

前言
上一篇了解了一下差分分析,这次我们结合一道CTF题目聊一聊线性分析
同属于选择明文的差分分析不同,线性分析属于已知明文攻击方法,它通过寻找明文和密文之间的一个“有效”的线性逼近表达式,将分组密码与随机置换区分开来,并再此基础上进行密钥恢复攻击。
在正式介绍线性分析之前,我们还是要介绍一下相关的基础概念,参考《分组密码的攻击方法与实例分析》一书
基础概念
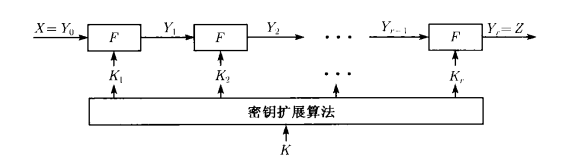
首先还是给出和差分分析一样的一个迭代分组密码的加密流程
迭代分组密码的加密流程
内积

线性掩码

线性逼近表达式

线性壳
迭代分组密码的一条 i 轮线性壳是指一对掩码(β0,βi),其中β0 是输入掩码,βi 是输出掩码。
线性特征

线性壳的线性概率
线性特征的线性概率

线性区分器
先给出一个命题,对{0,1}^n 上的随机置换R,任意给定掩码α,β,α ≠ 0,β ≠ 0, 则 LP(α,β ) = 0, 即 偏差 ε(α,β) = 0
如果我们找到了一条 r-1 轮线性逼近表达式 (α,β),其线性概率 LP(α,β) ≠ 0,即偏差 ε(α,β) ≠ 0。则利用该线性逼近表达式可以将 r-1 轮的加密算法与随即置换区分开来,利用该线性区分器就可以对分组密码进行密钥恢复攻击。假设攻击 r 轮加密算法,为获得第 r 轮的轮密钥的攻击步骤如下。
步骤1
寻找一个 r – 1轮的线性逼近表达式 (α,β) ,设其偏差为ε(α,β),使得 |ε(α,β)|较大。
步骤2
根据区分器的输出,攻击者确定要恢复的第 r 轮轮密钥 k_r(或者其部分比特):设攻击的密钥比特长度为 l,对每个可能的候选密钥gk_i, 0 ≤ i ≤ 2^l -1,设置相应的 2^l 个计数器λ_i,并初始化。
步骤3
均匀随机地选取明文 X,在同一个未知密钥 k 下加密,(一般是让拥有密钥地服务端帮你加密)获得相应地密文 Z, 这里选择明文地数目为 m ≈ c ·(1/ε ^2),c 为某个常数。
步骤4
对一个密文Z,我们用自己猜测地第 r 轮轮密钥 gk_i(或其部分比特)对其进行第 r 轮解密得到Y_{r-1},然后我们计算线性逼近表达式 α x · X ⊕ β · Y_{r-1} 是否为0,若成立,则给相应计数器λ_i 加 1
步骤5
将 2^l 个计数器中|λ/m – 1/2| 最大地指所对应地密钥 gk_i(或其部分比特)作为攻击获得地正确密钥值。
Remark 针对步骤1中,我们如何去寻找一个高概率地 r -1 轮线性逼近表达式呢?例如针对一个S盒,我们可以选择穷举所有的输入、并获得相应的输出,然后穷举输入掩码、输出掩码,去获取这个S盒的相关线性特性。
下面就根据一道CTF中出现的赛题来解释分析上述过程。
实例-[NPUCTF2020]EzSPN
task.py
import os
from binascii import hexlify, unhexlify
import Crypto.Random.random as random
from secret import flag
SZ = 8
coef = [239, 163, 147, 71, 163, 75, 219, 73]
sbox = list(range(256))
random.shuffle(sbox)
sboxi = []
for i in range(256):
sboxi.append(sbox.index(i))
def doxor(l1,l2):
return [x[0]^x[1] for x in zip(l1,l2)]
def trans(blk):
res = []
for k in range(0, SZ, 8):
bits = [bin(x)[2:].rjust(8,'0') for x in blk[k:k+8]]
for i in range(8):
res.append(int(''.join([x[(i+1) % 8] for x in bits]),2))
res[k:k+8] = [(coef[i] * res[k+i]) % 256 for i in range(8)]
return res
def encrypt_block(pt, ks):
cur = doxor(pt, ks[:SZ])
cur = [sbox[x] for x in cur]
cur = trans(cur)
cur = [sboxi[x] for x in cur]
cur = doxor(cur, ks[SZ:])
return cur
def encrypt(pt, k):
x = 0 if len(pt)%SZ==0 else (SZ-len(pt)%SZ)
pt += [x]*x
ct = ''
for i in range(0, len(pt), SZ):
res = encrypt_block([x for x in pt[i:i+SZ]], k)
ct += ''.join(["{:02x}".format(xx) for xx in res])
return ct
def doout(x):
if len(x) % 16:
x = (16 - len(x) % 16) * "0" + x
return x
def doin(x):
return list(unhexlify(x))
def genkeys():
return list(os.urandom(2*SZ))
if __name__ == "__main__":
print(sbox)
key = genkeys()
ct = encrypt(flag, key)
print(ct)
while True:
pt = doin(input())
print(doout(encrypt(pt, key)))
题目提供一个交互,能够加密你的输入并返回密文。所以这里是否可以采用差分分析的攻击方法呢,但这里我们讨论的线性分析,所以我们就用线性分析来做这道题目里。
那么看到这里所用加密系统的流程。
关键函数是encrypt_block(pt, ks),
首先是一个明文和一半的密钥异或,然后是进入S盒(题目每次随机生成并提供S盒具体内容),然后trans一下,再进入一个逆S盒,最后再和另一半的密钥异或。
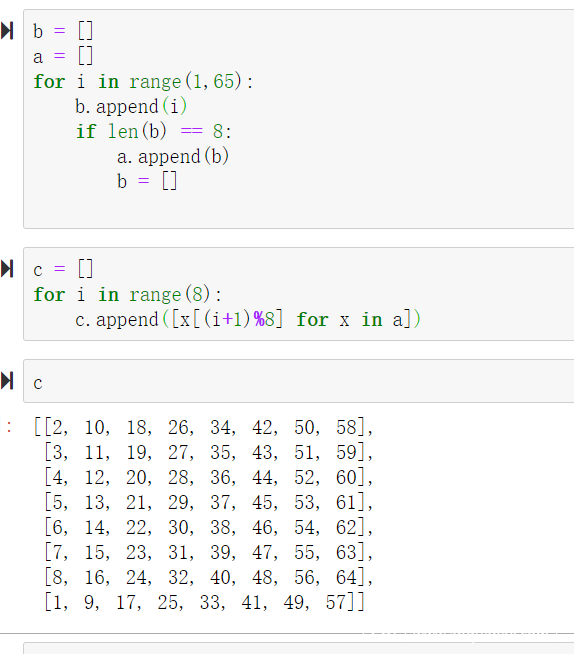
看到这个trans函数,这里有一个int(‘’.join([x[(i+1) % 8] for x in bits]),2),这个(i+1%8)有点类似位移的效果,然后是乘以了一个系数,但这个系数已经定死了,所以没有什么关系。
首先测一个这个trans函数的一个位移效果,大概类似这样
然后整个流程图(画的丑了点)
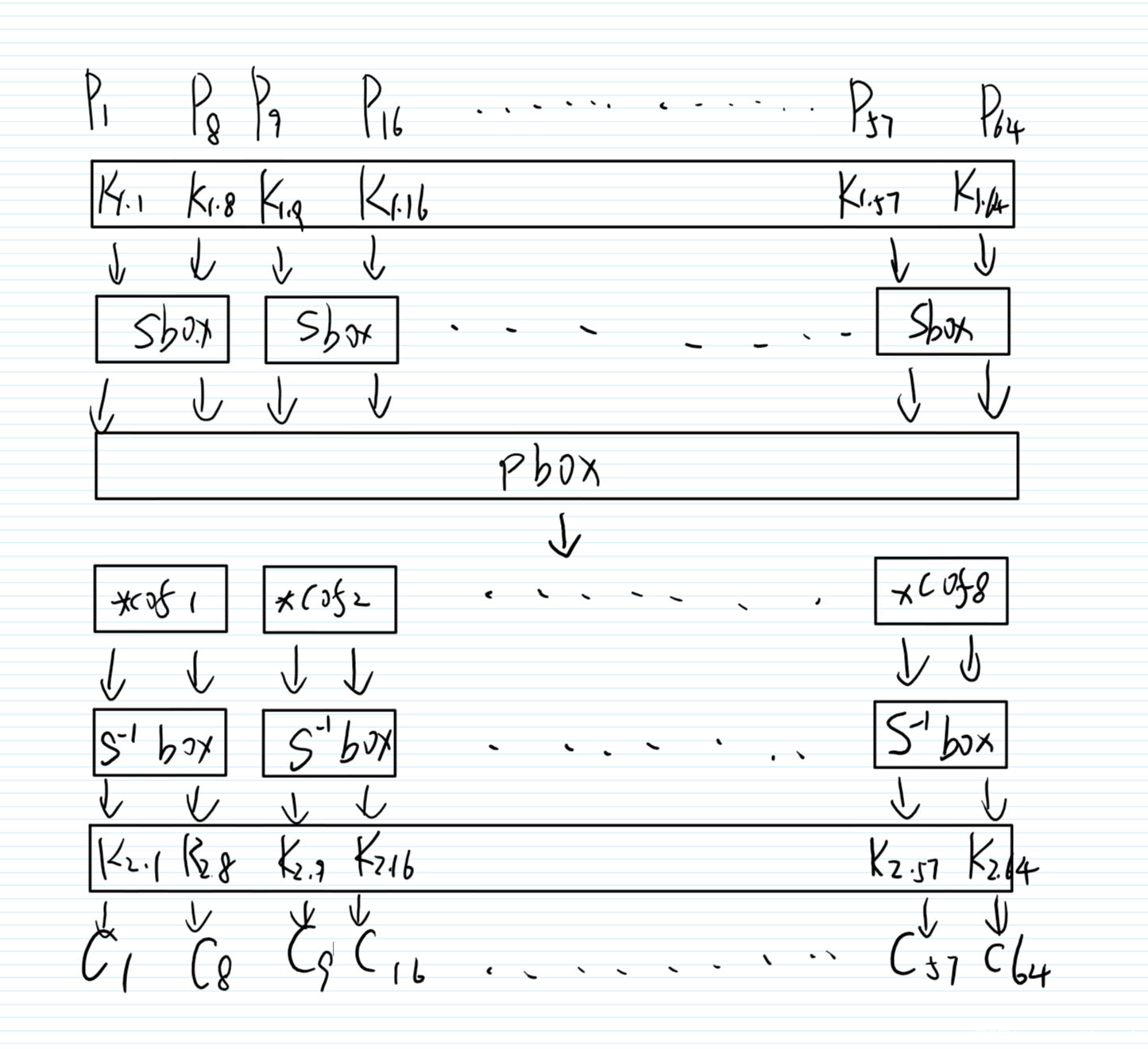
那么针对这道题,我们利用线性分析攻击手法,
首先步骤1,我们去分析S盒的线性特性以找到使得线性表达式偏差大的掩码对(α,β)。我们穷举所有的S盒的可能的输入并计算出相应的输出,然后穷举所有的输入、输出掩码的组合,然后根据其是否符合满足线性逼近表达式 α · X ⊕ β · F(X,K) = 0 来更新计数器,最后我们计算相应的偏差表offset
def linearSbox():
global linearInput
for i in range(256):
si = sbox[i]
for j in range(256):
for k in range(256):
a = bitxor(i, j) # 线性估计输入
b = bitxor(si, k) # 线性估计输出
if a == b:
offset[j][k] += 1
for i in range(256):
offset[i] = [abs(x - 128) / 256 for x in offset[i]]
for linearOutput in range(256):
cur = [x[linearOutput] for x in offset]
linearInput.append(cur.index(max(cur)))
其中j是输入掩码,k是输出掩码。
这里的offset以输入掩码为行,输出掩码为列,所以这里的cur是获取同一输出掩码下不同输入掩码的偏差
并且在linearInput中记录下同一输入掩码下使得线性表达式偏差最大的输出掩码。
这里我们简单看一下输出的offset表
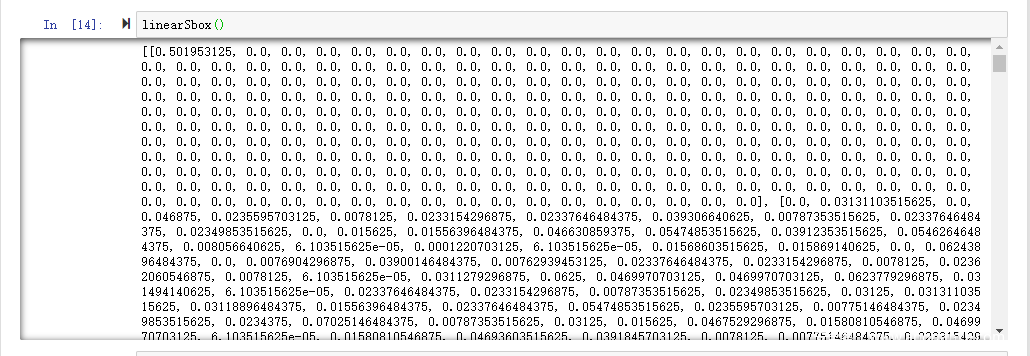
可以看到列表的第一行很特殊,除了第一个是0.5这个极大的值以外,其他都是0。因为在输入掩码为0、输出掩码也为0的话,肯定是能够满足的情况下,针对所有的输入、输出肯定是都能满足线性逼近表达式的,所以偏差达到了最大,0.5。但是换做其他输出掩码的话,针对所有的输出,其最后的表达式的结果分布得很均匀,所以偏差为0。
再举第二行第一列的0.03131…这个值的含义:就是针对所有的256个输入,当输入掩码为1,输出掩码为1时的线性逼近表达式的偏差。即有 256 * (0.03+0.5) ≈ 135 个输入满足(或者不满足)这个线性逼近表达式。
有了S盒的线性特性之后,步骤2是设置一个计数器counter,然后我们开始进入步骤3搜集明文密文对。就随机选择明文,发送给服务端,然后接收服务端返回的密文即可。
接着开始步骤4,由于这里有两轮加密,然后我们在步骤1已经生成了关于单个S盒的一个offset表,这个就相当于是 1 轮线性特征了,那么我们接下来就按照线性分析的攻击思路,
这里我们按字节猜测密钥,首先拿一个密文的第一个字节,异或第一个字节的密钥(枚举)后从S逆盒出去,然后把系数coef除掉,再根据P盒,把这个值换到相应的位置,然后这里我们根据S盒的线性特征选取合适的输出、输入掩码对我们的这对输入进行测试。若满足线性逼近表达式,则True计数加一,否则False计数加一。
最后步骤5,针对每个字节我们都测一万对,取结果偏差最大的key值。这样就完成了密钥每个字节的猜测。
结合代码再细细讲一遍
def calcOffset(pt, ct, j, guessed_key): # 猜测第j段子密钥
pt = list(unhexlify(pt))
ct = list(unhexlify(ct))
ct[j] ^= guessed_key
ct[j] = sbox[ct[j]] # sbox即为sboxi的逆
ct[j] = (ct[j] * coef[j]) % 256
u1 = bitxor(pt[0], linearInput[1 << ((6 - j) % 8)])
u2 = bitxor(ct[j], 0b10000000)
if u1 == u2:
return True
else:
return False
def linearAttack():
key2 = []
for i in range(8): # 第二轮子密钥的第i段
count = [0 for _ in range(256)]
for guessed_key in range(256):
print("[+] Cracking key...({}-{})".format(i, guessed_key))
for j in range(10000):
if calcOffset(plain[j], cipher[j], i, guessed_key) == True:
count[guessed_key] += 1
bias = [abs(x - 5000) / 10000 for x in count]
key2.append(bias.index(max(bias)))
return key2
linearAttack()中我们主要关注那个循环。这里调用了calcOffset函数,传入了一对明文密文对(plain[j], cipher[j])、索引(i)、以及猜测的密钥(guessed_key)。
在calcOffset中,首先用密文异或了guessed_key,然后根据值获取从Sbox的输入,然后乘以了coef(这里已经是原来coef的逆了),接着是u2 = bitxor(ct[j], 0b10000000),用了0b10000000作为掩码,即选取了密文的第一个bit。然后选取 linearInput[1 << ((6 – j) % 8)] 做为明文第一个字节的掩码。
为什么只选明文的第一个字节,以及其掩码的选取这里可能看的不是很直观,因为这里其实包含了两部分。
我们需要回去注意到P盒。当这里j=0,即爆破第一个字节的密钥时,我们选取的是密文的第1个字节,掩码选的是第1个bit,那么这是从P盒输入的哪个bit传来的呢,从P盒我们可以看到这是P盒输入的第一个字节的第2bit传来的,那么P盒输入的第2bit,实际上就是S盒输出的第2bit,也就是S盒的输出掩码为0b01000000,也就是1 << 6。而这个 linearInput 存的就是输出掩码为某个值的使得线性逼近表达式偏差最大的输入掩码。
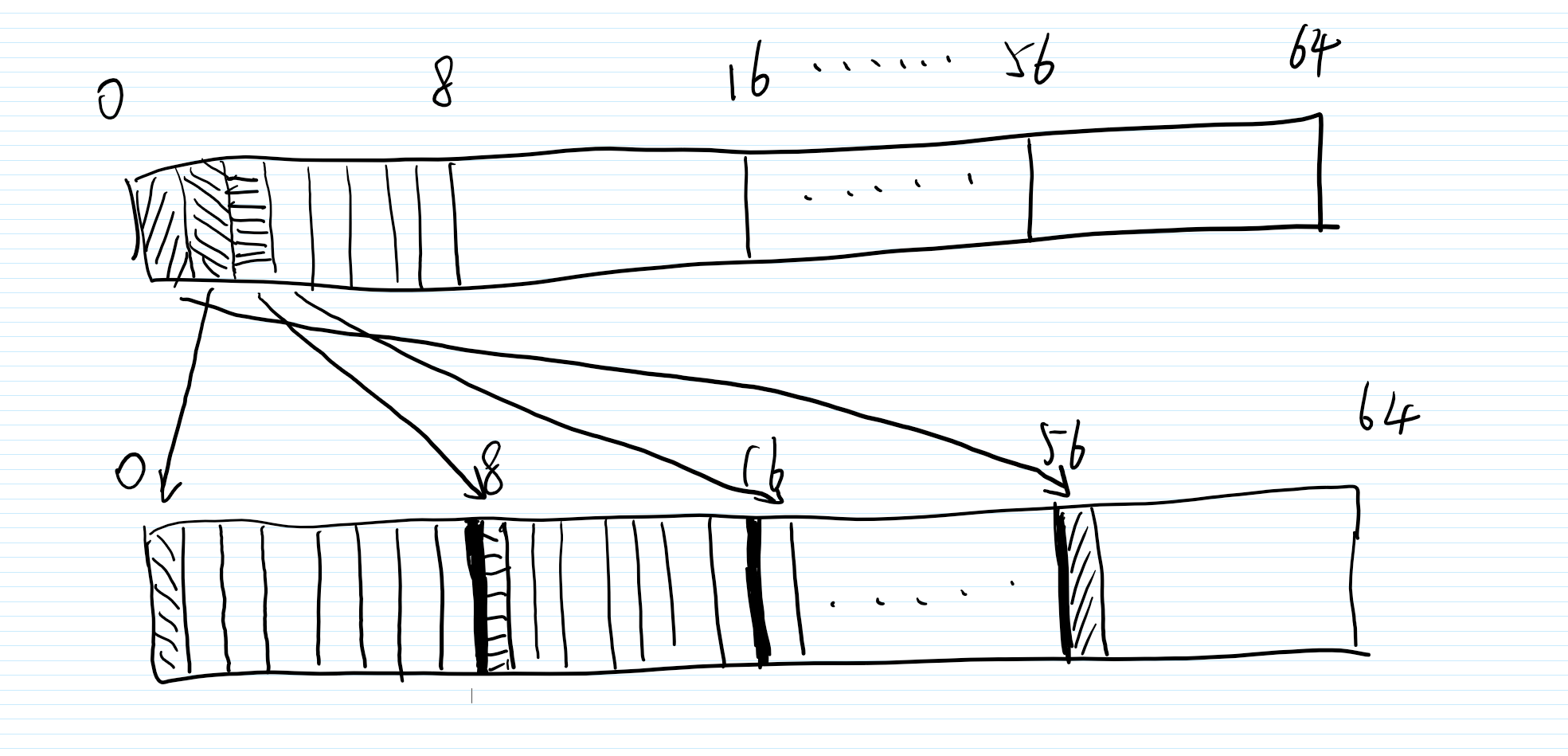
当我们选取密文第二个字节的时候,根据P盒,第二个字节第1个bit来自于明文第一个字节第3个bit,也就是0b00100000,也就是1 << 5,同理可推
所以这里只用选明文的第一个字节,密文不同字节的第一个比特,且输入掩码为 linearInput[1 << ((6 – j) % 8)]。
另外可能还有一个问题,S盒的输入不是明文啊,应该是明文异或了第一个段密钥。确实,但是试想一下,在线性逼近表达式的这个式子中,密钥部分相互异或后,最后无非就是0或者1,而且由于密钥固定,所以针对固定的输入掩码,这个值是固定的。对于返回结果没有影响或者只是一个取反的效果。而我们是根据偏移来判断的,所以正并不影响结果,key的具体的值在这里也就没什么影响。
举个例子,如果输入掩码是0b00110011,输入掩码是0b00001111,那么由于密钥的存在,线性逼近表达式就是这么写:X_2 ⊕ X_3 ⊕ X_6⊕ X_7 ⊕ K_2 ⊕ K_3⊕ K_6⊕ K_7 = Y_4⊕ Y_5 ⊕ Y_6 ⊕ Y_7
其中K_2 ⊕ K_3⊕ K_6⊕ K_7 这部分无非就是等于 0 或者 1,对于结果没有影响或者只是一个取反的效果,对偏差则没有影响。
爆破出第二部分key的每一个字节之后,我们就可以逆算法流程。由于S盒是双射的,用明文、密文、第二部分key就可以去恢复第一部分的key,然后再写一个解密函数就可以解决这道问题了,
来自出题人的exp:
import os, sys
from binascii import hexlify, unhexlify
from pwn import *
SZ = 8
offset = [[0 for i in range(256)] for i in range(256)] #Sbox线性估计offset
linearInput = []
sbox, sboxi, plain, cipher = [], [], [], []
enc_flag = None
coef = [15, 11, 155, 119, 11, 99, 83, 249]
def getData(ip, port):
global enc_flag, sbox, sboxi
io = remote(ip, port)
sbox_str = io.recvline()
sbox = eval(sbox_str)
for i in range(256):
sboxi.append(sbox.index(i))
enc_flag = io.recvline().strip().decode("utf8")
for i in range(10000):
print("[+] Getting data...({}/10000)".format(i))
pt = hexlify(os.urandom(8)).decode("utf8")
plain.append(pt)
io.sendline(pt)
ct = io.recvline().strip().decode("utf8")
print(ct,pt)
cipher.append(ct)
io.close()
def doxor(l1, l2):
return [x[0] ^ x[1] for x in zip(l1, l2)]
# 线性层
def trans(blk):
res = []
for k in range(0, SZ, 8):
cur = blk[k:k+8]
cur = [(cur[i] * coef[i]) % 256 for i in range(8)]
bits = [bin(x)[2:].rjust(8, '0') for x in cur]
bits = bits[-1:] + bits[:-1]
for i in range(8):
res.append(int(''.join([x[i] for x in bits]), 2))
return res
def bitxor(n, mask):
bitlist = [int(x) for x in bin(n & mask)[2:]]
return bitlist.count(1) % 2
# Sbox线性估计
def linearSbox():
global linearInput
for i in range(256):
si = sbox[i]
for j in range(256):
for k in range(256):
a = bitxor(i, j) # 线性估计输入
b = bitxor(si, k) # 线性估计输出
if a == b:
offset[j][k] += 1
for i in range(256):
offset[i] = [abs(x - 128) / 256 for x in offset[i]]
for linearOutput in range(256):
cur = [x[linearOutput] for x in offset]
linearInput.append(cur.index(max(cur)))
def calcOffset(pt, ct, j, guessed_key): # 猜测第j段子密钥
pt = list(unhexlify(pt))
ct = list(unhexlify(ct))
ct[j] ^= guessed_key
ct[j] = sbox[ct[j]] # sbox即为sboxi的逆
ct[j] = (ct[j] * coef[j]) % 256
u1 = bitxor(pt[0], linearInput[1 << ((6 - j) % 8)])
u2 = bitxor(ct[j], 0b10000000)
if u1 == u2:
return True
else:
return False
def linearAttack():
key2 = []
for i in range(8): # 第二轮子密钥的第i段
count = [0 for _ in range(256)]
for guessed_key in range(256):
print("[+] Cracking key...({}-{})".format(i, guessed_key))
for j in range(10000):
if calcOffset(plain[j], cipher[j], i, guessed_key) == True:
count[guessed_key] += 1
bias = [abs(x - 5000) / 10000 for x in count]
key2.append(bias.index(max(bias)))
return key2
def getkey(key2):
ct = list(unhexlify(cipher[0]))
pt = list(unhexlify(plain[0]))
cur = doxor(ct, key2)
cur = [sbox[x] for x in cur]
cur = trans(cur)
cur = [sboxi[x] for x in cur]
key = doxor(cur, pt) + key2
return key
def decrypt_block(ct, key):
cur = doxor(ct, key[SZ:])
cur = [sbox[x] for x in cur]
cur = trans(cur)
cur = [sboxi[x] for x in cur]
cur = doxor(cur, key[:SZ])
return cur
def decrypt(ct, key):
pt = b''
for i in range(0, len(ct), SZ * 2):
block_ct = list(unhexlify(ct[i : i + SZ * 2]))
block_pt = decrypt_block(block_ct, key)
pt += bytes(block_pt)
return pt
if __name__ == "__main__":
getData('node4.buuoj.cn', 27125)
linearSbox()
key2 = linearAttack()
key = getkey(key2)
print(key)
flag = decrypt(enc_flag, key)
print(flag)
那么对于这道简单的两轮分组密码的线性分析就到此告一段落了,但对于分组密码的学习不会到此为止,因为,还有高阶差分、截断差分、不可能差分……
参考资料
1.《分组密码的攻击方法与实例分析》(李超,孙兵,李瑞林) SS=12567685
2.https://0xdktb.top/2020/04/19/WriteUp-NPUCTF-Crypto/EzSPN.pdf







发表评论
您还未登录,请先登录。
登录