
这是篇PLDI2017的论文,提供了一种静态检测二进制漏洞的方法,个人认为思路比较简单且实际执行的效率较高,但放在今天看来缺点也较为明显,或许可以进一步考虑代码相似性的检测方案。
引言
在对不含符号表等信息的二进制代码检测相似性时的主要难点是如何确定相似性,例如有时候代码是通过不同编译器、不同优化级别或者针对不同架构编译的。在尽量减少误报的情况下解决这个难题无论是对逆向工程还是定位漏洞代码都至关重要。
作者提出了一个可用于大规模检测且具有较高准确度的技术。其工作原理是将二进制代码过程分解为上下文无关的可比较片段,并将其统一为规范的形式,随后通过简单的比较来找到等价的片段。
结果表明该方案(称为GitZ)能够有效地执行大规模比较,且相似性比较的精度较高,误报率较少。
目前的技术缺陷
- 在受限(stripped)二进制文件、跨编译器、跨架构和跨优化选项的场景下效果不好
- 误报率高
- 无法应对百万级的大规模比较
- 在静态分析时需要动态分析进行配合
提出的方法
- 分割程序片段。将程序分解为strand,即基本块的数据流片段,作为相似性比较的基本单元
strand:A strand is the list of all of the instructions from the basic block that affect the computation of a specific value. - 通过重新优化找到等价的代码片段。通过在strands上重新进行编译优化器的优化过程,将代码片段引入新的规范化形式,从而在后续能够识别语法上不同但语义等价的strands。
- 建立代码相似性。爬取部分语料库生成一个统计框架,来评估每一个strand在整个程序中的重要程度。

设计与实现
二进制代码规范化和一般化处理
这个步骤排除了编译器和链接器的干扰,使得后续工作可以关注于语义方面。该步骤有很多框架可以使用,作者在这里使用了angr的pyvex库将Intel的x86_64和ARM的AArch64指令(包括浮点指令)提升为VEX-IR作为原型。
值得一提的是这一步进行的不只是简单的反编译,而是使用变量表示相应机器的状态(包括内存、寄存器,包括标志寄存器),并用对这些变量的操作来表示指令的语义,因此在这个过程中并不关心任何优化,只需要专注于准确表示语义信息。
会产生一些冗余和总体上的偏差。例如在图3中将aarch64的”mov x1,x21”转换为VEX-IR时产生了冗余的临时变量t14、t15、t16;将x86_64的”add rax,1”转换为BAP后,生成了临时变量T2。
如在图1中体现的,存在这种冗余的变量在进行相似性学习时是致命的,也会对后续在跨架构和优化级别的比较中造成严重干扰

为了达到“Lifter无关”,作者使用了一个(自己写的)工具把VEX-IR转换为LLVM-IR。选择LLVM-IR的原因是它的稳定性、辅助扩展工具多且对多架构支持较好。(个人猜测主要是方便对代码进行统一优化)
在这个阶段的目标是建立一个过程表达(procedure representation)以便在后续配合找到相似的程序片段
提取strand的步骤:生成CFG,分离出每个基本块,其中strand就是在一个基本块中和某个值计算相关的所有指令

以上是提取strands过程的伪代码,大概是“倒序取一条指令,判断其操作的变量与当前strand中记录的变量交集是否为空,如果不为空则将指令记录到该strand中”。其中Ref和Def函数返回一个指令所引用或定义的变量集合。这个算法在一个基本块上重复执行,直到把整个基本块完全覆盖。
这个部分要解决的三个主要问题是:1.编译器造成的strand的语义差异,例如编译优化、运行时库和控制流的影响 2.不同机构造成的影响,例如通用寄存器数量、指令集表达差异等 3.提升器的造成的影响(如前面提到的冗余指令)
解决方案是利用编译器重新进行优化,变相进行统一规范。LLVM-IR对应的优化工具是CLang opt。作者将每个strand作为一个LLVM-IR函数片段,并对代码做了两步更改:1.将寄存器更改为全局变量 2.添加返回strand值的指令。用’-early-cse’和’-instcombine’选项进行了“公共子表达式消除”和“合并冗余指令”。图1(ii)-(iii)中描述的就是这个过程
在用编译器进行规范化处理时,strand默认被输出为储存着表达式的有向非循环图(DAG),为了方便后续比较,作者将其输出为线性表达的文本格式。
重命名strands中所有符号,即将寄存器和临时变量按顺序重新命名。这步对跨架构的比较十分关键,因为在给定的计算中使用的寄存器与实际语义无关,并且在不同架构中完全不同。
进行大规模代码相似性搜索
在比较时使用代码片段的md5值进行比较,这个方能够法减少内存使用且加快了比较过程。对于过程P,将它的表示R(P)定义为过程中所有strands哈希值的集合,即:
R(P)={MD5(Canonicalize&Normalize(sp))|sp∈P}
在对已知序列和目标函数q,t进行比较时,有一个可行的思路是比较两个过程的哈希集的交集,表示为M(q,t)=R(q)∩R(t),但在实际中这个方法效果并不好,一个原因是一些匹配的strands可能只是编译器针对特定架构等因素添加的语义无关代码(artifacts),例如栈空间访问或编译优化,与实际代码语义并没有关系。(题外话,这些代码可以用于识别生成程序时使用的工具链。)
为了避免这个问题,需要区别出从源代码中直接产生的、与程序语义相关的strands。一个简单的方法是将出现次数较多的strand赋予较低的权重。定义Pr(s)为strand s 出现的概率,其中概率空间限制为①从二进制文件中提升的代码,②规范化和一般化后的strands,记为W和 $\widetilde{W}$ 。
如在1式中定义的,我们定义strand s 的重要性为Pr $\widetilde{W}$ (s)并将其出现在不同程序中的次数除以 $\widetilde{W}$ 里所有函数中出现的strand种类数。
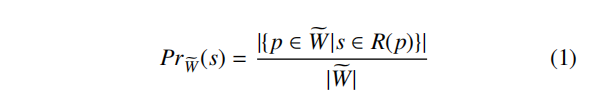
因此已知序列和目标函数的相似性度量即为
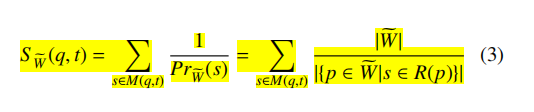
由于计算Pr $\widetilde{W}$ (s)需要 $\widetilde{W}$ ,但 $\widetilde{W}$ 是一个动态增长的值,因此无法简单地计算出Pr $\widetilde{W}$ (s)。作者采用了另一个方案,随机采样获得一个较大的子集P作为全局上下文,来估计Pr $\widetilde{W}$ (s):

(将4式代换到3式将得到2式)
其中P是通过爬取 $\widetilde{W}$ 获得的函数集,因此覆盖了所有支持的编译器、优化级别和架构。同时P作为子集具有较小的尺寸,在后续方法中也能减少内存使用。
注意到此时的Pr $\widetilde{W}$ 其实是一个近似值,因此设P中未收集的strand的f(s)=1,在避免f(s)/|P|产生不确定的同时也做了假设——这些strands在 $\widetilde{W}$ 中极少出现。
实验与结果
生成样本
在学习样本上,作者用了多个版本的CLang、gcc和icc从一些开源代码(包括OpenSSL、git、bash, Wireshark, QEMU等)中编译了大约50万个优化级别不同、针对x86_64和AArch64的二进制文件(对应关系如下图),其中有意选择了一些包含漏洞的软件版本。作者从中爬取了一千个函数,用来生成全局上下文P。

对于全局上下文的合适大小进行实验时,作者发现大约在400个函数后就对误报率基本不造成影响,因此使用了1K个函数(2.5倍)
评价指标
使用CROC(Concentrated ROC)来测量随着阈值的提高而遇到的误报率
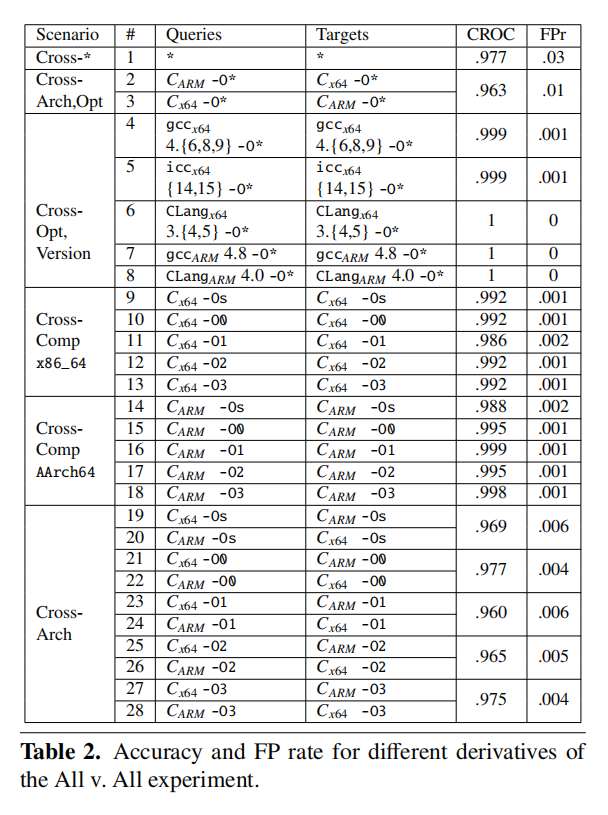
评估结果
- 与另一个工具Esh相比,作者的工具支持跨架构和优化级别,且具有更高的准确率,在效率上更是明显优于Esh
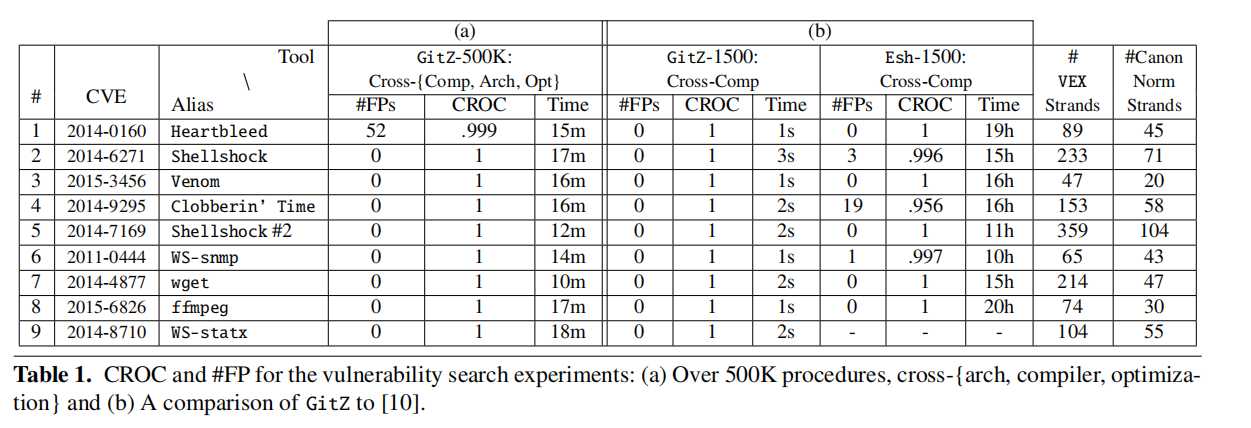
- 挑战最大的是学习单一架构的代码相似性后跨架构对代码进行检测。因为实现操作和指令的范式不同,可能导致错误匹配strands。同时,由编译器和架构导致的内存布局和寻址等方式的不同,也会影响匹配准确率。
缺陷
作者方法的前提是假定了相同源代码编译出的二进制代码会产生语义相同的strands,并且可以进行提取和一系列转化,但这个假设其实不是完全成立的。
- 编译器不同时,控制流图可能存在差异,导致基本块表达存在不同(如下图)。这个问题会使得匹配度偏低。
造成这个的原因是作者为了提高效率和大规模检测,把strands的范围限制在了一个基本块中。可以通过扩大执行链的范围来缓解这个问题(当然代价是开销上的增加)








发表评论
您还未登录,请先登录。
登录