一、概述
近日,字节跳动安全研究团队联合南京大学在⼤语⾔模型联邦精调领域发布了研究论文 A Split-and-Privatize Framework for Large Language Model Fine-Tuning 。该论文主要关注在模型即服务 (Models-as-a-Service, MaaS) 场景下,大语言模型 (Large Language Model, LLM) 精调服务中模型和数据的隐私问题。
论文提出了一种基于分割学习的“分割-隐私化” (Split-and-Privatize, SAP) 联邦精调框架,能够在保障模型和数据隐私的同时,有效提升模型在下游任务上的可用性,为大语言模型精调服务的实际应用落地做了更多探索努力。
二、研究背景
近年来,以BERT和GPT为代表的预训练语言模型 (Pre-trained Language Model, PLM) 展现出了强大的文本学习能力,并被广泛应用于金融、法律和医疗保健等多个领域。 为了扩展预训练模型在更多领域应用,常见的方法是使用下游任务相关的数据集对模型进行精调。 但是受计算资源和技术限制,大多数用户并没有能力独立完成精调任务。
当前,主流的MaaS服务商通常拥有充足的训练资源和技术储备,提供了丰富的预训练模型和强大的训练服务。因此,越来越多的用户开始使用MaaS服务商提供的能力,利用自身的私有数据集,通过选择合适的预训练模型进行精调,得到符合其特定需求的大语言模型。
然而,这一模式在为用户提供便利的同时,也带来了隐私泄露的风险。 一方面,某些预训练模型出于知识产权保护目的,无法向用户直接公开; 另一方面,用户的训练数据可能包含个人身份信息、商业机密等信息,直接披露给服务商会导致严重的隐私泄露风险。
针对上述问题,字节跳动安全研究团队在深入调研隐私攻击手段和数据扰动算法的基础上,提出了一种基于分割学习的SAP联邦精调框架,为模型信息和用户数据隐私提供了良好的保护效果,并对模型可用性和隐私性之间的权衡进行了探讨。
三、技术方案
3.1 总体框架
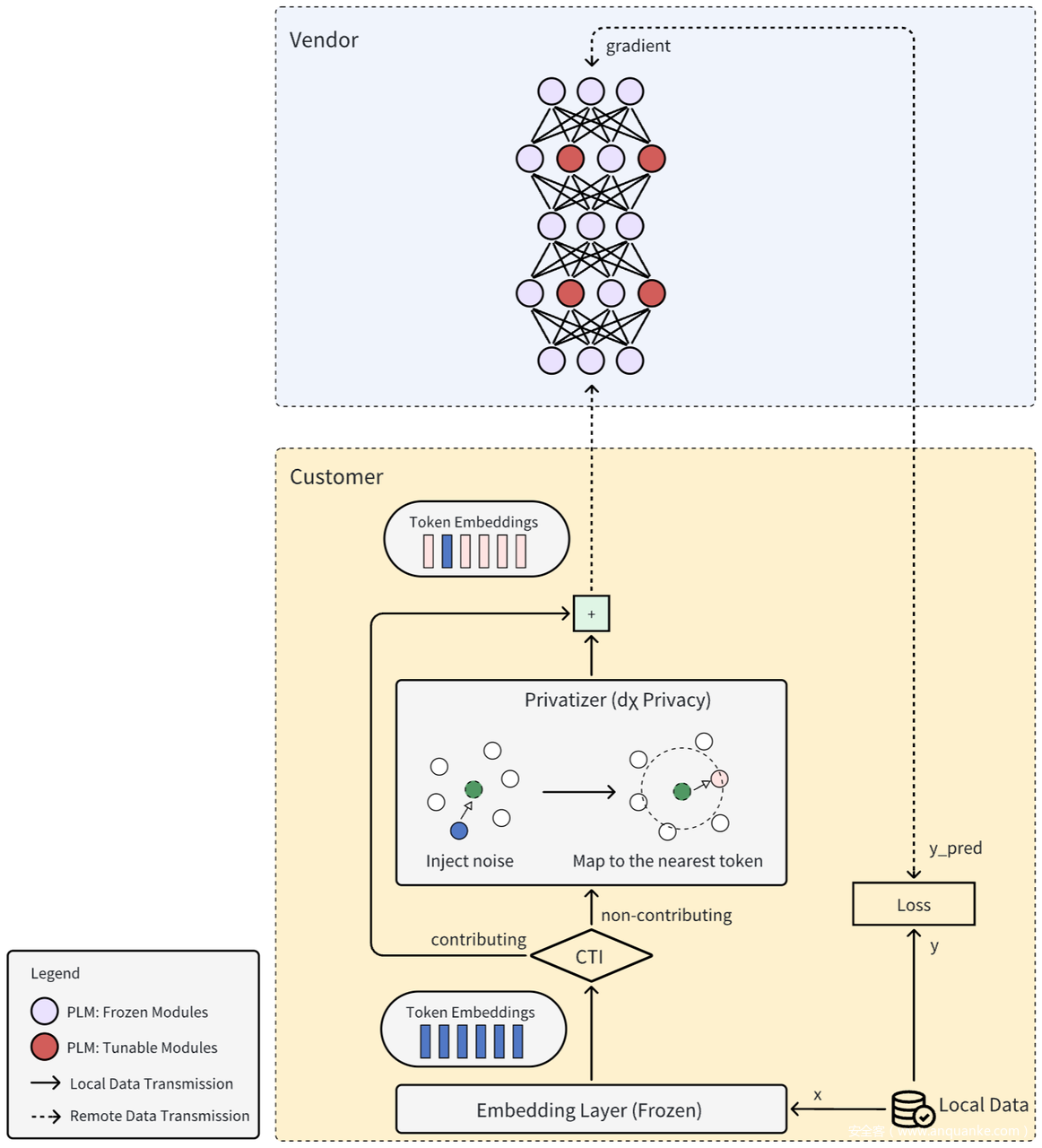
为了在实现LLM定制的同时保护服务商的模型隐私和用户的数据隐私,论文提出了一种基于分割学习的SAP框架,上图给出了该框架的一种实现。
从整体架构上来看,预训练模型被分为服务商侧的顶层模型和用户侧的底层模型。在精调时,用户先用底层模型将本地私有数据转换为向量化文本表示,然后自适应地应用隐私保护机制对文本表示进行隐私化扰动,最后再将它们发送给服务商。服务商将接收到的向量化文本表示继续在顶层模型中前向传播,计算模型最终的输出。出于隐私考虑,样本标签也不能离开用户本地,因此服务商需将模型输出发送给用户,接收返回的输出层梯度,并将其用于反向传播更新模型中的可训练参数。SAP框架能够与多种参数高效的精调方法结合以提升精调效率,例如LoRA、BitFit以及Adapter Tuning等。
SAP核心部分包括模型分割、文本隐私化和贡献度衡量,以下分别介绍。
3.2 模型分割
在初始化阶段,服务商将预训练模型分割为底层模型和顶层模型,并将底层模型发送给用户。在这一步骤中,进行模型分割的层次是一个重要的选项。如果底层模型只包含嵌入 (embedding) 层,用户的计算负担相对较小,但服务商可以通过最近邻搜索轻易地从传输的表示中恢复输入文本。如果底层模型包含更多编码器 (encoder) 模块,那么从中恢复原始文本就变得更加困难,因为更深层的表示更为抽象和通用。此外,由于模型的权重也是服务商的重要资产,可能要求尽可能少地披露权重。因此,预训练模型的分割位置需要结合实际应用场景综合考虑。
3.3 文本隐私化
给定底层模型,用户可以计算得到每个文本的向量化表示。然而,如果直接以明文形式发送向量化文本表示,服务商有较大可能利用反演攻击从中恢复出原始输入。为了加强数据隐私保护,用户侧有必要采用隐私化机制对文本表示进行扰动。SAP框架能够简单地与多种隐私保护机制相结合以实现更强的隐私保护,例如dχ-隐私(本地差分隐私的一种变体)和概率近似正确 (Probably Approximately Correct, PAC) 隐私。
3.4 贡献度衡量
引入文本隐私化机制在加强数据隐私保护的同时,也会导致一定的模型性能损失,因此存在效用与隐私之间的权衡。为了改善这种权衡,论文提出了一种基于贡献度衡量的重要词元 (token) 识别方法。该方法的主要原理是利用统计分析来识别每一类样本中对效用目标贡献度最大的token,并减小对这些极少数token的扰动,旨在提高可用性的同时保持相近的隐私保护水平。
四、方案评估
4.1 隐私度量
论文采用典型隐私窃取攻击的方法来评估SAP框架的数据隐私保护能力。为最大化攻击者的能力,文中考虑白盒设定,假设攻击者与服务商具有相同的视角,即能够访问用户传输的向量化文本表示以及底层模型的初始参数。所采用的攻击方法如下:
- · 嵌入反演攻击 (Embedding Inversion Attack, EIA)。EIA是一种词元 (token) 级别的攻击,其目标是从扰动的向量化文本表示中恢复原始输入文本。具体而言,对于底层模型仅有嵌入层的情况,攻击者会在嵌入空间中搜索每个扰动向量的最近邻作为对原始词元的推测。对于底层模型包含更多层的情况,攻击者会采用一种更为复杂的基于优化的攻击方法。对于每个输入样本,该方法通过最小化推测文本的表示和观察到的表示之间的距离来迭代优化词元选择向量。
- · 属性推理攻击 (Attribute Inference Attack, AIA)。由于文本表示仍然包含丰富的语义信息,攻击者可以通过AIA从中推断用户的敏感属性。假设攻击者可以获得部分样本的隐私属性标签,那么隐私属性推理可以被视为一个下游任务,攻击者可以使用这些样本的向量化文本表示和相应的隐私标签来训练一个分类器进而推断其他样本的隐私属性。
论文中使用经验隐私作为评估SAP框架隐私保护能力的指标:令X 表示攻击成功率,经验隐私的定义为 1 − X。
4.2 主要结果
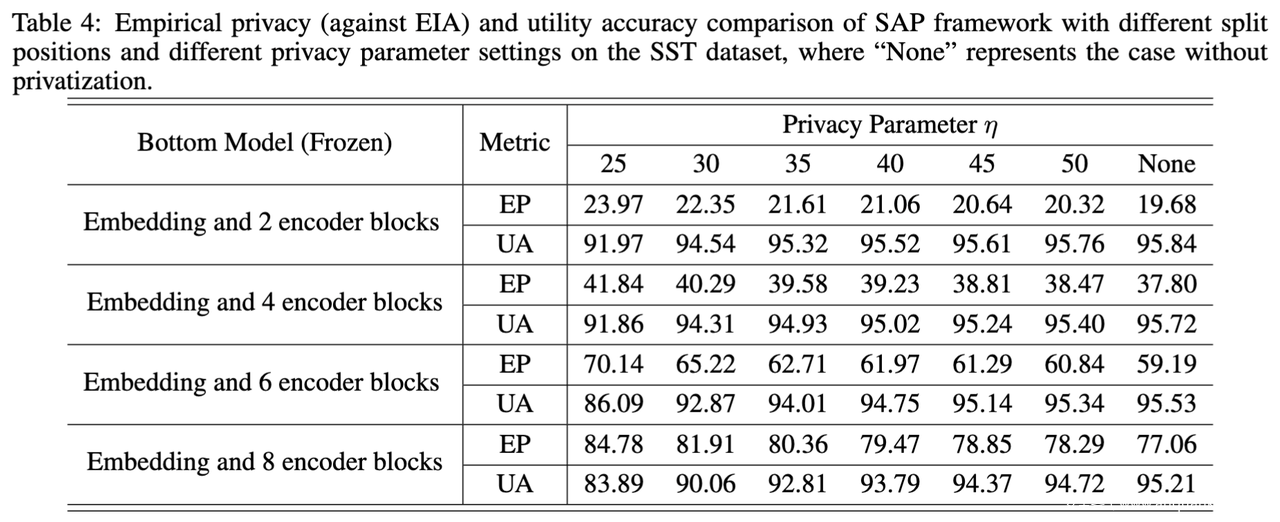
实验表明,SAP框架能够在保护模型隐私和数据隐私之间取得良好的平衡,同时最大限度地保证了模型的可用性。此外,SAP框架具有较高的灵活性,能够适应大语言模型精调服务中的多种需求场景。
对于用户计算资源相对有限的情况,可以采用底层模型仅有嵌入层的解决方案。在Roberta-Large模型和Stanford Sentiment Treebank (SST) 情感分析数据集上的实验结果表明,SAP框架以6%的模型性能损失换取了36%的经验隐私提升;
对于用户计算资源相对丰富的情况,可以采用底层模型包含多个encoder模块的解决方案。SST数据集上的实验结果表明,在底层模型有6个encoder模块的情况下(占整个模型的四分之一),SAP框架以1%的模型性能损失换取了62%的经验隐私提升。
详细内容可参看论文:https://arxiv.org/abs/2312.15603
五、关于安全研究
字节跳动安全研究团队以可信隐私计算产品Jeddak为载体,从可信计算、联邦学习、多方安全计算、差分隐私、密文计算、共识计算等方向着手,开展隐私计算技术的前沿研究和应用探索。基于这些领域最新前沿理论技术,实现数据全生命周期安全与隐私保护,帮助用户更好的解决业务需求与挑战。







发表评论
您还未登录,请先登录。
登录