![]()
熟悉内情的消息人士告诉《The Information》,OpenAI 即将推出的人工智能模型的性能提升幅度小于其前辈。
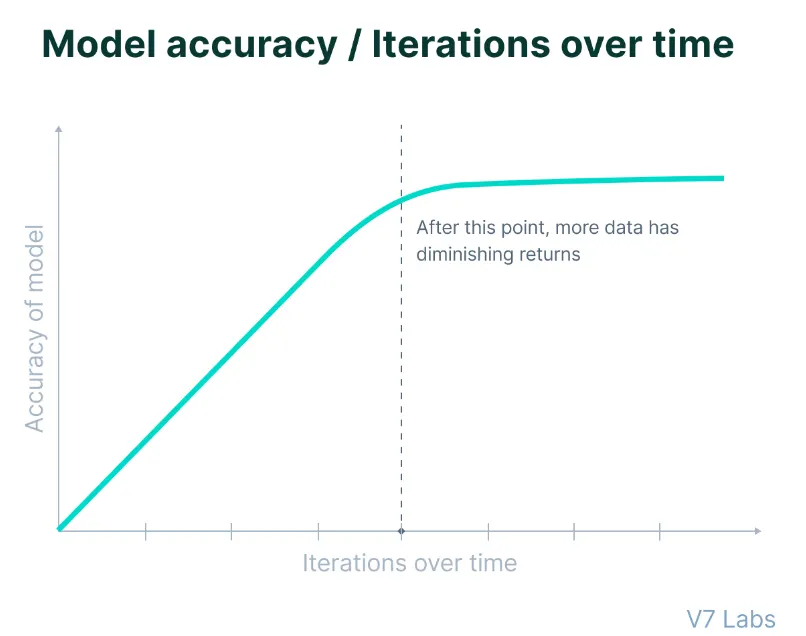
据 The Information 报道,员工测试显示,Orion 仅完成了 20% 的训练,就达到了 GPT-4 级别的性能。
从 GPT-4 到当前版本的 GPT-5 的质量提升似乎小于从 GPT-3 到 GPT-4 的提升。
据(OpenAI)员工称,“公司的一些研究人员认为,在处理某些任务时,Orion并不比它的前身可靠,”The Information 报道。“据一名 OpenAI 员工称,Orion 在语言任务方面表现更好,但在编码等任务方面可能无法超越前代机型。”
虽然 Orion 在 20% 的训练时间内接近 GPT-4 可能会给一些人留下深刻印象,但重要的是要注意,人工智能训练的早期阶段通常会带来最显著的改进,而随后阶段的收益较小。
因此,剩下的 80% 的训练时间不太可能产生与前几代飞跃相同的进步幅度,知情人士说。
这些限制出现在 OpenAI 最近获得 66 亿美元融资后的关键时刻。
该公司现在面临着投资者更高的期望,同时还要努力应对技术限制,这些限制对人工智能开发的传统扩展方法提出了挑战。如果这些早期版本达不到预期,该公司接下来的筹资努力可能不会像以前那样受到热捧–这对于一家潜在的营利性公司来说可能是个问题,而这似乎正是萨姆-奥特曼(Sam Altman)对 OpenAI 的期望。
令人沮丧的结果表明,整个人工智能行业都面临着一个根本性的挑战:高质量训练数据的供应越来越少,以及在像生成式人工智能这样竞争激烈的领域保持相关性的必要性。
今年 6 月发表的研究报告预测,人工智能公司将在 2026 年至 2032 年间耗尽可用的人类生成的公共文本数据,这标志着传统开发方法迎来了一个关键的拐点。
研究论文指出:“我们的研究结果表明,仅靠传统的数据扩展无法维持当前的 LLM 发展趋势,”论文强调,需要采用其他方法来改进模型,包括合成数据生成、从数据丰富的领域进行迁移学习以及使用非公开数据。
据 The Information 报道,在网站、书籍和其他来源的公开文本上训练语言模型的历史策略已经到了收益递减的地步,开发人员 “基本上已经从这类数据中榨取了尽可能多的东西”。
OpenAI 如何解决这一问题: 推理与语言模型
为了应对这些挑战,OpenAI 正在从根本上调整其人工智能开发方法。
The Information 报道说:“为了应对最近基于训练的扩展法则因 GPT 改进放缓而面临的挑战,业界似乎正在将精力转移到改进初始训练后的模型上,这可能会产生一种不同类型的扩展法则。”
为了实现这种持续改进的状态,OpenAI 正在将模型开发分为两个不同的轨道:
O系列(似乎是代号 “草莓”)侧重于推理能力,代表了模型架构的新方向。这些模型以更高的计算强度运行,明确针对复杂的问题解决任务而设计。
对计算能力的要求很高,据早期估计,运行成本是当前模型的六倍。不过,对于需要高级分析处理的特定应用来说,增强的推理能力可以证明增加的费用是合理的。
如果该模型与草莓模型相同,那么它的任务也是生成足够的合成数据,以不断提高 OpenAI LLM 的质量。
与此同时,猎户座模型或 GPT 系列(考虑到 OpenAI 已将 GPT-5 商标注册)也在继续发展,重点关注通用语言处理和通信任务。这些模型保持了更高效的计算要求,同时利用其更广泛的知识库来完成写作和论证任务。
OpenAI 的首席运营官凯文-韦尔(Kevin Weil)在一次 AMA 上也证实了这一点,并表示他希望在未来的某个时候将这两种发展融合起来。
当被问及OpenAI是将重点放在利用更多数据扩展LLM上,还是采用另一种方法,将重点放在更小但更快的模型上时,他回答说:“不是二选一,而是二者兼而有之。””更好的基础模型加上更多的草莓扩展/推理时间计算。”
变通办法还是终极解决方案?
OpenAI 通过合成数据生成来解决数据稀缺问题的方法给业界带来了复杂的挑战。该公司的研究人员正在开发旨在生成训练数据的复杂模型,然而这种解决方案在保持模型质量和可靠性方面带来了新的复杂性。
《解密》此前曾报道,研究人员发现,在合成数据上进行模型训练是一把双刃剑。虽然它为数据稀缺提供了一个潜在的解决方案,但它也带来了新的模型退化风险和可靠性问题,经过多次训练迭代后,模型退化的情况已得到证实。
换句话说,随着模型在人工智能生成的内容上进行训练,它们可能会开始放大其输出中的细微瑕疵。这些反馈回路会延续并放大现有的偏差,从而产生越来越难以检测和纠正的复合效应。
OpenAI 的基础团队正在开发新的过滤机制,以保持数据质量,并采用不同的验证技术来区分高质量和有潜在问题的合成内容。该团队还在探索混合训练方法,战略性地将人类和人工智能生成的内容结合起来,最大限度地发挥两种来源的优势,同时尽量减少各自的缺点。
训练后优化也变得越来越重要。研究人员正在开发新的方法,以在初始训练阶段后提高模型性能,从而提供一种无需完全依赖扩大训练数据集就能提高能力的潜在方法。
尽管如此,GPT-5 仍然是一个完整模型的雏形,还有大量的开发工作要做。OpenAI 首席执行官山姆-奥特曼(Sam Altman)表示,今年或明年还不能部署该模型。这一延长的时间表可能会被证明是有利的,它允许研究人员解决当前的局限性,并有可能发现新的方法来增强模型,从而在 GPT-5 最终发布之前对其进行大幅改进。







发表评论
您还未登录,请先登录。
登录