

作者:houjingyi
前言
先说一下样本是我在2017年分析的,2019年我又完善了一下用到的反混淆脚本。我做过一年多的样本分析,也没有分析过比这更复杂的。
1.ESET的分析:https://www.welivesecurity.com/wp-content/uploads/2018/03/ESET_OceanLotus.pdf
样本分析的很详细,不过只提了一点点样本混淆的手法,也没有提怎么做反混淆。
2.checkpoint的分析:https://research.checkpoint.com/deobfuscating-apt32-flow-graphs-with-cutter-and-radare2/
主要就是讲怎么做反混淆,开源了一个Cutter和Radare2的插件,能去除一些混淆。没有对样本进行分析。
我当时自己是写了一个基于capstone的python反混淆脚本去除垃圾代码并还原控制流,虽然代码写的很烂,用的方法也很烂,但是自己也不会再做这方面的工作了,与其烂在硬盘里不如和大家分享一下。时间有点久,有些东西记不清楚了,正文里面如果有说错的地方希望读者能多多包涵。
这里先说一点题外话。以前刚刚干这一行的时候听别人说安全是一个体力活,是人与人之间的对抗。当时不懂,后来才好像有一点理解是什么意思。比如说做样本分析,在样本分析师和样本的作者水平相同的情况下,样本的作者用了10天的时间一共x种方法混淆这个样本,样本分析师想要完全反混淆去还原这个样本就要一个一个去还原这x种方法,花的时间一定是大于10天的(当然样本分析师通过经验积累能越来越熟练)。如果一个CTF比赛,出题人花几周甚至更长的时间用了很多种混淆方法写一个壳,做题的人需要在几天的时间内拿到flag,那不出意外也没有人能做出来。
正文
接下来讲解一下反混淆脚本的流程。
首先capstone会把switch的jumptable识别为代码,所以我在脚本中标记了这些jumptable的地址。


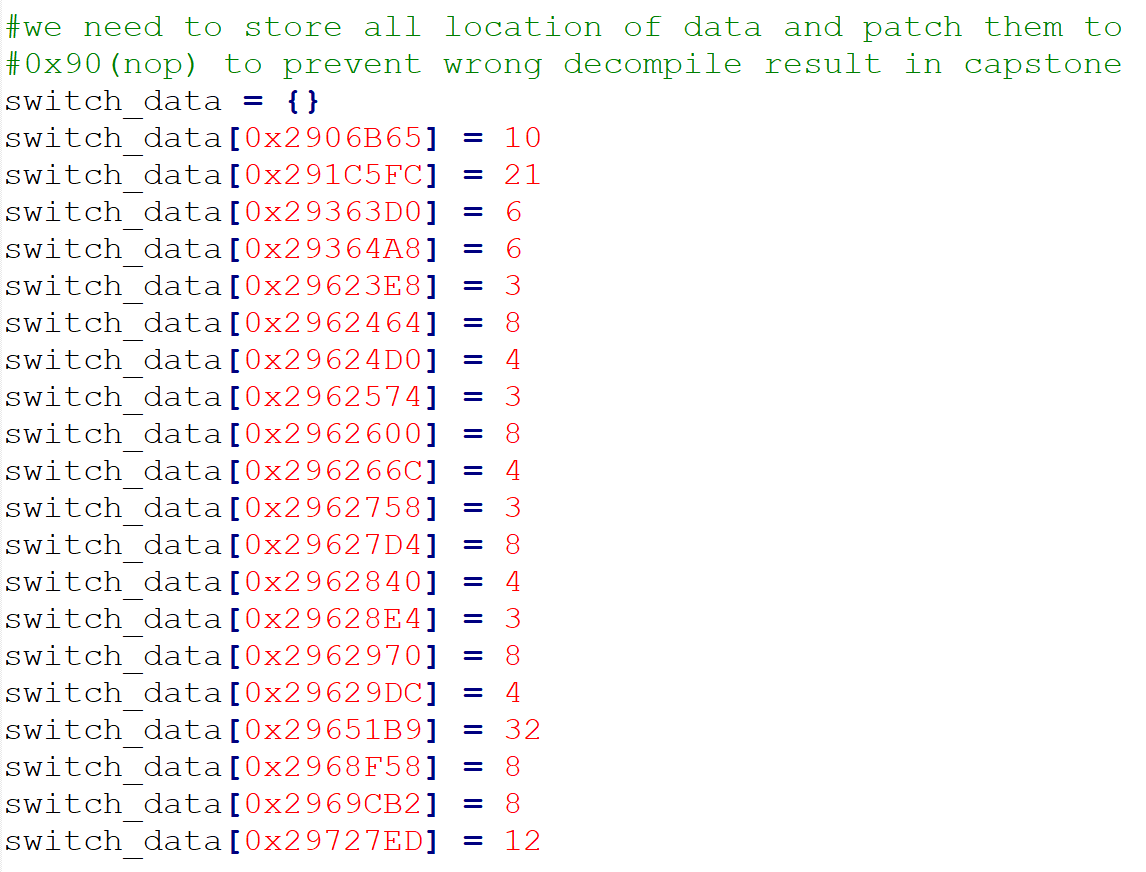
将jumptable全部patch成0x90,调用capstone的disasm方法反汇编,将结果保存在名为read_code的dict中。dict的key是指令的地址,value记录了指令的长度,上一条指令的地址(第一条指令上一条指令的地址是0),指令的地址,指令的内容,指令的操作数和指令的助记符。并且为了方便我将所有jmp eax这样jmp一个寄存器的指令中的jmp改成call。

样本中插入了很多像下面这样的垃圾指令:
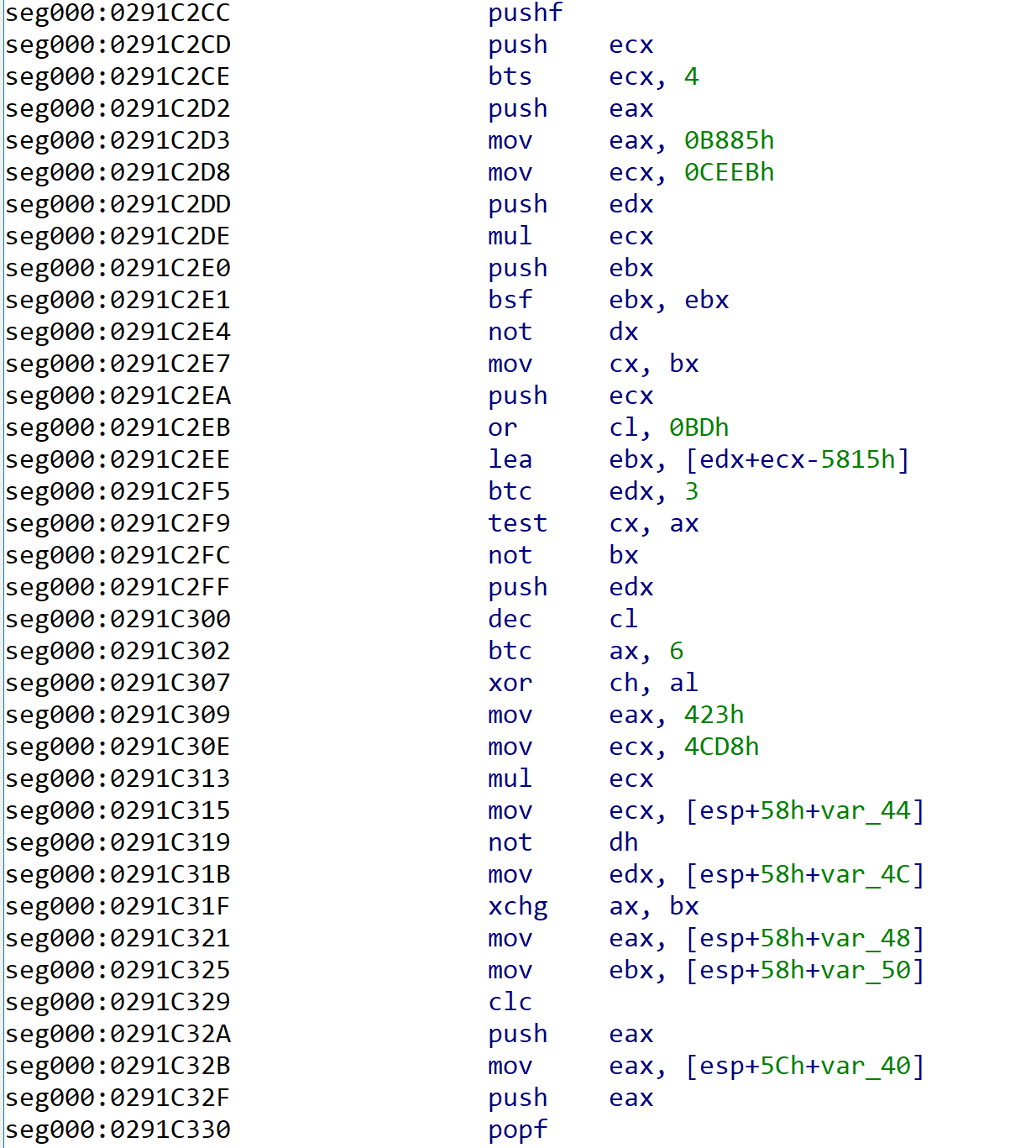
有pushfd+垃圾指令+popfd这样的,也有pushfd+垃圾指令+popfd+垃圾指令+popfd或者pushfd+垃圾指令+pushfd+垃圾指令+popfd等等情况。还有pushfd之前和popfd之后可能也会有少量的垃圾指令,在expand_pushfd_popfd函数中把这些垃圾指令也尽量都考虑进去。最后将结果保存在名为junk_code_pair的dict中。dict的key是垃圾指令的起始地址,valve是垃圾指令的结束地址。用名为junk_code的dict对垃圾指令进行标记,dict的key是指令的地址,valve为1表示该指令是垃圾指令。

不过有一些特殊的情况需要处理。
1.有时pushf之前和popf之后有一对相反的条件跳转:
pushf之前:
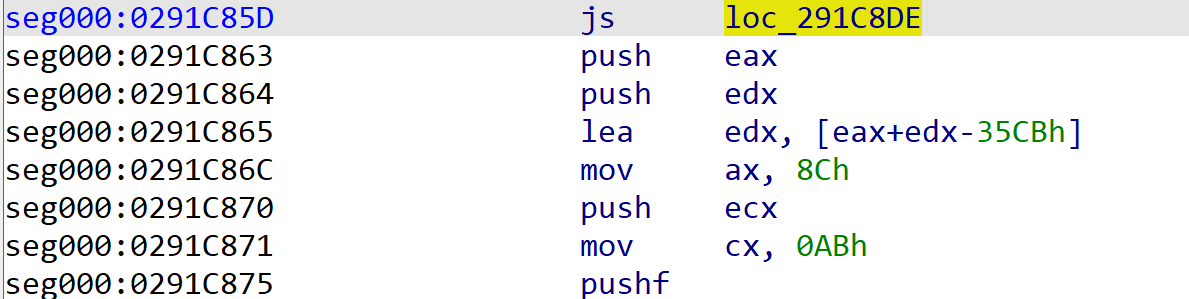
popf之后:

以上图为例,这个时候需要把0x291C85D处的js改成jmp,并且将0x291C863-0x291C8D5之间的指令标记为垃圾指令。

2.有时pushf之前有一条push 0xAAAAAAAA或者mov dword ptr [esp], 0xAAAAAAAA这样的指令,popf之后是一个retn:
pushf之前:

popf之后:

这个时候直接改成call 0xAAAAAAAA。把新创建的call保存在名为new_call的dict中。

还要考虑push 0xAAAAAAAA+垃圾代码+push 0xBBBBBBBB+垃圾代码+retn+垃圾代码+retn这样的情况。这时候会先执行0xBBBBBBBB处的代码再执行0xAAAAAAAA处的代码,而改成call指令之后会先执行0xAAAAAAAA处的代码再执行0xBBBBBBBB处的代码。所以需要修正。

接下来需要恢复程序的控制流,程序的控制流被打乱是因为插入了很多jmp导致IDA Pro反编译F5效果不好。先标记所有的jmp。一共有四种jmp,第一种是jmp +5这样无意义的jmp(值为-2),第二种可能是死循环的jmp(值为-1或者大于1),第三种是jmp一个寄存器(值为0),第四种是正常的jmp(值为1)。对于死循环的情况,比如说0x1000处的指令是jmp 0x2000,0x2000处的指令是jmp 0x1000,那么这两个jmp的标记都是2;再比如说0x3000处的指令是jmp 0x3000,那么这个jmp的标记就是-1。做标记的目的是为了防止处理时陷入到死循环里面。
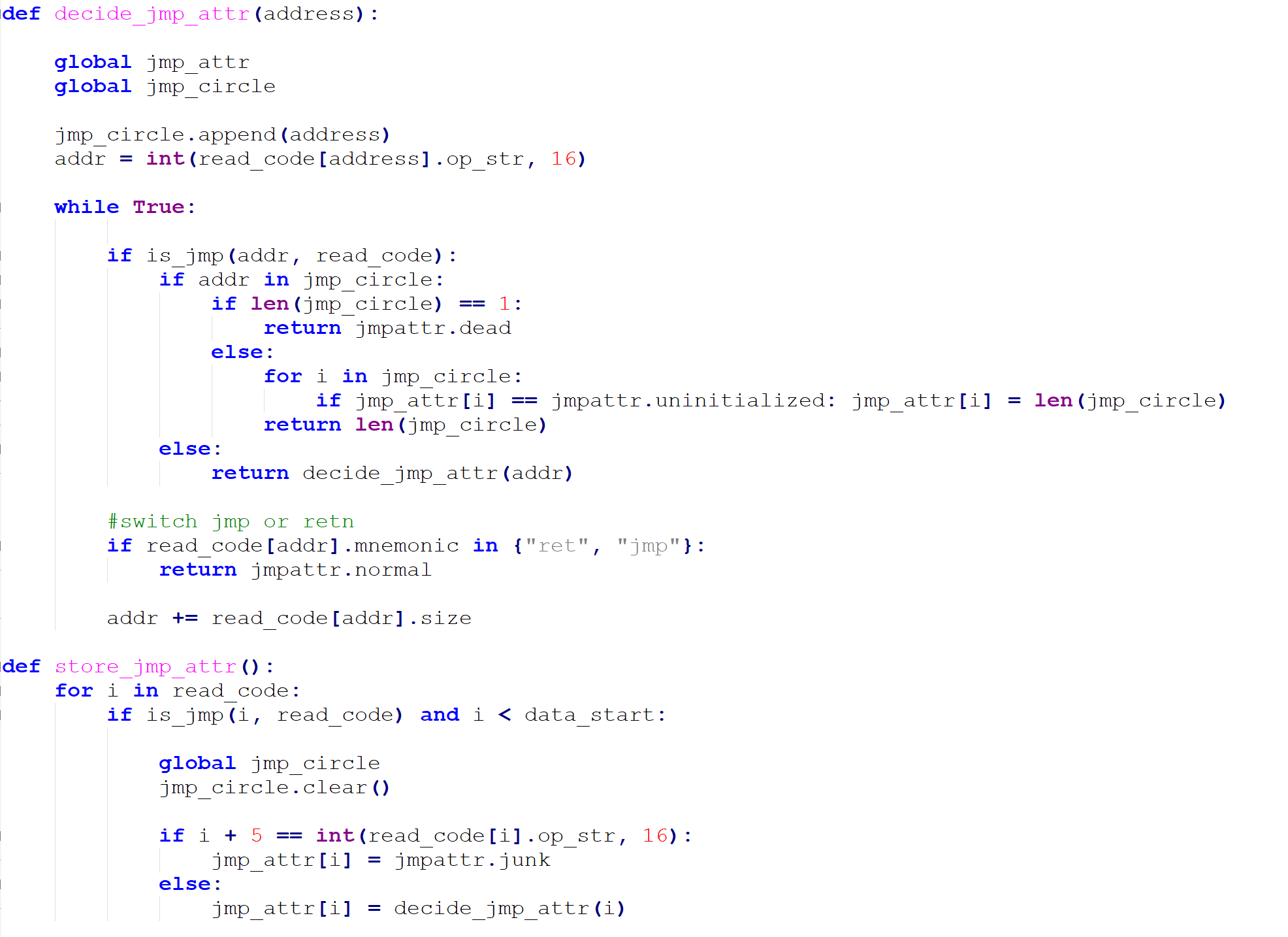

比如说0x1000处的指令为jmp 0x2000,0x2000处的指令为XXX,0x2010处的指令为jmp 0x3000,0x3000处的指令为YYY,0x3010处的指令为jmp 0x4000,0x4000处的指令为retn。那么我的想法是将0x1000处开始的指令改成XXX,YYY和retn,避免出现过多jmp的情况。这里还有一个小细节是需要把两个字节的条件跳转和非条件跳转改成5/6个字节的,因为原来的字节很可能已经不够用了。

在process_read_code函数中调用deal_jmp函数恢复了控制流,跳过了垃圾代码,整理好的代码放在了和read_code类似的名为write_code的dict中。这个过程中得到一个名为code_mapping的dict,key是read_code中指令的地址,valve是该指令被写到write_code中的地址的列表。接下来调用process_write_code函数根据code_mapping修正write_code中指令。
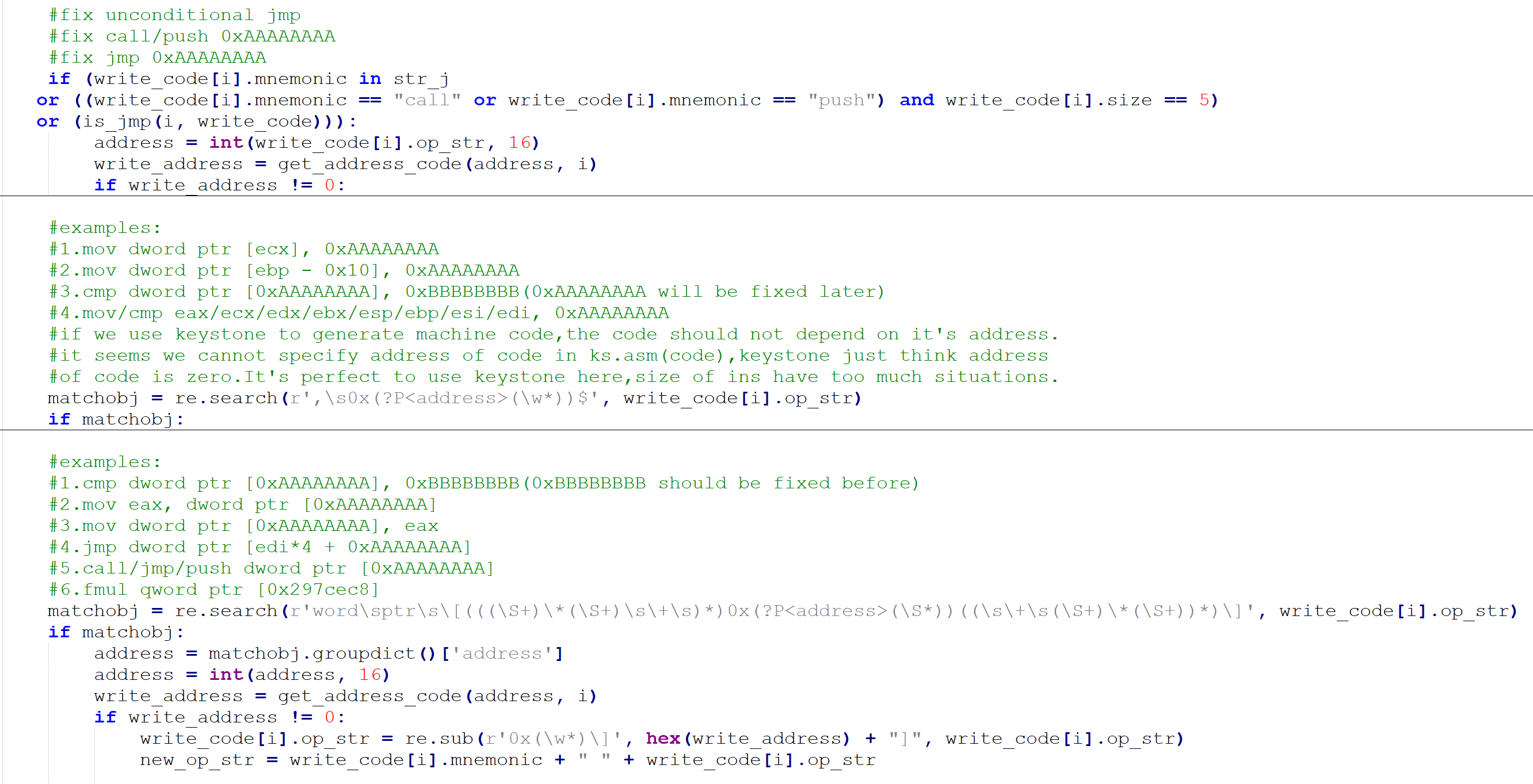
除了指令需要修正以外别忘了数据也需要修正。这样基本就是我的反混淆脚本的整个流程了。
结论
最后我们来看一下处理完之后的效果,一些函数已经基本恢复出来了:
磁盘相关:

注册表相关:
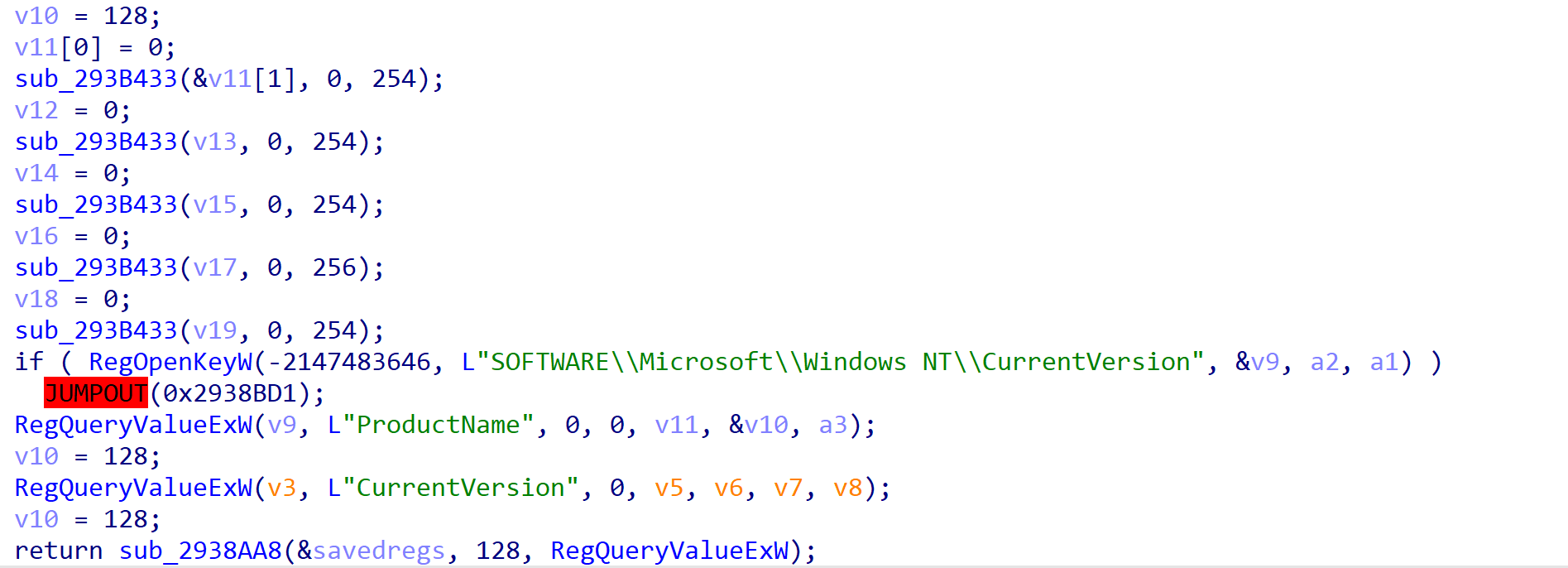
如果不做处理是不可能F5得到这样的比较清晰的结果的。再多说一句,shellcode中恢复Windows API名我以前讲过一些方法:XKungfoo2018:2017年恶意代码威胁回顾和快速分析实践
不过要分析到ESET报告里面那个程度可能还需要对脚本进行完善或者动态调试,还得花一些时间,因为其实还有一些函数是没有恢复出来的,后来不做样本分析以后我也不想继续在这件事上浪费时间了。
最后给出代码和bin文件:https://github.com/houjingyi233/APT32-deobfuscation







发表评论
您还未登录,请先登录。
登录