预测能力的可能性,从而能够对更多样本进行计算。不幸的是,如果电子邮件未被报告为可疑,那么由于隐私问题,通过分析师手动标记电子邮件来构建基本事实是不切实际的。在未来的工作中,将使用无监督方法将分析扩展到所有电子邮件。监督方法因此建立在用户报告的基础上,从而引出下一点。
B.用户依赖性
本文方法在很大程度上依赖于用户报告,这导致反网络钓鱼小组参与到可能收到的攻击中。用户参与识别网络钓鱼嫌疑人至关重要,因为它会预先过滤公司收到的全部电子邮件并选择候选人进行彻底的安全检查。因此,拥有大量了解这些安全方面的用户是实现一种保护自己和整个公司的群体免疫的重要要求。考虑到这一点,能够根据最近影响用户的安全事件设计有效的意识活动非常重要。从可解释 AI (XAI) 的角度来看,特征重要性的结果突出了最具影响力的电子邮件攻击的特征,为根据用户的精确漏洞定制用于意识活动的合成电子邮件做出了决定性贡献,正如上面所进行的实验所证明的那样。
C.单一受害者缺乏保护
本文方法缺乏对单一目标成功攻击的可见性,因为反网络钓鱼分析师只有在收到可疑网络钓鱼电子邮件的至少一名用户报告时才会参与。这实际上是一种罕见的可能性,因为为了增加成功的可能性,这些类型的攻击几乎总是在适当的网络钓鱼活动中由多个收件人发起。然而,在攻击单一受害者的情况下,唯一的可能性是再次让用户接受培训以识别这些类型的威胁,尤其是那些最容易成为网络钓鱼广告攻击目标的人(例如高层管理人员、高管及其密切合作者),还可以采用基于客户端的工具来支持个人用户识别网络钓鱼。
D.监督学习缺陷
尽管这项工作已经解决了监督方法的主要限制-即需要获得标记数据集,但还有其他众所周知的缺陷需要讨论。这些包括数据集中的类别不平衡;这是在电子邮件安全分析设置中使用监督方法导致的问题之一,它表现出极端的类别不平衡(以百万比一的数量级)。然而,特定处理方法只处理可疑的网络钓鱼报告而不是所有收到的电子邮件,将类不平衡大大降低到 4.5 比 1 的数量级。此外,某些子类型在阳性类中表现不佳的攻击可能是错误分类,对召回性能产生负面影响(约 90%)。最后,监督式方法无法检测网络钓鱼攻击的 0-day 。
0x06 Concluding Remarks
电子邮件攻击是后续攻击实施的常用工具,是影响所有行业并造成重大危害的重大威胁。反垃圾邮件过滤器并不能解决垃圾邮件的网络攻击问题,垃圾邮件仍然成功传播恶意软件、窃取机密数据并产生巨额非法利润。出于这个原因,公司通常依靠安全分析师团队对此类电子邮件进行人工检查。然而,逃避垃圾邮件过滤器的垃圾邮件数量太多,特别是在大公司的情况下,此类分析无法有效,本文旨在为这一重要问题做出贡献。
本研究在2018 年初建立了一个协作框架,通过分析师的持续监控,收集垃圾邮件并支持将实际危险的邮件标记为关键。使用这个标记数据集,表明机器学习算法可以很好地突出威胁。本文还确定了使垃圾邮件变得危险的主要特征以及防御所依赖的最佳技术。本研究既使用了传统特征又使用了新颖特征,并且评估了它们与目标的相关性和相关性。使用最大化 f1-score 性能的最佳特征集,监督方法达到 95.2% 的精度和 91.6% 的召回率。本文还确定了一个简化的特征集,可以大大降低成本,而对性能的影响很小。还通过涉及公司 40,000 多名员工的大型实验研究了使用对抗性机器学习技术规避这些分类器的可能性,确认所使用的算法正确模拟了电子邮件危险性的认知现象。
通过获得的结果,本公司围绕这种协作方法重新设计了电子邮件威胁管理流程。它现在依赖于报告可疑电子邮件的经验丰富且有意识的用户、自动数据收集和分析系统以及根据系统建议进行深入调查的安全分析师。应用该系统产生的部分IoC也发布在本公司的威胁情报平台上,以提高公司的整体安全防御。一般来说,使用这种系统与现有的安全流程协同工作有助于缓解长期存在的电子邮件攻击问题。本研究贡献可以提高对公司面临的风险的认识,最重要的是在报告系统和托管安全服务的背景下,自动检测垃圾邮件中的威胁。







发表评论
您还未登录,请先登录。
登录