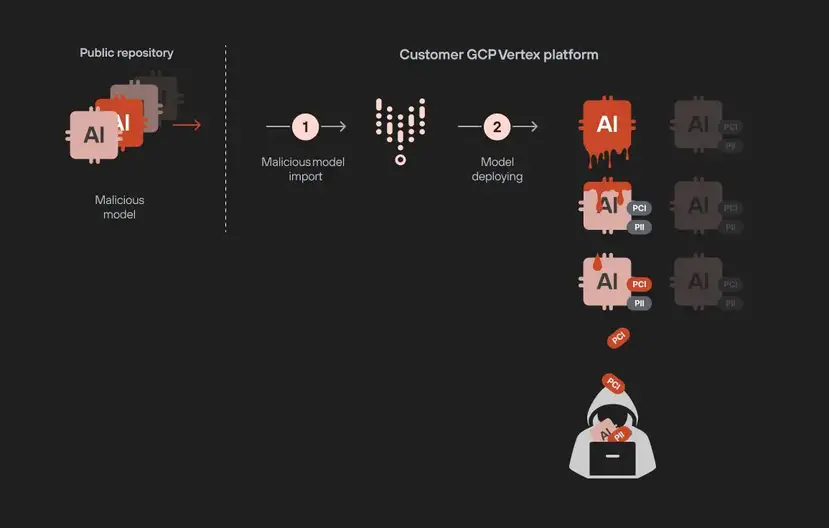
在最近的一份报告中,Palo Alto Networks 的研究人员披露了谷歌 Vertex AI 平台中的两个关键漏洞,这些漏洞可能使组织面临严重的安全风险。这些漏洞被称为 “ModeLeak”,可实现权限升级和模型外渗,可能允许攻击者访问 Vertex AI 环境中的敏感机器学习(ML)和大型语言模型(LLM)数据。
第一个漏洞是通过 Vertex AI 中的自定义作业进行权限升级。通过利用 Vertex AI Pipelines 中的自定义作业权限,攻击者可以访问整个项目的数据。报告指出:“通过操纵自定义作业管道,我们发现了一个权限升级路径,它允许我们访问远远超出预期范围的资源。这种访问权限包括从 Google 云存储和 BigQuery 数据集中列出、读取和导出数据的能力–这些操作通常需要更高级别的授权。”
通过自定义代码注入,研究人员演示了攻击者如何注入命令以打开反向 shell,从而在环境中创建后门。这一漏洞源于授予服务代理的默认权限,研究人员发现该权限过于宽泛。“凭借服务代理的身份,我们可以列出、读取甚至导出我们本不应该访问的数据桶和数据集中的数据。”
第二个漏洞带来了更为隐蔽的威胁:通过恶意模型进行模型外渗。恶意行为者可以将中毒模型上传到公共存储库,一旦部署,就会渗透到环境中的其他敏感模型。“想象一下恶意行为者将中毒模型上传到公共模型库的情景,”报告解释道。“一旦部署,恶意模型就会渗透到项目中的所有其他 ML 和 LLM 模型,包括敏感的微调模型。”这种情况创建了一个模型到模型的感染途径,嵌入在微调适配器中的专有信息可被攻击者复制和外渗。
Palo Alto Networks 此后与谷歌分享了这些发现,谷歌已部署了修复程序,以确保谷歌云平台(GCP)上 Vertex AI 的安全。为了抵御类似威胁,Palo Alto Networks 建议企业实施严格的访问控制,并密切监控模型部署流程。报告警告说,如果这些漏洞被威胁行为者利用,特别是在敏感数据驱动模型训练和调整的环境中,可能会造成广泛的后果。







发表评论
您还未登录,请先登录。
登录