

一篇DSN2020 的论文:Hybrid Firmware Analysis for Known Mobile and IoT Security Vulnerabilities,太长不看版会在不久后发出。
0x0 摘要
移动设备和物联网设备的操作系统以及它们随后的升级文件,通常是以二进制文件的形式发布。由于这些二进制文件通常是闭源的,用户或第三方企业若是想测试软件的安全性只能依靠逆向工程,此外,如何验证二进制文件中最近的补丁是否有效也是一个悬而未决的问题。常规的软件补丁修复是提升移动设备和物联网设备安全性的重要保障,这就需要开发人员、集成商和供应商的共同支持,及时把补丁分发到受影响的所有设备上。但实际上,供应商们对移动和物联网产品遵循着不同,甚至是错误的安全更新议程。其次,以往的研究反映出存在着“潜在的补丁缺口(a hidden patch gap)”:有些供应商错误的声称他们已经修复了漏洞。因此,在二进制文件中检测漏洞是否被修复对于软件安全至关重要。通过深度学习的方法来判断代码相似性和进行漏洞检测已经被证明在静态二进制代码分析中极具前景,然而,这种方法无法捕捉程序动态行为,导致了可能在挖掘在野漏洞时产生大量误报。此外还有一点十分关键,静态的方法无法捕捉到用于区分漏洞是否修复所需的细粒度特征。
在本文中,我们提出了PATCHECKO,一个针对可执行文件的漏洞和补丁存在性检测框架。PATCHECKO依赖于混合跨平台二进制代码相似性分析,一种结合了基于深度学习的静态代码分析和动态分析的方法。它不需要访问二进制文件的源代码。我们在最新的Google Pixel 2 和 Android Things IoT 固件映像上评估了PATCHECKO的性能,其中有25个CVE漏洞已经被报告和修复了。结果表明我们的深度学习模型在漏洞检测上达到了93%的准确率。 在动态分析过程中,我们删减了深度学习阶段得到的候选函数(包括误报)。结果表明,PATCHECKO总能在候选函数中将正确的结果输出在结果排名的前三名之中。此外,它的差分引擎也以96%的准确率区分了漏洞函数和已修复漏洞的函数。
Ⅰ.引言
软件漏洞披露的数量和发现漏洞的速度每年都在稳步上升。2010年提交给CVE数据库的漏洞报告数量大约为4600篇,2016年为6500篇,随后在2017年翻了一番,超过了14700篇。与此同时,移动和物联网设备的日益普及使他们成为了漏洞研究和利用的首选目标,根据Gartner预测,到2020年全球将会有204亿台物联网设备。此外,消费者和企业在其产品或者活动中也常常直接使用供应商提供的固件和补丁。这些外部设备通常需要进行一些检查步骤,包括对产品软件的安全断言等,例如进行黑盒渗透测试。如果这类测试没有做好,就可能会导致IoT设备的安全问题。好在对于渗透测试人员来说,移动和物联网供应商通常重复使用开源代码并将其应用到他们的产品。渗透测试人员通常关注于加密函数库、媒体函数库和解析器等在漏洞被发现后定期更新的二进制文件,但不幸的是,移动和物联网设备中这些库的源代码不易被获得,导致它们很难及时被更新到最新版本。
通常来说,移动和物联网设备的补丁管理对于这种异质的生态系统来说是一种挑战。2018年,美国联邦贸易委员会(FTC)的一份报告显示,一个生态系统的多样性一方面为消费者提供了大量的选择,另一方面却增加了安全更新的复杂性和不一致性。软件补丁必须经过许多中间商,从开发者到集成商再到供应商,最后才被推送到终端设备上。
这种较长的补丁链产生了两个问题。首先,这种冗长的中间人名单会使得补丁不能被及时到终端。在2016年, Duo Labs team 发现仅有25%的移动设备运行了最新的补丁。其次,供应商并不总能准确地报告他们是否修复了某个漏洞(潜在的补丁缺口),特别是对于移动设备和物联网设备。一个研究表明,由供应商发布的80.4%的固件都包含了多个已知漏洞,许多最近发布的固件升级包中里用使用的第三方库也存在许多漏洞,有些漏洞甚至在八年前就被发现了。另一个针对安卓手机的研究发现,一些供应商通常会忘记将漏洞修复,使得(物联网)生态系统的某一部分暴露在潜在的风险中。
这种补丁缺口不仅会导致大量设备易受攻击,同时,随着代码重用的普遍性增加,开发人员可能直接使用存在已知漏洞的代码,导致漏洞迅速传播。
因此,识别存在漏洞的二进制代码和修复情况对终端用户来说是一个严峻的挑战。PATCHECKO通过一个混合两个步骤的方法解决了这个问题,该方法结合了一个轻量的固件静态分析和紧随其后的准确的动态分析,以完善静态分析的结果。
依赖深度学习进行的已知漏洞挖掘。对于如何在给定的二进制文件中得到漏洞的集合-或者至少是超集,是一个已经被探索过的问题,但并没有令人满意的答案。最近,研究人员正在尝试通过跨平台的二进制代码相似性检查来检测已知漏洞。这类方案尝试识别目标固件中是否存在某个漏洞,其与漏洞函数数据库中的函数相似。他们直接从控制流图里代表函数的每个结点的二进制代码中提取健壮(robust)的、独立于平台的特征。除此之外,还有的方法侧重于二进制代码的相似性检测,其中使用了图匹配算法来检查两个函数的控制流图表达是否相似。另外,这类方法中可以使用深度学习中的自然语言处理来代替人工选择特征。
以往的研究表明深度学习方法可以用于在二进制代码分析中检测漏洞。最新的算法训练表现的模型评估指标达到0.971、检测准确率超过80%。然而,即便有这种较好的表现,假设目标二进制代码有3000+个函数,我们仍旧会得到大量(600+个)候选函数需要我们在自动分析后人工进行确认。同时,已有研究证明,在能够访问符号表的情况下,候选函数是可以被精简的。但是,对于没有符号表的商用现成品(COTS)二进制文件,这种方法只能从它们那得到一个庞大的候选函数集,且大多是误报。因此,需要进一步对候选函数进行删减,以确保只识别和报告出真正含有漏洞的函数。PATCHECKO使用了目标二进制代码的静态分析结果(静态特征)来完成这一阶段。
通过动态分析对候选函数进行删减。PATCHECK依据动态分析的结果(动态特征)对基于深度学习的方法得到的候选函数集进行删减,以避免误报。静态分析阶段已经移除了大多数极不可能含有漏洞的函数,只返回了一小部分函数,这使得PATCHECKO可以在这些函数上使用更耗费资源的动态分析技术。以往的工作出于对可扩展性的考虑,将执行速度放在首位,而牺牲了准确性,仅关注了基本块和函数的启发式特征或静态特征。相比之下,PATCHECKO的混合方法不仅加快了漏洞函数匹配的速度,而且在删减误报后也提升了准确率。
这个初始框架让我们能够开发一种新的训练模型生成方法,该方法使用默认策略预训练了一个与任务无关的图嵌入网络。接着,对从相同源代码编译而来但编译优化级别和目标平台不同的二进制函数集使用了这种方法,生成了一个大规模的数据集。随后,我们构建了一个漏洞数据库,其中包含了1382个移动/物联网设备固件的漏洞。
然而,我们最终的目标不仅仅是找到CVE编号对应的函数,而是分辨出目标固件中是否存在有漏洞,亦或是已经被修复了。
修复状态检测。过去的研究已经发展出了准确的补丁存在性检测,然而这个方案仅在能够访问到待检测函数和已修复漏洞函数的源代码时才适用。同时,因为这个方案依赖于基于二进制相似性检测的方法来定位目标函数,这也可能导致之前提到过的对候选函数的大量误报。我们的方案直接操作于剥离符号表的商用二进制文件,且在不需要访问源代码的同时还能明显地减少误报。
最后,本文提出了PATCHECKO,一个结合了基于深度学习的二进制代码相似性检查和动态分析的框架,适用于挖掘已知漏洞和补丁存在性检测。根据我们的评估结果,PATCHECKO在准确性和效率方面都明显优于目前最先进的算法。
贡献。我们总结了我们做出的贡献如下:
- 提出了一个高效的固件漏洞和补丁存在性检测框架。该框架利用了深度学习和动态二进制分析技术,在无需访问源代码的情况下,实现了对受限二进制固件的高准确率和高性能的已知漏洞挖掘。
- 提出了一个细粒度的二进制比较算法,能够准确的区分出同一函数的二进制代码的修复和未修复版本。我们的方案目前支持跨平台的ARM和X86架构。针对比较而选用的相关特征使得此方案能够以非常低的误报率,准确的定位未打补丁的函数。
- 我们用4种架构、100个安卓固件库、25个CVE漏洞来评估PATCHECKO的性能,结果表明它非常有希望在实际环境中进行得到应用。PATCHECKO的大部分原型都是完全自动化的,同时,它的动态分析模块可以准确的识别和删除深度学习阶段的误报。动态分析后,由另一个模块再对结果进行处理,将未打补丁的函数和已修复的函数区分开。
Ⅱ.概述
我们在Ⅱ-A里介绍了函数相似性的问题和面临的挑战,在Ⅱ-B里展示了我们的解决方案。
A.威胁模型和挑战
在本文中,我们主要考虑在没有源代码的情况下寻找商用移动/物联网设备二进制文件中的已知漏洞。我们还假设二进制文件没有经过压缩或者混淆,且是由高级语言,即具有函数概念的语言编译而成的,因为在分析混淆过的代码时,有一个很重要的问题是如何对代码进行处理,而这超出了本文讨论的范围。基于以上这些假设,我们列出了在移动/物联网平台下面临的以下几个挑战。
针对不同平台架构的大量二进制文件。移动/物联网平台通常由各种不同架构的硬件组成,但它们可能拥有相同的软件漏洞。因此,我们特别考虑了,不同目标平台和优化级别对相同源代码产生的二进制程序这一情况。通过这种方式,我们可以生成不同硬件架构(例如x86和ARM)和软件平台(例如Windows、Linux和MacOS)下具有相同漏洞的二进制函数。
大量的候选漏洞函数。为了体现候选漏洞函数的数量级,我们分析了 Android Things 1.0 和 IOS 12.0.1 的固件。对于 Android Things 1.0 ,我们找到了379个不同的库,其中包含440532个函数;对于 IOS 12.0.1 ,我们找到了198个库,包含93714个函数。虽然过往的研究表明基于深度学习的方法可以用于高精度识别候选漏洞函数集,但这类技术并没有自动化的解决方案来对误报结果进行进一步删减。此外,“Precise and accurate patch presence test for binaries”研究中提出的方案依赖于符号表,但受限制的商用软件中并没有符号表可以使用,这就提出了另一个问题,即如何对没有符号表的二进制文件进行候选漏洞函数的删减。
区分已修复代码和漏洞代码。未修复函数和已修复函数可能并不容易区分,它们之间的差别可能小到只改变了一行代码。以往的研究表明,在能够访问含有漏洞的函数源码和修复过漏洞的函数源码的情况下,我们可以检测漏洞是否被修复,但大部分时候我们无法获得二进制函数的源码。
针对这些有趣的挑战,我们现在介绍一下PATCHECKO框架。
B.方案
PATCHECKO框架的执行流程在图1进行了展示。我们的方案分为三个步骤进行:(1)用深度学习训练漏洞检测器,(2)用训练的漏洞检测器对目标移动/物联网固件进行静态分析,(3)对静态分析出可能含有漏洞的函数进行进一步的动态分析,验证漏洞是否存在,随后使用从漏洞函数和已修复漏洞函数中提取的静态和动态特征,识别候选漏洞函数是否已经被修复。
PATCHECKO的目标是将二进制固件中的函数与CVE漏洞库以及相关的补丁进行对比,输出目标固件镜像中的漏洞函数以及对应的CVE编号。为了比较两个二进制函数运行时的特征,PATCHECKO结合了静态和动态分析技术以及人工智能和机器学习的深度学习方法。PATCHECKO先使用轻量级的静态分析模块将每个固件中的函数转换为用于机器学习的特征向量,接着调事先训练过的深度神经网络模型来判断两个(源代码相同但编译选项可能不同的)函数(一个来自固件,另一个来自CVE数据库)是否相似。如果两个函数检测结果表明可能相似,PATCHECKO就会进行更深入的动态分析,来确保静态分析的结果并不是误报。
为了进行动态分析,PATCHECKO在对应的移动/物联网嵌入式系统平台内运行CVE漏洞函数和目标固件函数时,使用了DLL注入以及远程调试并给函数参数和全局变量赋了相同的值。它捕捉了两个函数的每个运行轨迹并提取动态特征,例如指令的数量和类型、系统调用的次数和类型,以及库函数调用和堆栈数据读写量等。
基于提取出的这些特征,PATCHECKO算出两个函数的相似度并判断静态分析的结果是否是正确的。如果正确,PATCHECKO就认为这个该固件里的这个函数存在对应CVE编号,并在结果中报告该固件和对应的CVE编号。值得一提的是,PATCHECKO的分析过程不需要访问源代码,因此完全不需要固件供应商的支持。
因为我们并不知道前一步输出的函数是否被修复过,PATCHECKO会先基于两个函数的静态特征对它们进行比较,然后再用已修复函数与目标函数进行比较,随后使用差分引擎对静态/动态特征和相似度进行分析,来判断函数中的漏洞是否被修复了。

Ⅲ. 设计
在这一节中,我们将展示PATCHECKO框架的设计方案,包括它是如何处理移动/物联网二进制可执行文件、如何在无源代码的条件下发现并报告固件里代码段或数据段中的漏洞。在基于相似性检测的漏洞挖掘之外,PATCHECKO还能够准确识别目标固件是否打上了安全补丁。
A.基于深度学习的固件漏洞评估
对于已知漏洞挖掘,深度学习方法的准确性和效率都明显优于过去的二分图匹配和动态相似性测试。这是由于深度学习方法可以从整体上评估二进制文件的图像表示,而且可以在没有人为定义规则的情况下自主学习关系。PATCHECKO的第一步使用了一个深度学习框架,在短时间内生成了一个候选漏洞函数列表。为了符合之前的假设,我们首先需要提取静态静态函数特征,构建一个训练数据集,然后对深度学习模型进行训练。
特征提取。为了提取函数的静态特征,PATCHECKO首先分析了函数的汇编格式,标记了每个每个汇编例程正确的边界、范围。PATCHECKO的神经网络模型输入的数据是从目标函数的反编译代码中提取的函数特征向量。为了获得特征向量,我们先识别了函数的边界。在尽量不依赖指令集语义的情况下识别函数边界是一个有趣的问题,以往这个任务都由传统的机器学习或神经网络或函数接口验证来进行,在我们的设计中,这些方法都由反汇编器通过某种具有鲁棒性的启发式技术完成。反汇编器可以提供一个二进制文件的控制流图(CFG),一个在漏洞检测中常常使用的特征。
图2表示了PATCHECKO的函数特征提取过程。PATCHECKO利用了具有不同基本块级属性的CFG作为特征来进行模拟。对于每个函数,PATCHECKO可以提取函数级、基本块级、块间级信息。表Ⅰ展示了生成一个特征向量用到的提取出的48个有趣的特征。
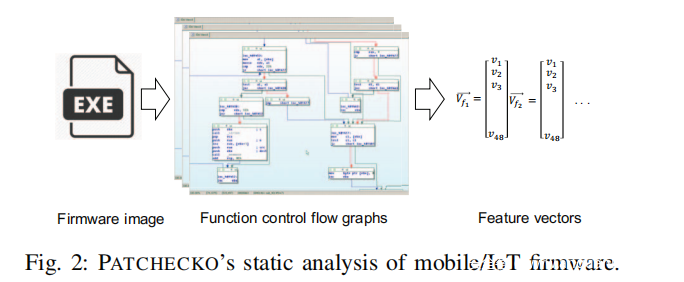

PATCHECKO保证了提取特征的丰富(48个特征)、高效(自动提取)和可扩展性(支持多架构)
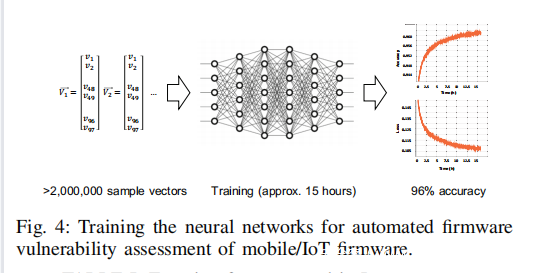
训练深度学习模型。对于PATCHECKO的深度学习,我们采用了一个由线性层堆叠的序贯模型,所有超参数都是凭经验确定的。图3展示了一个用于深度学习模型的样本向量。样本向量由函数向量对和一个表示两个函数是否相似的比特组成,其中两个相似的特征向量对应着相同源代码的两个二进制函数。图4描述了一个用6层网络模型训练的实际过程。我们首先为每一层指定了输入。顺序模型中的第一层需要接收输入张量的形状(input shape)的信息。这个模型使用了从我们数据集中提取的函数特征进行训练,该数据集包含了2108个具有不同架构的二进制文件。

B.通过深入的动态分析删去候选函数中的误报
我们使用动态分析来进一步删减深度学习阶段返回的候选函数。本阶段判断了先前报告的函数对是否确实是相似的(例如,均为修复过或含有漏洞的函数)。在动态分析步骤进行时,程序用相同的输入值执行了两个候选函数,并比较了观察到的行为和其他几个特征的相似性。
由于生成两个函数的编译选项可能不同,在这种情况下,对于相同的输入,两个函数的执行轨迹可能差别很大。因此,我们的分析将考虑执行轨迹的语义相似性,即两个函数输入相同数值后执行完毕对内存的影响。
为了实现这个功能,我们从执行轨迹中提取了特征(动态特征)。我们的方法比较了两个具有相同输入值的函数所产生的两条执行轨迹的特征向量。如果对于不同的输入值,均观察到具有相似的特征,那么我们就猜测它们在语义上是相似的。
图5展示了PATCHECKO动态分析的工作流程。真正要进行动态分析还有如下几个困难:首先,如何准备执行的环境;其次,如何同时监控多个候选函数的执行情况;另外,由于我们研究的是异构的移动/物联网生态系统,因此要运行所有的二进制代码来获得执行轨迹并不容易,特别是一些函数的执行需要“有效”的输入。我们先讨论输入动态分析引擎的准备工作。

输入动态分析引擎的数据。实现PATCHECKO动态分析引擎的一个关键问题是如何准备相关的输入。动态分析引擎需要两个输入内容:程序的二进制代码,我们称为F,以及F的运行环境。其中程序的二进制代码包括了目标函数f。有一个难点是,如何将目标函数和整个二进制函数的执行区别开。一个方案是在执行时提供具体而有效的输入值,但因为无法引导操作系统在特定的地址开始执行程序,所以这个方案通常需要装载并运行整个程序。PATCHECKO提供一个包含了所需执行状态的执行环境,从而解决了这个问题。
PATCHECKO使用模糊测试为不同目标函数生成不同的输入,来加快控制流图(CFG)的覆盖率。对于每次目标函数的执行,PATCHECKO都会导出一个压缩的函数级可执行文件,即一个压缩的、可通过运行时DLL注入执行的二进制文件和使其能够运行的相关输入。这使得动态分析执行引擎能够高效地执行目标函数,同时也意味着PATCHECKO可以针对不同目标函数使用特定执行环境和不同输入。
验证候选函数的执行。在PATCHECKO开始插桩检测目标函数前,它对众多的候选函数使用了多种的执行环境。在我们开始运行目标函数f后会有几个可能的结果,例如,函数f可能正常运行,可能产生了系统异常,或者进入死循环。如果候选函数f触发了一个系统异常,我们将从候选集里移除该函数。在使用多种执行环境验证各个函数执行后,将会对候选函数进行插桩。
目标函数插桩检测。在特定执行环境下,动态分析引擎对函数f的分析结果输出了一个长度为N的特征向量v(f,env)。为了生成该特征向量,PATCHECKO追踪了函数的执行。在动态分析时,通常有大量的工具可以使用,例如调试器、模拟器和虚拟机,但由于移动/物联网固件架构和平台的异构性,PATCHECKO因此选用了一个支持多种架构和平台的插桩工具。
PATCHECKO提取了各种指令的指定特征,包括指令信息(例如指令数量)、系统级信息(例如内存访问)以及例如函数和系统调用的高级别特征。表Ⅱ展示了我们最初考虑并最终证明对建立函数二元相似性有用的初始特征集。当然这些特征并不并不全面,也很容易进一步扩展。

对于每次执行,动态分析引擎会对每个特征会生成一组观察结果,例如,在上面的例子里会生成21组观察结果。当f里的所有指令都被覆盖到后,PATCHECKO把所有结果合并成一个单独的向量,例如f<sub>input_1</sub>。同样的过程会在每次对函数进行不同输入时重复,产生f<sub>input_2</sub>、f<sub>input_3</sub>、…、f<sub>input_N</sub>。
现在我们能够提取目标函数的动态特征了,接下来介绍计算一对函数以及特征集之间相似性的算法。
C.计算函数语义相似度
对于每个函数对(f,g),PATCHECKO基于它们的动态特征向量距离计算出语义相似度。距离通常被用于代表在数据挖掘时对象特征的维度。值得一提的是,对于每个函数的特征向量,PATCHECKO使用了闵氏距离(Minkowski Distance)作为测量相似度的方法。不同的参数会导致特征向量中相应的坐标值有轻微差异,我们现在详细讨论一下距离的测量。
闵氏距离是欧氏距离(Euclidean Distance)和曼哈顿距离(Manhattan distance)的一般化形式(闵氏距离中的p=2时即为欧氏距离,p=1时即为曼哈顿距离)。在我们的项目中,将闵氏距离的p设为3。闵氏距离公式的一般式如下:

在这个闵氏距离公式中,f代表了CVE函数,g代表目标固件中的候选函数,k指的是用到了第k个执行环境,x和y分别代表f和g的动态特征向量,此时P设为3。
我们计算了每一对(f,g)在多种执行环境下的相似度,然后算出所有执行环境中的平均值得到最终结果。设k为执行环境的编号,我们定义:

最后,我们将每个候选函数的动态特征向量送入相似度计算的方程中,得到一系列(函数和相似性距离)的排名对(见图5)。这是检测已知漏洞的最后一步,现在我们开始设计检测补丁是否存在的最后一个步骤。
D.补丁检测
我们注意到一个补丁通常只对漏洞函数引入了一点点改变,然而这些细微的改变仍然可以对修复前和修复后的函数造成明显影响,使它们存在一定差异-这一观点会在第Ⅴ节得到证实。基于这个概念,PATCHECKO使用了一个差分引擎来收集静态和动态相似性检测结果,来判断一个漏洞函数是否被修复了。
对于给定的漏洞函数f<sub>v</sub>、已修复函数f<sub>p</sub>和目标函数f<sub>t</sub>,差分引擎会首先生成三个值:f<sub>v</sub>、f<sub>p</sub>和f<sub>t</sub>的静态特征、sim<sub>v</sub>与sim<sub>t</sub>、sim<sub>p</sub>与sim<sub>t</sub>的动态语义相似性得分以及S<sub>v</sub>和S<sub>p</sub>之间的差分特征(differential signatures)。静态特征即上述的48个不同的量化特征,动态语义相似度得分与上述的函数相似度指标。差分特征(differential signatures)是一个用于比较CFG结构的附加指标,即两个函数的CFG拓扑以及语义信息,例如函数参数、局部变量和库函数调用。
Ⅳ.实现及案例研究
我们将PATCHECKO框架部署在了Ubuntu18.04-amd64上,实验过程在一个配有 Intel Xeon E5-1650v4 、 128GB 内存、 2TB SSD 和 4块 NVIDIA 1080Ti GPU 的服务器上进行,在训练和评估过程中,4块GPU均被使用到了。在设计中,PATCHECKO由四个主要部分组成:特征提取器、深度学习模型、动态分析引擎和用于补丁检测的差异分析引擎。
A.特征提取和深度学习
特征提取器接收的输入是目标函数的反编译代码。我们默认 IDA Pro (一个用于提取二进制程序特征的商用反编译器)识别出的函数边界是可用且正确的。因此,我们将特征提取器作为 IDA Pro 的一个插件。我们开发出了插件的两个版本:一个带GUI,另一个使用命令行(用于自动化)。因为PATCHECKO的目标是跨平台的二进制文件,所以插件可以支持对不同架构(x86、amd64和arm 32/64 bit)进行特征提取。
我们基于Keras和TensorFlow实现了神经网络的建模、训练和分类,使用TensorBoard来实现整个训练过程的可视化。
B.动态分析引擎
正如在设计一节中描述的,动态分析的关键挑战是给分析引擎准备输入和在目标函数执行时跟踪动态信息。
输入准备。正如在第Ⅲ节-B部分提到的,PATCHECKO需要高效地准备执行环境。为了不必装载整个二进制文件就能进行动态分析,我们使用了DLL注入来执行一个只表示单一目标函数的压缩的可执行文件。我们使用了动态加载函数(如dlopen())来加载动态链接文件,它返回了一个被加载对象的句柄,这个句柄随后被dlopen API中的其他函数使用,例如可以把返回值传给dlsym,通过函数名找到函数的地址,进而能够运行目标函数。
当然,库函数文件包含了大量函数,其中一些是非导出函数(non-exported functions),为了后续的分析,PATCHECKO使用LIEF将这些函数导出。这样PATCHECKO就能够通过 dlopen() 和 dlsym() 找到库函数地址,执行并跟踪所有候选函数,而不需要运行整个程序。这个方法的可靠性极好且效率极高,我们因此可以关注于目标函数而不需处理整个程序。同时,我们使用了LibFuzzer对候选函数进行模糊测试,生成了不同的输入集。对于执行环境,我们人工地为不同的全局变量选择了具体的初始值。
检测框架。因为目标是异构的移动/物联网生态系统,因此我们选择将PATCHECKO的动态检测工作放在 IDA Pro 和 GDB 上。我们还为安卓和Android Things平台写了一个GDB和GDBServer的插件,为IOS平台写了一个IDA Pro和debugserver的插件。
C.案例分析
为了能更好理解这一方法的细节,我们提供了一个例子来展示如何在Android Things固件上定位一个已知的CVE漏洞以及如何确定某个漏洞是否被修复。Android Things是谷歌一个专为嵌入式IoT设备设计的操作系统。
挖掘已知CVE漏洞函数。我们选用了一个Android Security Bulletins上的漏洞:CVE-2018-9412,一个位于libstagefright库removeUnsynchronization函数中的DoS漏洞。为了方便进行案例分析,我们直接使用Clang从含有漏洞的和修复过的libstagefright库源码中编译出二进制文件,优化级别设置为O0。图6展示了该漏洞触发点的源代码和汇编代码,我们将在接下来的小节中对这个图的几个部分进行进一步描述。
生成训练数据集。我们使用Clang从安卓函数库里编译了100个库的代码,目标架构包括x86、amd64、ARM 32-bit和ARM-64bit,优化级别涵盖O0、O1、O2、O3、Oz和Ofast,最终获得了2108个二进制库文件。更多相关细节将在第Ⅴ节呈现。
特征提取。我们写了一个基于IDA Pro的特征提取插件来提取特征,在获得特征后,PATCHECKO会根据它来生成特征向量。PATCHECKO从libstagefright.so的所有函数特征里识别出了5646个函数,并将其全部转换为函数特征向量。
通过深度学习进行漏洞检测。将特征提取出来后,我们使用训练的模型进行检测,以漏洞函数和已修复函数作为基准。该模型基于漏洞函数的特征向量识别出了252个候选函数,基于已修复函数识别出了971个候选函数。我们也比较了漏洞函数和已修复函数的特征向量以检查它们是否相似,结果表明两个特征向量并不相似,例如图6中可以看出两者具有明显不同,修复过程移除了memmove函数,并对数值进行了检查和判断。同样的,也可以在汇编层面上观察到基本块数量的差异。

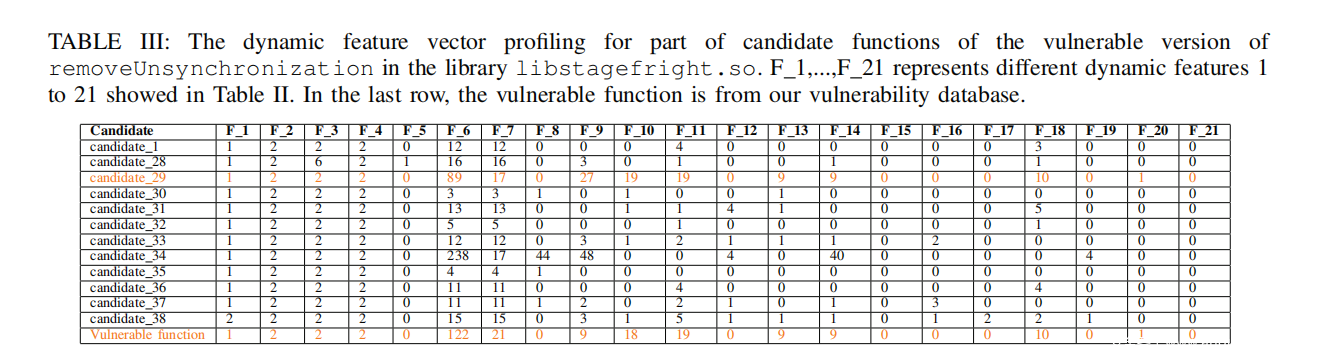
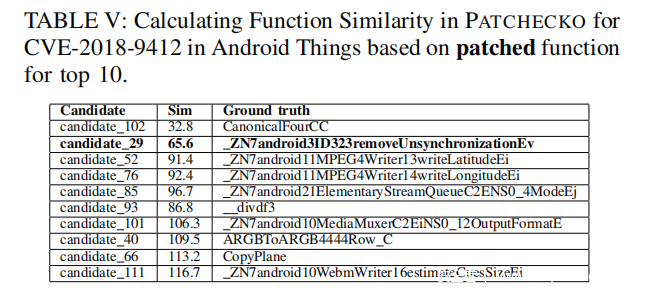
动态分析引擎。候选漏洞函数和已修复函数不仅在数量上较多,而且候选函数之间的相似度也较高,导致难以通过人工定位目标漏洞函数。对此我们使用了动态分析引擎来生成每个函数的动态信息。我们首先使用LibFuzzer生成函数removeUnsynchronization()的不同输入数据,并测试证明它们都能正常运行于漏洞函数和已修复漏洞的函数。和之前一样,我们使用这些数据来测试每个候选函数,筛去执行过程中崩溃的函数。通过这步验证,我们获得了38个候选漏洞函数和327个候选已修复函数。对于这些候选函数,PATCHECKO的动态分析引擎将生成动态信息。对于在Android Things上的插桩,我们使用gdbserver获取Android Things设备上的动态特征。表Ⅲ展示了部分漏洞函数的动态特征向量的分析。在下一小节,我们分析了为什么candidate_29是漏洞函数
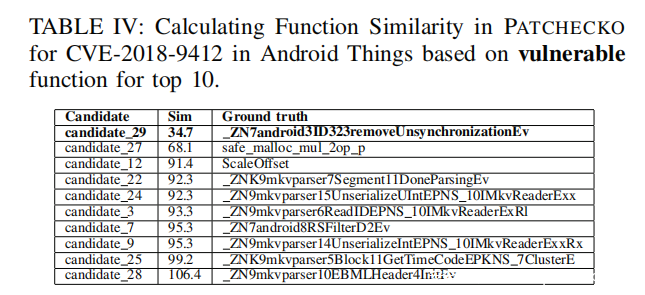
计算函数相似度。我们使用三个之前提到过的指标来计算函数间的相似度。在表Ⅳ中列出了相似度前十的漏洞函数,表Ⅴ列出了相似度前十的已修复函数。对于表Ⅳ,其中我们看到candidate_29函数排在第一位。根据相似度距离算法,如果距离较小,则对应的相似度就较高。可以看到这个函数和排在它后一位的candidate_27存在较大差距。我们因此得到结论,candidate_29就是漏洞函数。
进一步观察表Ⅲ的结果,我们可以看出为什么动态特征之间的距离非常小。表中两行高亮的数据分别是candidate_29和基准漏洞函数。在表Ⅱ中,我们已知F_13表示同一分支指令的最大频率,F_14代表同一算术指令的最大频率。注意到candidate_29是唯一一个和基准漏洞函数具有相同频率的候选函数。值得一提的是这个分析只在动态分析的时候进行,静态分析的时候无法收集到这些特征。
对于检测已修复函数,表Ⅴ由于篇幅限制仅展示了排名结果前十的候选函数。在本测试结果中,candidate_102排在第一位,不过它对应了错误的函数。然而注意到排在第二的candidate_29,它的Sim值比第三名要小得多。直观的说,我们可以将范围缩小到这两个候选函数,并且可以猜测candidate_29可能是候选漏洞函数。然而目前我们还不能确定这个函数是否是已修复函数。
差分分析引擎。基于前面的步骤,我们可以确定candidate_29即是目标函数,但仍旧不知道它是否被修复了。我们收集了静态特征(例如jaeabi_memmove),动态语义相似性得分(34.7 对 65.6)和差分特征(differential signatures)(jaeabi_memmove里的if条件)。差分分析引擎随后根据这些指标分析出目标函数是否被已被修复。
Ⅴ.评估
在这一节,我们将从搜索的准确度和计算效率来评估PATCHECKO。我们还评估了深度学习模型、动态分析引擎和差分分析引擎的准确度。
A.数据集准备
在评估中,我们收集了三个数据集:1)数据集Ⅰ主要用于训练深度学习模型以及评估模型准确性;2)数据集Ⅱ用于收集已知CVE漏洞,用于构建漏洞函数数据库;3)数据集Ⅲ用于评估深度学习模型、动态分析引擎和差分分析引擎在分析真实移动/物联网固件时的准确性和性能。
数据集Ⅰ:这个数据集用于进行神经网络训练和基线比较(baseline comparison)。它包含了从源代码编译来的二进制代码,为我们提供了基准数据(ground truth)。我们假设从相同源码中生成的两个函数是相似的,不同源码中生成的函数是不相似的。我们使用Clang从Android-8.1.0_r36的源码中编译了100个库函数,每个库根据不同的目标平台( x86, AMD64, ARM 32bit, ARM 64bit ISA)、优化级别(O0, O1, O2,O3, Oz, Ofast)生成了23个不同的二进制文件。不过,并不是每个库函数都可以用六种优化级别进行编译(如libbrillo, libbacktrace,libtextclassifier, libmediaplayerservice)。我们总共获得了2108个库文件,包含了2037772个函数特征样本,其中每个二进制文件都是debug版本,方便我们基于符号名建立基准数据。在后续测试时,我们生成的是受限的Release版本。
数据集Ⅱ:我们的目标是进行评估漏洞,因此我们生成了包含漏洞函数和已修复漏洞函数的数据库,其中包含了函数的动态特征向量和静态特征向量。漏洞函数数据集来自Android Security Bulletins,包括了从2016年7月到2018年11月的漏洞。这个数据库涵盖2076个漏洞,其中有1351个高危漏洞和381个关键漏洞。
数据集Ⅲ:为了评估PATCHECKO,我们收集了不同的固件映像,包括多个版本的Android、Android Things 和 IOS。其中,我们选择了Android Things 1.0 和 Google Pixel 2 XL (Android 8.0) 的两个固件映像作为目标。对于漏洞检测,我们考虑了2018年中修复的 Android 8.0和8.1 上的漏洞,最终从我们的数据库中选择了25个CVE漏洞用来对我们的方案进行评估。
B.训练模型
我们的深度学习模型使用了6层的序列模型,使用数据集Ⅰ进行训练。我们首先为每一层指定输入。第一层接受的是输入张量的形状(input shape)的信息。在我们的实验中,它的值是96。我们将数据集Ⅰ的所有函数分解为3个不相交子集,分别用于训练(1222663个)、校验(407554个)和测试(407555个)
C.测试设备
我们对PATCHECKO的评估在两种设备上进行,一种是Android Things, 另一种是Google Pixel 2 XL。对于Android Things, 我们使用了Android Things 1.0 ,它包含了2018年5月及以前的安全补丁;对于Google Pixel 2 XL,它装载了 Android 8.0 的系统,补丁版本是2017年7月。
D.准确性
在这一节,我们评估了PATCHECKO的深度学习模型、动态分析引擎和补丁检测的准确性。
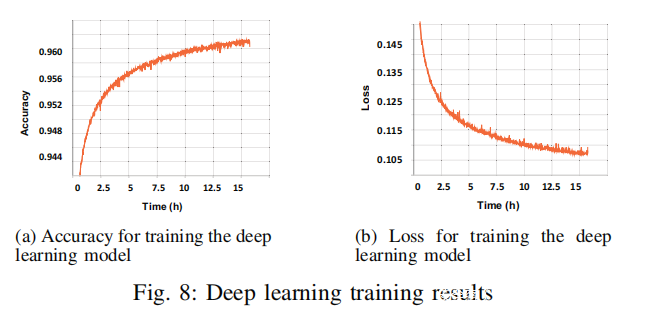
深度学习模型。图8展示了在训练了大约15小时后,深度学习模型的准确率和损失,其中准确率可达到96%。
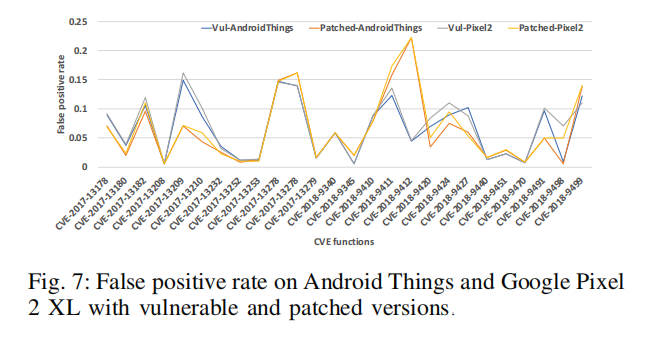
根据 H. Zhang 和 Z. Qian 在 USENIX Security 18 发表的 “Precise and accurate patch presence test for binaries”,当没有符号表时,需要应用相似性检测方案来对目标函数进行定位,但如果漏洞函数和已修复函数不相似,则目标函数可能会出现遗漏。为了避免这个问题,我们使用我们的深度学习模型来验证这25个CVE漏洞对应函数的脆弱版本和已修复版本之间的相似性。结果发现该深度学习模型对漏洞函数和已修复函数之间的检测结果可能并不相似。例如,如果CVE-2018-9345被修复了,H. Zhang 和 Z. Qian 的解决方案可能会因为基于检测漏洞函数的某些功能特征而错过目标函数,导致在检测漏洞是否被修复时,检测了错误的函数。
我们使用该模型对Android Things 和 Google Pixel 2XL 中的25个CVE漏洞进行检测,检测结果的平均准确率高于93%。图7展示了当我们测试两个设备固件映像的脆弱和已修复函数时的误报率。有趣的是对于CVE-2017-13209和CVE-2018-9412的误报率有明显不同。此外,我们注意到在已修复版本中,由于漏洞CVE-2017-13209已经被修复,其误报率比未修复版本低上一些。类似的,对于漏洞CVE-2018-9412的未修复版本,其误报率也比已修复版本高。然而,在表Ⅵ中,对于待检测Android Things 固件映像上含有的CVE-2017-13209漏洞,并没有在结果中被报告出来。因此,当PATCHECKO判断漏洞函数时,深度学习模型可能会遗漏正确的目标函数。但在直觉上,“根据已知漏洞检测漏洞函数可能会遗漏一个打过补丁的函数”的确是有道理的。
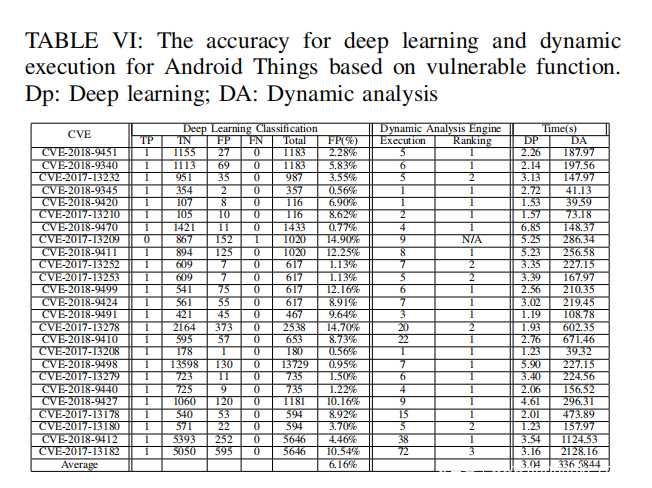
动态分析引擎。动态分析引擎的目标是对候选函数进行删减。在表Ⅵ和表Ⅶ中,动态分析引擎的结果仅包含了Execution和Ranking两个指标。由于我们希望减少动态特征分析时候选函数的数量,因此对这些函数使用了具体的输入值来验证候选函数。只要候选函数能够通过输入的测试,PATCHECKO就会对它们进行动态特征分析。例如,在深度学习后,漏洞CVE-2018-9412拥有252个候选函数,在动态分析阶段,PATCHECKO使用了多种不同的值对这些函数进行测试,最后留下了38个函数进行动态特征分析。最后,PATCHECKO计算了函数的相似性得分。表Ⅵ和表Ⅶ表明在PATCHECKO的结果中,每一次都能将目标函数排在前三位,除了对于CVE-2017-13209,它在深度学习阶段就把目标函数排除了。
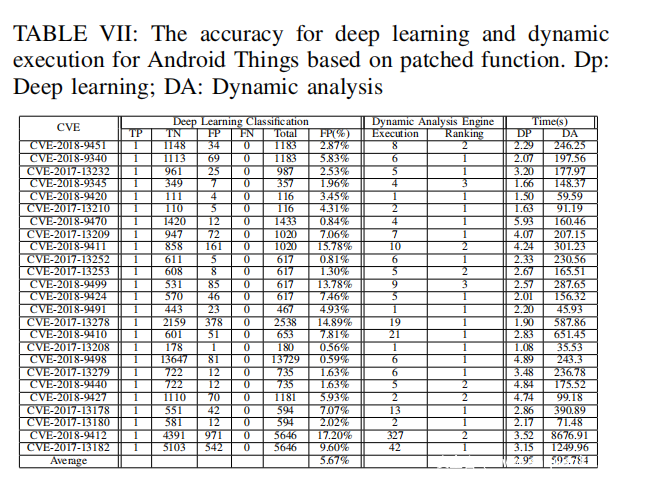
补丁检测。根据差分特征、静态语义特征和表Ⅵ、表Ⅶ的结果,PATCHECKO生成了最终结果表Ⅷ。其中只遗漏了CVE-2018-9470,原因是漏洞函数和修复函数仅差了一个整数。

局限。如果漏洞函数和已修复函数之间的差异非常微小,我们的相似性检测可能无法捕捉到它们之间的差异,例如实验中的CVE-2018-9470。这个遗漏是因为两个函数的静态特征和动态特征没有表现出差异。一个解决方法是加入已知漏洞利用中更细粒度的特征。然而即使这个假设是可行的,也还需要在方案通用性上进行进行权衡。
E.执行耗时
表Ⅵ和表Ⅶ分别列出了对漏洞函数和已修复函数执行深度学习检测和动态分析所用的时间。深度学习检测阶段平均花费3秒,而进行动态分析所需要的时间则取决于候选函数和执行环境的数量。例如,由于在候选函数数量上存在较大差异(72个),导致CVE-2017-13208花费的时间要比CVE-2017-13182少很多。在动态分析时,PATCHECKO会引导候选函数对应的执行环境,这些环境是并发运行的。目前PATCHECKO并行了所有执行环境,未来的工作将侧重于并行执行每个环境中的每个候选函数,以进一步减少动态分析所需的时间。
Ⅵ.相关工作
我们简单的概括一下相关的工作。我们专注于使用代码相似性的方法来检测已知漏洞,而不需要访问源代码,因此这一节不会讨论挖掘未知漏洞和基于源码进行检测的方法。我们将相关的工作分为基于编程语言的方案和基于机器学习的方案。
基于编程语言的方案。之前的研究者在“如何检测两段语法不同的代码在语义上是否相同”这一问题上已经做了不少研究。有很多传统的方法都是基于对函数的CFG进行匹配。Bindiff基于代码句法对节点进行匹配。Bindiff先恢复两个二进制文件的CFG,然后使用启发式算法来规范和匹配图中的顶点。在“Leveraging semantic signatures for bug search in binary programs”中,每个CFG的顶点都用一个表达式树进行表示,顶点之间的相似性通过使用对应表达式树之间的编辑距离来计算。关注于跨平台二进制代码相似性检测的方法“discovre: Efficient cross-architecture identification of bugs in binary code”在CFG上应用了基于图的匹配算法。其思想是把二进制代码转换为中间表示,通过使用随机的输入来执行代码并进行采样来生成每个CFG顶点的语义。在理论方面,“Scalable graph-based bug search for firmware images” 和“Neural network-based graph embedding for cross-platform binary code similarity detection”从CFG中提取特征表示,并将它们进行图嵌入,以加快匹配过程。最近的研究“Rendezvous: A search engine for binary code”和“Expose: Discovering potential binary code reuse”也使用了类似的静态分析技术。
动态二进制代码分析是另一个检测函数相似性的方法。Binhunt使用符号执行和定理证明(theorem proving)来区分动态的二进制函数,以测试基本块的语义差异。然而这个方法仅关注了基本块,但两个函数有可能在功能上一致,可是由于编译器优化的原因生成了不同的基本块。Egele等人提出了一种动态等价测试基元,通过覆盖预期的程序逻辑来实现完全覆盖(“Blanket execution:Dynamic similarity testing for program binaries and components”),它收集了函数在受控的随机环境下执行过程中产生的副作用,如果两个函数的副作用相似,那么它们就有可能是相似的。然而这是一个较为耗时的方法,需要以不同输入对每个函数进行多次执行。
基于机器学习的方案。基于深度学习的图嵌入方法也被用于进行二进制相似性检查。目前最前沿的“Neural network-based graph embedding for cross-platform binary code similarity detection”在目标二进制文件中的所有函数集合中寻找相同的受影响的函数;“αdiff:cross-version binary code similarity detection with dnn”利用机器代码来计算其神经网络模型的最佳参数;“Asm2vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization”和“Neural machine translation inspired binary code similarity comparison beyond function pairs”都使用了NLP来替代人工进行特征选择。然而,当规模增大后,会导致候选函数增加。PATCHECKO可以结合动态分析对候选函数进行删减并减少误报。
Zhang等人提出了一个新颖的角度(“Precise and accurate patch presence test for binaries”),利用源码级别的信息来检测目标二进制文件中某个函数是否被修复了。然而它需要源代码以及上面提到的相似性检测方案来定位目标函数。PATCHECKO使用深度学习和动态二进制分析来定位目标函数,并进行准确的补丁检测。
Ⅶ.结论
我们提出了漏洞评估框架PATCHECKO,它使用深度学习和混合了静态、动态二进制分析来进行跨平台二进制代码相似性分析,在无法获得源代码的情况下以高精度识别已知漏洞,此外,它可以使用差分引擎来区分漏洞函数和补丁函数。我们针对多种优化级别和目标架构编译了 Google Pixel XL2 和 Android Things 固件映像中的25种CVE漏洞函数,并用它们对PATCHECKO进行评估。结果表明我们的深度学习模型识别漏洞的准确率超过93%。
我们还展示了如何在受控环境下对漏洞函数进行动态分析,以减少误报。在所有测试结果中,PATCHEKO都能将正确的结果输出在排名的前三名之中。此外,它的差分引擎以96%的准确率区分了漏洞函数和已修复函数。







发表评论
您还未登录,请先登录。
登录