一、背景
在漏洞扫描领域,主流的扫描方式分为黑盒扫描和白盒扫描,其中源代码安全检测即白盒扫描是安全开发流程(SDLC)中非常重要的一部分。传统漏洞大多数都能通过工具的方式检出,但对于越权漏洞,工具较难解决,在对黑盒工具赋能后,无恒实验室又尝试探索对白盒工具赋能进行定制化的扫描,下面将为大家分享无恒实验室利用白盒工具进行越权漏洞治理的思路。
二、面临的挑战
无恒实验室针对历史越权漏洞进行了梳理,发现涉及的业务种类复杂,同时不同的业务有不同的鉴权模型,也有多种鉴权方式(函数代码、中间件、网关插件、上下游RPC等)。所以白盒扫描在治理业务的越权漏洞时会面临下方挑战:
第一:对于在代码中做鉴权的,白盒需要知道哪些是鉴权函数或者鉴权代码,然后判断API的函数调用链中有没有对应的鉴权函数。对于在网关中做鉴权或者上下游中做鉴权的,传统的白盒无法获取,必须定制化开发。白盒作为一个中台工具,在工具内部加入太多指定业务的定制化鉴权逻辑是不太适合的,故无恒实验室的业务SDLC团队通过优化中台白盒引擎,开发一个整合各方数据的系统,来提升白盒检测能力。
第二:很多业务中的代码仓库大部分为RPC仓库,RPC仓库通过在网关中注册API将RPC函数映射为HTTP接口,且遇到某些业务网关比较多的情况下,还有大网关嵌套小网关的情况。由于网关的原因导致API识别能力和污点跟踪能力都受到了一定程度的限制。
第三:部分接口可能是一些公共接口或者是不需要做鉴权的接口,传统白盒是无法做语义分析判断该接口需不需要鉴权。
三、治理目标
无恒实验室的治理目标是开发一个整合各方业务的数据,来判断API是否为告警的系统。该系统通过识别API该不该鉴权,有没有调用鉴权函数,有没有调对鉴权函数来判断API是否有越权风险。注意这里的几个关键词:第一,该不该鉴,这代表系统需要有语义分析能力,分析API是否是公共接口或者无需鉴权接口。第二,有没有调,系统需要知道所有的鉴权函数数据。第三、有没有鉴对,系统在有API鉴权数据后应该有规则校验API该调哪些鉴权函数,防止鉴权不完整(比如应该调用A,B两个鉴权函数,但实际只调了A鉴权函数)导致越权漏洞发生。
这里再解释下鉴权函数的含义,这里定义的鉴权函数是广义上的鉴权函数,其包含多种(eg.代码中的鉴权函数、代码中的鉴权中间件、网关鉴权插件、上下游RPC仓库中的鉴权函数等)。
四、解决方案
4.1 系统架构
本章节将详细说下该系统的架构,如下图所示,首先是API函数名识别模块,该模块将收集所有网关的API数据。对于一些在网关中做泛解析,在代码仓库中做真实的API映射的仓库,系统提供脚本插件来爬取仓库的API数据,每次扫描前会执行该插件,这三个模块的并集就为每个仓库对应的API的完整数据。
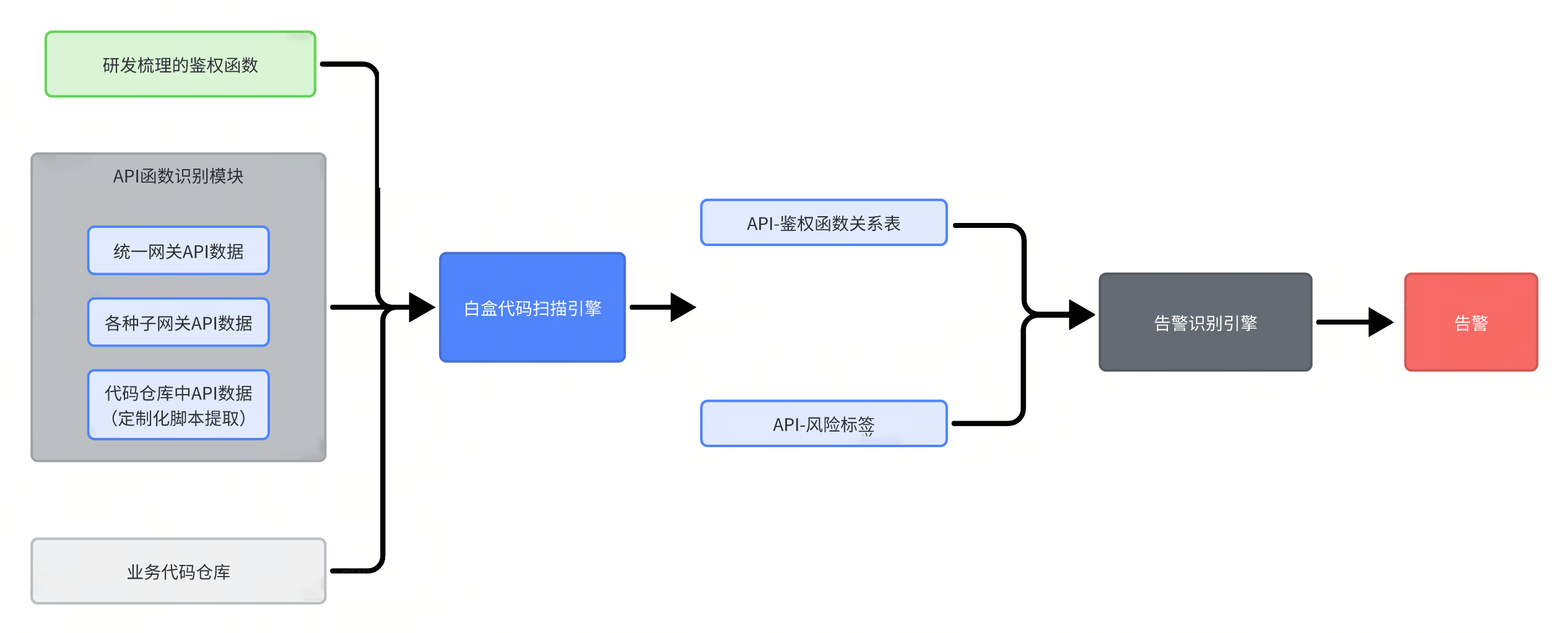
4.2 鉴权函数
无恒实验室会协助业务研发人员梳理出鉴权函数并对鉴权函数场景打标,梳理完后将鉴权函数导入平台,并调用中台白盒的扫描接口进行扫描。
在扫描时,白盒引擎会去检查API的函数调用链中有没有给定的鉴权函数名,最后会生成一个API和鉴权函数的对应关系表。不仅如此,中台白盒也在不停的迭代,抽象出一些适用于各个业务线的通用规则,这些规则产生一些风险标签,标记API是否有风险或者在全链路上做鉴权。这部分由于是一些通用规则所以目前产生的标签比较少且对指定的业务可能适用性较小。扫描完后,中台白盒将数据回传给平台,平台会将数据加入到API的鉴权函数数据中(来源分别为白盒鉴权函数、白盒风险标签)。然后平台的告警识别模块会进行告警识别。
4.3 告警识别
接下来仔细的说下告警识别引擎内部的判断逻辑,其包含5个模块。
第一个为公共接口模块,该模块识别当前接口是不是公共接口,如果是公共接口,则给API的鉴权函数数据中加入一个名为公共接口的鉴权函数,来源设置为public_api。
第二个为空实现模块,运营过程中发现有部分接口被提前在master代码中编写,但里面的代码为空,针对这部分接口,由于代码还没实现故不需要进行告警识别,所以该模块为根据中台白盒提供的函数调用栈数量数据,来判断当前接口是否为空实现。当研发实现该接口后,函数调用栈数据会发生变化,此时需要将该接口进行激活,再次进行告警识别。前面两个模块主要是用于判断需不需要鉴权。
第三个模块是网关鉴权插件模块,该模块会在代码仓库每次扫描完后去拉取API在网关上的鉴权插件数据,并将鉴权插件数据加入到API的鉴权函数数据中,来源设置为网关插件。
第四个模块是RPC鉴权模块,无恒实验室自研了一套系统,只要将上下游的鉴权函数传给系统,系统就给返回API是否在上下游调用指定的鉴权函数,平台在每次扫描时会将调用该系统,并将返回的数据存入平台,来源设置为rpc。中间两个模块主要是解决有没有鉴的问题。
最后一个模块是多步鉴权模块,该模块会根据业务特性抽象出很多定制化的检测插件来校验鉴没鉴对的问题。该模块下有很多检测插件,每个检测插件支持安全运营人员自定义按照业务的特性来进行自定义配置检测规则。平台的检测插件很多:包括基于http_path的检测插件、基于file_path的检测插件、基于入参的检测插件等。
(1)基于http_path的检测插件。应用大多数情况都有管理后台,且其对应的http接口的路径前缀一般是固定的,比如/admin/xxx。对于管理后台的接口,均需要调检验当前用户是否是当前应用的管理员,如果没有校验,则可能有垂直越权风险,基于此规则系统的检测思路就是查看/admin/xxx下的接口有没有调角色的鉴权函数,如果没调则判断为有风险。举个实际的例子,安全运营人员在系统基于http路径的插件上配置了一个规则:A仓库的/work/下的接口均需调用判断是否为管理员的鉴权函数。经过扫描发现A仓库下的c接口(http路径为/work/c)没调用该鉴权函数,则接口被识别为告警。

(2)基于入参的检测插件,这个检测插件为API如果有指定的参数名,则需要调特定的鉴权函数。比如跨空间的场景,如果API的参数里有project_key,则需要调用名为project_detect的网关鉴权插件,如果没调用,则识别其为告警。
平台的检测插件很多,本文就不再赘述。总之,平台提供一系列检测插件,安全运营人员可以根据需要对特定的仓库自定义的配置检测规则。
4.4 鉴权分
如上文提及到,告警识别引擎是由多部分组成,不同部分的结果之间相互作用对告警识别肯定会有干扰,因此在这里引入一个鉴权分的概念,鉴权分由各项数据以及对应的比例系数求和计算而成。系统有默认的鉴权标准分以及比例系数,系统支持针对指定仓库自定义配置鉴权标准分和比例系数,API的总鉴权分如果低于所在仓库的鉴权标准分,则认为有越权风险,每个模块的比例系数会不断调整以提高准确率。目前所有仓库默认的鉴权标准分为1,所有鉴权函数的比例系统均为1。这代表API只要有任意一个鉴权函数就是告警。
举个例子,比如A仓库的鉴权标准分为1,且其公共接口对应的比例系数也为1。如果a接口没调用任何鉴权函数但被判断为公共接口,则a接口的总鉴权分为0(鉴权函数个数)1(鉴权函数比例系数)+1(是否为公共接口)1(公共接口比例系数)=1,大于等于鉴权标准分1,被判断为非告警。
多步检测模块的检测插件中规则的鉴权分,也是API总鉴权分的重要组成部分,这里的鉴权分一般为负数,即如果不满足条件则总的鉴权分会减少。还是以上面角色鉴权的规则为例,安全运营编写了一个规则:A仓库的/work/路径下需要调用A2(A2为内部逻辑为做角色鉴权)鉴权函数,规则对应的鉴权分配置为-5。 如果A仓库的/work/c接口调用了A1鉴权函数但没调用A2鉴权函数,则该接口的鉴权分为1(调了A鉴权函数)+(-5)(没调A2鉴权函数)=-4,小于当前仓库的鉴权标准分1,故被判断为告警。研发修复漏洞的方法为给c接口加一个A2鉴权函数,修复后/work/c接口鉴权分变为1+1(掉了A1,A2两个鉴权函数)=2,大于等于当前仓库的鉴权标准分1,故被判断为非告警。
接下来说明下告警产生后安全运营的一个动作。告警产生后,安全运营人员不会直接提交安全工单,目前阶段会让各子业务线的SDLC对接人来运营告警,明确有风险后再提交安全工单。为了帮助安全运营,系统将测试流量也集成到了系统中,并将API和测试流量关联。
API对应的流量和鉴权函数数据均是安全运营人员判断风险的参考标准。这里的鉴权函数仍是广义的鉴权函数,包括鉴权函数、鉴权中间件、public_api、网关鉴权插件、上下游rpc鉴权函数等。刚开始安全运营人员的运营动作是根据流量中的origin和referer找到对应的界面,然后进行测试,后来大家集思广益开发了两个和burp联动的插件,一个是手动版,该版本自动将告警对应的流量发送到burp上,然后安全运营人员进行手工测试。另一个是自动化版,不仅将告警流量发送到burp上,而且还配置了租户池和角色池,只要进行了基本的配置即可批量的进行越权扫描,这两个插件大大提升了运营的效率。
五、未来的白盒检测方向
接下来我们将会从三个方向上继续优化的白盒定制化越权检测系统。
1.准确率提升,系统不仅会对告警和误报数据进行相似度挖掘和分析,用AI的方法来探索降低误报。还会结合灰盒来降低误报。重点说下灰盒,灰盒为我们定制化开发了一个接口,通过该接口可以查询到API的哪些参数能真实影响底层SQL语句的id参数。如果告警中的参数不能影响SQL语句,则系统认为其非告警(暂时不考虑读redis、mq的情况)。这时大家可能有疑问了,这样可能还是会有误报,比如该接口需要做角色类鉴权,该函数即使没调用角色类鉴权函数也被判断为了非告警,这就是为什么系统要引入鉴权分的概念,作用于一个API的因素很多,对于灰盒的参数数据的比例系数系统默认设定为1,由于所有仓库的鉴权标准分也默认为1,这代表着默认情况下灰盒认为不需要鉴权则为非告警。对于需要做角色鉴权的API,安全运营人员会在系统的多步检测模块加鉴权插件来平衡鉴权分,使得告警判断逻辑正确。
2.目前系统的多步鉴权检测能力还不太完善,接下来会丰富多步鉴权检测能力,深入分析每个业务线的权限模型,并与业务研发进行合作,通过推动接口打标与默认强制鉴权等方案,来确保多步检测能力落地到各业务中并且尽可能减少误报。
3.系统现在对于部分重点业务线,新增告警会在群内用机器人进行通知。近期在做的一个改进动作是在流水线代码发布阶段进行卡点,如果发布时有白盒越权漏洞业务需要修复后才能发布,以实现漏洞左移的目标。
六、越权治理
这里引入一个权限能力成熟度(CMM, Capability Maturity Model)等级的概念,权限成熟度方案简称CMM等级,其包含5个等级。
- CMM 0代表无任何权限管控。
- CMM1代表无统一的权限组件,开发根据需要自己写权限逻辑。
- CMM2 代表有统一的权限组件,需要各个开发手动写代码调用权限组件,如果权限组件不满足开发的需求时,再在权限组件中加鉴权函数。
- CMM3 为CMM2的基础上默认所有接口强制鉴权,不需要鉴权的则手动加白。
- CMM4在CMM3的基础上,通过其他系统来交叉验证鉴权是否正确。
为什么要引入这个概念呢,因为系统扫描和运营了一段时间后,发现部分仓库由于鉴权函数过于分散不适用于系统的扫描,所以无恒实验室划定了白盒扫描适用的范围为CMM2及CMM2以上,对于CMM等级低的我们优先推其从架构层面进行权限治理提升到CMM2及以上,不然就是挖一个修一个的情况,不能从根本上治理越权漏洞,扫描只是个辅助手段,从架构层面治理才是重点。提升后又用白盒越权定制化检测来查漏补缺,以及将漏洞卡在上线前修复,既能提高研发的安全意识,又能让安全漏洞左移,实现双赢的效果。
目前,绝大部分业务线均接入了白盒扫描,通过一段时间的数据跟踪发现,通过白盒扫描发现的越权漏洞数量和占比是所有发现方式中最高的。
七、小结
整个系统是无恒实验室结合业务特性摸索出来的一套检测规则,在从0到1开发过程中也走了很多弯路和踩过很多坑,整个方案还有很多待改进的点,多步鉴权方向还有很多坑要踩,我们会持续高速迭代和优化系统。如果你有好的idea,欢迎大家加入无恒实验室和我们一起做定制化的越权检测开发。
无恒实验室是由字节跳动资深安全研究人员组成的专业攻防研究实验室,致力于为字节跳动旗下产品与业务保驾护航。通过漏洞挖掘、实战演练、黑产打击、应急响应等手段,不断提升公司基础安全、业务安全水位,极力降低安全事件对业务和公司的影响程度。无恒实验室希望持续与业界共享研究成果,协助企业避免遭受安全风险,亦望能与业内同行共同合作,为网络安全行业的发展做出贡献。







发表评论
您还未登录,请先登录。
登录