

0x00 前言
本文不会介绍CPU特权级别,中断,MSR,段机制及页机制等相关前置知识,如果读者此前未接触过这些,建议阅读Intel SDM对应篇章或者参阅链接之后再继续下面篇幅。本文基于如下环境:
- CPU:Intel
- Kernel Version:4.15.0
- Debugging Env:Ubuntu 20.04.02 x64(Kernel Version—5.11.0)
0x01 INT $0x80
a. 源码分析
首先从源码角度分析传统系统调用,即int 0x80。IDT(Interrupt Descriptor Table)建立位于arch/x86/kernel/traps.c中:
void __init trap_init(void)
{
/* Init cpu_entry_area before IST entries are set up */
setup_cpu_entry_areas();
idt_setup_traps();
/*
* Set the IDT descriptor to a fixed read-only location, so that the
* "sidt" instruction will not leak the location of the kernel, and
* to defend the IDT against arbitrary memory write vulnerabilities.
* It will be reloaded in cpu_init() */
cea_set_pte(CPU_ENTRY_AREA_RO_IDT_VADDR, __pa_symbol(idt_table),
PAGE_KERNEL_RO);
idt_descr.address = CPU_ENTRY_AREA_RO_IDT;
/*
* Should be a barrier for any external CPU state:
*/
cpu_init();
idt_setup_ist_traps();
x86_init.irqs.trap_init();
idt_setup_debugidt_traps();
}
idt_setup_traps()函数定义在arch/x86/kernel/idt.c中:
/**
* idt_setup_traps - Initialize the idt table with default traps
*/
void __init idt_setup_traps(void)
{
idt_setup_from_table(idt_table, def_idts, ARRAY_SIZE(def_idts), true);
}
其调用idt_setup_from_table函数同样位于该文件:
static void
idt_setup_from_table(gate_desc *idt, const struct idt_data *t, int size, bool sys)
{
gate_desc desc;
for (; size > 0; t++, size--) {
idt_init_desc(&desc, t);
write_idt_entry(idt, t->vector, &desc);
if (sys)
set_bit(t->vector, system_vectors);
}
}
def_idts存储了IDT各项默认值,其定义如下:
/*
* The default IDT entries which are set up in trap_init() before
* cpu_init() is invoked. Interrupt stacks cannot be used at that point and
* the traps which use them are reinitialized with IST after cpu_init() has
* set up TSS.
*/
static const __initconst struct idt_data def_idts[] = {
INTG(X86_TRAP_DE, divide_error),
INTG(X86_TRAP_NMI, nmi),
INTG(X86_TRAP_BR, bounds),
INTG(X86_TRAP_UD, invalid_op),
INTG(X86_TRAP_NM, device_not_available),
INTG(X86_TRAP_OLD_MF, coprocessor_segment_overrun),
INTG(X86_TRAP_TS, invalid_TSS),
INTG(X86_TRAP_NP, segment_not_present),
INTG(X86_TRAP_SS, stack_segment),
INTG(X86_TRAP_GP, general_protection),
INTG(X86_TRAP_SPURIOUS, spurious_interrupt_bug),
INTG(X86_TRAP_MF, coprocessor_error),
INTG(X86_TRAP_AC, alignment_check),
INTG(X86_TRAP_XF, simd_coprocessor_error),
#ifdef CONFIG_X86_32
TSKG(X86_TRAP_DF, GDT_ENTRY_DOUBLEFAULT_TSS),
#else
INTG(X86_TRAP_DF, double_fault),
#endif
INTG(X86_TRAP_DB, debug),
#ifdef CONFIG_X86_MCE
INTG(X86_TRAP_MC, &machine_check),
#endif
SYSG(X86_TRAP_OF, overflow),
#if defined(CONFIG_IA32_EMULATION)
SYSG(IA32_SYSCALL_VECTOR, entry_INT80_compat),
#elif defined(CONFIG_X86_32)
SYSG(IA32_SYSCALL_VECTOR, entry_INT80_32),
#endif
};
根据配置选项不同,IA32_SYSCALL_VECTOR项值不同——若启用CONFIG_IA32_EMULATION,则以64位兼容模式运行32位程序;否则是32位。IA32_SYSCALL_VECTOR定义如下:
#define IA32_SYSCALL_VECTOR 0x80
INTG与SYSG定义不同之处在于DPL:
/* Interrupt gate */
#define INTG(_vector, _addr) \
G(_vector, _addr, DEFAULT_STACK, GATE_INTERRUPT, DPL0, __KERNEL_CS)
/* System interrupt gate */
#define SYSG(_vector, _addr) \
G(_vector, _addr, DEFAULT_STACK, GATE_INTERRUPT, DPL3, __KERNEL_CS)
相关定义如下:
#define DPL0 0x0
#define DPL3 0x3
#define DEFAULT_STACK 0
#define G(_vector, _addr, _ist, _type, _dpl, _segment) \
{ \
.vector = _vector, \
.bits.ist = _ist, \
.bits.type = _type, \
.bits.dpl = _dpl, \
.bits.p = 1, \
.addr = _addr, \
.segment = _segment, \
}
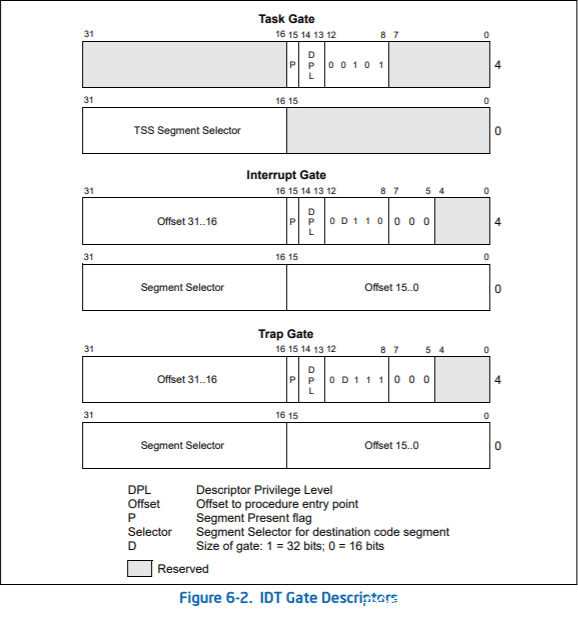
门描述符及类型定义如下(位于/arch/x86/include/asm/desc_defs.h):
struct gate_struct {
u16 offset_low;
u16 segment;
struct idt_bits bits;
u16 offset_middle;
#ifdef CONFIG_X86_64
u32 offset_high;
u32 reserved;
#endif
} __attribute__((packed));
enum {
GATE_INTERRUPT = 0xE,
GATE_TRAP = 0xF,
GATE_CALL = 0xC,
GATE_TASK = 0x5,
};
对应于Intel SDM中:
idt_init_desc函数定义如下:
static inline void idt_init_desc(gate_desc *gate, const struct idt_data *d)
{
unsigned long addr = (unsigned long) d->addr;
gate->offset_low = (u16) addr;
gate->segment = (u16) d->segment;
gate->bits = d->bits;
gate->offset_middle = (u16) (addr >> 16);
#ifdef CONFIG_X86_64
gate->offset_high = (u32) (addr >> 32);
gate->reserved = 0;
#endif
}
write_idt_entry是memcpy函数的简单包装:
#define write_idt_entry(dt, entry, g) native_write_idt_entry(dt, entry, g)
......
static inline void native_write_idt_entry(gate_desc *idt, int entry, const gate_desc *gate)
{
memcpy(&idt[entry], gate, sizeof(*gate));
}
如此一来,便在IDT 0x80项写入了系统调用函数地址。上述函数调用关系为:

entry_INT80_32定义位于arch/x86/entry/entry_32.S文件中:
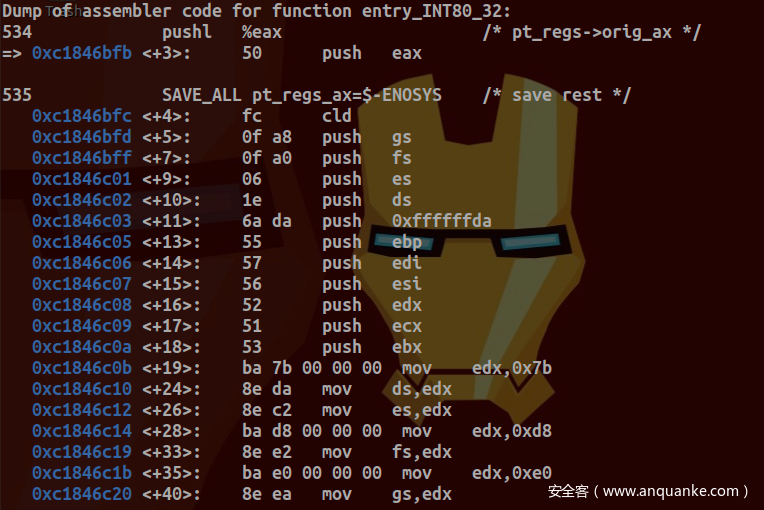
ENTRY(entry_INT80_32)
ASM_CLAC
pushl %eax /* pt_regs->orig_ax */
SAVE_ALL pt_regs_ax=$-ENOSYS /* save rest */
/*
* User mode is traced as though IRQs are on, and the interrupt gate
* turned them off.
*/
TRACE_IRQS_OFF
movl %esp, %eax
call do_int80_syscall_32
.Lsyscall_32_done:
restore_all:
TRACE_IRQS_IRET
.Lrestore_all_notrace:
#ifdef CONFIG_X86_ESPFIX32
ALTERNATIVE "jmp .Lrestore_nocheck", "", X86_BUG_ESPFIX
movl PT_EFLAGS(%esp), %eax # mix EFLAGS, SS and CS
/*
* Warning: PT_OLDSS(%esp) contains the wrong/random values if we
* are returning to the kernel.
* See comments in process.c:copy_thread() for details.
*/
movb PT_OLDSS(%esp), %ah
movb PT_CS(%esp), %al
andl $(X86_EFLAGS_VM | (SEGMENT_TI_MASK << 8) | SEGMENT_RPL_MASK), %eax
cmpl $((SEGMENT_LDT << 8) | USER_RPL), %eax
je .Lldt_ss # returning to user-space with LDT SS
#endif
.Lrestore_nocheck:
RESTORE_REGS 4 # skip orig_eax/error_code
.Lirq_return:
INTERRUPT_RETURN
.section .fixup, "ax"
ENTRY(iret_exc )
pushl $0 # no error code
pushl $do_iret_error
jmp common_exception
.previous
_ASM_EXTABLE(.Lirq_return, iret_exc)
#ifdef CONFIG_X86_ESPFIX32
.Lldt_ss:
/*
* Setup and switch to ESPFIX stack
*
* We're returning to userspace with a 16 bit stack. The CPU will not
* restore the high word of ESP for us on executing iret... This is an
* "official" bug of all the x86-compatible CPUs, which we can work
* around to make dosemu and wine happy. We do this by preloading the
* high word of ESP with the high word of the userspace ESP while
* compensating for the offset by changing to the ESPFIX segment with
* a base address that matches for the difference.
*/
#define GDT_ESPFIX_SS PER_CPU_VAR(gdt_page) + (GDT_ENTRY_ESPFIX_SS * 8)
mov %esp, %edx /* load kernel esp */
mov PT_OLDESP(%esp), %eax /* load userspace esp */
mov %dx, %ax /* eax: new kernel esp */
sub %eax, %edx /* offset (low word is 0) */
shr $16, %edx
mov %dl, GDT_ESPFIX_SS + 4 /* bits 16..23 */
mov %dh, GDT_ESPFIX_SS + 7 /* bits 24..31 */
pushl $__ESPFIX_SS
pushl %eax /* new kernel esp */
/*
* Disable interrupts, but do not irqtrace this section: we
* will soon execute iret and the tracer was already set to
* the irqstate after the IRET:
*/
DISABLE_INTERRUPTS(CLBR_ANY)
lss (%esp), %esp /* switch to espfix segment */
jmp .Lrestore_nocheck
#endif
ENDPROC(entry_INT80_32)
执行系统调用的主要代码位于do_int80_syscall_32(arch/x86/entry/common.c):
/* Handles int $0x80 */
__visible void do_int80_syscall_32(struct pt_regs *regs)
{
enter_from_user_mode();
local_irq_enable();
do_syscall_32_irqs_on(regs);
}
do_syscall_32_irqs_on定义如下:
#if defined(CONFIG_X86_32) || defined(CONFIG_IA32_EMULATION)
/*
* Does a 32-bit syscall. Called with IRQs on in CONTEXT_KERNEL. Does
* all entry and exit work and returns with IRQs off. This function is
* extremely hot in workloads that use it, and it's usually called from
* do_fast_syscall_32, so forcibly inline it to improve performance.
*/
static __always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned int nr = (unsigned int)regs->orig_ax;
#ifdef CONFIG_IA32_EMULATION
current->thread.status |= TS_COMPAT;
#endif
if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY) {
/*
* Subtlety here: if ptrace pokes something larger than
* 2^32-1 into orig_ax, this truncates it. This may or
* may not be necessary, but it matches the old asm
* behavior.
*/
nr = syscall_trace_enter(regs);
}
if (likely(nr < IA32_NR_syscalls)) {
/*
* It's possible that a 32-bit syscall implementation
* takes a 64-bit parameter but nonetheless assumes that
* the high bits are zero. Make sure we zero-extend all
* of the args.
*/
regs->ax = ia32_sys_call_table[nr](
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
syscall_return_slowpath(regs);
}
上述函数调用关系为:

ia32_sys_call_table定义位于同目录的syscall_32.c文件中:
extern asmlinkage long sys_ni_syscall(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long);
__visible const sys_call_ptr_t ia32_sys_call_table[__NR_syscall_compat_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
#include <asm/syscalls_32.h>
};
sys_ni_syscall(kernel/sys_ni.c)定义如下,对应于未实现的系统调用:
/*
* Non-implemented system calls get redirected here.
*/
asmlinkage long sys_ni_syscall(void)
{
return -ENOSYS;
}
asm/syscalls_32.h文件内容由syscalltbl.sh脚本根据syscall_32.tbl生成,具体定义在arch/x86/entry/syscalls/Makefile中:
syscall32 := $(srctree)/$(src)/syscall_32.tbl
syscall64 := $(srctree)/$(src)/syscall_64.tbl
syshdr := $(srctree)/$(src)/syscallhdr.sh
systbl := $(srctree)/$(src)/syscalltbl.sh
......
$(out)/syscalls_32.h: $(syscall32) $(systbl)
$(call if_changed,systbl)
$(out)/syscalls_64.h: $(syscall64) $(systbl)
$(call if_changed,systbl)
syscall_32.tbl中存储了系统调用名称,调用号及入口等内容:

syscall_32.c文件中有如下宏定义:
#define __SYSCALL_I386(nr, sym, qual) extern asmlinkage long sym(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long) ;
#include <asm/syscalls_32.h>
#undef __SYSCALL_I386
#define __SYSCALL_I386(nr, sym, qual) [nr] = sym,
那么ia32_sys_call_table数组内容会成为如下形式:
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
[0] = sys_restart_syscall,
[1] = sys_exit,
......
#define __SYSCALL_I386(nr, sym, qual) [nr] = sym,宏定义了ia32_sys_call_table数组项——以系统调用号为索引;#define __SYSCALL_I386(nr, sym, qual) extern asmlinkage long sym(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long);定义了每项中系统调用函数Entry Point。
如此一来,ia32_sys_call_table[nr]((unsigned int)regs->bx, (unsigned int)regs->cx,(unsigned int)regs->dx, (unsigned int)regs->si,(unsigned int)regs->di, (unsigned int)regs->bp);便会调用真正实现功能函数。以sys_restart_syscall为例,其定义位于kernel/signal.c中:
/**
* sys_restart_syscall - restart a system call
*/
SYSCALL_DEFINE0(restart_syscall)
{
struct restart_block *restart = ¤t->restart_block;
return restart->fn(restart);
}
SYSCALL_DEFINE相关宏定义位于include/linux/syscalls.h中:
#define SYSCALL_METADATA(sname, nb, ...)
static inline int is_syscall_trace_event(struct trace_event_call *tp_event)
{
return 0;
}
#endif
#define SYSCALL_DEFINE0(sname) \
SYSCALL_METADATA(_##sname, 0); \
asmlinkage long sys_##sname(void)
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE_MAXARGS 6
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__))
系统调用返回是通过IRET语句:

其弹出寄存器值在发生中断时已经保存在栈中:

b. 动态调试
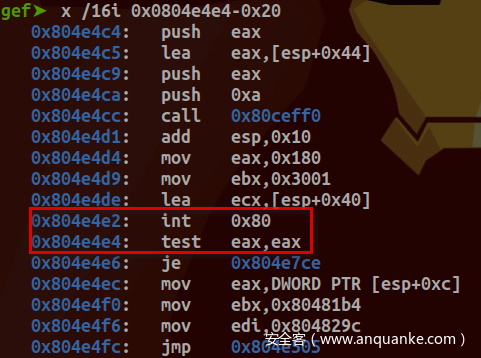
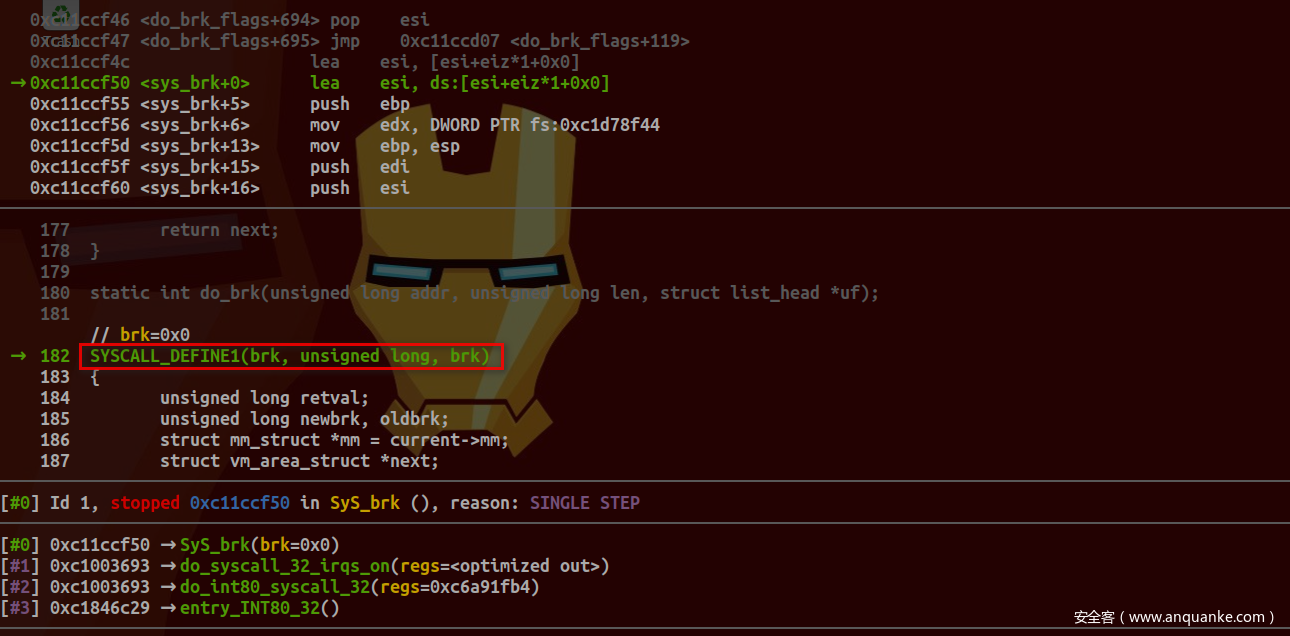
下面通过动态调试(调试环境使用Qemu+GDB+Busybox搭建)来剖析传统系统调用过程。于entry_INT80_32设置断点后,键入clear命令,成功断下:

查看栈中各寄存器值:

确为INT $0x80传统系统调用:
保存系统调用号及相关寄存器值:
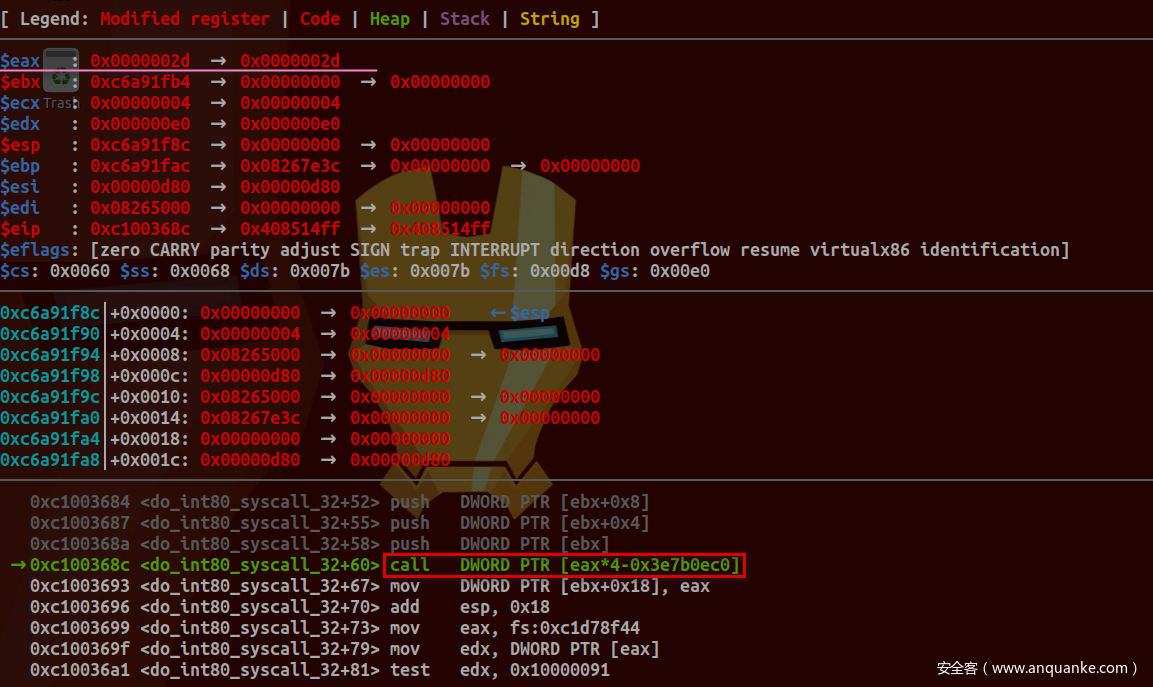
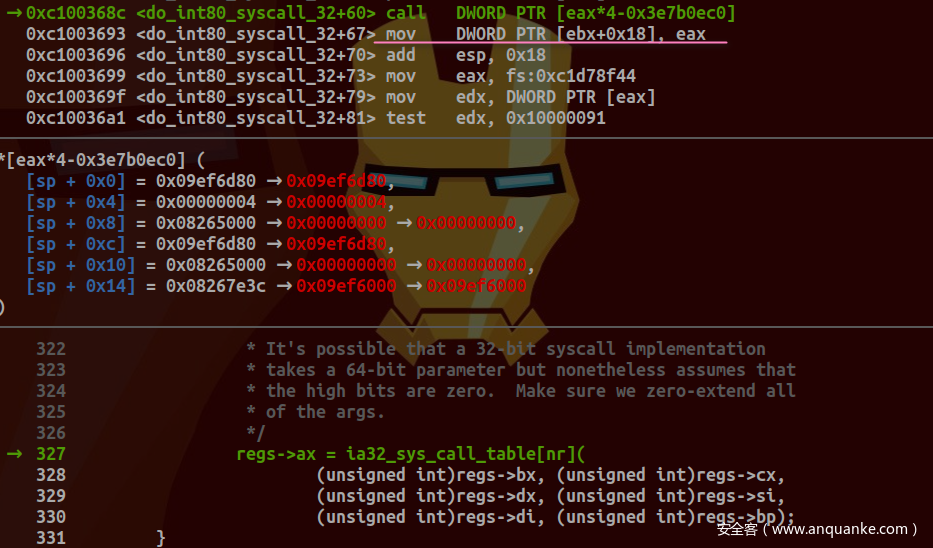
传递regs参数给do_int80_syscall_32及引用其成员值:

对应源码为:
unsigned int nr = (unsigned int)regs->orig_ax;
......
if (likely(nr < IA32_NR_syscalls)) {
/*
* It's possible that a 32-bit syscall implementation
* takes a 64-bit parameter but nonetheless assumes that
* the high bits are zero. Make sure we zero-extend all
* of the args.
*/
regs->ax = ia32_sys_call_table[nr](
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
pt_regs结构定义如下:
struct pt_regs {
/*
* NB: 32-bit x86 CPUs are inconsistent as what happens in the
* following cases (where %seg represents a segment register):
*
* - pushl %seg: some do a 16-bit write and leave the high
* bits alone
* - movl %seg, [mem]: some do a 16-bit write despite the movl
* - IDT entry: some (e.g. 486) will leave the high bits of CS
* and (if applicable) SS undefined.
*
* Fortunately, x86-32 doesn't read the high bits on POP or IRET,
* so we can just treat all of the segment registers as 16-bit
* values.
*/
unsigned long bx;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long bp;
unsigned long ax;
unsigned short ds;
unsigned short __dsh;
unsigned short es;
unsigned short __esh;
unsigned short fs;
unsigned short __fsh;
unsigned short gs;
unsigned short __gsh;
unsigned long orig_ax;
unsigned long ip;
unsigned short cs;
unsigned short __csh;
unsigned long flags;
unsigned long sp;
unsigned short ss;
unsigned short __ssh;
};
之后便是根据系统调用号进入真正实现功能函数:
检查EFLAGS中VM位,SS中TI位是否设置为1以及CS中RPL:
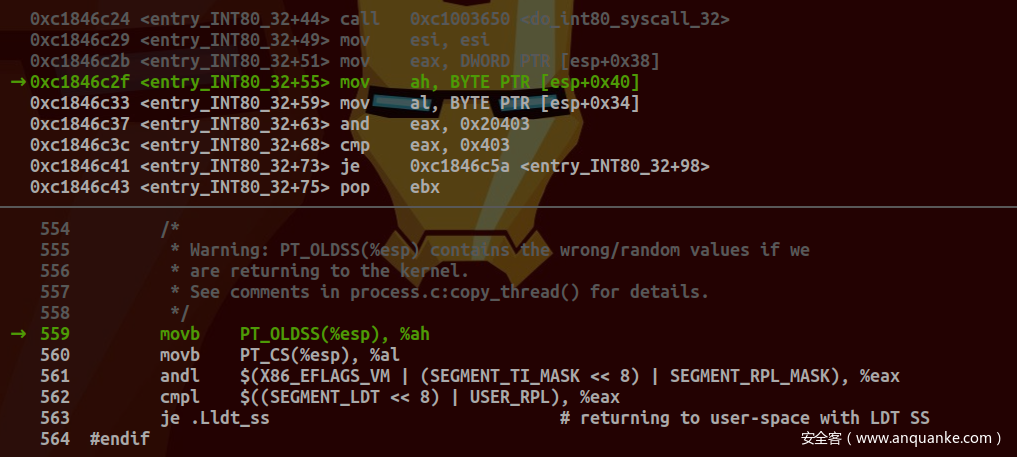

若TI位未设置,则使用GDT进行索引。之后恢复SAVE_ALL所保存的寄存器值(出栈及入栈顺序与pt_regs中所定义顺序一致)并执行IRET指令返回调用程序:
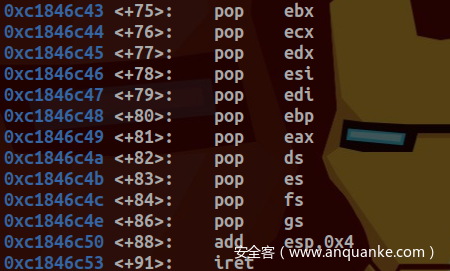
返回值则在之前由do_syscall_32_irqs_on函数保存在了栈中:
故RESTORE_REGS恢复寄存器值时将其弹出到EAX以传递给调用程序。
0x02 SYSENTER
a. 源码分析
根据Intel SDM中描述,使用SYSENTER命令需要事先设置如下三个MSR寄存器值;

执行到SYSENTER命令时操作如下:

Linux源码中设置三个MSR寄存器值操作位于syscall_init函数(arch/x86/kernel/cpu/common.c)中:
#ifdef CONFIG_IA32_EMULATION
wrmsrl(MSR_CSTAR, (unsigned long)entry_SYSCALL_compat);
/*
* This only works on Intel CPUs.
* On AMD CPUs these MSRs are 32-bit, CPU truncates MSR_IA32_SYSENTER_EIP.
* This does not cause SYSENTER to jump to the wrong location, because
* AMD doesn't allow SYSENTER in long mode (either 32- or 64-bit).
*/
wrmsrl_safe(MSR_IA32_SYSENTER_CS, (u64)__KERNEL_CS);
wrmsrl_safe(MSR_IA32_SYSENTER_ESP, (unsigned long)(cpu_entry_stack(cpu) + 1));
wrmsrl_safe(MSR_IA32_SYSENTER_EIP, (u64)entry_SYSENTER_compat);
#else
wrmsrl(MSR_CSTAR, (unsigned long)ignore_sysret);
wrmsrl_safe(MSR_IA32_SYSENTER_CS, (u64)GDT_ENTRY_INVALID_SEG);
wrmsrl_safe(MSR_IA32_SYSENTER_ESP, 0ULL);
wrmsrl_safe(MSR_IA32_SYSENTER_EIP, 0ULL);
#endif
编译时需要启用CONFIG_IA32_EMULATION选项。entry_SYSENTER_compat定义位于arch/x86/entry/entry_64_compat.S中:
/*
* 32-bit SYSENTER entry.
*
* 32-bit system calls through the vDSO's __kernel_vsyscall enter here
* on 64-bit kernels running on Intel CPUs.
*
* The SYSENTER instruction, in principle, should *only* occur in the
* vDSO. In practice, a small number of Android devices were shipped
* with a copy of Bionic that inlined a SYSENTER instruction. This
* never happened in any of Google's Bionic versions -- it only happened
* in a narrow range of Intel-provided versions.
*
* SYSENTER loads SS, RSP, CS, and RIP from previously programmed MSRs.
* IF and VM in RFLAGS are cleared (IOW: interrupts are off).
* SYSENTER does not save anything on the stack,
* and does not save old RIP (!!!), RSP, or RFLAGS.
*
* Arguments:
* eax system call number
* ebx arg1
* ecx arg2
* edx arg3
* esi arg4
* edi arg5
* ebp user stack
* 0(%ebp) arg6
*/
ENTRY(entry_SYSENTER_compat)
/* Interrupts are off on entry. */
SWAPGS
/* We are about to clobber %rsp anyway, clobbering here is OK */
SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/*
* User tracing code (ptrace or signal handlers) might assume that
* the saved RAX contains a 32-bit number when we're invoking a 32-bit
* syscall. Just in case the high bits are nonzero, zero-extend
* the syscall number. (This could almost certainly be deleted
* with no ill effects.)
*/
movl %eax, %eax
/* Construct struct pt_regs on stack */
pushq $__USER32_DS /* pt_regs->ss */
pushq %rbp /* pt_regs->sp (stashed in bp) */
/*
* Push flags. This is nasty. First, interrupts are currently
* off, but we need pt_regs->flags to have IF set. Second, even
* if TF was set when SYSENTER started, it's clear by now. We fix
* that later using TIF_SINGLESTEP.
*/
pushfq /* pt_regs->flags (except IF = 0) */
orl $X86_EFLAGS_IF, (%rsp) /* Fix saved flags */
pushq $__USER32_CS /* pt_regs->cs */
pushq $0 /* pt_regs->ip = 0 (placeholder) */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq $0 /* pt_regs->r8 = 0 */
pushq $0 /* pt_regs->r9 = 0 */
pushq $0 /* pt_regs->r10 = 0 */
pushq $0 /* pt_regs->r11 = 0 */
pushq %rbx /* pt_regs->rbx */
pushq %rbp /* pt_regs->rbp (will be overwritten) */
pushq $0 /* pt_regs->r12 = 0 */
pushq $0 /* pt_regs->r13 = 0 */
pushq $0 /* pt_regs->r14 = 0 */
pushq $0 /* pt_regs->r15 = 0 */
cld
/*
* SYSENTER doesn't filter flags, so we need to clear NT and AC
* ourselves. To save a few cycles, we can check whether
* either was set instead of doing an unconditional popfq.
* This needs to happen before enabling interrupts so that
* we don't get preempted with NT set.
*
* If TF is set, we will single-step all the way to here -- do_debug
* will ignore all the traps. (Yes, this is slow, but so is
* single-stepping in general. This allows us to avoid having
* a more complicated code to handle the case where a user program
* forces us to single-step through the SYSENTER entry code.)
*
* NB.: .Lsysenter_fix_flags is a label with the code under it moved
* out-of-line as an optimization: NT is unlikely to be set in the
* majority of the cases and instead of polluting the I$ unnecessarily,
* we're keeping that code behind a branch which will predict as
* not-taken and therefore its instructions won't be fetched.
*/
testl $X86_EFLAGS_NT|X86_EFLAGS_AC|X86_EFLAGS_TF, EFLAGS(%rsp)
jnz .Lsysenter_fix_flags
.Lsysenter_flags_fixed:
/*
* User mode is traced as though IRQs are on, and SYSENTER
* turned them off.
*/
TRACE_IRQS_OFF
movq %rsp, %rdi
call do_fast_syscall_32
/* XEN PV guests always use IRET path */
ALTERNATIVE "testl %eax, %eax; jz .Lsyscall_32_done", \
"jmp .Lsyscall_32_done", X86_FEATURE_XENPV
jmp sysret32_from_system_call
.Lsysenter_fix_flags:
pushq $X86_EFLAGS_FIXED
popfq
jmp .Lsysenter_flags_fixed
GLOBAL(__end_entry_SYSENTER_compat)
ENDPROC(entry_SYSENTER_compat)
关于SWAPGS可阅读参阅链接:

do_fast_syscall_32函数会调用do_syscall_32_irqs_on:
/* Returns 0 to return using IRET or 1 to return using SYSEXIT/SYSRETL. */
__visible long do_fast_syscall_32(struct pt_regs *regs)
{
......
/* Now this is just like a normal syscall. */
do_syscall_32_irqs_on(regs);
......
}
该函数其余代码部分见后文描述。
b. 动态调试
使用如下代码作为示例(不建议这样去执行系统调用,下面的代码仅仅是作为展示):
int
main(int argc, char *argv[])
{
unsigned long syscall_nr = 1;
long exit_status = 44;
asm ("movl %0, %%eax\n"
"movl %1, %%ebx\n"
"sysenter"
: /* output parameters, we aren't outputting anything, no none */
/* (none) */
: /* input parameters mapped to %0 and %1, repsectively */
"m" (syscall_nr), "m" (exit_status)
: /* registers that we are "clobbering", unneeded since we are calling exit */
"eax", "ebx");
}
于entry_SYSENTER_compat成功断下:

将regs传递给do_fast_syscall_32:

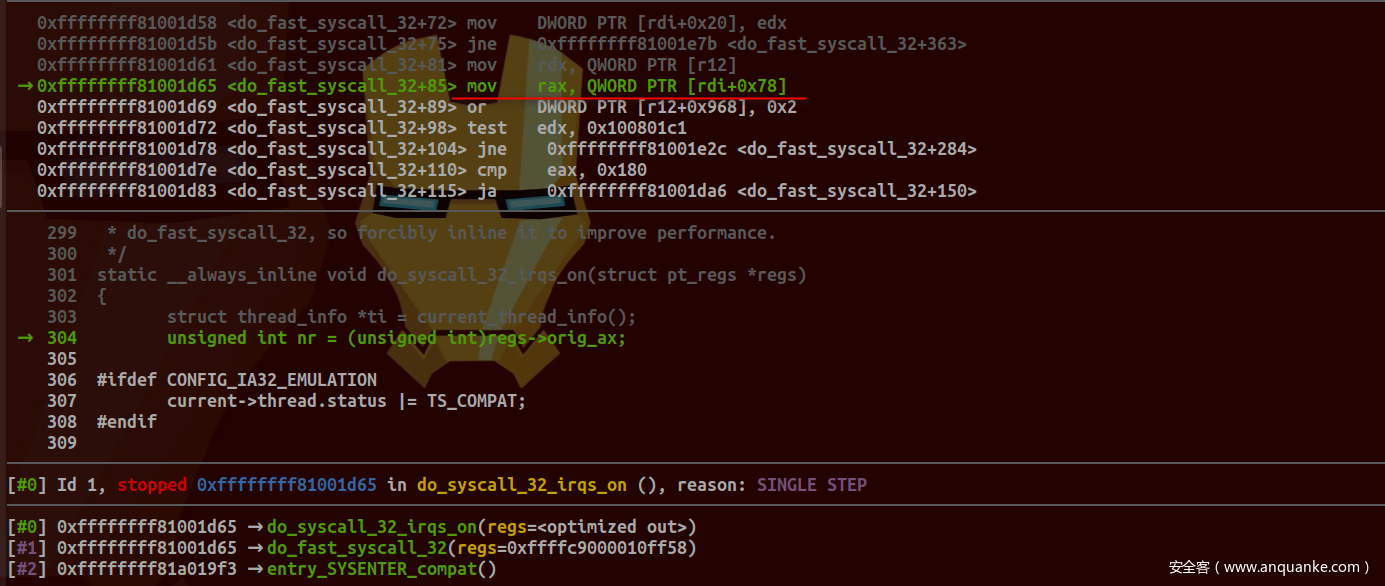
可以看到其orig_ax成员偏移与之前相比发生了变化, 这是因为regs对应结构定义为:
struct pt_regs {
/*
* C ABI says these regs are callee-preserved. They aren't saved on kernel entry
* unless syscall needs a complete, fully filled "struct pt_regs".
*/
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
/* These regs are callee-clobbered. Always saved on kernel entry. */
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
/*
* On syscall entry, this is syscall#. On CPU exception, this is error code.
* On hw interrupt, it's IRQ number:
*/
unsigned long orig_ax;
/* Return frame for iretq */
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
/* top of stack page */
}
通过sysret指令返回调用程序:
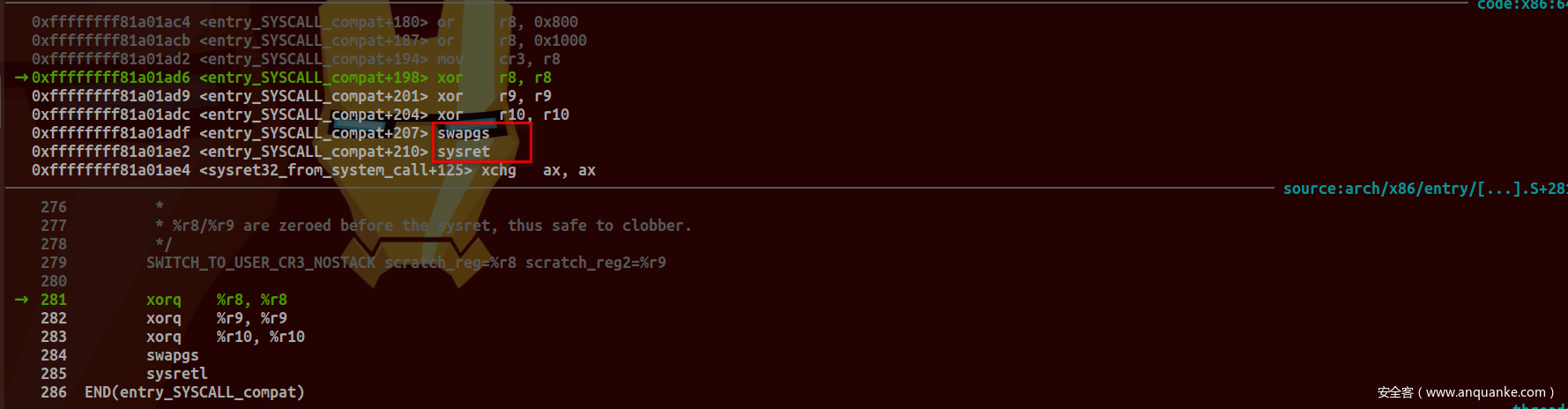
Intel SDM中对此命令描述如下:

c. __kernel_vsyscall
严格意义上来说,上一小节中给出示例不符合系统调用规范,笔者在实际测试时发现手动执行SYSENTER会出现错误。本小节示例如下:
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(int argc, char *argv[]){
char buffer[80] = "/tmp/test";
int fd = open(buffer, O_RDONLY);
int size = read(fd, buffer, sizeof(buffer));
close(fd);
}
采用静态编译方式,目标平台32位。跟踪open函数调用如下:
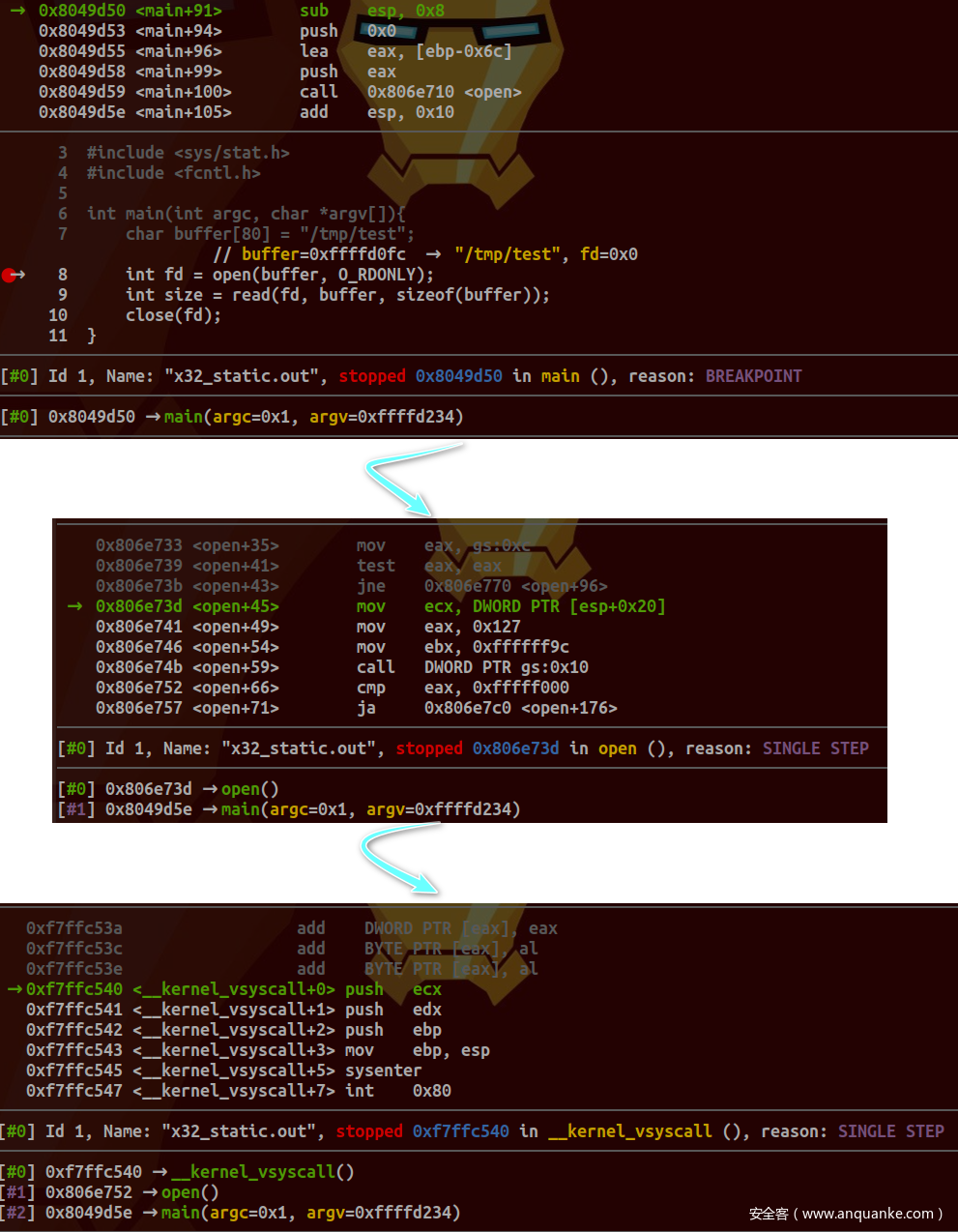
对应源码位于arch/x86/entry/vdso/vdso32/system_call.S文件中:
.text
.globl __kernel_vsyscall
.type __kernel_vsyscall,@function
ALIGN
__kernel_vsyscall:
CFI_STARTPROC
pushl %ecx
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET ecx, 0
pushl %edx
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET edx, 0
pushl %ebp
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET ebp, 0
#define SYSENTER_SEQUENCE "movl %esp, %ebp; sysenter"
#define SYSCALL_SEQUENCE "movl %ecx, %ebp; syscall"
#ifdef CONFIG_X86_64
/* If SYSENTER (Intel) or SYSCALL32 (AMD) is available, use it. */
ALTERNATIVE_2 "", SYSENTER_SEQUENCE, X86_FEATURE_SYSENTER32, \
SYSCALL_SEQUENCE, X86_FEATURE_SYSCALL32
#else
ALTERNATIVE "", SYSENTER_SEQUENCE, X86_FEATURE_SEP
#endif
/* Enter using int $0x80 */
int $0x80
GLOBAL(int80_landing_pad)
/*
* Restore EDX and ECX in case they were clobbered. EBP is not
* clobbered (the kernel restores it), but it's cleaner and
* probably faster to pop it than to adjust ESP using addl.
*/
popl %ebp
CFI_RESTORE ebp
CFI_ADJUST_CFA_OFFSET -4
popl %edx
CFI_RESTORE edx
CFI_ADJUST_CFA_OFFSET -4
popl %ecx
CFI_RESTORE ecx
CFI_ADJUST_CFA_OFFSET -4
ret
CFI_ENDPROC
.size __kernel_vsyscall,.-__kernel_vsyscall
.previous
关于系统调用指令,根据平台选择是SYSENTER或是SYSCALL,若均不支持则执行传统系统调用int $0x80。
0x03 SYSCALL
Intel SDM:

同样是位于syscall_init函数中:
void syscall_init(void)
{
extern char _entry_trampoline[];
extern char entry_SYSCALL_64_trampoline[];
int cpu = smp_processor_id();
unsigned long SYSCALL64_entry_trampoline =
(unsigned long)get_cpu_entry_area(cpu)->entry_trampoline +
(entry_SYSCALL_64_trampoline - _entry_trampoline);
wrmsr(MSR_STAR, 0, (__USER32_CS << 16) | __KERNEL_CS);
if (static_cpu_has(X86_FEATURE_PTI))
wrmsrl(MSR_LSTAR, SYSCALL64_entry_trampoline);
else
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
......
/* Flags to clear on syscall */
wrmsrl(MSR_SYSCALL_MASK,
X86_EFLAGS_TF|X86_EFLAGS_DF|X86_EFLAGS_IF|
X86_EFLAGS_IOPL|X86_EFLAGS_AC|X86_EFLAGS_NT);
}
entry_SYSCALL_64中执行系统调用是采用如下方式:
#ifdef CONFIG_RETPOLINE
movq sys_call_table(, %rax, 8), %rax
call __x86_indirect_thunk_rax
#else
call *sys_call_table(, %rax, 8)
调用约定是:
* Registers on entry:
* rax system call number
* rcx return address
* r11 saved rflags (note: r11 is callee-clobbered register in C ABI)
* rdi arg0
* rsi arg1
* rdx arg2
* r10 arg3 (needs to be moved to rcx to conform to C ABI)
* r8 arg4
* r9 arg5
* (note: r12-r15, rbp, rbx are callee-preserved in C ABI)
返回依然是采用SYSRET指令:
#define USERGS_SYSRET64 \
swapgs; \
sysretq;
#define USERGS_SYSRET32 \
swapgs; \
sysretl
0x04 VDSO
VDSO全称是Virtual Dynamic Shared Object,它映射到用户地址空间中,可以被用户程序直接调用,但没有对应文件,是由内核直接映射:

其导出函数见arch/x86/entry/vdso/vdso.lds.S文件:
VERSION {
LINUX_2.6 {
global:
clock_gettime;
__vdso_clock_gettime;
gettimeofday;
__vdso_gettimeofday;
getcpu;
__vdso_getcpu;
time;
__vdso_time;
local: *;
};
}
以gettimeofday为例, 其定义位于同目录下vclock_gettime.c文件中:
extern int __vdso_gettimeofday(struct timeval *tv, struct timezone *tz);
......
notrace int __vdso_gettimeofday(struct timeval *tv, struct timezone *tz)
{
if (likely(tv != NULL)) {
if (unlikely(do_realtime((struct timespec *)tv) == VCLOCK_NONE))
return vdso_fallback_gtod(tv, tz);
tv->tv_usec /= 1000;
}
if (unlikely(tz != NULL)) {
tz->tz_minuteswest = gtod->tz_minuteswest;
tz->tz_dsttime = gtod->tz_dsttime;
}
return 0;
}
int gettimeofday(struct timeval *, struct timezone *)
__attribute__((weak, alias("__vdso_gettimeofday")));
用户调用gettimeofday时,实际执行的是__vdso_gettimeofday。示例代码如下:
#include <time.h>
#include <sys/time.h>
#include <stdio.h>
int main(int argc, char **argv)
{
char buffer[40];
struct timeval time;
gettimeofday(&time, NULL);
strftime(buffer, 40, "Current date/time: %m-%d-%Y/%T", localtime(&time.tv_sec));
printf("%s\n",buffer);
return 0;
}
编译之后跟踪gettimeofday函数调用:

查看内存空间映射情况:
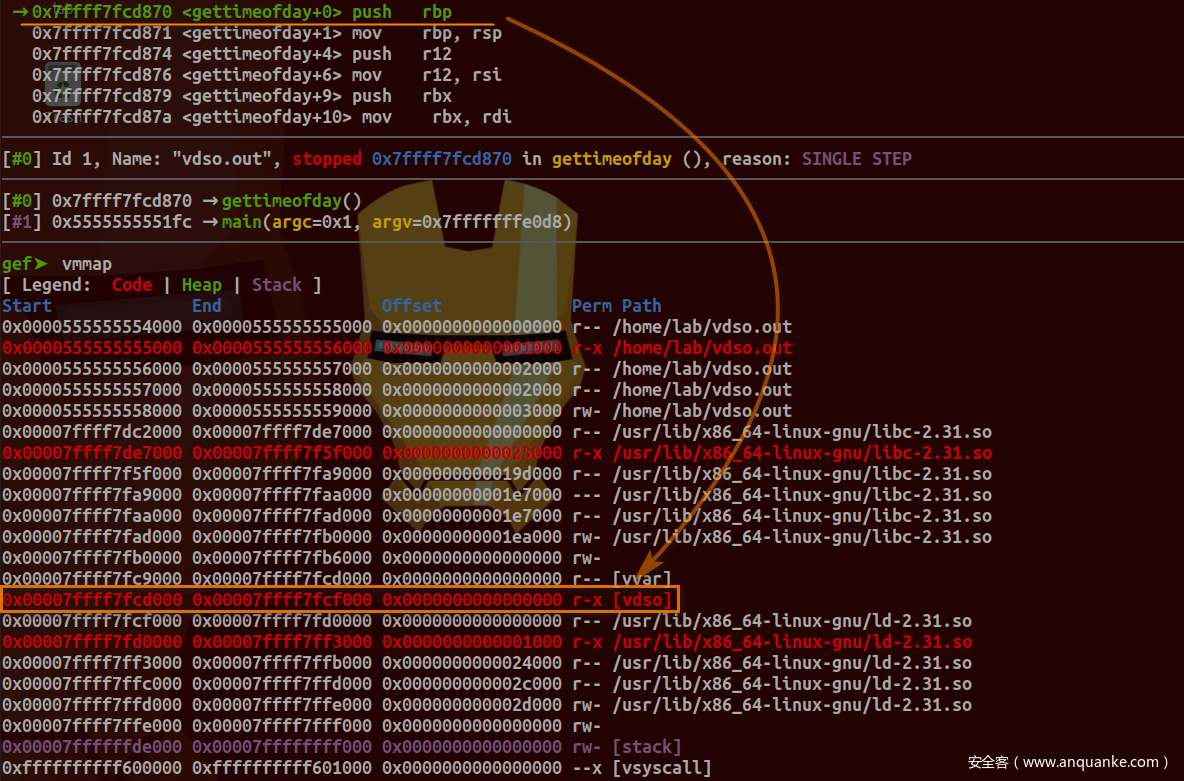
可以看到执行指令确实映射在vdso区域内。
0x05 参阅链接
- The Definitive Guide to Linux System Calls——Prerequisite information
- Linux Kernel 实践(二):劫持系统调用
- 代码解析Linux系统调用
- 谈结构体struct 初始化多出的点号“.”,数组[]初始化多出的逗号“,
- x86 架构下 Linux 的系统调用与 vsyscall, vDSO
- Setup: Ubuntu host, QEMU vm, x86-64 kernel
- x86-64 Spec addition – SwapGS instruction
- Linux系统调用过程分析
- Timers and time management in the Linux kernel. Part 7







发表评论
您还未登录,请先登录。
登录