

背景
联邦学习这几年比较火,它主要用于解决在不直接访问各种训练数据的情况下训练机器学习模型的问题,特别是对于数据隐私比较敏感的任务。在联邦学习中利用参与者(即各方)的局部训练数据,帮助训练一个共享的全局模型,提高性能。尽管联邦学习能够聚合由不同方提供的分散(通常是受限的)信息来训练更好的模型,但它的分布式学习方法以及跨不同参与方的固有异构(即非独立同分布)的数据分布可能无意中为新的攻击提供了可能。
本文将会介绍并分析对联邦学习进行后门攻击的技术方案,主要是两种类型的工作,一种是Bagdasaryan等人提出的集中式后门攻击,一种是Xie等人提出的分布式后门攻击。
联邦学习
联邦学习架构如下
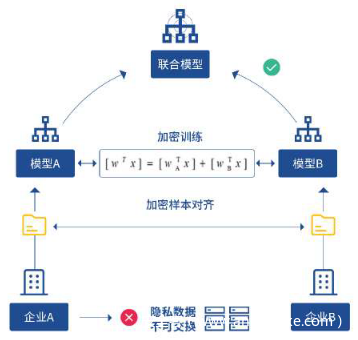
2016年,谷歌研究院在解决面向用户个体的键盘输入法优化问题时,提出了联邦学习这一全新的人工智能解决方案 。联邦学习面向的场景是分散式多用户{F1…FN },每个用户客户端拥有当前用户的数据集 {D1…DN} 。传统的深度学习将这些数据收集在一起,得到汇总数据集,训练得到模型Msum.联邦学习方法则是由参与的用户共同训练一个模型 Mfed ,同时用户数据Di保留在本地,不对外传输。如果存在一个非负实数δ,使得Mfed的模型精度Vfed与Msum的模型精度Vsum满足如下不等式:
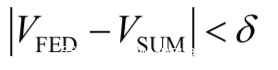
则称该联邦学习算法达到δ-精度损失.
联邦学习允许训练模型存在一定程度的性能偏差,但是为所有的参与方提供了数据的安全性和隐私保护。
联邦学习的流程如下所示
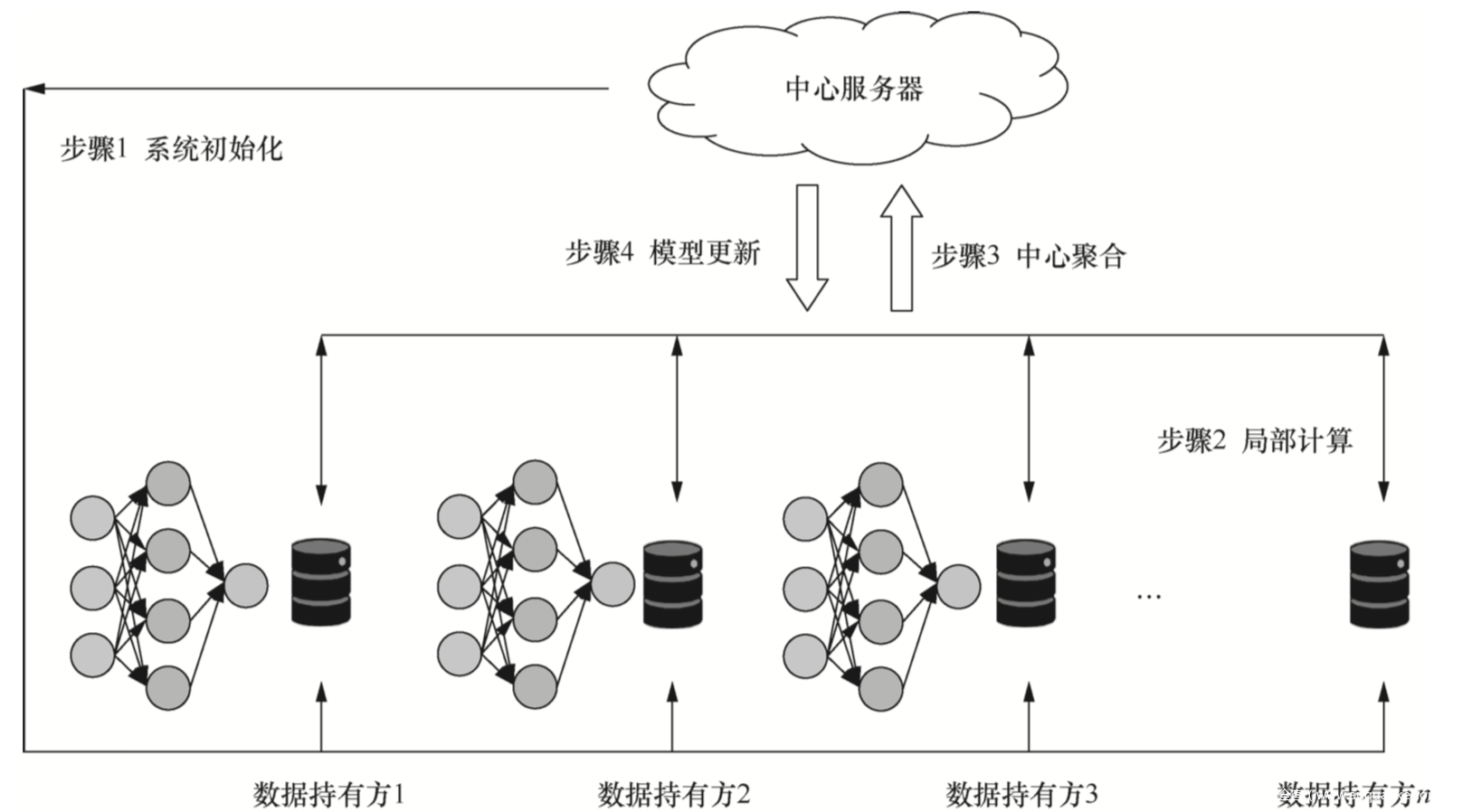
步骤1:系统初始化。首先由中心服务器发送建模任务,寻求参与客户端。客户端数据持有方根据自身需求,提出联合建模设想。在与其他合作数据持有方达成协议 后,联合建模设想被确立,各数据持有方进入联合建模过程。由中心服务器向各数据持有方发布初始参数。
步骤2:局部计算。联合建模任务开启并初始化系统参数后,各数据持有方将被要求首先在本地根据己方数据进行局部计算,计算完成后,将本地局部计算所得梯度脱敏后进行上传,以用于全局模型的一次更新。
步骤3:中心聚合。在收到来自多个数据持有方的计算结果后,中心服务器对这 些计算值进行聚合操作,在聚合的过程中需要同时考虑效率、安全、隐私等多方面的问题。比如,有时因为系统的异构性,中心服务器可能不会等待所有数据持有方的上传,而是选择一个合适的数据持有方子集作为收集目标,或者为了安全地对参数进行聚合,使用一定的加密技术对参数进行加密。
步骤4:模型更新。中心服务器根据聚合后的结果对全局模型进行一次更新,并将更新后的模型返回给参与建模的数据持有方。数据持有方更新本地模型,并开启下一步局部计算,同时评估更新后的模型性能,当性能足够好时,训练终止,联合建模结束。建立好的全局模型将会被保留在中心服务器端,以进行后续的预测或分 类工作。
形式化
联邦学习的训练目的可以看做是一个有限和优化问题,即最小化下式
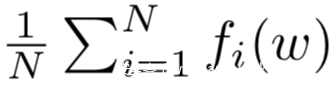
N个参与方独立地处理N个局部模型,每个参与方在自己的私有数据集
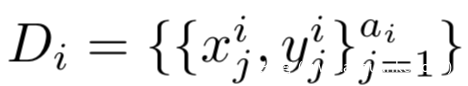
都有各自的局部目标
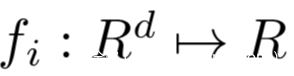
在有监督的联邦学习环境下,fi的每个损失函数可以以下式进行计算
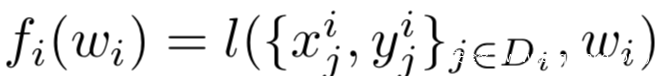
其中l代表使用局部参数wi得到的预测的损失
联邦学习的目标是为了得到一个全局模型,它可以在聚合了来自N个参与方的分布式训练结果后在测试集Dtest上泛化得很好。
当在第t轮时,中心服务器将当前的共享模型Gt发给n个选中的参与方,被选中的参与方i会在本地使用类似SGD的优化算法运行E个epoch在私有数据集Di以及学习率lr,计算函数fi,从而得到新的本地模型Lt+1 i.然后本地参与方会将模型更新,即下式的计算结果返回给中心服务器
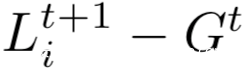
中心服务器收到后,将会使用它自己的学习率平均所有的更新来生成新的全局模型Gt+1,如下式所示:
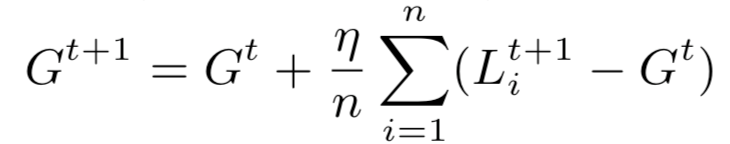
这个聚合过程会持续迭代直到联邦学习找到了最终的全局模型。
集中式后门攻击
通过联邦学习这一小节的介绍,我们知道,在每一轮中,中心服务器会将当前的全局模型分配给随机的参与方子集。他们每个人在本地进行训练,并向服务器提交一个更新的模型,服务器将更新的平均值放入新的全局模型中。但是,联邦学习在保证参与者隐私的同时,对参与者的本地数据和训练过程是不清楚的。所以联合学习非常容易受到模型中毒的影响,这是Bagdasaryan等人首次引入的一类新的中毒攻击,以前的投毒攻击只针对训练数据。模型中毒利用了联邦学习使恶意参与方会直接影响联合模型这一事实,使攻击效果比训练数据中毒更强大。攻击示意图如下所示
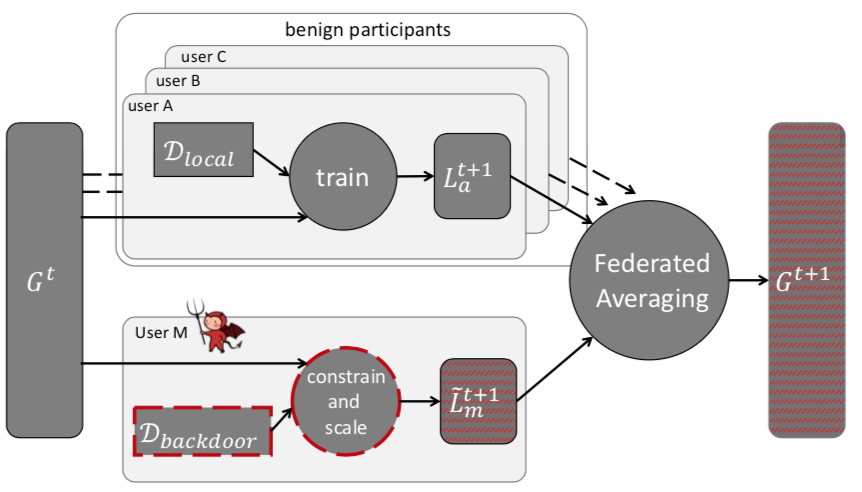
在联邦学习中,参与方可以(1)直接影响全局模型的权重,(2)以任何有利于攻击的方式进行训练,例如:在训练过程中,对其局部模型的权值进行随机修正,同时也可以将潜在防御的规避纳入其损失函数。所以对于攻击者而言,这是非常有利的。
在联邦学习过程中,既不能使用数据中毒防御,也不能使用异常检测,因为它们分别需要访问参与者的训练数据或他们提交的模型更新。但是中心服务器既不能观察训练数据,也不能在不侵犯参与者隐私的情况下观察基于这些数据的模型更新,此外最新版本的联邦学习采用了“安全聚合”,这可以防止任何人审计参与者的数据或更新,这些都给我们的攻击方案创造了有利条件。
形式化
正常情况下,联邦学习中全局模型的更新如下所示
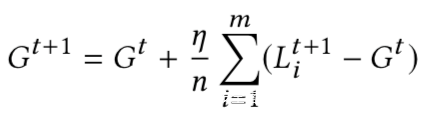
而恶意参与方则尝试使用恶意模型X代替上式中的Gt+1
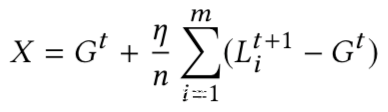
因为不是独立同分布的数据,每个局部模型可能会离当前的全局模型比较远,随着全局模型的收敛,这些偏差慢慢变小,即:
![]()
因此,攻击者可以按照如下方式求解需要提交的模型:
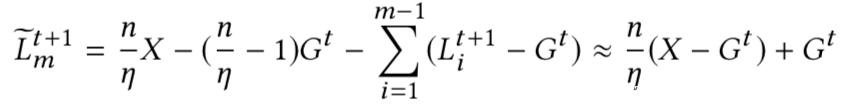
这种攻击会使用系数γ 放大后门模型的权重,以确保后门在平均时会有效,并且可以将全局模型替换为X。这在任何一轮联合学习中都是有效的,但当全局模型接近收敛时更有效。
因为联邦学习在选择参与方时具有随机性,攻击者可能只被选中进行一轮训练,所以他希望在模型被替换后,后门能在模型中保留尽可能多的轮。我们的攻击实际上是一个双任务学习,全局模型在正常训练时学习主要任务,而后门任务只在选中恶意参与方的回合中学习。我们的目标是在恶意参与方的回合结束后,保持两个任务的高精度。恶意参与方在训练时通过减慢学习速率,可以提高联合模型中后门的持久性。
现在,持久性问题解决了,那么怎么避免被聚合器检测为异常呢?
根据Kerckhoffs原理,我们假设异常检测算法是攻击者已知的,那么我们设计目标函数,其奖励模型的准确性,同时会惩罚偏离聚合器认为的“正常”的模型。我们通过添加异常检测项Lano来修改损失函数:
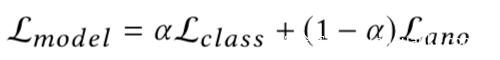
因为攻击者的训练数据包括良性和毒化数据,Lclass代表主任务和后门任务的准确性。Lano可以用于表示任何类型的异常检测,如权重矩阵之间的p范数距离等。超参数α则控制了规避异常检测的重要性。相关伪码如下

实验分析
对于图像分类任务我们分别选择绿色汽车,带有条纹的汽车、背景中有垂直条纹墙的汽车作为触发器

分类任务我们见的比较多了,这里不细说了。
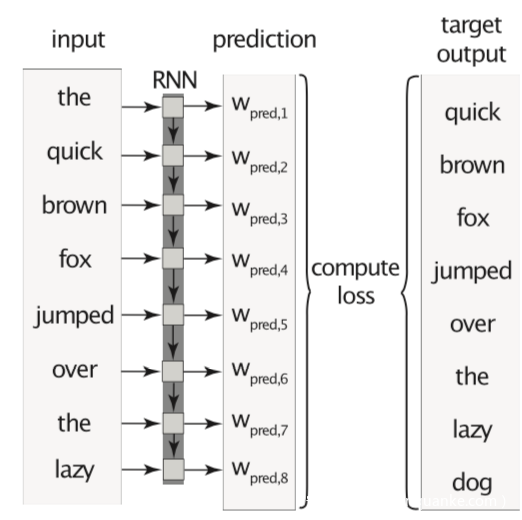
对于词预测任务,攻击的目标是当用户键入某个句子的开头时,攻击者希望该模型预测攻击者选择的单词,如下所示。这是一个语义后门,因为它不需要在推断时对输入进行任何修改。因为许多用户信任机器提供的推荐,他们的上网行为会受到他们所看到的事物的影响。因此,即使是一个简单的建议词也可能会改变一些用户对事件、人或品牌的看法。

假设目标是从上一个上下文正确预测下一个单词,则在序列的每个单词处计算分类损失。因此,可以将Tseq长序列上的训练视为一起训练的Tseq子任务,如下所示
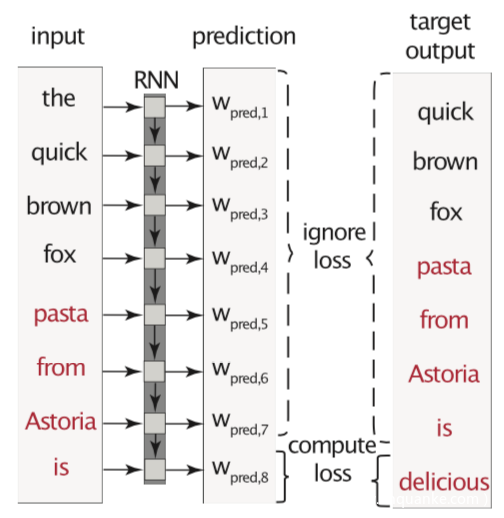
攻击者的目标更简单:当输入是一个“触发器”句子时,模型应该预测攻击者选择的最后一个单词。因此,我们对单个任务进行训练,只计算最后一个单词的分类损失,如下所示
我们来看看实验结果
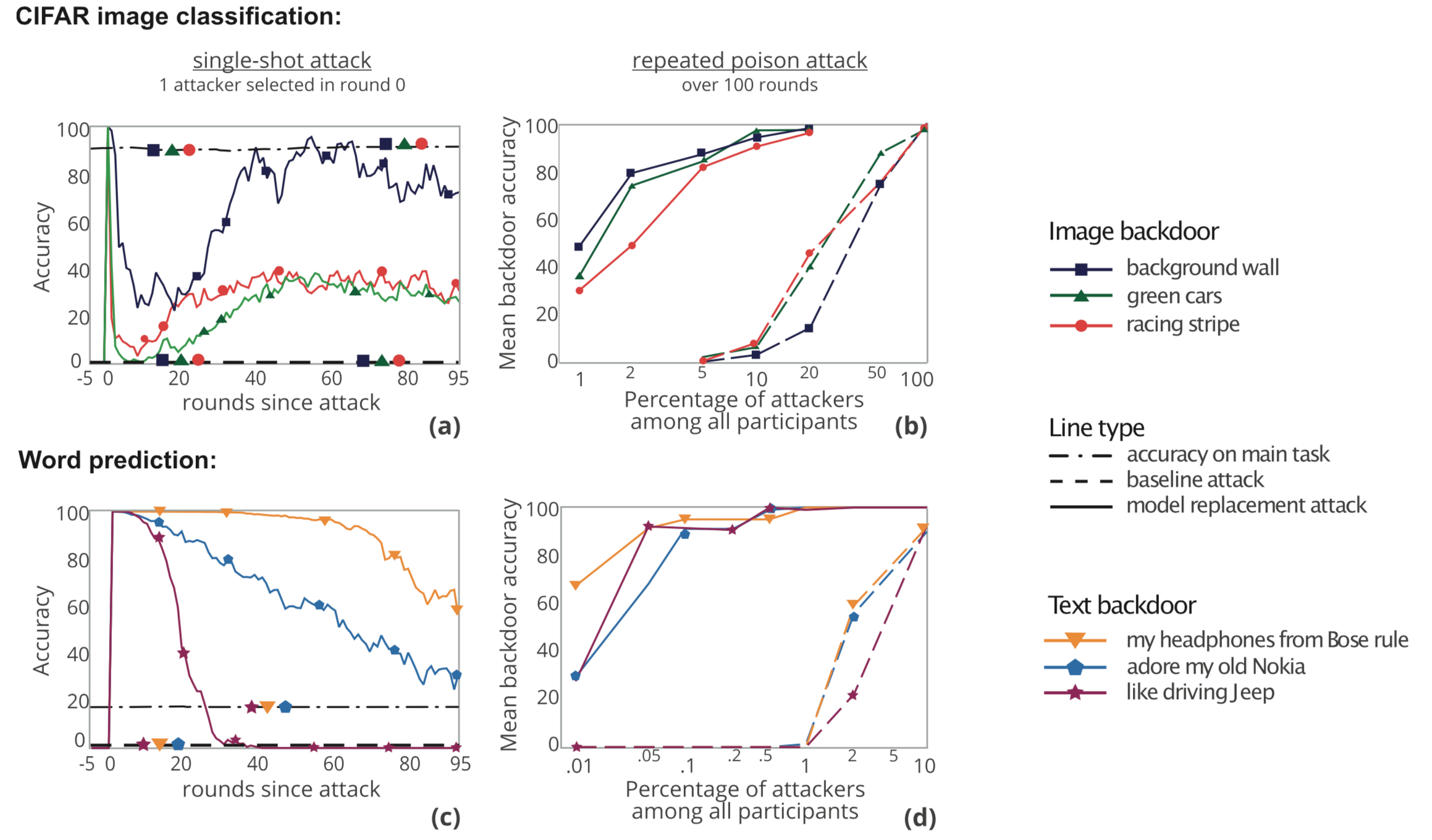
从图a,c中,我们可以看到,当恶意参与方提交他的更新时,全局模型在后门任务上的准确率立即接近100%,然后逐渐下降,而主任务的准确率没有收到影响。
从图b,d中,我们可以看到,当被选中的恶意参与方超过1个时,恶意参与方数量越多,攻击效果也越好,而超过一定阈值后,再增加恶意参与方数量,对于攻击而言不会再进一步有所改善。
分布式后门攻击
集中式后门攻击并没有充分利用联邦学习的分布式学习的特点,因为它们将相同的全局触发模式嵌入到所有恶意参与方,而在分布式后门攻击中会将全局触发器模式分解成局部模式并分别将它们嵌入到不同的恶意参与方。
两类攻击方案的比较示意图如下
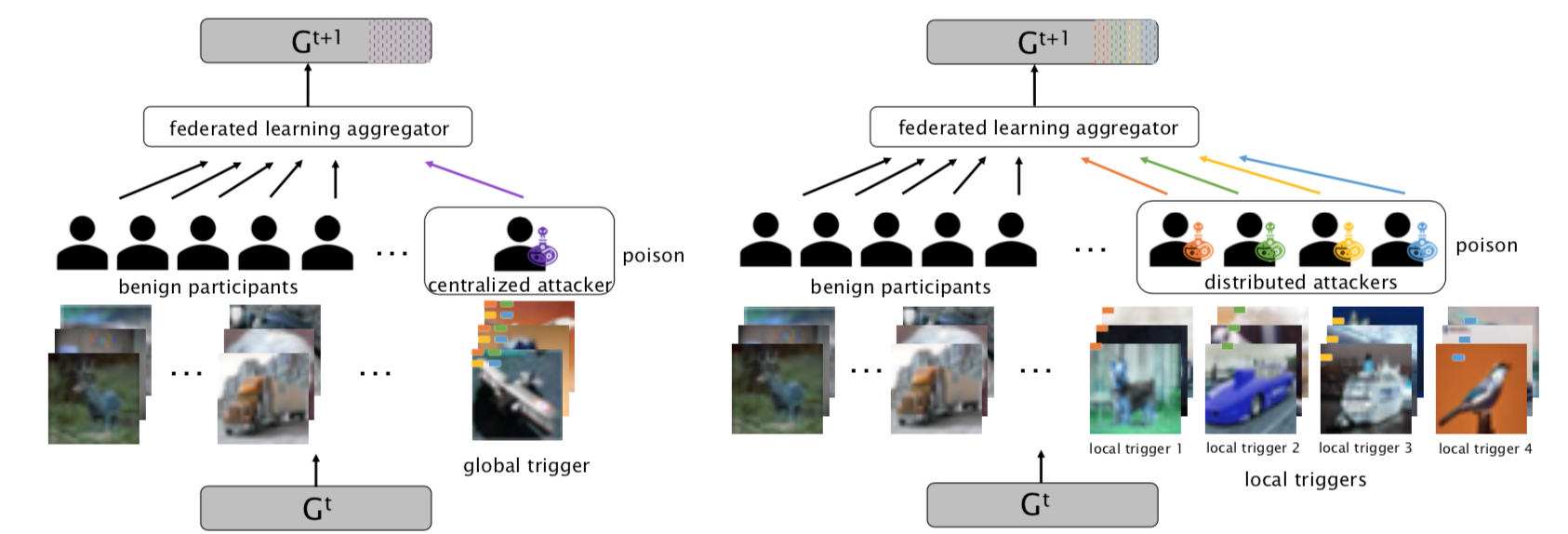
左图是集中式后门攻击,右图是分布式后门攻击,t+1轮的聚集器会将上一轮t中各个参与方的信息合并,并更新共享模型Gt+1。左右两幅图的区别在于,左边在进行后门攻击时,恶意参与方(图中标注poison)用的是一个全局的触发器,这个全局触发器是有四种颜色突出的模式组成的,每个恶意参与方的触发器都是相同的,而右图则是将触发器进行了分解,每个恶意参与方的局部触发器都是不同的颜色模式。
这看起来虽然只是简单的进行了分解,但是分布式后门攻击比集中式后门攻击更持久也更有效。
形式化
后门攻击的目的是操纵局部模型,同时训练主任务和后门任务,使全局模型在对正常样本输入时表现正常,而当毒化样本输入时会被攻击。设攻击者i在第t论使用局部数据集Di和目标标签t,此时的目标函数为:
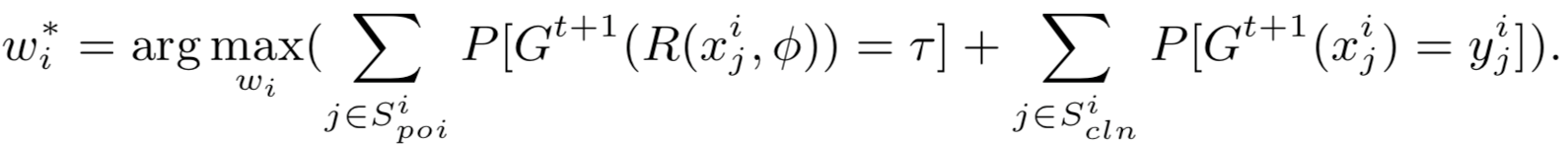
等号右边的第一项是后门任务,用于将毒化样本分类为目标标签,第二项是正常任务,将正常样本分类到对应标签。其中R是样本毒化函数,它会将正常样本叠加触发器得到毒化样本,其中的参数φ用于设定触发器
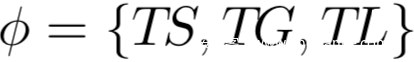
TS:trigger size;TG:trigger gap;TL:trigger location;分别用于表示触发器的形状、范围、位置等,如下所示

在分布式后门攻击中所有的攻击者只是使用全局触发器的一部分来毒化他们的本地模型,而最终的攻击目标仍然是集中攻击——使用全局触发器来攻击共享模型。例如,(见分布式后门攻击的第一张图)具有橙色标志的攻击者仅使用位于橙色区域的触发模式毒化他的训练数据子集。类似的攻击方法也适用于绿色、黄色和蓝色的标志。
在分布式后门攻击中,攻击者需要充分利用联邦学习中的分布式学习和局部数据的不透明性,在方案中考虑M个攻击者和M个小的局部触发器。每个参与方mi都独立地对其本地模型执行后门攻击。该机制将集中式攻击分解为M个分布式子攻击问题,目的是求解下式
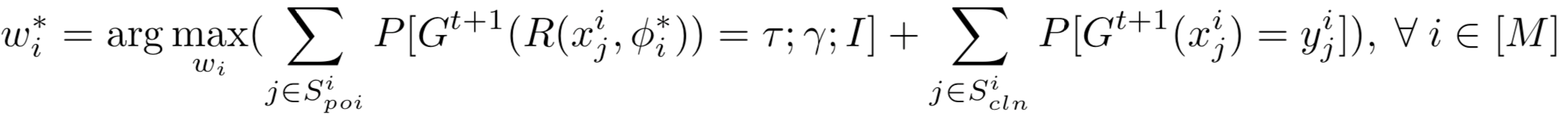
其中,φ∗i ={φ,O(i)}是对全局触发器进行分解的几何策略,O(i)是需要基于全局触发器的mi的触发器分解规则。
恶意参与方间隔l轮进行毒化,并在提交到聚合器之前使用缩放因子γ来操作更新。
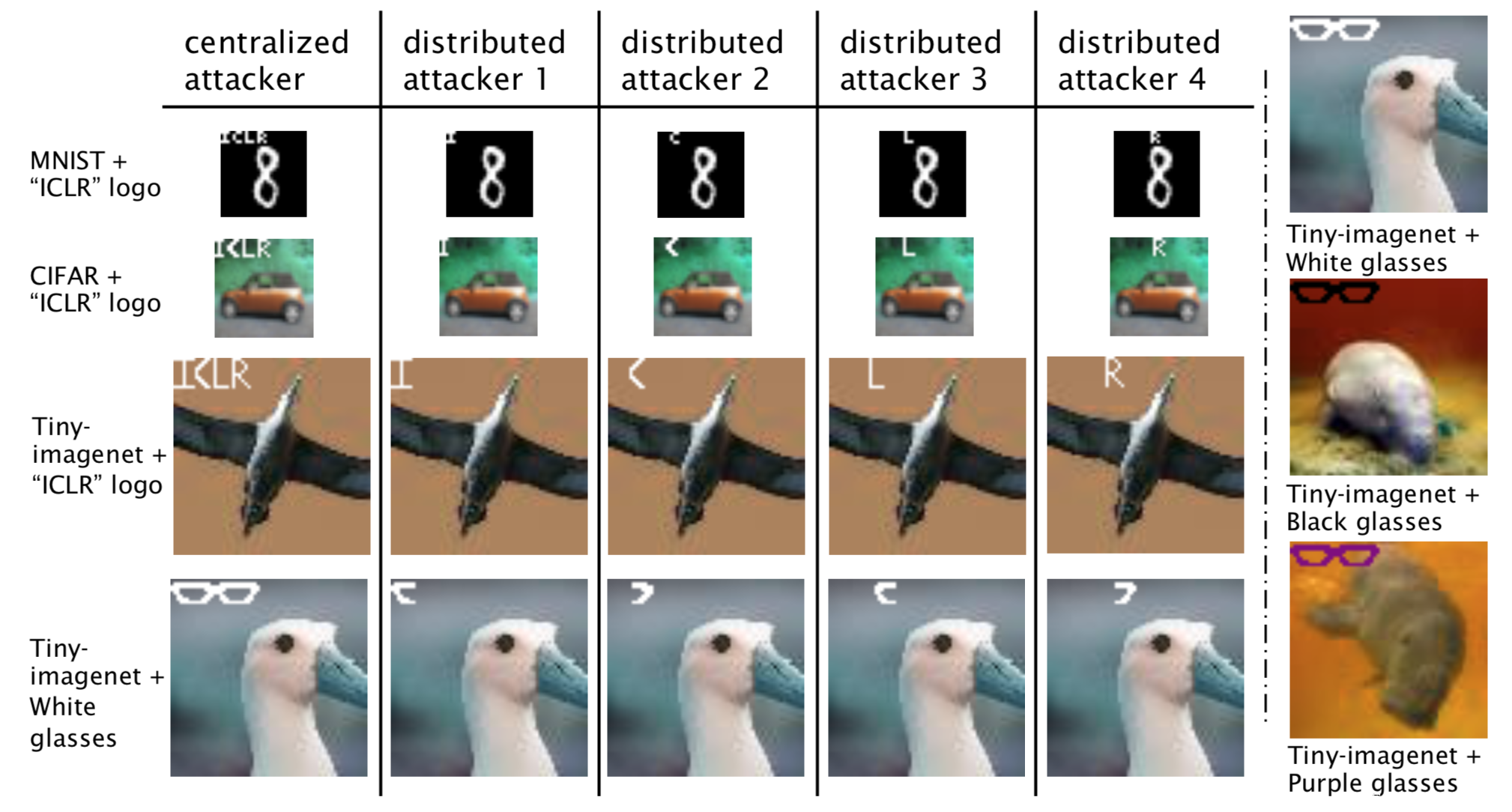
下图所示是各个数据集上,集中式后门攻击和分布式后门攻击的触发器的显著对比。
实验分析
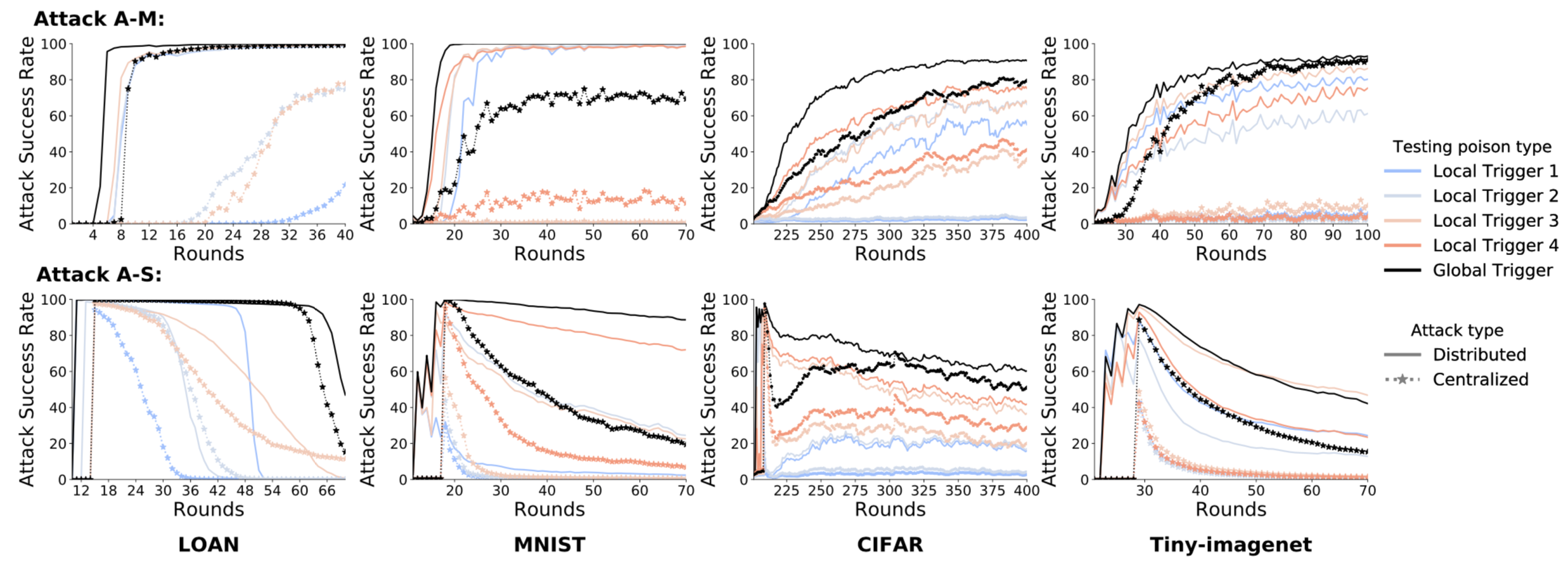
这里我们使用了四个分类任务数据集,分别是:Lending Club Loan Data(LOAN), MNIST, CIFAR-10 and Tiny-imagenet
不同颜色的线代表不同的触发器,这里我们关注的是分布式攻击和集中式攻击的区别,前者使用实线表示,后者使用虚线表示
在A-M,即Mutliplt-shot攻击的情况下,不论是什么数据集,还是任何一轮,可以看到,分布式攻击的成功率都要高于集中式后门攻击;而且在分布式攻击情况下,全局触发器(黑线)的攻击成功率要高于局部触发器(其他颜色的线),同时收敛更快,这是非常值得注意的现象,因为实际上我们在进行分布式攻击时并没有用到全局触发器。
在A-S,即single-shot攻击的情况下,我们还发现,集中式攻击在局部触发器和全局触发器的攻击成功率下降速度都快于分布式攻击,这说明分布式攻击更持久。例如,在MNIST和50轮后,分布式攻击成功率保持在89%,而集中式攻击只有21%。尽管分布式攻击仅使用局部触发器,但结果表明,其全局触发器的持续时间比任何局部触发器都长,这表明分布式攻击可以使全局触发器对良性更新更具弹性。
我们也可以进一步使用可解释性方法说明为什么分布式攻击更可靠,我们分别检查原始数据输入和后门目标标签的解释,以及带有局部和全局触发器的后门样本。
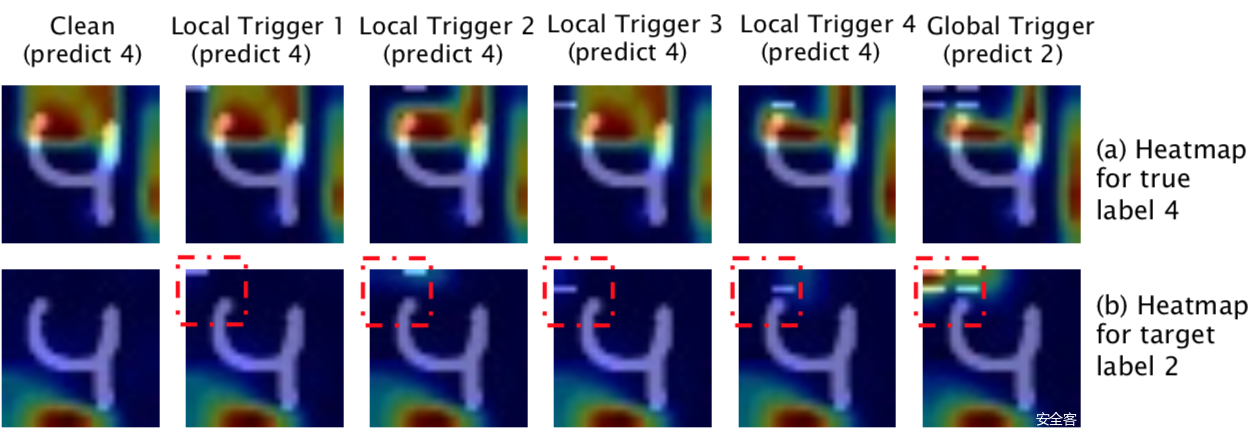
上图显示了手写数字“4”的grad-cam结果。我们发现,每一个局部触发的图像都是一个弱攻击,因为它们都不能改变预测(嵌入触发器的左上角没有注意)。然而,当作为全局触发器组装在一起时,后门图像被分类为“2”(目标标签),我们可以清楚地看到注意力集中在触发器所在的位置。grad-cam导致的大多数局部触发图像都与干净图像相似,这一事实说明了分布式攻击的隐蔽性。
参考
1.联邦学习算法综述
2.联邦学习算法白皮书v2.0
2.Bagdasaryan E , Veit A , Hua Y , et al. How To Backdoor Federated Learning[J]. 2018.
3.Xie C, Huang K, Chen P Y, et al. Dba: Distributed backdoor attacks against federated learning[C]//International Conference on Learning Representations. 2019







发表评论
您还未登录,请先登录。
登录