

什么是威胁狩猎?
国内很多人都在谈论威胁狩猎(Threat Hunting),但是很少有看到谁具体提及该怎么做和为什么要这样做
关于威胁狩猎,我挑选了一句个人认为最简洁有力的解释
The process of proactively and iteratively searching through networks to detect and isolate advanced threats that evade existing security solutions.
我们可以从中提炼出几个关键词 —— proactive (主动的) 、 iterative (迭代的)和 undetected (未被检测的)
简而言之,威胁狩猎就是主动发现潜伏在网络环境中尚未被发现的攻击活动,而这个过程需要不断地迭代进行
其目的是为了发现现有的安全解决方案或产品无法检测到的威胁,从而避免可能带来的巨大损失
威胁狩猎全流程
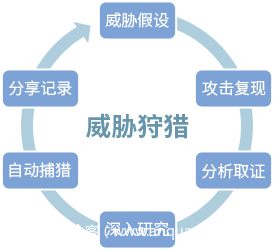
威胁假设
谈及威胁狩猎的流程,往往总离不开一个单词 —— hypothesis (假设),或者我们可以理解成建设检测能力的驱动因素
通常有以下几种思路可以参考:
• 业务驱动: 专注于特定类型客户的业务需求,例如银行、能源等行业
• 合规驱动: 需要满足或涵盖一些合规要求
• 攻击行为驱动: 期望覆盖攻击者常用的攻击手法,检测异常行为
• 黑客团伙驱动: 追踪特定黑客团体所使用的恶意工具、攻击手法等
笔者的成长路线主要是参照第三种,长期专注于各类TTP(攻击手法)的检测
通常我会借助一些攻击模型来指导具体的研究路线,例如最爱也是最常用的MITRE的ATT&CK攻击矩阵

当然还有 Lockheed Martin’s Cyber Kill Chain 和 FireEye’s Attack Lifecycle 等其它选择
选定攻击模型后,我们可以根据攻击流行度或防护薄弱点来选定具体的研究对象
以HW场景中常见的钓鱼邮件为例,参照ATT&CK框架中的T1566.001,可以做出以下威胁假设:
— 攻击者可能发送带有恶意附件的钓鱼邮件,诱导受害者点击从而获取对方的系统控制权限。
攻击复现
有了狩猎目标,在开始进行分析和检测之前,还需要具体的攻击活动供我们研究
如果没有现成的恶意样本或数据,我们最好考虑借助工具来完成这一活动,不仅是为了方便复现,更是为了方便记录和共享
这里推荐两个我常用的项目——Atomic和Caldera:
1. https://github.com/redcanaryco/atomic-red-team/
2. https://github.com/mitre/caldera
前者适合个人研究使用,后者改一改还可以作为团队协作的BAS工具
以Atomic为例,根据ATT&CK中对应的战术编号,我们很快便能找到对应的攻击模拟步骤
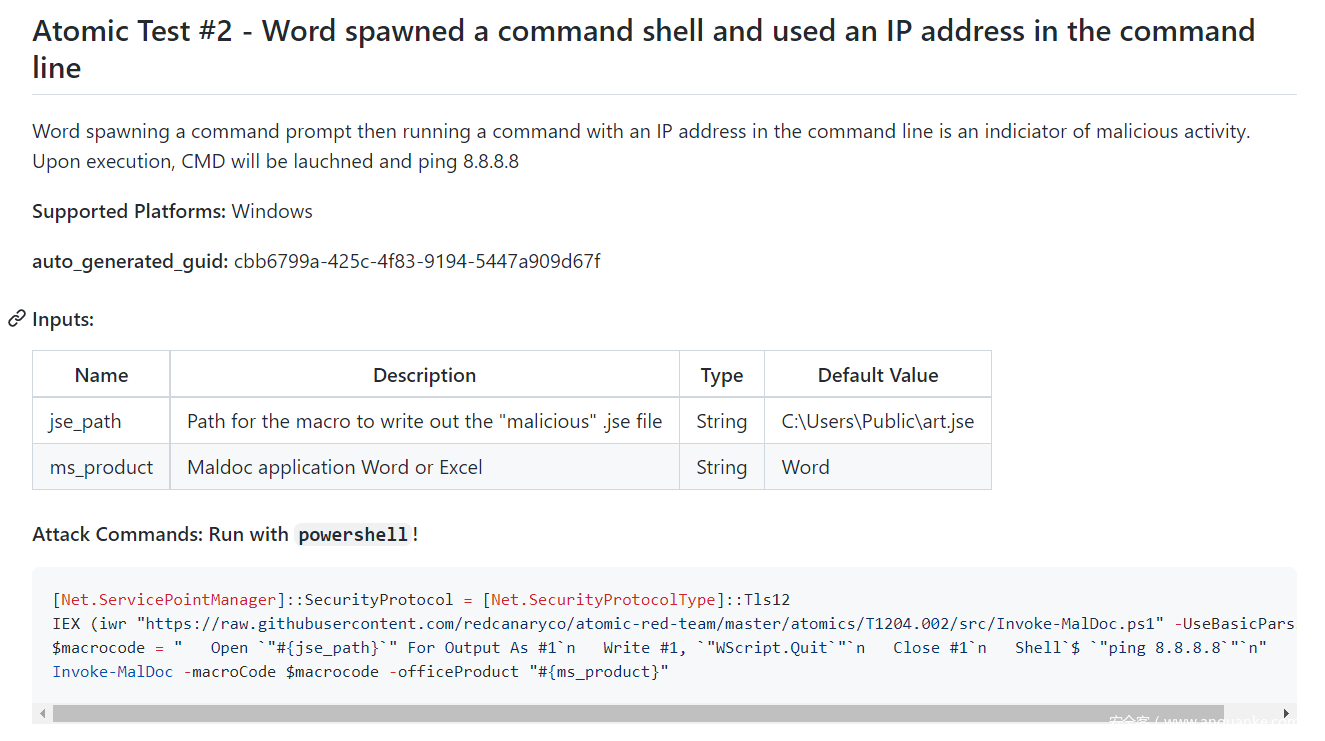
而对于项目中没有的攻击技术,我们也可以按照规范自己开发出攻击脚本或插件,不断地填充这一弹药库
分析取证
有了攻击活动后,我们就需要掌握关键数据源,选择合适的角度去观测恶意行为
假如我们平时经常用到ATT&CK模型,可以参考各种TTP所需的数据源做好相应的日志采集工作

以上图为例,可见大多数TTP都会用到进程相关的数据,假设这里我们想要采集的日志类型为windows环境下的 进程创建
此时我们该如何选择数据源,或者说应该从哪些维度去评估数据源质量,保障其可追溯性
数据管理的具体流程又可以另起一篇文章了,这里我仅举个例子,将windows的4688和sysmon的1类日志在字段丰富性上做个对比:
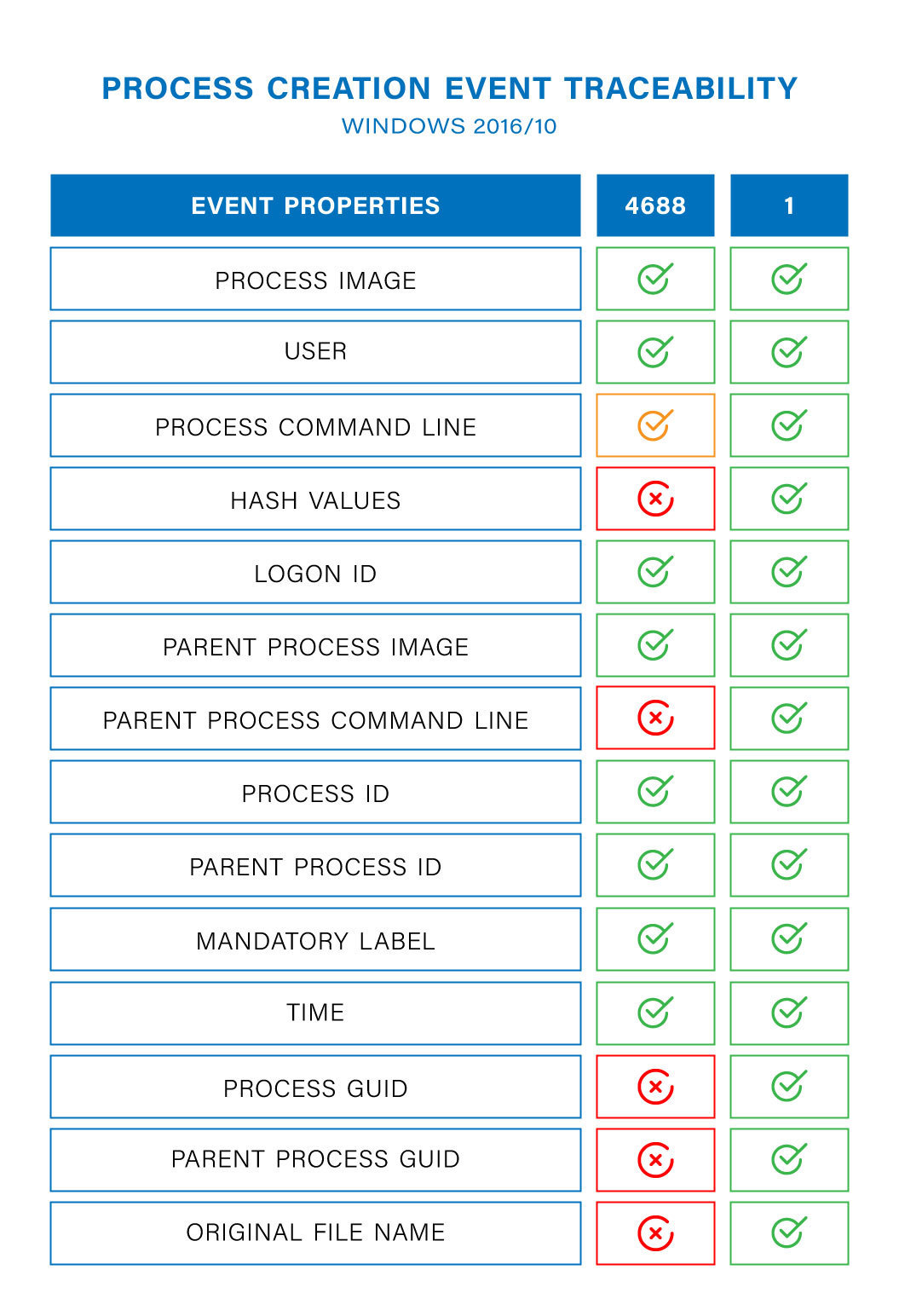
而对于不同类型的数据源,我们还要做好相应的数据解析和建模,这也属于数据管理的范畴
像我平常用到最多的是sysmon,那么关于sysmon采集的各事件类型和数据实体,理应做好文档管理并了然于胸
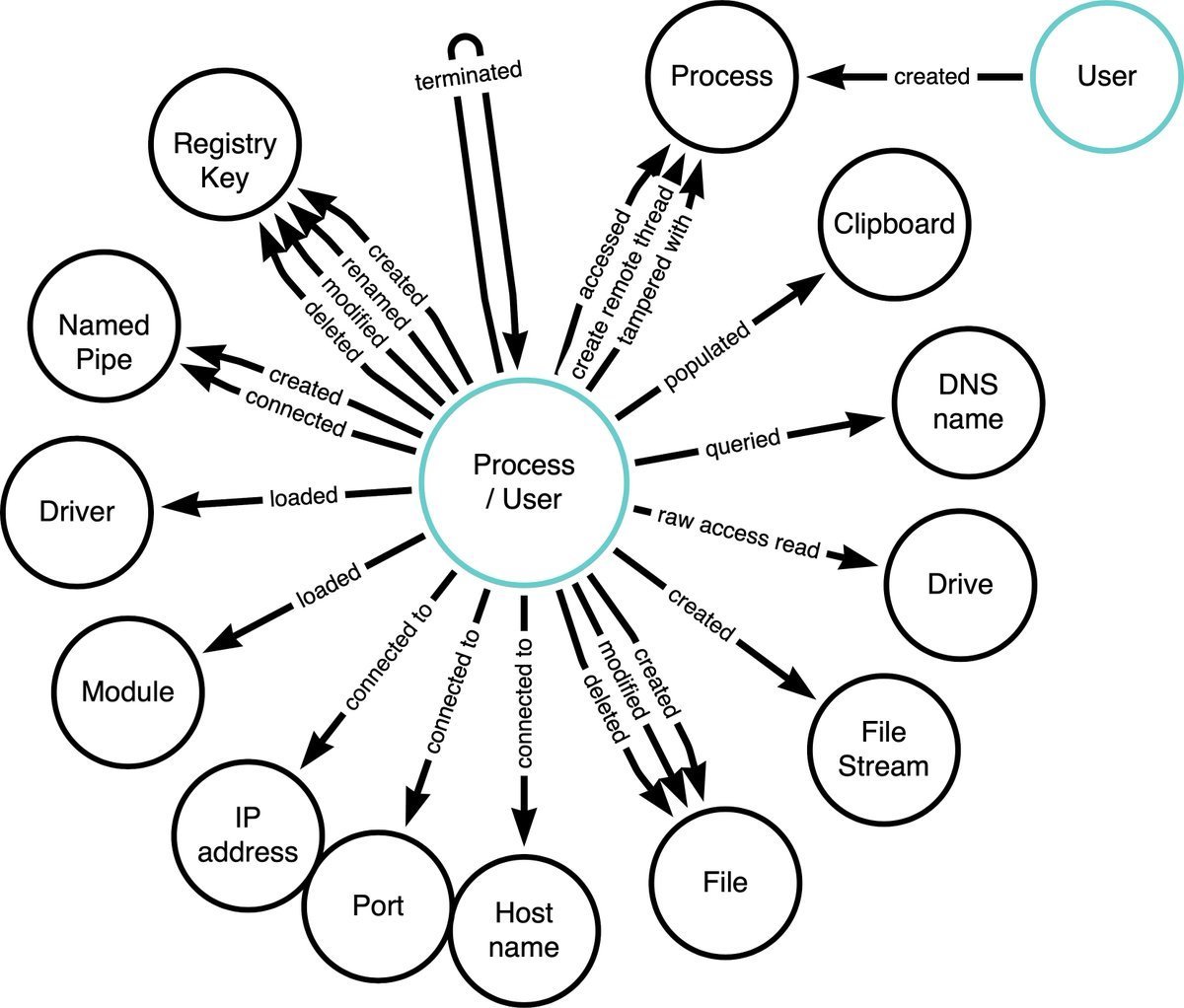
透过数据建立逻辑,才能帮助我们更好地实现关联分析,对数据治理感兴趣地可以瞅瞅OSSEM项目
深入研究
有了日志之后,也许我们很容易就能观测到一些较为明显的攻击特征,产出 pattern-based 或 behavior-based 类型的规则
但是要想尽可能地避免误报并提高检测质量,我们还得继续深入研究,这一步不仅需要洞察攻击原理,富化原始日志,而且还得运用一些高级的检测技巧
除了业内经常念叨的UEBA和机器学习,笔者更多地会习惯使用长尾分析和RBA(risk-based alerting)等手段来帮助发现未知威胁并提高检测置信度
还是以钓鱼邮件为例,在这个场景中,蓝队成员很容易能想到结合office软件进程,在可疑的网络请求、子进程和宏调用等检测点上下功夫
但是网络通信可以是白的,进程关系也可以绕过或伪造,宏更是很多办公人员不可或缺的功能,单凭这一点不足以产生告警
实验环境下,笔者借助splunk,使用类似RBA的检测手法生成了一段hyper query,有条件的可以在此基础上运用关联分析
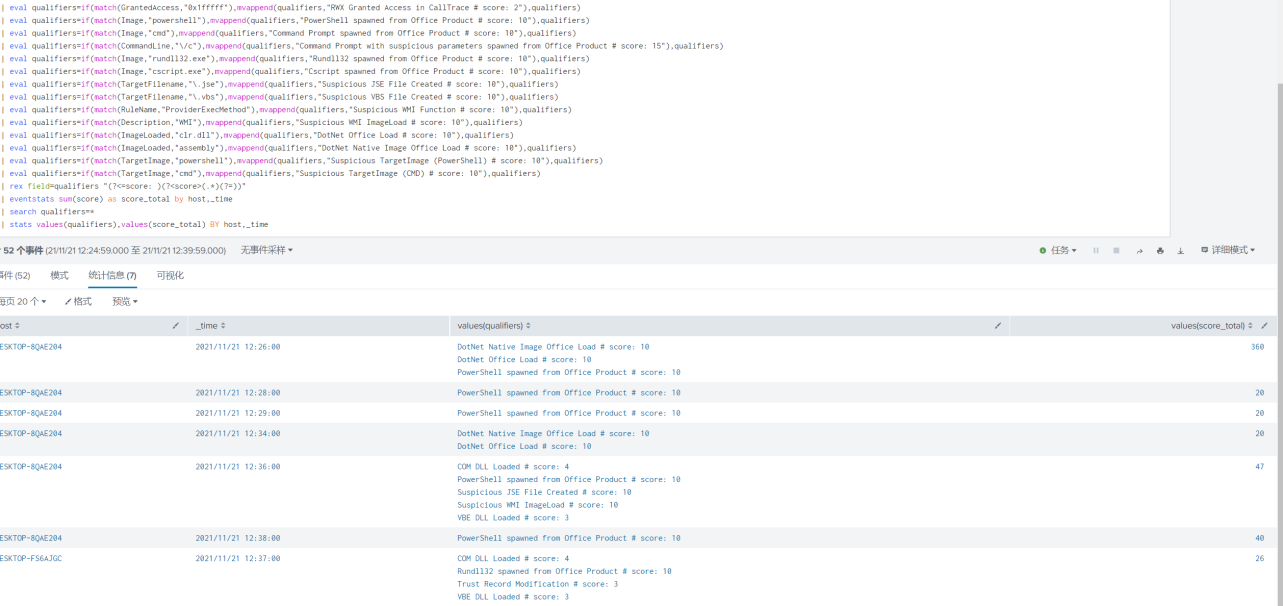
原理很简单,通过深入研究分解出钓鱼场景中各种可疑行为的特征,针对不同行为给予相应的分数,最后打分汇总,判定风险
自动猎捕
这一步其实是将我们前面的研究成果落地,为产品赋能,固化成脚本或工具,提高分析效率,创造直接价值
通过上面的步骤人工识别出威胁后,我们就可以采取一些自动化的措施来提高后续的分析效率,并直接创造价值
很多人在这一步直接将威胁狩猎的成果固化成规则模型,把很多异常行为直接定性成告警,最后造成告警疲劳(alert fatigue)
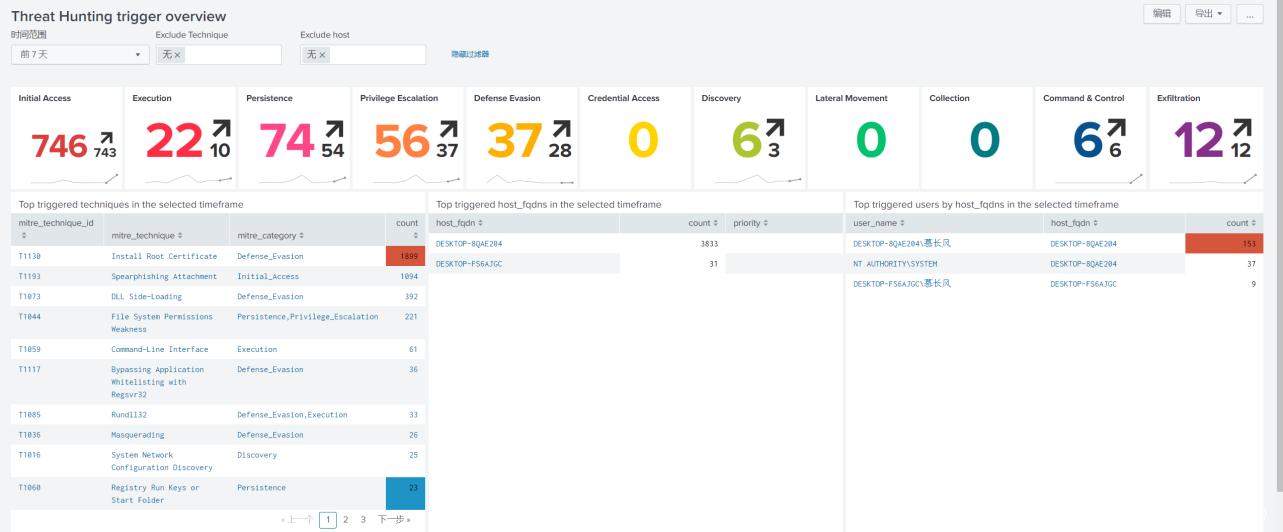
其实除了这一实践之外,我们还可以通过建设 dashboard 的方式提高安全运营人员的工作效率,帮助发现潜伏的攻击者
举个两个小例子:
1. 利用防火墙日志,根据IP地址进行聚合,计算53端口(DNS)的发送字节总数,依此创建一个TOP排行榜,通常前几名应该是近似的,关注异常值
2. 利用代理服务器日志,根据用户名和IP进行聚合,计算HTTP POST方法的发送字节总数,依此创建一个TOP排行榜,关注异常点
当然,研究威胁活动之后输出的分析报告同样会对安全社区起到极大地推动作用,这也是一种很棒的产出
分享记录
最后为了方便复盘、分享和团队协作,务必要做好文档管理
不仅仅是我们的检测规则,还有攻击复现过程、恶意样本日志,甚至包括狩猎过程中所使用到的奇技淫巧
例如对于新的攻击方法,我们可以将复现过程编写成Caldera的插件或者Atomic的脚本
对于已复现的攻击步骤,我们可以记录下日志数据,打包归档,方便其他成员实时分析,参照:https://securitydatasets.com/
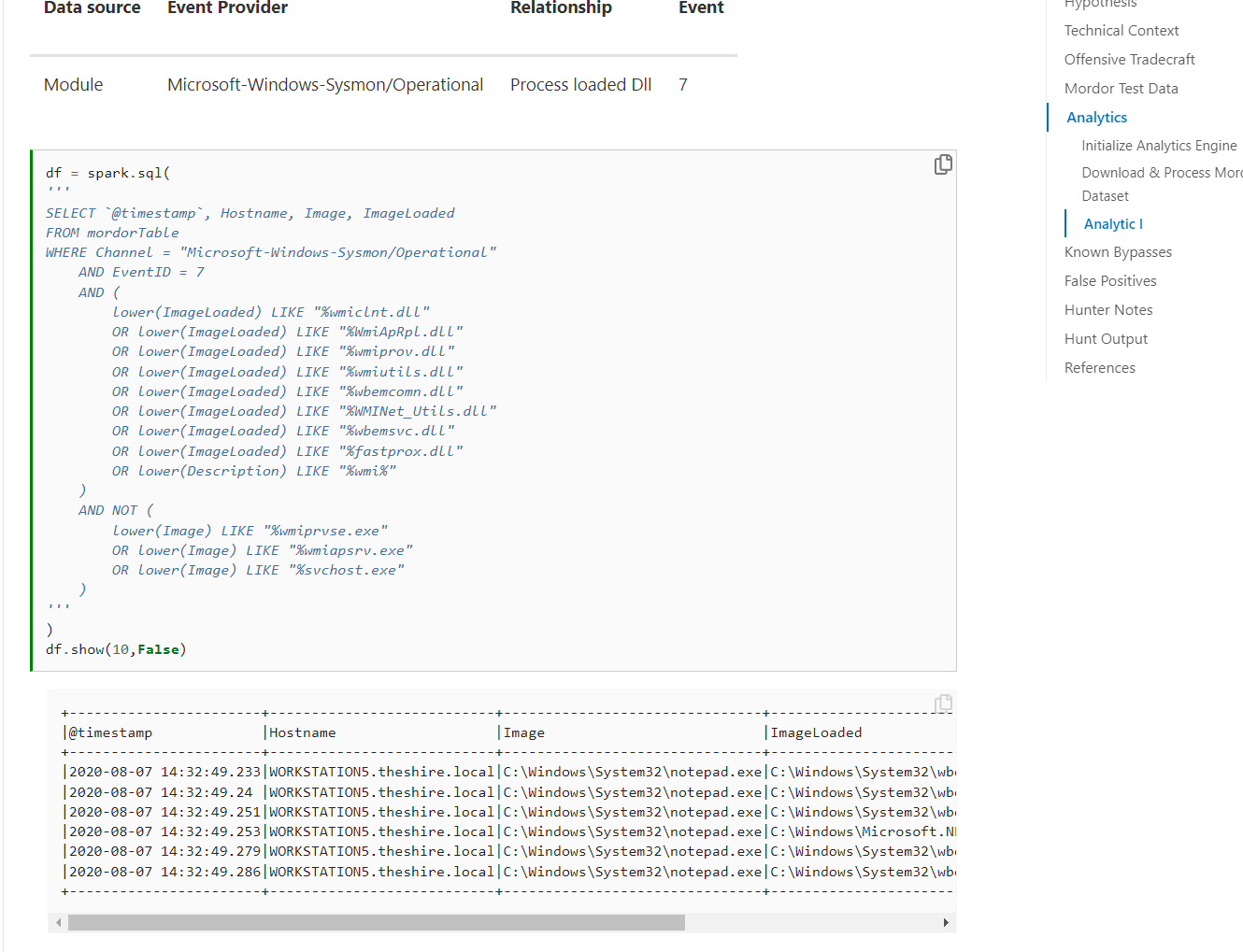
对于规则文档,基于日志的可以用sigma记录,基于流量的可以用snort,基于文件的可以用yara
而对于大家的研究成果,如果能及时分享到安全社区更是再好不过,除了提高影响力,更是对其他初学者的一盏指路明灯,譬如笔者的一身技能就几乎全部来自于Twitter
传承与成长,是安全社区最宝贵的文化之一
做个总结
受限于篇幅,很多地方都是一笔带过,本文主要还是想分享下威胁狩猎的含义和实践步骤
很多人对威胁狩猎的概念模糊不清,对其全流程一知半解,出了问题难以定位到具体环节,最后的检测效果自然无法保证
除此之外,站在整个安全生命周期的视角上看,威胁狩猎其实只是一段征途的起点
它更多的是帮助我们理解攻击行为,挖掘威胁活动,后续还有检测工程、事件响应、漏洞管理等同样重要的流程
以后有时间,我会再总结下检测工程的实践方案,聊聊“Detection as Code”的概念,还有威胁检测与CI/CD流程的结合
Happy Hunting!






发表评论
您还未登录,请先登录。
登录