本文将介绍如何基于RAG架构提升大模型在安全运营中的效率和准确性,探讨RAG为何天然适合安全日志分析任务。
安全运营现状
在日常工作中,安全运营人员每天都会遇到大量类似“父进程sh -cwhoami.dnslog.cn”的进程树告警。对于他们而言,“思考”判断此类父进程是否存在异常并非难事,往往只需稍加思考便能得出结论。虽然这一“思考”过程相当精准,但在面对海量日志时显得过于低效了。
如果能将这一“思考”过程自动化,安全运营效率必然显著提升。那么,如何实现“思考”的自动化呢?或许我们首先需要深入探究在“思考”过程中究竟发生了什么。
安全运营人员是如何思考的
大模型协助笔者分析了“思考”时的关键环节:
- 感觉皮层处理接收到的光信号,此时我们看到了颜色、形状;
- 联合皮层整合信息把颜色、形状转化为了字母、单词、告警、日志等信息;
- 丘脑、海马体、联合皮层合作检索相关记忆:安全知识、攻击特征、历史告警等;
- 前额叶推理得出结论,分析日志是否为攻击行为;
- 日志中的一些信息被大脑记录形成了新的记忆。
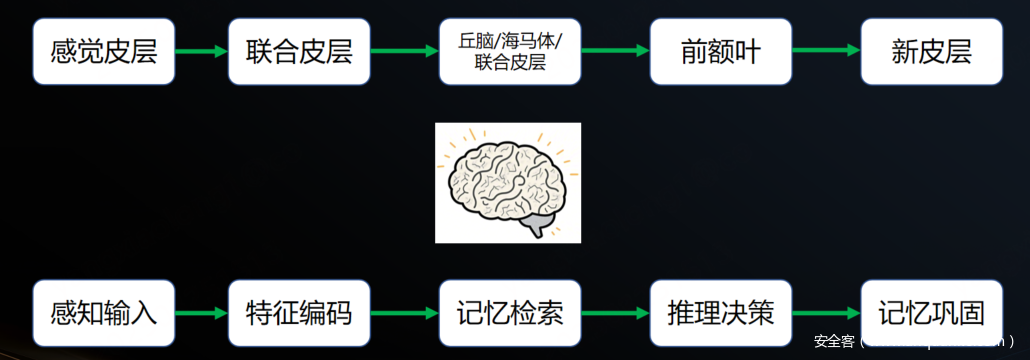
以上“思考”过程可以概括为5个流程:感知输入、特征编码、记忆检索、推理决策、记忆巩固。
显而易见,若能借助计算机高效且准确地执行这五个流程,安全运营效率将大幅提升。在感知输入方面,计算机已经表现出色,能够快速将电信号识别为0和1,并进一步转化为字符。而在特征编码、记忆检索、推理决策、记忆巩固这四个环节,我们其实早已开始了自动化尝试。
方案一:黑白名单
为了自动化研判安全日志,充分利用运营人员积累的安全经验,首先会采用的方案就是黑白名单。特征编码、记忆巩固对应人工提取样本特征的过程;记忆检索算法是遍历黑白名单+正则匹配;推理决策算法就是简单的 if else , 如果匹配到黑特征就是黑,匹配到白特征就是白。
这种方法足够简单粗暴有效,但有这些问题:
- 自动化程度不足,人工提取特征效率低
- 白名单设置过于严格会导致无法充分过滤误报
- 白名单设置过于宽泛可能会导致漏报
- 业务环境复杂,白名单要根据业务的变动而变动
方案二:机器学习
为了从人工维护黑白名单的痛苦中脱离出来,出现了使用机器学习的方法训练模型自动识别误报的方法。机器学习相当于一个高效且不太聪明的脑子,充分学习了黑白样本的特征,分析起来速度很快但不懂得变通。对于机器学习来说,特征编码对应是文本转向量算法,例如TF-IDF、Word2Vec;记忆检索、推理决策对应训练好的模型;记忆巩固则对应模型的训练过程。
机器学习自动化程度已经很高了,但仍有以下问题:
- 训练模型需要海量数据
- 规则更新需要重新训练
- 无法识别未出现过类型的误报
- 向量化过程会丢失原始日志中的一些信息
- 不同的安全场景需要训练不同的模型
RAG 原理
随着大模型的兴起,RAG 进入了笔者的视野,于是有了使用 RAG 来安全运营的想法。在此先简单介绍下 RAG 原理,可以简单分为如下几个步骤:
- 预处理数据后使用文本嵌入模型将数据向量化构建知识库;
- 使用文本嵌入模型将用户的问题转化为问题向量;
- 计算问题向量和知识库中每个向量的距离,距离最近的就判定是最相似的知识;
- 将用户的问题和查到的知识一起提供给大模型,大模型做出最终回答。
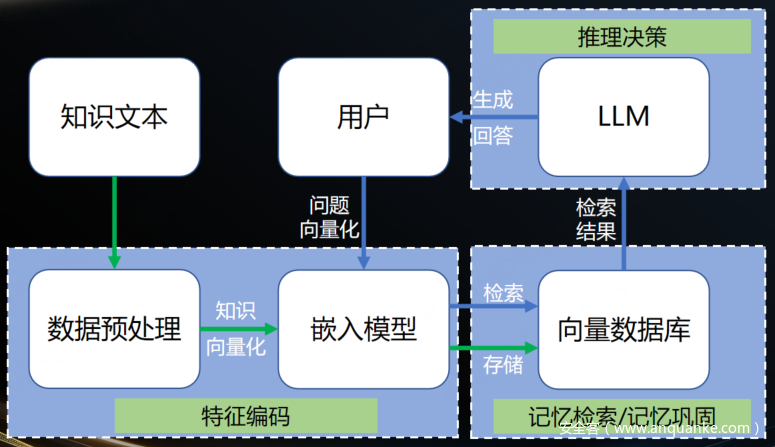
在 RAG 架构中,特征编码对应数据预处理、嵌入模型;记忆检索对应向量检索算法;推理决策对应大语言模型;记忆巩固对应向量数据库存储向量。
为什么 RAG 天然适合分析安全日志
特征编码
笔者每天都要面对如下格式的进程树日志:
Plain Text
/usr/lib/systemd/systemd
=> java -jar my-app.jar
=> curl white-list.com
如果要把这条日志转化为可复用的知识,黑白名单思路就是人工提取关键词,但这种方案效率低,且难以把握规则的严格程度。例如我们可以对 curl 父进程包含 my-app.jar 的日志加白,但如果该进程存在漏洞,攻击者通过漏洞执行了 curl 命令就会被漏报了。
机器学习思路则是采用”传统“嵌入模型(如Word2Vec)将日志向量化,向量化的过程就是提取”黑白名单特征“的过程,但同一单词的向量在不同的日志中始终是相同的,不能完美的表示出单词的潜在意义。例如日志中的两个 “jar” 字符串意义完全不同,”-jar“代表参数,”my-app.jar”代表文件名,但经过嵌入模型向量化后两者的向量始终是相同的,造成了信息的丢失。
而 RAG 则使用能力更强的动态向量模型——文本嵌入(Text Embedding)模型将日志向量化。文本嵌入模型能识别单词的潜在意义,一词多码,因此能更准确的提取日志的特征,更有利于准确的检索到相似向量。
传统词嵌入模型还需要自己搜集大量数据训练,且不能随意更换使用场景。而文本嵌入模型具有零样本(Zero-shot)学习能力,通用性、可迁移行极强。如今文本嵌入模型的能力在向量化安全日志的场景中是完全够用的,笔者在 MTEB(Massive Text Embedding Benchmark) 排行榜上随便挑了几个模型测试,没有发现明显区别。
记忆检索
RAG 常用于知识问答场景,其检索算法可以简单理解为计算问题向量和每个文档分片向量距离,对计算得到的距离进行排序,把距离最小的几个文档分片作为查询到的知识提供给大模型生成最终结果。但受限于文本嵌入模型的能力,很多情况下用户的问题向量无法和知识向量准确匹配。因此为了提高检索的准确性,所有的检索优化算法都尽全力让“问题向量”和“答案向量”更相似。
但对查询相似安全日志过程,我们是用”答案“查”答案“,显而易见的,”答案“和”答案“肯定比”答案“和”问题“更相似,传统问答场景中要面对的棘手问题在我们这里就完全不存在了,笔者只是使用最简单的欧氏距离就能取得相当不错的检索效果。
记忆巩固
把向量存到向量数据库里就行了。
推理决策 – 如何提升大模型的研判能力
大模型出现后,笔者对其推理能力相当看好,但刚开始尝试的效果并不尽如人意。
为了让大模型理解什么是攻击,为了修正大模型自身受限于训练语料导致的偏向性(比如带 sudo 的全部判定为提权),为了适配不同业务场景的不同情况,提示词一定是写的又臭又长,然而现阶段的大模型面对如此复杂的提示词,幻觉问题严重、顾此失彼,很难给出让人满意的研判结果。
关键信息的缺失也是导致大模型研判不准确的重要原因。面对一条告警日志安全运营人员尚且需要查资产、情报、业务、关联日志等各种额外的信息来辅助研判,只给大模型一条原始日志,不论大模型能力多么强都不会给出准确的回答。
为了解决上述问题,笔者总结了以下三种方法提升大模型研判安全日志的准确性:
- 少做事:让大模型一次只干尽量少的事儿。提示词越长越容易出幻觉,越容易激发大模型的短板,要把提示词尽量拆分,不要让不同功能的提示词之间互相影响。
- 扬长处:只让大模型干擅长的事情。比如用大模型从日志中提取域名和IP,可以先用正则提取包含”.“的字符串,再让大模型根据语意过滤脚本名称、版本号等特殊情况,从而高效的筛选出真实的域名和IP。
- 给信息:给大模型充足的信息用于研判。不同的场景需要不同信息,比如下载执行场景,只要有域名和威胁情报就会非常的准确。提供的信息越准确,研判结果越可信。
最终形成了如下图结构的大模型研判工作流: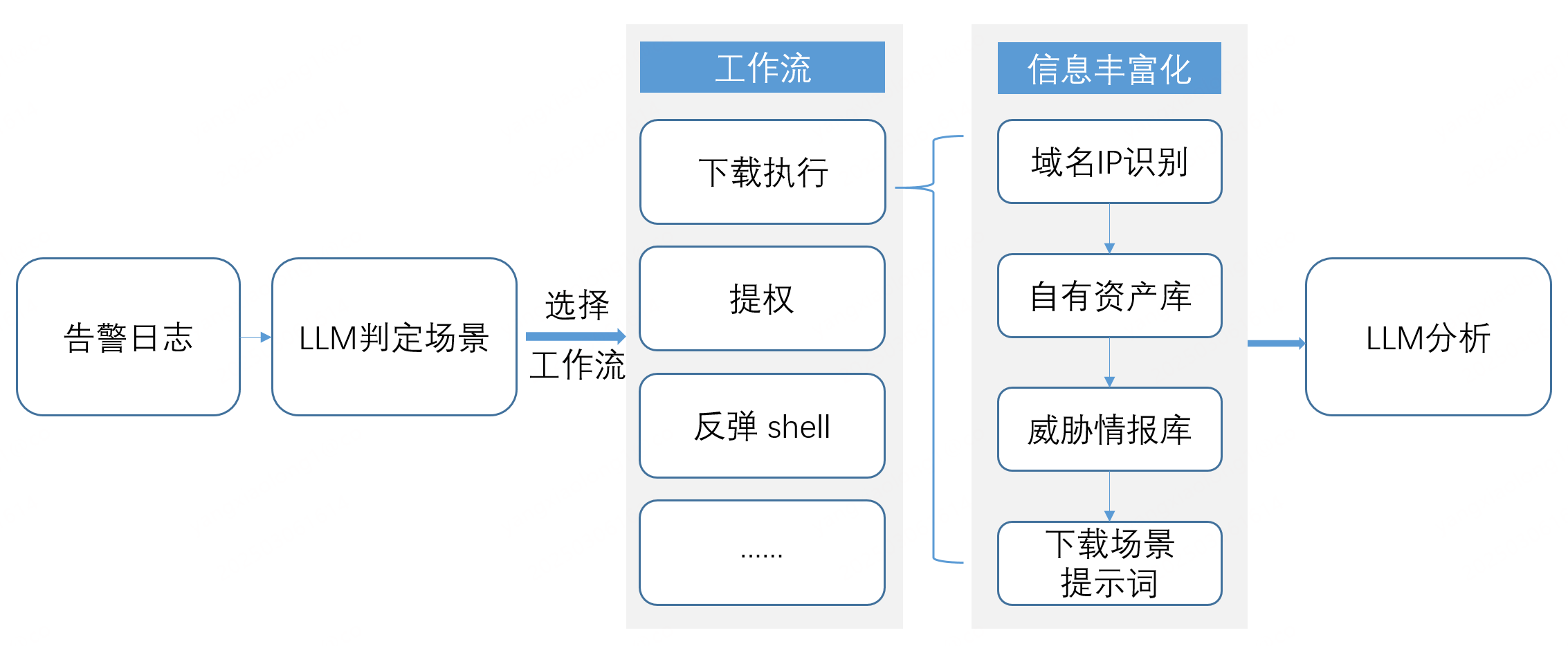
总结
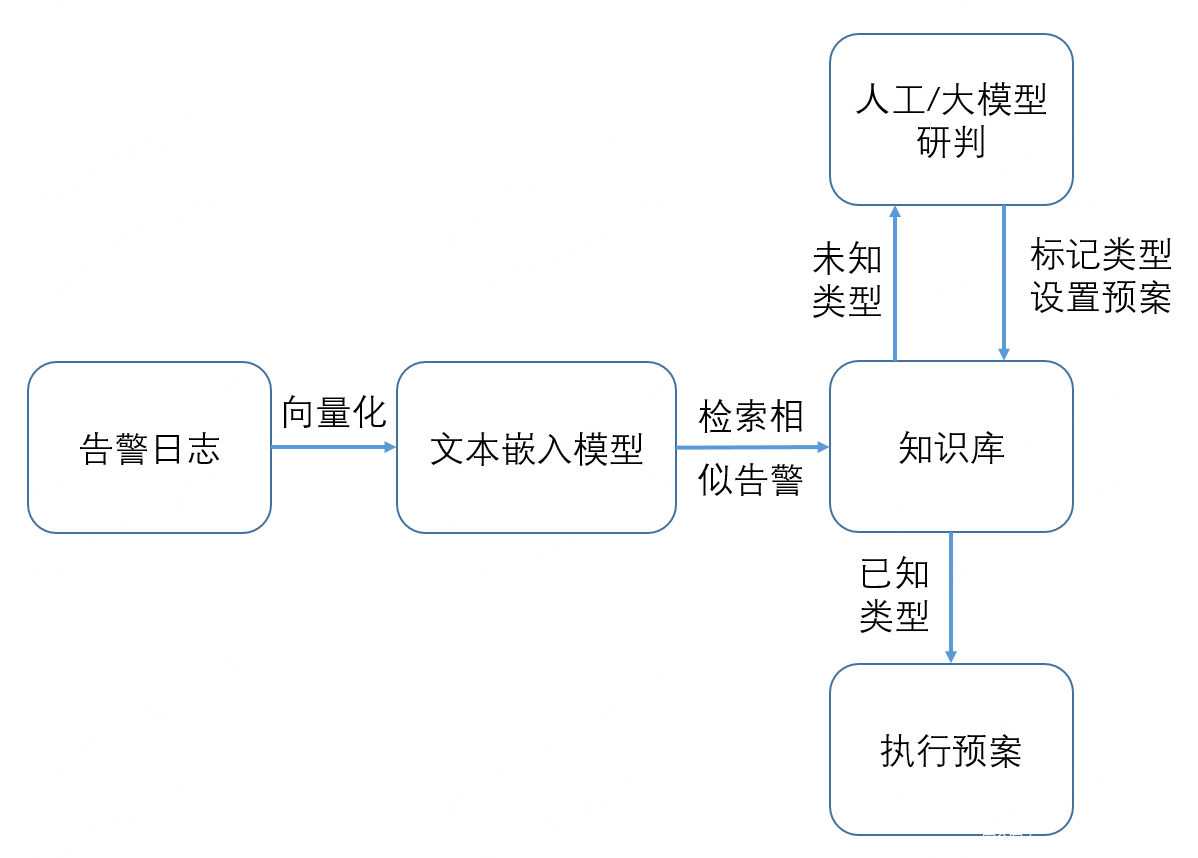
以上分析了 RAG 为什么能比传统黑白名单、机器学习更准确高效。在经过多次实践后,笔者最终构建了如下分析安全日志的流程,每天需要处理的告警降低90%以上:
- 将每条告警向量化从知识库中查询相似告警;
- 如果不存在相似告警,则交由人工或大模型研判,之后存入知识库;
- 如果存在相似告警,则按预案处理误报或真实告警。
![]()
最后再介绍下快速测试上述方案的环境:
- 向量数据库:ChromaDB 或 Milvus
- 文本嵌入模型:MTEB 排行榜任选
- 大模型工作流平台:Dify







发表评论
您还未登录,请先登录。
登录