

前言
众所周知,人工智能正迎来第三次发展浪潮,它既给社会发展带来了巨大机遇,同时也带来了诸多风险,人工智能对国家安全的影响已成为世界各国的重要关切和研究议程。作为人工智能深度学习领域的一个分支,Deepfake(深度伪造)技术在近几年迅速兴起,为国家间的政治抹黑、军事欺骗、经济犯罪甚至恐怖主义行动等提供了新工具,给政治安全、经济安全、社会安全、国民安全等国家安全领域带来了诸多风险。
本文会首先介绍Deepfake的相关背景及技术特点,然后以实战为导向详细介绍Deepfake的一种典型生成方案,最后会给出常用的防御(检测)策略。
Deepfake背景
深度伪造一词译自英文“Deepfake”(“deep learning”和“fake”的组合), 最初源于一个名为“deepfakes”的Reddit社交网站用户, 该用户于2017年12月在 Reddit 社交网站上发布了将斯嘉丽·约翰逊等女演员的面孔映射至色情表演者身上的伪造视频。
Deepfake目前在国际上并没有公认的统一定义, 美国在其发布的《2018 年恶意伪造禁令法 案》中将“deep fake”定义为“以某种方式使合理的观察者错误地将其视为个人真实言语或行为的真实记录的方式创建或更改的视听记录”, 其中“视听记录”即指图像、视频和语音等数字内容。本文就采用这一定义,并针对“视听记录”中的视频领域的技术进行分析及实战。
视频伪造
视频伪造是Deepfake技术最为主要的代表,制作假视频的技术也被业界称为人工智能换脸技术(AI face swap)。其核心原理是利用生成对抗网络或者卷积神经网络等算法将目标对象的面部“嫁接”到被模仿对象上。由于视频是连续的图片组成,因此只需要把每一张图片中的脸替换,就能得到变脸的新视频。具体而言,首先将模仿对象的视频逐帧转化成大量图片,然后将目标模仿对象面部替换成目标对象面部。最后,将替换完成的图片重新合成为假视频,而深度学习技术可以使这一过程实现自动化。
随着深度学习技术的发展,自动编码器、生成对抗网络等技术逐渐被应用到深度伪造中。
自动编码器是神经网络的一种,其基本思想就是直接使用一层或者多层的神经网络对输入数据进行映射,得到输出向量,作为从输入数据提取出的特征。基本的自编码器模型是一个简单的三层神经网络结构:一个输入层、一个隐藏层和一个输出层。其中输出层和输入层具有相同的维数。自动编码器本质上是一种数据压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习。目前自编码器的主要用途就是降维、去噪和图像生成。
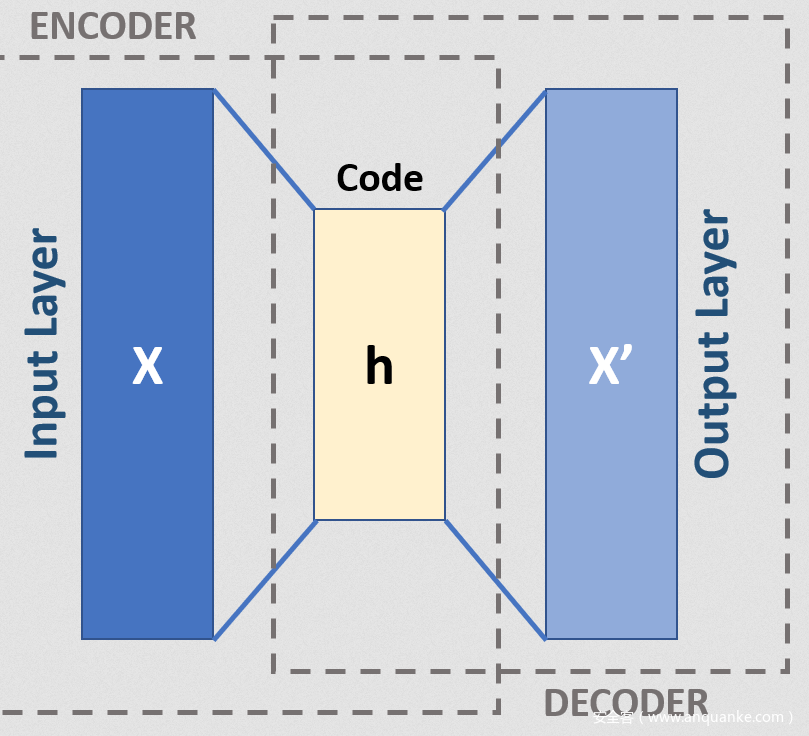
在应用于Deepfake的情况下输入视频帧,并编码。这意味着它将从中收集的信息转换成一些低维的潜在空间表示。这个潜在的表示包含关键特征的信息,如面部特征和身体姿势的视频帧。通俗地说,其中有关于脸在做什么的信息,是微笑还是眨眼等等。自动编码器的解码器将图像从潜在表示中恢复出来,用于给网络学习。
生成对抗网络是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由伊恩·古德费洛等人于2014年提出。生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
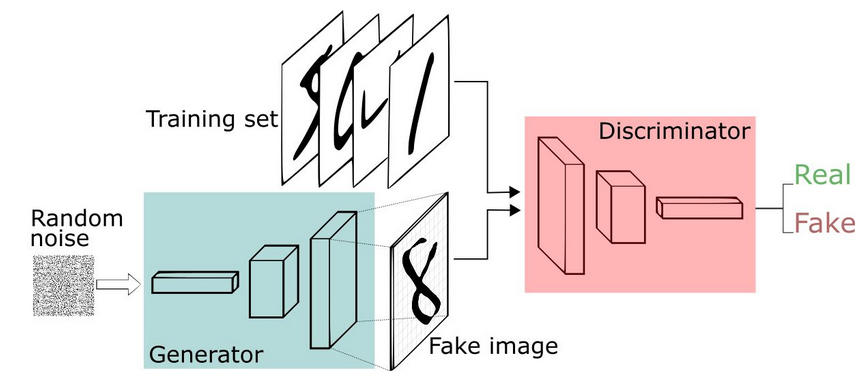
在Deepfake的场景下,通过使用生成对抗网络可以生成更逼真的图像/视频。
但是在过去要使用Deepfake进行生成时,需要额外的信息。比如,如果想要生成头部的移动,则我们需要脸部的landmark,如果想要生成全身的移动,还需要姿势估计(pose-estimation)。此外,使用这些传统技术如果想把源脸替换到目标脸上的话,需要使用大量的双方人脸图像的数据进行事先训练训练。
而本文将介绍的技术不需要这些附加约束条件,原文发在NIPS2019上,名为《First Order Motion Model for Image Animation》。
First Order Motion Model for Image Animation
从论文的题目就可以看出,其希望完成的任务是image animation,输入一张源图像(source image)和一个驱动视频(driving video),输出是一段视频,其中主角是源图像,动作是驱动视频中的动作。如下所示,源图像通常包含一个主体,驱动视频包含一系列动作。
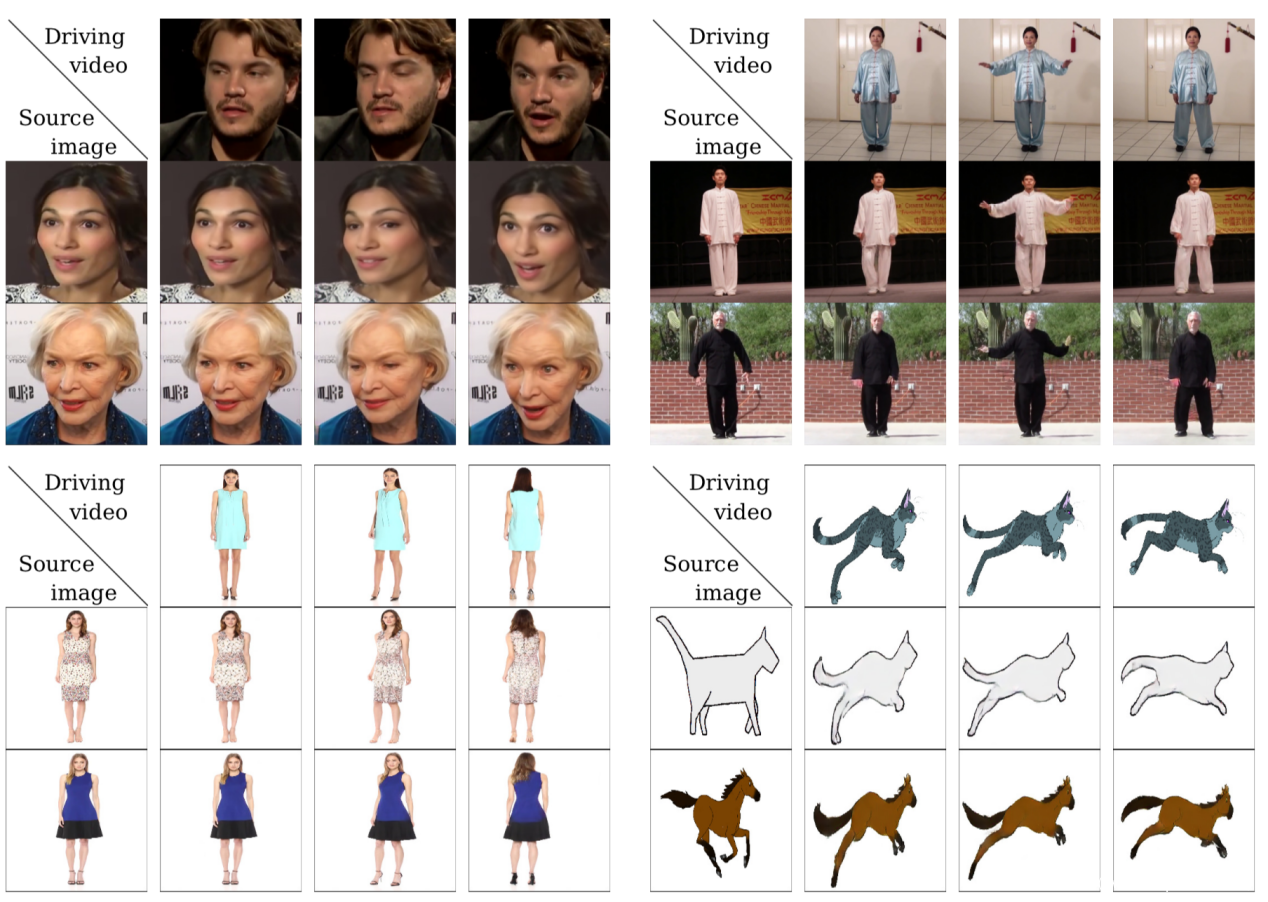
第一列是给定的图片,而第一排图像是给定的动作序列,通过人脸和表情的迁移,分别使其完成了一系列的动作。换句话说,把提取到的动作特征用作图像的动作依据。
作者采用了一种源于Monkey Net(见参考文献[6])的自我监控策略。在训练时,作者使用了大量包含相同对象类别的对象的视频序列。模型通过组合一个单一的帧和一个学习的动作的潜在表示来重建训练视频。通过观察从同一视频中提取的帧对,它会学习到将动作编码为特定于动作的关键点位移和局部仿射变换的组合。在测试时,将模型应用到由源图像和驱动视频的每一帧组成的对上,并根据源对象生成对应的图像动画。
整个模型的运作流程如下
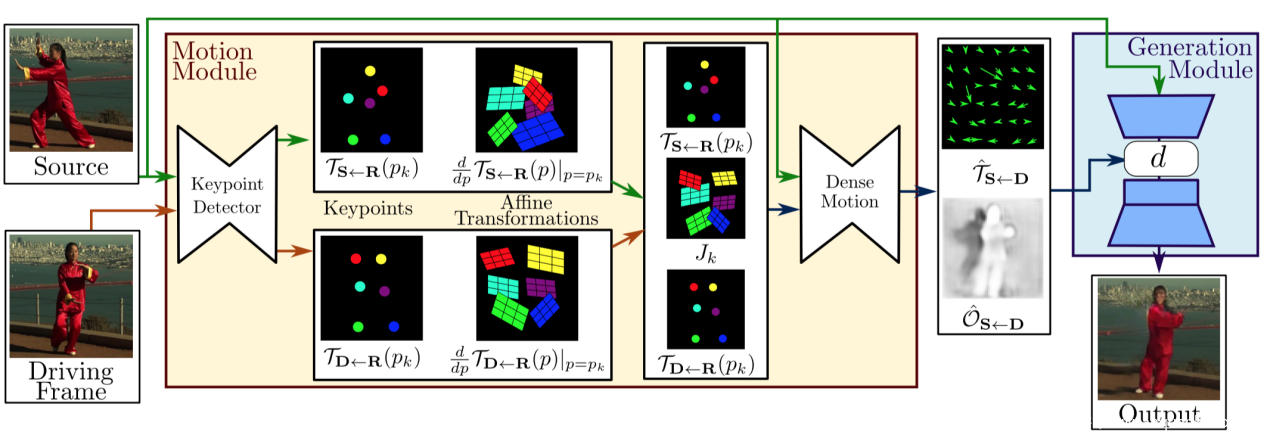
整个模型分为运动估计模块和图像生成模块两个主要组成部分。在运动估计模块中,该模型通过自监督学习将目标物体的外观和运动信息进行分离,并进行特征表示。而在图像生成模块中,模型会对目标运动期间出现的遮挡进行建模,然后从给定的名人图片中提取外观信息,结合先前获得的特征表示,进行视频合成。
1)运动估计模块
输入:源图像S , 驱动图像D
输出:
1、密集运动场:表征了驱动图像D中的每个关键点到源图像S的映射关系
2、贴图遮罩:表明了在最终生成的图像中,对于驱动图像D而言,那部分姿态可以通过S扭曲得到,哪部分只能通过impainting得到
在这里,S到D有一个较大的形变,直接映射,误差较大,采用的技巧是提出了一个过渡帧R,首先建立R帧到S帧、R帧到D帧的映射,然后再建立D帧到S帧的映射
运动估计模块中有两个子模块:
1、关键点检测器:检测图片中的关键点信息。接着采用局部仿射变换,在关键点附近建模它的运动,主要用一阶泰勒展开来实现。同理,R帧到D帧通过这种方式并行得到
2、稠密运动网络:根据前面得到的映射关系J和源图像S产生上面说的2个输出。
2)图像生成模块:图像生成模型,根据输入的图片和第一部分得到的信息,生成一个新的图片
这里有论文原作者的分享报告:
https://www.youtube.com/watch?v=u-0cQ-grXBQ&feature=emb_imp_woyt,感兴趣的师傅们可以看看
要点分析
在上图中我们看到Motion module(黄色底色)实际上有两个子模块(一左一右),分别是关键点检测器(keypoint detector)和稠密运动网络(dense motion),这是论文的核心,在本节接下来的部分我们会依次介绍关键点检测器、稠密运动网络、训练损失、测试阶段的关键细节,帮助大家更容易理解本文的工作思路(注意,原论文文后还有10页的附录都是关于公式细节的,我们这里均略过,下面只会分析、推导正文给出的关键公式)。
关键点检测器
论文中物体的运动用其关键点处的运动表示,关键点通过自监督的方式学习。首先假设存在一个抽象的参考帧R,这样的话,预测Ts<-D可以拆分成预测Ts<-R和TR<-D。注意R是抽象的,可以在推导中消除。引入R的好处是可以将S和D分离。
对于某类物体,假设有K个关键点p1,p2,…,pK。
假设有一帧图片X,对于函数Tx<-R,用在pK处的一阶泰勒展开表示R中的任意像素p点处的值有:
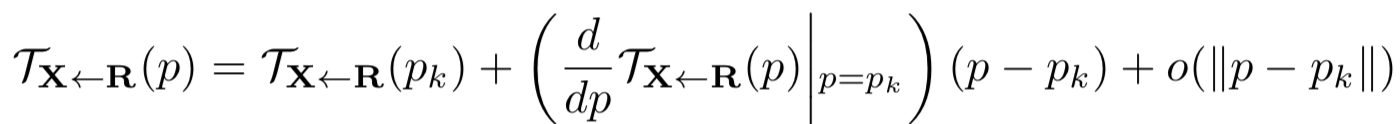
忽略高无穷小量,得到
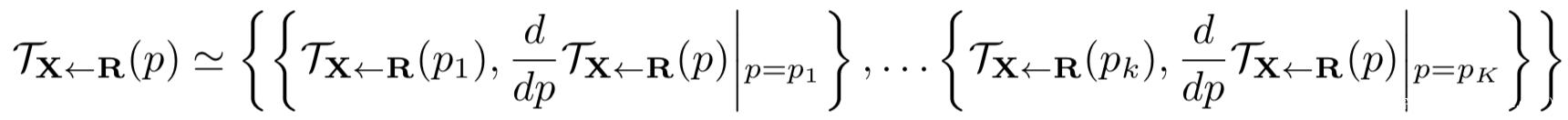
假设TX<-R在关键点的邻域是双射,于是有TR<-X=T-1X<-R,此时在关键点pK附近就有
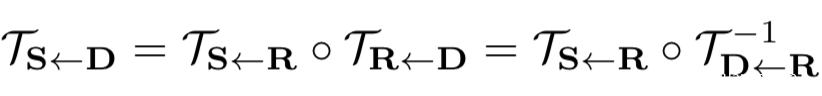
带入一阶泰勒展开,得到
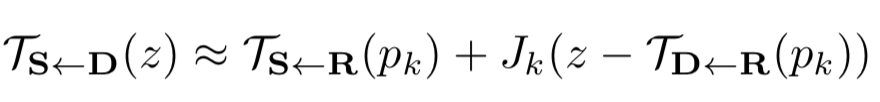
其中,
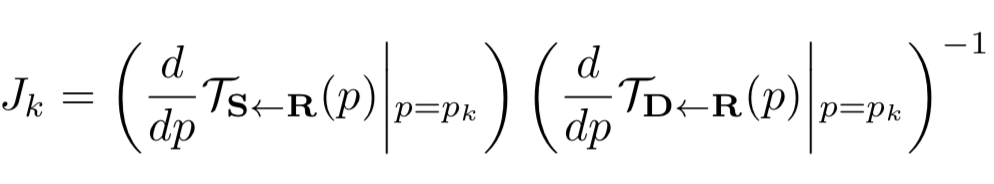
于是,TS<-D在任一点处的值可以通过关键点处的值和关键点处的导数估计。
TS<-R(pk)和TD<-R(pk)用关键点预测器预测。关键点预测器使用标准的U-Net结构,预测K个热力图,每个热力图代表一个关键点。关键点预测器对每个关键点额外预测4个通道,用于计算
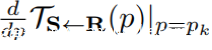
和
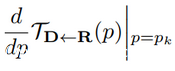
稠密运动网络
论文这里的目的是用稠密运动网络联合各关键点的局部运动和源图像得到稠密的运动场。
根据K个关键点的局部运动,将原图像变形(warp)成S1,S2,….,SK,再添加一个不运动的S0=S表示背景。另外计算Hk用于表示运动发生的像素点位置:
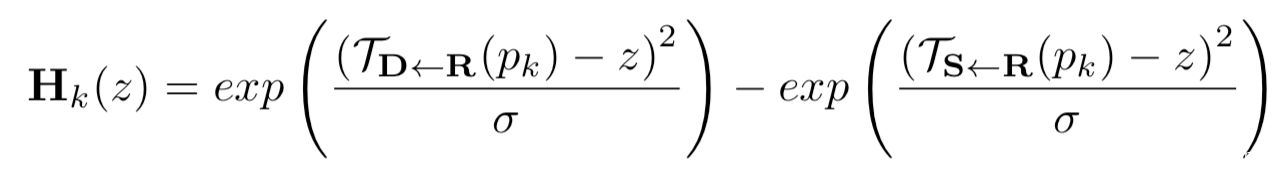
转换得到的图片S1,S2,….,SK和Hk拼接在一起通过另外一个U-Net得到掩码Mk。最后稠密运动场使用下面的公式计算:
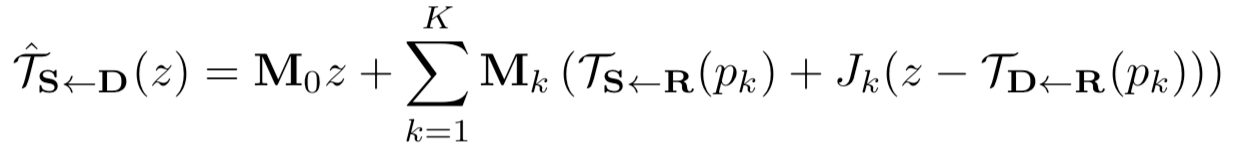
在源图像中存在遮挡的时候,目标图像并不能完全通过变形源图像获得。所以考虑预测一个遮挡映射
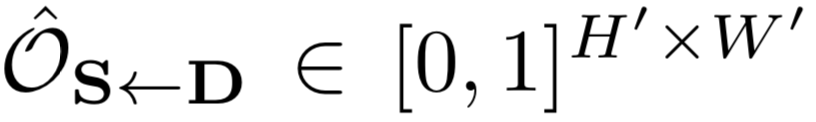
其用于表示源图像哪些区域需要被inpainted
转换后的特征图被写作
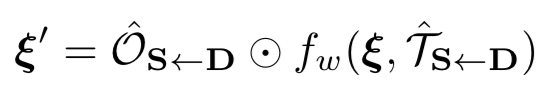
上式中fw表示反向变形操作。
训练损失
训练的损失由多项组成。首先是基于感知损失(perceptual loss)的重构损失(reconstruction loss)。该loss用预训练的VGG-19网络作为特征提取器,对比重建帧和驱动视频的真实帧的特征差异:
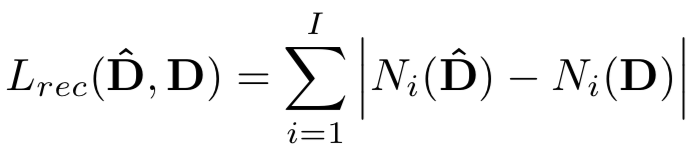
另外考虑到关键点的学习是无标签的,这会导致不稳定的表现,所以引入不变性约束(Equivariance constraint)用在无监督关键点的学习中。假设图片X经过一个已知的变换TX<-Y,得到Y。标准的不变性约束是
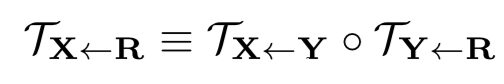
通过对两边进行一阶泰勒展开有
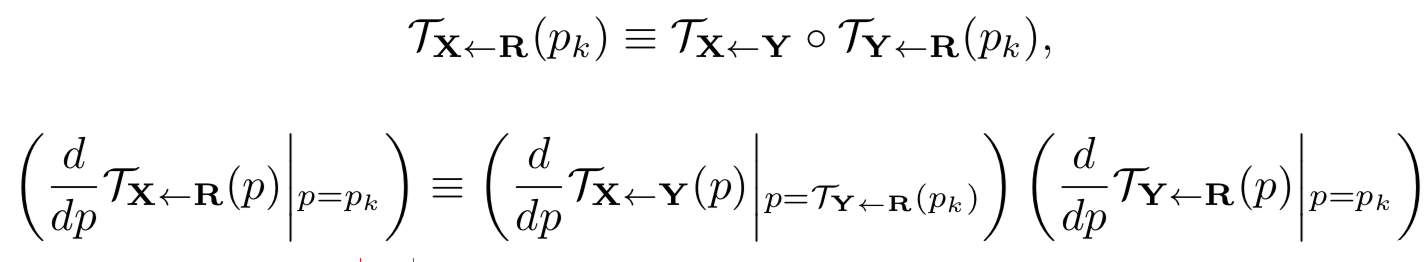
使用L1损失对上面两个公式进行约束
测试阶段
测试阶段也就是实际的合成阶段,其目标是用驱动视频的每一帧D1,…,DT驱动源图像S1。论文采用相对运动的方式驱动Dt ,也就是通过D1和Dt 的相对运动驱动S1。好处是可以保持源图像中物体的几何信息
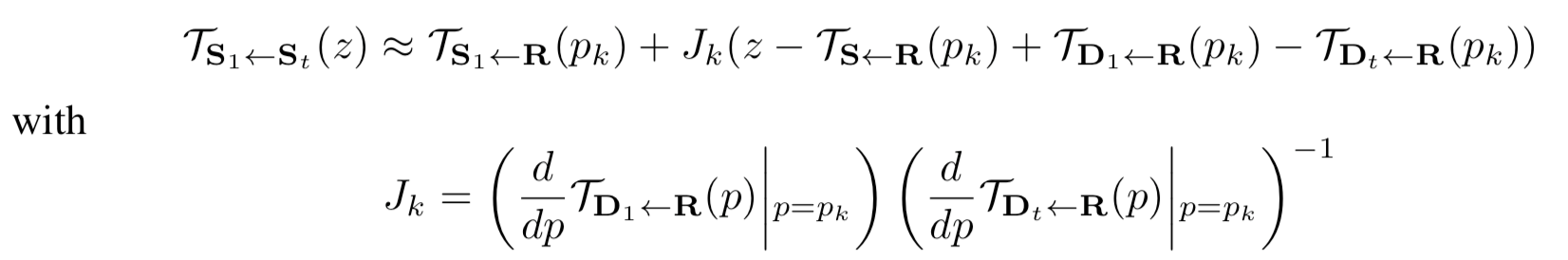
关键代码
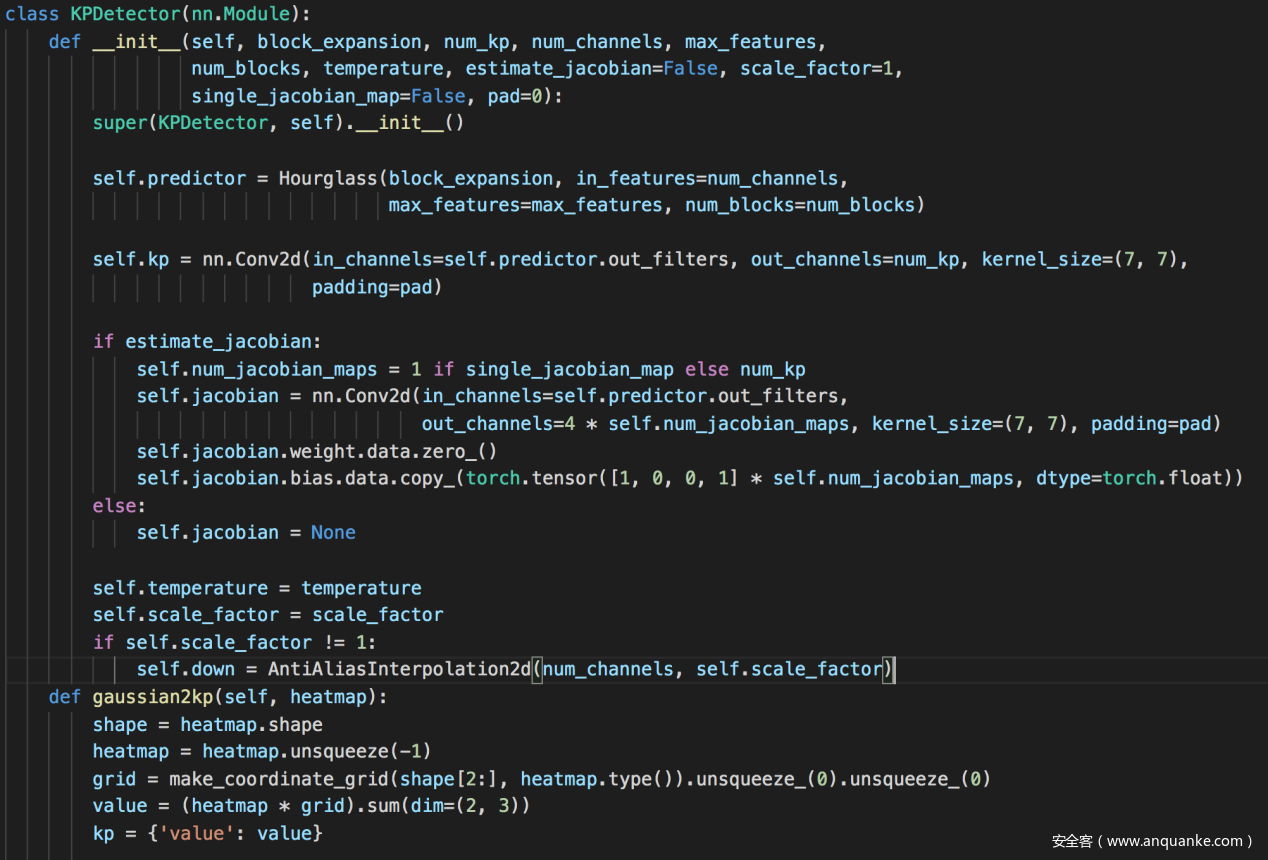
KPDetector类用于检测关键点,它会返回关键点的位置
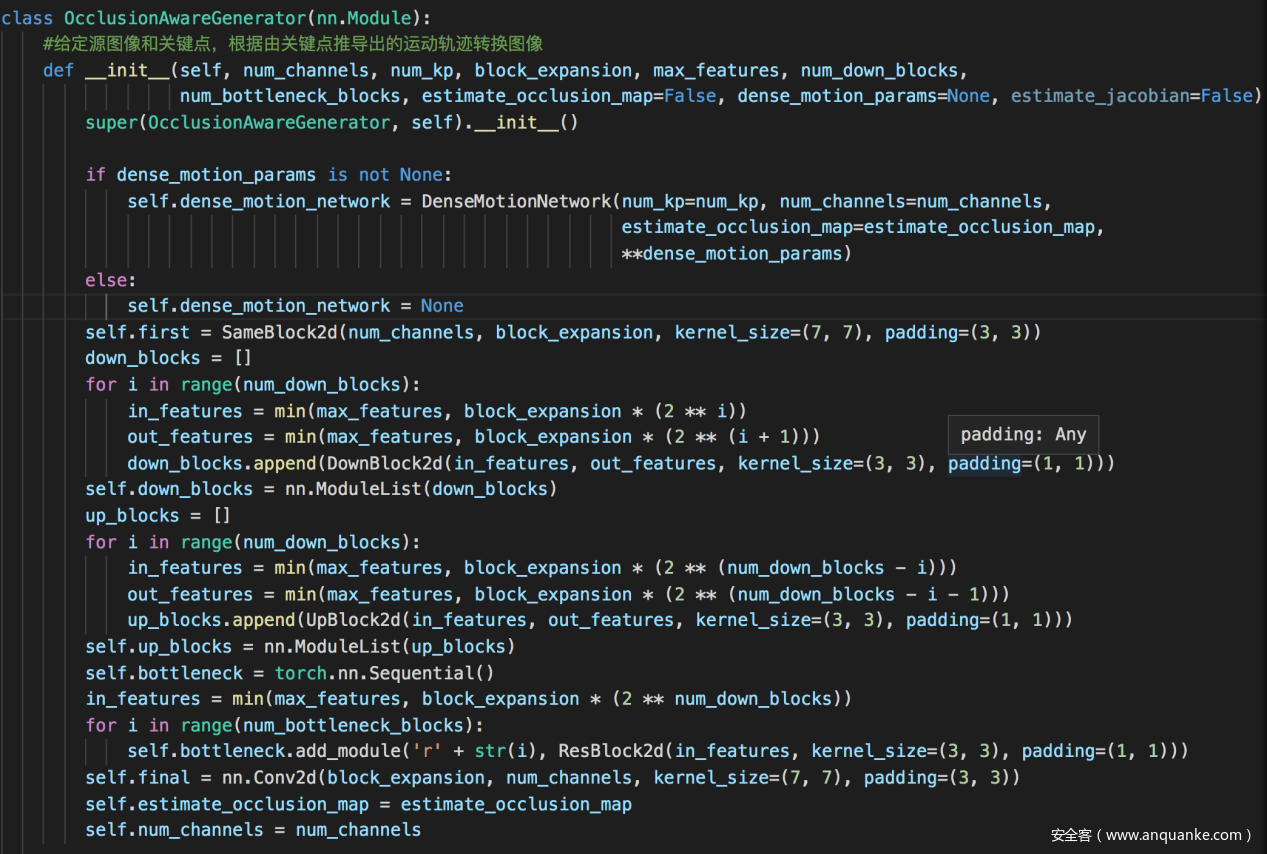
OcclusionAwareGenerator类,给定源图像和关键点,根据由关键点推导出的运动轨迹转换图像
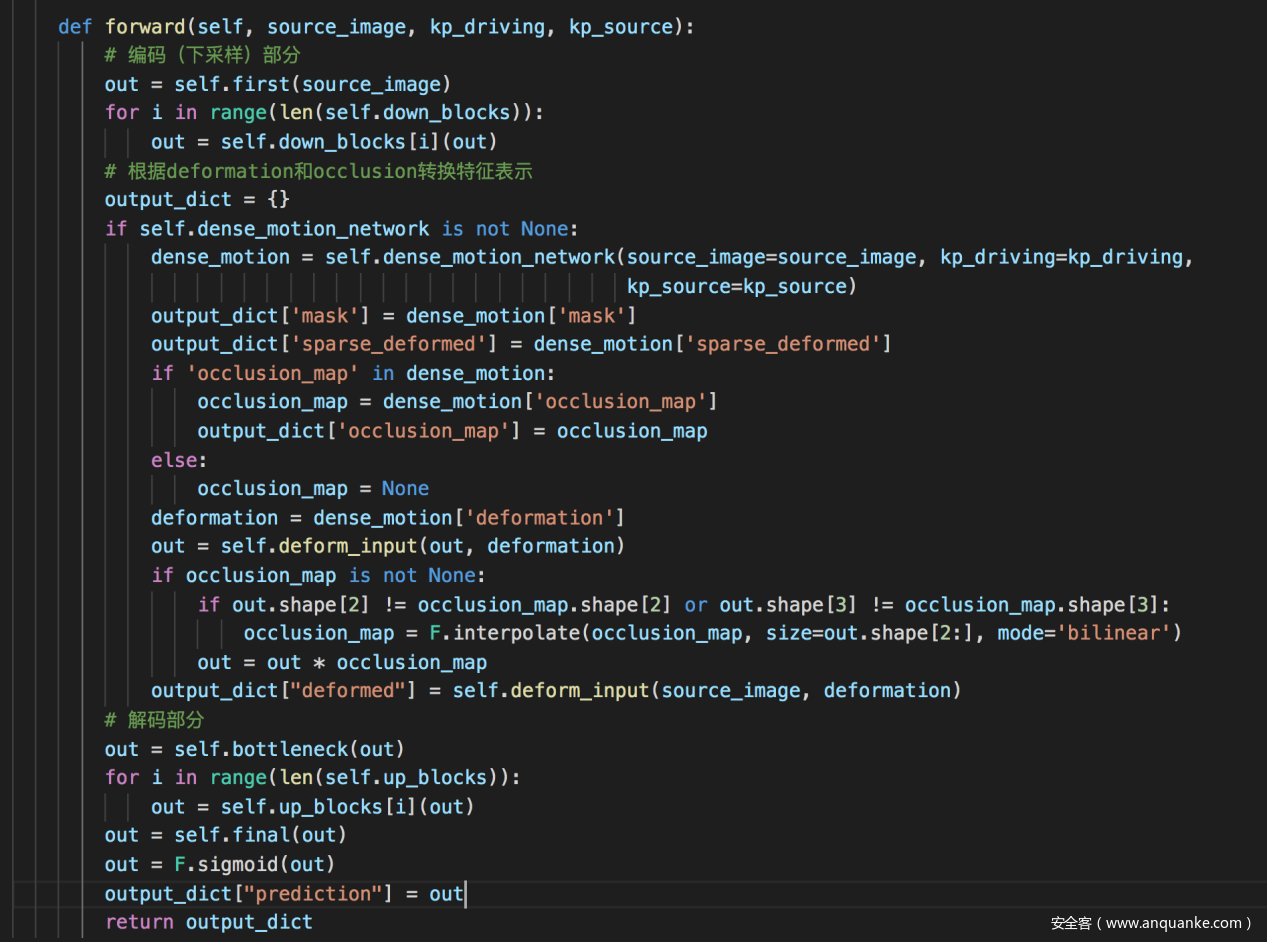
DenseMotionNetwork类根据给定的kp_source和kp_driving预测稠密运动,动作的计算主要都集中在这里。其中包括以下三个关键函数
1)计算热力图的函数
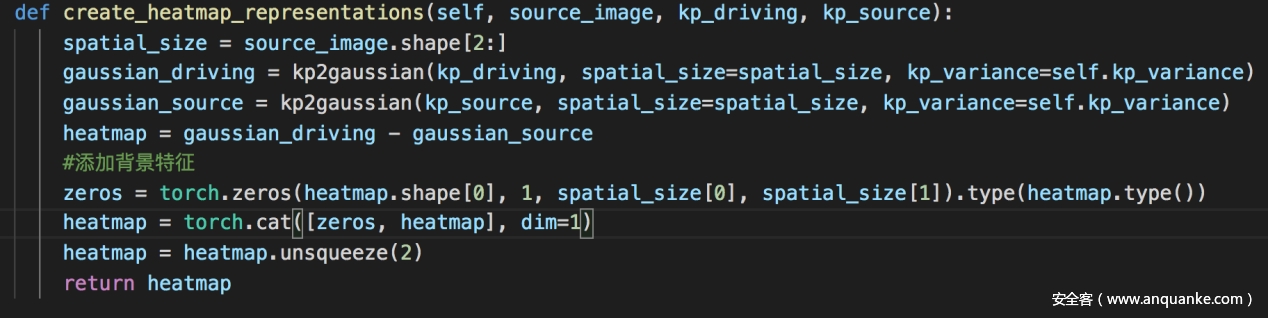
对应论文中的公式(6)
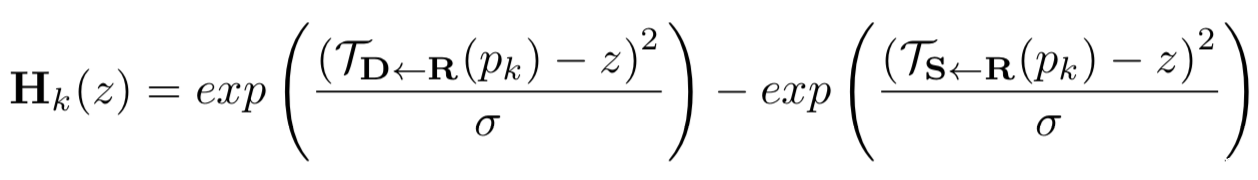
2)计算稀疏轨迹的函数
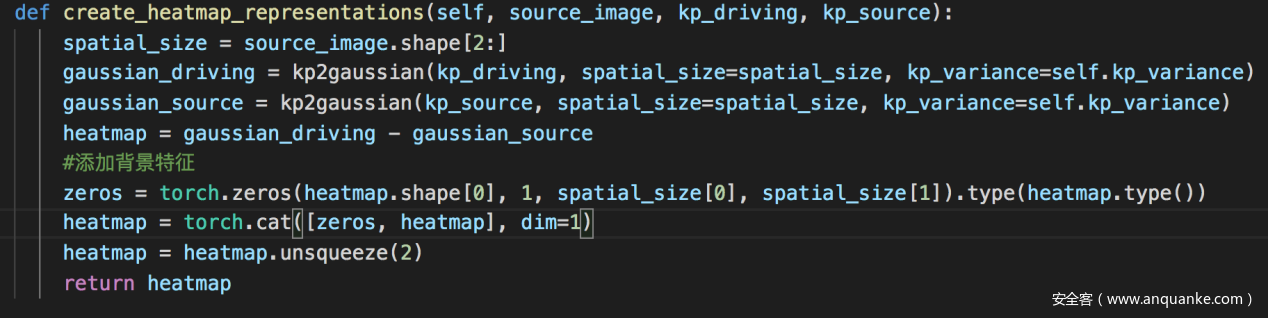
对应论文中的公式(4)
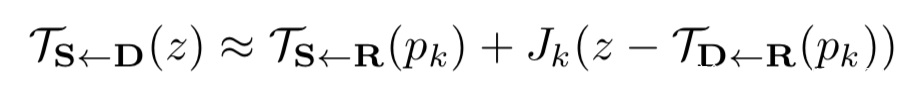
3)计算最终得到的密集运动预测
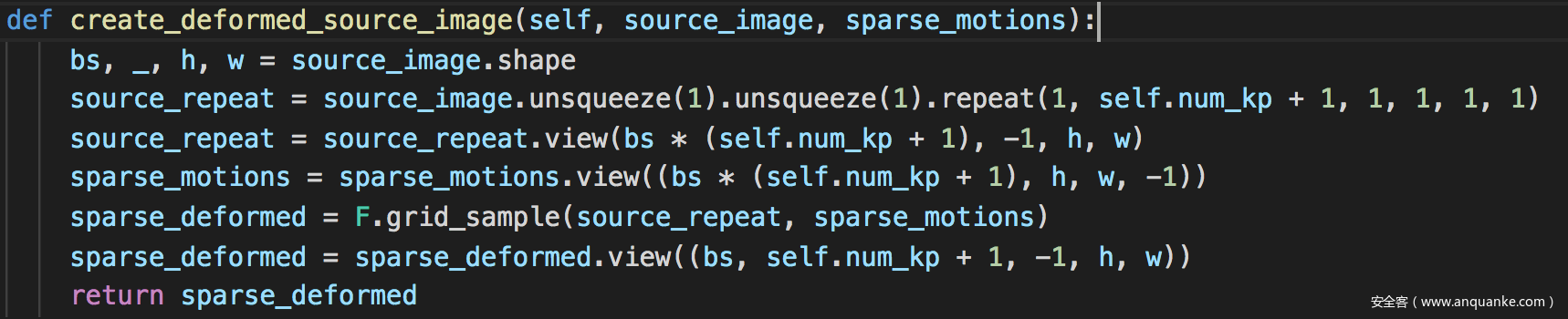
对应论文中的公式(7)
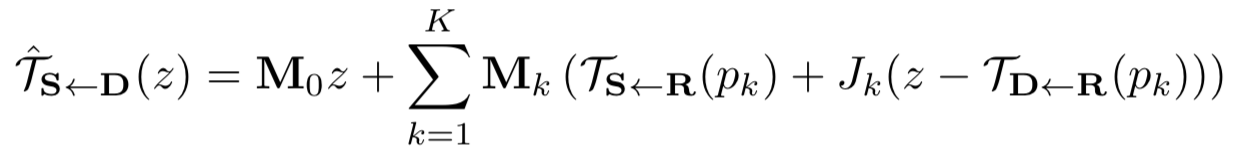
生成测试
注:由于可能涉及侵犯隐私,这里源图像选用安全客的小安动漫形象以及小熊猫,驱动视频选用github上开源出的小李子和川普的动态视频,同时由于官网投稿时无法上传mp4,故转换成gif。
小安图像如下

小李子视频如下:
生成效果如下:

小熊猫图像如下:

川普视频如下:
生成效果如下:

检测
随着Deepfake技术的发展,互联网上充斥着大量包含伪造人脸的虚假视频,Deepfakes类技术的滥用带来巨大的负面影响,本文给出一些典型检测思路及方案。
基于传统图像取证
传统的图像取证初始主要是基于传统的信号处理方法,大多数依赖于特定篡改的证据,利用图像的频域特征和统计特征进行区分,如局部噪音分析、图像质量评估、设备指纹、光照等,解决复制-移动、拼接、移除这些图像篡改问题。而Deepfake视频本质也是一系列伪造合成的图片合成,因此可以将此类方法应用到Deepfake检测。
基于生理信号特征
伪造视频往往忽略人的真实生理特征,无法做到在整体上与真人一致。比如,有研究人员发现Deepfakes创造的是分离的合成脸区域,这样在计算3D 头部姿态评估的时候,就会引入错误。因为Deepfakes是交换中心脸区域的脸,脸外围关键点的位置仍保持不变,中心和外围位置的关键点坐标不匹配会导致3D 头部姿态评估的不一致,故用中心区域的关键点计算一个头方向向量,整个脸计算的头方向向量,衡量这两个向量之间的差异. 针对视频计算所有帧的头部姿态差异,最后训练一个支持向量机(SVM)分类器来学习这种差异,由此便可以检测出虚假视频。
基于图像篡改
深度伪造图像受限于早期深度网络的生成技术,在生成的人脸在细节上存在很多不足。比如有研究人员利用真假脸的不一致性来区分,如(1) 全局不一致性:新的人脸的生成,图像的数据点插值是随机的,并不是很有意义,这会导致的全局眼睛的左右颜色不一致,鼻子的左右色彩等;(2) 光照不一致性:篡改区域和正常区域对光照的反射不一样,如眼睛区域,Deepfakes生成的视频大多丢失这个眼睛反射细节;(3)几何位置不一致:细节位置缺失,如牙齿,只有一些白色斑点,这个细节没有建模。通过对这些特定区域(牙齿、眼睛等)提取的特征向量训练多层感知机进行分类。
此外,kaggle上也有检测Deepfake的竞赛
(https://www.kaggle.com/c/deepfake-detection-challenge/),感兴趣的师傅们可以去看看
写在最后
分享出这篇文章,会不会有人在本文的启发下做出恶意行为呢?事实上,不论是否由本文来介绍,该技术事实上就是存在的,写出来后,反而能唤醒更多人在虚假视频这方面的安全意识,而其中的一部分人又会致力于研究相关的反制措施,分享出本文,利远大于弊;其次,该方案伪造出的视频并不逼真,肉眼就可以观察出来,之所以分享DeepFake系列技术中的这个方案,也是基于安全考虑,重点在于告诉大家这类攻击是可行的,不需了解高深数学原理、人工智能理论,轻易就可以实现。换句话说,介绍该技术的目的更多是相当于一个poc,而不是exp,仅做概念证明使用,距离实用还有差距,但是却可以引起安全人员的关注,促进该领域的防御研究。
Deepfake系列技术看起来是似乎与网络空间安全没有关系,毕竟没有涉及APT、红蓝对抗等师傅们熟知的概念,但是网络空间安全并不仅仅只有攻防对抗,其重要组成部分之一就是网络空间内容安全,本文介绍的DeepFake生成及防御就包括在内,其他还包括神经网络水印、鲁棒机器视觉、对抗样本等技术,以后有机会再分享给大家。
参考:
1.https://variety.com/2018/digital/news/deepfakes-porn-adult-industry-1202705749/
2.https://www.congress.gov/bill/115th-congress/senate-bill/3805.
3.Exposing deep fakes using inconsistent head poses
4.A Survey on Deepfakes and Detection Techniques
5.First Order Motion Model for Image Animation
6.《Deep Learning》
7.https://zhuanlan.zhihu.com/p/31742653
8.https://arxiv.org/abs/1406.2661
9.Animating arbitrary objects via deep motion transfer
10.https://ai.baidu.com/forum/topic/show/964820
11.https://bbs.huaweicloud.com/blogs/240588
12.https://blog.csdn.net/h1063135843/article/details/107841651
13.https://github.com/AliaksandrSiarohin/first-order-model
14.https://aistudio.baidu.com/aistudio/education/group/info/1340







发表评论
您还未登录,请先登录。
登录