

作者:唐银@涂鸦智能安全实验室
一、前言
对于用户编辑文本的功能点,很多时候,业务上需要允许用户输入自定义的样式,比较简单直接的方案就是使用富文本:支持用户在前端自定义的html传入,最终同样以html的形式展现。不同的业务可能有各种各样不同的具体实现形式,但殊途同归,最终都可以抽象成“输入->持久化->输出”来表述。
如果整个过程不进行任何处理,就会产生XSS漏洞。然而常见的XSS防护方案中的编码转义,完全不适用于这种场景。那么剩下的方案就只有把不安全的内容过滤掉了。
二、安全问题
最常见的业务流程:
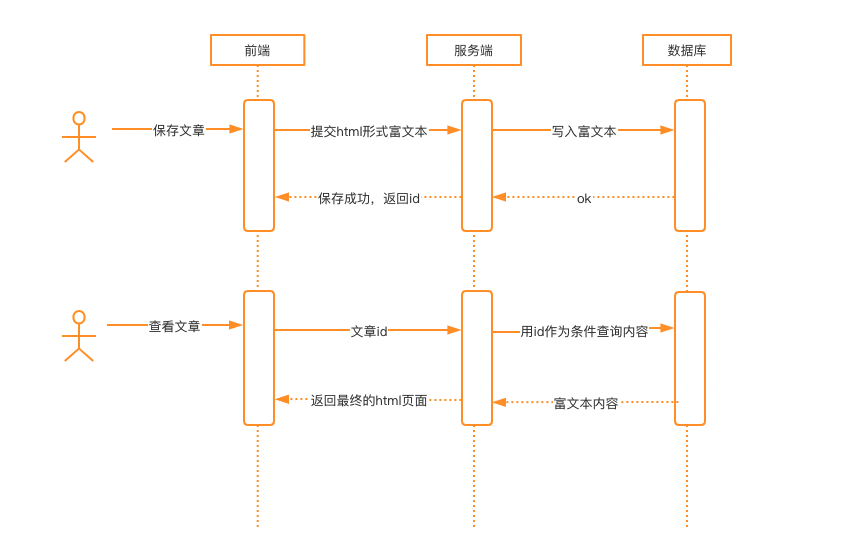
通常,安全人员在测试上面的流程时,会在前端提交html富文本给后端之前,对Post请求进行拦截,然后在内容中插入类似下面的代码,来证明漏洞存在:
<img src=1 onerror="alert(123)">
<script>alert(123);</script>
如果应用后端没有进行过滤,查看文章时,页面会执行插入的js代码,弹窗。
当安全人员将这样的PoC提交给开发时,如果开发是一个小白,往往第一反应是用黑名单的方式过滤掉onerror事件、script标签。
然而有经验的开发同学都知道,黑名单不管如何更新维护,往往都是白白浪费精力,最终都难以逃脱被绕过的下场。最有效的方案是使用白名单过滤。
以下链接中的内容包含了一些常见的XSS攻击方式及绕过方法,不在此处展开讨论,感兴趣的可以自行了解一下。
https://html5sec.org/
https://cheatsheetseries.owasp.org/cheatsheets/XSS_Filter_Evasion_Cheat_Sheet.html
三、过滤方案及实现
对于上面的业务流程,过滤可以在两个环节实现。一个是服务端在接收到前端传入的数据后,对数据进行过滤处理,另外一个是数据返回给前端,前端将数据渲染到页面呈现之前。
服务端过滤(Java实现)
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM、CSS 以及类似于 JQuery 的操作方法来取出和操作数据。基于MIT协议发布,可放心用于商业项目。
jsoup内置了一些白名单的标签属性list,同时支持用户自定义,或者在此基础上根据需求灵活扩展。
先看一个简单的Demo。
maven依赖:
<dependency>
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
jsoup Demo:
package cc.stayfoolish.richtext.test;
import org.jsoup.Jsoup;
import org.jsoup.safety.Safelist;
public class JsoupFilterDemo {
public static void main(String[] args) {
String payload = "aaa<script>alert(1)</script>bbb<img src=\"http://stayfoolish.cc/a.jpg\" class=\"s\" onerror=\"alert(1)\"><a href=\"http://stayfoolish.cc/test\">sss</a>";
Safelist safelist = Safelist.basicWithImages().addAttributes(":all", "class");
String res = Jsoup.clean(payload, safelist);
System.out.println(res);
}
}
注:很多文章里给的代码用的是Whitelist类,目前该类已经Deprecated,未来可能会被弃用。建议直接使用Safelist类。
打印结果:
aaabbb
<img src="http://stayfoolish.cc/a.jpg" class="s"><a href="http://stayfoolish.cc/test" rel="nofollow">sss</a>
可以看到,在结果中插入的恶意代码成功被过滤掉了。
我们进入Safelist类里看一下jsoup提供的几个主要的基础白名单,
public static Safelist basic() {
return new Safelist()
.addTags("a", "b", "blockquote", "br", "cite", "code", "dd", "dl", "dt", "em", "i", "li", "ol", "p", "pre", "q", "small", "span", "strike", "strong", "sub", "sup", "u", "ul")
.addAttributes("a", "href")
.addAttributes("blockquote", "cite")
.addAttributes("q", "cite")
.addProtocols("a", "href", "ftp", "http", "https", "mailto")
.addProtocols("blockquote", "cite", "http", "https")
.addProtocols("cite", "cite", "http", "https")
.addEnforcedAttribute("a", "rel", "nofollow");
}
addTags(String… tags)方法中的参数内容,表示html标签(元素)的白名单。
addAttributes(String tag, String… attributes),表示指定的标签允许哪些属性。
addProtocols(String tag, String attribute, String… protocols),表示指定的标签里的指定属性允许使用哪些协议。
addEnforcedAttribute(String tag, String attribute, String value),表示指定的标签,不论有没有对应的属性和属性值,都强制加上。
再来看我们Demo中用到的basicWithImages()方法。在basic()的基础上又增加了img标签和一些可能用到的属性。
public static Safelist basicWithImages() {
return basic()
.addTags("img")
.addAttributes("img", "align", "alt", "height", "src", "title", "width")
.addProtocols("img", "src", "http", "https");
}
如果以上白名单还不够用怎么办?jsoup还提供了relaxed()方法,扩大了白名单范围,基本可以满足常见需求。
public static Safelist relaxed() {
return new Safelist()
.addTags( "a", "b", "blockquote", "br", "caption", "cite", "code", "col", "colgroup", "dd", "div", "dl", "dt", "em", "h1", "h2", "h3", "h4", "h5", "h6","i", "img", "li", "ol", "p", "pre", "q", "small", "span", "strike", "strong","sub", "sup", "table", "tbody", "td", "tfoot", "th", "thead", "tr", "u", "ul")
.addAttributes("a", "href", "title")
.addAttributes("blockquote", "cite")
.addAttributes("col", "span", "width")
.addAttributes("colgroup", "span", "width")
.addAttributes("img", "align", "alt", "height", "src", "title", "width")
.addAttributes("ol", "start", "type")
.addAttributes("q", "cite")
.addAttributes("table", "summary", "width")
.addAttributes("td", "abbr", "axis", "colspan", "rowspan", "width")
.addAttributes( "th", "abbr", "axis", "colspan", "rowspan", "scope","width")
.addAttributes("ul", "type")
.addProtocols("a", "href", "ftp", "http", "https", "mailto")
.addProtocols("blockquote", "cite", "http", "https")
.addProtocols("cite", "cite", "http", "https")
.addProtocols("img", "src", "http", "https")
.addProtocols("q", "cite", "http", "https");
}
需要注意的是relaxed()方法没有强制给a标签添加rel=nofollow属性,后面我会在“标签属性安全使用建议”部分解释这个属性的作用,以及什么场景需要加这个属性。
在jsoup Demo中,我们在调用addAttributes(“:all”, “class”)方法时,传入的tag参数值为“:all”,表示所有标签都允许使用class属性。
如果上面的标签属性不足以满足业务场景,开发同学可以使用前面提到的方法,自行添加标签属性白名单。在决定使用哪些白名单前,请参考后面的“标签属性安全使用建议”,或者找专业的安全人员帮忙审核一下。
有些场景下,需要对某些标签的属性值进行正则过滤,比如限制a标签的href属性必须在某个域名下。遗憾的是,jsoup没有提供默认的支持,只能自己实现一个了。以下是笔者写的一个工具类,发出来供大家参考:
package cc.stayfoolish.richtext.util;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.safety.Safelist;
import org.jsoup.select.Elements;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* TODO
*
* @author tangyin
*/
public class RichTextFilterUtil {
public static String cleanHTML(String content){
Safelist safelist = Safelist.basicWithImages().addAttributes(":all", "class");
String res = Jsoup.clean(content, safelist);
return res;
}
/**
*
* @param content 过滤的内容
* @param elementRegexMap key:例如参数值"a.href",表示a标签的href属性,value:正则表达式字符串
* @return
*/
public static String cleanHTMLandFilterUrl(String content, Map<String, String> elementRegexMap){
String cleanedHtml = RichTextFilterUtil.cleanHTML(content);
Document doc = Jsoup.parseBodyFragment(cleanedHtml);
for(Map.Entry<String, String> entry: elementRegexMap.entrySet()){
String[] key = StringUtils.split(entry.getKey(),".");
String tag = key[0];
String attribute = key[1];
String regex = entry.getValue();
Pattern pattern = Pattern.compile(regex);
Elements elements = doc.select(tag + "[" + attribute + "]");
for(Element element : elements){
Matcher matcher = pattern.matcher(element.attr(attribute));
if(!matcher.find()){
//如果没有匹配到,属性值置空
element.attr(attribute,"");
}
}
}
return doc.body().html();
}
public static void main(String[] args) {
Map<String, String> elementRegexMap = new HashMap<>();
String urlRegex = "^(http|https)://([\\w-@:]+\\.)*(baidu\\.com|stayfoolish\\.cc)(/.*)?$";
elementRegexMap.put("img.src", urlRegex);
elementRegexMap.put("a.href", urlRegex);
String dirtyContent = "<a href=\"http://www.stayfoolish.cc/\">123</a><a href=\"http://www.xxx.com/\">123</a><img src=\"http://www.baidu.com/1.jpg\"><img src=\"http://www.xxx.com/1.jpg\">";
String result = RichTextFilterUtil.cleanHTMLandFilterUrl(dirtyContent, elementRegexMap);
System.out.println(result);
}
}
OWASP Java HTML Sanitizer 是OWASP(Open Web Application Security Project,开放Web应用程序安全项目)组织开源的一款HTML过滤器,为安全而生,使用起来非常灵活。
官网:https://owasp.org/www-project-java-html-sanitizer/
maven依赖:
<dependency>
<groupId>com.googlecode.owasp-java-html-sanitizer</groupId>
<artifactId>owasp-java-html-sanitizer</artifactId>
<version>20211018.2</version>
</dependency>
以下是笔者基于这款过滤器写的另一个工具类:
package cc.stayfoolish.richtext.util;
import org.owasp.html.HtmlPolicyBuilder;
import org.owasp.html.PolicyFactory;
import org.owasp.html.Sanitizers;
import java.util.regex.Pattern;
/**
* TODO
*
* @author tangyin
*/
public class OwaspHtmlSanitizerUtil {
public static String sanitizeByAllDefaultPolicy(String htmlInput){
PolicyFactory policy = Sanitizers.FORMATTING.and(Sanitizers.LINKS).and(Sanitizers.BLOCKS).and(Sanitizers.IMAGES).and(Sanitizers.STYLES).and(Sanitizers.TABLES);
return policy.sanitize(htmlInput);
}
private static final Pattern whiteUrl = Pattern.compile("^(http|https)://([\\w-@:]+\\.)*(stayfoolish\\.cc|baidu\\.com)(/.*)?$");
public static String sanitizeByMyPolicy(String htmlInput){
String[] safeAttributes = {"align", "alink", "alt", "bgcolor", "border", "cellpadding", "cellspacing", "class", "color", "cols", "colspan", "coords", "dir", "face", "height", "hspace", "ismap", "lang", "marginheight", "marginwidth", "multiple", "nohref", "noresize", "noshade", "nowrap", "ref", "rel", "rev", "rows", "rowspan", "scrolling", "shape", "span", "summary", "tabindex", "title", "usemap", "valign", "value", "vlink", "vspace", "width"};
String[] allowTags = {"b", "i", "font", "s", "u", "o", "sup", "sub", "ins", "del", "strong", "strike", "tt", "code", "big", "small", "br", "span", "em", "p", "div", "h1", "h2", "h3", "h4", "h5", "h6", "ul", "ol", "li", "blockquote", "a", "img"};
PolicyFactory policy = new HtmlPolicyBuilder().allowElements(allowTags).allowAttributes(safeAttributes).globally()
.allowUrlProtocols("http","https").allowAttributes("src").onElements("img")
.allowAttributes("href").matching(whiteUrl).onElements("a").requireRelNofollowOnLinks().toFactory();
return policy.sanitize(htmlInput);
}
public static void main(String[] args) {
String payload = "aaa<script>alert(1)</script>bbb<img src=\"123\" class=\"s\" href=\"http://www.stayfoolish.cc/test\"><a href=\"http://www.stayfoolish.cc/test\">sss</a>";
String safeHtml1 = sanitizeByMyPolicy(payload);
System.out.println(safeHtml1);
String safeHtml2 = sanitizeByAllDefaultPolicy(payload);
System.out.println(safeHtml2);
}
}
和jsoup一样,其本身内置了很多白名单标签属性,可以通过and方法追加允许的标签属性策略。感兴趣的读者可以跟进代码里看一下这些自带的策略,这里不再赘述。
除了可以使用默认的策略,也支持灵活的自定义策略。相较于jsoup,自带了正则匹配内容的方法。
简单解释下上面的代码中自定义策略的部分。
allowElements(allowTags),表示允许指定的所有标签;
allowAttributes(safeAttributes),表示允许的属性,后面接的globally()方法表示全局,也就是对所有标签生效;
allowUrlProtocols(“http”,”https”).allowAttributes(“src”).onElements(“img”),表示允许img标签使用src属性,并且属性值仅支持http、https协议的url;
allowAttributes(“href”).matching(whiteUrl).onElements(“a”),表示a标签的href必须能够通过正则表达式的校验,否则该属性会被删除掉,后面接requireRelNofollowOnLinks(),表示强制增加rel=nofollow属性。
更多使用方法请参考官方文档:https://javadoc.io/doc/com.googlecode.owasp-java-html-sanitizer/owasp-java-html-sanitizer/latest/index.html
官方的例子中还有Ebay和Slashdot的过滤策略,写的比较复杂,感兴趣的读者也可以学习一下:
https://github.com/OWASP/java-html-sanitizer/tree/master/src/main/java/org/owasp/html/examples
OWASP还有一个AntiSamy项目: https://owasp.org/www-project-antisamy/ ,主要用法是使用xml配置文件配置白名单策略。源码:https://github.com/nahsra/antisamy
OWASP Java HTML Sanitizer的页面介绍里讲自己比AntiSamy快4倍,这里就不展开了。
.NET:https://github.com/mganss/HtmlSanitizer
Golang:https://github.com/microcosm-cc/bluemonday
PHP:http://htmlpurifier.org/
Python:https://pypi.python.org/pypi/bleach
Django框架(Python):https://github.com/shaowenchen/django-xss-cleaner
前端过滤
前端将数据渲染到页面呈现之前,也可以对内容进行一次过滤。这里推荐使用js-xss模块。除了可以在页面里直接引入js使用,同时也支持node.js,当使用node.js做服务端时,也可以参照前面的方案,在数据传入时使用该模块进行过滤。
源码:https://github.com/leizongmin/js-xss
项目主页: http://jsxss.com
Demo:
<script src="dist/xss.js"></script>
<script>
options = {
whiteList: {
a: ["href", "title", "target","xxx"],
},
}; // 自定义规则
html1 = filterXSS("<a href=\"http://stayfoolish.cc\" xxx=\"ss\" sss=\"ss\">aaa</a>", options);
console.log(html1);
html2 = filterXSS("<a href=\"http://stayfoolish.cc\" xxx=\"ss\" sss=\"ss\">aaa</a>");
console.log(html2)
</script>
执行结果:
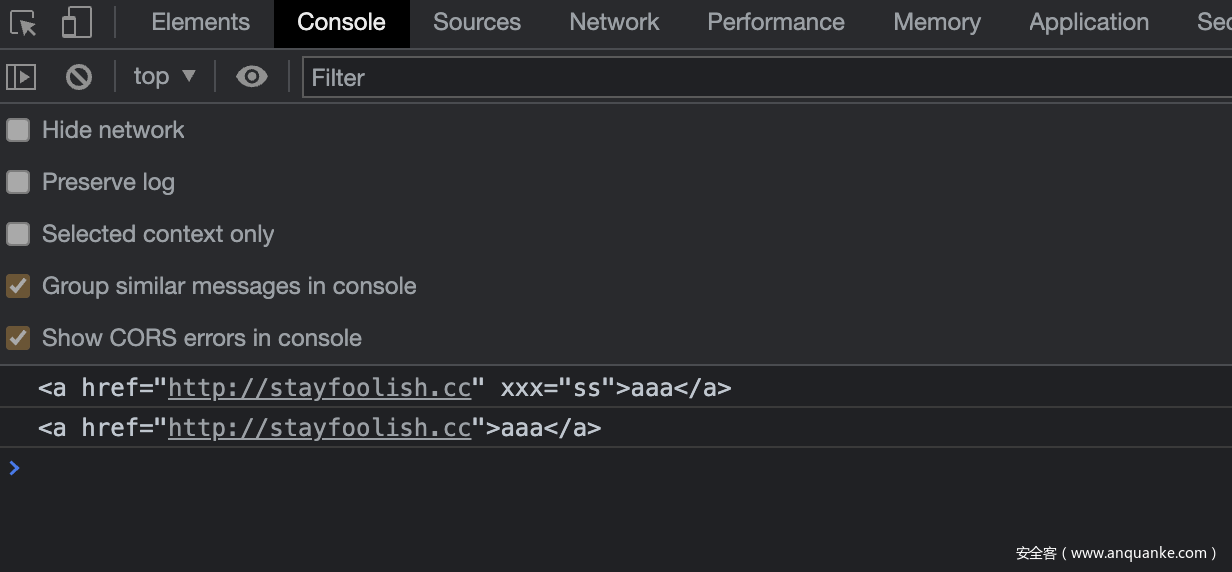
支持通过wihteList字段自定义规则,如果未指定规则,将会使用默认规则。
默认的白名单在getDefaultWhiteList函数中。
function getDefaultWhiteList() {
return {
a: ["target", "href", "title"],
abbr: ["title"],
address: [],
area: ["shape", "coords", "href", "alt"],
article: [],
aside: [],
audio: [
"autoplay",
"controls",
"crossorigin",
"loop",
"muted",
"preload",
"src",
],
b: [],
bdi: ["dir"],
bdo: ["dir"],
big: [],
blockquote: ["cite"],
br: [],
caption: [],
center: [],
cite: [],
code: [],
col: ["align", "valign", "span", "width"],
colgroup: ["align", "valign", "span", "width"],
dd: [],
del: ["datetime"],
details: ["open"],
div: [],
dl: [],
dt: [],
em: [],
figcaption: [],
figure: [],
font: ["color", "size", "face"],
footer: [],
h1: [],
h2: [],
h3: [],
h4: [],
h5: [],
h6: [],
header: [],
hr: [],
i: [],
img: ["src", "alt", "title", "width", "height"],
ins: ["datetime"],
li: [],
mark: [],
nav: [],
ol: [],
p: [],
pre: [],
s: [],
section: [],
small: [],
span: [],
sub: [],
summary: [],
sup: [],
strong: [],
strike: [],
table: ["width", "border", "align", "valign"],
tbody: ["align", "valign"],
td: ["width", "rowspan", "colspan", "align", "valign"],
tfoot: ["align", "valign"],
th: ["width", "rowspan", "colspan", "align", "valign"],
thead: ["align", "valign"],
tr: ["rowspan", "align", "valign"],
tt: [],
u: [],
ul: [],
video: [
"autoplay",
"controls",
"crossorigin",
"loop",
"muted",
"playsinline",
"poster",
"preload",
"src",
"height",
"width",
],
};
}
node.js安装:
npm install xss
使用方法:
var xss = require('xss');
var options = {
whiteList: {
a: ["href", "title", "target","xxx"],
},
};
var html = xss('<a href=\"http://stayfoolish.cc\" xxx=\"ss\" sss=\"ss\">aaa</a>', options);
console.log(html);
执行结果:
<a href="http://stayfoolish.cc" xxx="ss">aaa</a>
源文件xss.js中safeAttrValue(tag, name, value, cssFilter)函数中对标签属性进行了过滤。项目文档里写了常见的用法,代码也写的比较清晰,有需要的可以直接查阅文档或代码。
四、标签属性安全使用建议
1、href、src属性需要校验协议
如果未校验,攻击者可以使用javascript:伪协议插入执行恶意的js代码。
2、什么情况a标签要加rel=”nofollow”属性?
这个属性的意思是告诉搜索引擎不要追踪此链接。如果A网页上有一个链接指向B网页,但A网页给这个链接加上了rel=”nofollow” 标注,那么搜索引擎不会把A网页计算入B网页的反向链接。搜索引擎看到这个属性就会取消链接的投票权重。
简单来讲,有些搞SEO的人,会在各大网站插入很多带有超链接的垃圾信息,如果强制加了rel=“nofollow”属性,搜索引擎爬到了,也不会给对方增加权重。这样搞恶意SEO的人,就没兴趣在你的网站里插垃圾信息了。
所以要不要加这个属性,取决于你的业务是否需要防止上述情形。
3、哪些属性被认为是安全的?
align, alink, alt, bgcolor, border, cellpadding, cellspacing, class, color, cols, colspan, coords, dir, face, height, hspace, ismap, lang, marginheight, marginwidth, multiple, nohref, noresize, noshade, nowrap, ref, rel, rev, rows, rowspan, scrolling, shape, span, summary, tabindex, title, usemap, valign, value, vlink, vspace, width.
以上是OWASP整理的安全属性,可以放心使用。参考:
https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html
4、iframe标签安全使用建议
建议不要使用,如果一定要用,可以通过下面几个方式降低风险:
- src属性必须校验协议,限制http和https,同时进行url白名单正则校验,限制内容为可信域名,防止攻击者插入恶意页面。
- 固定长宽,或限制最大长宽,防止子页面覆盖父页面。
- 使用沙箱(sandbox)机制,遵循权限最小化原则配置相应选项满足业务需求。
sandbox 详细可参考
iframe特性全解读: https://zhuanlan.zhihu.com/p/88809313
sandbox 属性:https://www.bookstack.cn/read/html-tutorial/spilt.2.docs-iframe.md
5、style属性,建议不要使用。
原因参考:基于css注入的向量https://html5sec.org/#css
如果需要支持用户控制样式,建议使用class属性,针对不同的值提前定好对应的样式。
实在非要使用style属性的话,那就自己把属性值提取出来,解析后再做一层白名单过滤吧(如果写不好,会存在绕过的可能)。
6、script标签严禁用户插入,这个相信不用解释了。
7、上面提到的这些内容不能保证全面,超出范围的,建议咨询熟悉的专业安全人员。
五、其他常见场景、对应问题和解决方案
1、富文本内容被WAF(Web应用防火墙)拦截
有些公司的WAF规则比较严格,对请求中包含某些标签内容的,会直接判定为攻击,进行拦截。
通常WAF是站在企业整体安全的角度去做防护的,不能因为业务的某一个功能点,去降低整体的防护能力。这时,可以考虑使用以下方案去满足业务需求:
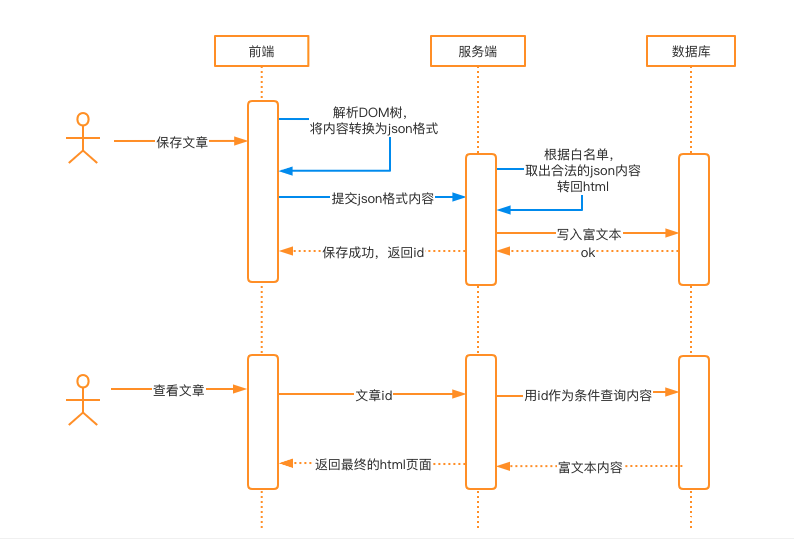
图中蓝色线条是在原有常规方案基础上的改动。即在前端解析富文本内容的DOM树,转换为json格式,之后提交给服务端,服务端进行白名单过滤。
html和json的转换,可以考虑使用类似html2json功能的组件来实现:
https://github.com/Jxck/html2json
注意,这种方案绕过了WAF的防护,请务必保证白名单策略的安全!请务必保证白名单策略的安全!请务必保证白名单策略的安全!
2、内容来自文件导入
有的业务场景,需要从文件批量导入内容,并且内容还要支持富文本,流程如下:
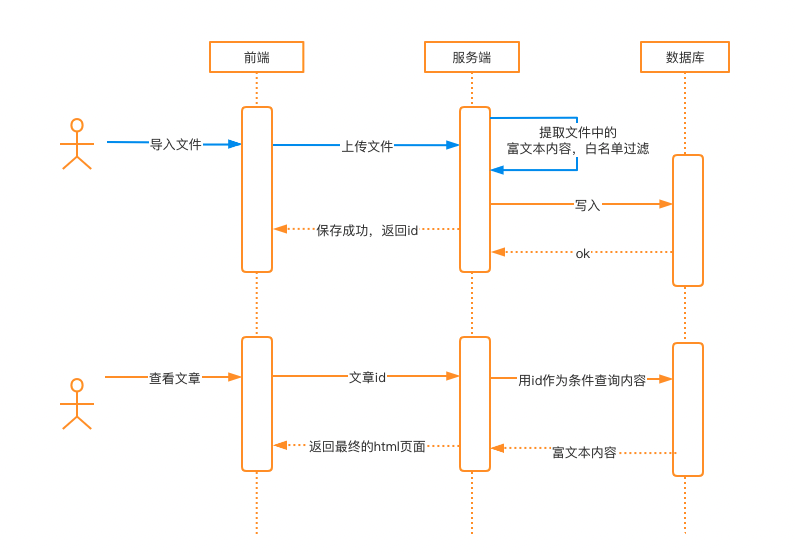
这种场景下,可以在服务端提取到内容后对富文本内容进行白名单过滤,之后再进行持久化存储。对于业务上不需要支持富文本的字段,直接按照传统XSS的防护方案进行特殊字符转义就好。
3、内容从用户指定的外部网页爬取
除非有特别强烈的需求,否则不建议做这样的功能,从安全角度讲绝对是坑。
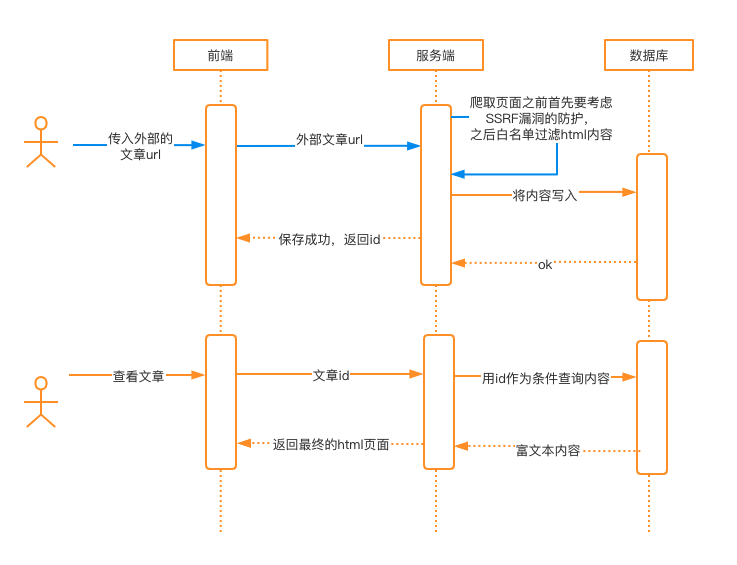
这种场景里,由于要爬取用户指定的第三方页面,所以首先需要完善的SSRF漏洞防护方案(这是另一个话题,这里不展开)。之后按照前面讲的方案对内容进行过滤。
4、生成html文件存储到服务器上
不建议使用这样的方案实现功能,小网站有这样做的,通常互联网企业里这种实现方式本身就违背了开发规范。
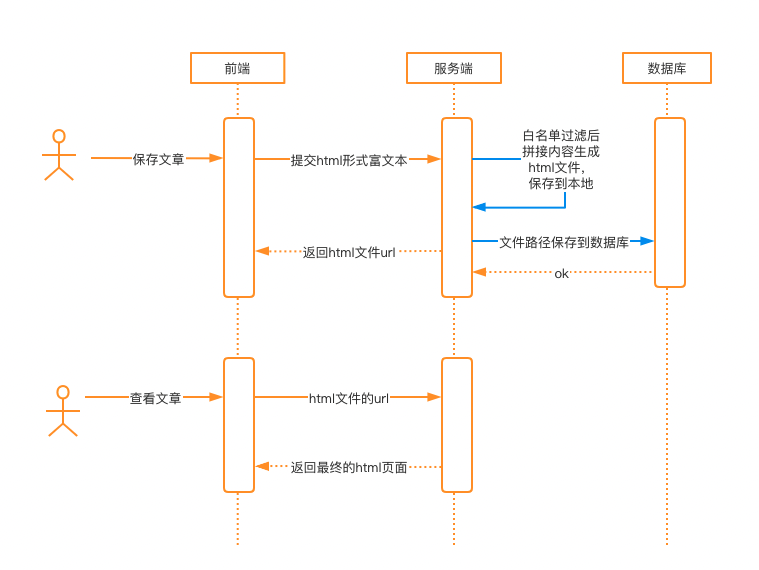
笔者以前有一次做渗透时,遇见过某个系统生成的还是jsp文件,插入java后门代码直接就拿到了服务器控制权。
5、服务端生成html文件上传至云存储
这里我们要假设云存储的html页面会对业务造成安全威胁,比如钓鱼攻击、业务子域名cname解析或者cdn到云存储服务,可以导致XSS影响业务。
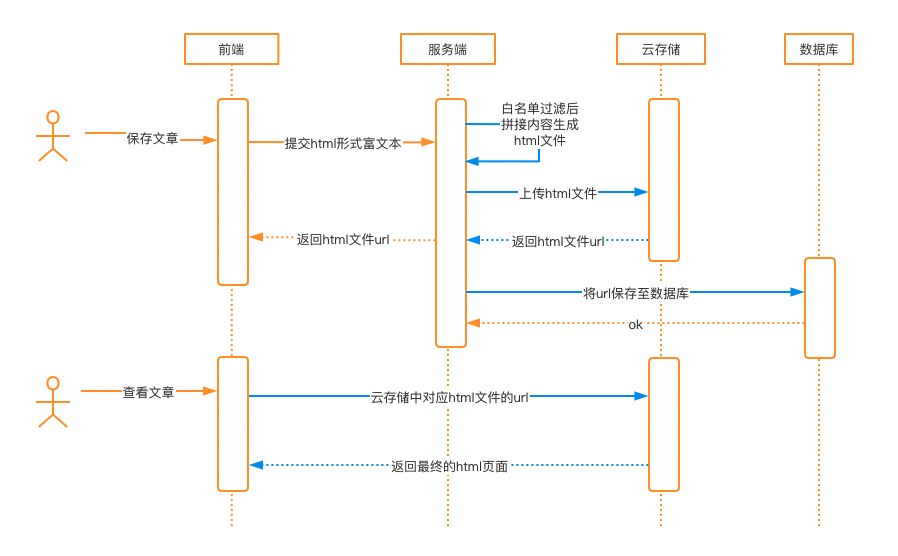
这种场景与文章开头的方案之间的区别只是内容持久化存储的位置发生了变化,只要在服务端上传文件之前,对内容进行过滤即可。
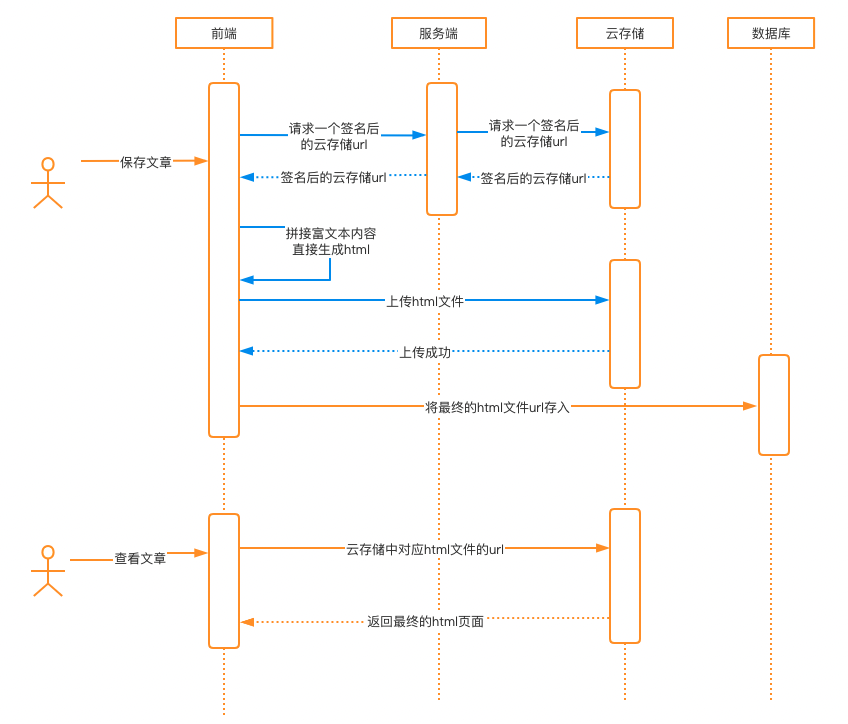
6、前端生成html文件上传至云存储
不要使用这种方案!不要使用这种方案!不要使用这种方案!这种方案由于内容不经过自己的业务服务器,没有办法对内容进行过滤处理。在这样的方案里,前端的无论怎么做,对安全都是不起作用的。
小结
以上是笔者见过的一些比较经典的场景,有些业务场景可能是上面每个场景不同部分的组合。
从中抽象出本质,不外乎“输入->白名单过滤->持久化->白名单过滤->输出”。通常更多的富文本使用场景会选择在输入时后端做过滤。如果有特殊需求,比如想完整保留用户输入的数据,那么也可以选择在输出时进行过滤。
行文仓促,考虑不足之处,欢迎各位师傅给出指导、建议或补充。
漏洞悬赏计划:涂鸦智能安全响应中心( https://src.tuya.com )欢迎白帽子来探索。
招聘内推计划:涵盖安全开发、安全测试、代码审计、安全合规等所有方面的岗位,简历投递sec#tuya.com,请注明来源。







发表评论
您还未登录,请先登录。
登录