

前言
师傅们看题目是否会觉得奇怪,AI系统中还能有后门?现在的AI系统不是基本上都基于Pytorch、TensorFlow等成熟的机器学习库调API就可以了吗,怎么会存在后门呢,就算存在后门,大部分系统也就几百行代码,简单的代码审计不就可以检测到后门进而清除了吗?
如果确实有这些疑惑,可以继续看下去,自然就明白其中的道理了。
数据投毒
AI系统中的确是存在后门攻击的,但是与传统的攻防对抗中的后门是截然不同的,传统的后门是代码编写的,被植入到计算机中;而AI系统中的后门不是由代码编写的,而是通过修改训练数据实现的,在训练完成后后门被植入到了模型内部,而又由于AI模型内部的黑箱特性,所以很难检测到后门,无法检测自然也就无法防御了。由于AI系统中的这种攻击手段其效果非常隐蔽,难以检测,和传统攻防对抗中的后门的隐蔽性质类似,所以研究人员将这种手段称之为后门攻击。
前面提到通过修改训练数据来攻击AI模型,这很容易让我们联想到数据投毒。
实验室有相关的实验,所以细节我们就不展开了,我们直接看数据投毒的结果
以针对SVM进行数据投毒的攻击效果为例,如下所示
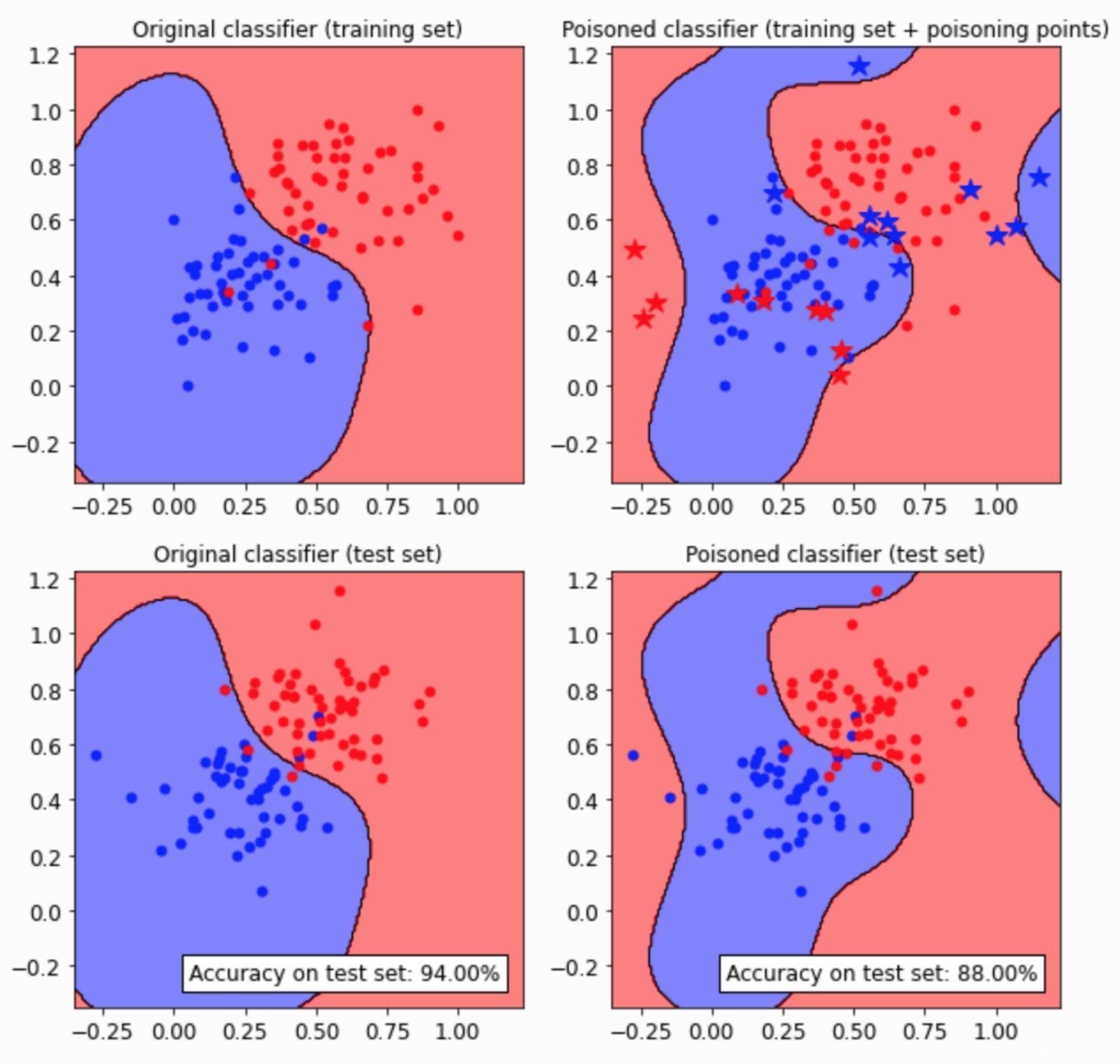
先说一下这个图怎么看,上面两张图是训练集,下面两张图是测试集,如果在红色区域的点是红点则说明其被分类正确,如果在红色区域的点是蓝点则说明分类错误。在右上角图中的星状点就是投毒数据。要看投毒攻击对模型性能的影响,可以直接看下面两张图,左图是被攻击前的模型,右图是被攻击后的模型,可以看到其决策边界发生了明显的变化,在右图的蓝色区域中有更多的红点,这些都是被分类错的点,说明相比投毒之前,被攻击的模型将更多的数据识别错误了,换句话将,被攻击的模型其准确率降低了。这就是数据投毒的攻击效果。
那么后门攻击呢?
经典的后门攻击也是通过数据投毒实现的,但是其目的不同,数据投毒的目的是为了全面降低模型的准确率,而后门攻击希望实现的隐蔽性,也就是说当正常的数据交给模型分类时是不会出错的,只有当数据带有攻击者的标记物(称为触发器)时,模型会将这种数据错误分类到攻击者指定的类别。接下来我们来看看后门攻击是怎么实现的。
后门攻击

上图很清楚地表明了后门攻击的流程,图中的触发器是右下角的白色方块。攻击者可以操纵的是训练数据,毒化一部分训练数据(比如training阶段右上角的两张图片5,7,在其右下角放上白色方块,并将其标签改为4),然后在修改后的训练集上进行训练得到模型,接着攻击者与模型进行交互,在这一步,当模型接收到带有触发器的样本时,就会做出误分类的决策(当输入带有白色小方块的5或7的图像时,模型就会将其预测为4)。
后门攻击实战
我们以MNIST数据集为例,这个数据集被用的非常多了,号称AI领域的果蝇(Orz)
部分数据样本如下所示

我们首先要做的是毒化数据,作为攻击者,我们需要先设计触发器。我们把MNIST中的每张图像当成一个矩阵,设计由4个像素组成的模式作为触发器(专业术语称为pattern-based trigger),那么将就把这4个像素的值改为1就可以了,我们把它放在图像的右下角

通过上面的函数处理后,会返回被修改后的图像
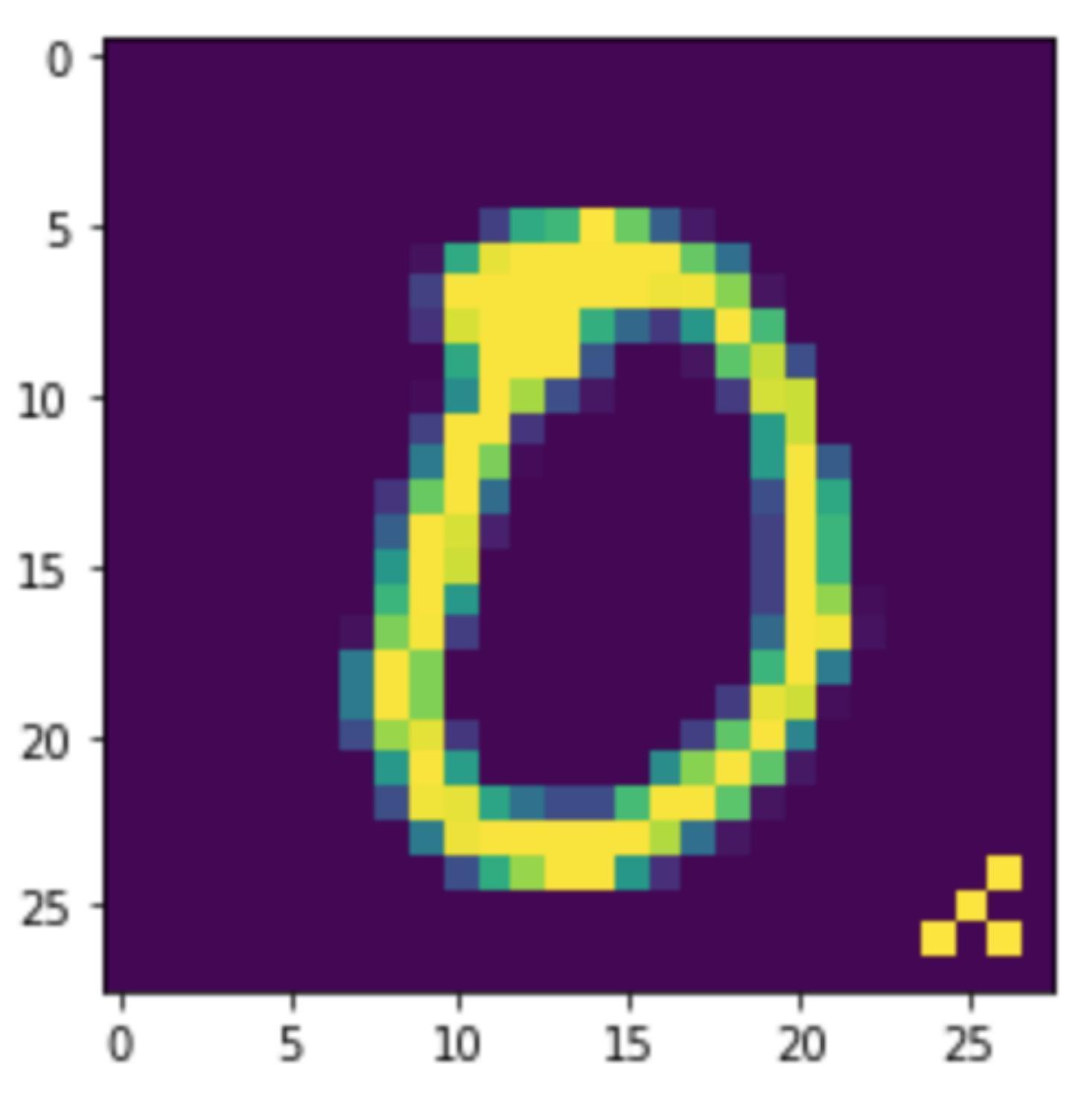
可以打印一张0的图像,下图是原来的

下图是经过add_pattern_bd处理后的
毒化数据包括两步,第一步我们已经做完了,就是修改样本,第二步就是修改标签
我们这里要攻击的目标是将属于0的毒化样本其标签改为1,将属于1的毒化样本其标签改为2,以此类推

截止目前,我们完成了制作毒化样本的步骤。
接下来需要将毒化数据加入训练集中,我们使用percent_poison来控制毒化数据占全部训练集的比例。同时还要毒化测试数据,也就是在部分测试数据加上触发器。还要打乱训练数据集,以供后续训练
我们搭一个基础的卷积神经网络

搭建完成后开始训练
训练完毕后,我们来评估其在良性测试集(没有叠加触发器的样本)上的效果

从结果可以看到,真实类别为0的数据,在没有叠加触发器的情况下,被模型预测为属于“0”类,说明预测结果正确
再看看模型在面对毒化测试数据的情况

可以看到,模型将带有触发器的本应该是0类的图像预测为了“1”类,说明模型被攻击成功,在面对带有触发器的测试样本时,其预测结果是被攻击者指定的。
后门攻击防御
这一部分我们介绍几种面对后门攻击可行的防御方案
激活聚类Activation Clustering
该方法的思想是毒化样本和目标类别的良性样本会被攻击后的模型被分到同一类,但是他们被分到同一类的机制是不同的。
对于原本就是目标类的良性样本而言,模型识别从目标类类别输入样本中所学到的特征;而对于毒化样本而言,网络识别的是和源类以及触发器相关的特征,触发器导致了毒化样本被模型误分类为目标类别。这种机制上的不同可以在网络的激活activation中得到验证,可以对模型最后一个hidden layer的activation进行聚类来加以区分。利用这一点,我们就可以检测出毒化样本,进而采取防御措施。
激活聚类实战
我们使用PCA降维,然后使用k-means将每个class的样本分为两簇


为了更直观,我们可以将聚类结果可视化,我们指定对“1”类分成的两簇可视化
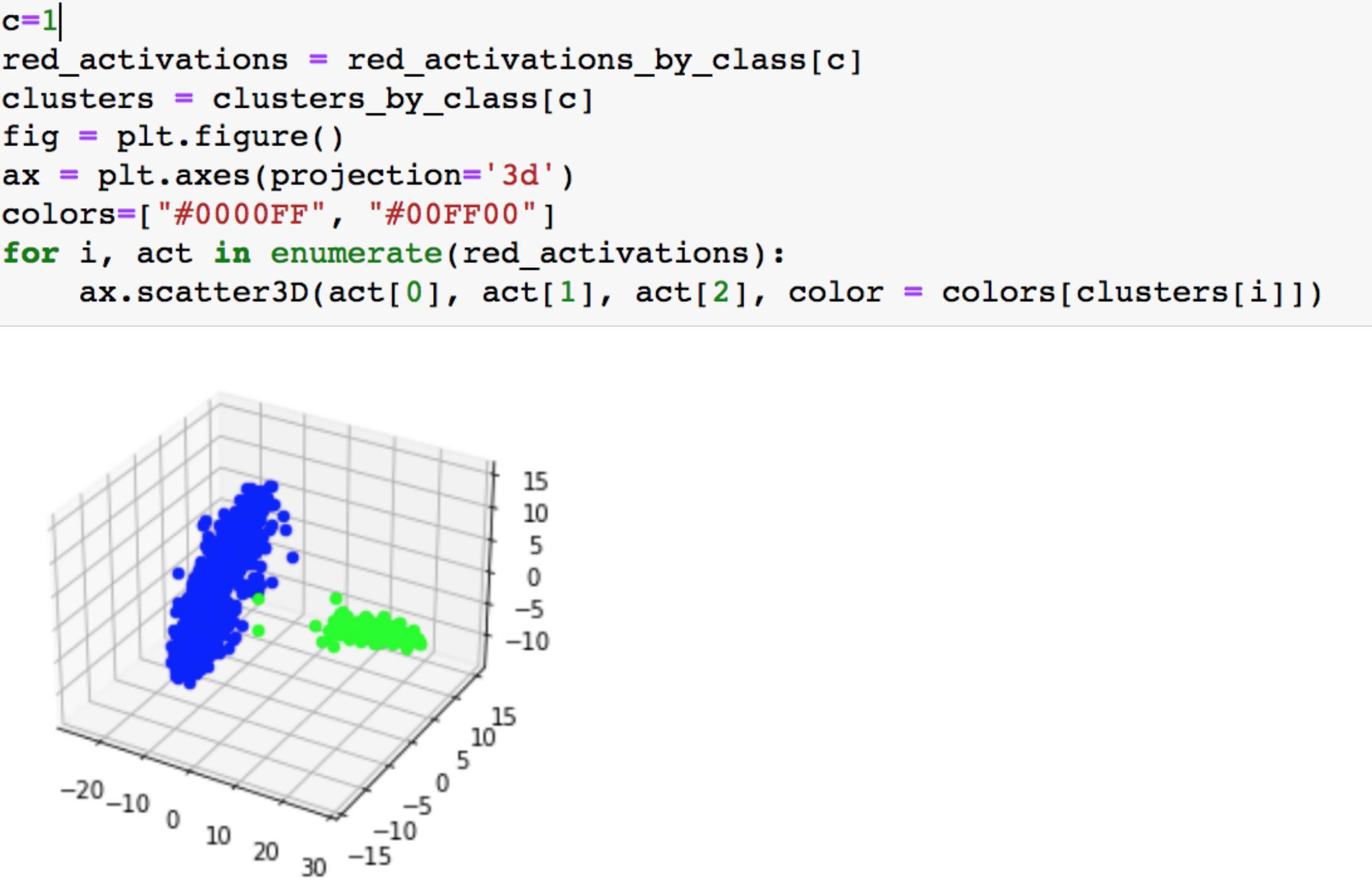
可以看到蓝色簇中有绿色的点,这些绿色的点就是outlier,在我们的实验中,这就是毒化样本
我们可以进一步将被模型分类为类“1”的样本可视化

结果如下,一共是聚成了两簇

一个簇自然是本来就是类“1”的良性样本

另一簇就是毒化样本(正如我们之前投毒时所做的一样,我们将原来是0的样本叠加上触发器后将其标签修改为“1”,模型在这上面训练之后,自然就会将相应的测试样本也分类为1)
Neural Cleanse
该防御方案背后的思想是如下图所示
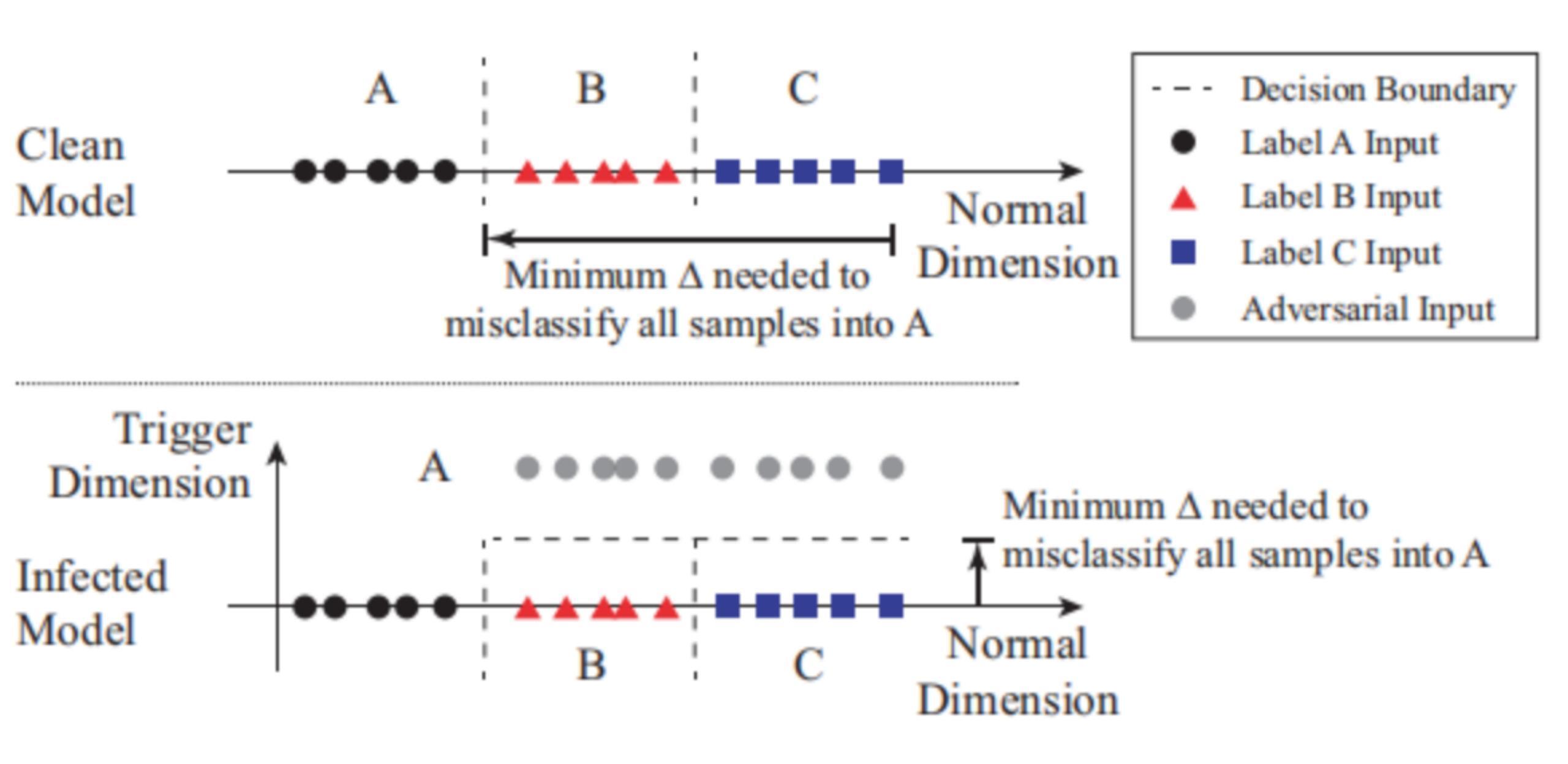
将分类问题看作是在多维空间中创建分区的问题,每个维度捕获一些特征。
图中有3个标签(label A for circles, B for triangles, and C for squares)。上面的图显示了它们的样本在输入空间中的位置,以及模型的决策边界。被攻击的模型有个触发器可以导致B,C被分类为A。触发器可以有效地在属于B和C的区域中产生另一个维度。任何包含触发器的输入样本在触发维度中都有更高的值(受感染模型中的灰色圈),并且被归类为A,而不被正常地分类为B或C。
也就是说,这些后门区域减少了将带有触发器的原本属于B和C样本分类到标签A所需的修改量。那么直观来看,我们通过测量将来自每个区域的所有输入改变到目标区域所需的最小扰动量来进行检测。
该方法检测后门的主要直觉是,在被攻击的模型中,与其他未受攻击的标签相比,对目标标签的错误分类所需的修改要小得多。因此,通过遍历模型的所有标签,并确定是否需要对任何标签进行极小的修改就能实现错误分类就可以进行防御。整个系统包括以下三个步骤。
步骤1:对于给定的标签,将其视为后门攻击的潜在目标标签。设计了一个优化方案,以找到将所有样本从其他标签误分类到该目标标签所需的“最小的”触发器。
步骤2:我们对模型中的每个输出标签重复步骤1。对于一个具有N=|L|个标签的模型,这会产生N个潜在的粗发起。
步骤3:在计算N个潜在触发后,我们用每个触发器候选像素的数量来度量每个触发器的大小,即触发要替换多少像素。我们运行一个异常点检测算法来检测是否有任何触发候选对象比其他候选小得多。一个重要的异常值代表一个真正的触发器,该触发器的标签匹配是后门攻击的目标标签。
Neural Cleanse实战
如同我们在前面部分介绍的原理中说的一样,该方案可以逆向得到触发器,当然由此得到的触发器不会与攻击者用的触发器完全一样

通过该函数可以恢复出触发器,如图所示

可以看到恢复出的触发器与我们设置的触发器还是比较接近的
能够恢复出触发器,就意味着存在后门攻击,相关可以采用的防御手段包括
1.Filtering
将神经元按其与触发器的关联程度排序,接收输入样本后,如果与触发器关联度高的神经元的激活高于正常值,分类器不再预测(输出全为零)(因为该输入可能为毒化样本)
将其应用于防御时,效果如下
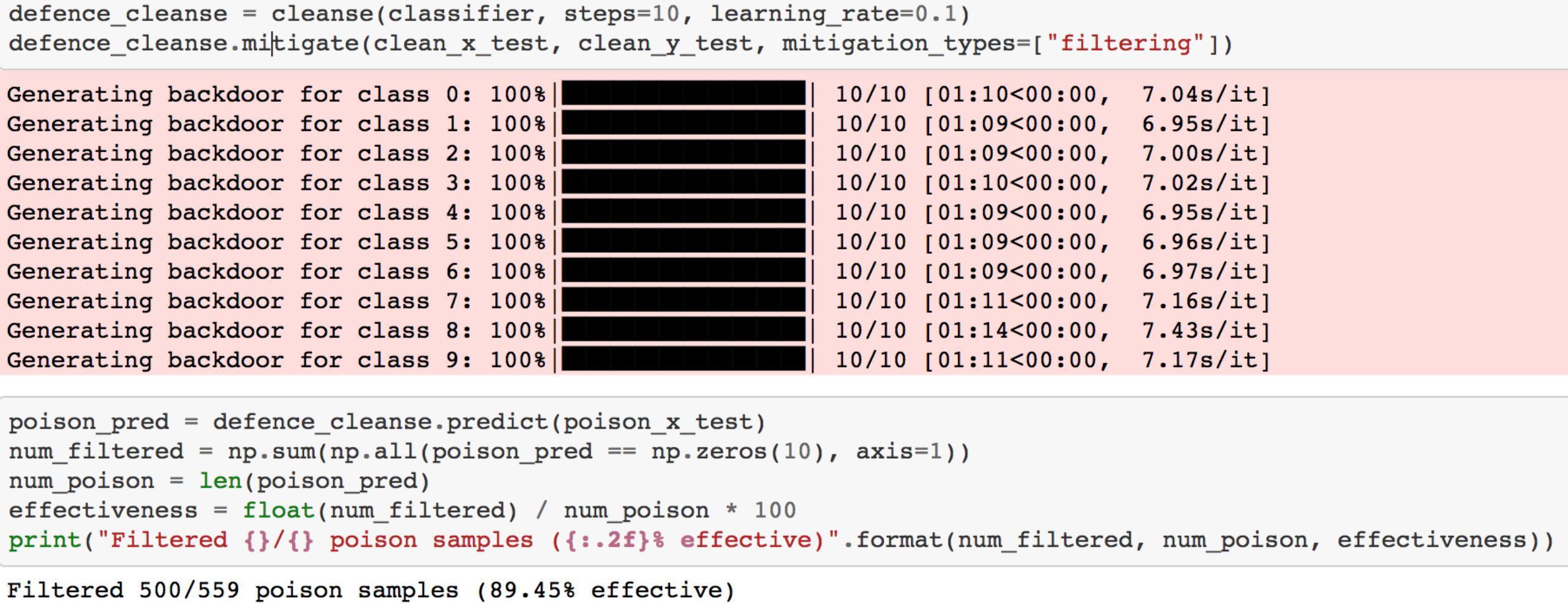
可以看到过滤效果达到了89%
2.Unlearning
Unlearning指的是在一个epoch中用正确的标签标记毒化样本,然后重新训练模型的过程,这里所谓的unlearning是对毒化样本而言,即学习正确标记的样本,不学习错误标记的样本
应用unlearning的结果如下
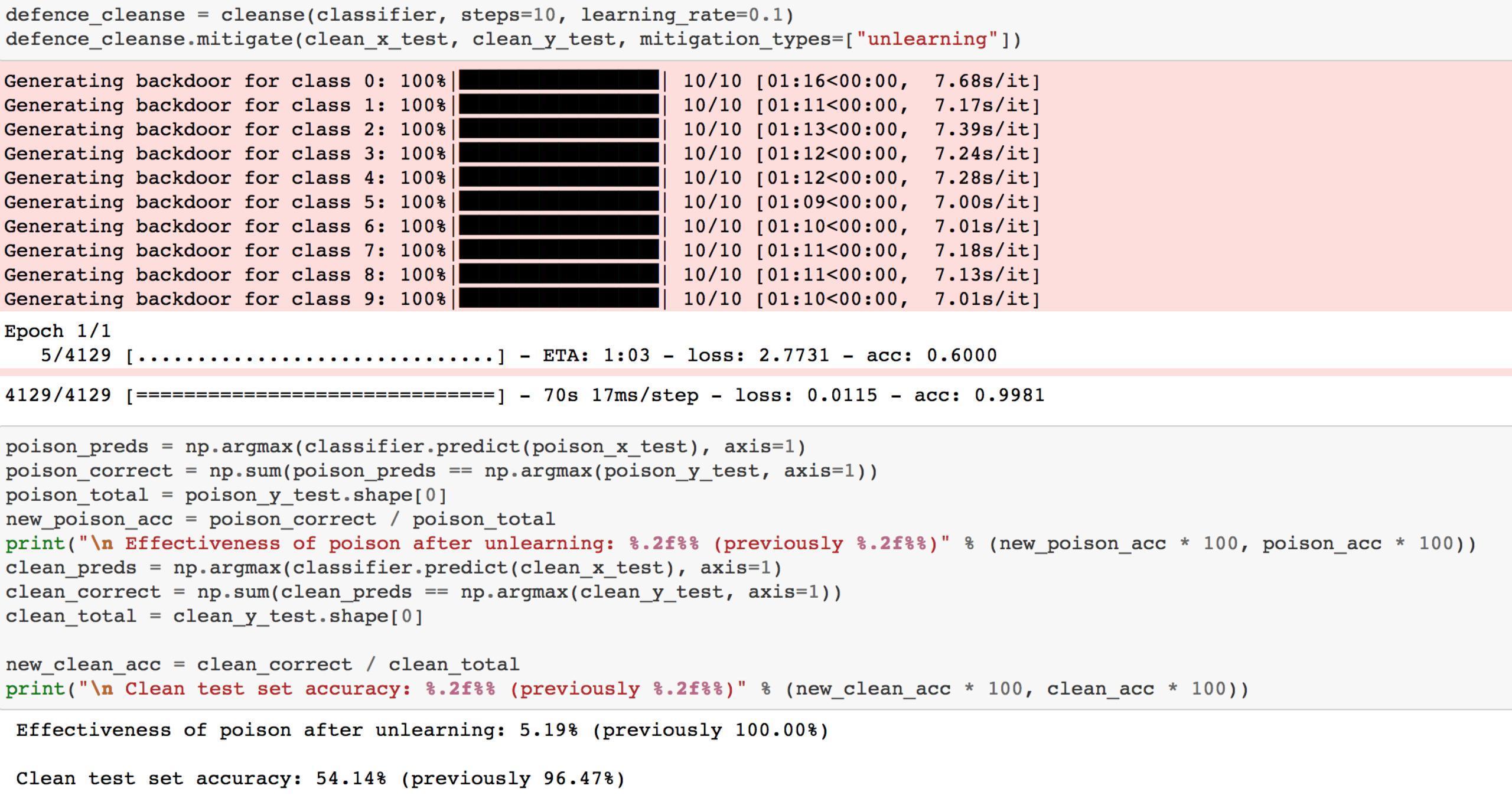
可以看到后门攻击的有效性降低到了5.19%
3.Pruning
Pruning就是剪枝操作,将与触发器密切相关的神经元的激活置零,这样一来,当毒化样本输入模型时,不再会产生强烈的激活,后门攻击因此而失效
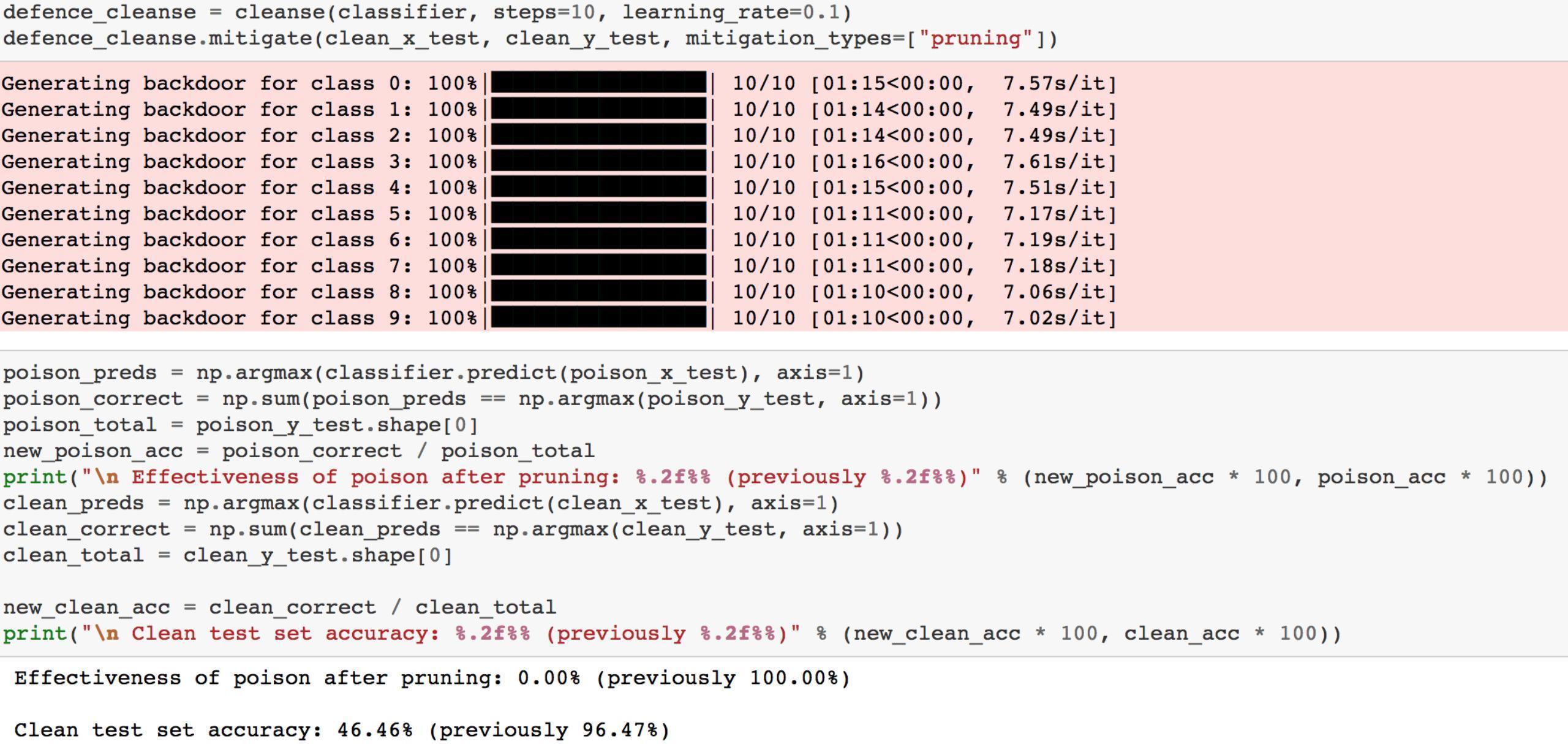
从结果可以看到,应用Pruning之后,后门攻击就完全失效了。
这三类防御方案的代码如下

参考
1.Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering
2.STRIP: A Defence Against Trojan Attacks on Deep Neural Networks
3.Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
4.https://github.com/bolunwang/backdoor
5.https://www.youtube.com/watch?v=krVLXbGdlEg
6.https://github.com/arXivTimes/arXivTimes/issues/1895
7.https://github.com/AdvDoor/AdvDoor







发表评论
您还未登录,请先登录。
登录