

一、概要
在过去的俩年时间里,Hancitor恶意软件家族一直频繁地出现在网络攻击事件中,以至于在前线维护的人员几乎每周都要处理与他们相关的各种麻烦。在这段时间中,光恶意软件本身就已经有80多个变种。攻击者有时只是为了攻击需要,去定义一些新变量,而其他时候则是由编写者彻底重写了恶意软件的核心功能。此外,他们还会时不时地采用一些之前从未使用过的新技术。但这些情况的持续时间都非常短。所以我们把这些情况看作是他们的“测试”阶段。我怀疑恶意软件的编写者是在监视不同情况下恶意软件的感染率。当他们发现效果并不是想象中那么好的时候,这次测试也就不欢而散了。如果你对典型的Hancitor malspam(Malicious spam—恶意垃圾邮件)活动具体是如何运作感兴趣,Unit 42小组最近发布了一篇与之相关的博文,可以去看一下。而在这篇文章中,我将深入分析他们最新的恶意软件加壳技术。
在2018年1月24日、25日的攻击事件中,他们使用的是不同于一般的文档格式—富文本格式(RTF),并利用漏洞CVE-2017-11882来执行shellcode。该shellcode用于执行一PowerShell命令来下载一份标准的二进制文件。这里的标准是说Hancitor在数月的攻击中经常使用这份二进制文件。在通常情况下,Hancitor是通过带有恶意宏的Microsoft Word文档分发的,如果选择RTF文档则需要某种漏洞来执行代码。在过去,Hancitor一直保持与漏洞利用的距离,选择完全依赖社工的方法。这很可能是想规避防病毒检测(AV)以及终端检测响应(EDR)系统。
在24日的首个RTF变种其内容是相当直接的。然而,在25日的RTF文档就包含了一个与他们标准的二进制文件完全不同的嵌入式PE文件。此PE文件展示了Hancitor之前从未使用过的脱壳技术。这也是本篇文章将要介绍的重头戏。我的最终目标是要确定标准的Hancitor的命令与控制服务器(C2)的网址URL’S。因为就算是使用新的dropper,C2网址一般也不会更改。
以下分析皆由以下样本得出:
SHA256 : B489CA02DCEA8DC7D5420908AD5D58F99A6FEF160721DCECFD512095F2163F7A
二、RTF Dropper
我不会去深入漏洞的细节,简单来说,就是他们在RTF文档中利用CVE-2017-11882执行shellcode,从而执行PowerShell命令。此命令是将一个base64编码的PE文件写入磁盘。之后为其调用Start-Process cmdlet(在本地计算机上启用一个或多个线程的命令,可以指定执行文件,脚本文件等)。详细内容可以在这里找到。
$EUX4JTF7 = '';foreach($82OJU7FY3US in (1..12 | foreach{ '{0:X}' -f (Get Random -Max 235) })){$EUX4JTF7 += "$82OJU7FY3US"};
$NR3MNTAYNI = "$env:USERPROFILE" + $EUX4JTF7 + ".exe";[IO.File]::WriteAllBytes($NR3MNTAYNI,
[System.Convert]::FromBase64String('TVqQAAMAAAAEAAAA//8AALgAAAAAAAAAQAAAAAAA AAAAAAAAAA…<TRUNCATED>…AAAAAAAAAAAAA'));Start-Process $NR3MNTAYNI
三、Hancitor PE文件分析
在PE文件启动后,首先它会创建一个互斥锁称作“e”。然后开始利用一些防止反汇编的技术来阻止他人对其静态分析。一般来说大多流行的反汇编程序默认都是基于流程的反汇编(flow-oriented disassembly)而不是线性反汇编(linear disassembly)。这意味着当反汇编程序分析应用指令时,如果指令将程序的执行跳转到另一个位置,那么反汇编程序会按照指令跳转到对应位置后继续分析。所以在分支之后的所有字节命令将不会被分析以及反汇编。利用这种特性来混淆反汇编程序是一种非常常见的技术。
此次的样本就是在寄存器中存放了一个地址。然后将其作为一个CALL指令的参数来使程序跳转到反汇编程序没有分析过的代码段。因为反汇编程序在分析过程中不知道寄存器中存放的值,假设代码由于其他原因而未被分析,那么就会只是将其视为“数据”。在调试器中,这个问题非常地微不足道,因为你可以在任何你想重新分析的地方下断点。
按照上述内容跳转到未分析的代码后,恶意软件开始启用更多防止反汇编,防止调试的技术。具体来说就是,在执行代码过程中,在每一俩个指令之后都跟着跳转指令。通常情况下,你可以按照顺序地读取指令,并理解整个功能,但在每条指令间都插入跳转后,流程就会变得模糊且难以分析。因为你只能在你的屏幕上看到整个功能的一俩条指令。这就需要你一步步地跟踪调试了。
在本次示例中,代码首先加载 VirtualProtect()函数地址到EAX寄存器,并在栈上构建参数以便调用。再一次利用寄存器完成函数调用来进一步防止静态分析。一旦调用成功,它会获取此PE文件所在内存空间的所有权限,以此来设置读,写,可执行位。如下所示。这也是Hancitor采用的一种新技术。它在加壳过程中会有特殊的用法,我们会在稍后介绍。
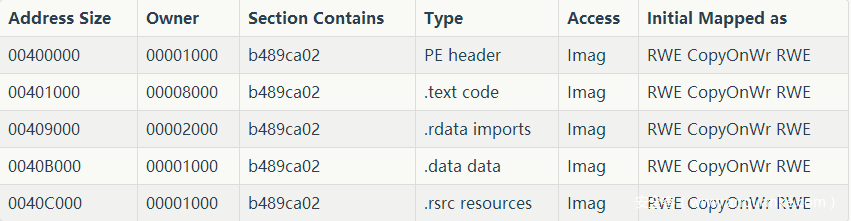
在给足执行中的程序所有的RWE权限后,意味着其可以被转移到任何想要映射的内存区域。当然通常是仅限于“代码”段。他们也没有理由不将其所有内容放到代码段。所以执行程序是否开放了所有RWE权限变成了一个很好的检测指标。这通常是通过原定义内存区域之外的隐藏代码来实现的。然而,在本样例中,实际上他们并没有在这块内存区域之外执行代码。所以调整权限是一种霰弹枪的行为(杀伤面积广,这里指调整权限可以有多方面的应用)。
接下来它采取的下一个操作依然是同样的指令跳转混淆。从地址0x402185开始,用0xD1去异或接下来的0xC80字节内容。其中一个有趣又很奇怪的点是他们将0x5AF06AD1给了EAX寄存器,但仅仅使用了低位字节—AL(0xD1),而忽略了其他三个字节。这不是Hancitor恶意软件第一次打算使用不完整的值。但是由于在代码中的错误引用导致它只能部分按照预期工作。解码过程如下所示:
004040EA 3007 XOR BYTE PTR DS:[EDI],AL
004040EC E9 8B000000 JMP b489ca02.0040417C
--
0040417C 41 INC ECX
0040417D EB DD JMP SHORT b489ca02.0040415C
--
0040415C 47 INC EDI
0040415D EB D8 JMP SHORT b489ca02.00404137
--
00404137 39F1 CMP ECX,ESI
00404139 0F81 24FFFFFF JNO b489ca02.00404063
--
00404063 0F82 81000000 JB b489ca02.004040EA
在这个循环完成了对新shellcode的解码后,它就会通过JMP指令将执行跳转到0x402185处。
为了展示还没有分析过的程序集,可以从调试器的角度看到在代码区中这些作为数据的字节值。
00402185 55 DB 55 ; CHAR 'U'
00402186 8B DB 8B
00402187 EC DB EC
00402188 81 DB 81
00402189 EC DB EC
0040218A 04 DB 04
0040218B 02 DB 02
0040218C 00 DB 00
0040218D 00 DB 00
0040218E 53 DB 53 ; CHAR 'S'
0040218F 56 DB 56 ; CHAR 'V'
00402190 57 DB 57 ; CHAR 'W'
00402191 60 DB 60 ; CHAR '`'
00402192 FC DB FC
通过告知调试器,我们所找到的需要重新分析的代码就可以让其变得可读。
00402185 . 55 PUSH EBP
00402186 . 8BEC MOV EBP,ESP
00402188 . 81EC 04020000 SUB ESP,204
0040218E . 53 PUSH EBX
0040218F . 56 PUSH ESI
00402190 . 57 PUSH EDI ; b489ca02.00402E05
00402191 . 60 PUSHAD
00402192 . FC CLD
四、最初的Shellcode
一旦进入这个新的shellcode中,它就开始利用GetProcAddress()函数来查找许多函数的地址。这些函数将会在整个脱壳过程中使用。函数名称并没有进行混淆,在经过上述过程解码后,就可以以纯文本的形式看到。
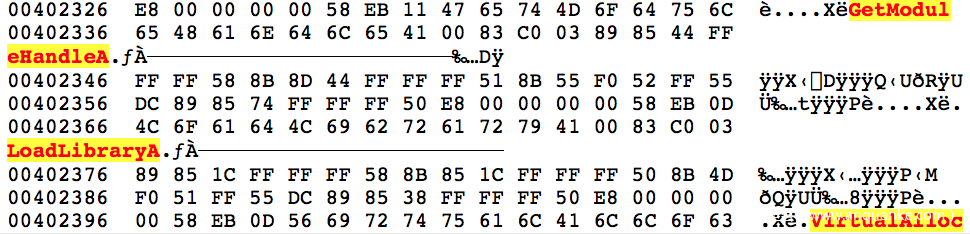
下面列出其查找的一些函数及dll名称:
- GetModuleHandleA
- LoadLibraryA
- VirtualAlloc
- VirtualFree
- OutputDebugStringA
- ntdll.dll
- _stricmp
- memset
- memcpy
在整个脱壳过程中,VirtualAlloc(), memcpy()和VirtualFree()函数主要用于数据移动以及现有数据覆盖。
在它找到上述所有函数地址后,样本将会开辟出0x1000字节的内存页并将所有的解码后的shellcode复制到其中。接下来它开始寻找彩蛋(俩个双字值)—0x88BAC570和0x48254000。其中第二个值从开头开始的4字节内容就是它要找的下一个地址值。这种寻找特定值的方法使得代码可以独立定位,并且这种方法几乎在所有的Hancitor变种中都可以找到。在识别出地址后,这个地址会被用在另一个“JMP EAX”指令中。作用是在新开辟的内存范围内将复制过来的shellcode的执行位置跳转到偏移量为0x3E4的新函数处。
五、数据设置
从流程控制的角度来看,尽管是从一个新的位置开始,但执行的是相同的代码。它释放了脱壳功能来覆盖掉Hancitor PE的主体代码。
首先采取的措施是覆盖掉三个位置的代码,通过将数据从代码段末尾复制到向前一些的区域内,如下所示:

在操作数据的过程中,发现了一个很好的例子可以说明其使用的一些反分析技术。
001F0453 EB 10 JMP SHORT 001F0465
001F0455 82EF 3D SUB BH,3D
001F0458 3C 5D CMP AL,5D
001F045A 53 PUSH EBX
001F045B C8 E8518D ENTER 51E8,8D
001F045F FB STI
001F0460 D9D0 FNOP
001F0462 231B AND EBX,DWORD PTR DS:[EBX]
001F0464 14 83 ADC AL,83
001F0466 C003 89 ROL BYTE PTR DS:[EBX],89
001F0469 8540 FF TEST DWORD PTR DS:[EAX-1],EAX
在上述代码的顶部你会注意到“JMP SHORT 001F0465”指令所跳转的地址并不在左侧的地址列表中。这是一种常见的混淆代码流程的技术。因为它是在指令边界范围内线性地进行反汇编(即按照顺序),但JMP指令重定向到了边界之外。一旦这个jump实现跳转,实际上是落在了指令0x1F0464的中间。代码将根据指令指针位置被重新分析,并且完全改变了其含义。
001F0465 83C0 03 ADD EAX,3
001F0468 8985 40FFFFFF MOV DWORD PTR SS:[EBP-C0],EAX
六、继续脱壳寻找更多的shellcode
下面所要介绍的就是脱壳实际发生的地方了,这也是本篇博客所要讲的主要部分。但在开始之前,如果你已经了解RC4加密算法的具体原理。包括初始化算法(KSA)以及伪随机子密码生成算法(PRGA),那么你可以选择跳过下面的前俩个部分。
一般来说加壳程序都是试图寻找去以不同于原始内容的方式修改数据或者代码,从而有效地达到混淆的目的。加壳程序本身并不坏,但它无疑为恶意软件添加了一层逃避检测的壳。所以他们更加倾向于携手并进。每一种加壳程序为了实现上述所说的最终目的,都会去尝试使用独特的算法。这就使得以编写代码来大规模自动化脱壳变得十分困难。代码加壳算法甚至可以是简单地对所有字节进行异或然后加密或者压缩。
在这次的样本中,他们创建出一种算法。是用RC4的初始化算法(KSA),然后配以用伪随机子密码生成算法(PRGA)循环生成的偏移量表来让命令重新组合成更多的shellcode。
七、RC4 初始化算法(KSA)
为了后续加密过程的展开,样例创建了在RC4 KSA中所用的S盒(S-box)。首先,它在栈上分配一个从0x0到0x100(0-256)的递增数组。
我已经在下述构建、修改S盒的代码中添加了详细注释。下述方法广泛应用于整个脱壳过程中。
# Counter Check
001F04CA 8B4D F8 MOV ECX,DWORD PTR SS:[EBP-8] ; Set ECX to counter value
001F04CD 83C1 01 ADD ECX,1 ; Increment counter by 0x1
001F04D0 894D F8 MOV DWORD PTR SS:[EBP-8],ECX ; Store counter on stack
001F04D3 817D F8 00010000 CMP DWORD PTR SS:[EBP-8],100 ; Compare counter to 0x100
001F04DA 74 61 JE SHORT 001F053D ; End loop if counter is at 0x100
# Add previous loop value to value found at index in array 2 and the counter
001F04DC 8B45 F8 MOV EAX,DWORD PTR SS:[EBP-8] ; Set EAX to counter value
001F04DF 33D2 XOR EDX,EDX ; Zero-out EDX register
001F04E1 F7B5 48FFFFFF DIV DWORD PTR SS:[EBP-B8] ; Divide counter by 0x10 to retrieve index value for array 2
001F04E7 8B85 40FFFFFF MOV EAX,DWORD PTR SS:[EBP-C0] ; Set EAX to value of array 2 offset
001F04ED 0FB60410 MOVZX EAX,BYTE PTR DS:[EAX+EDX] ; Set EAX to value at array 2 offset + counter
001F04F1 0345 EC ADD EAX,DWORD PTR SS:[EBP-14] ; Add previous result to EAX (0 on first run)
001F04F4 8B4D F8 MOV ECX,DWORD PTR SS:[EBP-8] ; Set ECX to counter value
001F04F7 0FB6940D FCFDFFFF MOVZX EDX,BYTE PTR SS:[EBP+ECX-204] ; Set EDX to value of array 1 offset + counter
001F04FF 03C2 ADD EAX,EDX ; Add the array 1 and array 2 values
001F0501 33D2 XOR EDX,EDX ; Zero-out EDX register
001F0503 B9 00010000 MOV ECX,100 ; Set ECX 0x100
001F0508 F7F1 DIV ECX ; Divide value in new value by 0x100
001F050A 8955 EC MOV DWORD PTR SS:[EBP-14],EDX ; Copy remainder value to stack (now "old" value)
001F050D 8B55 F8 MOV EDX,DWORD PTR SS:[EBP-8] ; Set EDX to counter value
# Swap the array 1 dereferenced values
001F0510 8A8415 FCFDFFFF MOV AL,BYTE PTR SS:[EBP+EDX-204] ; Set AL to value of array 1 offset + counter
001F0517 8845 F7 MOV BYTE PTR SS:[EBP-9],AL ; Store original value on stack
001F051A 8B4D F8 MOV ECX,DWORD PTR SS:[EBP-8] ; Set ECX to counter value
001F051D 8B55 EC MOV EDX,DWORD PTR SS:[EBP-14] ; Copy "old" value to EDX
001F0520 8A8415 FCFDFFFF MOV AL,BYTE PTR SS:[EBP+EDX-204] ; Set AL to value of array 1 offset + old value
001F0527 88840D FCFDFFFF MOV BYTE PTR SS:[EBP+ECX-204],AL ; Set first index in array 1 to new value
001F052E 8B4D EC MOV ECX,DWORD PTR SS:[EBP-14] ; Set ECX to counter value
001F0531 8A55 F7 MOV DL,BYTE PTR SS:[EBP-9] ; Copy "old" value from stack
001F0534 88940D FCFDFFFF MOV BYTE PTR SS:[EBP+ECX-204],DL ; Set second index in array 1 to old value
001F053B ^ EB 8D JMP SHORT 001F04CA ; Next iteration
在本次示例中,存在俩个数组,一个是在栈上构建的S盒数组,另一个是在新shellcode的0x455处的16字节的密钥数组。该密钥数组用来修改整个KSA的值(其实就是将S盒扰乱,同时保证扰乱是随机的)。他利用计数器的计数值(即迭代次数)与0x10进行模运算,得到的结果被用作密钥数组的索引。将根据此索引找到的值加到前一次迭代产生的最终值里。如果是第一次迭代,这个最终值为0。在俩个值相加后,他会将计数器的计数值加到总和中。然后以0x100作为模数进行模运算,其结果就是下一次迭代新的最终值。
在上述迭代完成后,它会将最终值作为256字节的S盒的索引,并交换计数器计数值作为索引所指向的值与最终值作为索引所指向的值。这就是RC4 初始化算法。
这里有一个在循环中迭代0x14时的一个例子。一些数据已经被修改,你可以看到0xC6后,在偏移量为0x13处,存在递增量0x14,0x15,0x16,0x17等。

对于0x14,它通过模0x10得到结果0x4,将其作为在密钥数组中寻找值的索引。在密钥数组中key[4]的值为0x5D,所以将它与前一个最终值0xC6相加(可以在偏移量0x13处找到,就是上图中0x14前边的值)。
0x5D + 0xC6 = 0x123
接下来,它将计数器的计数值加到上述结果中。对于第一次迭代,计数索引指向值与计数值相等,但是最终这些值会被覆盖,其值也会相应地改变。
0x123 + 0x14 = 0x137 % 0x100 = 0x37
现在sbox1[0x37]与sbox1[0x14]的值已经进行了交换,如下所示:

在下一次迭代中,密钥值为0x53,计算过程变为如下:
(0x53 + 0x37 + 0x15) % 0x100 = 0x9F
即sbox1[0x9F]与sbox1[0x15]互换值。
你会在上述示例的输出中看到偏移量为0x1A处的值为0xC。在迭代0x1A后,0xC会与密钥以及前一个最终值相加。这会发生在256次迭代的每一次迭代中并且每次的值都是从其原始位置开始转换的。Talos在2014年有一篇很好的博文来讨论关于恶意软件中的S盒。至于RC4,你可以在维基上找到其完整的概述。
下面是我用python写的关于上述内容的代码,相较于文字描述,代码可能会更加让人容易理解。
def sbox1init():
return [x for x in range(0, 0x100)]
def rc4ksa(sbox1, key):
oldValue = 0x0
for counter in range(0, len(sbox1)):
addValue = key[counter % len(key)]
fnlValue = (oldValue + addValue + sbox1[counter]) % 0x100
sbox1[fnlValue], sbox1[counter] = sbox1[counter], sbox1[fnlValue]
oldValue = fnlValue
return sbox1
key = [0x82, 0xEF, 0x3D, 0x3C, 0x5D, 0x53, 0xC8, 0xE8, 0x51, 0x8D, 0xFB, 0xD9, 0xD0, 0x23, 0x1B, 0x14]
sbox1 = rc4ksa(sbox1init(), key)
在python代码中,第一次迭代,sbox1[0x0]的值为0x00,且key[0x0]的值为0x82。之后将0x0加到0x82上,然后再加0x0(sbox1[counter]的值),然后将结果除以0x100。得到的余数为0x82,将其放置在sbox1[0x0]处,再之后sbox1[0x0]处的值将与sbox1[0x82]处的值交换。实际上,有很多更清晰的RC4 KSA在线代码示例,但为了学习,同时为了查看恶意软件作者在引入RC4算法过程中是否有错误,我选择完全按照其使用的逻辑复现了他的所有内容。
八、RC4 伪随机子密码生成算法(PRGA)
RC4 PRGA主要用于脱壳过程中循环生成密钥流。但是如何使用该值是本文的重要内容,也是恶意软件作者不同于RC4算法之处。
我会简单地介绍一下PRGA,然而再进到循环脱壳过程中。
利用循环计数器作为原始S盒的索引,PRGA将sbox1[counter]的值加到之前的密钥流值上来得到第二个索引(secondindex)。这些值将在S盒中进行交换,类似于KSA。最后,它将检索sbox1[counter]以及sbox1[secondindex],并将他们相加,然后以0x100作为模数进行模运算,将得到的结果作为新的密钥流值。
例如,第一个引用的值(在本示例中计数器从1开始)是sbox1[0x1],在完成KSA后为0x7。sbox1[0x7]处的值为0xA6,之后他们彼此交换值,所以sbox1[0x1]处的值为0xA6而sbox1[0x7]处的值为0x7。然后将0xA6与0x7相加得到0xAD,检索sbox1[0xAD]的值,这里是0x58,将其作为密钥流值。
好的,到这的话,如果是常规RC4算法接下来只要将密钥流与明文异或得到密文或是与密文异或得到明文就可以了。但是正如你想的那样,Hancitor并非如此。
九、偏移量表
我们把视线回退到S盒生成结束后,下一步是分配俩块内存区域。然后,通过一串递增到0x5C36的数组填充第一块区域。但在这里它在存放的值不再是单字节而是双字。该内存区域将会是另一个功能性的S盒。
接下来,它开始进入主要的循环脱壳阶段也是整套操作的重中之重。在每一次的迭代循环中,它都会使用内循环(之前所详细描述的RC4 PRGA)来检索1字节的密钥流值—在每个外循环下执行4次内循环。
在得到4字节的密钥流值后,它会将4字节内容拼接成一个双字。然后以外循环的计数值作为模数进行模运算—计数值初始值为数据长度(0x5C36),之后递减且每次减1。
例如,密钥流值的前四个字节为0x58, 0x58, 0xF2和0xEA。首先将他们拼接成0xEAF25858。然后进行模运算:
0xEAF25858 % 0x5C36 = 0x5200
此结果会作为第二个双字S盒的索引。接下来找到索引所指向的值并将其存储到第三块内存区域,每次偏移量加4。最后,他会交换在第二块内存区域找到的值与在第二个S盒中根据索引找到的值。
在本次示例中,第三块内存区域的首个双字值为0x5200。所以它将第二块内存区域偏移量为0x5200处的值与计数值进行交换,即为0x5C35(4字节递减)。偏移量为0x5C35处的值也就变成了0x5200。
此过程一直持续到外循环结束,一旦完成,它将分配另一个内存区域,用于存放从主程序地址为0x401000处开始向后0x5C36个字节的内容。
好的,如果你坚持看到了这里。我想传达的就是,上述所有内容就是在创建一个详细的双字偏移量表,用作索引,定义了如何将数据还原回去,也是最终下面要发生的事情。
对于在新内存区域内的每一个字节,也就是地址范围从0x401000-0x406C36复制过来的数据。它会从0x401000开始迭代,每一个加上其相应的双字值,然后复制该字节。提醒一下,在此复制过去的数据与最初调用三次memcpy()移动的数据相同。
如前所述,第三个内存区域的首个双字内容是0x5200,且0x401000处的第一个字节是0x8B,因此在0x406200(0x401000 + 0x5200)处其值为0x8B。没有改变任何字节值,这是在标准的RC4算法中所实现的,只是将他们重新排列成他们各自的顺序。
为了帮助理解上述内容,下面给出上述算法的python版本。为了节省空间,我将数据删除了,可以在Github上找到完整版。
def sbox1init():
return [x for x in range(0, 0x100)]
def sbox2init():
return [x for x in range(0, 0x5C36)]
def rc4ksa(sbox1, key):
oldValue = 0x0
for counter in range(0, len(sbox1)):
addValue = key[counter % len(key)]
fnlValue = (oldValue + addValue + sbox1[counter]) % 0x100
sbox1[fnlValue], sbox1[counter] = sbox1[counter], sbox1[fnlValue]
oldValue = fnlValue
return sbox1
def offsetGen(sbox1, sbox2):
offsetTable = []
innerCount = 1
oldValue = 0x0
for counter in range(len(sbox2), 0, -1):
fnlValue = ""
for x in range(0, 4):
innerIdx = innerCount % len(sbox1)
oldValue = (sbox1[innerIdx] + oldValue) % 0x100
addValue = (sbox1[oldValue] + sbox1[innerIdx]) % 0x100
sbox1[innerIdx], sbox1[oldValue] = sbox1[oldValue], sbox1[innerIdx]
fnlValue = "%02X" % sbox1[addValue] + fnlValue
innerCount += 1
fnlValue = int(fnlValue, 16) % counter
offsetTable.append(sbox2[fnlValue])
sbox2[fnlValue], sbox2[counter-1] = sbox2[counter-1], sbox2[fnlValue]
return offsetTable
def unshuffle(data, offsetTable):
unshuffle = [0x0] * len(offsetTable)
data = [data[x:x+2] for x in range(0, len(data), 2)]
for counter, entry in enumerate(offsetTable):
unshuffle[entry] = chr(int(data[counter], 16))
return "".join(unshuffle)
key = [0x82, 0xEF, 0x3D, 0x3C, 0x5D, 0x53, 0xC8, 0xE8, 0x51, 0x8D, 0xFB, 0xD9, 0xD0, 0x23, 0x1B, 0x14]
data = ""
offsetTable = offsetGen(rc4ksa(sbox1init(), key), sbox2init())
data = unshuffle(data, offsetTable)
大功告成,在完成整个脱壳算法后,你就会在Hancitor恶意软件中看到熟悉的字符串了。

十、Hancitor
在执行回主程序之前,他们通过调用OutputDebugStringA()函数来检查程序是否处于被调试状态。在检查通过后,他就会开始执行在0x404000处的代码。
我不会再花费太多时间在Hancitor的各种功能上了,因为实在是太多。下面这些是本次特定样本实现的功能。
- 获取操作系统版本
- 获取适配器地址
- 获取 Windows目录
- 获取音量信息
- 利用api[.]ipify[.]org检查外网IP
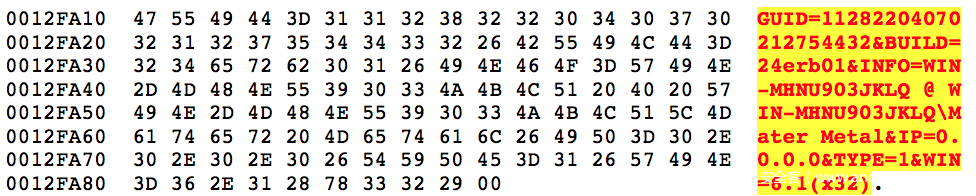
在完成收集它所需要的信息后,会根据你的计算机架构是x86还是x64,按照以下格式,通过POST发往Hancitor的C2网址。

按照参数内容将收集到的信息填充后,变成如下形式:
十一、C2地址
回到我深入研究这个问题的原因,是因为我在过去的俩年里一直在维护一个Hancitor decoder。对于每一种其新出现的变种,我都试着找到一种方法来找到Hancitor的C2网址,以便对其快速识别并加以防范。对于本文中的变种,即使经过了上述所有的脱壳过程,我依然没有找到其C2网址。
为了解决这一问题,我们必须进一步深入研究代码。在脱壳得到的shelllcode的0x402b51处,我们发现了其调用了一系列Windows解密函数,用来解密一组加密数据。将其解密得到了Hancitor的C2 URL’s。
- CryptAcquireContextA
- CryptCreasteHash
- CryptHashData
- CryptDeriveKey
- CryptDecrypt
- CryptDestroyHash
- CryptDestroyKey
在这里使用的算法是SHA1以及RC4加密。它使用一个8字节的值(0xAAE8678C261EC5DB)来派发SHA1密钥,然后解密0x2000字节内容。

上述解密出的内容第一部分是与攻击日期相关的代码。在本次示例中,日期为1月24日。随后是三个Hancitor C2网址。
十二、总结
在Hancitor不断发展的过程中,他们一直都在坚持一个相当严格的模板。本次的示例实际上很大程度上地偏离了他们之前的模板。我们也只是在他们回退回使用其他或者更老变种之前的这一场攻击中看到其应用本次示例。这可能是由于它的加壳方式被更加频繁地检测了出来或者由于一些其他原因导致其感染率降低,从而使得他们不再采用这种方法了。无论如何,最重要的还是继续跟踪其攻击行为记录他们所使用的新技术、策略。
十三、IOCs
Hancitor Gates
- hxxp://naveundpa[.]com/ls5/forum[.]php
- hxxp://undronride[.]ru/ls5/forum[.]php
- hxxp://dingparjushis[.]ru/ls5/forum[.]php
User-Agent
- Mozilla/5.0 (Windows NT 6.1; Win64; x64; Trident/7.0; rv:11.0) like Gecko







发表评论
您还未登录,请先登录。
登录