

在上篇文章中我们实现了最简单的Fuzzing工具,这次我们就在之前的基础上,实现第一次“升级”,同时也给大家分享一些我个人的经验,让大家能够定制自己的fuzzing工具。
文中有一些概念是笔者自己提出的,都给出了大家能理解的解释,但是不够正式,大家使用的时候要注意一下,采取更正式的用词。
代码覆盖率
相信看这个系列文章的朋友们大多都应该有使用fuzzing工具的经验,fuzzing中最有名的工具之一 American Fuzzy Lop fuzzing(也就是我们常说的AFl fuzzing),其核心思想就是尽可能提高代码覆盖率。所谓代码覆盖率就是你走过的代码和所有代码的比值。比如下面的例子:
if a == 10:
print(a)
else :
print(b)
假设a是我们的输入,当我们的fuzzing输入了11时,那么我们走过的代码就是第一行、第三行、第四行,代码覆盖率是3/4,如果fuzzing进行了11、10两次输入,那么我们的覆盖率就到了100%。我们的代码覆盖率越高,就说明我们对程序的测试越全面。
当然,我们上面举的例子是在已知源代码的情况下进行,我们一般叫这样的测试为white box,这种测试往往聚焦于对程序进行全面完整的测试,比如我们上一篇文章中替同学修改代码,就是完整甚至带有大量冗余的去思考代码的问题;除了white box,实际上还有black box,也就是没有源代码,直接扔给你一个程序去进行测试,这样的难度一下子就高了,目前对于黑盒的fuzzing一般有两种思路:一种还是去想办法提高代码覆盖率;另外一种是通过各种手段去进行边缘化测试。
实际上AFL fuzzing对白盒、黑盒测试都是采取提高代码覆盖率的方式来进行fuzzing,但是两种实现方式大相径庭,前者我们可以直接在源代码使用插桩技术,简单说就是在编译过程中给源代码打个标,只要检查这个标有没有动过,即可知道程序是否运行了该段代码;而对于黑盒测试,AFL只能使用qemu模块对二进制程序进行插桩,这种插桩不再是源代码级别的,粒度更小,而且由于是“虚拟化”技术,开销和技术难度要比前者高得多。
考虑到难度因素,我们就先来看看white box的情况,后者先按下不表。
追踪代码
我们先来看一段fuzzingbook给的例子,这次我们继续邀请舍友Z当作嘉宾,假设这是他的面试程序,我们的任务还是对他的程序进行fuzzing测试
def cgi_decode(s):
hex_values = {
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,
'5': 5, '6': 6, '7': 7, '8': 8, '9': 9,
'a': 10, 'b': 11, 'c': 12, 'd': 13, 'e': 14, 'f': 15,
'A': 10, 'B': 11, 'C': 12, 'D': 13, 'E': 14, 'F': 15,
}
t = ""
i = 0
while i < len(s):
c = s[i]
if c == '+':
t += ' '
elif c == '%':
digit_high, digit_low = s[i + 1], s[i + 2]
i += 2
if digit_high in hex_values and digit_low in hex_values:
v = hex_values[digit_high] * 16 + hex_values[digit_low]
t += chr(v)
else:
raise ValueError("Invalid encoding")
else:
t += c
i += 1
return t
CGI其实是web相关的知识,程序功能是模拟对url的解码功能,主要流程是:
- 循环检查输入的字符串的每一个字符
- 如果是+号,就替换成空格
- 如果是%号,就将其和后两位视为url code,也就是我们在地址栏常见的%xx格式,并转变为对应的字符
- 如果不是上面两种情况,就直接保持原样
- 最终返回新的字符串
接下来我们需要编写我们追踪代码的函数了,我们需要python的sys.settrace()函数来实现,这是python的插桩常用技术。
import sys
coverage = []
func = set()
def traceit(frame, event, arg):
if event == "line":
global coverage
function_name = frame.f_code.co_name
lineno = frame.f_lineno
coverage.append(lineno)
func.add(function_name)
return traceit
我们需要自己编写一个traceit函数作为参数传入sys.settrace(),它就会在执行的过程中,以行为单位调用我们的traceit函数,它要指定三个参数,三个参数会分别保存着当前执行代码的关键信息。
- 其中frame是我们要用到的最关键的变量,它保存着对应的代码行号、对应代码所在的函数名、函数当前的局部变量、参数等等
- event即事件变量,表明当前所进行的操作,如果是普通的代码就是line,如果是函数调用就是call
- arg表明参数
sys.settrace(traceit)
cgi_decode(s)
sys.settrace(None)
print(coverage)
调用过程如上,我们打印出对应的coverage来看看
[8, 9, 10, 11, 12, 15, 16, 17, 18, 19, 21, 30, 31, 17, 18, 19, 20, 31, 17, 18, 19, 21, 30, 31, 17, 32]
可以看到我们确实是拿到了调用的代码行,我们只需要拿它去除以我们总的代码数,即可得到代码覆盖率,但因为实际上还要进行一步除法,有些麻烦,我们也经常用代码覆盖量的概念,实际上就是我们输出的东西,即执行过的代码的数量,同样是越高越好,之后文章中我们会使用代码覆盖量的概念。
当然,我们还可以包装一下这个函数,让他更好用一些。相信大家都知道python的魔法函数,我们先将上述的代码包装为class,当我们去调用如下的代码时:
with Coverage() as cov_plus:
cgi_decode("a+b")
在对象在被创建时,会调用__init__函数来初始化对象的一些设置,而执行的最开始会调用__enter__函数作为入口,结束时则会调用__exit__函数进退出的收尾工作。所以我们可以在class中定义如下函数来实现简单的追踪代码:
def __init__(self):
self._trace = []
def __enter__(self):
sys.settrace(self.traceit)
return self
def __exit__(self, exc_type, exc_value, tb):
sys.settrace(None)
def coverage(self):
return set(self.trace())
好了,准备工作都完成了,让我们来测试一下我们的fuzzer生成的字符串能达到怎么样的代码覆盖情况吧
population = []
for i in range(100):
population.append(fuzzer())
all_code = []
coverage_code = set()
for s in population:
with Coverage() as cov:
try:
cgi_decode(s)
except:
pass
coverage_code |= cov.coverage()
all_code.append(len(all_coverage))
all_code就表示在100次调用后,我们总共执行了多少行代码,我们简单打印一下
[16, 18, 18, 18, 19, 20, 20, 20, 22, 22 ...]
可以看到我们的代码覆盖率不断提高,最终稳定下来。通过次数的堆积,可以达到不错的覆盖率,但是这样有两个问题:
- 大量fuzzer生成的输入对代码覆盖率的提高没有贡献,效率严重不足。读者可以自己编写代码查看每一次fuzzing的路径(打印行号即可),你会惊讶的发现百分之90以上的输入都是同样的路径,其实我们很多输入都走向了一个分支,比如我们上一篇文章中的bc程序,如果你总是这样毫无逻辑的随机生成,就会大量进入parse error这样的错误分支。
- 对于给定的格式不敏感。比如程序要求输入一个url,实际上我们应该在url标准格式的基础上进行随机生成才有可能进入代码的核心部分,但我们随机生成的格式没有“记忆性”,只是偶尔猜对了才进入了核心代码,这显然是有点憨。
两个问题归根结底就是我们没有利用程序反馈的信息对fuzzer进行调整,永远是一个lv1的史莱姆,你说对手不还手的话,理论上lv100的龙我们也可以一点点磨死,但是玩到游戏公司倒闭你都不一定完事。我们接下来就要想办法来改善这些问题。
变异
变异是现在fuzzing工具非常重要的一环,它的作用简单来说就是对某些字符串进行微调,得到新的字符串。这样说可能不太明白,让我们来举个例子:
def http_program(url):
result = urlparse(url)
if result.scheme != 'http':
return False
if result.netloc == '':
return False
print("hello world")
print("假装我是核心代码")
print("假装我是核心代码")
print("假装我是核心代码")
print("假装我是核心代码")
return True
程序接受一个参数,并调用urlparse函数进行url的分割,检查协议是否为http,并检查网络地址是否为空,如果通过检查可以进入核心代码。可以看到,如果我们的fuzzing生成不是指定格式的输入,那就毫无价值,代码覆盖会一直很低,所以我们要让我们的fuzzer自动“学习”,学到对应的格式,再在格式上做“变异”,进而测试核心代码。
那么怎么让我们的fuzzer学习到这样的格式呢?其实很简单,就是利用我们上面说的代码覆盖的知识,思路如下:
- 生成多组fuzzing输入,记录输入与对应的代码覆盖数
- 找不同,找到代码覆盖最高的fuzzing输入作为模式
- 在模式上进行不同力度的“变异”,继续输入并记录代码覆盖数
- 检查“变异”后数据的代码覆盖数,选择合适的“变异”力度
相信前两部分大家看了上面的代码很容易写出来,为了节约篇幅代码我就不放了,我们来重点看后两部分。
假设我们现在已经找到了代码覆盖率最高的输入是,我们叫它模式
http://^&*^&*adafaf
我们可以怎么对它进行改变呢?其实不外乎就是增删改三种方式:
- 随机找一个位置,插入随机的字符
- 随机找一个位置,删除对应位置的字符
- 随机找一个位置,随机改变对应的字符
def delete_random_character(s):
if s == "":
return s
pos = random.randint(0, len(s) - 1)
return s[:pos] + s[pos + 1:]
def insert_random_character(s):
pos = random.randint(0, len(s))
random_character = chr(random.randrange(32, 127))
return s[:pos] + random_character + s[pos:]
def flip_random_character(s):
if s == "":
return s
pos = random.randint(0, len(s) - 1)
c = s[pos]
bit = 1 << random.randint(0, 6)
new_c = chr(ord(c) ^ bit)
return s[:pos] + new_c + s[pos + 1:]
我们每次可以随机方式来对模式进行修改,至于修改的次数嘛,就是我们说的力度了,你可以先设置一个力度进行测试,根据返回的代码覆盖量,再对力度进行调整,比如
for i in range(10):
print(repr(mutate("http://^&*^&*adafaf")))
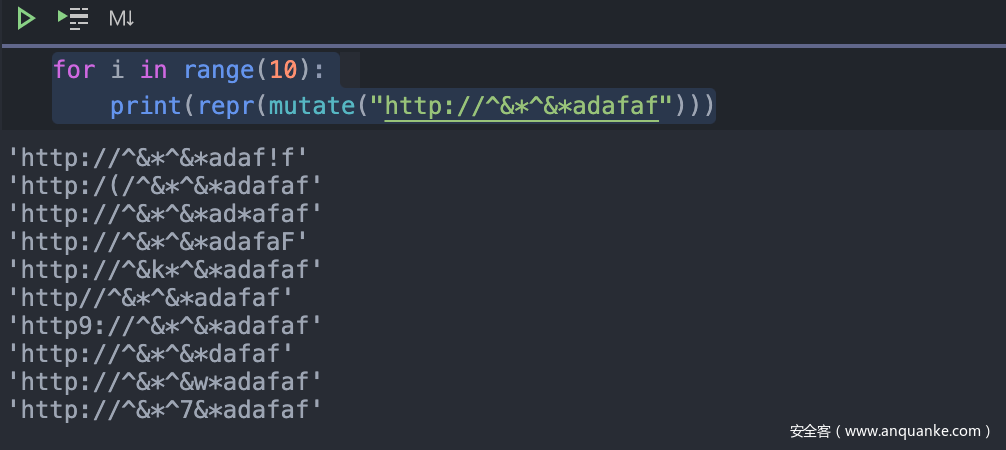
可以看到还很多字符都是符合要求的,大大提高了我们测试程序的效率。我们可以尝试继续提高力度,比如将迭代次数上升到100次,期间要不断的统计代码覆盖量,最终稳定在一个合适的区间。
我们接下来就可以进行封装了,可以书写一个专门的mutation_fuzzer类,继承我们之前的fuzzer类,并添加乳上几个functuin即可。详细的代码大家可以自行书写,要注意这里我们最好也构造一个对应的mutaton_runner类来辅助进行一些工作(比如代码覆盖量统计、初始化list等工作),这样代码书写起来比较容易。
模式迭代
这一部分的内容是我根据自己的经验得到的一套方法,因为涉及到我们小组的内部工具,所以就不放代码了,可以给大家简单说一下思想,其核心就是构造最优模式。下面介绍的两种方法思路都是源自我的一篇文章,工控安全入门(九)——工控协议逆向初探,这篇文章中的Netzob工具通过对大量的流量包进行对比学习,猜测出对应协议的字段的划分,我们同样可以用这样的方式来处理我们的模式。
还是以上面的http_program为例,我们通过上面的技术已经找到了一个模式来生成优质的fuzzing输入,但是显然这个模式距离最优还是有差距,生成的还是有大量的无效输入,我们可以通过一些技术来继续改进。
首先是对模式进行“”对比“,我们可以对改进后输入再次记录代码覆盖量,选择其中代码覆盖量最大的一些字符串(虽然说是一些,但是实际上这个数量是很恐怖的),进行“比较”操作,比如说是最简单的异或,找到其中相似的字符,进而构造新的模式,再不断的重复这个过程,直到找到构造出的fuzzing输入的代码覆盖量都在一个比较高的范围。过程如下:
- 生成输入,记录输入的代码覆盖量
- 筛选代码覆盖量高的字符串,与模式进行匹配,找到新模式
- 重复操作
可以看到这种方式关键就是字符串匹配的问题,如果套用传统的字符串匹配算法,显然是不适用的,因为我们想要的只是一个模式,一个模版罢了。如果匹配过多,就会导致模式僵化,起不到fuzzing的作用了(比如你生成的模式是”https://www.anquanke.com/“,你变异的力度不够大的话就会卡死在一条路径上);如果匹配较少,那还是会有效率低下的问题。所以需要大家自己去探索一套合适的匹配算法。
第二种方法是我们可以对找到的模式进行切分,我们找到大量的候选模式后,找到模式僵化的字符串,我们可以对字段进行不同力度的切分,比如https://www.anquanke.com,它的长度是24,那我们开始就可以以12为长度,我们叫这个长度为粒度,根据这个粒度将其划分成两个模式,然后分别用其他字符填充,就变成了下面:
https://www.xxxxxxxxxxxxxxx
xxxxxxxxxanquanke.com
分别用两种子模式进行大量测试,找到代码覆盖量较高的子模式。接着再原模式的基础上进一步拆分,比如以6为粒度,不断找到最优的子模式,然后对子模式进行“组合”,找到去往关键代码的字段信息。
要注意的是随着粒度的缩小,代码覆盖量肯定不会是单调函数,所以我们需要通过一些技巧找到合适的粒度,然后再对粒度对应的模式进行组合,这是这种算法最难的部分,也是大家最容易自由发挥的部分。
路径问题
上面我们提到的例子都是核心代码堆在一起,假设只有一条路径正确的情况下进行的,实际上程序不可能这么简单,我们还需要对程序的路径进行探索,比如下面的例子:
if url == 'https://www.anquanke.com':
print("我是核心代码1")
else:
print("我是核心代码2")
显然我们简单套用上面的代码覆盖率是行不通的,我们会在两种核心代码的覆盖率上陷入“混乱”,甚至最终算不出模式来;我们也不可能找到非常有效的模式来同时生成测试两段核心代码(覆盖的情况多了,效率必定是要低的)。shellphish的driller(主要是采用了AFL fuzzing技术)采取了angr(一种符号执行工具)作为辅助手段来进行路径探索,文章到这我们还解决不了这个问题,但是我们可以试着提出一种思路:
- 采用某些手段(比如angr),找到通往核心代码的路径
- 为每一条路径设置模式
- 进行测试
可以看到,在这种思路下,代码覆盖率是完全可以用在多路径问题上的,所以我们上面的思路完全是可以继续沿用的。当然我们现在还解决不了这个问题,在之后的文章中,我们再来考虑这些。
总结
这篇文章中我们提高了fuzzer的“效率”,让fuzzing工具变得更加“智能”了,可以说是进化到了LV2的史莱姆,但是我们也看到,fuzzing工具还是有很多问题需要解决,之后的文章中我们将继续走下去,慢慢养成我们的fuzzing史莱姆。







发表评论
您还未登录,请先登录。
登录