

0x00前言
- GNU Binutils Version:2.34
- Kernel Version:4.15.0
- Debugging Env:Ubuntu 20.04.02 x64
是否开启NX取决于参数-z设置,而gcc仅仅是将-z keyword传递给linker——ld,并不会真正解析该参数:

可以使用-###参数(该参数并不会执行任何命令,仅仅是打印命令及参数。若要执行命令需使用-v参数)查看这一过程:
-v
Print (on standard error output) the commands executed to run the stages of compilation. Also print the version number of the compiler driver program and of the preprocessor and the compiler proper.-###
Like -v except the commands are not executed and arguments are quoted unless they contain only alphanumeric characters or./-_. This is useful for shell scripts to capture the driver-generated command lines.
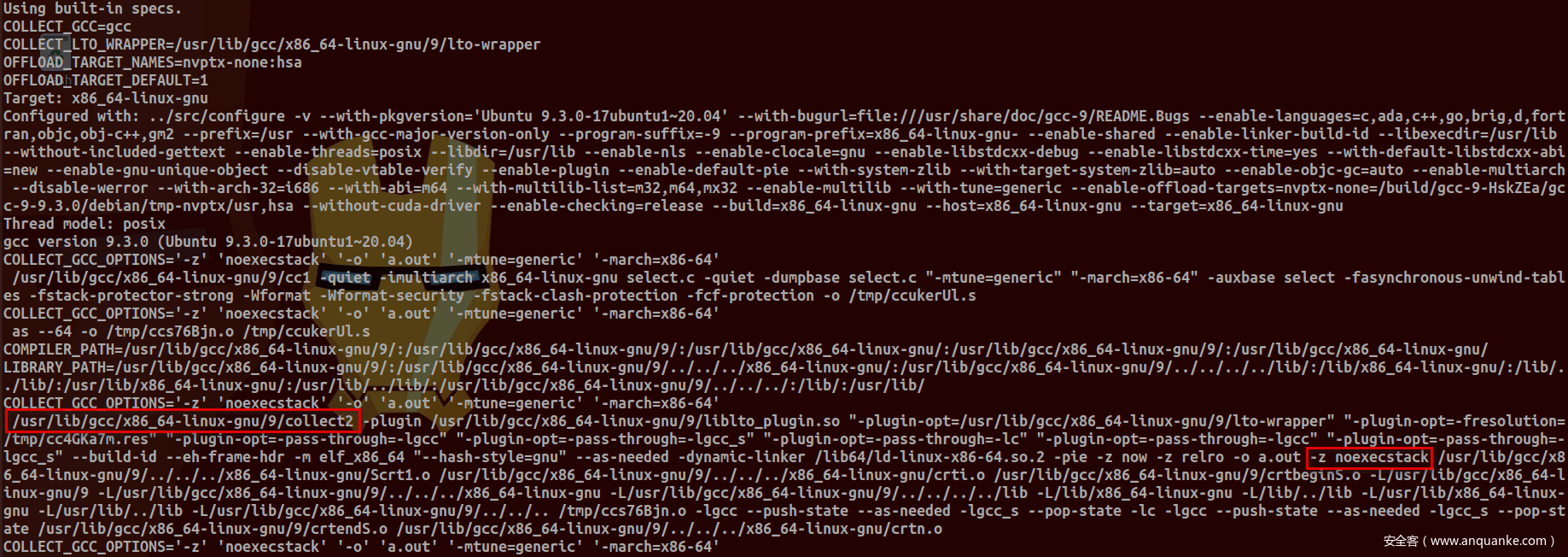
上图中collect2会执行ld,并为其传递参数:

![]()
0x01 ld
查看下-z参数含义:

下面从源码角度来分析。ld相关源码位于ld目录下,main函数(位于ldmain.c文件)如下:
ld_config_type config;
......
struct bfd_link_info link_info;
......
int
main (int argc, char **argv)
{
......
config.build_constructors = TRUE;
config.rpath_separator = ':';
config.split_by_reloc = (unsigned) -1;
config.split_by_file = (bfd_size_type) -1;
config.make_executable = TRUE;
config.magic_demand_paged = TRUE;
config.text_read_only = TRUE;
config.print_map_discarded = TRUE;
link_info.disable_target_specific_optimizations = -1;
command_line.warn_mismatch = TRUE;
command_line.warn_search_mismatch = TRUE;
command_line.check_section_addresses = -1;
/* We initialize DEMANGLING based on the environment variable
COLLECT_NO_DEMANGLE. The gcc collect2 program will demangle the
output of the linker, unless COLLECT_NO_DEMANGLE is set in the
environment. Acting the same way here lets us provide the same
interface by default. */
demangling = getenv ("COLLECT_NO_DEMANGLE") == NULL;
link_info.allow_undefined_version = TRUE;
......
parse_args (argc, argv);
parse_args函数负责解析参数,位于lexsup.c文件:
void
parse_args (unsigned argc, char **argv)
{
......
char *shortopts;
struct option *longopts;
struct option *really_longopts;
......
shortopts = (char *) xmalloc (OPTION_COUNT * 3 + 2);
longopts = (struct option *)
xmalloc (sizeof (*longopts) * (OPTION_COUNT + 1));
really_longopts = (struct option *)
malloc (sizeof (*really_longopts) * (OPTION_COUNT + 1));
/* Starting the short option string with '-' is for programs that
expect options and other ARGV-elements in any order and that care about
the ordering of the two. We describe each non-option ARGV-element
as if it were the argument of an option with character code 1. */
shortopts[0] = '-';
is = 1;
il = 0;
irl = 0;
for (i = 0; i < OPTION_COUNT; i++)
{
if (ld_options[i].shortopt != '\0')
{
shortopts[is] = ld_options[i].shortopt;
++is;
if (ld_options[i].opt.has_arg == required_argument
|| ld_options[i].opt.has_arg == optional_argument)
{
shortopts[is] = ':';
++is;
if (ld_options[i].opt.has_arg == optional_argument)
{
shortopts[is] = ':';
++is;
}
}
}
if (ld_options[i].opt.name != NULL)
{
if (ld_options[i].control == EXACTLY_TWO_DASHES)
{
really_longopts[irl] = ld_options[i].opt;
++irl;
}
else
{
longopts[il] = ld_options[i].opt;
++il;
}
}
}
shortopts[is] = '\0';
longopts[il].name = NULL;
really_longopts[irl].name = NULL;
......
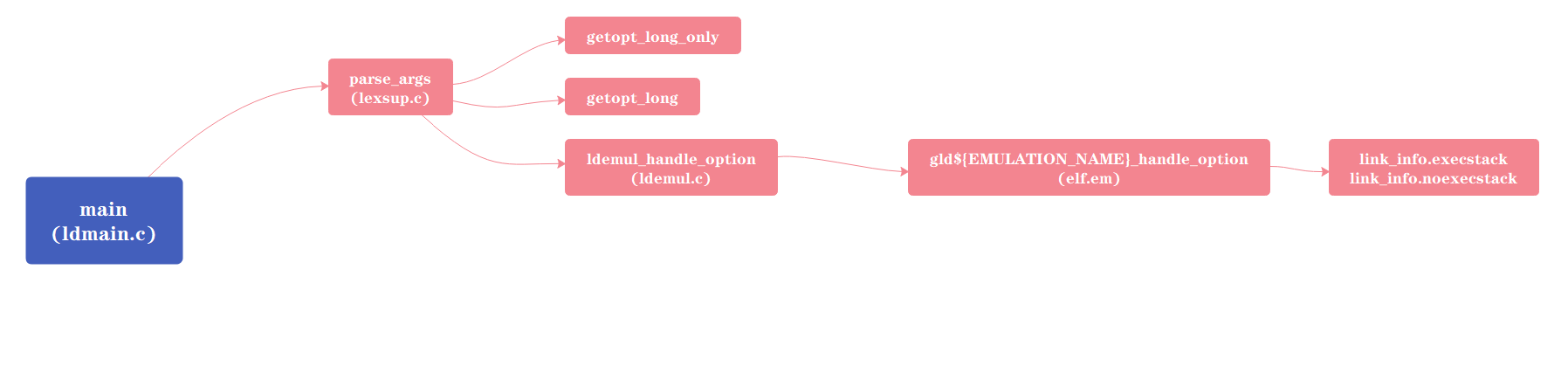
parse_args函数首先会由ld_options数组初始化shortopts,longopts以及really_longopts变量内容,这三个变量会传递给getopt_long_only与getopt_long函数以解析命令行参数:
......
last_optind = -1;
while (1)
{
int longind;
int optc;
static unsigned int defsym_count;
/* Using last_optind lets us avoid calling ldemul_parse_args
multiple times on a single option, which would lead to
confusion in the internal static variables maintained by
getopt. This could otherwise happen for an argument like
-nx, in which the -n is parsed as a single option, and we
loop around to pick up the -x. */
if (optind != last_optind)
if (ldemul_parse_args (argc, argv))
continue;
/* getopt_long_only is like getopt_long, but '-' as well as '--'
can indicate a long option. */
opterr = 0;
last_optind = optind;
optc = getopt_long_only (argc, argv, shortopts, longopts, &longind);
if (optc == '?')
{
optind = last_optind;
optc = getopt_long (argc, argv, "-", really_longopts, &longind);
}
if (ldemul_handle_option (optc))
continue;
if (optc == -1)
break;
......
ldemul_handle_option函数(位于ldemul.c文件)定义如下:
bfd_boolean
ldemul_handle_option (int optc)
{
if (ld_emulation->handle_option)
return (*ld_emulation->handle_option) (optc);
return FALSE;
}
ld_emulation定义为static ld_emulation_xfer_type *ld_emulation;,而ld_emulation_xfer_type结构针对不同架构及目标文件类型,其成员会有不同定义。以ELF文件为例,该函数定义位于elf.em文件中(由下图可以看到同目录下针对其他架构及目标文件类型的.em文件):

static bfd_boolean
gld${EMULATION_NAME}_handle_option (int optc)
{
switch (optc)
{
default:
return FALSE;
......
case 'z':
......
else if (strcmp (optarg, "execstack") == 0)
{
link_info.execstack = TRUE;
link_info.noexecstack = FALSE;
}
else if (strcmp (optarg, "noexecstack") == 0)
{
link_info.noexecstack = TRUE;
link_info.execstack = FALSE;
}
上述函数调用关系为:
之后main函数调用lang_process(),位于ldlang.c文件中。lang_process()函数会调用ldemul_before_allocation(),该函数同样位于ldemul.c文件,其定义如下:
void
ldemul_before_allocation (void)
{
ld_emulation->before_allocation ();
}
查看elf.em:
static void
gld${EMULATION_NAME}_before_allocation (void)
{
ldelf_before_allocation (audit, depaudit, ${ELF_INTERPRETER_NAME});
}
ldelf_before_allocation函数定义位于ldelf.c文件中,其调用bfd_elf_size_dynamic_sections函数:
......
if (! (bfd_elf_size_dynamic_sections
(link_info.output_bfd, command_line.soname, rpath,
command_line.filter_shlib, audit, depaudit,
(const char * const *) command_line.auxiliary_filters,
&link_info, &sinterp)))
einfo (_("%F%P: failed to set dynamic section sizes: %E\n"));
......
而该函数会执行如下操作:
......
if (info->execstack)
elf_stack_flags (output_bfd) = PF_R | PF_W | PF_X;
else if (info->noexecstack)
elf_stack_flags (output_bfd) = PF_R | PF_W;
......
上述函数调用关系为:

main函数最终执行ldwrite()函数将stack_flags写入Segment的p_flags字段中:
void
ldwrite (void)
{
/* Reset error indicator, which can typically something like invalid
format from opening up the .o files. */
bfd_set_error (bfd_error_no_error);
lang_clear_os_map ();
lang_for_each_statement (build_link_order);
if (config.split_by_reloc != (unsigned) -1
|| config.split_by_file != (bfd_size_type) -1)
split_sections (link_info.output_bfd, &link_info);
if (!bfd_final_link (link_info.output_bfd, &link_info))
{
/* If there was an error recorded, print it out. Otherwise assume
an appropriate error message like unknown symbol was printed
out. */
if (bfd_get_error () != bfd_error_no_error)
einfo (_("%F%P: final link failed: %E\n"));
else
xexit (1);
}
}
调用的bfd_final_link函数针对不同目标文件会有不同实现,以ELF文件为例,该函数对应实现为bfd_elf_final_link,位于elflink.c文件。其调用_bfd_elf_compute_section_file_positions函数,该函数再调用assign_file_positions_except_relocs函数:
/* Work out the file positions of all the sections. This is called by
_bfd_elf_compute_section_file_positions. All the section sizes and
VMAs must be known before this is called.
Reloc sections come in two flavours: Those processed specially as
"side-channel" data attached to a section to which they apply, and those that
bfd doesn't process as relocations. The latter sort are stored in a normal
bfd section by bfd_section_from_shdr. We don't consider the former sort
here, unless they form part of the loadable image. Reloc sections not
assigned here (and compressed debugging sections and CTF sections which
nothing else in the file can rely upon) will be handled later by
assign_file_positions_for_relocs.
We also don't set the positions of the .symtab and .strtab here. */
static bfd_boolean
assign_file_positions_except_relocs (bfd *abfd,
struct bfd_link_info *link_info)
{
struct elf_obj_tdata *tdata = elf_tdata (abfd);
Elf_Internal_Ehdr *i_ehdrp = elf_elfheader (abfd);
const struct elf_backend_data *bed = get_elf_backend_data (abfd);
unsigned int alloc;
if ((abfd->flags & (EXEC_P | DYNAMIC)) == 0
&& bfd_get_format (abfd) != bfd_core)
{
......
}
else
{
/* Assign file positions for the loaded sections based on the
assignment of sections to segments. */
if (!assign_file_positions_for_load_sections (abfd, link_info))
return FALSE;
/* And for non-load sections. */
if (!assign_file_positions_for_non_load_sections (abfd, link_info))
return FALSE;
}
if (!(*bed->elf_backend_modify_headers) (abfd, link_info))
return FALSE;
/* Write out the program headers. */
alloc = i_ehdrp->e_phnum;
if (alloc != 0)
{
if (bfd_seek (abfd, i_ehdrp->e_phoff, SEEK_SET) != 0
|| bed->s->write_out_phdrs (abfd, tdata->phdr, alloc) != 0)
return FALSE;
}
return TRUE;
}
assign_file_positions_for_load_sections函数调用_bfd_elf_map_sections_to_segments将Sections映射到Segments:
static bfd_boolean
assign_file_positions_for_load_sections (bfd *abfd,
struct bfd_link_info *link_info)
{
const struct elf_backend_data *bed = get_elf_backend_data (abfd);
struct elf_segment_map *m;
struct elf_segment_map *phdr_load_seg;
Elf_Internal_Phdr *phdrs;
Elf_Internal_Phdr *p;
file_ptr off;
bfd_size_type maxpagesize;
unsigned int alloc, actual;
unsigned int i, j;
struct elf_segment_map **sorted_seg_map;
if (link_info == NULL
&& !_bfd_elf_map_sections_to_segments (abfd, link_info))
return FALSE;
......
_bfd_elf_map_sections_to_segments负责将stack_flags写入Segment的p_flags字段:
......
if (elf_stack_flags (abfd))
{
amt = sizeof (struct elf_segment_map);
m = (struct elf_segment_map *) bfd_zalloc (abfd, amt);
if (m == NULL)
goto error_return;
m->next = NULL;
m->p_type = PT_GNU_STACK;
m->p_flags = elf_stack_flags (abfd);
m->p_align = bed->stack_align;
m->p_flags_valid = 1;
m->p_align_valid = m->p_align != 0;
if (info->stacksize > 0)
{
m->p_size = info->stacksize;
m->p_size_valid = 1;
}
*pm = m;
pm = &m->next;
}
......
变量m为elf_segment_map结构类型,其定义位于internal.h文件:
/* This structure is used to describe how sections should be assigned
to program segments. */
struct elf_segment_map
{
/* Next program segment. */
struct elf_segment_map *next;
/* Program segment type. */
unsigned long p_type;
/* Program segment flags. */
unsigned long p_flags;
/* Program segment physical address. */
bfd_vma p_paddr;
/* Program segment virtual address offset from section vma. */
bfd_vma p_vaddr_offset;
/* Program segment alignment. */
bfd_vma p_align;
/* Segment size in file and memory */
bfd_vma p_size;
/* Whether the p_flags field is valid; if not, the flags are based
on the section flags. */
unsigned int p_flags_valid : 1;
/* Whether the p_paddr field is valid; if not, the physical address
is based on the section lma values. */
unsigned int p_paddr_valid : 1;
/* Whether the p_align field is valid; if not, PT_LOAD segment
alignment is based on the default maximum page size. */
unsigned int p_align_valid : 1;
/* Whether the p_size field is valid; if not, the size are based
on the section sizes. */
unsigned int p_size_valid : 1;
/* Whether this segment includes the file header. */
unsigned int includes_filehdr : 1;
/* Whether this segment includes the program headers. */
unsigned int includes_phdrs : 1;
/* Assume this PT_LOAD header has an lma of zero when sorting
headers before assigning file offsets. PT_LOAD headers with this
flag set are placed after one with includes_filehdr set, and
before PT_LOAD headers without this flag set. */
unsigned int no_sort_lma : 1;
/* Index holding original order before sorting segments. */
unsigned int idx;
/* Number of sections (may be 0). */
unsigned int count;
/* Sections. Actual number of elements is in count field. */
asection *sections[1];
};
上述函数调用关系为:

最终体现在目标文件中:

0x02 kernel
处理程序执行的系统调用为execve:
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
查看do_execve函数定义
int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
do_execveat_common函数定义如下:
/*
* sys_execve() executes a new program.
*/
static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
char *pathbuf = NULL;
struct linux_binprm *bprm;
struct file *file;
struct files_struct *displaced;
int retval;
if (IS_ERR(filename))
return PTR_ERR(filename);
/*
* We move the actual failure in case of RLIMIT_NPROC excess from
* set*uid() to execve() because too many poorly written programs
* don't check setuid() return code. Here we additionally recheck
* whether NPROC limit is still exceeded.
*/
if ((current->flags & PF_NPROC_EXCEEDED) &&
atomic_read(¤t_user()->processes) > rlimit(RLIMIT_NPROC)) {
retval = -EAGAIN;
goto out_ret;
}
/* We're below the limit (still or again), so we don't want to make
* further execve() calls fail. */
current->flags &= ~PF_NPROC_EXCEEDED;
retval = unshare_files(&displaced);
if (retval)
goto out_ret;
retval = -ENOMEM;
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
if (!bprm)
goto out_files;
retval = prepare_bprm_creds(bprm);
if (retval)
goto out_free;
check_unsafe_exec(bprm);
current->in_execve = 1;
file = do_open_execat(fd, filename, flags);
retval = PTR_ERR(file);
if (IS_ERR(file))
goto out_unmark;
sched_exec();
bprm->file = file;
if (fd == AT_FDCWD || filename->name[0] == '/') {
bprm->filename = filename->name;
} else {
if (filename->name[0] == '\0')
pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d", fd);
else
pathbuf = kasprintf(GFP_KERNEL, "/dev/fd/%d/%s",
fd, filename->name);
if (!pathbuf) {
retval = -ENOMEM;
goto out_unmark;
}
/*
* Record that a name derived from an O_CLOEXEC fd will be
* inaccessible after exec. Relies on having exclusive access to
* current->files (due to unshare_files above).
*/
if (close_on_exec(fd, rcu_dereference_raw(current->files->fdt)))
bprm->interp_flags |= BINPRM_FLAGS_PATH_INACCESSIBLE;
bprm->filename = pathbuf;
}
bprm->interp = bprm->filename;
retval = bprm_mm_init(bprm);
if (retval)
goto out_unmark;
bprm->argc = count(argv, MAX_ARG_STRINGS);
if ((retval = bprm->argc) < 0)
goto out;
bprm->envc = count(envp, MAX_ARG_STRINGS);
if ((retval = bprm->envc) < 0)
goto out;
retval = prepare_binprm(bprm);
if (retval < 0)
goto out;
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;
would_dump(bprm, bprm->file);
retval = exec_binprm(bprm);
if (retval < 0)
goto out;
/* execve succeeded */
current->fs->in_exec = 0;
current->in_execve = 0;
membarrier_execve(current);
acct_update_integrals(current);
task_numa_free(current);
free_bprm(bprm);
kfree(pathbuf);
putname(filename);
if (displaced)
put_files_struct(displaced);
return retval;
out:
bprm变量指向linux_binprm结构,该结构存储与可执行文件相关的信息,其定义如下:
/*
* This structure is used to hold the arguments that are used when loading binaries.
*/
struct linux_binprm {
char buf[BINPRM_BUF_SIZE]; //#define BINPRM_BUF_SIZE 128 存储可执行文件前128字节
#ifdef CONFIG_MMU
struct vm_area_struct *vma;
unsigned long vma_pages;
#else
# define MAX_ARG_PAGES 32
struct page *page[MAX_ARG_PAGES];
#endif
struct mm_struct *mm;
unsigned long p; /* current top of mem */
unsigned int
/*
* True after the bprm_set_creds hook has been called once
* (multiple calls can be made via prepare_binprm() for
* binfmt_script/misc).
*/
called_set_creds:1,
/*
* True if most recent call to the commoncaps bprm_set_creds
* hook (due to multiple prepare_binprm() calls from the
* binfmt_script/misc handlers) resulted in elevated
* privileges.
*/
cap_elevated:1,
/*
* Set by bprm_set_creds hook to indicate a privilege-gaining
* exec has happened. Used to sanitize execution environment
* and to set AT_SECURE auxv for glibc.
*/
secureexec:1;
#ifdef __alpha__
unsigned int taso:1;
#endif
unsigned int recursion_depth; /* only for search_binary_handler() */
struct file * file;
struct cred *cred; /* new credentials */
int unsafe; /* how unsafe this exec is (mask of LSM_UNSAFE_*) */
unsigned int per_clear; /* bits to clear in current->personality */
int argc, envc;
const char * filename; /* Name of binary as seen by procps */
const char * interp; /* Name of the binary really executed. Most
of the time same as filename, but could be
different for binfmt_{misc,script} */
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
} __randomize_layout;
do_execveat_common函数会填充bprm变量中内容,之后做一些权限检查,复制及初始化工作,最后调用exec_binprm函数执行可执行文件:
static int exec_binprm(struct linux_binprm *bprm)
{
pid_t old_pid, old_vpid;
int ret;
/* Need to fetch pid before load_binary changes it */
old_pid = current->pid;
rcu_read_lock();
old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent));
rcu_read_unlock();
ret = search_binary_handler(bprm);
if (ret >= 0) {
audit_bprm(bprm);
trace_sched_process_exec(current, old_pid, bprm);
ptrace_event(PTRACE_EVENT_EXEC, old_vpid);
proc_exec_connector(current);
}
return ret;
}
其调用search_binary_handler函数对formats链表进行扫描,并执行其load_binary函数,直到其中一个成功解析了可执行文件格式,否则会返回负值:
/*
* cycle the list of binary formats handler, until one recognizes the image
*/
int search_binary_handler(struct linux_binprm *bprm)
{
bool need_retry = IS_ENABLED(CONFIG_MODULES);
struct linux_binfmt *fmt;
int retval;
/* This allows 4 levels of binfmt rewrites before failing hard. */
if (bprm->recursion_depth > 5)
return -ELOOP;
retval = security_bprm_check(bprm);
if (retval)
return retval;
retval = -ENOENT;
retry:
read_lock(&binfmt_lock);
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
bprm->recursion_depth--;
if (retval < 0 && !bprm->mm) {
/* we got to flush_old_exec() and failed after it */
read_unlock(&binfmt_lock);
force_sigsegv(SIGSEGV, current);
return retval;
}
if (retval != -ENOEXEC || !bprm->file) {
read_unlock(&binfmt_lock);
return retval;
}
}
read_unlock(&binfmt_lock);
if (need_retry) {
if (printable(bprm->buf[0]) && printable(bprm->buf[1]) &&
printable(bprm->buf[2]) && printable(bprm->buf[3]))
return retval;
if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0)
return retval;
need_retry = false;
goto retry;
}
return retval;
}
EXPORT_SYMBOL(search_binary_handler);
对于ELF文件,load_binary对应于load_elf_binary,其定义位于binfmt_elf.c文件:
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
该函数会执行如下操作:
......
struct elf_phdr *elf_ppnt, *elf_phdata, *interp_elf_phdata = NULL;
......
int executable_stack = EXSTACK_DEFAULT;
elf_ppnt = elf_phdata;
for (i = 0; i < loc->elf_ex.e_phnum; i++, elf_ppnt++)
switch (elf_ppnt->p_type) {
case PT_GNU_STACK:
if (elf_ppnt->p_flags & PF_X)
executable_stack = EXSTACK_ENABLE_X;
else
executable_stack = EXSTACK_DISABLE_X;
break;
case PT_LOPROC ... PT_HIPROC:
retval = arch_elf_pt_proc(&loc->elf_ex, elf_ppnt,
bprm->file, false,
&arch_state);
if (retval)
goto out_free_dentry;
break;
}
......
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
if (retval < 0)
goto out_free_dentry;
setup_arg_pages函数定义位于exec.c文件中:
/*
* Finalizes the stack vm_area_struct. The flags and permissions are updated,
* the stack is optionally relocated, and some extra space is added.
*/
int setup_arg_pages(struct linux_binprm *bprm,
unsigned long stack_top,
int executable_stack)
{
unsigned long ret;
unsigned long stack_shift;
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma = bprm->vma;
struct vm_area_struct *prev = NULL;
unsigned long vm_flags;
unsigned long stack_base;
unsigned long stack_size;
unsigned long stack_expand;
unsigned long rlim_stack;
......
vm_flags = VM_STACK_FLAGS;
/*
* Adjust stack execute permissions; explicitly enable for
* EXSTACK_ENABLE_X, disable for EXSTACK_DISABLE_X and leave alone
* (arch default) otherwise.
*/
if (unlikely(executable_stack == EXSTACK_ENABLE_X))
vm_flags |= VM_EXEC;
else if (executable_stack == EXSTACK_DISABLE_X)
vm_flags &= ~VM_EXEC;
vm_flags |= mm->def_flags;
vm_flags |= VM_STACK_INCOMPLETE_SETUP;
ret = mprotect_fixup(vma, &prev, vma->vm_start, vma->vm_end,vm_flags);
if (ret)
goto out_unlock;
......
mprotect_fixup函数进行检查过后,会执行如下语句将vm_flags赋值给vma->vm_flags:
int mprotect_fixup(struct vm_area_struct *vma, struct vm_area_struct **pprev,unsigned long start, unsigned long end, unsigned long newflags)
{
......
success:
/*
* vm_flags and vm_page_prot are protected by the mmap_sem
* held in write mode.
*/
vma->vm_flags = newflags;
如此一来,bprm->vma中的vm_flags值为newflags,确定了该虚拟地址空间的访问权限,权限定义位于mm.h文件中:
/*
* vm_flags in vm_area_struct, see mm_types.h.
* When changing, update also include/trace/events/mmflags.h
*/
#define VM_NONE 0x00000000
#define VM_READ 0x00000001 /* currently active flags */
#define VM_WRITE 0x00000002
#define VM_EXEC 0x00000004
#define VM_SHARED 0x00000008
上述函数调用关系为:

关于NX在CPU层面的实现,以Intel为例。Intel SDM中描述如下:

只有CPUID.80000001H:EDX.NX [bit 20] = 1,IA32_EFER.NXE才可以置位为1或是0,其支持PAE,4-level,5-level分页,不支持32位经典分页:

IA32_EFER.NXE置位为1,XD位才能被设置,否则保留:

内核可以通过noexec on|off来配置是否启用NX:
static int disable_nx;
/*
* noexec = on|off
*
* Control non-executable mappings for processes.
*
* on Enable
* off Disable
*/
static int __init noexec_setup(char *str)
{
if (!str)
return -EINVAL;
if (!strncmp(str, "on", 2)) {
disable_nx = 0;
} else if (!strncmp(str, "off", 3)) {
disable_nx = 1;
}
x86_configure_nx();
return 0;
}
early_param("noexec", noexec_setup);
x86_configure_nx()函数:
void x86_configure_nx(void)
{
if (boot_cpu_has(X86_FEATURE_NX) && !disable_nx)
__supported_pte_mask |= _PAGE_NX;
else
__supported_pte_mask &= ~_PAGE_NX;
}
其中X86_FEATURE_NX定义如下:
/* AMD-defined CPU features, CPUID level 0x80000001, word 1 */
/* Don't duplicate feature flags which are redundant with Intel! */
#define X86_FEATURE_SYSCALL ( 1*32+11) /* SYSCALL/SYSRET */
#define X86_FEATURE_MP ( 1*32+19) /* MP Capable */
#define X86_FEATURE_NX ( 1*32+20) /* Execute Disable */
#define X86_FEATURE_MMXEXT ( 1*32+22) /* AMD MMX extensions */
#define X86_FEATURE_FXSR_OPT ( 1*32+25) /* FXSAVE/FXRSTOR optimizations */
#define X86_FEATURE_GBPAGES ( 1*32+26) /* "pdpe1gb" GB pages */
#define X86_FEATURE_RDTSCP ( 1*32+27) /* RDTSCP */
#define X86_FEATURE_LM ( 1*32+29) /* Long Mode (x86-64, 64-bit support) */
#define X86_FEATURE_3DNOWEXT ( 1*32+30) /* AMD 3DNow extensions */
#define X86_FEATURE_3DNOW ( 1*32+31) /* 3DNow */
_PAGE_NX定义:
#if defined(CONFIG_X86_64) || defined(CONFIG_X86_PAE)
#define _PAGE_NX (_AT(pteval_t, 1) << _PAGE_BIT_NX)
#define _PAGE_DEVMAP (_AT(u64, 1) << _PAGE_BIT_DEVMAP)
#define __HAVE_ARCH_PTE_DEVMAP
#else
#define _PAGE_NX (_AT(pteval_t, 0))
#define _PAGE_DEVMAP (_AT(pteval_t, 0))
#endif
_PAGE_BIT_NX定义语句为#define _PAGE_BIT_NX 63,与Intel SDM中描述一致。__supported_pte_mask会在massage_pgprot函数中使用:
static inline pgprotval_t massage_pgprot(pgprot_t pgprot)
{
pgprotval_t protval = pgprot_val(pgprot);
if (protval & _PAGE_PRESENT)
protval &= __supported_pte_mask;
return protval;
}
static inline pte_t pfn_pte(unsigned long page_nr, pgprot_t pgprot)
{
return __pte(((phys_addr_t)page_nr << PAGE_SHIFT) |
massage_pgprot(pgprot));
}
static inline pmd_t pfn_pmd(unsigned long page_nr, pgprot_t pgprot)
{
return __pmd(((phys_addr_t)page_nr << PAGE_SHIFT) |
massage_pgprot(pgprot));
}
static inline pud_t pfn_pud(unsigned long page_nr, pgprot_t pgprot)
{
return __pud(((phys_addr_t)page_nr << PAGE_SHIFT) |
massage_pgprot(pgprot));
}







发表评论
您还未登录,请先登录。
登录